
提高篇:元胞自动机介绍及其实现方法
前言
元胞自动机(Cellular Automaton, CA)是一种用简单局部规则模拟复杂全局行为的离散动力学建模方法。它将空间划分为网格,每个网格元胞根据邻居状态按确定或随机规则演化,适合模拟具有空间显式特征的动态系统——交通流、疾病传播、火灾蔓延、人群疏散、城市扩张等。
对于数学建模竞赛来说,元胞自动机的核心优势是:不需要建立复杂的微分方程,而是通过直观的格子规则和参数调节就能模拟出丰富的时空动态。这使得 CA 成为处理空间扩散类问题的利器。
适用读者
本教程面向已经了解传统统计学方法等基础数学建模方法的读者。如果你已经掌握 OLS 回归、假设检验、聚类分析等方法,但对空间动态建模还不熟悉,本教程将带你从零开始掌握元胞自动机。
本教程不深入探讨元胞自动机的理论数学(如元胞自动机的图灵完备性证明、形式语言理论等),而是聚焦于如何用 Python 代码实现各类 CA 模型、如何调节参数、如何解读结果、如何画出论文配图。
内容结构
环境说明
Python 版本:3.8+
核心依赖:NumPy(向量化运算)、Matplotlib(可视化)
中文字体:
plt.rcParams['font.sans-serif'] = ['SimHei']
运行方式
# 安装依赖(如未安装)
pip install numpy matplotlib scipy
# 每个章节的代码均可独立运行
import numpy as np
import matplotlib.pyplot as plt
学习建议
先通读第 1 章,理解四大要素和向量化实现框架
第 2 章(一维 CA)和第 3 章(生命游戏)是理解 CA 行为的基础,建议边读边跑代码
第 4–7 章是核心应用,每章对应一类典型建模场景,可直接作为数模论文的模板套用
第 8 章的性能优化和速查表是实战提效的关键,建议在跑大网格模拟前重点阅读
第1章 元胞自动机基础概念
1.1 什么是元胞自动机
元胞自动机(Cellular Automaton, CA)是一种离散的动力学系统,由大量简单的单元(称为"元胞")按照局部规则在网格空间上演化。尽管单个元胞的行为极其简单,但整体却能涌现出高度复杂的时空模式——这是元胞自动机最迷人的特征。
元胞自动机在数学建模中的优势:
能够模拟空间显式的动态过程(不同于常微分方程的均匀混合假设)
局部相互作用即可产生全局模式
适合模拟交通流、疾病传播、火灾蔓延等具有空间特征的系统
1.2 四大要素
元胞自动机由以下四个基本要素构成:
1.2.1 元胞(Cell)
元胞是自动机的基本单元,每个元胞具有一个离散状态(如 0 或 1、健康/感染/康复等)。最简单的元胞自动机只使用两个状态,但复杂模型可以使用更多状态。

1.2.2 元胞空间(Lattice)
元胞排列成的网格结构,常见的有:
一维:线性排列(适合交通流、波传播)
二维正方形网格:最常用(适合扩散、生长过程)
二维六边形网格:各向同性更好(适合自然现象模拟)
三维:体素网格(适合 3D 扩散、肿瘤生长)
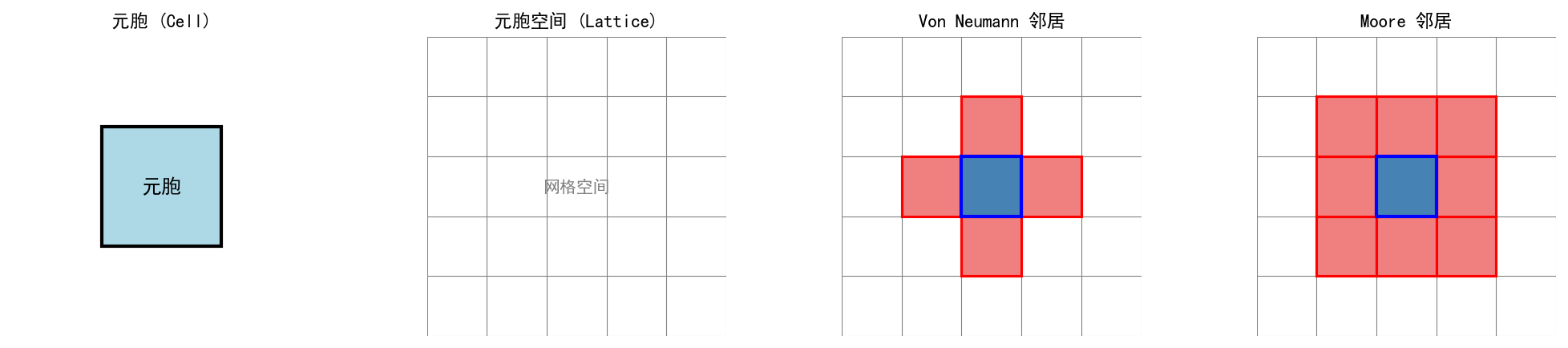
1.2.3 邻居(Neighborhood)
定义哪些元胞之间可以相互影响。两种最常用的邻居定义:
对于一维元胞自动机,邻居就是左右相邻的两个元胞(半径为 1 时)。
1.2.4 规则(Rule)
规则决定每个元胞在下一时刻的状态,基于当前自身状态和邻居状态。规则可以是确定性的(相同输入总是相同输出)或随机的(引入概率)。
1.3 一维元胞自动机——初体验
一维元胞自动机是最简单的 CA 形式。每个元胞的邻居是左右各一个元胞,三个元胞(左-中-右)共 种组合,每种组合可以映射到 0 或 1,因此一共有 种可能的规则,编号为 0–255(Wolfram 编码)。
import numpy as np
import matplotlib.pyplot as plt
def rule_1d(rule_num, generations=50):
"""生成一维元胞自动机"""
cells = np.zeros((generations, 2 * generations + 1), dtype=int)
cells[0, generations] = 1 # 初始单个激活元胞
# 解码 Wolfram 规则编号
rules = [int(x) for x in format(rule_num, '08b')]
rule_dict = {}
for i, (a, b, c) in enumerate([(1,1,1),(1,1,0),(1,0,1),(1,0,0),
(0,1,1),(0,1,0),(0,0,1),(0,0,0)]):
rule_dict[(a, b, c)] = rules[i]
for t in range(generations - 1):
for i in range(1, len(cells[0]) - 1):
left = cells[t, i-1]
center = cells[t, i]
right = cells[t, i+1]
cells[t+1, i] = rule_dict[(left, center, right)]
return cells
cells_rule30 = rule_1d(30, 60)
cells_rule184 = rule_1d(184, 60)

Stephen Wolfram 将 256 种一维 CA 规则分为四类:
Rule 30(上图左)是典型的混沌型规则,其右侧边界产生著名的分形三角形图案,甚至被用作随机数生成器。Rule 184(上图右)则可以模拟交通流——黑色条纹的移动反映了车流波。
1.4 元胞自动机 vs 其他建模方法
1.5 Python 实现基础框架
在后续章节中,我们将统一使用 NumPy 进行向量化操作,实现高效的元胞自动机模拟。基本框架如下:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
class CellularAutomaton:
def __init__(self, shape, states=2):
self.shape = shape # 网格形状 (rows, cols)
self.states = states # 状态数
self.grid = np.zeros(shape, dtype=int)
def initialize(self, method='random', **kwargs):
"""初始化网格状态"""
if method == 'random':
p = kwargs.get('p', 0.5)
self.grid = np.random.choice(self.states, self.shape,
p=[1-p, p] if self.states == 2 else None)
elif method == 'single':
cx, cy = kwargs.get('center', (self.shape[0]//2, self.shape[1]//2))
self.grid[cx, cy] = 1
def step(self):
"""执行一步演化(子类实现)"""
raise NotImplementedError
def run(self, steps, snapshot=False):
"""运行多步,可选择是否记录快照"""
history = []
for _ in range(steps):
self.step()
if snapshot:
history.append(self.grid.copy())
return history
1.6 本节小结
元胞自动机 = 元胞 + 元胞空间 + 邻居 + 规则
一维 CA 有 256 种规则,分为四类:均匀、周期、混沌、复杂
Von Neumann 邻居(4 邻域)和 Moore 邻居(8 邻域)是最常用的定义
元胞自动机适合模拟具有空间显式特征的系统
后续章节将使用 NumPy 向量化实现,避免 Python 循环带来的性能问题
第2章 一维元胞自动机
2.1 Wolfram 编码系统
在一维元胞自动机中,每个元胞的邻居是左右相邻的两个元胞。三个元胞(左-中-右)各有 0 或 1 两种状态,共 种输入组合。每种组合映射到 0 或 1 的输出,因此有 种可能的规则。
Stephen Wolfram 将这 256 种规则按二进制编码命名。例如 Rule 30 的二进制表示为 00011110,对应十进制 30。
2.2 四类规则
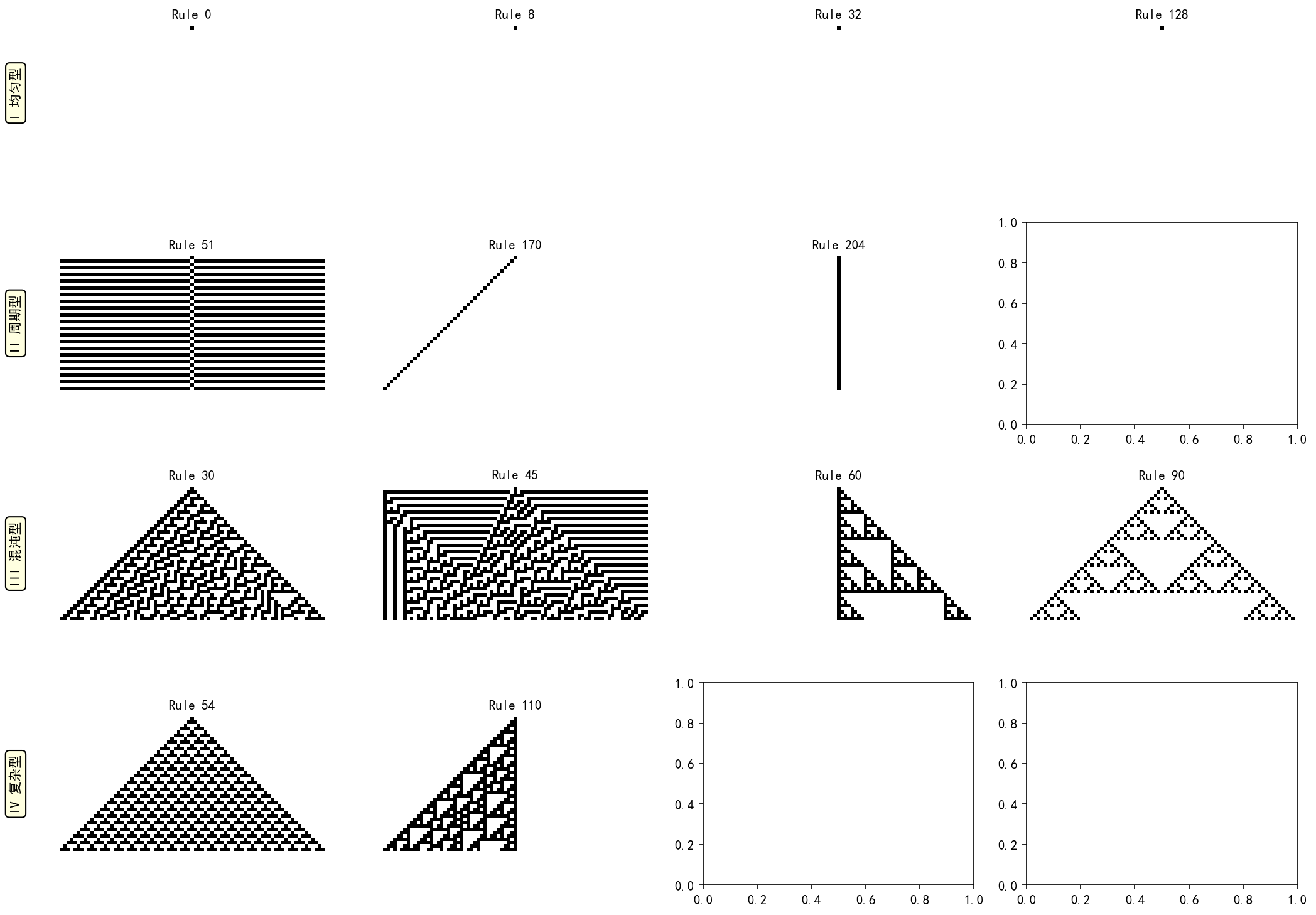
Wolfram 将 256 种规则分为四类:
关键洞见:III 类和 IV 类规则处于"混沌边缘"(Edge of Chaos)——介于完全有序和完全无序之间的区域,这是复杂系统产生丰富行为的典型位置。
2.3 Rule 30——混沌与伪随机数
Rule 30 是最著名的混沌型规则之一。从单点初始条件出发,其右侧边界产生分形三角形图案。

import numpy as np
import matplotlib.pyplot as plt
def run_rule_1d(rule_num, init='single', generations=50, width=None):
"""运行一维元胞自动机(向量化版本)"""
if width is None:
width = 2 * generations + 1
cells = np.zeros((generations, width), dtype=int)
if init == 'single':
cells[0, width // 2] = 1
elif init == 'random':
cells[0, :] = np.random.randint(0, 2, width)
# 解码规则
rules = np.array([int(x) for x in format(rule_num, '08b')])
lookup = np.zeros(8, dtype=int)
for idx, k in enumerate([(1,1,1),(1,1,0),(1,0,1),(1,0,0),
(0,1,1),(0,1,0),(0,0,1),(0,0,0)]):
lookup[k[0]*4 + k[1]*2 + k[2]] = rules[idx]
# 向量化演化
for t in range(1, generations):
left = cells[t-1, :-2]
center = cells[t-1, 1:-1]
right = cells[t-1, 2:]
key = left * 4 + center * 2 + right
cells[t, 1:-1] = lookup[key]
return cells
cells = run_rule_1d(30, generations=100, width=201)
plt.imshow(cells, cmap='magma', interpolation='nearest')
plt.axis('off')
Rule 30 的一个有趣应用:Wolfram 曾提议用 Rule 30 中间列的元胞状态作为伪随机数生成器,因为其行为在统计上近似随机。
2.4 Rule 90——谢尔宾斯基三角形
Rule 90 的规则对应 ,等价于左右邻居的 XOR 运算:。
从单点初始出发,Rule 90 精确地生成谢尔宾斯基三角形(Sierpinski Triangle)——一个经典的分形。

# 单点初始 → 完美分形
cells_90 = run_rule_1d(90, init='single', generations=64, width=129)
# 随机初始 → 不规则但仍有分形特征
cells_90r = run_rule_1d(90, init='random', generations=80, width=161)
左图展示了从单个激活元胞出发,经过 64 代演化后形成的谢尔宾斯基三角形。右图使用随机初始条件,分形结构被破坏但仍然可见——不同"波前"相互干涉,形成菱形图案。
2.5 Rule 110——通用计算
Rule 110 是已知最简单的图灵完备系统之一。Matthew Cook 在 2004 年证明,Rule 110 可以模拟循环标签系统(Cyclic Tag System),因此具有通用计算能力。

从随机初始条件出发,Rule 110 产生三种传播的"粒子"(局部结构),它们以不同速度运动并相互碰撞。这些碰撞可以编码逻辑门(AND、OR、NOT),进而构建任意计算。
这个结果的意义深远:一个仅由 8 条简单规则定义的系统,其计算能力等同于通用图灵机。这也支持了 Wolfram 的"计算等价性原理"——许多看似简单的系统实际上具有与任何计算系统相当的内在计算能力。
2.6 Rule 184——交通流模拟
Rule 184 可以模拟一维交通流:1 代表车辆,0 代表空位。规则是:如果前方有空位,车辆就前进一格;否则停在原地。

def simulate_traffic(density, steps=60, width=120):
"""Rule 184 交通流模拟"""
grid = np.zeros((steps, width), dtype=int)
grid[0, :] = np.random.choice([0, 1], width, p=[1-density, density])
rules = np.array([int(x) for x in format(184, '08b')])
lookup = np.zeros(8, dtype=int)
for idx, k in enumerate([(1,1,1),(1,1,0),(1,0,1),(1,0,0),
(0,1,1),(0,1,0),(0,0,1),(0,0,0)]):
lookup[k[0]*4 + k[1]*2 + k[2]] = rules[idx]
for t in range(1, steps):
left = np.roll(grid[t-1], 1)
center = grid[t-1]
right = np.roll(grid[t-1], -1)
key = left * 4 + center * 2 + right
grid[t, :] = lookup[key]
return grid
# 三种密度
grid_low = simulate_traffic(0.1) # 低密度
grid_mid = simulate_traffic(0.3) # 中等密度
grid_high = simulate_traffic(0.5) # 高密度
从左到右分别展示了低、中、高三种密度下的交通流时空图(横轴为空间位置,纵轴为时间):
低密度(0.1):车辆自由行驶,形成平行的对角线
中等密度(0.3):出现局部拥堵波,向后传播
高密度(0.5):严重拥堵,大部分车辆停滞不前
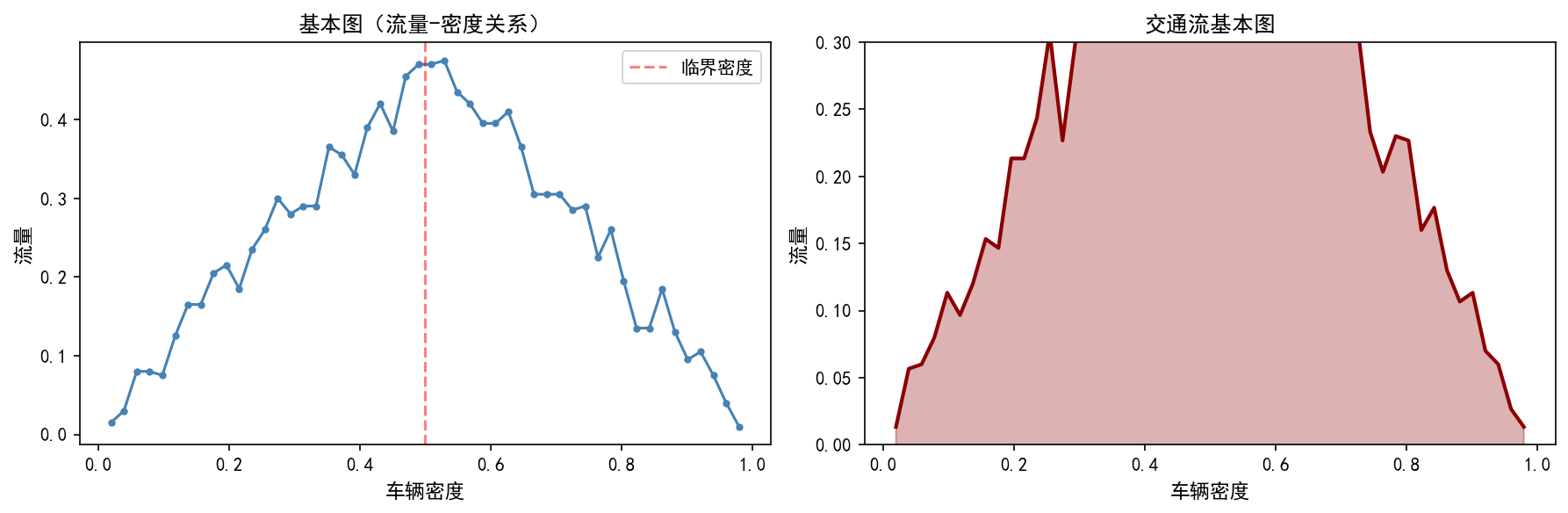
2.7 基本图(Fundamental Diagram)
交通工程中,流量-密度关系(基本图)是分析交通流的核心工具。
def measure_flux(density, steps=200, width=200):
"""测量交通流量(单位时间通过边界的车数)"""
grid = simulate_traffic(density, steps, width)
flux = 0
for t in range(1, steps):
# 跨越左边界的车数
if grid[t-1, 0] == 1 and grid[t-1, -1] == 0:
flux += 1
return flux / steps
densities = np.linspace(0.02, 0.98, 50)
fluxes = [measure_flux(d) for d in densities]
基本图的特征:
低密度区:流量随密度线性增长(自由流状态)
临界密度:流量达到峰值(约在密度 0.5 处)
高密度区:流量随密度下降(拥堵状态)
最大流量出现在临界密度处,这对应实际道路上的通行能力
2.8 实用技巧速查
2.9 本节小结
一维 CA 有 256 种规则,分为四类:均匀、周期、混沌、复杂
Rule 30 产生混沌行为,可用作伪随机数生成
Rule 90 等价于 XOR,生成谢尔宾斯基分形
Rule 110 是图灵完备的——最简单的通用计算机器
Rule 184 模拟交通流,展示自由流→拥堵的相变
基本图描述了流量与密度的关系,是交通工程的核心工具
向量化实现(
np.roll+ 查找表)比逐元胞循环快得多
第3章 生命游戏
3.1 Conway 生命游戏规则
Conway 的"生命游戏"(Game of Life)是最著名的元胞自动机,由 John Horton Conway 于 1970 年提出。它是一个零玩家游戏——给定初始状态后,系统自动演化。
规则(每个元胞只有两种状态:生 = 1,死 = 0):
使用 Moore 邻居(8 个邻居),四个角落和边缘采用截断边界(即边界外的元胞始终为死)。
3.2 向量化实现
import numpy as np
def game_of_life_step(grid):
"""生命游戏一步演化(向量化)"""
neighbors = np.zeros_like(grid)
# 8个方向的邻居求和
for di in [-1, 0, 1]:
for dj in [-1, 0, 1]:
if di == 0 and dj == 0:
continue
neighbors += np.roll(np.roll(grid, di, axis=0), dj, axis=1)
# Conway规则
new_grid = np.zeros_like(grid)
new_grid[(grid == 1) & ((neighbors == 2) | (neighbors == 3))] = 1
new_grid[(grid == 0) & (neighbors == 3)] = 1
return new_grid
核心技巧:使用 np.roll() 实现周期性移位,8 次移位叠加得到每个元胞的邻居总数。向量化避免了 Python 的双重 for 循环,速度提升约 100 倍。
3.3 经典图案

静态图案(Still Lifes)
这些图案在演化中保持不变:
蜂箱(Beehive):6 个元胞的最小静态结构
方块(Block):最简单的静态图案
振荡器(Oscillators)
这些图案周期性重复:
闪烁灯(Blinker):周期 2,3 个元胞
脉冲星(Pulsar):周期 2,48 个元胞,具有高度对称性
飞船(Spaceships)
这些图案在网格中平移运动:
滑翔机(Glider):5 个元胞,每 4 代向右下方移动一格。这是最简单的"飞船",在生命游戏中扮演信息载体的角色。
混沌增长图案
R-pentomino:仅 5 个元胞,但经过 1103 代才稳定下来,最终产生 6 个滑翔机。它展示了简单初始条件如何导致长期复杂行为。
3.4 滑翔机运动

滑翔机每 4 代完成一个周期,向右下方移动一格(对角线方向)。这个特性非常重要——滑翔机可以被用来在生命游戏中传递信息。
glider = np.zeros((15, 15), dtype=int)
glider[1:4, 1:4] = [[0,1,0],
[0,0,1],
[1,1,1]]
history = run_game_of_life(glider.copy(), 20)
从上到下观察滑翔机的运动轨迹,可以看到它沿着对角线方向平移。这种"自复制"的运动模式是生命游戏中涌现行为的典型例子——简单的局部规则产生了复杂的全局运动。
3.5 R-pentomino:从简单到复杂
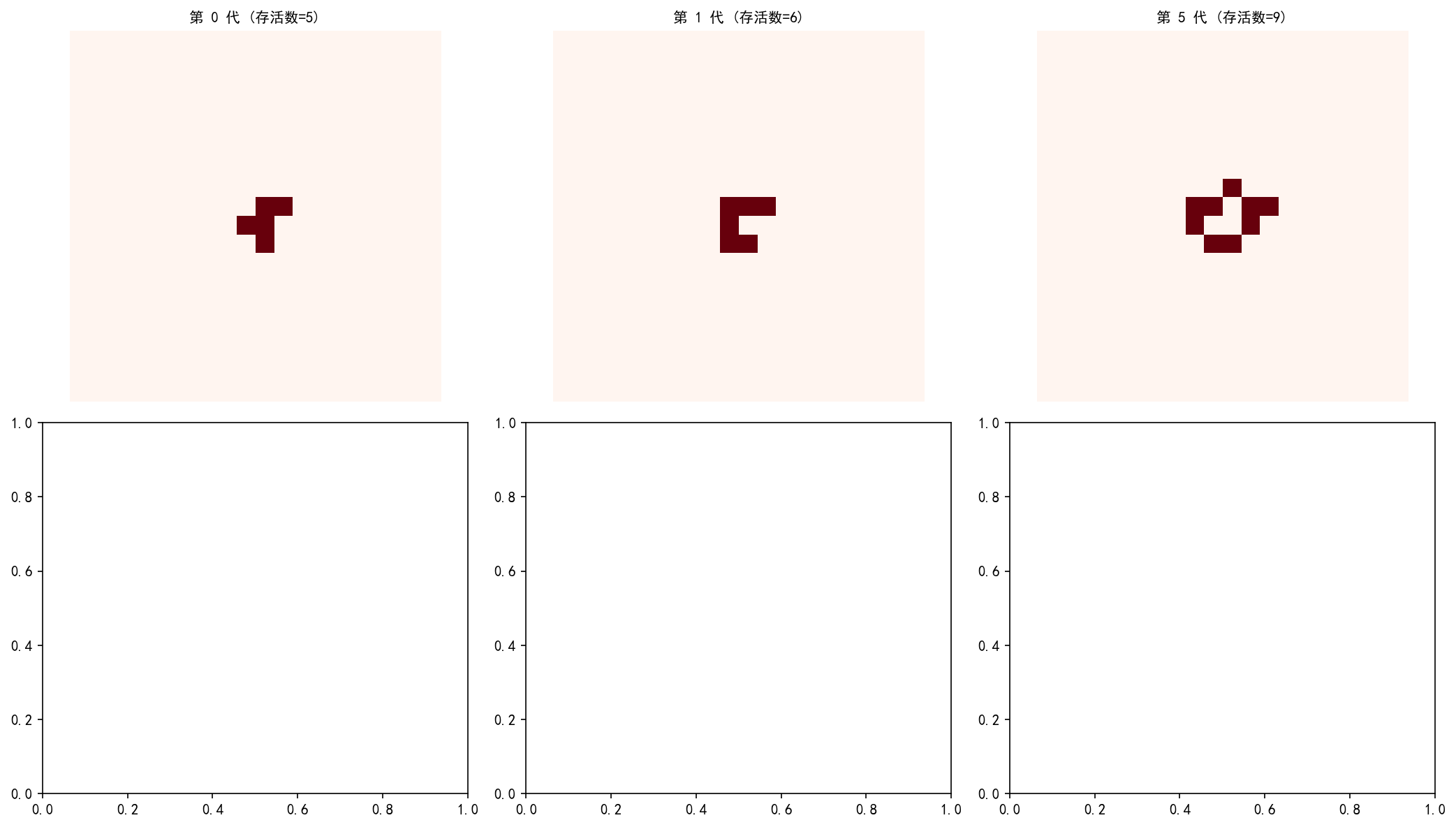
r_pentomino = np.zeros((20, 20), dtype=int)
r_pentomino[9,10] = 1; r_pentomino[9,11] = 1
r_pentomino[10,9] = 1; r_pentomino[10,10] = 1
r_pentomino[11,10] = 1
R-pentomino 最初只是一个 L 形的 5 元胞图案,但它产生了令人惊奇的演化行为:
前 10 代:快速扩张,形成不规则的扩散图案
50 代:产生了滑翔机发射器
500 代:接近稳定,产生多个滑翔机和振荡器
1103 代:完全稳定
这个例子说明:即使是最简单的初始条件,也可能产生长期的复杂行为。
3.6 种群数量动态
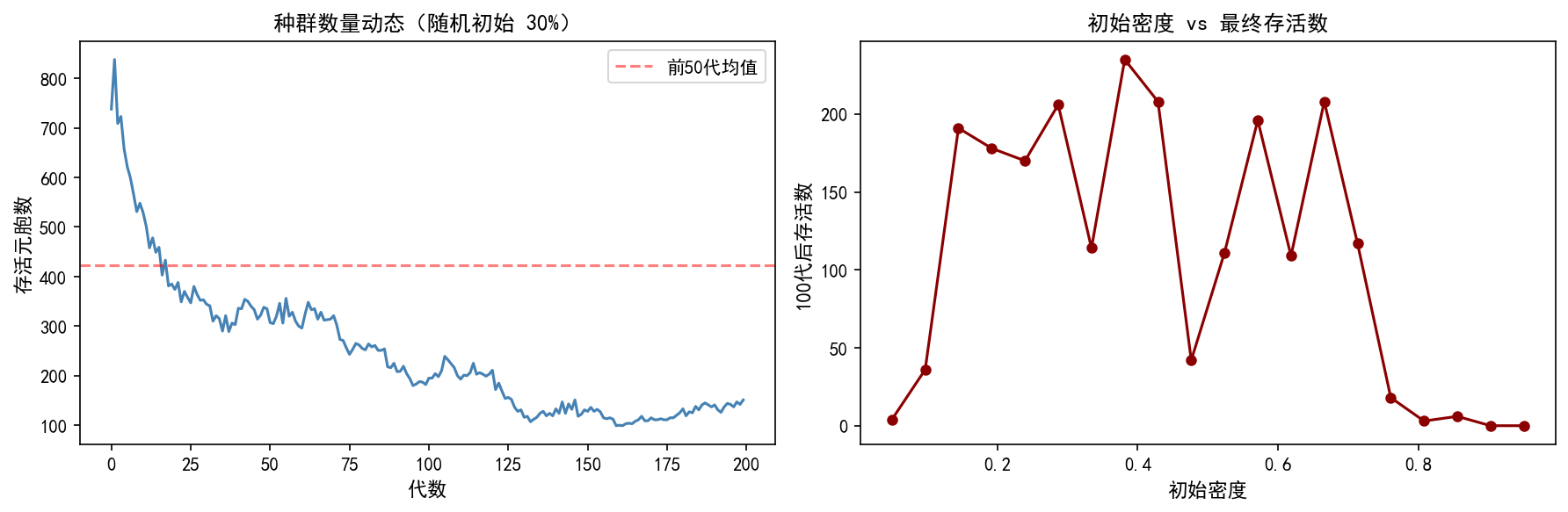
np.random.seed(42)
grid = np.random.choice([0,1], size=(50,50), p=[0.7,0.3])
pop_history = []
for _ in range(200):
pop_history.append(np.sum(grid))
grid = game_of_life_step(grid)
左图展示了从 30% 随机密度初始的种群数量变化。可以看到:
初期骤降:大量孤立元胞因孤独死亡迅速消失
振荡阶段:剩余结构形成振荡器和稳定图案
稳定阶段:系统收敛到一个准平衡态
右图展示了不同初始密度对应的最终存活数。临界密度约为 30%——低于此密度系统趋向灭绝,高于此密度系统维持活跃。
3.7 滑翔机枪——无限增长

Gosper Glider Gun 是第一个被发现的无限增长图案。它由 Bill Gosper 于 1970 年发现,由两个振荡器组成,周期性地向右发射滑翔机。
gun = np.zeros((30, 30), dtype=int)
# 左上振荡器块
gun[5,1:6] = 1; gun[6,1:6] = 1
# 连接桥
gun[5,11] = 1; gun[6,13] = 1; gun[7,12] = 1
# ... (完整图案见脚本)
滑翔机枪的存在证明了生命游戏中可以存在无界增长的模式——即使局部规则是确定性的,系统的全局行为可以无限复杂。
3.8 图灵完备性
生命游戏是图灵完备的——可以通过滑翔机枪、滑翔机碰撞和逻辑门构造,模拟任何图灵机的计算。这意味着:
理论上可以在生命游戏中实现任何算法
判定一个给定图案是否会无限增长是一个不可判定问题
生命游戏中可以构造"计算机中的计算机"
3.9 实用技巧速查
3.10 本节小结
生命游戏仅 4 条规则,却能产生静态、振荡、运动、混沌、无限增长等多种行为
图案分类:Still Life(静态)、Oscillator(振荡)、Spaceship(运动)、Gun(发射)
滑翔机是信息传递的载体,滑翔机枪是无限增长的来源
向量化实现(
np.roll)比逐元胞循环快约 100 倍生命游戏是图灵完备的,具有通用计算能力
R-pentomino 说明简单初始可以导致长期复杂行为
第4章 森林火灾模型
4.1 Drossel-Schwabl 森林火灾模型
森林火灾模型(Forest Fire Model, FFM)是研究自组织临界性(Self-Organized Criticality, SOC)的经典元胞自动机模型。Drossel 和 Schwabl 于 1992 年提出的版本包含三个状态和三条规则:
状态定义:
演化规则(同步更新,Moore 邻居):
燃烧 → 空地:燃烧中的元胞在下一步变为空地
蔓延:树木若邻居中有燃烧的元胞,则被点燃(变为燃烧状态)
生长:空地以概率 p 长出新树
闪电:树木以概率 f 被闪电击中而自燃
import numpy as np
from matplotlib.colors import ListedColormap
cmap = ListedColormap(['#f0f0f0', '#2d8f2d', '#d4380d']) # 空地/树木/燃烧
def forest_fire_step(grid, p_grow=0.01, p_strike=0.001):
"""森林火灾模型一步演化"""
new_grid = grid.copy()
# 计算燃烧邻居数
burning = (grid == 2).astype(int)
burn_neighbors = np.zeros_like(grid, dtype=int)
for di in [-1, 0, 1]:
for dj in [-1, 0, 1]:
if di == 0 and dj == 0:
continue
burn_neighbors += np.roll(np.roll(burning, di, 0), dj, 1)
# 规则:燃烧 → 空地
new_grid[grid == 2] = 0
# 规则:树木被邻居点燃
new_grid[(grid == 1) & (burn_neighbors > 0)] = 2
# 规则:闪电自燃
rand = np.random.random(grid.shape)
new_grid[(grid == 1) & (rand < p_strike)] = 2
# 规则:空地长树
new_grid[(grid == 0) & (rand < p_grow) & (new_grid == 0)] = 1
return new_grid
4.2 演化过程
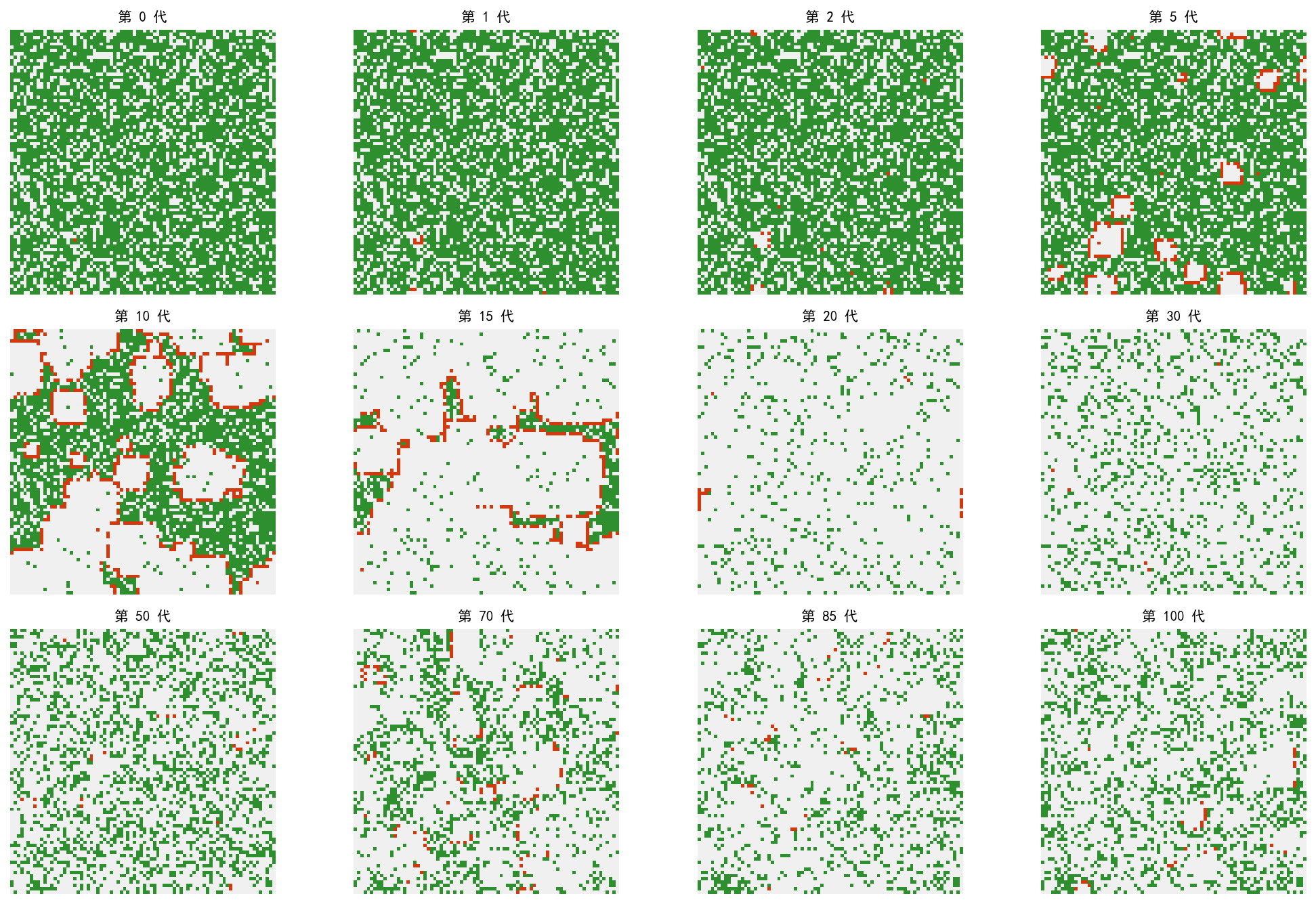
从随机初始森林(70% 密度)和 3 个起火点出发:
早期(1-5 代):火线向四周蔓延,形成环状燃烧波
中期(10-30 代):火线遇到空地衰减,出现多条火线
后期(50-100 代):森林重新生长,系统进入生长-燃烧的动态平衡
4.3 参数敏感性
闪电概率 f 和生长概率 p 控制了系统的行为:
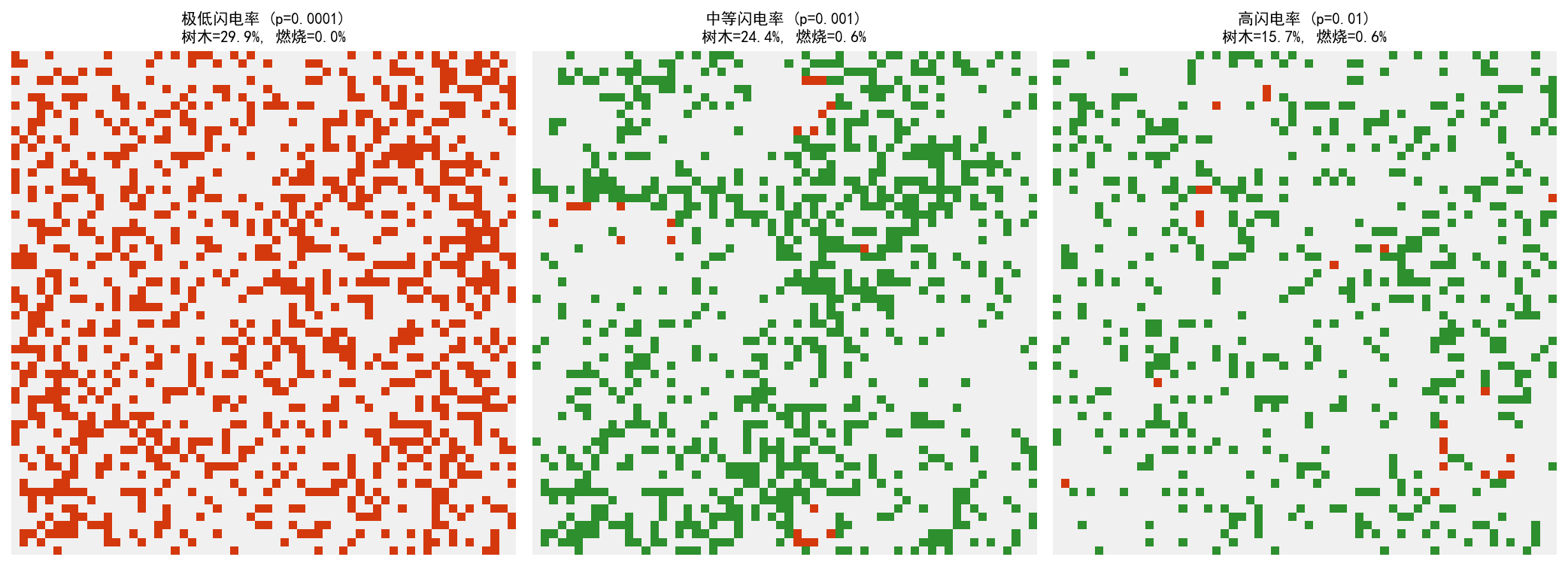
当 f→0 时,系统趋近于自组织临界状态——森林密度自发地调整到临界值附近,小火灾频繁,大火灾稀有但破坏巨大。
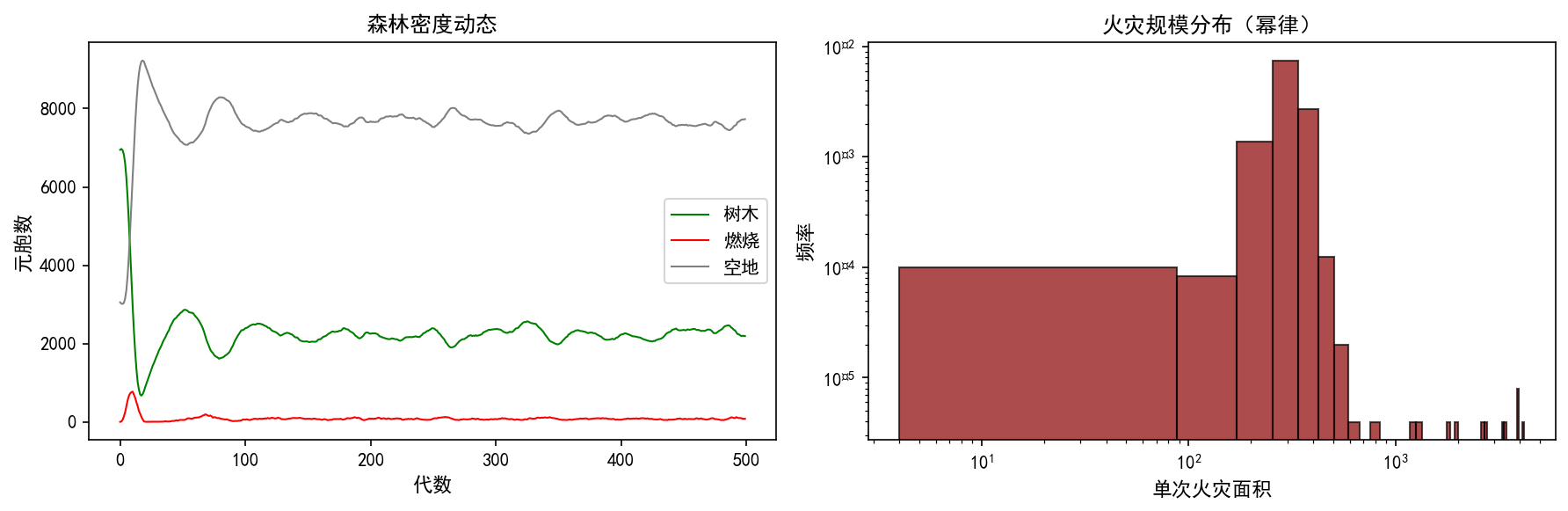
4.4 森林密度动态
np.random.seed(42)
grid = np.random.choice([0, 1], size=(100, 100), p=[0.3, 0.7])
grid[50, 50] = 2 # 单点起火
tree_counts, burn_counts, empty_counts = [], [], []
for _ in range(500):
tree_counts.append(np.sum(grid == 1))
burn_counts.append(np.sum(grid == 2))
empty_counts.append(np.sum(grid == 0))
grid = forest_fire_step(grid, p_grow=0.01, p_strike=0.001)
左图展示了树木、燃烧、空地三类元胞的数量随时间变化:
树木(绿色):在临界密度附近振荡
燃烧(红色):呈脉冲状——偶尔的大火事件
空地(灰色):大火后骤增,然后缓慢恢复
右图的火灾规模分布在对数坐标下近似为一条直线,表明火灾大小服从幂律分布(Power Law):
这是自组织临界系统的标志性特征——没有特征尺度,小火灾和大火灾遵循相同的统计规律。
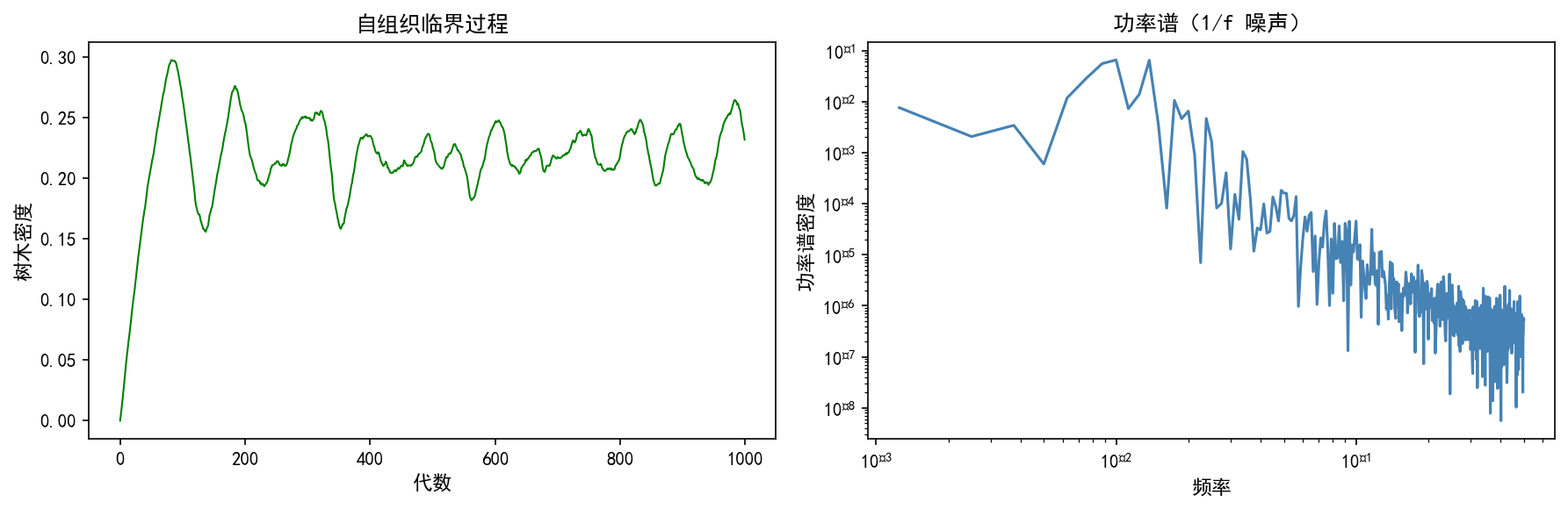
4.5 自组织临界性(SOC)
自组织临界性是指系统自发地演化到临界状态,而不需要外部参数精确调节。森林火灾模型是 SOC 的经典示例之一。
grid = np.zeros((100, 100), dtype=int)
tree_density_series = []
for _ in range(1000):
tree_density_series.append(np.sum(grid == 1) / 10000)
grid = forest_fire_step(grid, p_grow=0.005, p_strike=0.0005)
SOC 系统的关键特征:
1/f 噪声:功率谱密度 ,其中
幂律分布:事件规模的分布没有特征尺度
鲁棒性:系统受到扰动后能自发恢复到临界状态
其他 SOC 系统的例子:沙堆模型、地震模型、太阳耀斑。
4.6 建模应用——森林防火策略
森林火灾模型可以用于评估不同的防火策略:
悖论:完全扑灭所有小火(降低 f)会导致森林密度积累,最终引发更大的灾难性火灾。这解释了为什么"零火灾"方法在长期可能适得其反。
4.7 实用技巧速查
4.8 本节小结
森林火灾模型 = 3 个状态(空地/树木/燃烧)+ 4 条规则
关键参数:生长概率 p 和闪电概率 f
当 f→0 时系统趋近于自组织临界状态
火灾规模服从幂律分布——SOC 的标志性特征
"零火灾"政策可能适得其反(SOC 悖论)
功率谱 可用于检测 SOC 行为
第5章 传染病传播模型
5.1 SIR 格子元胞自动机
经典的 SIR 模型用常微分方程描述易感者(S)、感染者(I)、康复者(R)之间的转移,但假设人群是均匀混合的——每个人接触其他人的概率相同。这在现实中并不成立,尤其对于具有空间聚集特征的传染病。
格子 SIR 模型将人群放在二维网格上,感染仅通过邻居传播,能捕捉空间传播的关键特征。
状态定义:
演化规则(同步更新,Moore 邻居):
感染:易感元胞被每个感染邻居以概率 β 传染
康复:感染元胞以概率 γ 康复
import numpy as np
from matplotlib.colors import ListedColormap
cmap_sir = ListedColormap(['#5b9bd5', '#d4380d', '#70ad47']) # 易感/感染/康复
def sir_ca_step(grid, beta=0.3, gamma=0.1):
"""SIR格子元胞自动机一步演化"""
new_grid = grid.copy()
# 计算感染邻居数
infected = (grid == 1).astype(int)
inf_neighbors = np.zeros_like(grid, dtype=int)
for di in [-1, 0, 1]:
for dj in [-1, 0, 1]:
if di == 0 and dj == 0:
continue
inf_neighbors += np.roll(np.roll(infected, di, 0), dj, 1)
# 感染:易感者被感染邻居传染
susceptible = (grid == 0)
prob_infected = 1 - (1 - beta) ** inf_neighbors
rand = np.random.random(grid.shape)
new_grid[susceptible & (rand < prob_infected)] = 1
# 康复
currently_infected = (grid == 1)
rand2 = np.random.random(grid.shape)
new_grid[currently_infected & (rand2 < gamma)] = 2
return new_grid
感染概率 表示:每个感染邻居独立地以概率 β 传播,n 个感染邻居至少传播一次感染的概率。
5.2 疫情演化序列
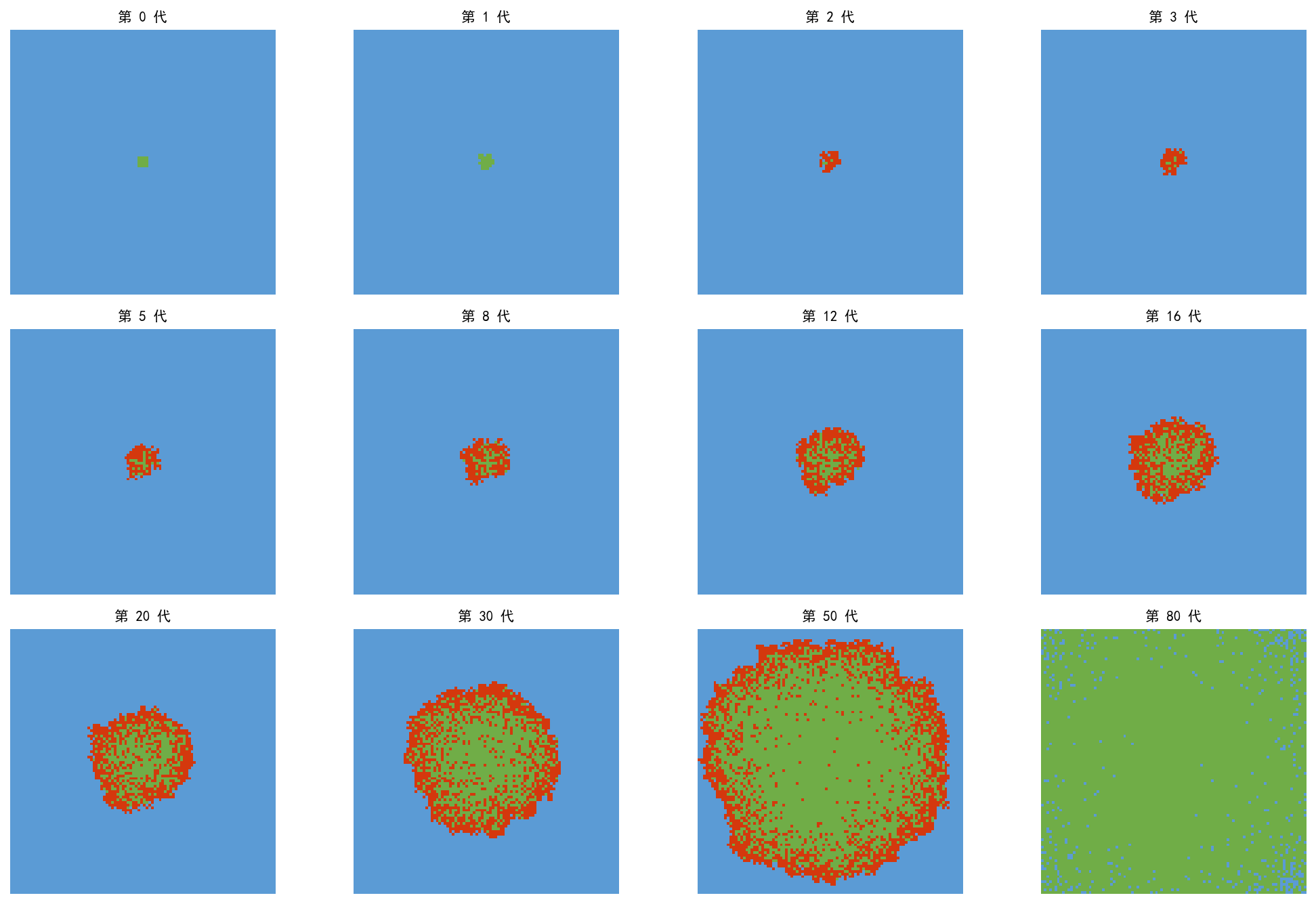
从 4×4 的初始感染区(红色)出发:
早期(1-3 代):感染向四周扩散,形成环形波前
中期(5-20 代):波前持续扩张,中心区域开始康复(绿色)
后期(30-80 代):疫情到达边界后衰减,大部分人群康复
感染前沿(红色环)的传播速度取决于 β 和 γ 的相对大小。
5.3 SIR 时间序列
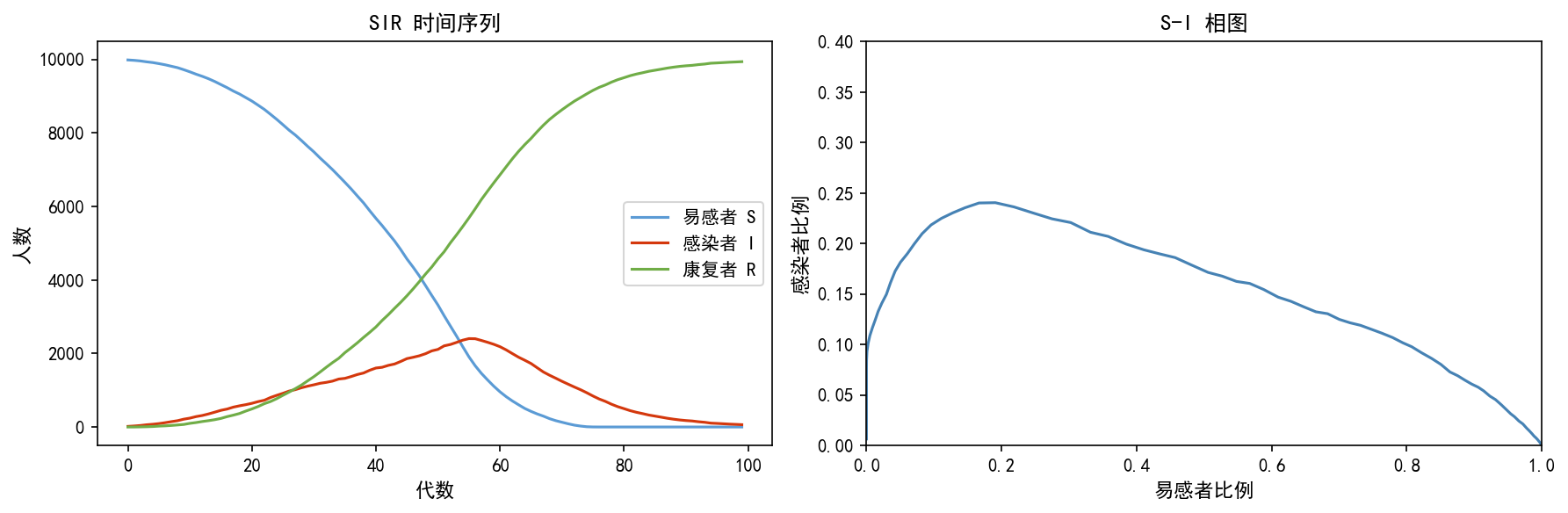
S_history, I_history, R_history = [], [], []
for _ in range(100):
S_history.append(np.sum(grid == 0))
I_history.append(np.sum(grid == 1))
R_history.append(np.sum(grid == 2))
grid = sir_ca_step(grid, beta=0.3, gamma=0.1)
左图的 SIR 曲线展示了经典的疫情模式:
S 曲线:持续下降,最终趋于稳定值(约 60% 被感染)
I 曲线:先上升后下降,峰值出现在约 15 代
R 曲线:单调递增,最终达到约 40%
右图的 S-I 相图展示了易感者与感染者的关系——这是流行病学中判断疫情是否达到拐点的关键工具。
5.4 R0 的影响
R0(基本传染数)是衡量疾病传播力的核心指标,在格子模型中可以近似为 (8 是 Moore 邻居数)。
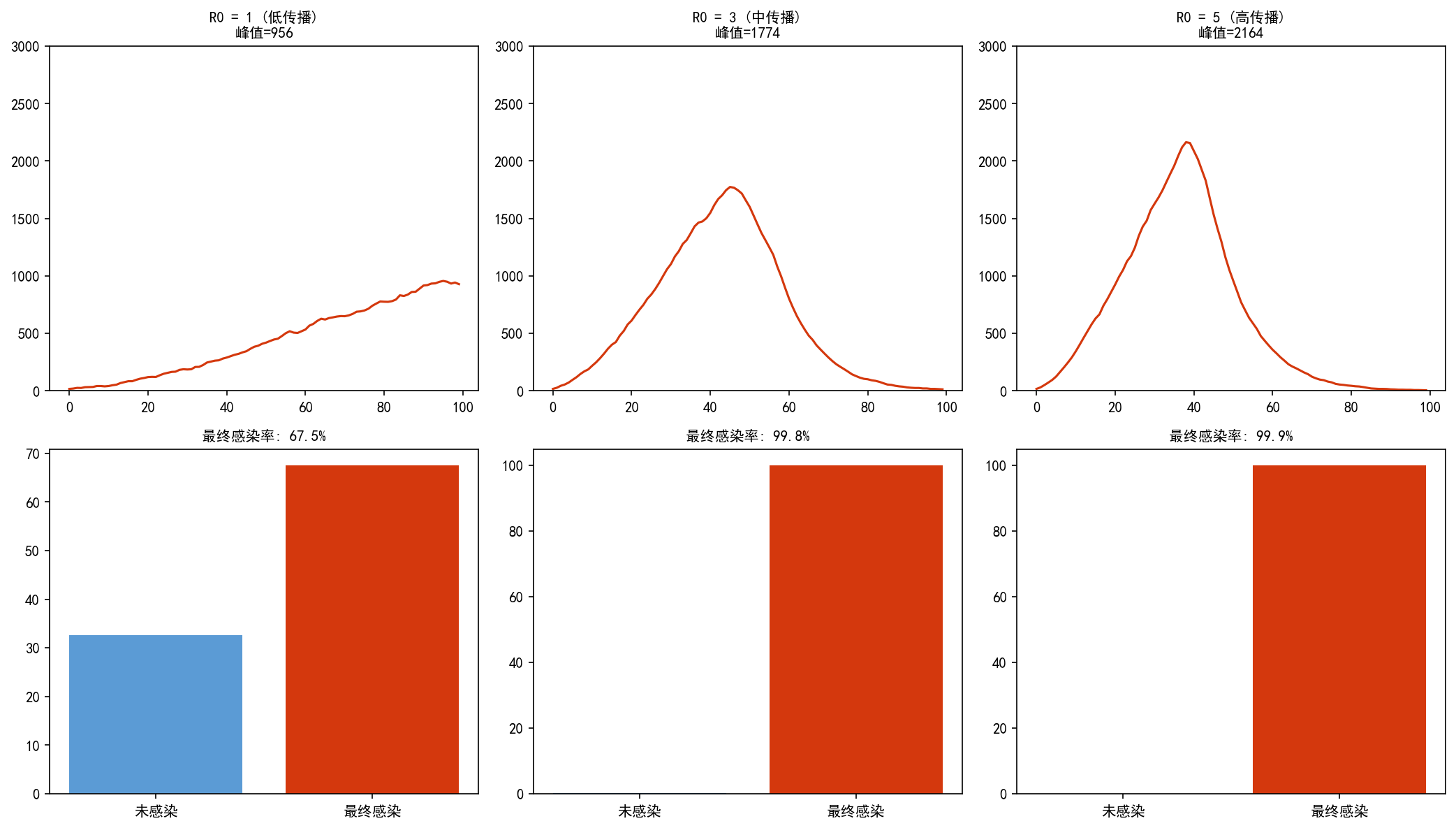
关键发现:即使 R0 很高,最终感染率也不会达到 100%——部分易感者因为被康复者隔离而幸免。这与均匀混合 ODE 模型的结果一致。
5.5 干预策略对比
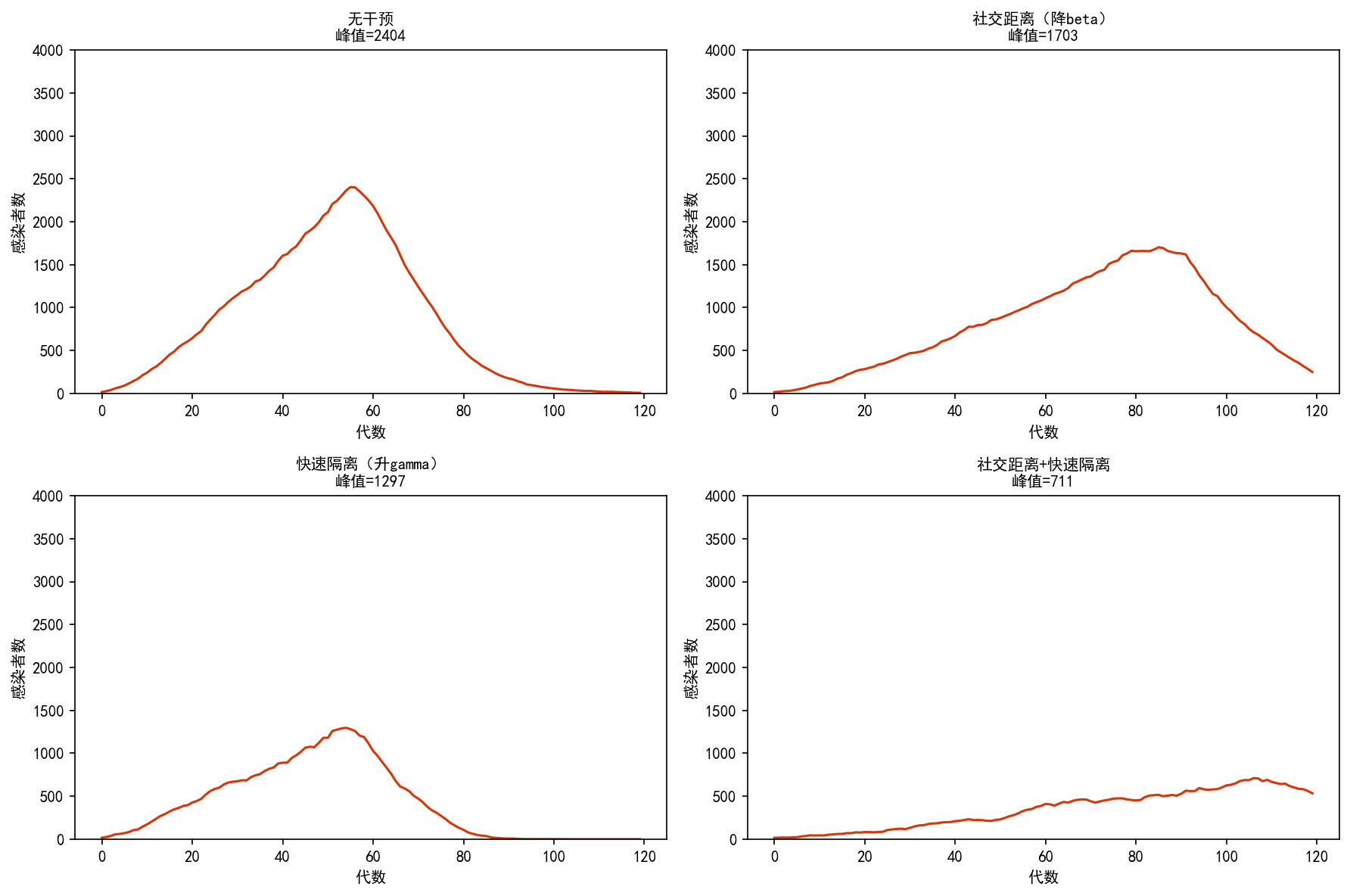
社交距离(降低 β)和快速隔离(提高 γ)的组合策略效果最优,这与实际疫情防控的经验一致。
5.6 空间传播模式

从 6×6 初始感染区出发,疫情呈现环形波前传播:
红色前沿:新感染的区域,传播速度最快
绿色中心:已康复区域,形成免疫"屏障"
感染人数先快速增长,后因易感者耗尽而放缓
这种空间模式是格子 CA 模型相对于 ODE 模型的核心优势——ODE 模型无法捕捉感染前沿的传播和空间异质性。
5.7 与 ODE SIR 模型的对比
格子 SIR 模型更接近实际——人的接触是局部的,疫情传播具有明显的空间聚集特征。
5.8 实用技巧速查
5.9 本节小结
格子 SIR 模型 = 3 个状态 + 2 条规则(感染 + 康复)
感染概率 考虑多个感染邻居的累积效应
R0 ≈ ,控制疫情的关键
空间传播呈现环形波前,ODE 模型无法捕捉此特征
社交距离 + 快速隔离的组合干预效果最优
向量化实现(
np.roll)保证高效模拟
第6章 人群疏散模拟
6.1 基本模型
人群疏散是元胞自动机在安全工程中的经典应用。模型将房间抽象为二维网格,每个人是一个元胞,以最短路径向出口移动。
状态定义:
核心思想:每个人根据到最近出口的最短距离(BFS 计算)选择移动方向,每一步向距离出口更近的空地移动一格。
from collections import deque
def compute_distance_map(rows, cols, exits, walls=None):
"""BFS计算到最近出口的距离图(跳过墙)"""
dist = np.full((rows, cols), -1, dtype=int)
queue = deque()
for er, ec in exits:
dist[er, ec] = 0
queue.append((er, ec))
wall_set = set(walls) if walls is not None else set()
while queue:
r, c = queue.popleft()
for dr in [-1, 0, 1]:
for dc in [-1, 0, 1]:
if abs(dr) + abs(dc) != 1:
continue
nr, nc = r + dr, c + dc
if 0 <= nr < rows and 0 <= nc < cols and dist[nr, nc] == -1:
if (nr, nc) not in wall_set:
dist[nr, nc] = dist[r, c] + 1
queue.append((nr, nc))
return dist
6.2 疏散演化过程
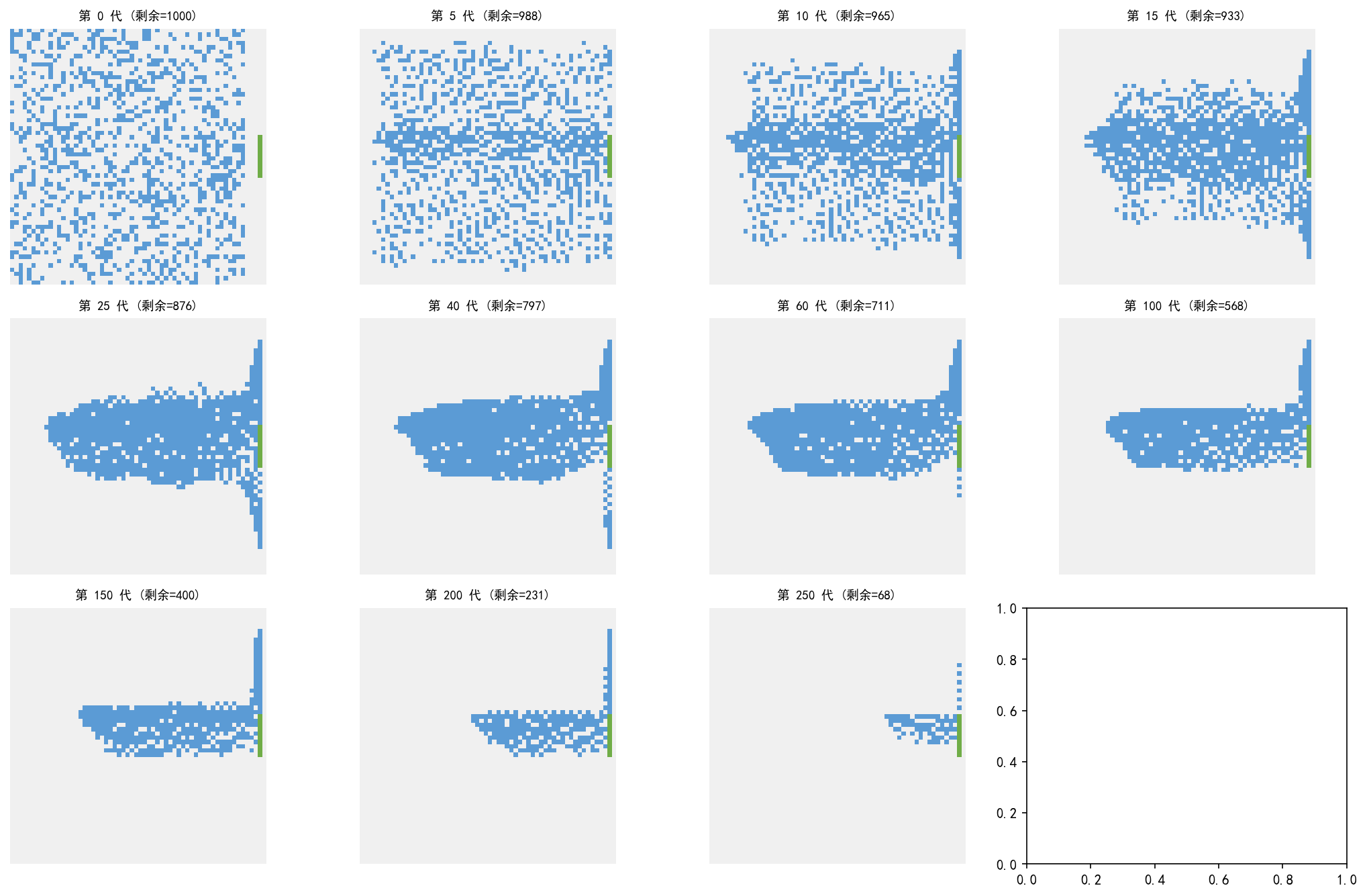
从 60×60 的开放房间(右侧单出口)出发,1010 人随机分布:
早期(5-15 代):人群开始向出口汇聚,形成扇形流动
中期(25-60 代):流线稳定,出口附近出现排队
后期(100-290 代):人数持续减少,最后几人缓慢撤离
疏散过程呈现出典型的扇形流线——远离出口的人沿最短路径汇向出口。
6.3 多出口对比
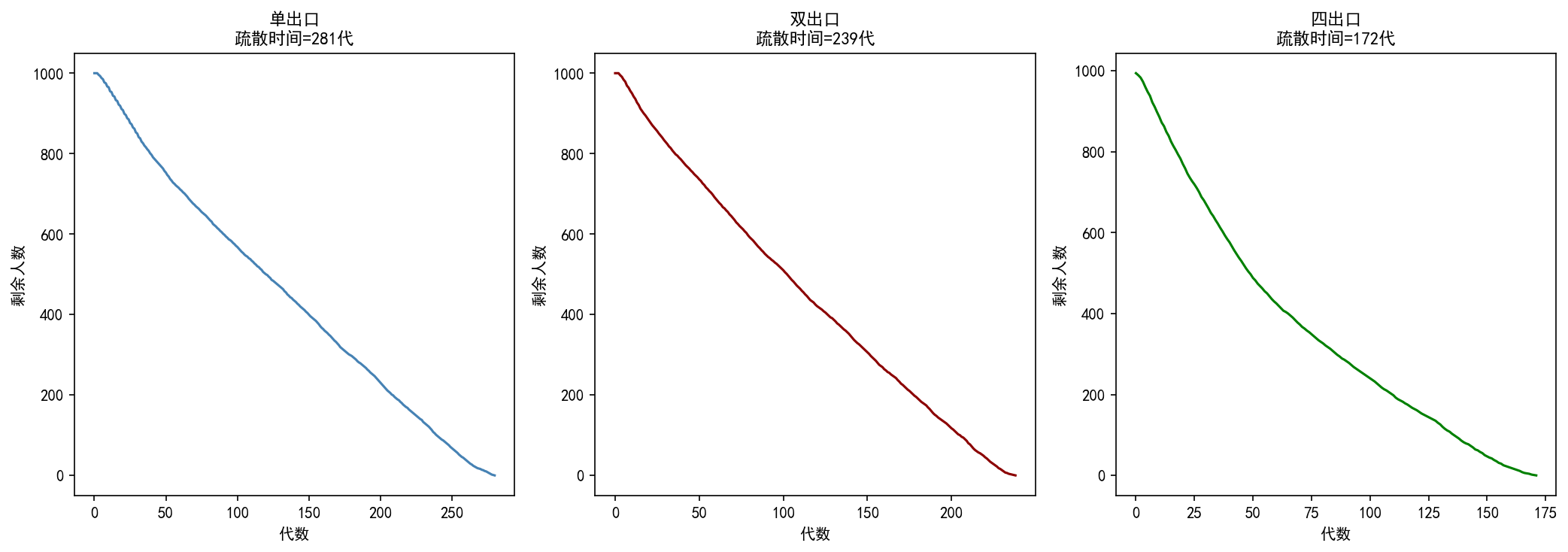
# 四出口场景
exits = ([(r, cols-2) for r in range(12, 18)] + # 右上
[(r, cols-2) for r in range(42, 48)] + # 右下
[(rows-2, c) for c in range(12, 18)] + # 左下
[(rows-2, c) for c in range(42, 48)]) # 右下
关键发现:
增加出口数量可以显著缩短疏散时间,但改善幅度递减
双出口比单出口节省 15%,但四出口比双出口额外节省 28%
出口分布的均匀性很重要——四出口分布在对角位置,每个人都能找到较近的出口
6.4 瓶颈效应

在房间中间设置一道墙,仅留一个 5 格宽的开口作为走廊:
# 中间走廊墙(留5格开口)
grid[20:40, 40] = 2 # 墙
grid[25:30, 40] = 0 # 开口
疏散过程呈现明显的两阶段特征:
阶段一(0-60 代):人群从房间左侧涌向走廊开口,在开口处形成拥堵
阶段二(100-400 代):通过走廊后,人群向出口移动,最后阶段的疏散显著放缓
瓶颈处的拥堵是疏散时间的决定性因素。实际建筑中,走廊宽度、门宽等瓶颈设计直接影响安全性能。
6.5 密度-时间关系
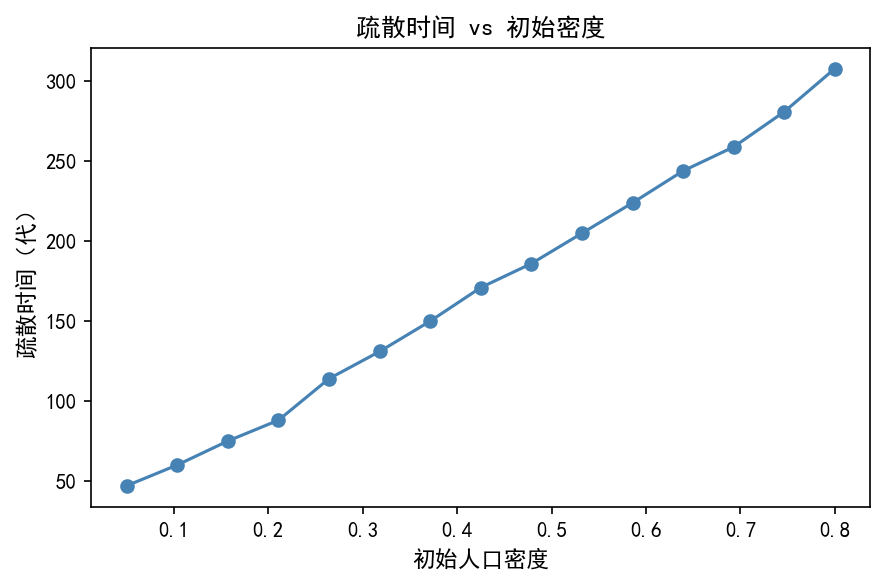
def evac_time(density, seed=42):
"""测量不同初始密度下的疏散时间"""
np.random.seed(seed)
g = np.zeros((40, 40), dtype=int)
g[15:25, 38] = 3 # 出口
people_count = int(density * 40 * 35)
# ... 随机放置人员
_, pops = run_evacuation(g.copy(), exits, 500)
return len(pops)
疏散时间随初始人口密度呈加速增长趋势:
低密度(< 0.2):近似线性增长,人员间几乎不互相阻碍
中密度(0.2-0.5):增长加速,开始出现排队效应
高密度(> 0.5):急剧增长,拥堵成为主导因素
这反映了人群疏散中的非线性拥堵效应——当密度超过某个阈值后,疏散时间急剧增加。
6.6 建模要点
6.7 实用技巧速查
6.8 本节小结
人群疏散模型 = 4 个状态(空地/人/墙/出口)+ BFS 路径规划
BFS 距离图是核心——为每个人计算到最近出口的最短路径
增加出口数量可以缩短疏散时间,但改善幅度递减
瓶颈(走廊、门)是疏散时间的决定性因素
疏散时间随人口密度呈非线性增长
随机顺序更新避免并行移动冲突
第7章 城市扩张与土地利用
7.1 城市增长元胞自动机
城市增长模型(Urban Growth CA)是地理信息科学和城市规划中的核心工具。最著名的是 SLEUTH 模型(Slopes, Land use, Exclusions, Urbanization, Transportation, Hillshade),它用元胞自动机模拟城市边界的时空演化。
本教程介绍一个简化版本,包含以下要素:
状态定义:
三种增长机制:
路边增长:沿道路网络的扩展(受
p_urban控制)自发生长:随机出现新城市中心(受
p_spont控制)扩散增长:从现有城市边界向外扩散(需要 ≥2 个城市邻居)
def urban_growth_step(grid, roads, p_urban=0.01, p_spont=0.001):
"""城市增长一步演化"""
new_grid = grid.copy()
# 计算城市邻居数
urban = (grid == 1).astype(int)
urban_neighbors = sum(np.roll(np.roll(urban, di, 0), dj, 1)
for di in [-1,0,1] for dj in [-1,0,1] if di or dj)
# 道路邻居
road = (grid == 3).astype(int)
road_neighbors = sum(np.roll(np.roll(road, di, 0), dj, 1)
for di in [-1,0,1] for dj in [-1,0,1] if di or dj)
# 可开发区域
developable = (grid == 0)
# 三种增长机制
road_grow = developable & (road_neighbors > 0) & (rand < p_urban)
spontaneous = developable & (rand < p_spont)
diffusion = developable & (urban_neighbors >= 2) & (rand < p_urban * 2)
new_grid[road_grow | spontaneous | diffusion] = 1
return new_grid
7.2 城市扩张演化
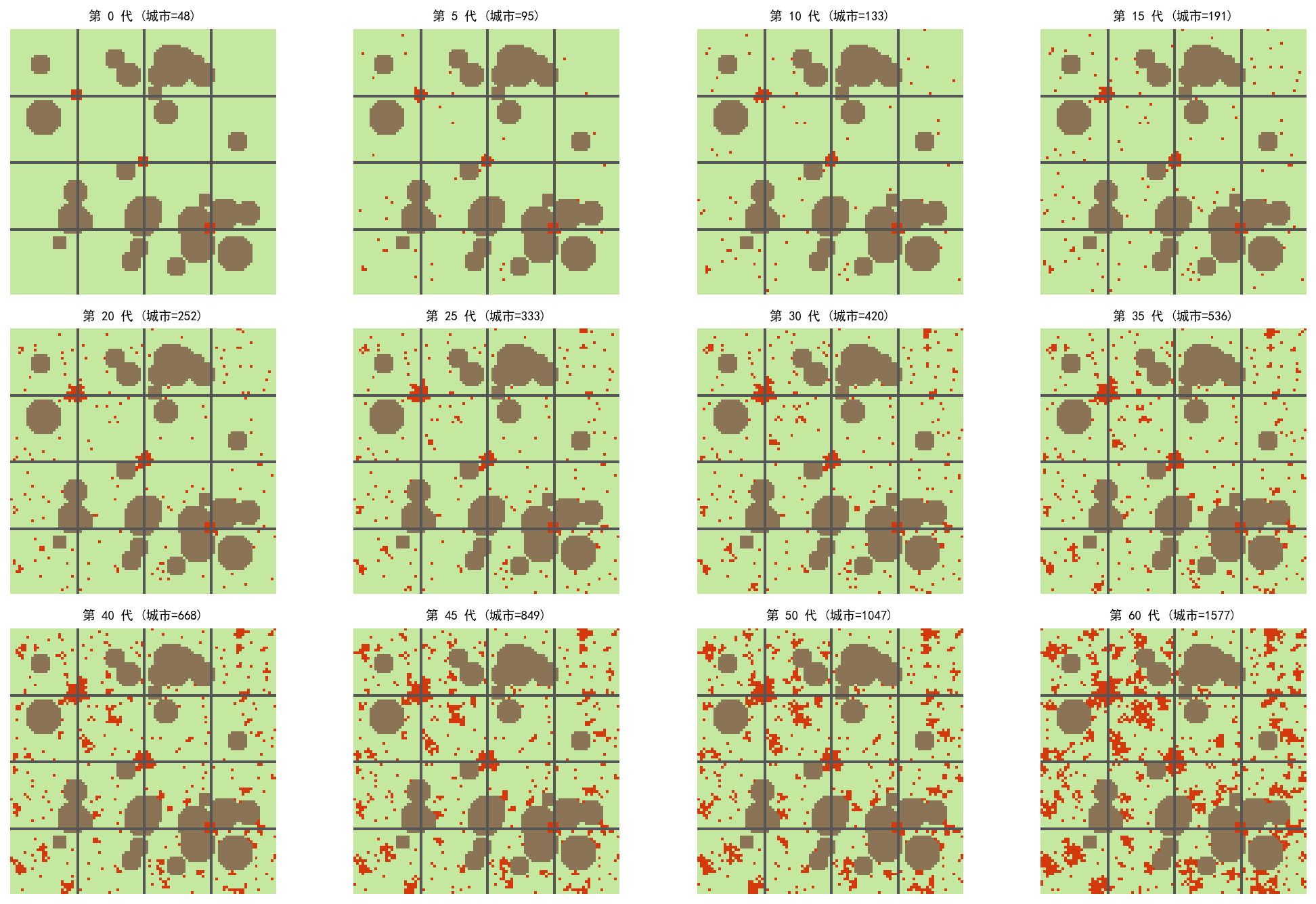
从 3 个城市中心和道路网络出发:
早期(5-15 代):城市沿道路扩展,出现零星的新开发点
中期(20-35 代):城市区域逐渐合并,道路沿线形成连续开发带
后期(40-60 代):城市快速扩张,自发生长产生大量分散开发
山地(棕色圆形区域)有效阻止了城市扩张,体现了地形约束的作用。
7.3 土地利用变化
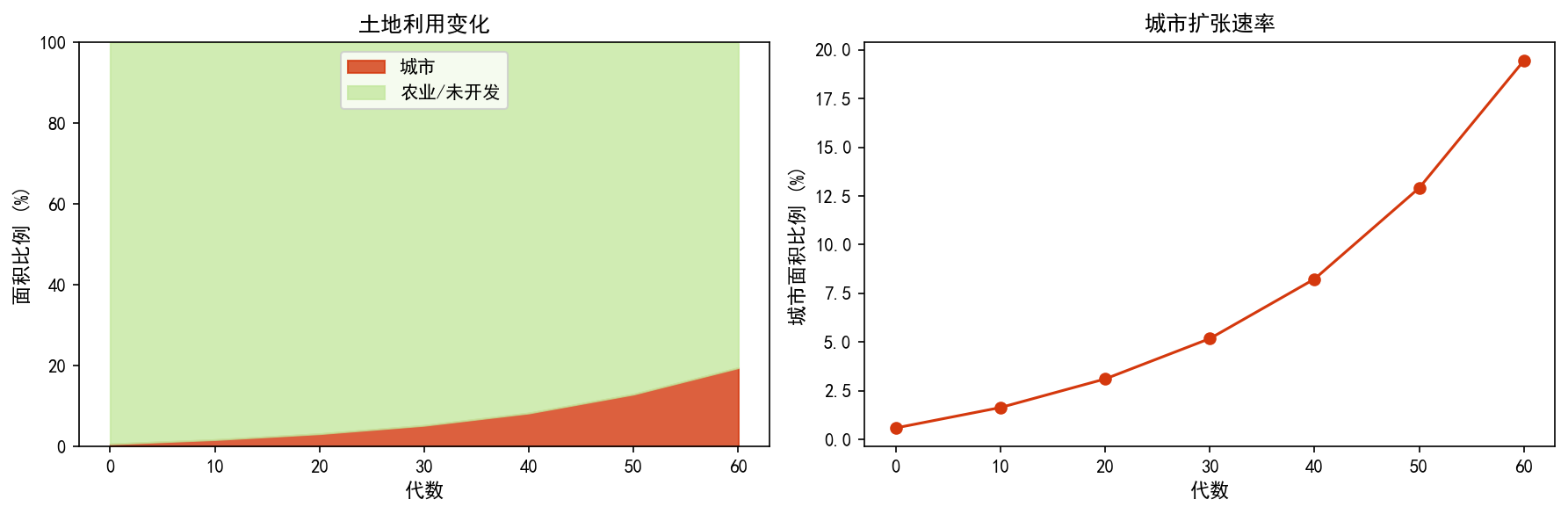
# 计算各时期土地利用比例
for t in time_points:
g = history[t]
total = rows * cols - np.sum(g == 2) # 排除山地
urban_pct.append(np.sum(g == 1) / total * 100)
左图的堆叠面积图展示了农业用地向城市用地的转换过程:
城市面积从约 0.5% 增长到 20%
农业用地相应减少
右图的城市扩张速率曲线呈现加速增长特征——这与实际城市发展的 S 形曲线(logistic growth)的早期阶段一致。
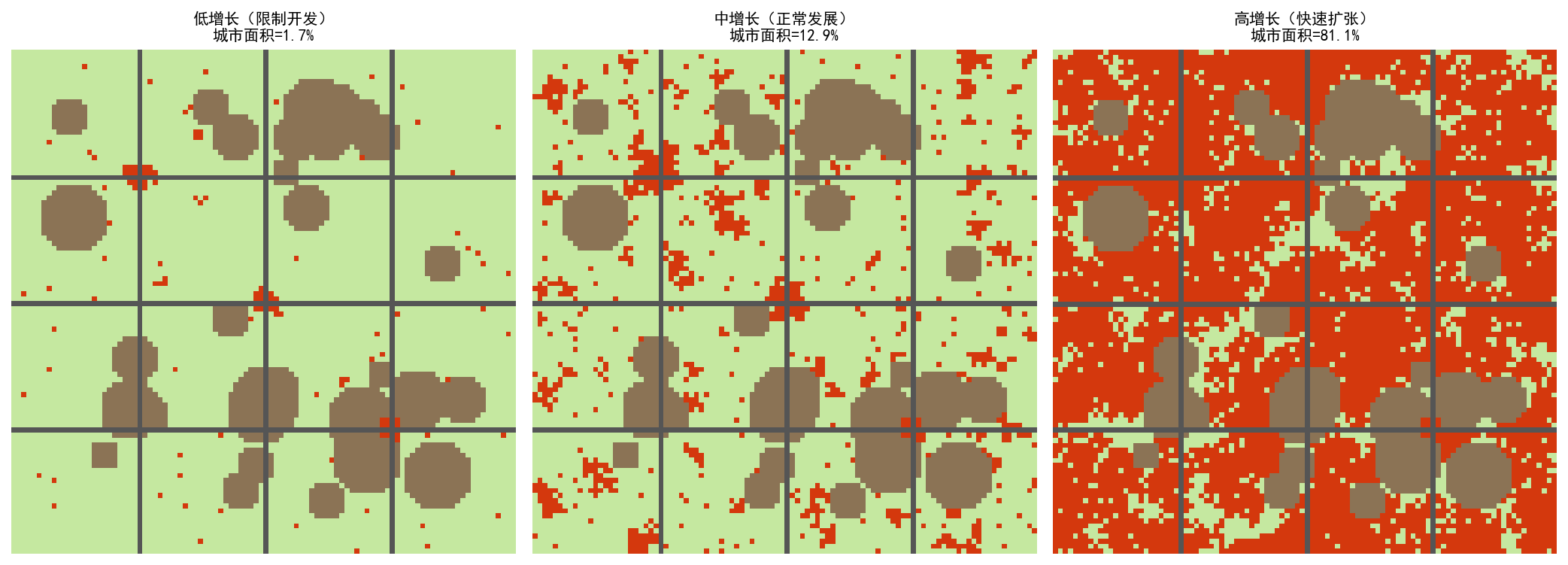
7.4 不同增长情景对比
关键发现:
低增长情景下,城市主要沿道路发展,形态紧凑
中增长情景下,自发生长开始显现,出现"跳跃式"开发
高增长情景下,城市几乎覆盖全部可开发区域
7.5 城市蔓延指数
城市蔓延(Urban Sprawl)指低密度、分散的城市发展模式。蔓延指数(边界/面积比)是量化蔓延程度的常用指标:
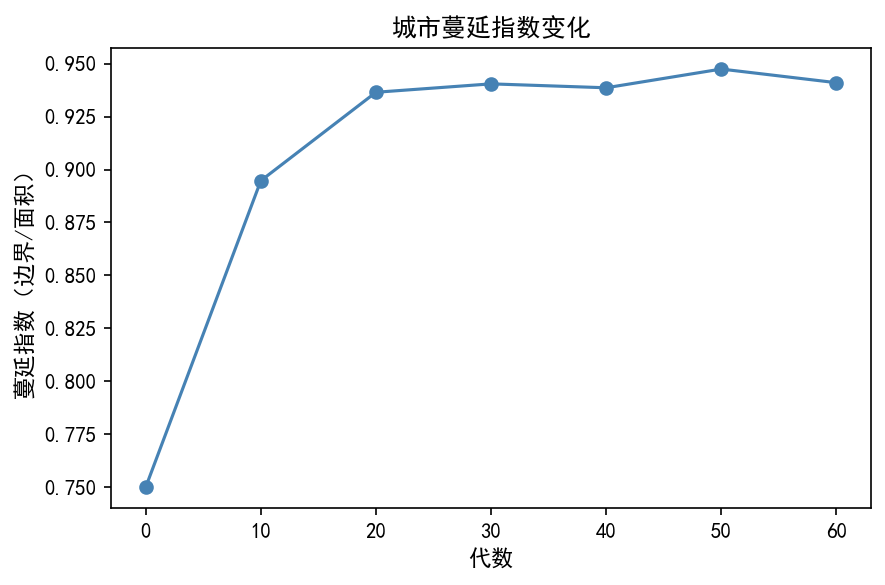
def compute_sprawl_index(grid):
"""计算蔓延指数"""
urban = (grid == 1).astype(int)
# 计算城市边界元胞(至少有一个非城市邻居)
edge = np.zeros_like(urban)
for di in [-1, 0, 1]:
for dj in [-1, 0, 1]:
if di == 0 and dj == 0:
continue
edge |= (urban == 1) & (np.roll(np.roll(urban, di, 0), dj, 1) == 0)
return np.sum(edge) / max(np.sum(urban), 1)
蔓延指数的变化趋势:
初期快速上升:分散开发导致边界/面积比急剧增加
后期趋于稳定:城市区域合并,边界增长放缓
指数越高,说明城市形态越分散、越低效
7.6 建模要点
7.7 实用技巧速查
7.8 本节小结
城市增长 CA 包含三种机制:路边增长、自发生长、扩散增长
关键参数
p_urban(路边增长率)和p_spont(自发生长率)控制城市形态地形约束(山地、水域)通过设置不可开发区实现
蔓延指数 = 边界/面积比,量化城市紧凑度
低增长→紧凑发展,高增长→大范围蔓延
模型可用于城市规划情景分析和政策评估
第8章 高级技巧与实战总结
8.1 性能优化
元胞自动机模拟的性能是实际应用中的关键问题。以下是从慢到快的几种实现方式:
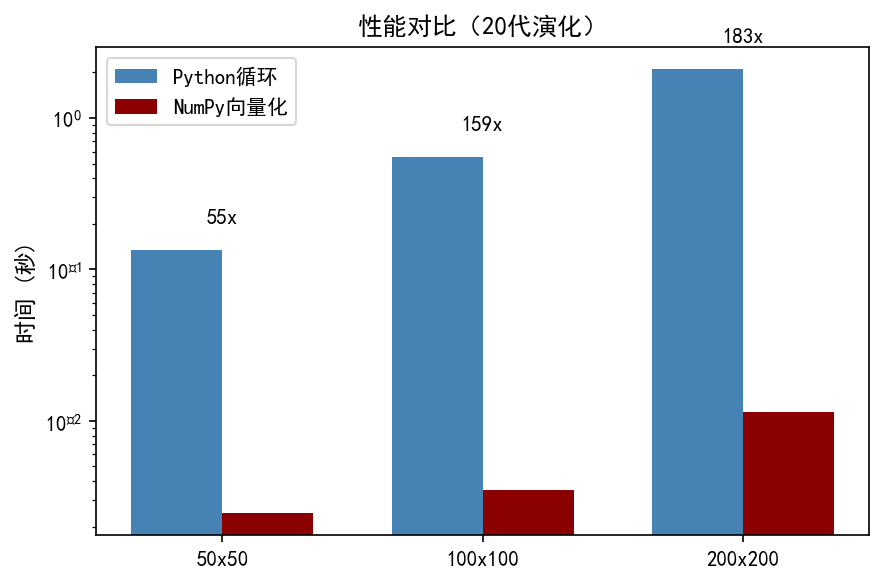
NumPy 向量化加速 55–183 倍,核心技巧:
用
np.roll()代替 for 循环计算邻居用布尔索引代替条件判断
用查找表代替 if-elif 链
# 向量化核心:8次roll叠加计算邻居
neighbors = sum(np.roll(np.roll(grid, di, 0), dj, 1)
for di in [-1, 0, 1] for dj in [-1, 0, 1] if di or dj)
# 布尔索引更新状态
new_grid = ((grid == 1) & ((neighbors == 2) | (neighbors == 3))) | \
((grid == 0) & (neighbors == 3)).astype(int)
进一步优化的方向:
Numba JIT:对无法向量化的逻辑(如 BFS)用
@njit装饰器,可再提速 10-50 倍GPU 加速:用 CuPy 替代 NumPy,适合超大网格(>1000×1000)
稀疏表示:对稀疏状态用
scipy.sparse,节省内存
8.2 边界条件

选择建议:
模拟全局/无限系统 → 周期性边界
模拟有限区域(如房间、城市) → 固定边界
需要避免边界效应影响中心区域 → 用更大的网格 + 周期性边界
8.3 邻居定义的选择
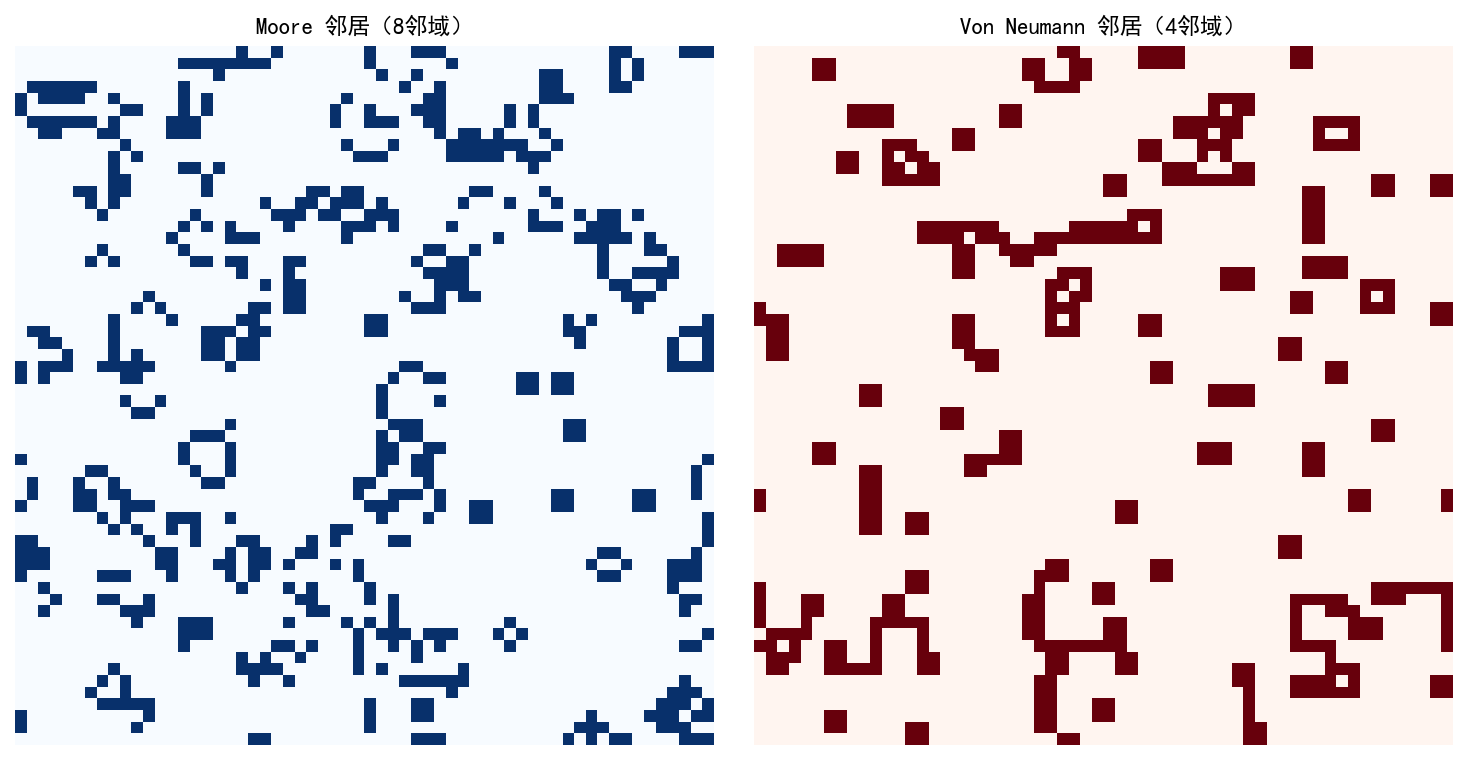
关键差异:
Moore 邻居允许对角传播,波前呈圆形
Von Neumann 邻居仅正交传播,波前呈菱形
相同初始条件下,Moore 的传播速度更快
8.4 多模型对比

用相同的 4×4 初始激活区域运行 40 代后,三种模型展现出截然不同的行为:
建模要点:
生命游戏:关注图案的稳定性和复杂性
森林火灾:关注自组织临界性和幂律分布
SIR 模型:关注传播速度和最终感染率
8.5 完整代码模板
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
class CellularAutomaton:
def __init__(self, shape, states=2):
self.shape = shape
self.states = states
self.grid = np.zeros(shape, dtype=int)
def initialize(self, method='random', **kwargs):
if method == 'random':
p = kwargs.get('p', 0.5)
self.grid = np.random.choice(self.states, self.shape,
p=[1-p, p] if self.states == 2 else None)
elif method == 'single':
cx, cy = kwargs.get('center', (self.shape[0]//2, self.shape[1]//2))
self.grid[cx, cy] = 1
def step(self):
raise NotImplementedError
def run(self, steps, snapshot=False):
history = []
for _ in range(steps):
self.step()
if snapshot:
history.append(self.grid.copy())
return history
8.6 实战速查表
通用技巧
模型选择指南
调试建议
8.7 本节小结
NumPy 向量化是性能优化的第一选择,比 Python 循环快 55–183 倍
边界条件影响模拟结果——周期性适用于无限空间,固定边界适用于有限区域
邻居定义决定传播特性——Moore 各向同性,Von Neumann 各向异性
不同 CA 模型适用于不同场景——选择取决于状态数和核心机制
使用面向对象模板可以提高代码复用性
实战中注意:向量化邻居计算、布尔索引更新、自定义色带可视化
教程到此结束。元胞自动机是一种"简单规则产生复杂行为"的建模范式,在数学建模竞赛中特别适合处理具有空间显式特征的动态系统问题。希望本教程能帮助你快速上手!
附录:完整代码获取
本教程所有代码均可通过以下链接下载: