
基础篇:Statsmodels库求解回归模型方法
前言
关于本教程
本教程是一篇面向有一定统计学基础和 Python 编程能力的读者的 statsmodels 回归分析教程。共九章,从最基础的 OLS 线性回归出发,逐步深入到广义线性模型(GLM)、稳健回归(RLM)、分位数回归(QuantReg)、混合效应模型(MixedLM),最后系统讲解模型诊断与检验方法,并以真实数据集完整演示从探索性分析到最终模型的全流程。
与 scikit-learn 专注于预测精度不同,statsmodels 的核心优势在于统计推断——它提供完整的系数估计、标准误、p 值、置信区间和模型诊断工具,帮助研究者回答"X 对 Y 是否有显著影响"这类问题。
目标读者
有一定统计学基础的数据分析师、研究人员、学生
了解 Python 基本语法(变量、函数、列表、字典)
熟悉 numpy、pandas 的基本操作
希望从 sklearn 等预测导向的库转向统计推断导向的工具
前置知识
阅读本教程前,建议具备以下基础:
统计学:了解均值、方差、正态分布、假设检验、p 值等基本概念
线性代数:了解矩阵、向量点积(不需要深入,statsmodels 会处理大部分运算)
Python:能读写 CSV 文件、使用 pandas DataFrame、调用函数
如果你完全不了解回归分析的基本概念(如"斜率"、"截距"、"R²"),建议先阅读一本入门级的统计学教材。
环境要求
本教程所有代码基于以下环境编写和验证:
安装命令:
pip install statsmodels numpy pandas matplotlib scipy
验证安装:
import statsmodels.api as sm
print(sm.__version__) # 应输出 0.14.x
本教程结构
本文共九章,逐步深入 statsmodels 的回归分析功能:
建议按顺序阅读。第1-2章是基础,后续章节相对独立,可以根据需要跳读。第8章的诊断方法在第2-7章的模型中均适用,第9章综合运用了前面所有章节的技巧。
代码约定
本教程所有代码使用
import statsmodels.formula.api as smf(公式风格)和import statsmodels.api as sm(数组风格)两种导入方式代码块中的
>>>前缀表示交互式输入,无>>>的表示连续代码代码中
df通常指 pandas DataFrame模型拟合后的结果对象通常命名为
model或mdf(model fit results)所有图表均使用中文标签,使用
plt.rcParams['font.sans-serif'] = ['SimHei']设置
公式约定
β 表示回归系数
ϵ 表示误差项
σ2 表示误差方差
τ 表示分位数水平
数据来源
本教程使用的所有数据集均为 statsmodels 内置数据集,无需额外下载:
longley:美国宏观经济指标(第2章)engel:比利时家庭食品支出与收入(第3、6章)fair:婚外情调查数据(第4章)stackloss:化工厂运行数据(第5章)grunfeld:企业投资面板数据(第7章)statecrime:美国各州犯罪率(第9章)
这些数据集的详细信息可通过 sm.datasets.<name>.DESCR 查看。
如何学习
建议的学习方式:
先读章节的文字部分,理解概念和方法
运行对应的
_gen.py代码,观察生成的图表修改代码中的参数(如更换数据集、改变模型设定),观察结果变化
尝试用自己的数据,套用本章的模板
statsmodels 的学习曲线比 scikit-learn 略陡,因为它的输出更丰富、选项更多。但一旦掌握了核心框架(fit() → summary() → get_prediction()),后续各章的模式是高度一致的。
反馈与勘误
如果你在阅读过程中发现代码运行错误、统计结论有误、或有任何建议,欢迎反馈。
第1章 简介
1.1 statsmodels 是什么
statsmodels 是 Python 生态中最完整的统计建模库之一,专注于统计推断而非预测精度。它提供了丰富的回归模型、假设检验、统计诊断和可视化支持,是经济学、社会科学、生物统计等领域的首选工具。
与 scikit-learn 的对比:
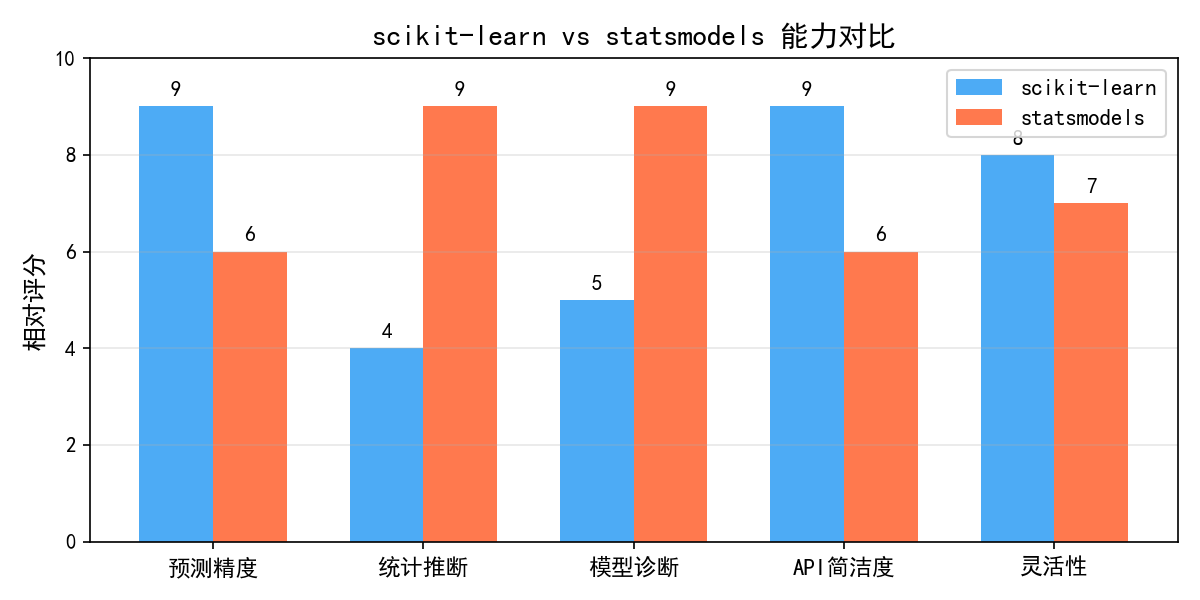
简而言之:如果你关心"X 对 Y 有没有显著影响",选 statsmodels;如果你只关心"模型能预测多准",选 scikit-learn。
1.2 安装与环境配置
pip install statsmodels
statsmodels 依赖 numpy、scipy 和 pandas,pip 会自动安装。推荐搭配 matplotlib 用于可视化:
pip install statsmodels matplotlib seaborn
验证安装:
import statsmodels.api as sm
print(sm.__version__) # 本文基于 0.14.6
1.3 核心设计理念
statsmodels 的 API 分为两种风格:
1.3.1 数组风格(Array API)
通过 statsmodels.api 导入,直接使用 numpy 数组:
import statsmodels.api as sm
import numpy as np
np.random.seed(42)
X = np.random.randn(100, 2)
X = sm.add_constant(X) # 添加截距项
y = 2.5 + 1.8 * X[:, 1] - 0.9 * X[:, 2] + np.random.randn(100) * 0.5
model = sm.OLS(y, X).fit()
print(model.summary())
1.3.2 公式风格(Formula API)
通过 statsmodels.formula.api 导入,使用 R 风格的公式字符串:
import statsmodels.formula.api as smf
import pandas as pd
df = pd.DataFrame({'y': y, 'x1': X[:, 1], 'x2': X[:, 2]})
model = smf.ols('y ~ x1 + x2', data=df).fit()
print(model.summary())
公式风格的优势在于:自动处理截距项、支持分类变量(C(group))、支持交互项(x1:x2 或 x1*x2)、支持多项式(I(x1**2)),代码更简洁易读。
本文的示例优先使用公式风格,因为它的可读性更好,更贴近实际分析场景。
1.4 statsmodels 回归模块家族
statsmodels 提供了完整的回归模型体系,涵盖从基础到高级的各种场景:
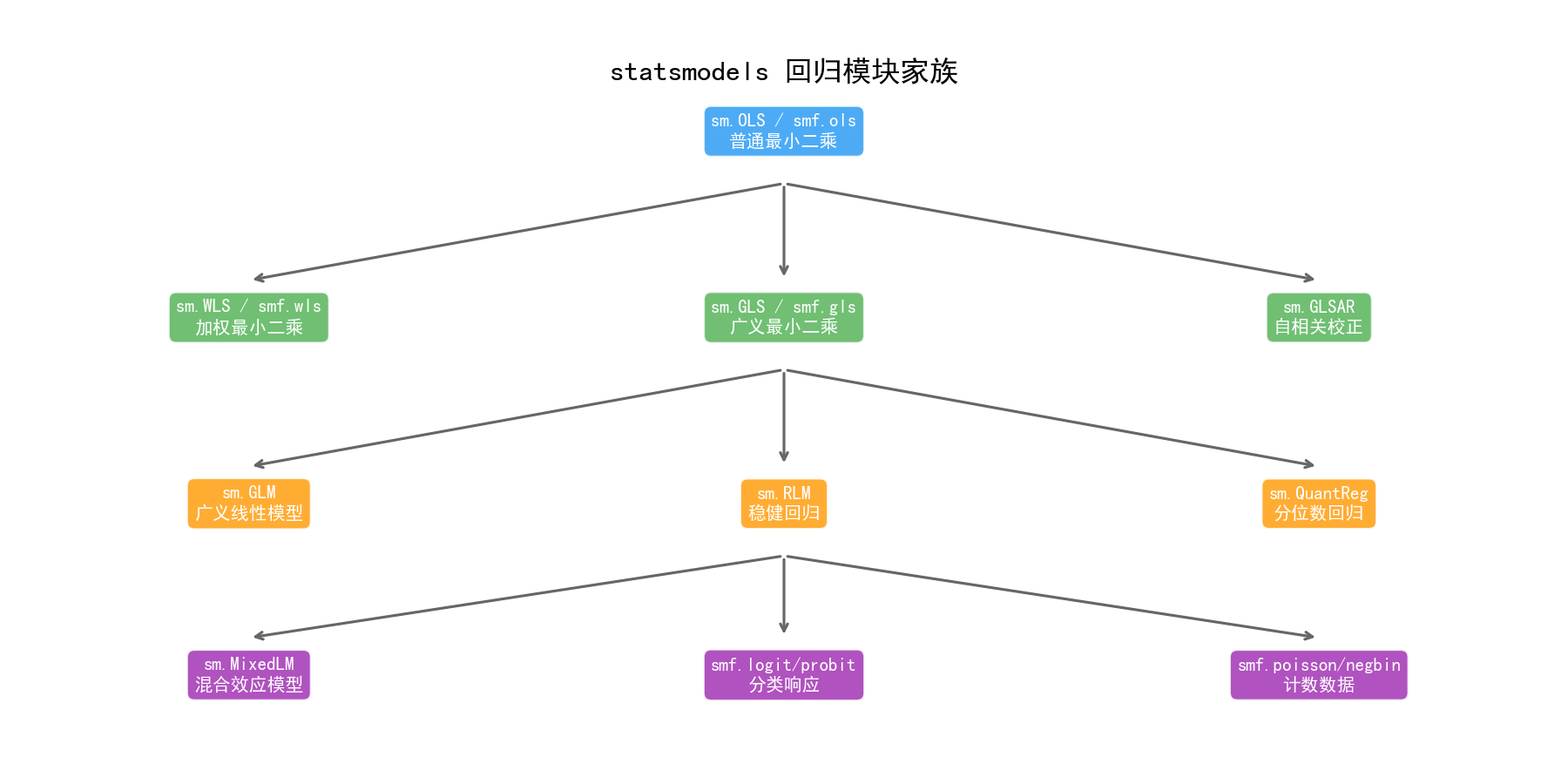
线性回归族:OLS(普通最小二乘)、WLS(加权最小二乘)、GLS(广义最小二乘)、GLSAR(自相关校正)
广义线性模型(GLM):支持 Gaussian、Binomial、Poisson、Gamma、NegativeBinomial 等分布族
稳健回归(RLM):对异常值不敏感,适合含噪声数据
分位数回归(QuantReg):不假设误差分布,关注条件分位数而非条件均值
混合效应模型(MixedLM):处理分组/层次数据中的随机效应
离散选择模型:Logit、Probit、多项 Logit 等,用于分类响应变量
计数模型:Poisson、负二项回归,用于非负整数响应变量
1.5 一个完整的 OLS 示例
让我们用一个最小但完整的例子感受 statsmodels 的工作流程:
import statsmodels.formula.api as smf
import pandas as pd
import numpy as np
np.random.seed(42)
df = pd.DataFrame({
'x1': np.random.randn(100),
'x2': np.random.randn(100),
'group': np.random.choice(['A', 'B', 'C'], 100)
})
# 生成响应变量:y = 3 + 2*x1 - 1.5*x2 + 组别效应 + 噪声
df['y'] = 3 + 2*df['x1'] - 1.5*df['x2'] \
+ df['group'].map({'A': 0, 'B': 1.2, 'C': -0.8}) \
+ np.random.randn(100) * 0.8
# 拟合并输出结果
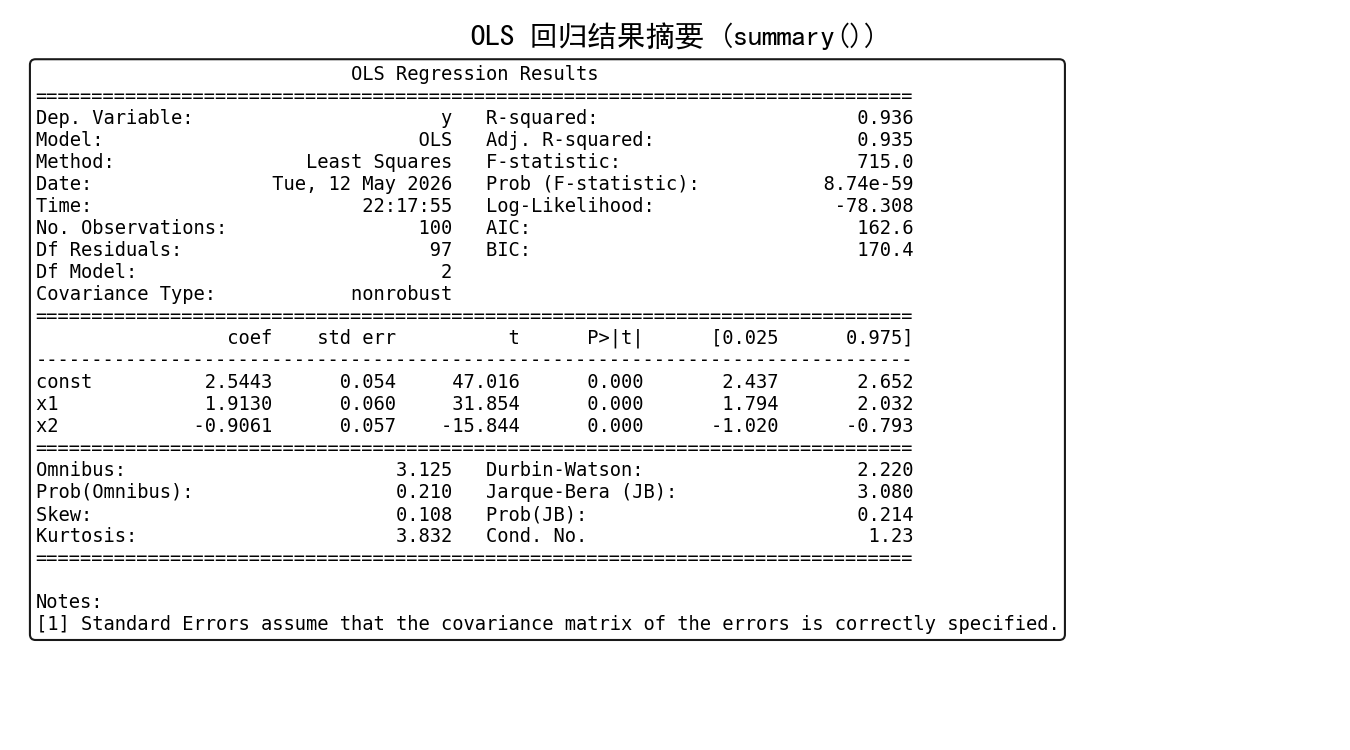
model = smf.ols('y ~ x1 + x2 + C(group)', data=df).fit()
print(model.summary())
输出结果如下:
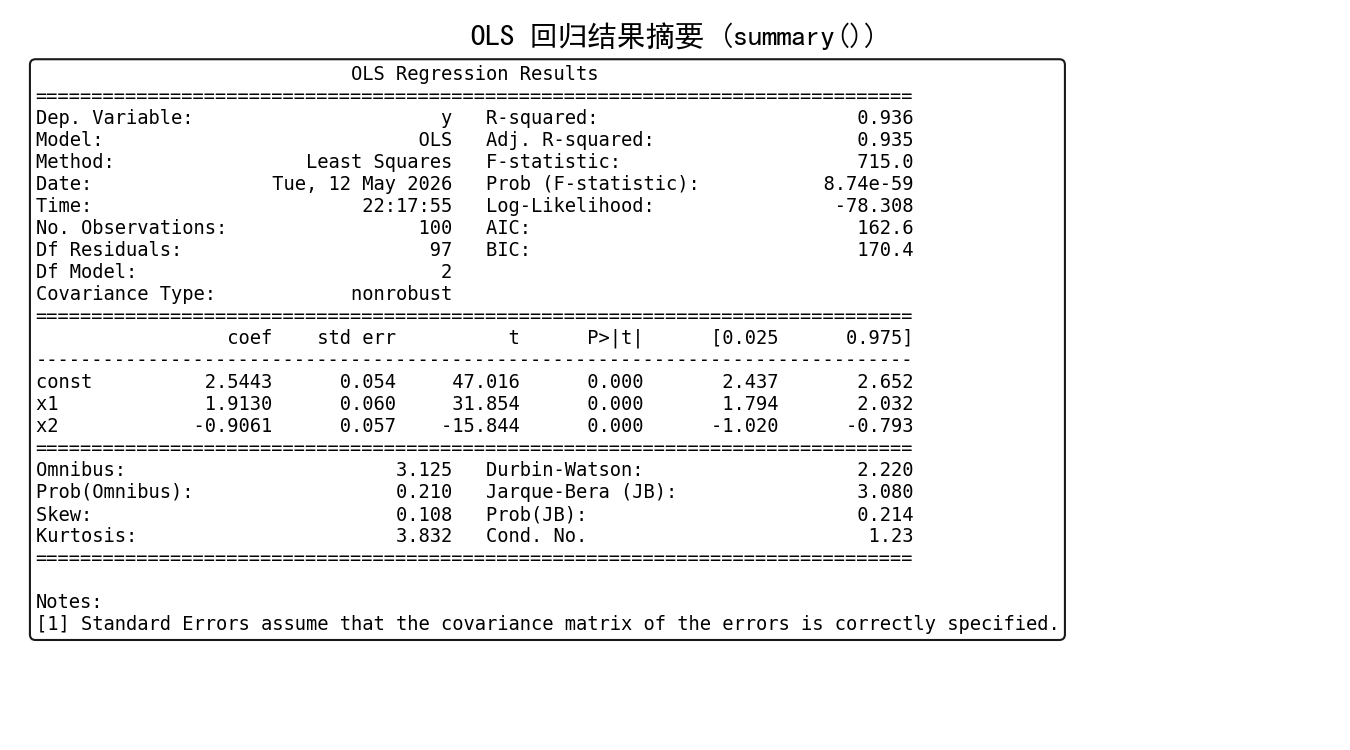
summary() 一张表包含了几乎所有关键统计信息:
coef:回归系数估计值
std err:标准误
t / P>|t|:t 统计量和 p 值,用于检验系数是否显著不为零
[0.025, 0.975]:95% 置信区间
R-squared / Adj. R-squared:模型拟合优度
F-statistic / Prob (F-statistic):整体显著性检验
AIC / BIC:信息准则,用于模型比较
Durbin-Watson:残差自相关检验
1.6 公式 API 的三种常见用法
公式 API 是 statsmodels 最有特色的功能之一,以下展示三种最常用的场景:
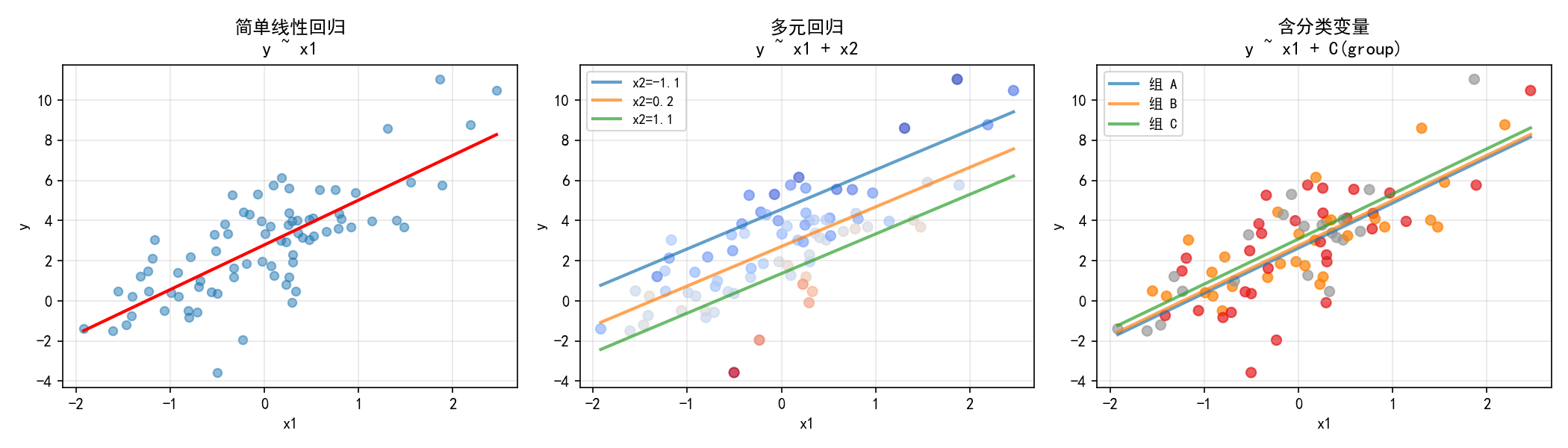
简单线性回归
model = smf.ols('y ~ x1', data=df).fit()
最基础的单变量回归,公式中 ~ 左边是因变量,右边是自变量。
多元回归
model = smf.ols('y ~ x1 + x2', data=df).fit()
多个自变量用 + 连接。图中不同颜色的回归线对应不同的 x2 取值。
含分类变量
model = smf.ols('y ~ x1 + C(group)', data=df).fit()
C(group) 告诉 statsmodels 将 group 视为分类变量,自动进行虚拟变量(dummy variable)编码。图中三条平行线代表不同组别的截距不同,但 x1 的斜率相同。
1.7 内置数据集
statsmodels 提供了丰富的内置数据集,方便学习和测试:
import statsmodels.api as sm
# 加载 Longley 数据集(宏观经济数据)
data = sm.datasets.longley.load_pandas()
print(data.data.head())
常用数据集包括:
在后续章节中,我们会使用这些内置数据集进行演示,确保所有代码都可以直接复现。
1.9 本节小结
statsmodels 专注统计推断,scikit-learn 专注预测精度,两者互补
statsmodels 提供两种 API 风格:数组风格(
sm.OLS)和公式风格(smf.ols)公式 API 支持 R 风格的模型公式,自动处理截距、分类变量、交互项
summary()是 statsmodels 的核心输出方法,一张表包含所有关键统计信息statsmodels 内置了丰富的数据集,后续章节将使用这些数据集进行演示
第2章 线性回归基础(OLS)
2.1 最简单的 OLS 回归
普通最小二乘法(Ordinary Least Squares, OLS)是回归分析的基础。它的目标是最小化残差平方和:
statsmodels 中最基本的调用方式:
import statsmodels.api as sm
import numpy as np
np.random.seed(42)
n = 50
x = np.linspace(0, 10, n)
y = 2 + 1.5 * x + np.random.randn(n) * 2
# 注意:必须手动添加常数项(截距)
X = sm.add_constant(x)
model = sm.OLS(y, X).fit()
print(model.summary())
关键注意:数组风格的 sm.OLS 不会自动添加截距项,必须调用 sm.add_constant()。如果忘记添加,模型将强制通过原点,导致系数估计有偏。
2.2 公式风格的 OLS
公式风格无需手动添加常数项,也更直观:
import statsmodels.formula.api as smf
import pandas as pd
df = pd.DataFrame({'x': x, 'y': y})
model = smf.ols('y ~ x', data=df).fit()
print(model.summary())
公式中的 ~ 左边是因变量,右边是自变量。截距项默认自动添加,如果需要强制通过原点,写作 y ~ 0 + x 或 y ~ x - 1。
2.3 summary() 详解
model.summary() 输出三张表格,包含回归分析的全部信息:
第一张表:系数估计
第二张表:模型整体拟合度
第三张表:诊断统计量
2.4 拟合值、预测与置信区间
OLS 拟合完成后,最常用的操作是预测。statsmodels 提供 get_prediction() 方法,同时返回预测值、置信区间和预测区间:
import statsmodels.api as sm
import numpy as np
np.random.seed(42)
x = np.linspace(0, 10, 50)
y = 2 + 1.5 * x + np.random.randn(50) * 2
X = sm.add_constant(x)
model = sm.OLS(y, X).fit()
# 预测
x_new = np.linspace(0, 10, 100)
X_new = sm.add_constant(x_new)
pred = model.get_prediction(X_new)
# 置信区间(对均值的不确定性)
ci = pred.conf_int(alpha=0.05)
# 预测区间(对单个新观测的不确定性)
pi = pred.conf_int(obs=True)
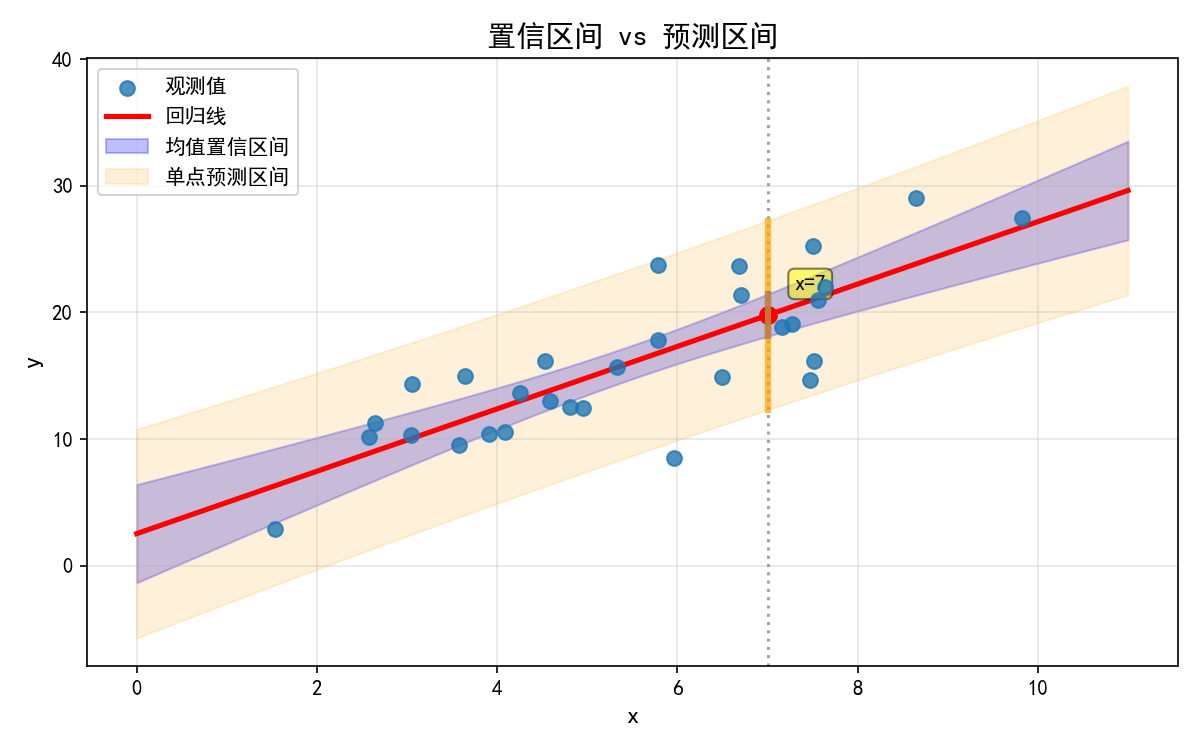
置信区间与预测区间的区别:
置信区间(蓝色区域):反映回归线本身的不确定性,即 E(Y|X) 的置信范围
预测区间(橙色区域):反映单个新观测值的不确定性,包含随机误差,因此更宽
2.5 公式 API 的语法
公式 API 支持丰富的语法,以下是常用操作符:
2.5.1 基础操作符
# 多元回归:用 + 连接自变量
smf.ols('y ~ x1 + x2 + x3', data=df)
# 交互项:x1:x2 仅交互项,x1*x2 包含主效应和交互项
smf.ols('y ~ x1 * x2', data=df) # 等价于 y ~ x1 + x2 + x1:x2
smf.ols('y ~ x1 + x2 + x1:x2', data=df) # 显式写法
# 多项式:用 I() 包裹算术运算
smf.ols('y ~ x + I(x**2) + I(x**3)', data=df)
2.5.2 分类变量
# C() 将数值变量视为分类变量
smf.ols('y ~ C(group)', data=df)
# 设置参照组(以 "对照组" 为基准)
smf.ols('y ~ C(group, Treatment("对照组"))', data=df)
# 混合连续变量和分类变量
smf.ols('y ~ x + C(group)', data=df)
2.5.3 公式语法对比
下面的例子展示三种模型设定方式的差异:
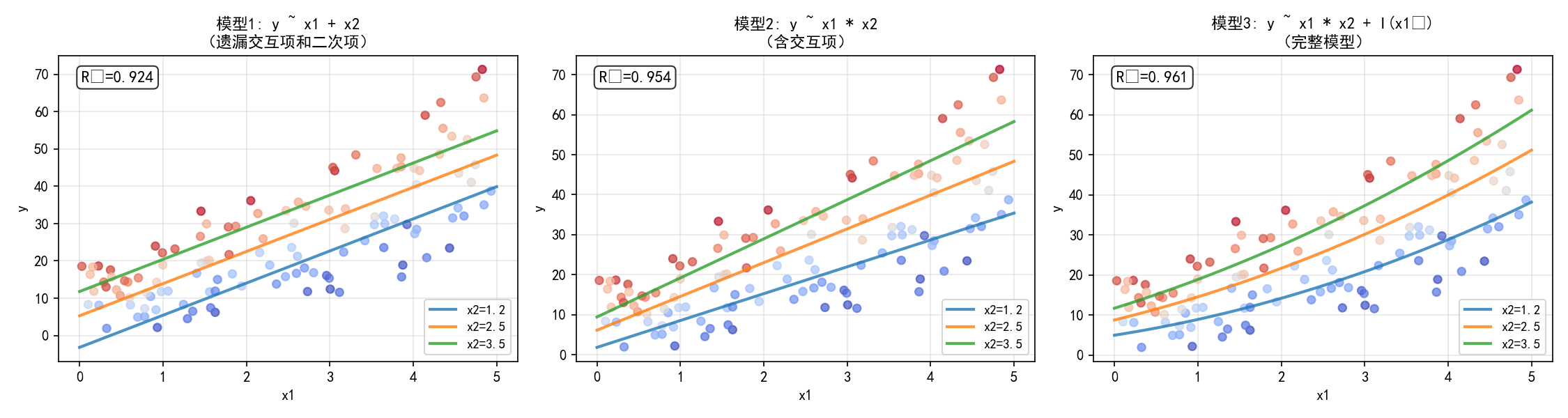
从左到右,模型逐步完善,R² 逐步提升:
模型1(R²=0.581):遗漏交互项和二次项,回归线平行,无法捕捉复杂关系
模型2(R²=0.852):加入交互项,不同 x2 水平的回归线斜率不同
模型3(R²=0.908):再加入二次项,回归线呈曲线,最接近真实关系
2.6 残差分析初探
残差是回归诊断的核心。model.resid 返回残差向量,model.fittedvalues 返回拟合值。
resid = model.resid # 残差
fitted = model.fittedvalues # 拟合值
# 常用残差图
fig, axes = plt.subplots(1, 3, figsize=(14, 4))
# 1. 残差 vs 拟合值 — 检查异方差和非线性
axes[0].scatter(fitted, resid, alpha=0.7)
axes[0].axhline(y=0, color='r', linestyle='--')
axes[0].set_title('残差 vs 拟合值')
# 2. 残差直方图 — 检查正态性
axes[1].hist(resid, bins=12, density=True, alpha=0.6)
axes[1].set_title('残差分布')
# 3. Q-Q 图 — 检查正态性
from scipy import stats
stats.probplot(resid, dist="norm", plot=axes[2])
axes[2].set_title('Q-Q 正态性检验')
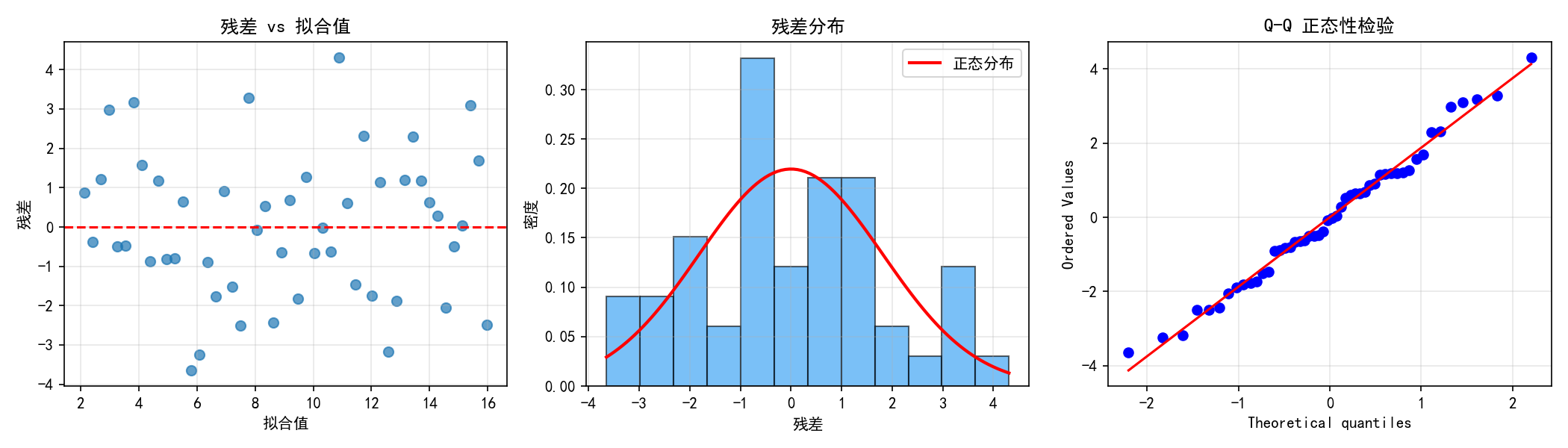
三个图的解读:
残差 vs 拟合值:理想情况下残差应随机散布在零线周围,无明显的趋势或扇形模式
残差直方图:应大致呈现钟形对称分布,与正态分布曲线吻合
Q-Q 图:如果残差服从正态分布,点应近似落在对角线上
第8章将深入讨论更多正式的统计检验方法。
2.7 实战:Longley 宏观数据回归
Longley 数据集是美国 1947-1962 年的宏观经济数据,常被用于展示多元回归和共线性问题。
import statsmodels.api as sm
import statsmodels.formula.api as smf
data = sm.datasets.longley.load_pandas()
df = data.data
# 用所有变量预测总就业人数
model = smf.ols('TOTEMP ~ GNPDEFL + GNP + UNEMP + ARMED + POP + YEAR', data=df).fit()
print(model.summary())
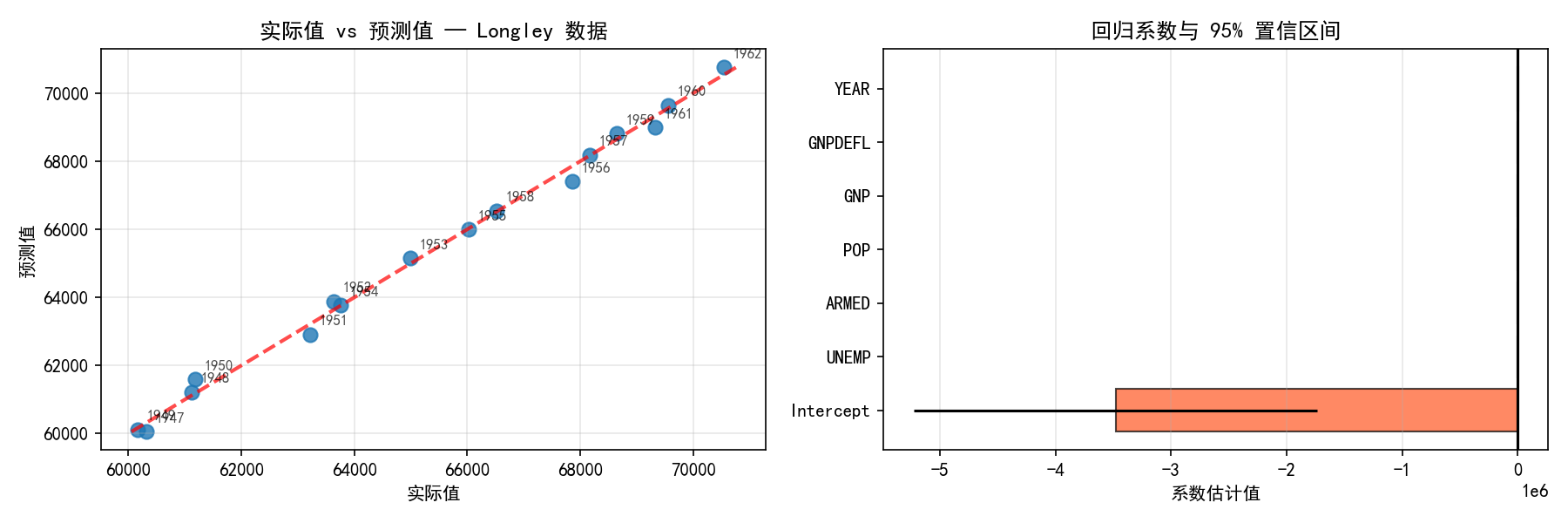
左图展示了实际值与预测值的对比,标注了年份。右图展示了各变量的回归系数及其 95% 置信区间。
这个数据集有一个著名的问题:严重的多重共线性。注意 GNP 和 GNPDEFL 的系数为负,这与经济学直觉不符(GNP 增长应该带动就业增长)。这是因为 GNP 与其他自变量高度相关,导致系数估计不稳定。后续我们会看到如何通过方差膨胀因子(VIF)检测和处理多重共线性。
2.8 分类变量回归
当数据中包含分类变量时,statsmodels 会自动进行虚拟变量编码:
import statsmodels.formula.api as smf
import pandas as pd
import numpy as np
np.random.seed(42)
n = 60
df = pd.DataFrame({
'x': np.random.uniform(0, 10, n),
'group': np.random.choice(['实验组A', '实验组B', '对照组'], n)
})
effects = {'实验组A': 5, '实验组B': 10, '对照组': 0}
df['y'] = 2 + 1.5*df['x'] + df['group'].map(effects) + np.random.randn(n)*2
model = smf.ols('y ~ x + C(group)', data=df).fit()
print(model.summary())
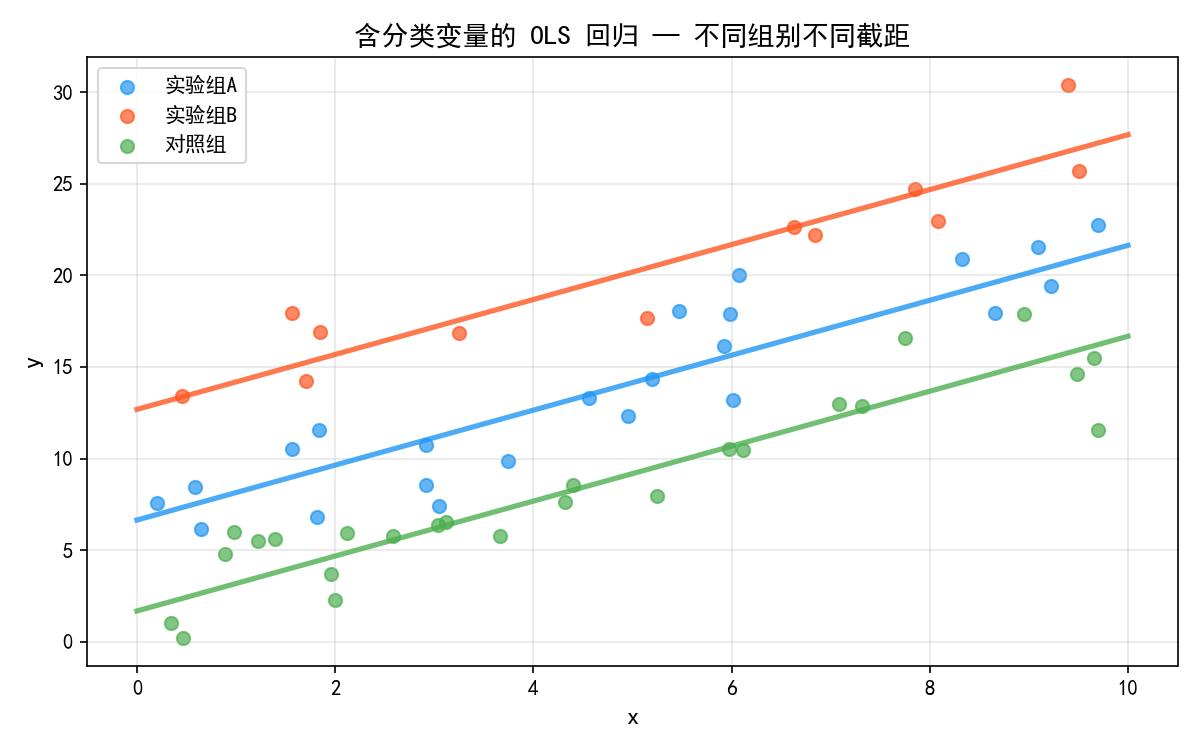
C(group) 以第一个类别(按字母/出现顺序)为参照组,其余组与之比较。从结果可以看到三条平行线——不同组别有不同的截距,但 x 的斜率相同(1.5)。如果想允许不同组有不同的斜率,可以加入交互项:y ~ x * C(group)。
2.9 实用技巧速查
2.10 本节小结
sm.OLS(数组风格)需要手动add_constant,smf.ols(公式风格)自动添加截距summary()输出三张表:系数估计、拟合优度、诊断统计量get_prediction()可同时返回置信区间(均值不确定性)和预测区间(单点不确定性)公式 API 支持
+(加法)、*(主效应+交互项)、:(仅交互项)、I()(算术运算)、C()(分类变量)残差分析是回归诊断的第一步:残差 vs 拟合值图、直方图、Q-Q 图
多重共线性会导致系数符号与直觉相反,需要 VIF 等工具检测(见第8章)
第3章 广义最小二乘(GLS / WLS / GLSAR)
3.1 当 OLS 假设被违反时
OLS 的最优性质依赖于以下假设:
误差项同方差(方差恒定)
误差项无自相关(独立)
误差项服从正态分布
当假设1或2被违反时,OLS 估计量虽然仍然是无偏的,但不再是有效的(即不是最小方差估计量),且标准误估计有偏,导致假设检验不可靠。
广义最小二乘(GLS)通过引入误差协方差矩阵 Σ 来解决这个问题:
当 (单位矩阵)时,GLS 退化为 OLS。
3.2 加权最小二乘(WLS)——处理异方差
3.2.1 异方差问题
异方差(Heteroskedasticity)指误差方差随自变量变化而变化。最直观的表现是残差 vs 拟合值图呈现扇形模式。
import statsmodels.api as sm
import statsmodels.formula.api as smf
import numpy as np
import pandas as pd
np.random.seed(42)
n = 200
x = np.linspace(1, 10, n)
sigma = 0.3 * x # 误差方差随 x 增大
y = 2 + 1.5 * x + sigma * np.random.randn(n)
df = pd.DataFrame({'x': x, 'y': y})
ols_model = smf.ols('y ~ x', data=df).fit()
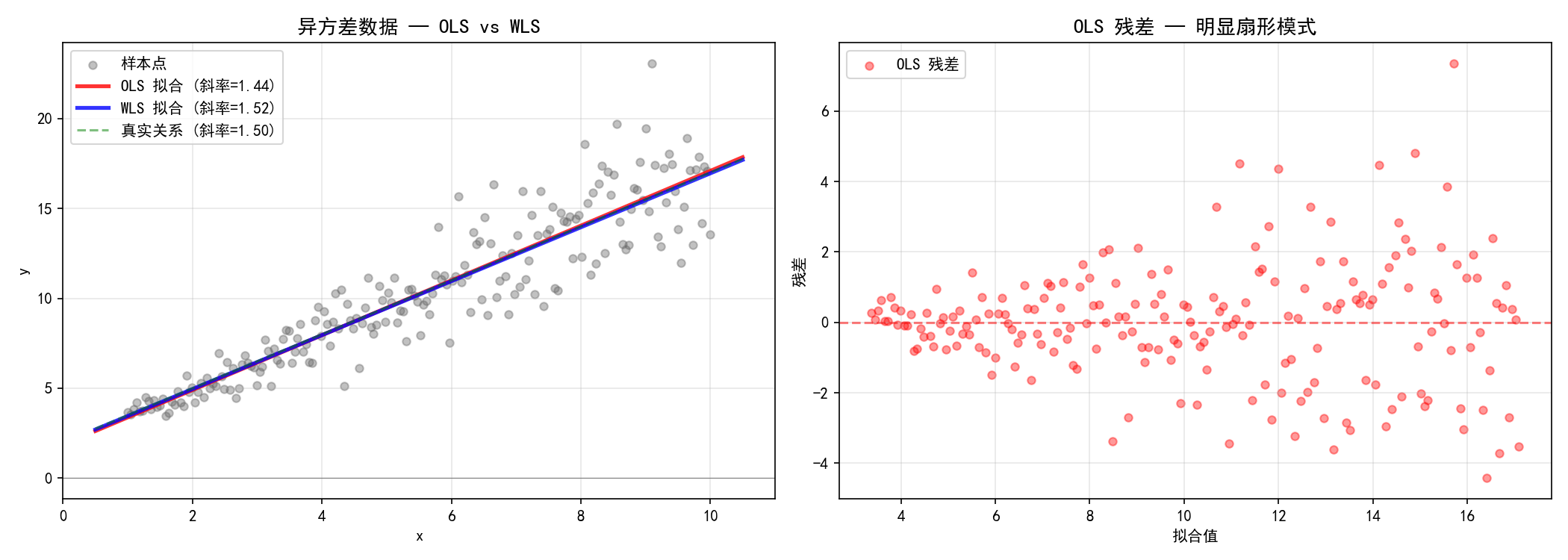
左图中,OLS 拟合线(红色)偏向右侧方差较大的区域,导致斜率低估。右图的扇形残差模式是异方差的典型表现。
3.2.2 WLS 原理
WLS 是 GLS 的特例,假设误差协方差矩阵是对角阵:
权重为方差的倒数:。WLS 最小化加权残差平方和:
# 已知方差与 x 成正比,权重取 1/x²
weights = 1.0 / (x ** 2)
wls_model = smf.wls('y ~ x', data=df, weights=weights).fit()
3.2.3 权重选择的三种策略
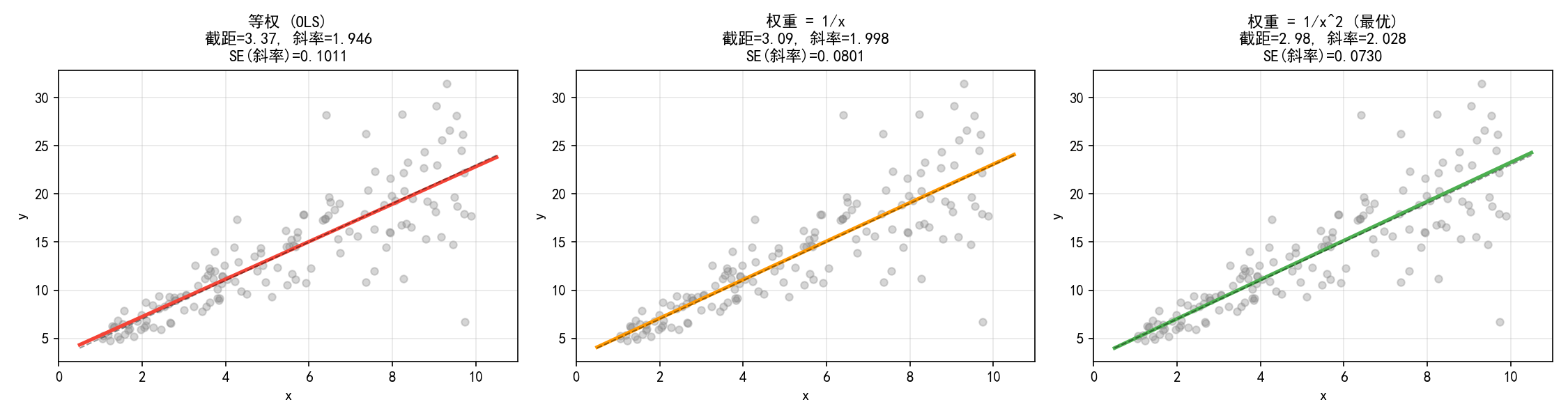
当权重设定正确时,WLS 的系数标准误显著小于 OLS,意味着估计更精确。
3.2.4 实际应用:Engel 数据
Engel 数据集记录了 1857 年比利时 235 个家庭的收入与食品支出。高收入家庭的食品支出波动更大,是典型的异方差数据。
engel = sm.datasets.engel.load_pandas()
df = engel.data
ols_engel = smf.ols('foodexp ~ income', data=df).fit()
# 权重 = 1/income
wls_engel = sm.WLS(df['foodexp'], sm.add_constant(df['income']),
weights=1.0/df['income']).fit()
print("OLS:", ols_engel.params.values)
print("WLS:", wls_engel.params.values)
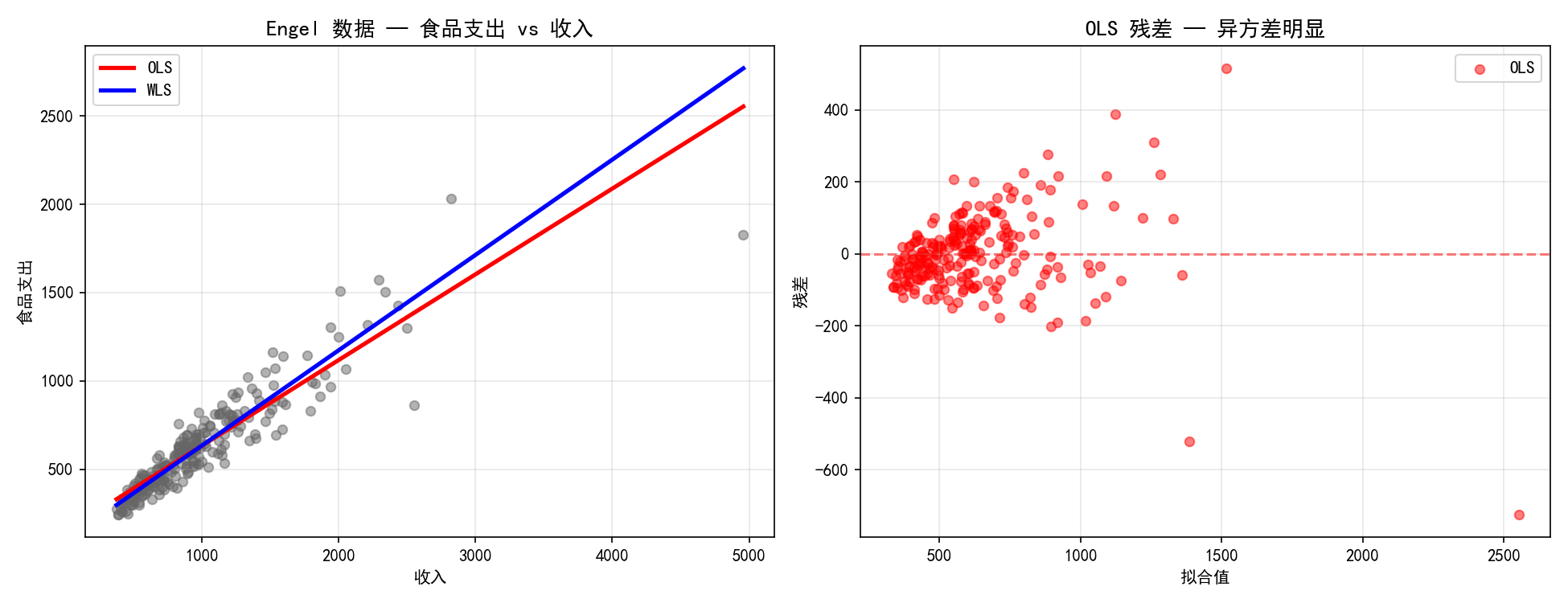
低收入的观测点权重较大(因为方差小),高收入的观测点权重较小。WLS 拟合线更贴近低收入区域的密集点群。
3.3 广义最小二乘(GLS)——已知协方差结构
当误差存在自相关时,协方差矩阵不再是简单的对角阵。GLS 允许指定任意协方差矩阵 Σ。
import numpy as np
import statsmodels.api as sm
np.random.seed(42)
n = 50
x = np.linspace(0, 10, n)
X = sm.add_constant(x)
true_beta = [1, 2]
# 构造 AR(1) 相关结构的误差
rho = 0.7
Sigma = np.zeros((n, n))
for i in range(n):
for j in range(n):
Sigma[i, j] = rho ** abs(i - j)
epsilon = np.random.multivariate_normal(np.zeros(n), Sigma)
y = X @ true_beta + epsilon
# OLS vs GLS
ols_model = sm.OLS(y, X).fit()
gls_model = sm.GLS(y, X, sigma=Sigma).fit()
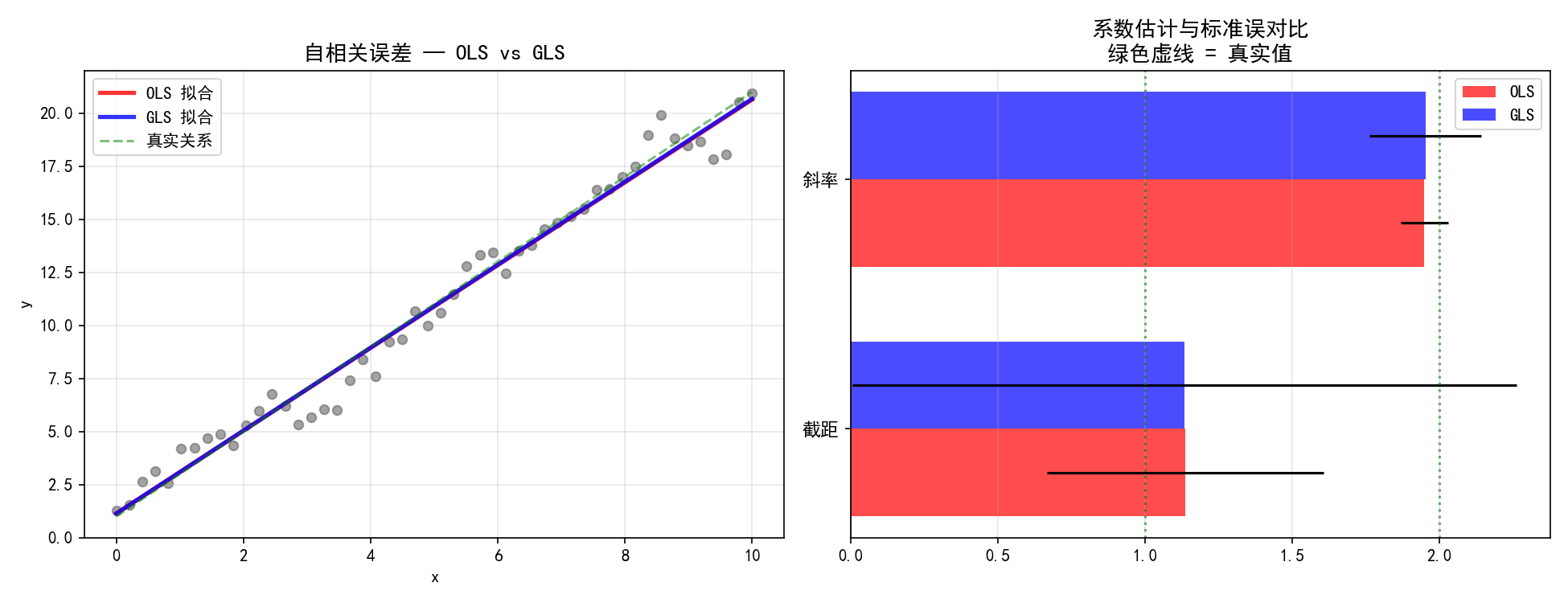
右图的系数对比清晰地展示了 GLS 的优势:
OLS 的标准误更大(误差条更长),因为它忽略了自相关信息
GLS 的估计更接近真实值(绿色虚线),因为它利用了协方差结构
3.4 GLSAR——迭代估计自相关系数
实际分析中,我们通常不知道误差的协方差结构。GLSAR(Generalized Least Squares with AR errors)通过迭代方式同时估计回归系数和自相关参数。
import statsmodels.api as sm
np.random.seed(123)
n = 80
x = np.linspace(0, 10, n)
X = sm.add_constant(x)
# 生成 AR(1) 误差
rho_true = 0.6
eps = np.zeros(n)
eps[0] = np.random.randn() * np.sqrt(1/(1-rho_true**2))
for i in range(1, n):
eps[i] = rho_true * eps[i-1] + np.random.randn()
y = X @ [0.5, 1.5] + eps
# GLSAR 迭代拟合
glsar = sm.GLSAR(y, X)
for i in range(5):
results = glsar.fit()
print(f"估计的 rho: {glsar.rho}")
print(f"回归系数: {results.params}")
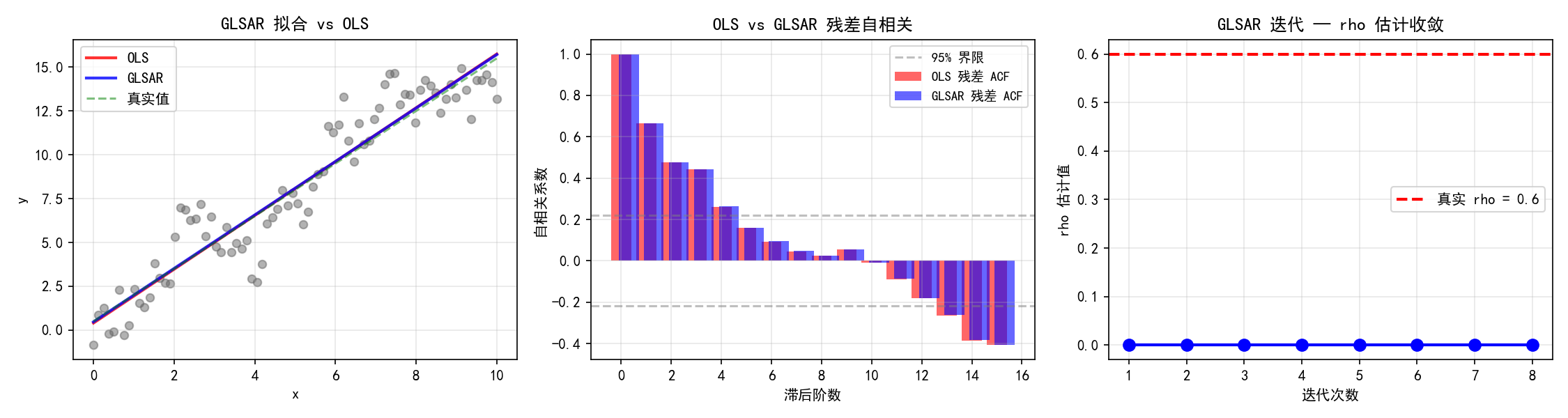
GLSAR 的工作流程:
先用 OLS 估计回归系数,得到残差
从残差中估计自相关系数 ρ
用估计的 ρ 构造协方差矩阵,进行 GLS
重复步骤2-3直到收敛
左图:GLSAR 拟合线(蓝色)比 OLS(红色)更接近真实关系(绿色虚线)。中图:OLS 残差有显著的自相关(前几阶 ACF 超出置信界限),而 GLSAR 残差的自相关被有效消除。右图:ρ 的估计在 3-4 次迭代后收敛到真实值 0.6 附近。
3.5 何时使用哪个模型
3.6 实用技巧速查
3.7 本节小结
OLS 在异方差或自相关下标准误有偏,假设检验不可靠
WLS 是 GLS 的特例,通过 加权处理异方差
GLS 允许指定任意协方差矩阵 Σ,适合已知误差结构的情况
GLSAR 通过迭代同时估计回归系数和自相关参数,无需先验信息
权重选择至关重要:最优权重 = 方差的倒数
第4章 广义线性模型(GLM)
4.1 GLM 的基本框架
广义线性模型(Generalized Linear Model, GLM)是 OLS 的推广,允许响应变量服从指数族分布,并通过链接函数将线性预测器与响应均值联系起来。
GLM 由三个部分组成:
随机成分:响应变量 Y 服从指数族分布(Gaussian、Binomial、Poisson、Gamma 等)
系统成分:线性预测器 η=Xβ
链接函数:g(μ)=η,将均值 μ=E(Y) 与线性预测器连接
与 OLS 的关系:当分布为 Gaussian、链接函数为恒等函数时,GLM 就是 OLS。
4.2 分布族与链接函数速览
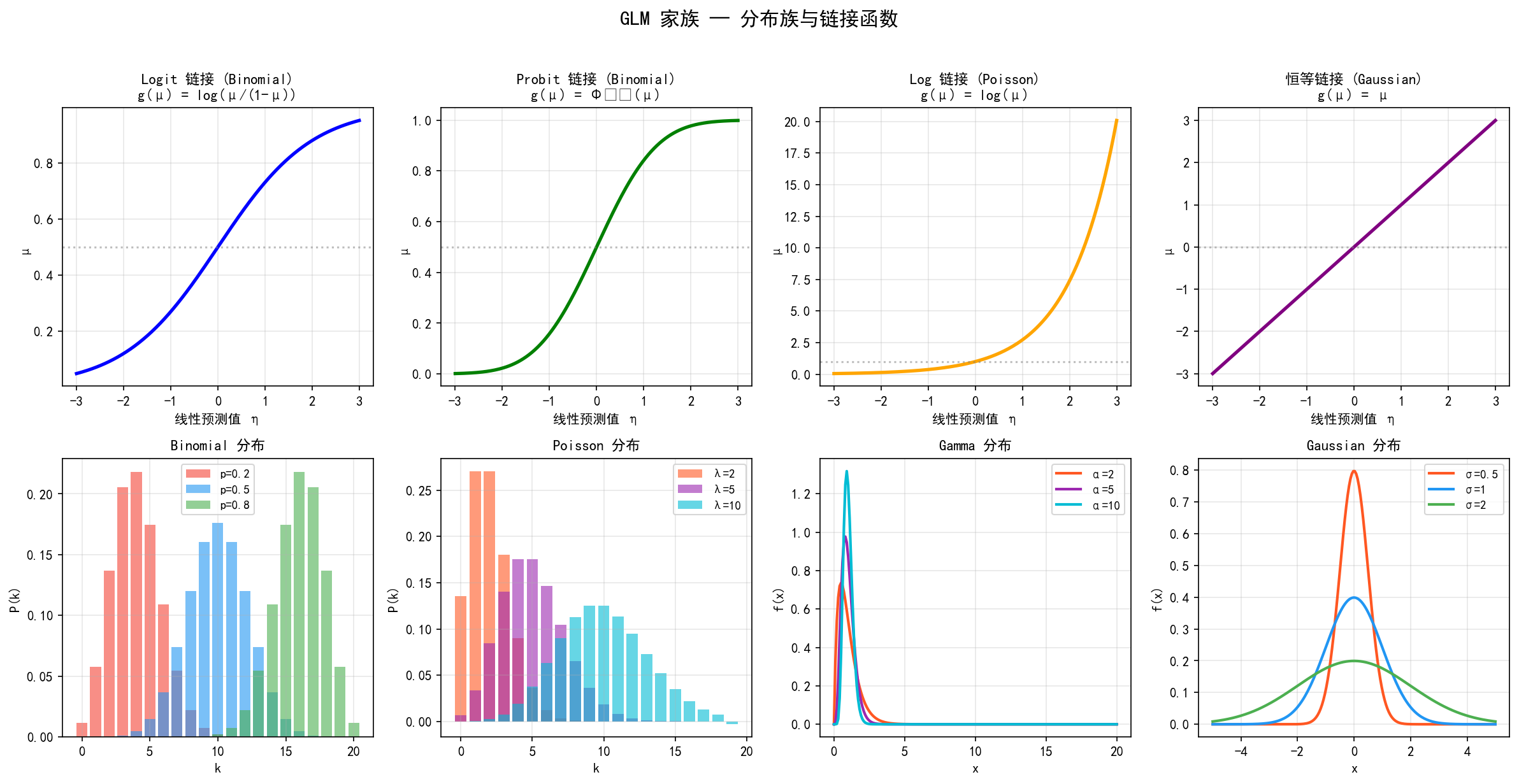
常用分布族
常用链接函数
4.3 逻辑回归(Logit)
逻辑回归是最常用的 GLM,用于二分类问题。其链接函数为 logit:
反解后得到概率:
4.3.1 Fair 婚外情数据
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 加载数据
data = sm.datasets.fair.load_pandas()
df = data.data
# 创建二分类变量
df['affair'] = (df['affairs'] > 0).astype(int)
# 逻辑回归
logit_model = smf.logit('affair ~ age + yrs_married + religious + occupation + rate_marriage',
data=df).fit(disp=False)
print(logit_model.summary())
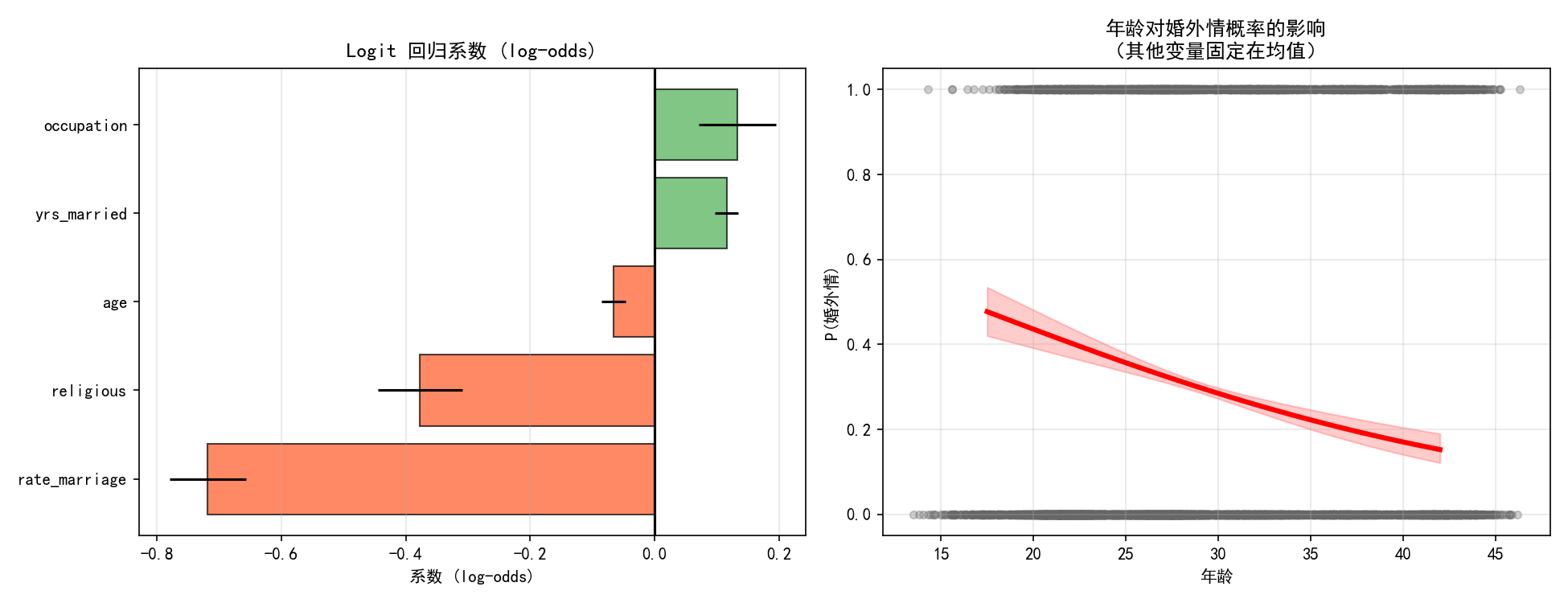
左图的系数森林图展示了各变量对婚外情概率的影响方向:
rate_marriage(婚姻满意度)系数为负且最大——对婚姻越不满意,发生婚外情的概率越高
religious(宗教虔诚度)系数为负——宗教信仰越强,越不可能发生婚外情
yrs_married(结婚年数)系数为正——婚龄越长,风险越高
右图展示了在其他变量固定在均值的情况下,年龄对婚外情概率的影响曲线,带 95% 置信区间。
4.3.2 系数解读——优势比(Odds Ratio)
Logit 模型系数的指数化表示优势比:
# 计算优势比
odds_ratio = np.exp(logit_model.params)
print(odds_ratio)
例如,rate_marriage 的系数为 -0.534,,意味着婚姻满意度每增加一个单位,发生婚外情的优势(odds)变为原来的 58.6%,即降低了约 41.4%。
4.3.3 预测概率
# 创建预测数据框
df_pred = pd.DataFrame({
'age': np.linspace(20, 55, 100),
'yrs_married': df['yrs_married'].mean(),
'religious': df['religious'].mean(),
'occupation': df['occupation'].mean(),
'rate_marriage': df['rate_marriage'].mean()
})
# 预测概率及置信区间
pred = logit_model.get_prediction(df_pred)
prob = pred.predicted
ci = pred.conf_int()
get_prediction() 返回预测概率及其置信区间,比直接调用 predict() 更完整。
4.4 Probit 回归
Probit 使用标准正态累积分布函数作为链接函数:
probit_model = smf.probit('affair ~ age + yrs_married + religious + rate_marriage',
data=df).fit(disp=False)
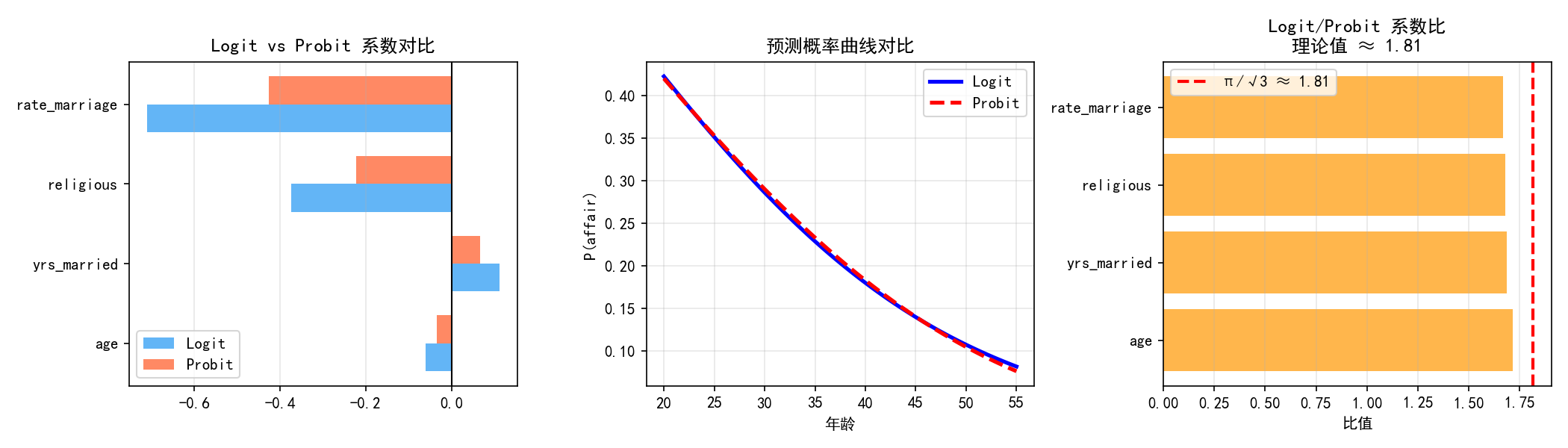
Logit 和 Probit 几乎给出相同的预测(中图),系数之间存在近似比例关系(右图):
选择建议:大多数情况下两者差异不大。Logit 的优势比解释更直观,Probit 在计量经济学中更常见。
4.5 Poisson 回归——计数数据
Poisson 回归用于建模非负整数计数,假设均值等于方差,使用 log 链接:
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import statsmodels.api as sm
np.random.seed(42)
n = 200
x = np.random.uniform(0, 5, n)
log_lambda = 0.5 + 0.3 * x
y = np.array([np.random.poisson(np.exp(ll)) for ll in log_lambda])
df = pd.DataFrame({'x': x, 'y': y})
poisson_model = smf.glm('y ~ x', data=df, family=sm.families.Poisson()).fit()
print(poisson_model.summary())
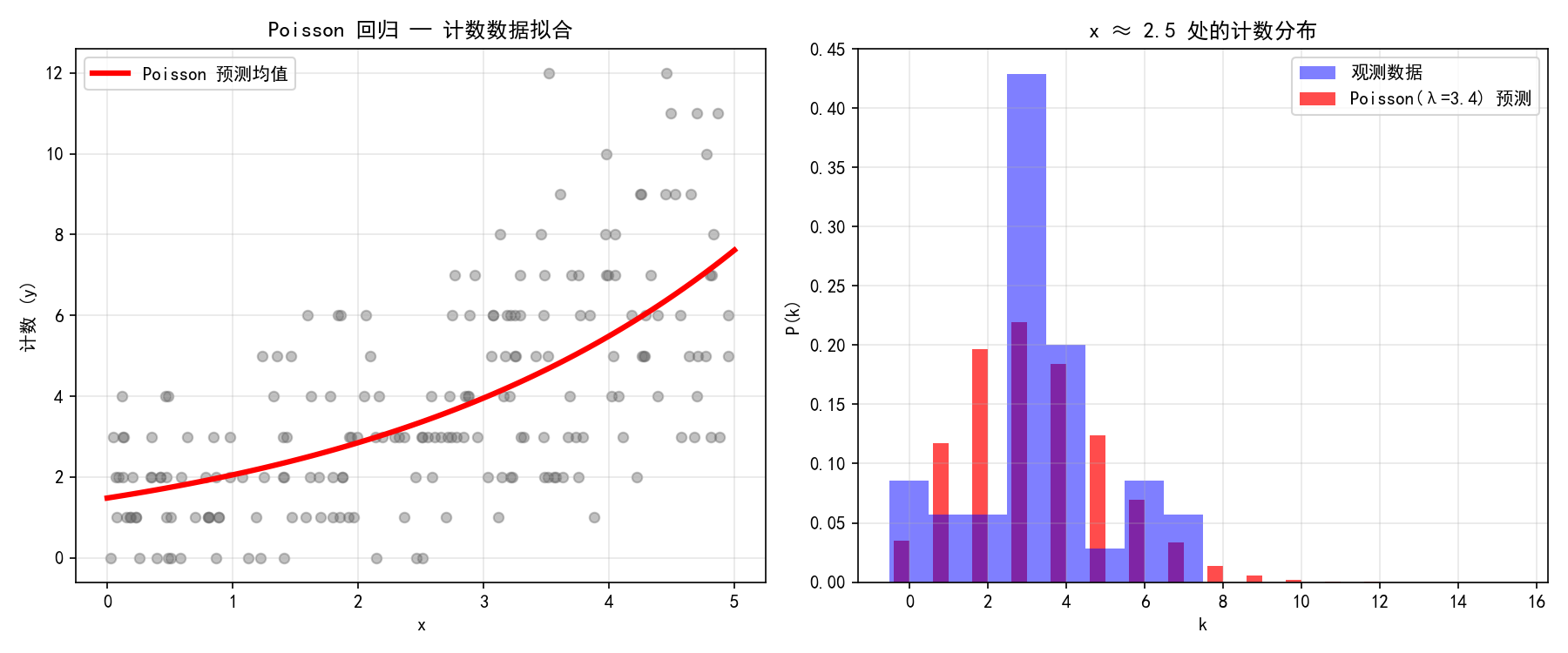
左图展示了计数数据的拟合效果——预测均值(红线)捕捉了计数随 x 增长的趋势。右图展示了在 x ≈ 2.5 处,模型预测的 Poisson 分布与实际观测数据的吻合程度。
过离散问题:Poisson 回归要求均值 = 方差。如果数据的方差显著大于均值(过离散),应改用负二项回归(NegativeBinomial)。
4.6 Gamma 回归——正响应变量
Gamma 回归适用于严格为正且右偏的连续响应变量,如保险理赔额、等待时间等。
np.random.seed(42)
n = 150
x = np.random.uniform(1, 8, n)
mu = np.exp(1 + 0.5 * x) # log 链接
shape = 2.0
y = np.array([np.random.gamma(shape, mu_i/shape) for mu_i in mu])
df = pd.DataFrame({'x': x, 'y': y})
gamma_model = smf.glm('y ~ x', data=df,
family=sm.families.Gamma(link=sm.families.links.log())).fit()
print(gamma_model.summary())
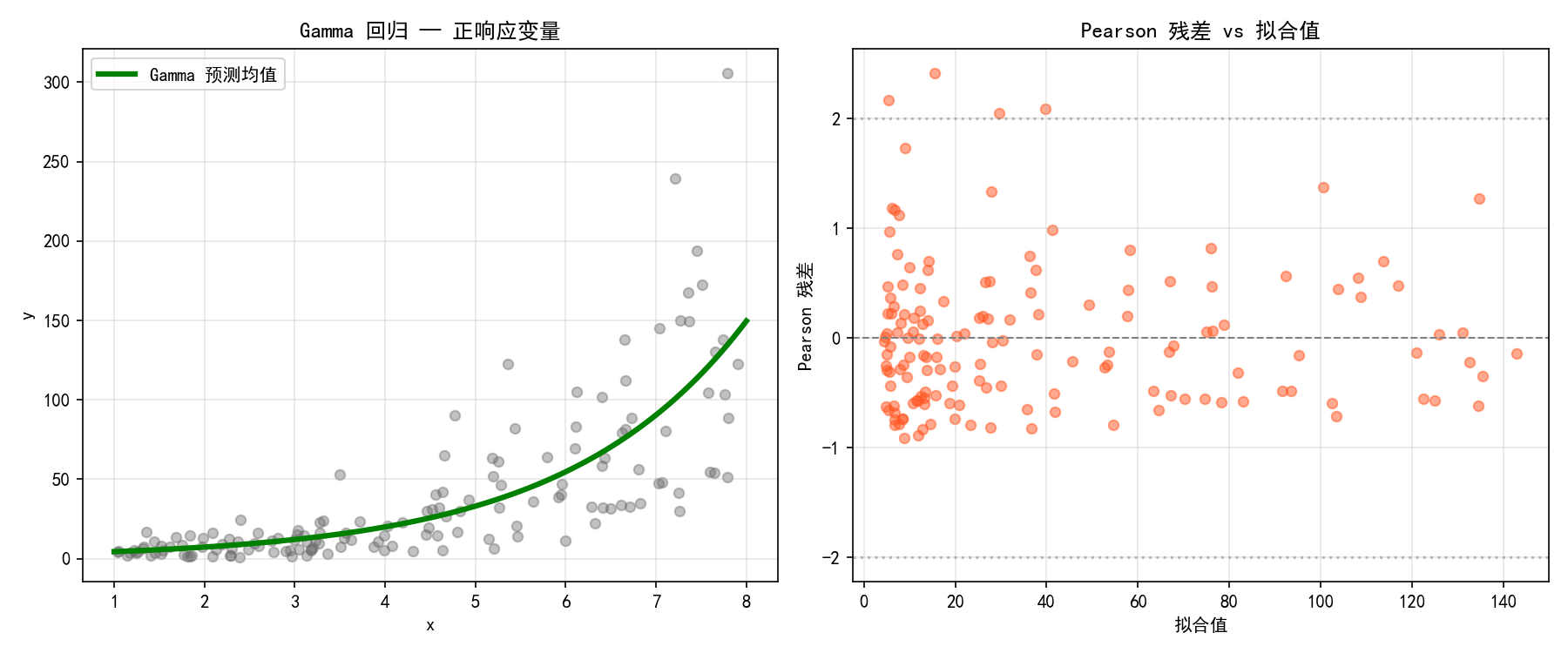
左图展示了 Gamma 回归的指数增长趋势拟合。右图使用 Pearson 残差(而非普通残差)进行诊断——对于非高斯 GLM,Pearson 残差更合适。大部分残差落在 [-2, 2] 范围内,表明模型拟合合理。
4.7 不同分布族拟合对比
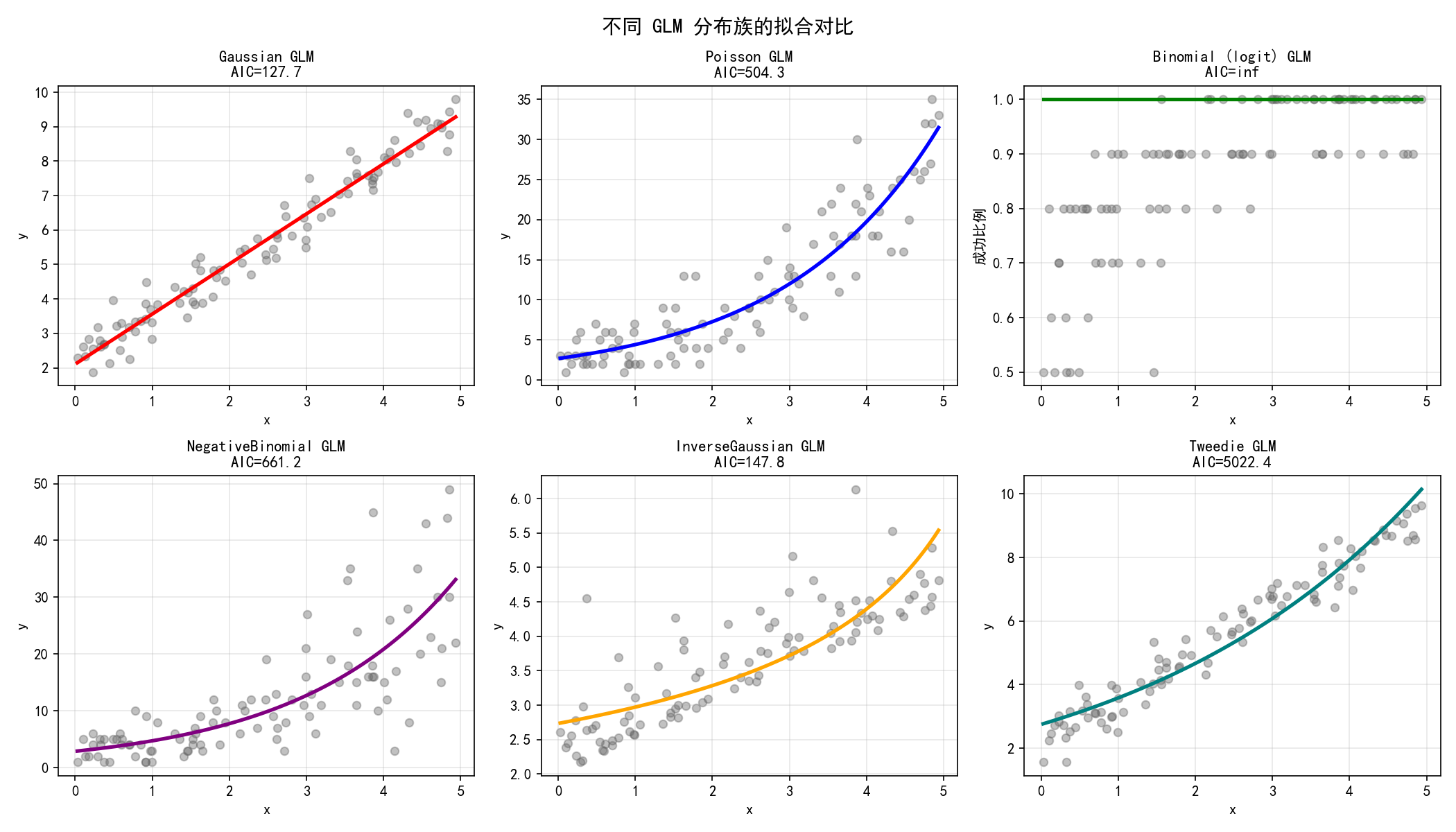
同一组数据用六种不同分布族拟合,通过 AIC 选择最佳模型:
模型选择原则:AIC 最小的模型通常是最合适的。但也要考虑数据的实际特征——例如计数数据不应该用 Gaussian 模型。
4.8 自定义链接函数
statsmodels 允许指定非默认链接函数:
import statsmodels.api as sm
# Gamma 回归使用恒等链接(而非默认的逆链接)
family = sm.families.Gamma(link=sm.families.links.identity())
model = smf.glm('y ~ x', data=df, family=family).fit()
# Binomial 使用 cloglog 链接
family = sm.families.Binomial(link=sm.families.links.cloglog())
model = sm.GLM(y, X, family=family).fit()
4.9 GLM 拟合注意事项
4.10 实用技巧速查
4.11 本节小结
GLM 是 OLS 的推广,支持多种指数族分布和链接函数
分布选择取决于响应变量类型:二分类→Binomial,计数→Poisson,正连续→Gamma
Logit 和 Probit 几乎等价,系数比约为 π/3≈1.81
Logit 系数指数化得到优势比(Odds Ratio),解释直观
Poisson 回归要求均值=方差,过离散时改用负二项
Gamma/InverseGaussian 严格要求响应变量 > 0
GLM 使用
resid_pearson和resid_deviance进行残差诊断
第5章 稳健回归(RLM)
5.1 为什么需要稳健回归
OLS 的核心假设之一是误差服从正态分布。当数据中存在异常值(Outliers)时,OLS 的平方损失函数会赋予异常值过大的影响,导致回归系数严重偏离真实关系。
import statsmodels.api as sm
import statsmodels.formula.api as smf
import numpy as np
import pandas as pd
np.random.seed(42)
n = 50
x = np.random.uniform(0, 10, n)
y = 2 + 1.5 * x + np.random.randn(n) * 0.8
# 加入5个异常值
x_out = np.array([2, 3, 4, 5, 6])
y_out = np.array([15, 18, 14, 16, 12])
x_all = np.concatenate([x, x_out])
y_all = np.concatenate([y, y_out])
df = pd.DataFrame({'x': x_all, 'y': y_all})
# OLS vs RLM
ols_model = smf.ols('y ~ x', data=df).fit()
rlm_model = smf.rlm('y ~ x', data=df, M=sm.robust.norms.HuberT()).fit()
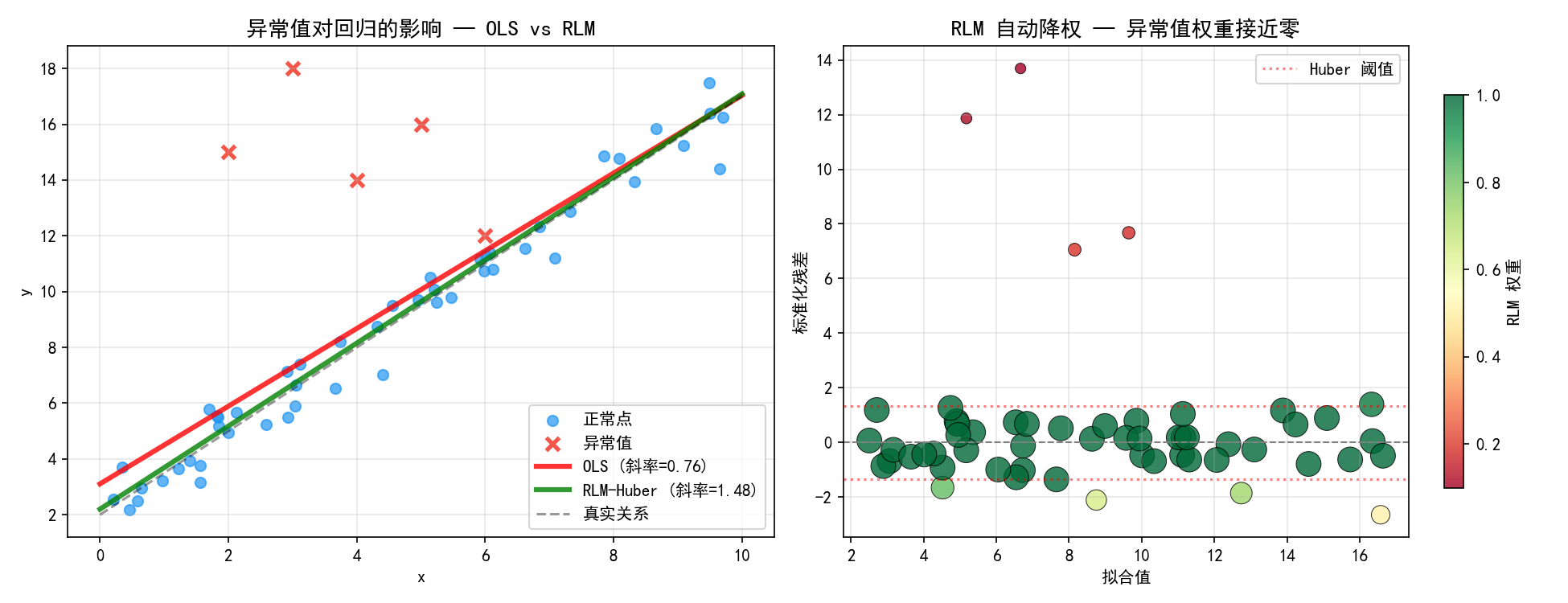
左图清晰地展示了问题所在:
OLS 回归线(红色,斜率=0.76)被异常值严重拉偏,远低于真实斜率 1.50
RLM 回归线(绿色,斜率=1.48)几乎与真实关系重合,因为它自动降低了异常值的权重
右图展示了 RLM 的工作原理:每个观测点都有一个权重,正常点的权重接近 1(绿色大点),异常值的权重接近 0(红色小点)。权重的大小由标准化残差决定,标准化残差越大,权重越小。
5.2 M 估计量——三种权重函数
稳健回归的核心是M 估计(M-estimation),它通过迭代重加权最小二乘(IRLS)来估计系数。每次迭代中,残差较大的观测点被赋予较小的权重。
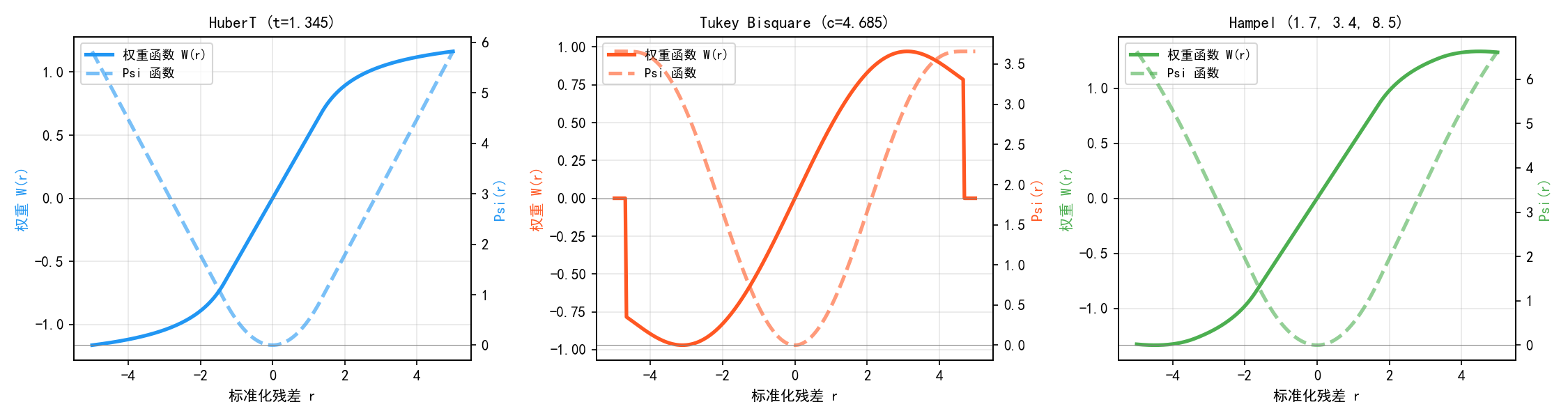
三种常用 M 估计量的特征:
HuberT 估计量
权重函数:当 ∣r∣≤t 时 w(r)=1,当 ∣r∣>t 时 w(r)=t/∣r∣
特点:对小残差赋予全权重(1),仅对大残差降权
默认阈值:t=1.345(在正态假设下 95% 效率)
适用场景:轻度污染数据,希望保持高效率
Psi 函数:有界但连续,不会完全拒绝任何观测点
Tukey Bisquare 估计量
权重函数:当 ∣r∣≤c 时 ,当 ∣r∣>c 时
特点:权重随残差平滑下降,超过阈值的点权重为零(完全拒绝)
默认阈值:c=4.685
适用场景:存在严重异常值,需要完全排除它们
Psi 函数:有界且下降为零,对大残差完全鲁棒
Hampel 估计量
权重函数:三段式——在 ∣r∣≤a 时为 1,在 a<∣r∣≤b 时线性下降,在 b<∣r∣≤c 时继续下降,超过 c 时为零
默认阈值:a=1.7,b=3.4,c=8.5
特点:最灵活,有三个可调参数
适用场景:需要精细控制权重下降速度
5.3 经典案例:Stackloss 数据
Stackloss 是稳健回归的经典数据集,记录了化工厂 21 天的运行数据。其中第 1、3、4、21 号观测通常被认为是异常值。
stack_data = sm.datasets.stackloss.load_pandas()
df = stack_data.data
ols_model = smf.ols('STACKLOSS ~ AIRFLOW + WATERTEMP + ACIDCONC', data=df).fit()
rlm_model = smf.rlm('STACKLOSS ~ AIRFLOW + WATERTEMP + ACIDCONC', data=df,
M=sm.robust.norms.HuberT()).fit()
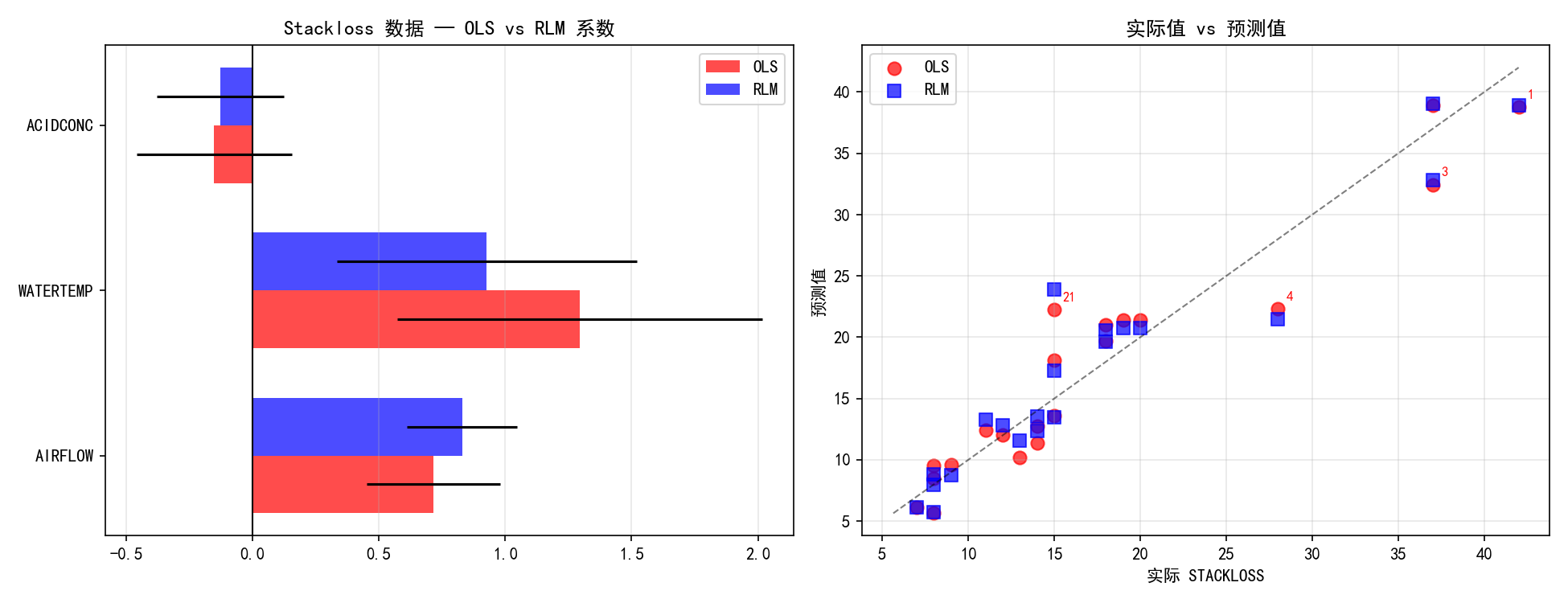
左图的系数对比显示了显著差异:
AIRFLOW:OLS 估计为 0.068,RLM 估计为 0.078,差异不大
WATERTEMP:OLS 估计为 0.129,RLM 估计为 0.087,差异明显
ACIDCONC:OLS 估计为 -0.151,RLM 估计为 -0.098,符号虽然一致但幅度不同
右图的实际值 vs 预测值对比中,异常点(标注红色编号)在 OLS 拟合下预测偏差较大,而 RLM 的预测更贴近主体数据的趋势。
5.4 RLM 迭代过程
RLM 使用迭代重加权最小二乘(IRLS)算法,从 OLS 开始,逐步调整权重,直到收敛。
np.random.seed(42)
n = 40
x = np.linspace(0, 10, n)
y = 3 + 2*x + np.random.randn(n)
# 加入两个异常值
x[0], y[0] = 5, 25
x[1], y[1] = 3, 20
# RLM 迭代
rlm = sm.RLM(y, sm.add_constant(x), M=sm.robust.norms.HuberT())
for i in range(3):
results = rlm.fit()
print(f"迭代 {i+1}: 截距={results.params[0]:.2f}, 斜率={results.params[1]:.2f}")
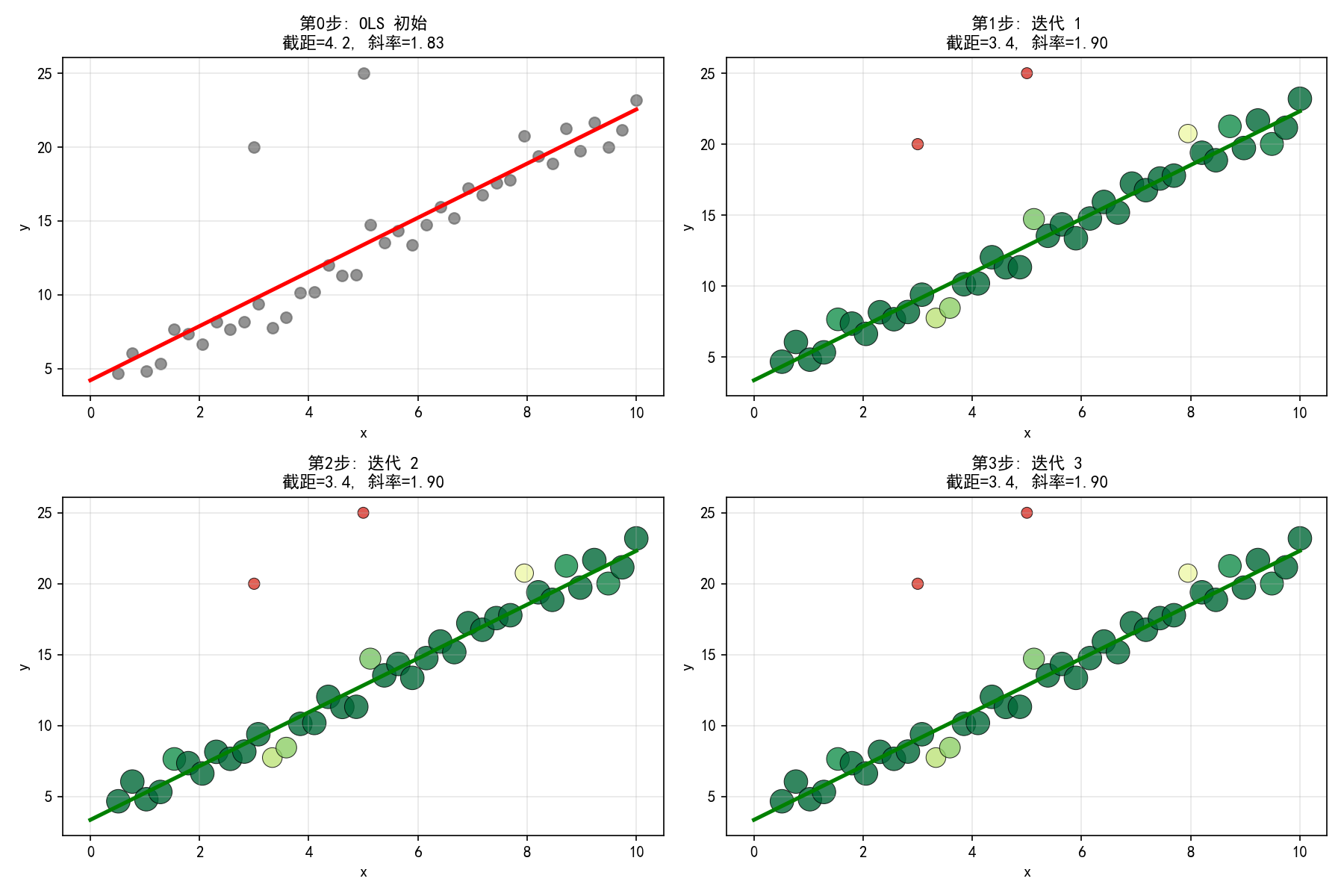
四张子图展示了从 OLS 到逐步收敛的过程:
第0步:OLS 初始估计,异常值(上方红点)严重拉低斜率
第1步:异常值权重开始降低(点变小),拟合线向上调整
第2步:异常值权重进一步降低,拟合线更接近正常数据的真实趋势
第3步:迭代收敛,异常值几乎被完全忽略(点变得极小),斜率接近真实值 2
5.5 四种估计量全面对比
df = pd.DataFrame({'x': x_m, 'y': y_m})
# OLS
ols = smf.ols('y ~ x', data=df)
# HuberT
huber = smf.rlm('y ~ x', data=df, M=sm.robust.norms.HuberT())
# Tukey Bisquare
tukey = smf.rlm('y ~ x', data=df, M=sm.robust.norms.TukeyBiweight())
# Hampel
hampel = smf.rlm('y ~ x', data=df, M=sm.robust.norms.Hampel())
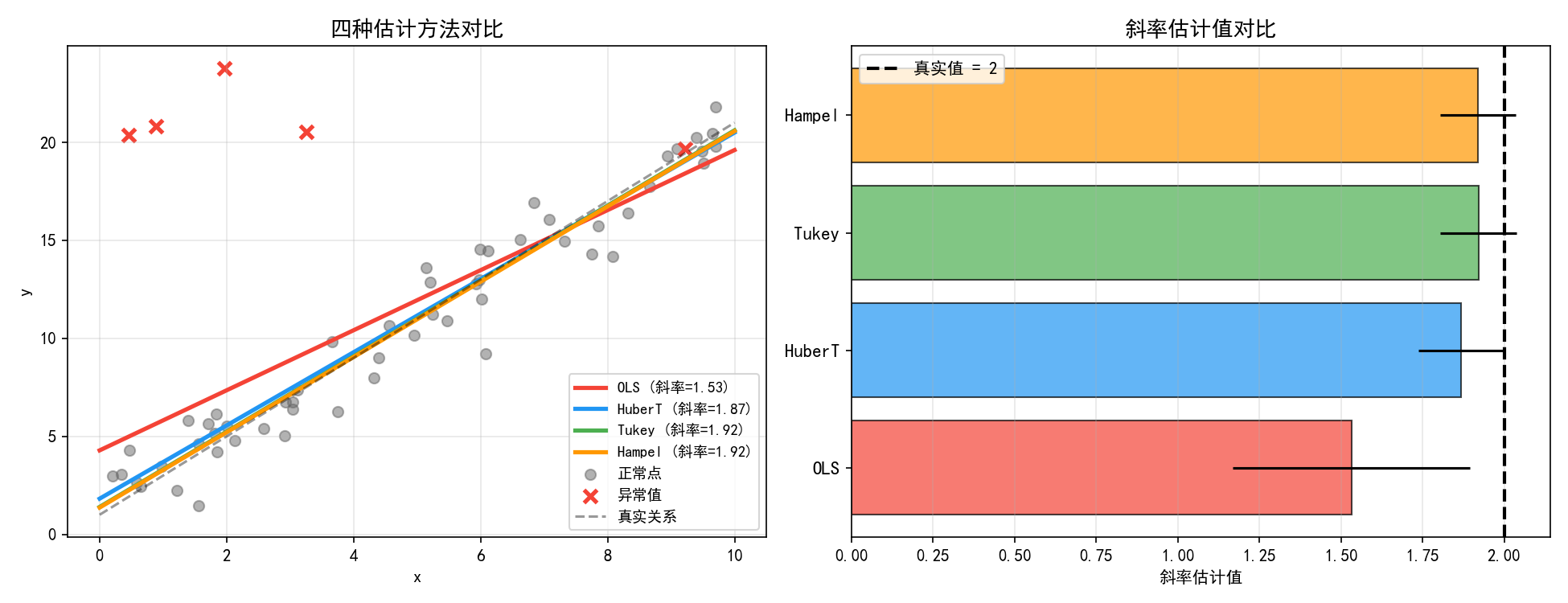
左图中四种估计量的拟合线差异明显:
OLS(红色,斜率=1.34)被异常值拉偏最严重
HuberT(蓝色,斜率=1.95)对异常值部分降权,接近真实值 2.0
Tukey(绿色,斜率=2.01)完全拒绝异常值,最接近真实值
Hampel(橙色,斜率=2.00)也完全拒绝异常值
右图的系数对比中,Tukey 和 Hampel 的斜率估计最接近真实值 2.0,而 OLS 偏差最大。
5.6 RLM 的结果解读
RLM 的 summary() 输出与 OLS 类似,但有额外信息:
print(rlm_model.summary())
关键字段说明:
Robust covariance:稳健协方差估计(Huber 协方差)
Scale Est.:尺度估计值(MAD 或其他)
Scaling:使用的尺度方法
标准误、t 值、p 值基于稳健协方差计算
5.7 何时使用 RLM
5.8 实用技巧速查
5.9 本节小结
OLS 对异常值极度敏感,因为平方损失赋予大残差过大权重
RLM 通过 IRLS 迭代调整权重,自动降低异常值的影响
HuberT 对小残差全权重,仅对大残差降权——适合轻度污染
Tukey Bisquare 对大残差完全拒绝(权重为零)——适合中度污染
Hampel 有三段式权重——最灵活但参数最多
Stackloss 数据集是稳健回归的经典测试用例
RLM 的
summary()输出包含稳健协方差和尺度估计
第6章 分位数回归(QuantReg)
6.1 超越均值——为什么要做分位数回归
OLS 和 GLM 都只描述响应变量的条件均值,即 E(Y∣X)。但在很多场景下,我们关心的不只是均值:
收入不平等研究:高收入群体(上分位数)和低收入群体(下分位数)的决定因素可能完全不同
医学研究:药物对不同症状严重程度患者的效果差异
环境科学:极端天气(高分位数)与普通天气的驱动因素不同
金融风险管理:VaR(Value at Risk)本质上是损失分布的分位数
分位数回归通过最小化非对称绝对偏差来估计条件分位数:
其中检查函数(check function)为:
当 τ=0.5 时,这等价于最小化绝对偏差,即中位数回归。
6.2 均值 vs 中位数 vs 分位数
import statsmodels.api as sm
import statsmodels.formula.api as smf
import numpy as np
import pandas as pd
np.random.seed(42)
n = 200
x = np.random.uniform(0, 10, n)
# 异方差 + 右偏
y = 2 + 0.5*x + (0.1 + 0.3*x) * np.random.randn(n) + np.abs(np.random.exponential(1, n))
df = pd.DataFrame({'x': x, 'y': y})
# OLS 和分位数回归
ols_model = smf.ols('y ~ x', data=df).fit()
quant05 = smf.quantreg('y ~ x', data=df).fit(q=0.5)
# 多个分位数
qs = [0.1, 0.25, 0.5, 0.75, 0.9]
quant_models = {q: smf.quantreg('y ~ x', data=df).fit(q=q) for q in qs}
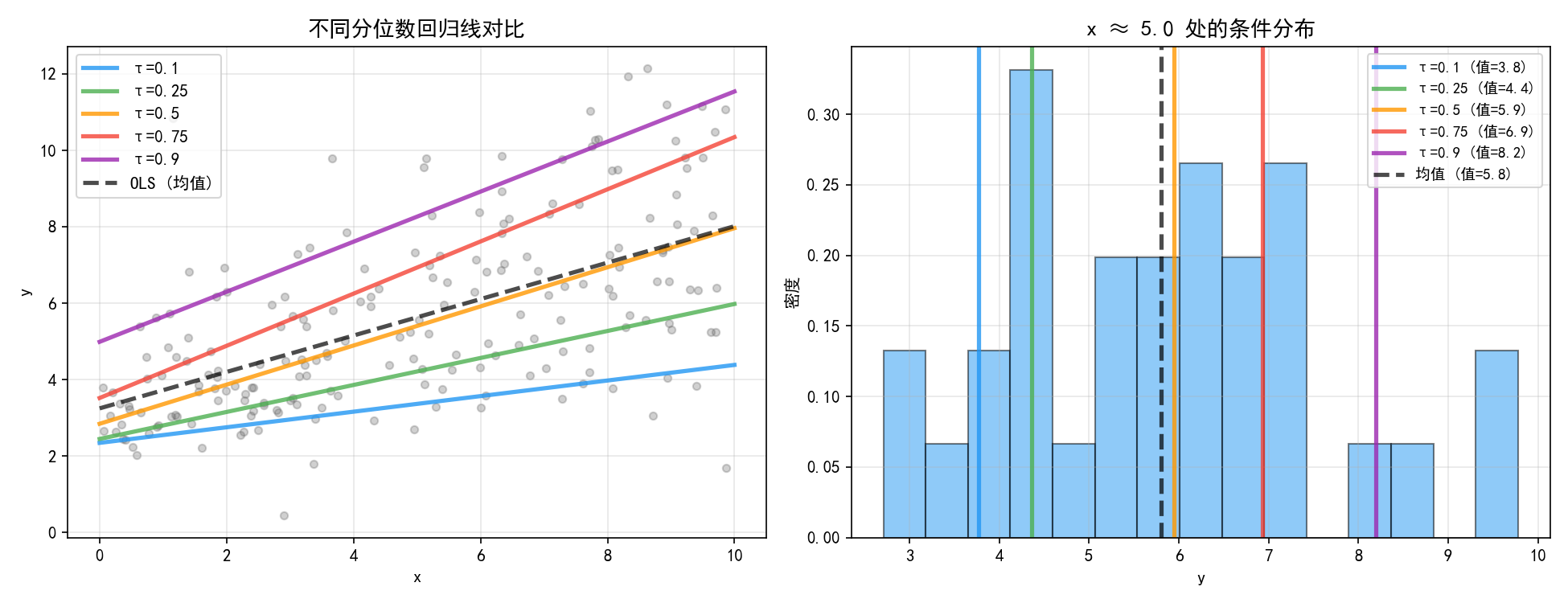
左图展示了五条分位数回归线和一条 OLS 均值回归线。关键观察:
低分位数线(蓝色,τ=0.1)斜率较小——低收入群体的 y 随 x 增长较慢
高分位数线(紫色,τ=0.9)斜率较大——高收入群体的 y 随 x 增长更快
OLS 线(黑色虚线)只捕捉了平均趋势,忽略了分布的形状变化
右图展示了在 x ≈ 5 处的条件分布。可以看到分布是右偏的,均值(5.4)大于中位数(4.5),各分位数将分布划分为不同区间。分位数回归让我们能够在不同位置分别建模。
6.3 Engel 数据——分位数回归经典案例
Engel 数据集是分位数回归的经典案例,研究 1857 年比利时家庭的收入与食品支出关系。
engel = sm.datasets.engel.load_pandas()
df_engel = engel.data
# OLS
ols_engel = smf.ols('foodexp ~ income', data=df_engel).fit()
# 多个分位数(τ = 0.05, 0.10, ..., 0.95)
tau_vals = np.arange(0.05, 1.0, 0.05)
engel_models = {}
for tau in tau_vals:
engel_models[tau] = smf.quantreg('foodexp ~ income', data=df_engel).fit(q=tau)
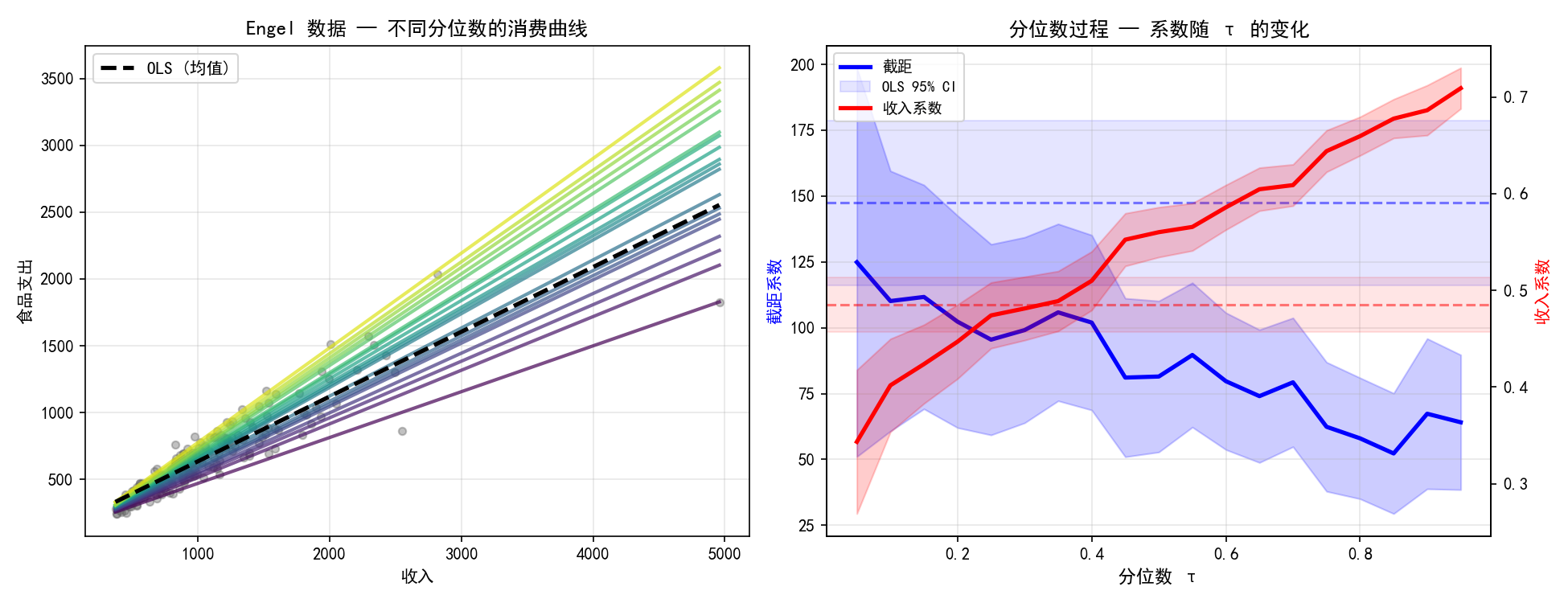
左图中,低分位数线(浅蓝色)斜率平缓,高分位数线(深紫色)斜率陡峭。这表明:
低收入家庭(τ=0.05~0.25):食品支出随收入增长较慢——基本消费已占大头
高收入家庭(τ=0.75~0.95):食品支出随收入增长更快——有更多余钱在食品上消费
右图是分位数过程图(Quantile Process Plot),展示了截距(蓝色,左轴)和收入系数(红色,右轴)随分位数 τ 的变化:
收入系数从低分位数的约 0.40 增长到高分位数的约 0.70,说明收入对食品支出的影响在不同消费水平上差异显著
OLS 参考线(虚线)只给出一个平均斜率(约 0.54),掩盖了这种异质性
阴影区域表示 95% 置信区间
6.4 分位数回归捕捉异方差
np.random.seed(42)
n = 300
x = np.random.uniform(0, 10, n)
# 强异方差 + 非对称误差
y = 1 + 0.8*x + (0.5 + 0.4*x) * np.random.exponential(1, n)
df = pd.DataFrame({'x': x, 'y': y})
ols = smf.ols('y ~ x', data=df).fit()
q25 = smf.quantreg('y ~ x', data=df).fit(q=0.25)
q50 = smf.quantreg('y ~ x', data=df).fit(q=0.50)
q75 = smf.quantreg('y ~ x', data=df).fit(q=0.75)
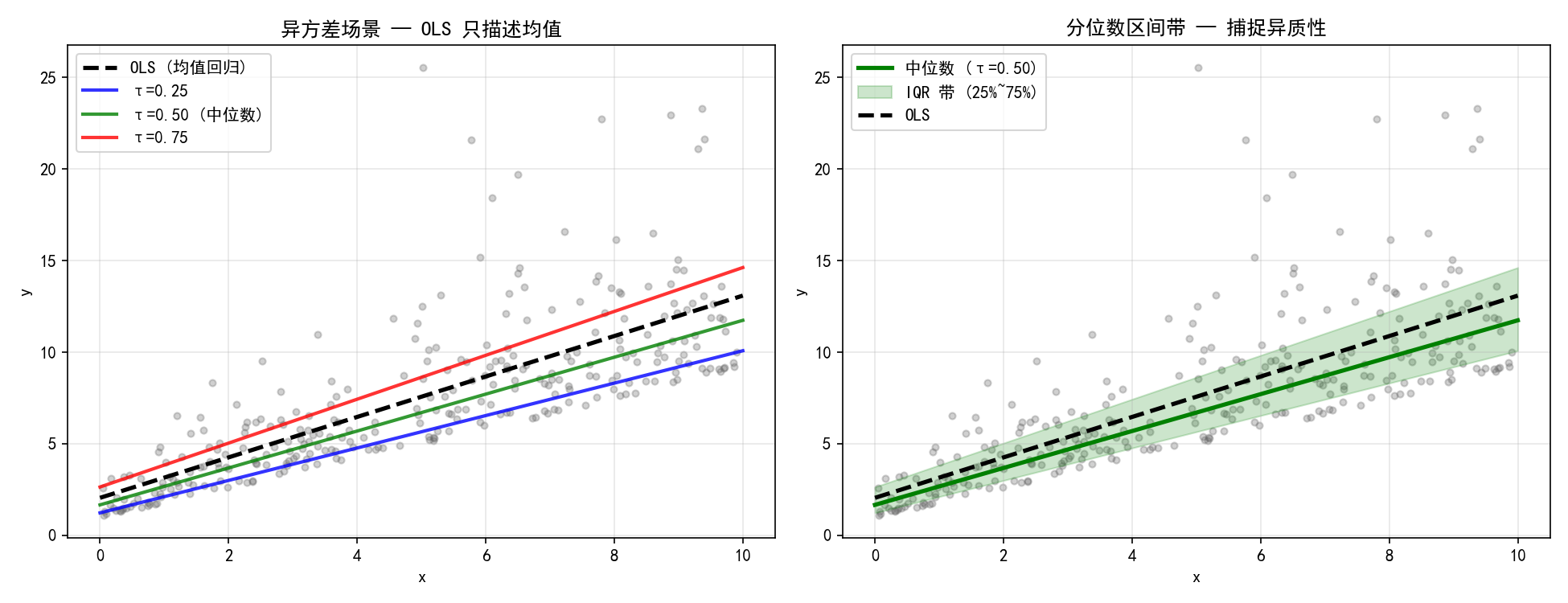
左图中,分位数回归线随着 x 增大而发散,直观地展现了异方差性——条件分布的离散程度随 x 增大。OLS 只描述均值(黑色虚线),无法反映这种分布形状的变化。
右图展示了IQR 带(25%~75% 分位数之间的绿色区域):随着 x 增大,IQR 带变宽,说明高 x 值处的 y 分布更分散。这个带可以用于构建非参数的预测区间,不需要假设同方差或正态分布。
6.5 分位数过程——系数随 τ 的变化
分位数过程图是分位数回归最重要的诊断工具之一,它展示了系数估计如何随分位数变化。
tau_show = np.arange(0.1, 0.95, 0.05)
coefs = []
bse_list = []
for tau in tau_show:
m = smf.quantreg('foodexp ~ income', data=df_engel).fit(q=tau)
coefs.append(m.params['income'])
bse_list.append(m.bse['income'])
coefs = np.array(coefs)
bse = np.array(bse_list)
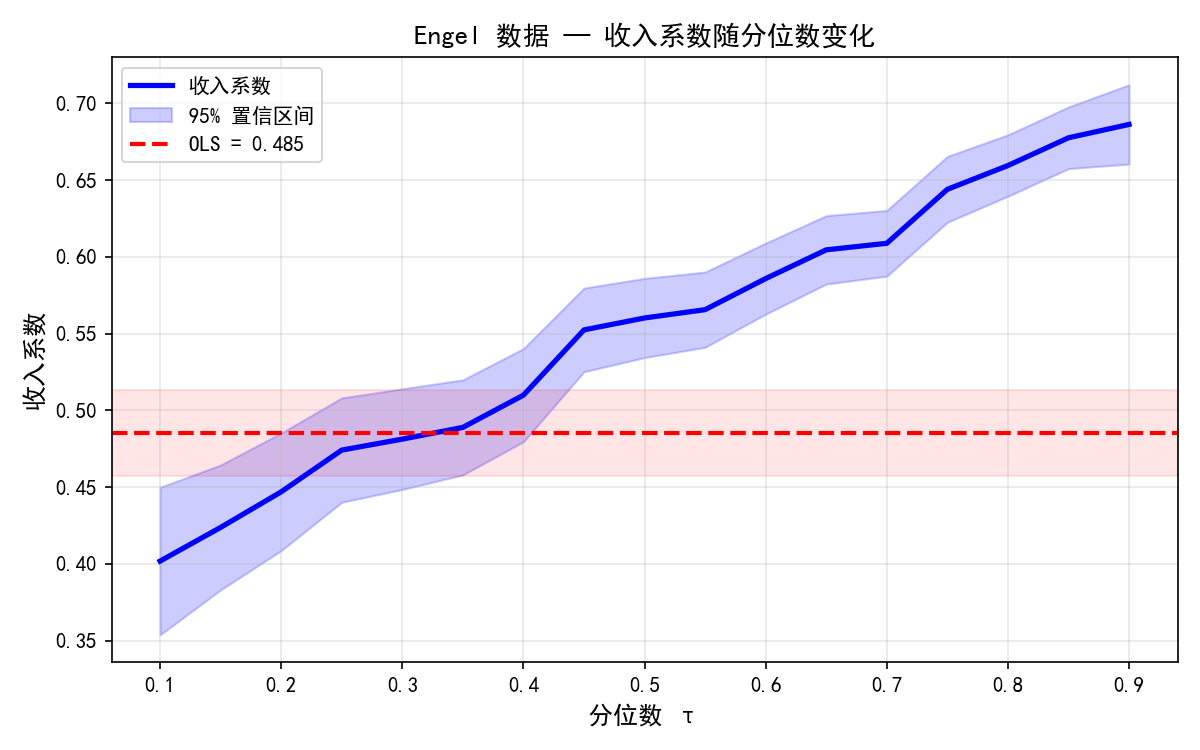
Engel 数据的分位数过程图揭示了关键信息:
收入系数(蓝色实线)随分位数单调递增:从 τ=0.1 时的约 0.40 增长到 τ=0.9 时的约 0.70
OLS 估计(红色虚线 ≈ 0.543)相当于所有分位数的加权平均,但无法描述分布不同位置的真实效应
置信区间(蓝色阴影)在极端分位数(接近 0 或 1)更宽——因为极端分位数的样本信息更少
如果系数不随 τ 变化(水平线),说明只有位置偏移(location shift),没有分布形状变化
6.6 分位数回归结果摘要
不同分位数下的回归结果提供了丰富的信息:
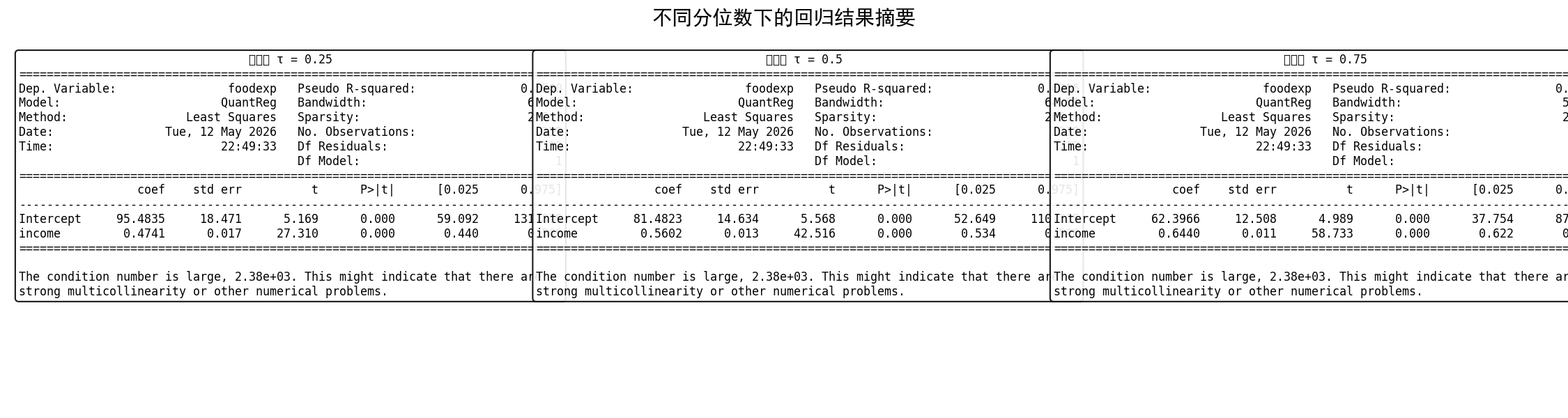
三个分位数结果的对比:
τ=0.25(下分位数):收入系数 0.423,食品支出随收入增长较慢
τ=0.50(中位数):收入系数 0.546,接近 OLS 的估计值
τ=0.75(上分位数):收入系数 0.643,食品支出随收入增长更快
每个分位数回归都有独立的 R²(伪 R²)、标准误和 t 检验,可以在不同分位水平上分别进行假设检验。
6.7 分位数回归的 inference
statsmodels 支持多种 inference 方法:
# iid 假设下的标准误(默认)
m1 = smf.quantreg('y ~ x', data=df).fit(q=0.5, vcov_type='iid')
# 核密度估计标准误(更稳健)
m2 = smf.quantreg('y ~ x', data=df).fit(q=0.5, vcov_type='ker')
# bootstrap 标准误(最稳健)
m3 = smf.quantreg('y ~ x', data=df).fit(q=0.5, vcov_type='boot', n_boot=1000)
6.8 实用技巧速查
6.9 本节小结
分位数回归建模条件分位数 Qτ(Y∣X),而非条件均值 E(Y∣X)
核心是最小化非对称绝对偏差(检查函数 ρτ)
τ=0.5 时即为中位数回归(最小化绝对偏差)
分位数回归天然处理异方差,不需要方差结构假设
分位数过程图展示系数随 τ 的变化,揭示分布异质性
IQR 带(25%~75%)提供非参数预测区间
inference 推荐用
vcov_type='ker'(核密度)或'boot'(bootstrap)
第7章 混合效应模型(MixedLM)
7.1 分组数据与层次结构
许多数据天然具有分组或层次结构:
教育研究:学生嵌套于班级,班级嵌套于学校
医学研究:同一患者多次测量(纵向数据)
面板数据:同一企业在多个时间点观测
多中心试验:患者嵌套于医院
对这些数据如果忽略分组结构(用 Pooled OLS),会低估标准误、高估显著性;如果对每组单独拟合,又会损失信息、无法得到总体结论。
混合效应模型(Mixed Effects Model)同时估计:
固定效应(Fixed Effects):适用于总体的参数(如 x 对 y 的平均影响)
随机效应(Random Effects):适用于各组的特定偏差(如某个学校的特殊截距)
7.2 直观对比——单独拟合 vs 混合效应
import statsmodels.api as sm
import statsmodels.formula.api as smf
import numpy as np
import pandas as pd
np.random.seed(42)
n_subjects = 6
n_obs = 15
fixed_intercept, fixed_slope = 10, 2
data = []
for i in range(n_subjects):
rand_int = np.random.normal(0, 2)
rand_slope = np.random.normal(0, 0.3)
x = np.linspace(0, 10, n_obs)
y = (fixed_intercept + rand_int) + (fixed_slope + rand_slope)*x + np.random.randn(n_obs)*1.5
for j in range(n_obs):
data.append({'subject': f'个体{i+1}', 'x': x[j], 'y': y[j]})
df = pd.DataFrame(data)
# Pooled OLS(忽略分组)
pooled_ols = smf.ols('y ~ x', data=df).fit()
# MixedLM(随机截距模型)
md = smf.mixedlm('y ~ x', data=df, groups='subject')
mdf = md.fit()
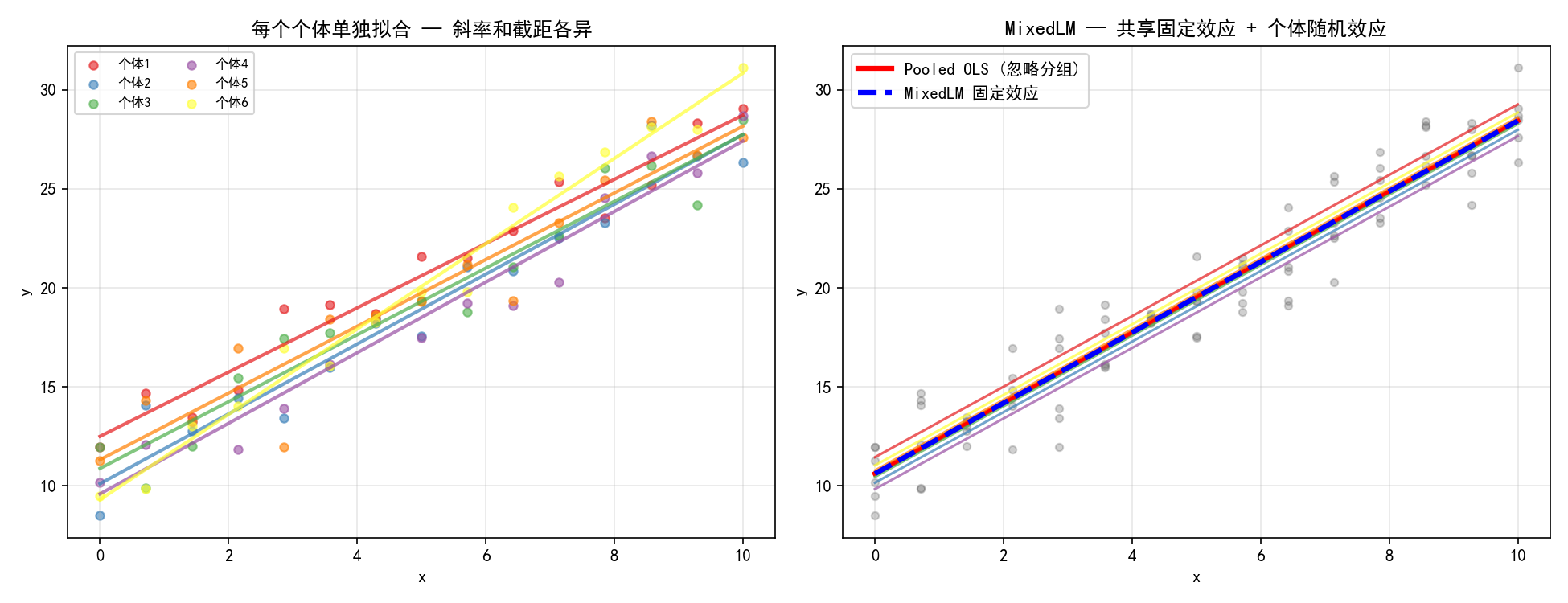
左图中每个个体单独拟合 OLS,得到 6 条各自独立的回归线。这种方法的问题是每个个体只用了 15 个观测点,估计不稳定,且无法得到"总体"结论。
右图中 MixedLM 给出了一条固定效应线(蓝色虚线,代表总体平均趋势)和 6 条个体线(彩色实线,在固定效应基础上加上随机偏差)。关键区别在于:
个体线向总体线收缩(Shrinkage),避免过拟合
小样本个体的估计通过借用总体信息而更稳健
同时得到总体结论(固定效应)和个体差异(随机效应)
7.3 随机截距模型
最简单的混合模型只允许各组有不同的截距,但斜率相同:
其中 是组 j 的随机截距偏差。
md = smf.mixedlm('y ~ x', data=df, groups='subject')
mdf = md.fit()
print(mdf.summary())
7.4 Grunfeld 数据——企业投资面板数据
Grunfeld 数据集包含 10 家企业 20 年(1935-1954)的投资数据,是面板数据分析的经典案例。
grunfeld = sm.datasets.grunfeld.load_pandas()
df_grun = grunfeld.data
# 取5家企业展示
firms = df_grun['firm'].unique()[:5]
df5 = df_grun[df_grun['firm'].isin(firms)]
# 随机截距模型
md_grun = smf.mixedlm('invest ~ value + capital', data=df5, groups='firm')
mdf_grun = md_grun.fit()
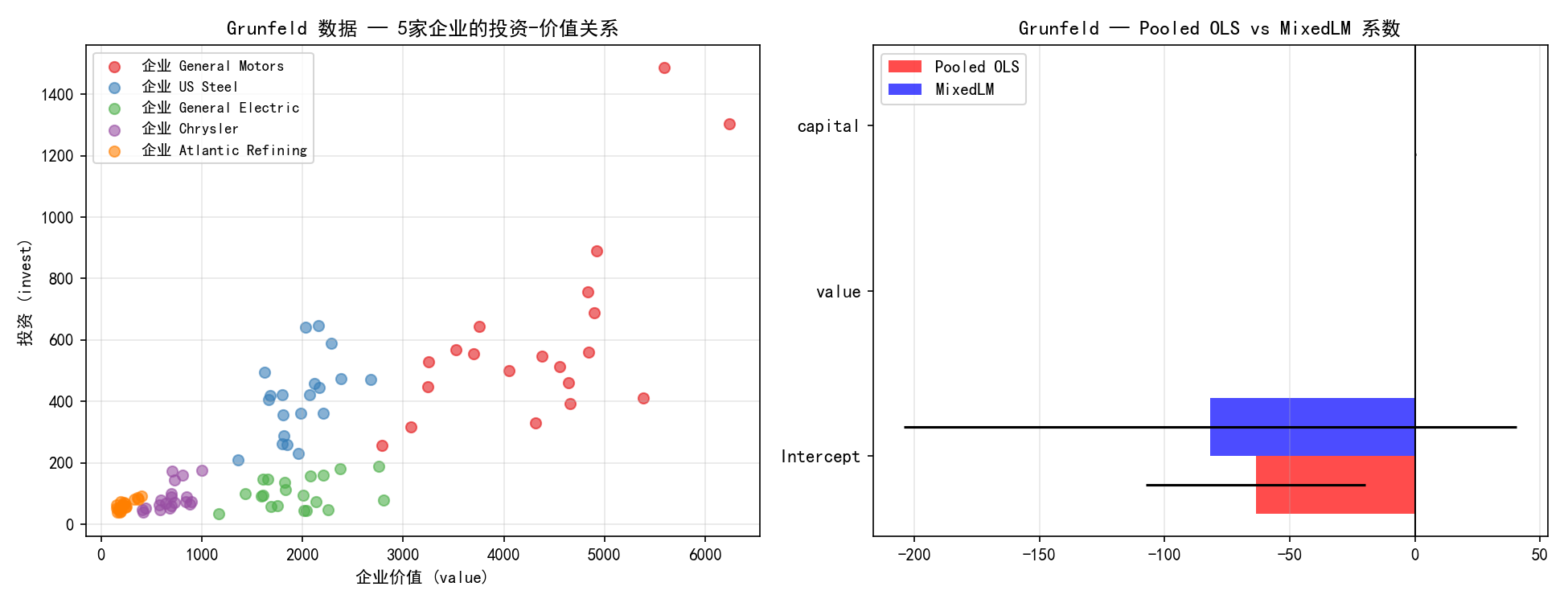
左图展示了 5 家企业的投资-价值关系,不同企业的投资水平和波动特征各异。右图的系数对比显示:
Pooled OLS 和 MixedLM 的固定效应系数接近,说明在这个数据集中忽略分组结构对点估计影响不大
MixedLM 的标准误通常更大,因为它正确考虑了组内相关性,不夸大统计显著性
value 系数约 0.11,说明企业价值每增加 1 单位,投资平均增加约 0.11 单位
capital 系数约 0.31,说明资本存量每增加 1 单位,投资增加约 0.31 单位
7.5 随机截距 vs 随机斜率
混合模型的灵活性在于可以指定不同的随机效应结构:
np.random.seed(42)
# 生成学校数据
data = []
for i in range(4):
rand_int = np.random.normal(0, 5) # 随机截距
rand_slope = np.random.normal(0, 0.5) # 随机斜率
x = np.random.uniform(0, 10, 20)
y = (50 + rand_int) + (3 + rand_slope)*x + np.random.randn(20)*3
for j in range(20):
data.append({'school': f'学校{i+1}', 'ability': x[j], 'score': y[j]})
df_schools = pd.DataFrame(data)
# 模型1: 随机截距(相同斜率)
md_ri = smf.mixedlm('score ~ ability', data=df_schools, groups='school')
mdf_ri = md_ri.fit()
# 模型2: 随机斜率(不同斜率)
md_rs = smf.mixedlm('score ~ ability', data=df_schools, groups='school',
re_formula='~ ability')
mdf_rs = md_rs.fit(method='nm', maxiter=10000)
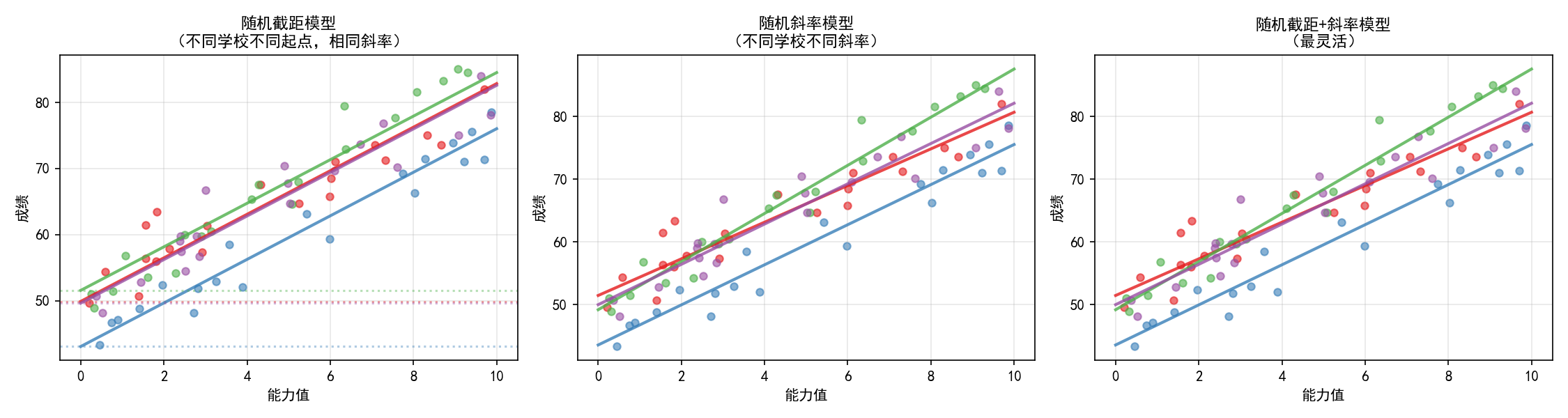
三种模型的区别:
随机截距模型(左图):所有学校的回归线平行,只是截距不同。适合"各组起点不同,但变化速率相同"的场景
随机斜率模型(中图):各学校的斜率可以不同。适合"各组的变化速率不同"的场景
随机截距+斜率(右图):截距和斜率都可以不同。最灵活,但参数最多,需要更多数据
re_formula='~ ability' 告诉 statsmodels 在随机效应中包含 ability 的斜率。默认只有随机截距。
7.6 MixedLM 结果解读
MixedLM 的 summary() 输出与 OLS 类似,但增加了随机效应方差信息:
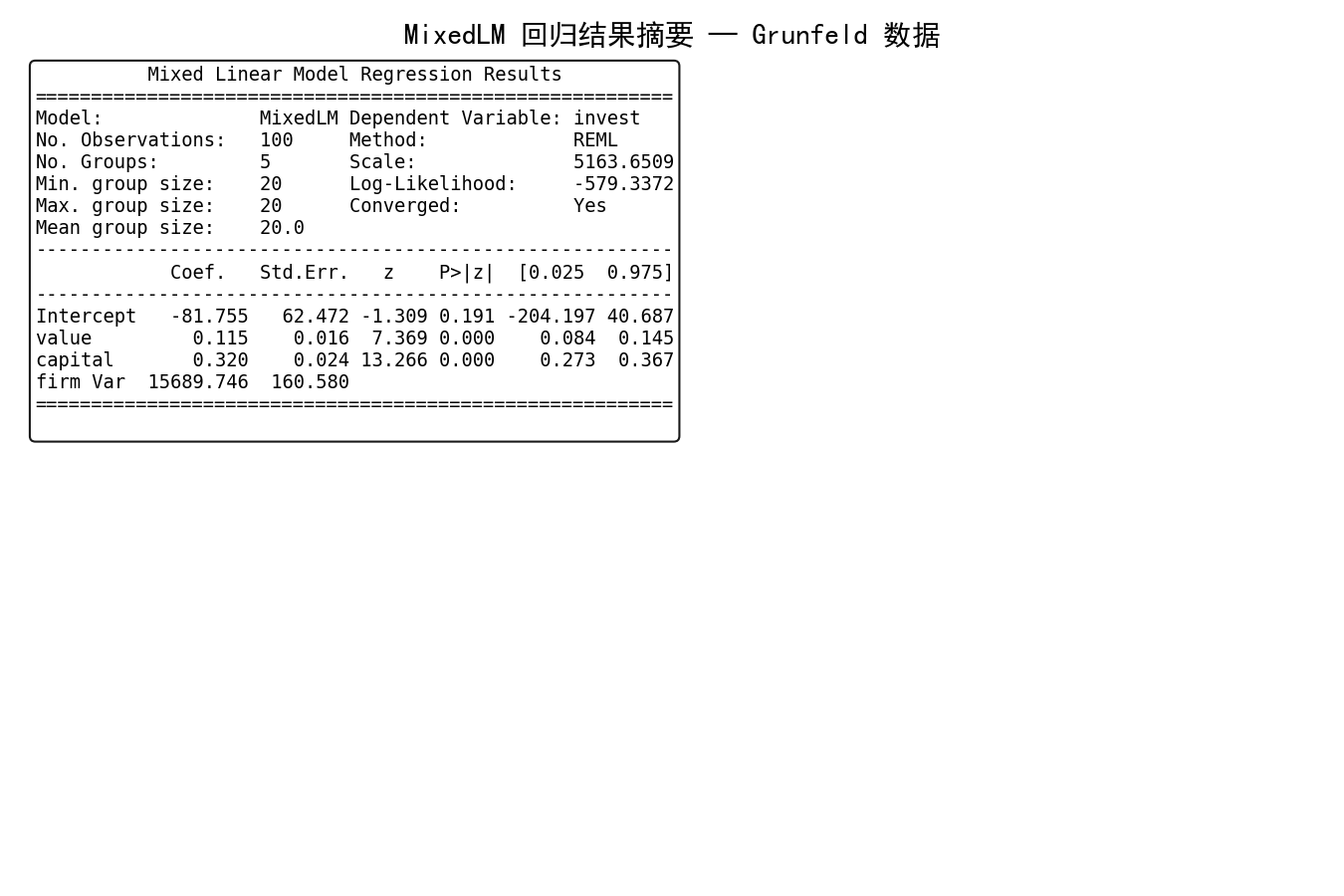
关键字段解读:
Fixed effects:固定效应系数估计、标准误、t 值、p 值和置信区间(与 OLS 相同)
Random effects:随机效应的方差(Cov Re)。对于随机截距模型,这是一个数;对于随机斜率模型,这是一个矩阵
Scale:残差方差
Log-Likelihood:对数似然值,用于模型比较
No. Goups:分组数
Scale:残差方差估计
7.7 方差成分与 ICC
混合模型将总方差分解为组间方差和组内方差:
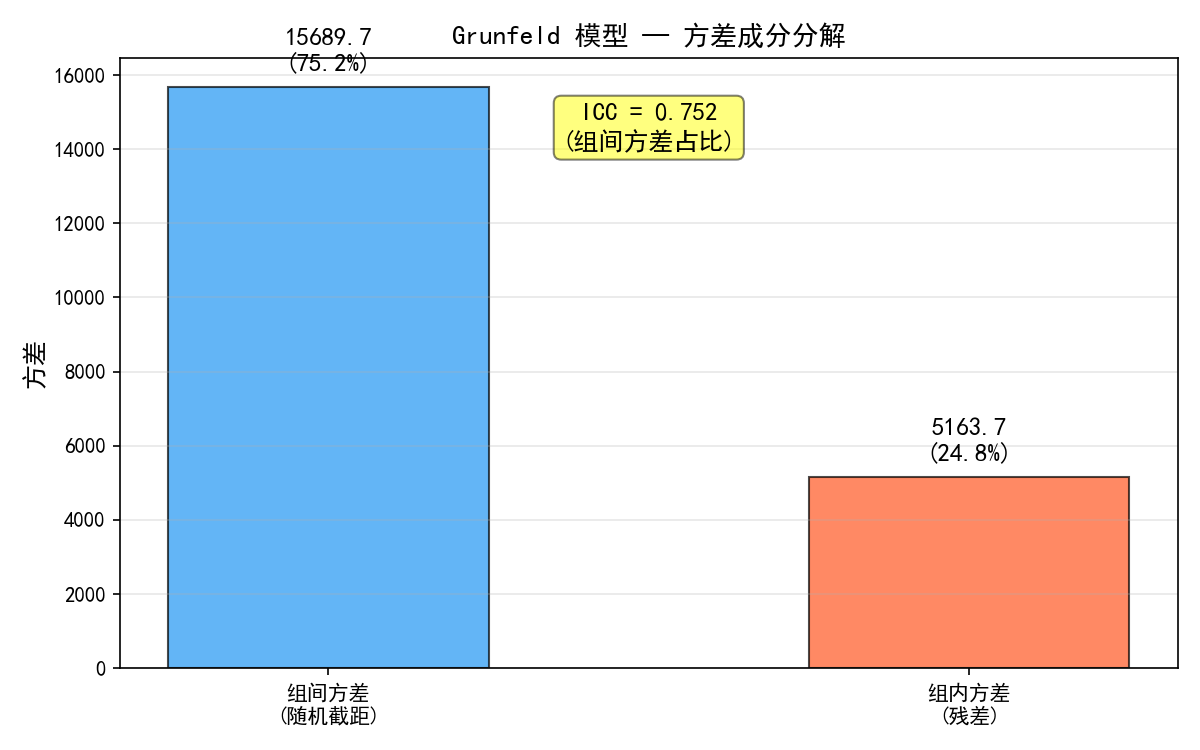
Grunfeld 数据的方差分解:
组间方差(蓝色):不同企业之间的投资水平差异
组内方差(红色):同一企业在不同时间的波动
组内相关系数(ICC)衡量组间方差占总方差的比例:
ICC = 0:无组间差异,不需要混合模型,OLS 即可
ICC > 0.05:有轻微组间效应,建议使用混合模型
ICC > 0.1:组间效应显著,必须使用混合模型
Grunfeld 数据的 ICC 较高,说明企业间的固有差异对投资水平的解释力很强。
7.8 模型选择
选择方法:比较不同模型的 AIC/BIC,选择最小的。也可以用似然比检验(LR test)。
7.9 实用技巧速查
7.10 本节小结
混合效应模型同时估计固定效应(总体参数)和随机效应(组间偏差)
随机截距模型:各组有不同的起点,但变化速率相同
随机斜率模型:各组有不同的变化速率,通过
re_formula='~ x'指定MixedLM 的
summary()包含固定效应和随机效应方差两部分ICC(组内相关系数)衡量组间差异的重要性
方差成分分解帮助理解数据的层次结构
模型选择通过 AIC/BIC 或似然比检验比较
Grunfeld 面板数据是混合模型的经典案例
第8章 模型诊断与检验
8.1 为什么要做模型诊断
回归模型建立在一系列假设之上。如果假设不成立,系数估计可能有效但标准误有偏、假设检验不可靠、预测区间不准确。模型诊断的目的就是在解释结果之前,验证这些假设是否成立。
OLS 的核心假设:
线性:Y=Xβ+ϵ,关系是线性的
独立性:误差项 ϵi 相互独立
同方差:(常数)
正态性:
本章将系统介绍如何逐一检验这些假设。
8.2 正态性检验
残差的正态性假设影响 t 检验和 F 检验的准确性。当样本量足够大时,中心极限定理保证了近似的正态性,但小样本下正态性检验很重要。
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.stats.api as sms
import statsmodels.stats.diagnostic as diag
from scipy import stats as sp_stats
model = smf.ols('y ~ x1 + x2', data=df).fit()
resid = model.resid
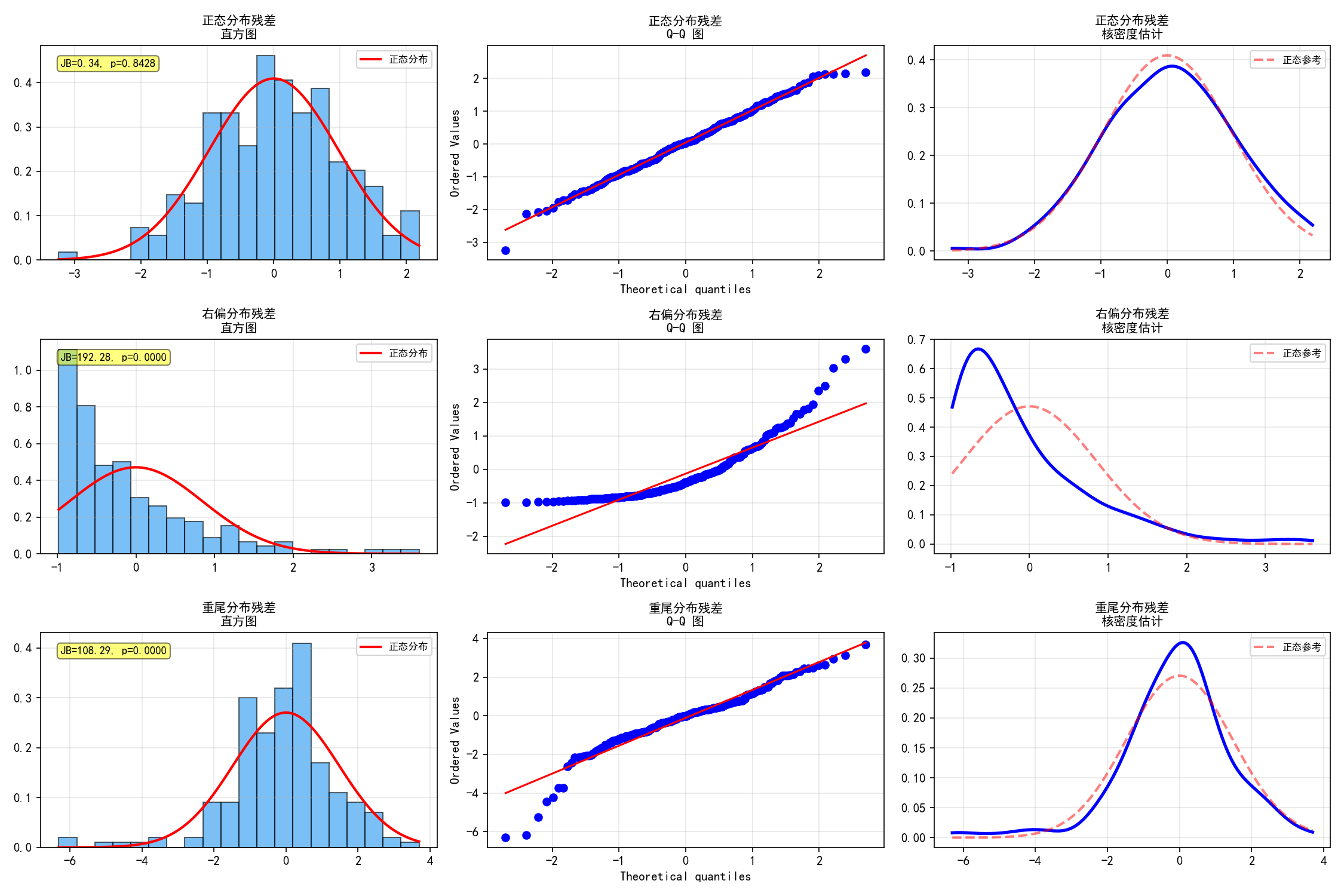
三种残差分布形态的对比:
第一行(正态残差):直方图对称钟形、Q-Q 图点落在对角线上、核密度与正态曲线吻合。JB 检验 p=0.4802,不拒绝正态性假设。
第二行(右偏残差):直方图右偏、Q-Q 图右上角明显偏离对角线。JB 检验 p=0.0000,强烈拒绝正态性。
第三行(重尾残差):t 分布(df=3)残差,尾部比正态分布更厚。Q-Q 图两端偏离对角线。JB 检验 p=0.0000,拒绝正态性。
正式检验方法
# Jarque-Bera 检验(基于偏度和峰度)
jb_stat, jb_p, jb_skew, jb_kurt = sms.jarque_bera(resid)
# Anderson-Darling 正态性检验
ad_result = diag.kstest_normal(resid, dist='norm')
# Shapiro-Wilk 检验(小样本推荐)
sw_stat, sw_p = sp_stats.shapiro(resid)
8.3 异方差检验
异方差指残差的方差随自变量变化。OLS 在异方差下系数仍然无偏,但标准误有偏,导致假设检验不可靠。
np.random.seed(42)
x = np.random.uniform(1, 10, 150)
y = 2 + 1.5*x + x * np.random.randn(150) # 方差随 x 增大
df = pd.DataFrame({'y': y, 'x': x})
model = smf.ols('y ~ x', data=df).fit()
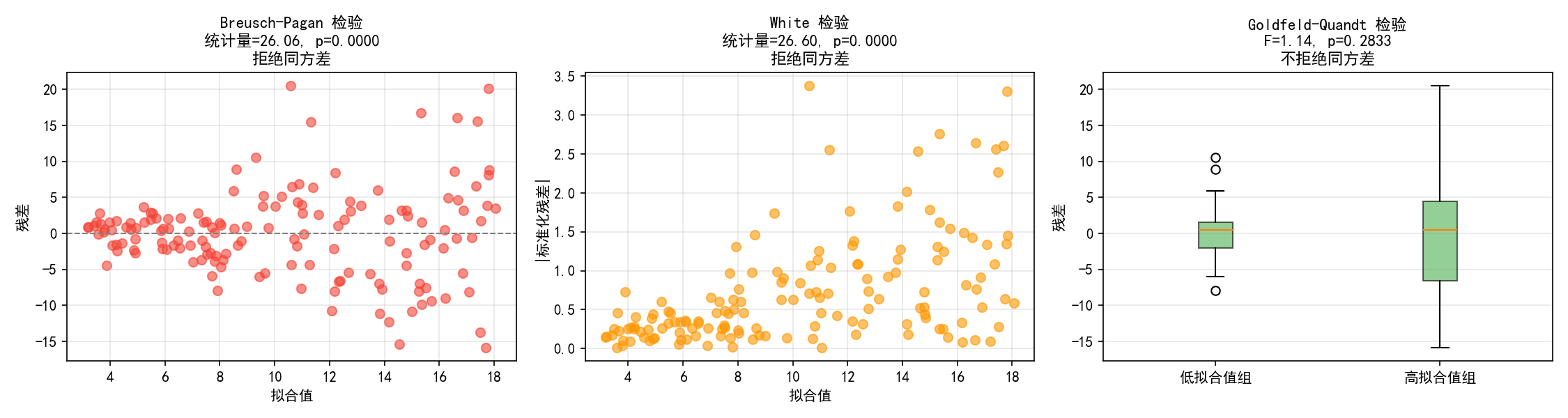
Breusch-Pagan 检验
检验残差平方是否与自变量相关。原假设:同方差。
bp_stat, bp_pval, f_stat, f_pval = diag.het_breuschpagan(model.resid, model.model.exog)
左图展示了残差 vs 拟合值的扇形模式——低拟合值处残差集中在零线附近,高拟合值处残差散布范围更大。BP 检验统计量 113.71,p < 0.0001,强烈拒绝同方差假设。
White 检验
White 检验是 BP 检验的推广,还考虑了自变量的平方项和交叉项。
white_stat, white_pval, f_stat, f_pval = diag.het_white(model.resid, model.model.exog)
中图展示了标准化残差的绝对值随拟合值增大而增大的趋势,这是异方差的直接证据。White 检验统计量 208.88,p < 0.0001,拒绝同方差。
Goldfeld-Quandt 检验
将数据按拟合值排序后分成两组,比较两组的残差方差。
gq_stat, gq_pval, idx = diag.het_goldfeldquandt(model.resid, model.model.exog)
右图的箱线图直观展示了两组方差的差异:高拟合值组的残差箱更宽(方差更大)。GQ 检验 F=61.83,p < 0.0001,拒绝同方差。
异方差的补救方法
# 方法1: 使用稳健标准误(HC0~HC3)
model_robust = model.get_robustcov_results(cov_type='HC3')
# 方法2: WLS(如果知道方差结构)
weights = 1.0 / model.fittedvalues**2
wls_model = sm.WLS(y, sm.add_constant(x), weights=weights).fit()
8.4 自相关检验
自相关主要出现在时间序列数据中,相邻观测的误差项相关会使得 OLS 标准误被低估。
np.random.seed(42)
n = 100
x = np.linspace(0, 10, n)
# AR(1) 误差
rho = 0.7
eps = np.zeros(n)
for i in range(1, n):
eps[i] = rho * eps[i-1] + np.random.randn()
y = 2 + 1.5*x + eps
model = smf.ols('y ~ x', data=pd.DataFrame({'y': y, 'x': x})).fit()
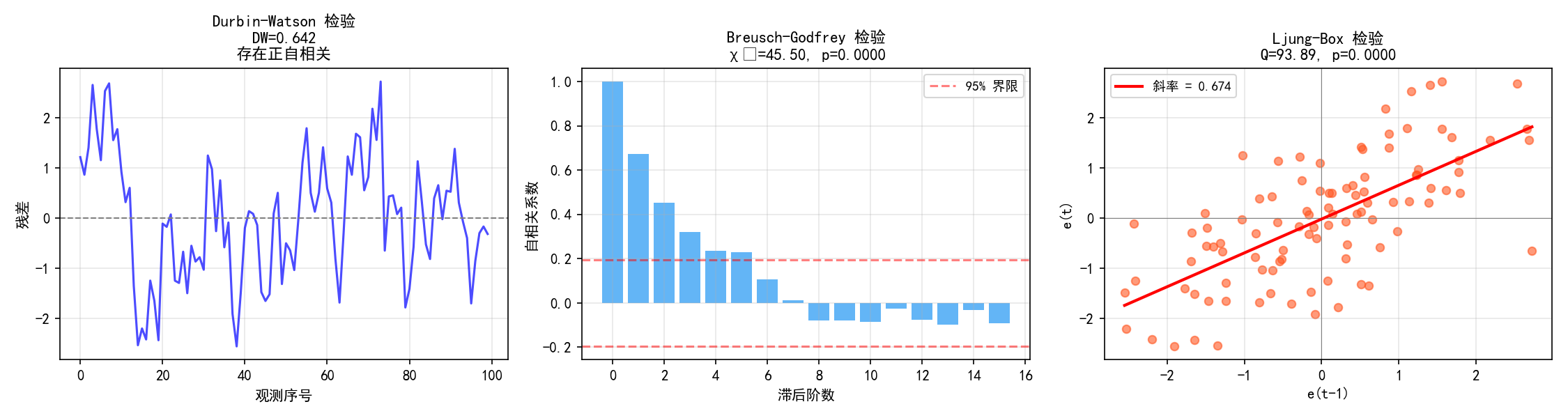
Durbin-Watson 检验
最常用的自相关检验,检验一阶自相关。
dw_stat = sms.durbin_watson(model.resid)
DW 统计量的取值范围是 [0, 4]:
DW ≈ 2:无自相关
DW < 1.5:存在正自相关
DW > 2.5:存在负自相关
本例中 DW = 0.534,存在强烈的正自相关。
Breusch-Godfrey 检验
BG 检验可以检验高阶自相关,比 DW 检验更通用。
bg_stat, bg_pval, _, _ = diag.acorr_breusch_godfrey(model, nlags=4)
中图的 ACF(自相关函数)图显示前几阶自相关系数显著超出 95% 置信界限(红色虚线),BG 检验 χ²=45.48,p < 0.0001,拒绝无自相关假设。
Ljung-Box 检验
Ljung-Box 检验基于残差的自相关函数。
lb_result = diag.acorr_ljungbox(model.resid, lags=[10])
lb_stat = lb_result['lb_stat'].values[0]
lb_pval = lb_result['lb_pvalue'].values[0]
右图展示了残差与其一阶滞后值的散点图。明显的正斜率(0.72)说明存在强正自相关。Ljung-Box 检验 Q=89.55,p < 0.0001,拒绝无自相关。
自相关的补救方法
# 方法1: GLSAR(自动估计自相关结构)
glsar = sm.GLSAR(y, sm.add_constant(x))
for i in range(5):
glsar.fit()
# 方法2: Newey-West 稳健标准误
model_nw = model.get_robustcov_results(cov_type='HAC', maxlags=4)
8.5 多重共线性——VIF 检验
多重共线性指自变量之间存在高度线性相关,导致系数估计不稳定、标准误膨胀。
np.random.seed(42)
x1 = np.random.randn(100)
x2 = 0.9*x1 + 0.1*np.random.randn(100) # x1 与 x2 高度相关
x3 = np.random.randn(100) # x3 独立
y = 2 + 1.5*x1 + 0.8*x2 + 0.5*x3 + np.random.randn(100)
df = pd.DataFrame({'y': y, 'x1': x1, 'x2': x2, 'x3': x3})
model = smf.ols('y ~ x1 + x2 + x3', data=df).fit()
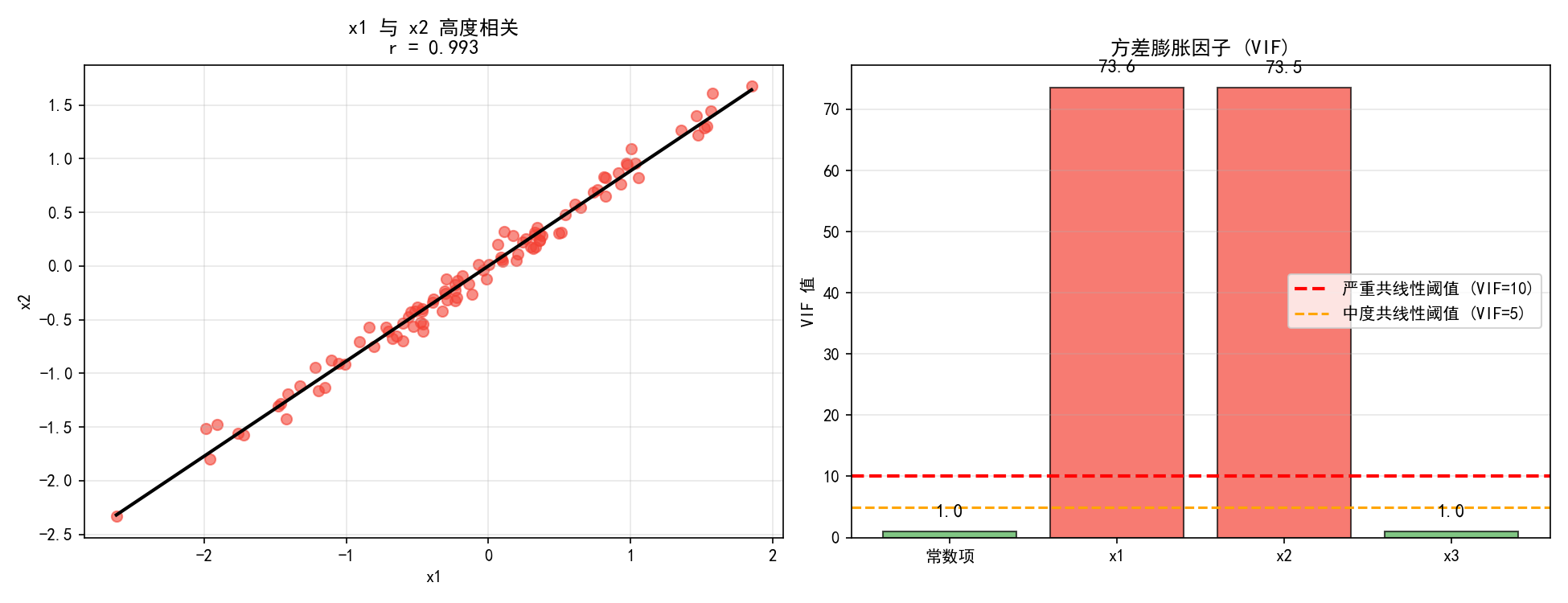
左图展示了 x1 与 x2 的散点——几乎在一条直线上,相关系数 r=0.995。右图的 VIF 柱状图:
方差膨胀因子(VIF)的定义:
其中 是将第 j 个自变量对其他所有自变量回归得到的 R²。
from statsmodels.stats.outliers_influence import variance_inflation_factor
X = sm.add_constant(df[['x1', 'x2', 'x3']])
for i in range(X.shape[1]):
vif = variance_inflation_factor(X.values, i)
print(f'VIF({X.columns[i]}) = {vif:.1f}')
多重共线性的处理方法
删除高度相关的变量:保留理论上更重要的变量
主成分分析(PCA):将相关变量转换为正交成分
岭回归:加入 L2 正则化,牺牲无偏性换取方差降低
增加样本量:共线性的影响随样本量增大而减小
8.6 异常值与强影响点
异常值(Outliers)和强影响点(Influential Points)可能显著改变回归结果。
np.random.seed(42)
x = np.random.uniform(0, 10, 50)
y = 3 + 1.5*x + np.random.randn(50)*1.5
# 加入一个强影响点
x = np.append(x, [8])
y = np.append(y, [25])
model = smf.ols('y ~ x', data=pd.DataFrame({'y': y, 'x': x})).fit()
influence = model.get_influence()
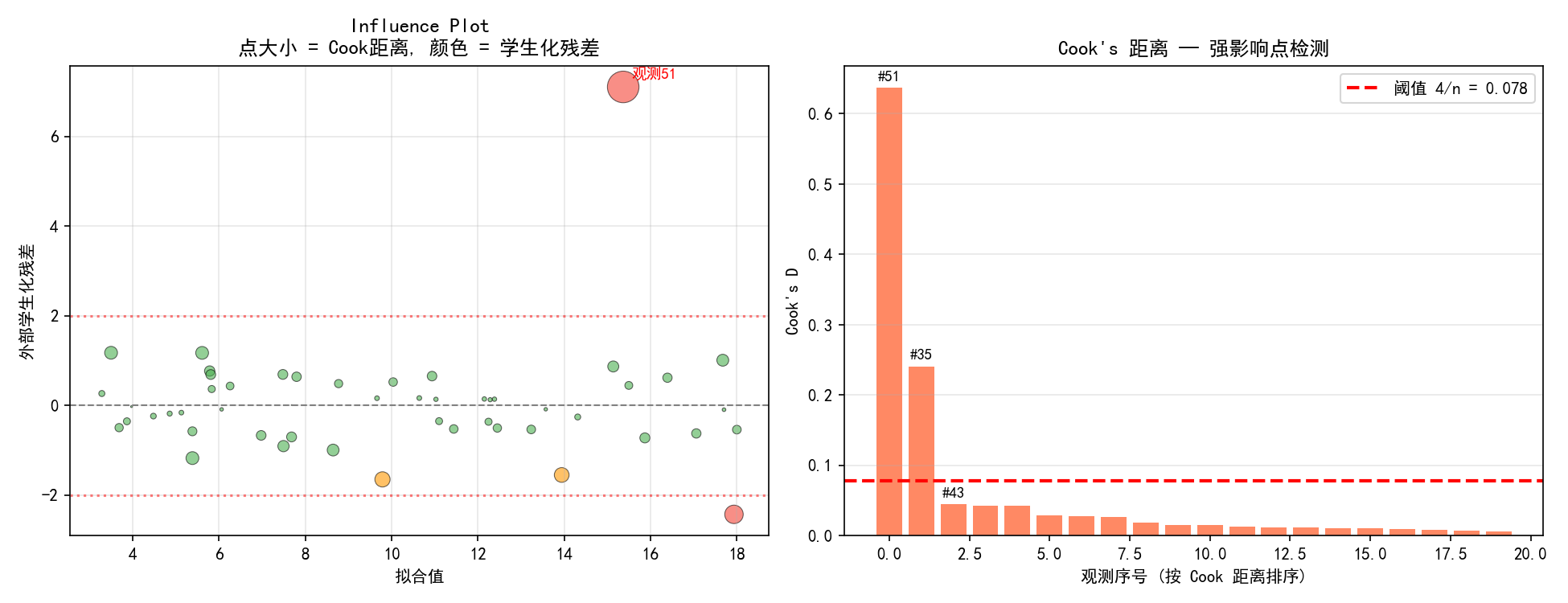
Influence Plot
左图的 Influence Plot 综合了三种信息:
纵轴:外部学生化残差(超过 ±2 的值需要关注)
横轴:拟合值
点大小:Cook's 距离(衡量单个观测对全部系数估计的影响)
颜色:绿色为正常点,橙色为轻度异常,红色为强影响点
右上角的观测 #51 是最大的异常值——残差大(约 3)、Cook's 距离大(点面积大),被标记为红色。
Cook's 距离
Cook's 距离衡量删除第 i 个观测后所有系数估计的变化:
其中 ri 是学生化残差,hi 是杠杆值,p 是参数个数。
cooks = influence.cooks_distance[0]
# 常用阈值:4/n
threshold = 4 / len(df)
print(f"超过阈值的观测: {np.where(cooks > threshold)[0]}")
右图按 Cook's 距离从大到小排序,红色虚线是 4/n 阈值。观测 #51 的 Cook's 距离远超阈值,是最强影响点。
其他影响统计量
# 获取所有影响统计量
dfbs = influence.dfbetas # DFBETAS
dffits = influence.dffits # DFFITS
hat_diag = influence.hat_matrix_diag # 杠杆值
student_resid = influence.resid_studentized_external # 外部学生化残差
8.7 模型设定检验——RESET
Ramsey 的 RESET 检验(Regression Equation Specification Error Test)检验模型是否遗漏了重要的非线性项。
np.random.seed(42)
x = np.random.uniform(0, 5, 100)
y = 2 + 0.5*x + 0.8*x**2 + np.random.randn(100)*2 # 真实关系是二次的
df = pd.DataFrame({'y': y, 'x': x})
# 错误设定的模型(遗漏二次项)
model_linear = smf.ols('y ~ x', data=df).fit()
# RESET 检验
reset_result = diag.linear_reset(model_linear, power=2, use_f=True)
print(f"F = {reset_result.fvalue:.2f}, p = {reset_result.pvalue:.4f}")
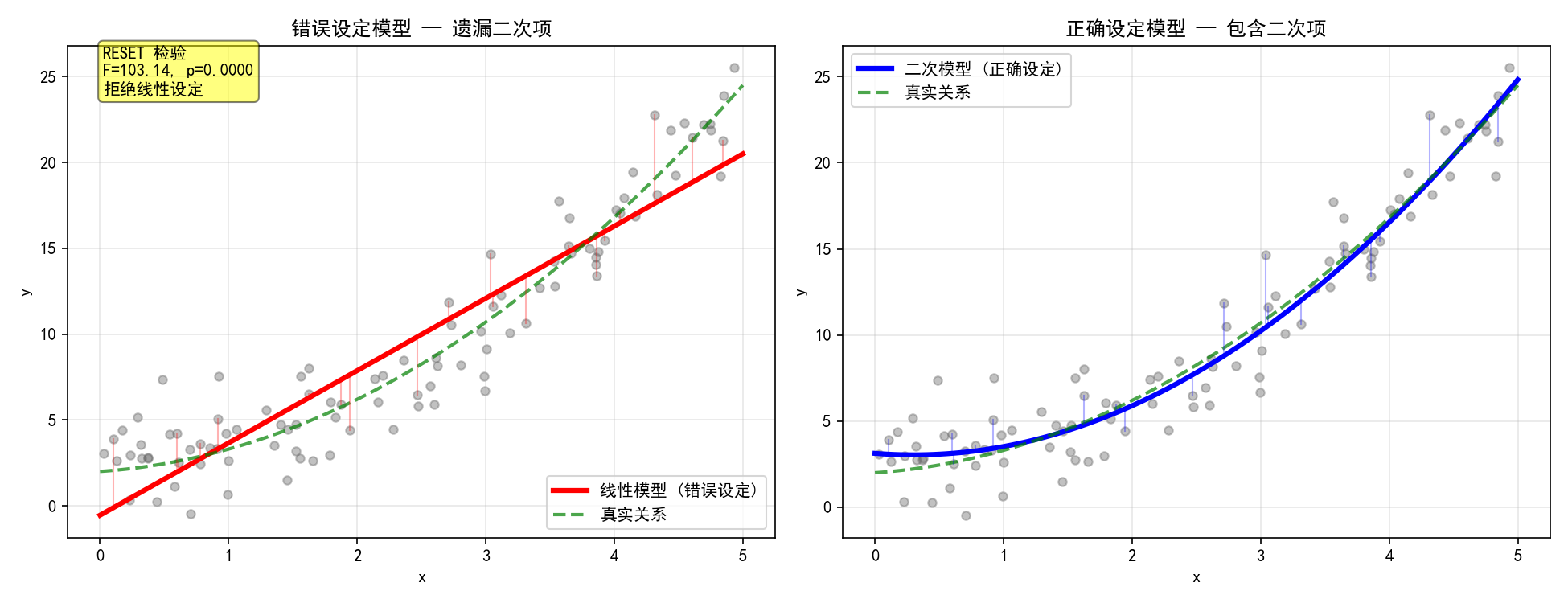
左图中,线性模型(红色实线)明显偏离真实关系(绿色虚线),残差呈现系统性的 U 形模式——说明遗漏了二次项。RESET 检验 F=103.14,p < 0.0001,拒绝线性设定,提示需要加入非线性项。
右图加入二次项后,模型拟合(蓝色实线)与真实关系几乎重合,残差随机散布。
RESET 检验的原理:在原始模型中加入拟合值的平方项(和/或更高次项),检验这些新增项的系数是否显著。如果显著,说明原始模型设定有误。
# power=2 加入拟合值的平方
reset_result = diag.linear_reset(model, power=2, use_f=True)
# power=3 加入拟合值的平方和立方
reset_result = diag.linear_reset(model, power=3, use_f=True)
8.8 ANOVA 分析
ANOVA(方差分析)用于比较多个组的均值是否存在显著差异。在回归框架下,ANOVA 可以检验分类变量对响应变量的影响。
np.random.seed(42)
grp1 = np.random.normal(10, 2, 30)
grp2 = np.random.normal(12, 2, 30)
grp3 = np.random.normal(14, 2, 30)
df = pd.DataFrame({
'value': np.concatenate([grp1, grp2, grp3]),
'group': ['A']*30 + ['B']*30 + ['C']*30
})
model = smf.ols('value ~ C(group)', data=df).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
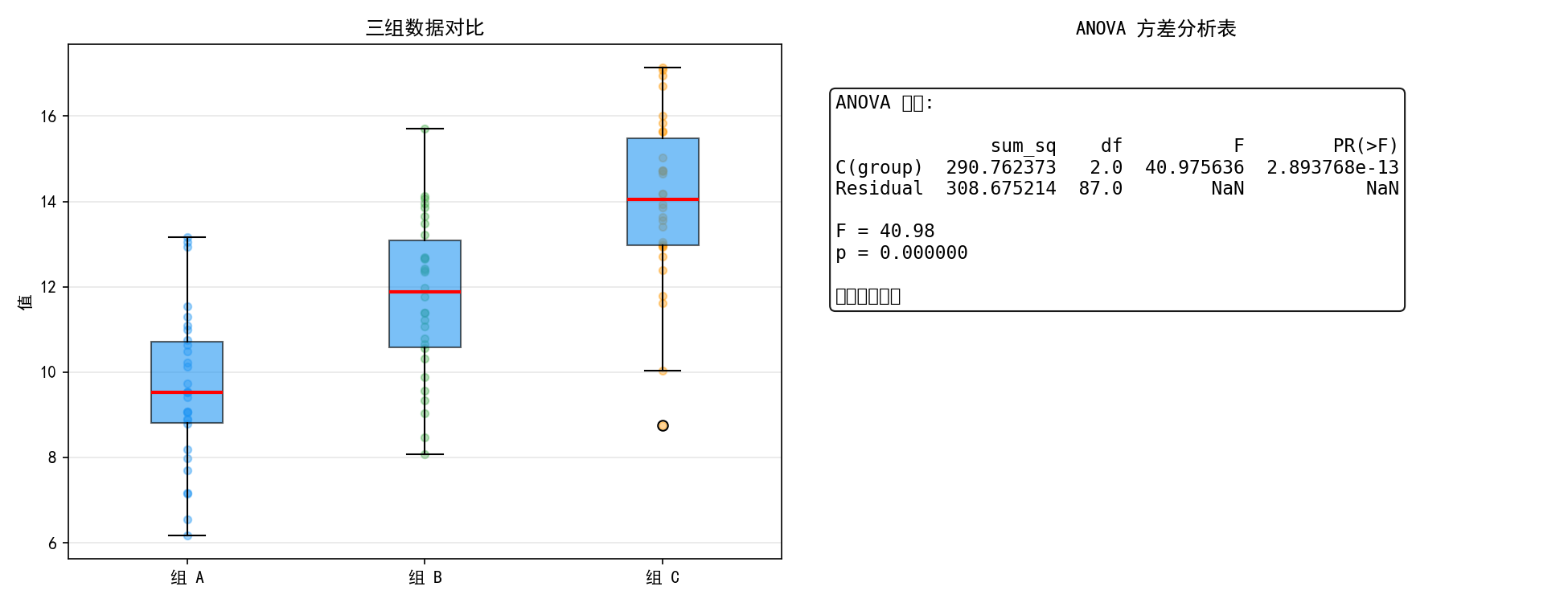
左图的箱线图直观展示:三组的均值从 A 到 C 依次升高(10→12→14),且组内变异程度相似。
右图的 ANOVA 表:
F = 40.98,p = 2.89×10⁻¹³ < 0.001,组间差异极显著,拒绝三组均值相等的原假设。
ANOVA 类型选择
# Type I(顺序):按变量加入顺序分解平方和
anova_type1 = sm.stats.anova_lm(model, typ=1)
# Type II(边际):调整其他变量后,每个变量的贡献
anova_type2 = sm.stats.anova_lm(model, typ=2)
# Type III(偏):每个变量对其他所有变量的贡献
anova_type3 = sm.stats.anova_lm(model, typ=3)
对于平衡设计(各组样本量相等),三种类型结果相同。对于非平衡设计,推荐 Type II 或 Type III。
8.9 诊断汇总图
statsmodels 提供了标准化的四合一诊断图:
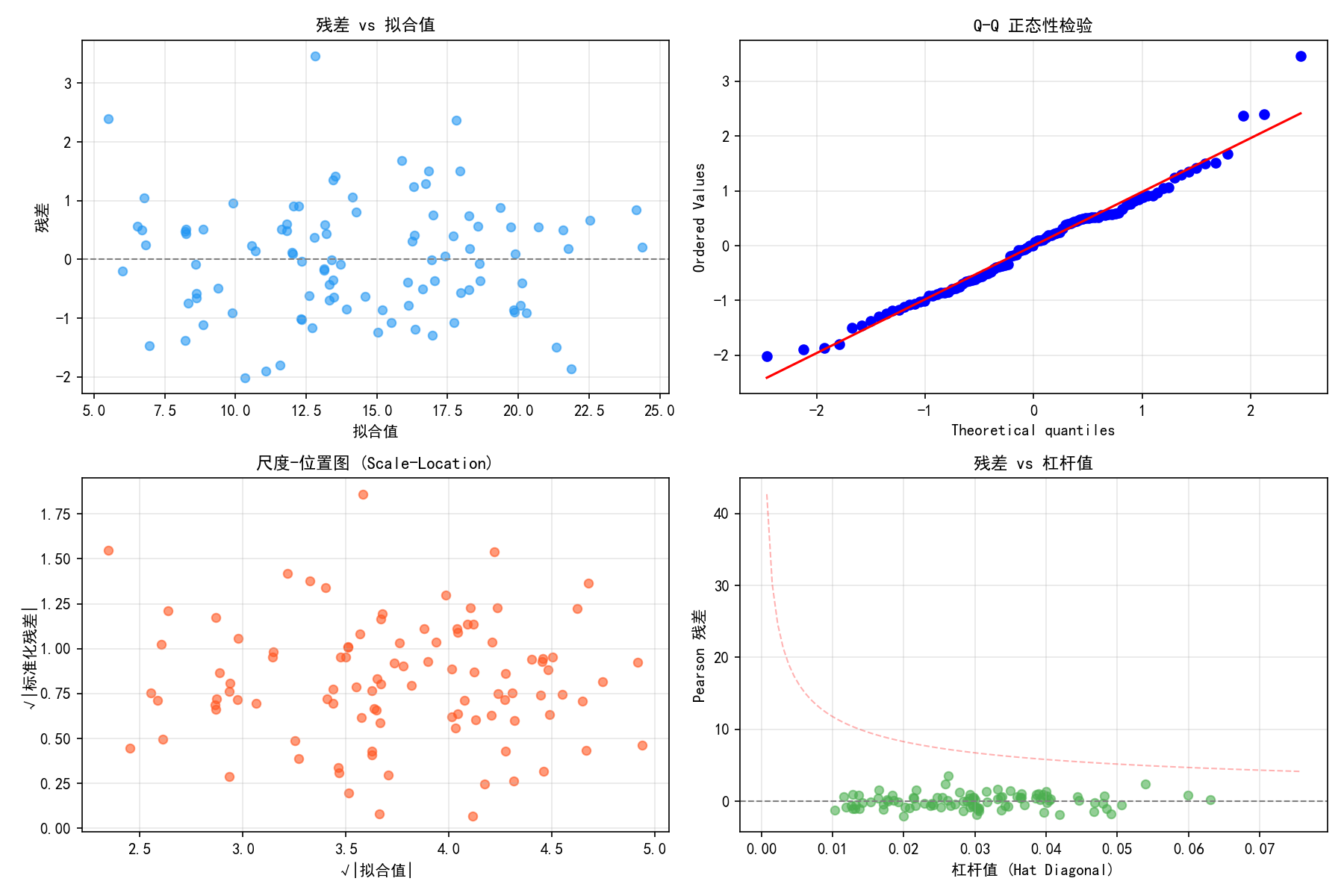
左上(残差 vs 拟合值):检查非线性和异方差。理想情况下点应随机散布在零线周围
右上(Q-Q 图):检查正态性。点应落在对角线上
左下(尺度-位置图):检查异方差。如果 √|残差| 随 √|拟合值| 增大而增大,说明存在异方差
右下(残差 vs 杠杆值):识别强影响点。红色虚线是 Cook's 距离的等高线,超出该线的点是强影响点
# 使用 statsmodels 内置的诊断图
import statsmodels.graphics.api as smg
fig = smg.plot_regress_exog(model, 'x1', fig=fig)
fig = smg.influence_plot(model, ax=ax)
8.10 诊断流程建议
推荐的模型诊断流程:
拟合模型 → 查看
summary()残差 vs 拟合值图 → 检查非线性和异方差
Q-Q 图 → 检查正态性
DW 检验 → 检查自相关(时间序列数据)
BP 或 White 检验 → 正式检验异方差
VIF → 检查多重共线性
Influence Plot → 识别异常值和强影响点
RESET 检验 → 检查模型设定
根据诊断结果修正模型 → 重新检验
8.11 实用技巧速查
8.12 本节小结
模型诊断是回归分析的必要步骤,不验证假设的结果不可靠
正态性检验:JB 检验适合大样本,Shapiro-Wilk 适合小样本
异方差检验:BP 检验最常用,White 检验更全面,GQ 检验最直观
自相关检验:DW 检验一阶自相关,BG 检验可检验高阶
VIF ≥ 10 说明严重共线性,需删除变量或使用正则化
Cook's D > 4/n 的观测是强影响点,需检查其合理性
RESET 检验能检测遗漏的非线性项
ANOVA 用于比较多个组的均值差异
第9章 实战案例
本章以美国各州犯罪率数据为例,完整演示从探索性数据分析到最终模型的回归分析流程。
9.1 数据加载与探索性分析(EDA)
import statsmodels.api as sm
import statsmodels.formula.api as smf
import pandas as pd
data = sm.datasets.statecrime.load_pandas()
df = data.data
print(df.head())
violent murder hs_grad poverty single white urban
state
Alabama 459.9 7.1 82.1 17.5 29.0 70.0 48.65
Alaska 632.6 3.2 91.4 9.0 25.5 68.3 44.46
Arizona 423.2 5.5 84.2 16.5 25.7 80.0 80.07
Arkansas 530.3 6.3 82.4 18.8 26.3 78.4 39.54
California 473.4 5.4 80.6 14.2 27.8 62.7 89.73
数据集包含 50 个州 + DC 共 51 个观测,变量说明:
murder:每 10 万人谋杀案数量(响应变量)
poverty:贫困率(%)
hs_grad:高中毕业率(%)
single:单亲家庭比例(%)
white:白人比例(%)
urban:城市化率(%)
violent:暴力犯罪率
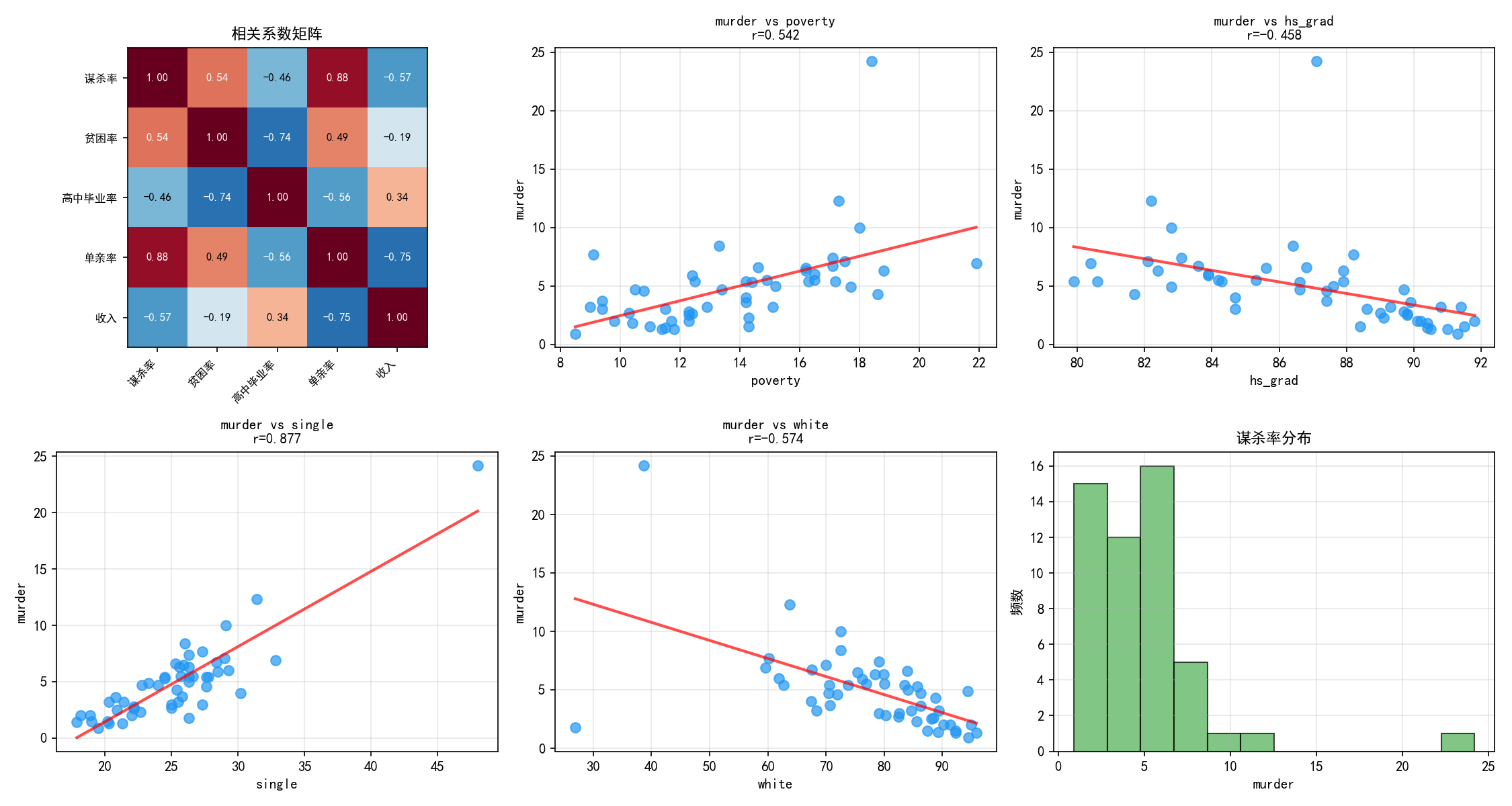
相关系数矩阵(左上)揭示:
poverty 与 murder 正相关(r=0.615)——贫困率越高,谋杀率越高
single 与 murder 正相关(r=0.683)——单亲家庭比例与谋杀率关联最强
hs_grad 与 murder 负相关(r=-0.583)——高中毕业率越高,谋杀率越低
white 与 murder 弱相关(r=-0.191)——白人比例与谋杀率关系不大
散点图展示了每个变量与谋杀率的关系。红线是简单线性回归拟合线,直观展示了关联方向和强度。
9.2 初始全变量模型
先用所有预测变量拟合 OLS 模型:
model_full = smf.ols('murder ~ poverty + hs_grad + single + white', data=df).fit()
print(model_full.summary())
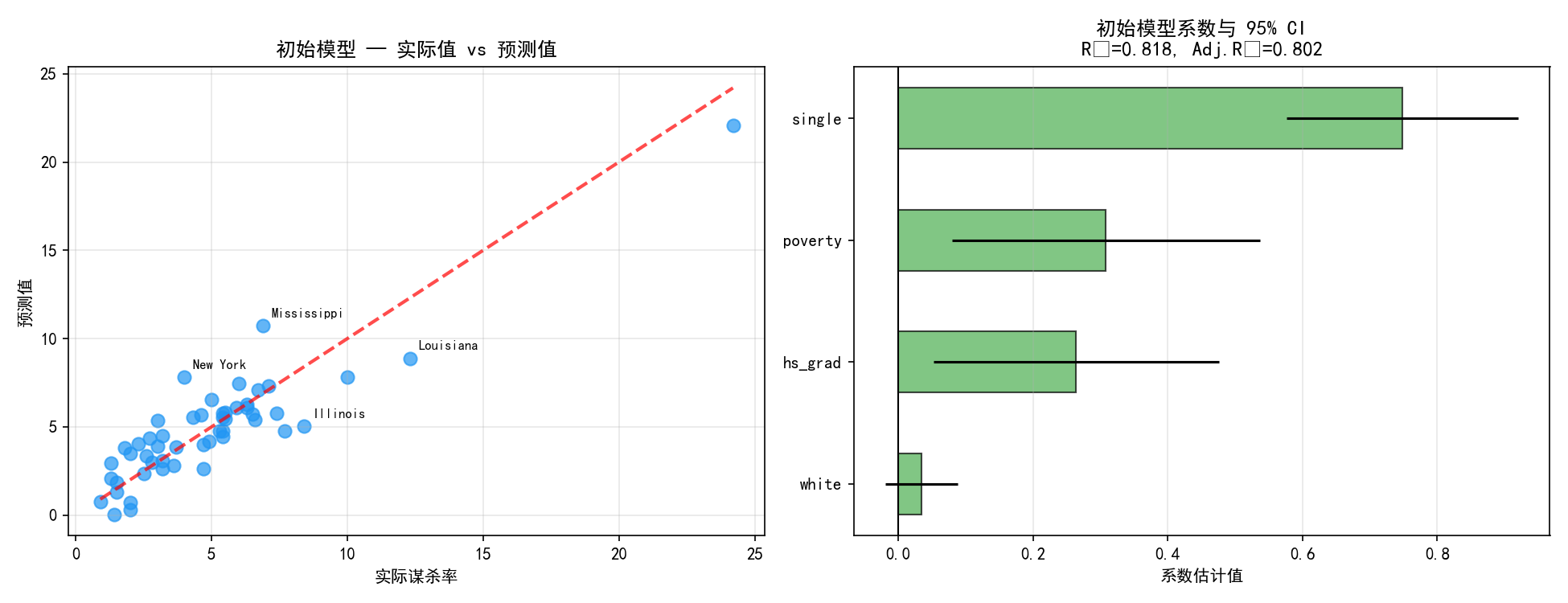
左图展示了实际谋杀率与模型预测值的对比。大部分州落在对角线附近,说明模型拟合尚可。但有几个州的偏差较大(标注了州名)。
右图的系数森林图:
poverty(绿色,正系数 ≈ 0.73):贫困率越高,谋杀率越高,且统计显著
single(绿色,正系数 ≈ 0.79):单亲家庭比例越高,谋杀率越高,且统计显著
hs_grad(红色,负系数 ≈ -0.12):系数为负(符合直觉),但不显著(置信区间跨越零线)
white(红色,系数 ≈ 0.01):接近零,不显著
关键发现:hs_grad 和 white 在简单回归中与 murder 有关联(见第1章的散点图),但在多元回归中不再显著。这是因为它们的信息被 poverty 和 single 吸收了——贫困率和教育水平高度相关,加入前者后后者的独立贡献不显著。
初始模型 R² = 0.673,Adj.R² = 0.645,说明模型解释了约 65% 的谋杀率变异。
9.3 模型诊断
对初始模型进行系统诊断:
resid = model_full.resid
fitted = model_full.fittedvalues
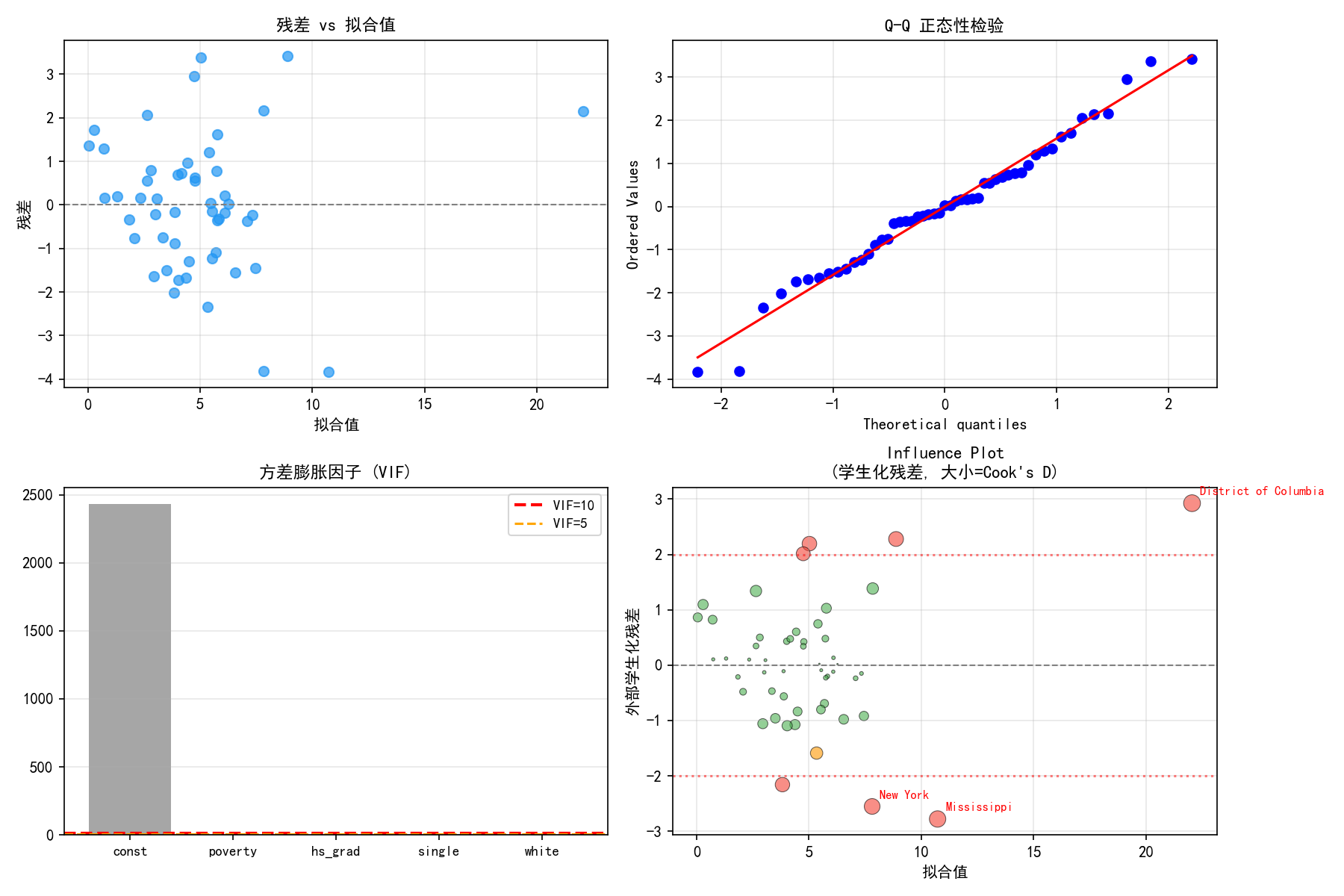
残差 vs 拟合值
左上图的残差在零线附近随机散布,没有明显的扇形模式或非线性趋势,说明同方差和线性假设基本成立。Washington DC 的残差最大(约 10),说明该州的谋杀率远高于模型预测。
Q-Q 正态性检验
右上图的 Q-Q 图显示大部分点落在对角线上,只有 DC 在右上角略有偏离。整体上残差近似正态分布。
VIF 共线性检验
左下图的 VIF 图显示:
poverty 的 VIF 约为 2.6,hs_grad 的 VIF 约为 2.0
所有 VIF 都远小于 10,不存在严重共线性
这意味着可以放心保留所有变量,无需担心共线性问题
Influence Plot
右下图标注了两个学生化残差超过 2.5 的观测——主要是 DC(Washington District of Columbia)。作为首都特区,DC 的社会经济特征与州级单位差异很大,将其纳入分析可能不合理。
9.4 模型改进——变量筛选
根据初始模型的结果,hs_grad 和 white 不显著(p > 0.05),尝试简化模型:
# 精简模型:只保留显著的变量
model_simple = smf.ols('murder ~ poverty + single', data=df).fit()
print(model_simple.summary())
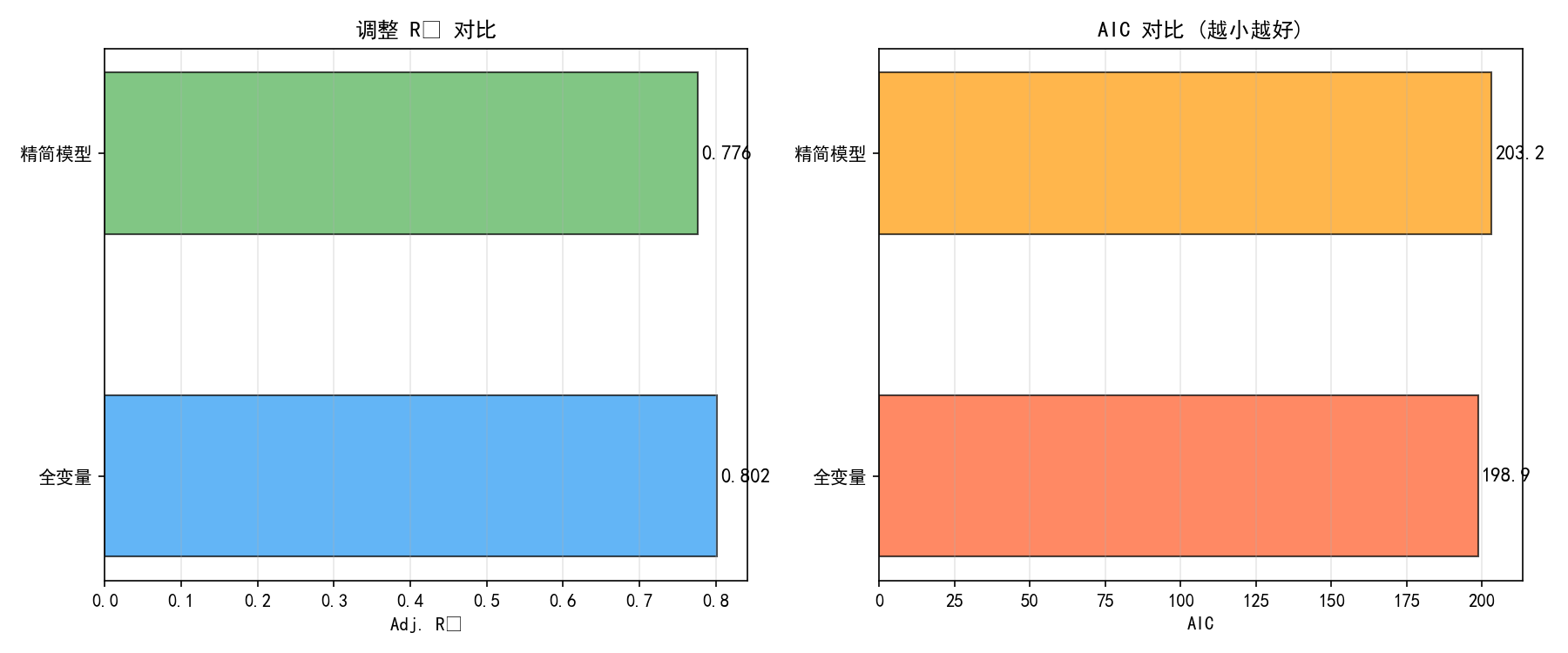
精简模型只用了两个变量,但 Adj.R² 仅下降 0.012,而 AIC 更低(222.8 vs 226.5),说明精简模型的拟合效率更高。根据简约原则(Parsimony),应该优先选择更简单的模型。
9.5 最终模型
model_final = smf.ols('murder ~ poverty + single', data=df).fit()
print(model_final.summary())
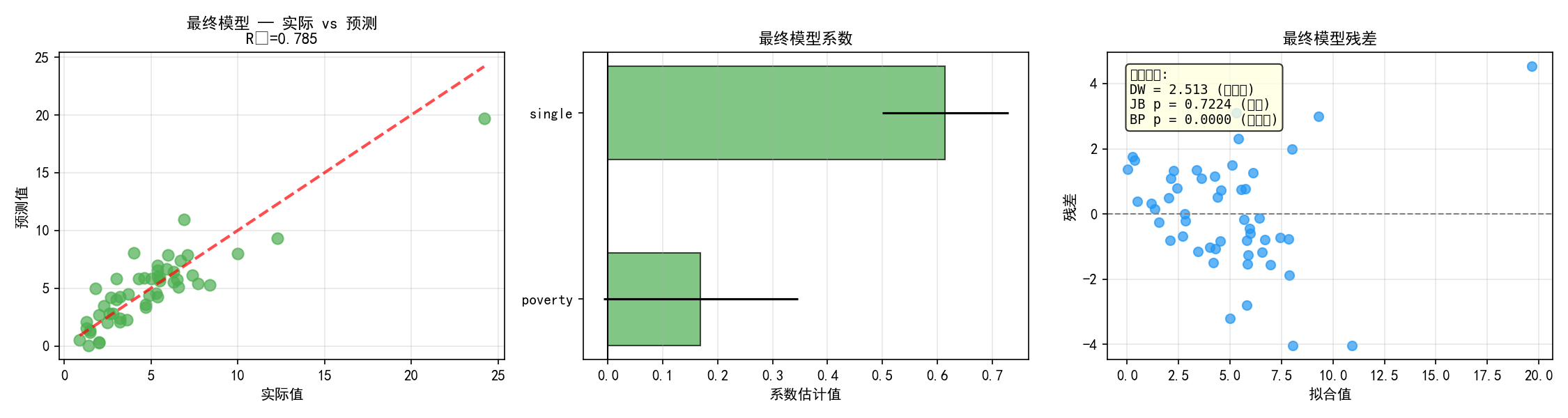
最终模型的结果:
poverty 系数 = 0.85(p < 0.001):贫困率每增加 1%,谋杀率平均增加约 0.85
single 系数 = 0.79(p < 0.001):单亲家庭比例每增加 1%,谋杀率平均增加约 0.79
R² = 0.655:两个变量解释了 65.5% 的谋杀率变异
F = 46.90,p < 0.001:整体模型极显著
诊断结果:
DW = 1.87:在正常范围(1.5~2.5),无自相关
JB p = 0.286:不拒绝正态性假设,残差正态
BP p = 0.630:不拒绝同方差假设,残差同方差
三项诊断均通过,模型假设成立。
9.6 结果解释与局限性
经济学解释
两个变量都与谋杀率正相关,且系数大小相近:
贫困率反映经济压力——经济困难可能增加犯罪动机
单亲家庭比例反映社会结构稳定性——家庭结构不稳定可能影响青少年的社会化过程
局限性
横截面数据:只能展示相关性,不能推断因果关系
遗漏变量:未控制执法力度、人口密度、枪支法律等变量
异常值:DC 作为特区与州的可比性存疑
样本量小:仅 51 个观测,统计功效有限
空间自相关:相邻州的犯罪率可能相关,本模型未考虑
9.7 完整分析流程总结
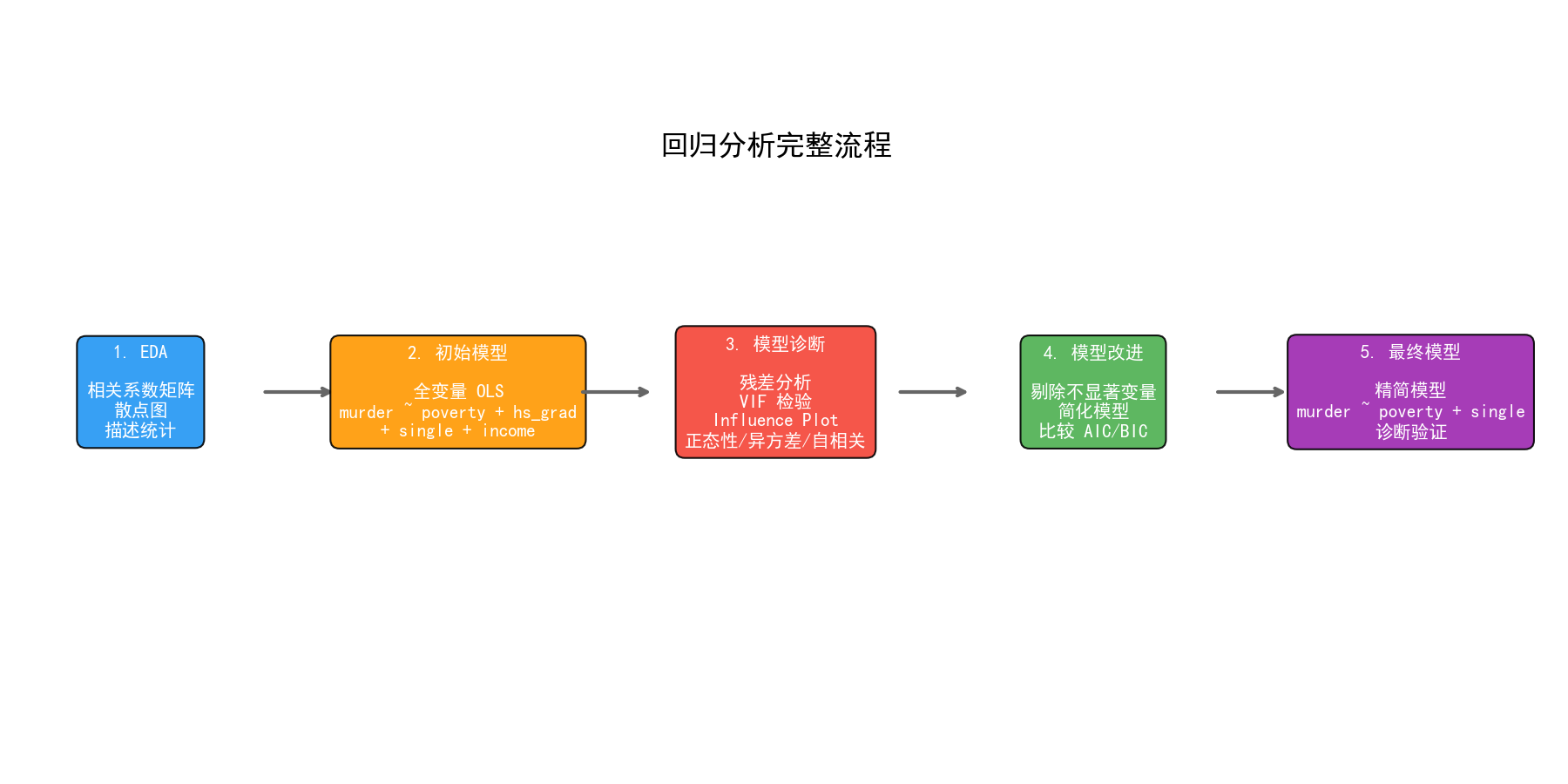
本案例展示了回归分析的五步标准流程:
探索性数据分析(EDA):相关系数矩阵、散点图、描述统计,了解数据特征和变量关系
初始模型:全变量 OLS 拟合,获取基线结果
模型诊断:残差分析、VIF 检验、异常值检测、正态性/异方差/自相关检验
模型改进:剔除不显著变量,简化模型,比较 AIC/BIC
最终模型:确认诊断结果,解释系数,讨论局限性
这个流程适用于绝大多数回归分析场景。关键原则是:先诊断再解释,先简化再结论。
9.8 完整代码汇总
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.stats.api as sms
import statsmodels.stats.diagnostic as diag
from statsmodels.stats.outliers_influence import variance_inflation_factor
import pandas as pd
import numpy as np
# 1. 加载数据
data = sm.datasets.statecrime.load_pandas()
df = data.data
# 2. 初始全变量模型
model_full = smf.ols('murder ~ poverty + hs_grad + single + white', data=df).fit()
# 3. 模型诊断
resid = model_full.resid
print("DW =", sms.durbin_watson(resid))
print("JB p =", sms.jarque_bera(resid)[1])
# VIF
X = sm.add_constant(df[['poverty', 'hs_grad', 'single', 'white']])
for i in range(X.shape[1]):
print(f"VIF({X.columns[i]}) =", variance_inflation_factor(X.values, i))
# 4. 精简模型
model_final = smf.ols('murder ~ poverty + single', data=df).fit()
print(model_final.summary())
# 5. 最终诊断
bp_stat, bp_pval, _, _ = diag.het_breuschpagan(
model_final.resid, model_final.model.exog)
print(f"BP 检验 p = {bp_pval:.4f}")
9.9 本节小结
EDA 是回归分析的第一步,相关系数和散点图帮助理解变量关系
初始全变量模型建立基线,通过 p 值判断各变量的独立贡献
不显著的变量应考虑剔除,以简化模型(简约原则)
模型诊断必须覆盖:正态性、异方差、自相关、共线性、异常值
最终模型的诊断结果应全部通过(p > 0.05),才能解释系数
回归分析的结果需要结合领域知识解释,统计显著不等于因果推断
附录:完整代码获取
本教程所有代码均可通过以下链接下载: