
基础篇:Scikit-learn库求解聚类分析和主成分分析模型方法
前言
关于本教程
本教程是面向有一定 Python 编程基础、希望掌握无监督学习方法的读者的 Scikit-learn 聚类与降维教程。共九章,从聚类分析的三大经典算法(K-Means、DBSCAN、层次聚类)出发,系统讲解主成分分析(PCA)与 Kernel PCA,最后通过综合案例展示"先降维、再聚类"的完整 Pipeline。
Scikit-learn 的核心优势在于算法工程化——它提供统一的 fit / transform / predict 接口、丰富的评估指标和可视化工具,帮助研究者回答"数据有哪些内在结构"这类问题。
目标读者
有一定 Python 编程基础的数据分析师、研究人员、学生
了解 numpy 数组操作和 pandas DataFrame 基本使用
熟悉 matplotlib 基本绘图
前置知识
阅读本教程前,建议具备以下基础:
线性代数:了解向量、矩阵乘法、特征值(不需要深入推导,Scikit-learn 会处理大部分运算)
Python:能使用 numpy 进行数组运算、用 pandas 读取数据、调用函数
Scikit-learn 基础:了解
fit()/transform()/predict()的基本用法
如果你完全不了解聚类或降维的基本概念(如"簇"、"质心"、"方差"),建议先阅读第0章的导论部分。
环境要求
本教程所有代码基于以下环境编写和验证:
安装命令:
pip install scikit-learn numpy pandas matplotlib scipy
验证安装:
import sklearn
print(sklearn.__version__) # 应输出 1.x
本教程结构
建议按顺序阅读。第0-1章是基础,第2-4章为聚类专题,第5-6章为降维专题,第7章综合实战,第8章为全局回顾。
代码约定
本教程所有代码使用
from sklearn.cluster import KMeans等直接导入方式数据变量通常命名为
X(特征矩阵)和y(标签,无监督学习中仅用于评估)模型对象通常命名为
km、dbscan、pca等缩写所有图表均使用中文标签,使用
plt.rcParams['font.sans-serif'] = ['SimHei']设置代码块为可独立运行的完整代码段
公式约定
教程中使用 LaTeX 格式书写数学公式:
X 表示 n×d 特征矩阵
μi 表示第 i 个簇的质心
λi 表示第 i 个主成分的特征值
K(xi,xj) 表示核函数
数据来源
本教程使用的所有数据集均为 Scikit-learn 内置数据集,无需额外下载:
make_blobs:人工生成的球状簇(第1、2、3、4、7章)make_moons:半月形簇(第1、2、4章)make_circles:同心圆簇(第4、6章)make_swiss_roll:瑞士卷流形(第6章)load_iris:鸢尾花数据(第5、7章)load_digits:手写数字图像(第5、7章)
这些数据集可通过 sklearn.datasets 模块直接加载。
如何学习
建议的学习方式:
先读章节的文字部分,理解概念和方法
运行对应的
_gen.py代码,观察生成的图表修改代码中的参数(如更换数据集、改变簇数或 ε),观察结果变化
尝试用自己的数据,套用本章的模板
Scikit-learn 的学习曲线相对平缓,因为它的 API 高度统一(fit() → transform() → predict())。一旦掌握了一个算法的使用模式,后续章节的模式是高度一致的。
反馈与勘误
如果你在阅读过程中发现代码运行错误、结论有误、或有任何建议,欢迎反馈。
第0章 导论
本章介绍无监督学习的基本概念,以及 Scikit-learn 中聚类与降维工具的全局设置。
0.1 无监督学习概述
与有监督学习(给定特征 X 和目标变量 y,学习映射 f:X→y)不同,无监督学习只有特征矩阵 X,没有标签 y。它的目标是从数据的内在结构中发现模式:
0.2 聚类的直观理解
聚类(Clustering)的核心思想是簇内相似度高、簇间相似度低。不同算法对"相似度"的定义不同:
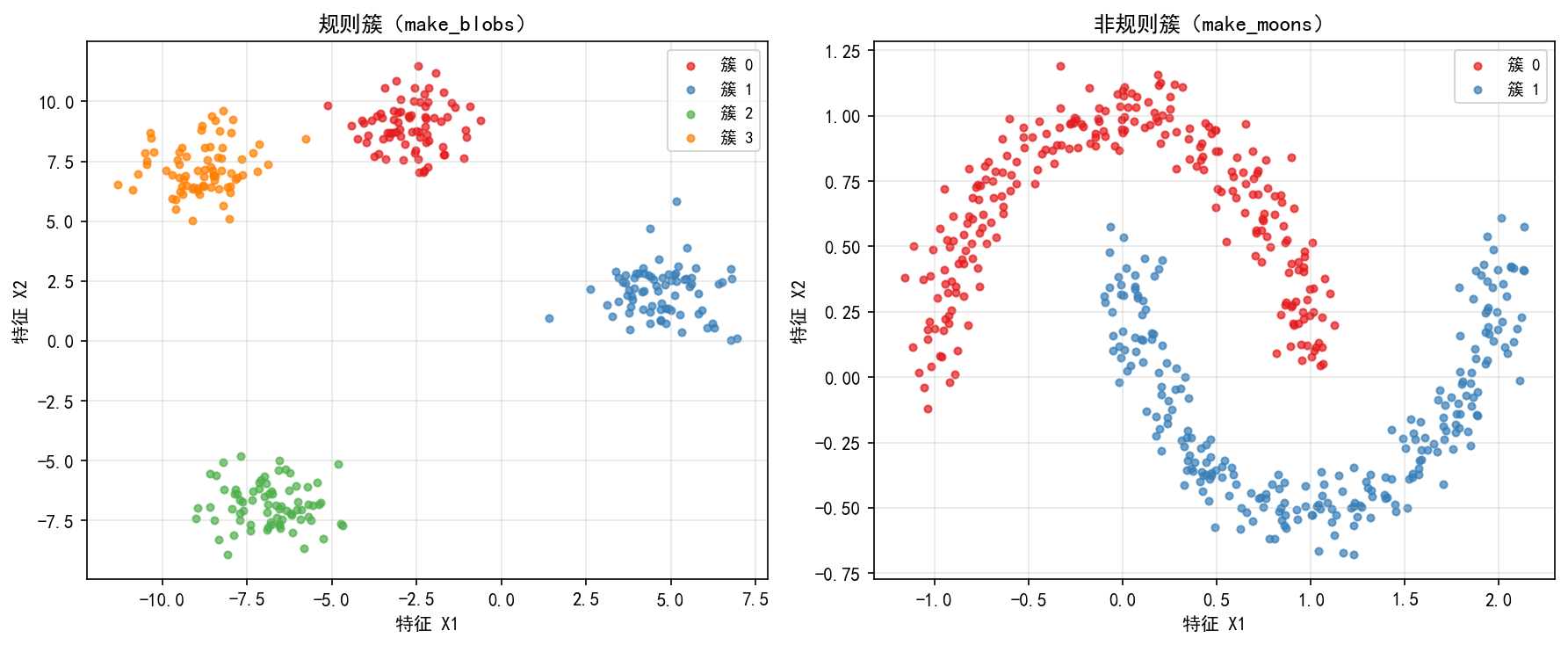
左图展示了 make_blobs 生成的规则簇——4 个高斯分布的簇,各簇中心远离、边界清晰。这类数据适合 K-Means 等基于质心的算法。
右图展示了 make_moons 生成的非规则簇——两个半月形的簇,簇之间没有明确的线性边界。这类数据需要 DBSCAN 或谱聚类等基于密度/流形的算法。
0.3 PCA 的直观理解
主成分分析(PCA)的目标是找到一个低维子空间,使得数据在该子空间上的投影方差最大化。
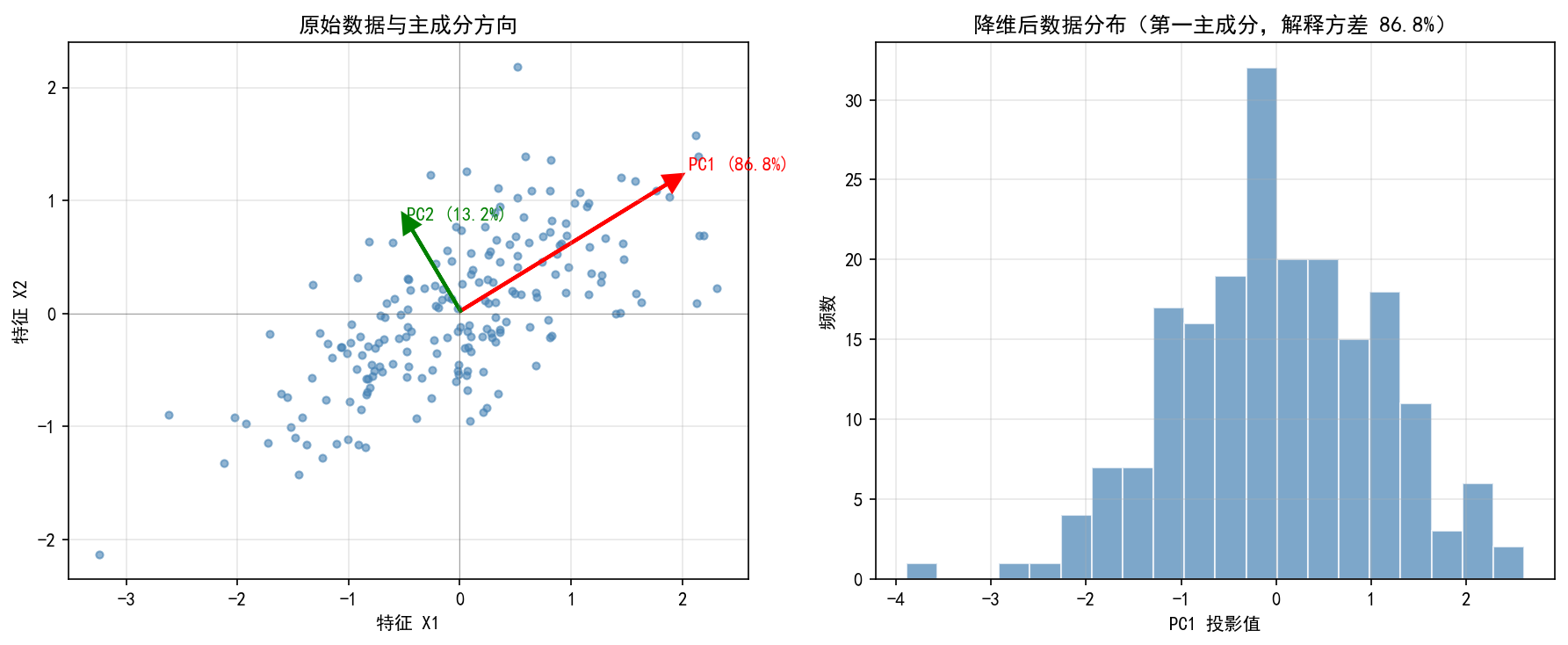
左图展示了原始二维数据(蓝色散点)以及两个主成分方向(红色箭头为 PC1,绿色箭头为 PC2)。PC1 方向捕捉了数据中最大的方差(86.8%),PC2 方向捕捉了剩余方差(13.2%)。
右图展示了将数据投影到 PC1 后的分布——将二维数据压缩到一维,仍保留了 86.8% 的信息。
PCA 的核心公式:
对中心化后的数据 X,计算协方差矩阵
对 C 做特征值分解:
特征向量(V 的列)即为主成分方向,特征值(Λ 的对角元)的大小决定了各主成分的重要性
0.4 环境配置与中文字体
import matplotlib.pyplot as plt
# Windows 系统中文字体适配
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
如果你的系统不是 Windows:
macOS:使用
'PingFang SC'或'Heiti SC'Linux:使用
'Noto Sans CJK SC'或'WenQuanYi Micro Hei'
0.5 Scikit-learn 数据集一览
本教程使用的内置数据集:
0.6 本节小结
无监督学习无需标签,核心任务是发现数据内在结构
聚类按"相似度"定义分为基于质心(K-Means)、基于密度(DBSCAN)、基于层次等类别
PCA 通过特征值分解找到方差最大的投影方向,实现降维
本教程所有可视化使用
SimHei中文字体,非 Windows 用户需替换对应字体
第1章 K-Means 聚类
K-Means(K-均值)是最经典的聚类算法之一。其核心思想是迭代优化质心,使每个样本到所属簇质心的距离最小化。
1.1 K-Means 算法原理
目标函数
K-Means 优化的目标函数(惯性/Inertia)为:
其中 k 为簇数,Ci 为第 i 个簇,μi 为第 i 个簇的质心。
算法步骤
初始化:随机选择 k 个点作为初始质心
分配:将每个样本分配到最近的质心所属簇
更新:重新计算每个簇的质心(取簇内均值)
重复步骤 2-3,直到质心不再变化或达到最大迭代次数
关键特点
需要预先指定簇数 k
适合球状簇(各簇方差相近)
对异常值敏感(均值受极端值影响)
对初始质心敏感(多次运行结果可能不同)
1.2 Scikit-learn 基本用法
from sklearn.cluster import KMeans
# 创建 KMeans 模型
km = KMeans(n_clusters=4, random_state=42, n_init=10)
# 拟合数据
km.fit(X)
# 获取聚类标签
labels = km.labels_
# 获取质心坐标
centers = km.cluster_centers_
# 获取惯性值
inertia = km.inertia_
常用参数速查:
k-means++ 初始化:默认策略,通过概率分散选择初始质心,比完全随机更稳定,通常收敛更快。
1.3 簇数 k 的选择
方法一:肘部法(Elbow Method)
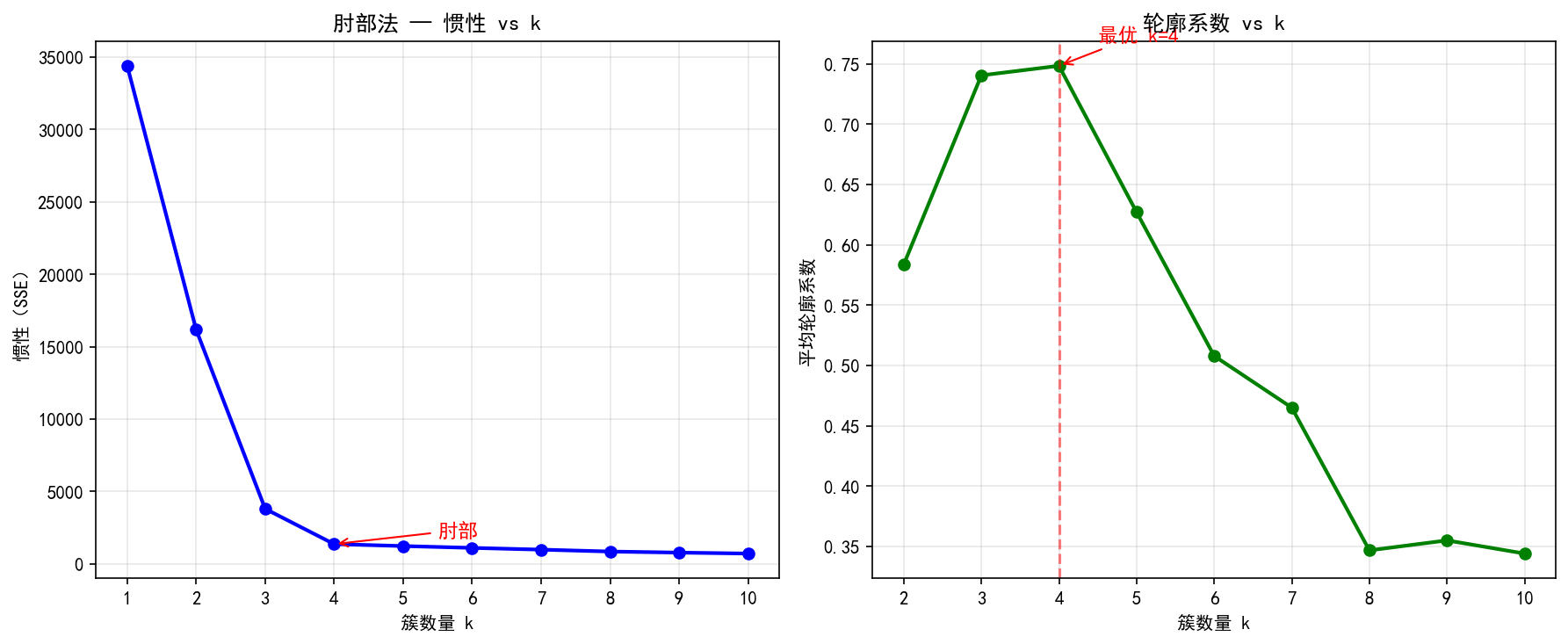
左图:肘部法
随着 k 增加,惯性(SSE)单调递减。当 k 等于真实簇数时,下降趋势明显变缓,形成"肘部"。本例中肘部出现在 k=4 处,与真实簇数一致。
右图:轮廓系数
轮廓系数衡量样本与其所属簇的紧密程度(范围 [−1,1]):
接近 1:样本与所属簇紧密,与邻近簇远离
接近 0:样本在两个簇的边界上
接近 -1:样本可能被分错了簇
本例中轮廓系数在 k=4 处达到峰值,同样指示正确簇数。
肘部法代码示例
from sklearn.cluster import KMeans
k_range = range(1, 11)
inertias = []
for k in k_range:
km = KMeans(n_clusters=k, random_state=42, n_init=10)
km.fit(X)
inertias.append(km.inertia_)
# 绘制肘部曲线
plt.plot(k_range, inertias, 'bo-')
plt.xlabel('簇数量 k')
plt.ylabel('惯性(SSE)')
方法二:轮廓系数分析
from sklearn.metrics import silhouette_score
k_range = range(2, 11)
sil_scores = []
for k in k_range:
km = KMeans(n_clusters=k, random_state=42, n_init=10).fit(X)
sil_scores.append(silhouette_score(X, km.labels_))
1.4 不同 k 值的聚类效果
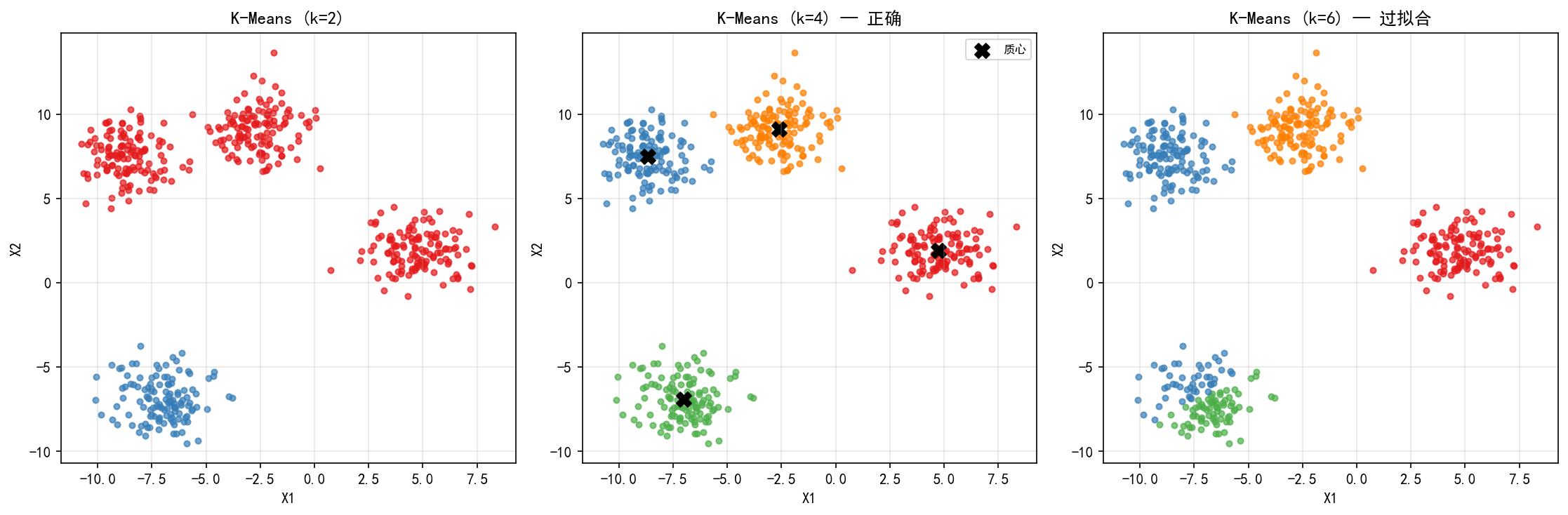
k=2(左):将 4 个真实簇合并为 2 组,粒度太粗
k=4(中):正确识别出 4 个簇,质心(黑叉)位于各簇中心
k=6(右):将真实簇进一步拆分,过度拟合
1.5 轮廓系数详细解读
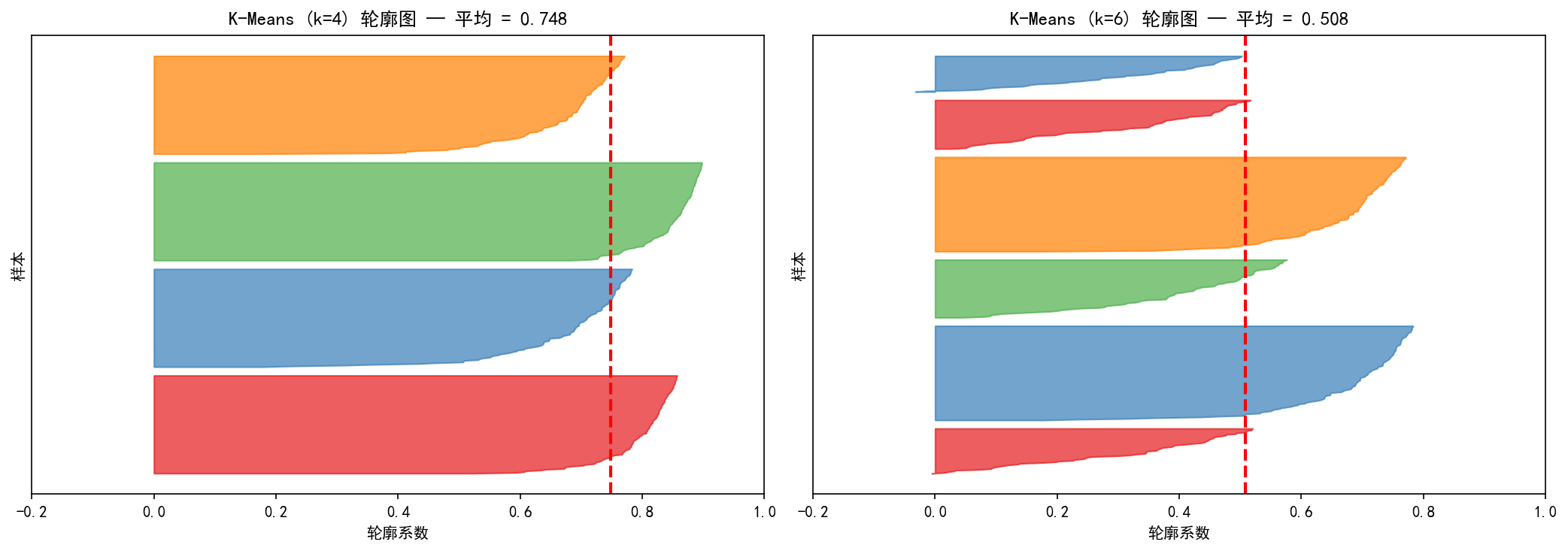
左图:k=4 的轮廓图
每个水平条代表一个簇内的样本,按轮廓系数从小到大排列。
所有簇的样本轮廓系数均大于平均线(红色虚线,0.748)
四个簇的轮廓分布宽度相近,表明各簇质量均衡
平均轮廓系数 0.748,属于高质量聚类
右图:k=6 的轮廓图
部分簇中出现轮廓系数低于平均线(0.508)的样本
有的簇轮廓系数接近 0,说明这些样本处于簇边界,聚类质量下降
平均轮廓系数从 0.748 降至 0.508,表明 k=6 不如 k=4
轮廓图解读规则
1.6 K-Means 的局限性
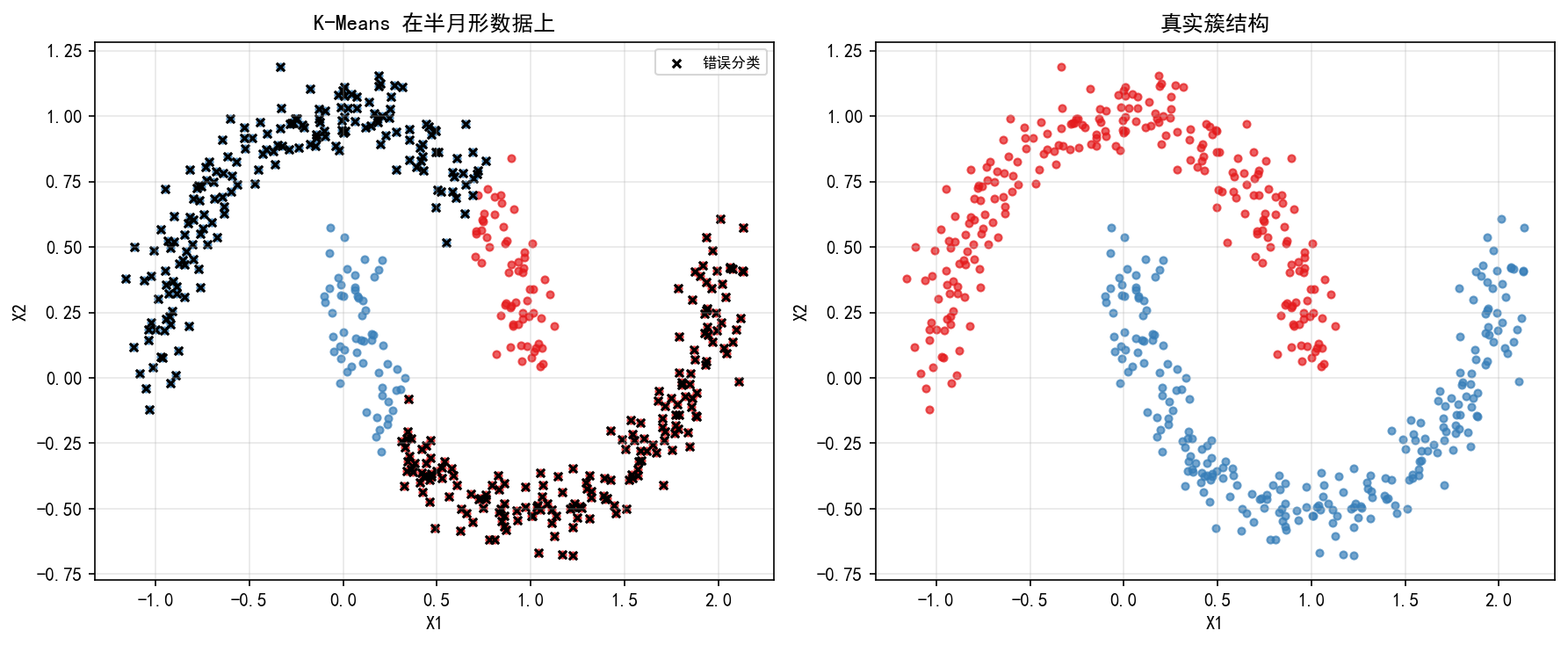
K-Means 假设簇是凸形(球状)的,当面对非凸形状的数据时,表现不佳。
左图:K-Means 将两个半月形簇按上下分割(而非左右),导致大量错误分类(黑叉标记)。
右图:真实的半月形簇结构——K-Means 无法捕捉这种基于密度/流形的簇形态。
解决方案:对于非球形簇,应使用 DBSCAN(第2章)或谱聚类等算法。
1.7 实用技巧
数据标准化
K-Means 基于欧氏距离,不同量纲的特征会影响聚类结果。建议先标准化:
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
km = KMeans(n_clusters=4, random_state=42, n_init=10).fit(X_scaled)
用已拟合模型预测新样本
# 训练模型
km = KMeans(n_clusters=4, random_state=42, n_init=10).fit(X_train)
# 预测新数据
labels_new = km.predict(X_test)
与 PCA 结合
高维数据可先用 PCA 降维,再运行 K-Means:
from sklearn.decomposition import PCA
pca = PCA(n_components=0.95) # 保留95%方差
X_reduced = pca.fit_transform(X)
km = KMeans(n_clusters=4, random_state=42, n_init=10).fit(X_reduced)
1.8 本节小结
K-Means 通过迭代优化质心,最小化样本到质心的距离平方和
需要预先指定簇数 k,可通过肘部法和轮廓系数确定
k-means++ 初始化比随机更稳定,
n_init=10建议保留K-Means 适合球状簇,对非凸形状(如半月形)效果差
聚类前建议标准化数据,避免量纲影响
轮廓系数 > 0.7 为高质量聚类,0.5~0.7 为中等,< 0.5 需调整参数
第2章 DBSCAN 聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,基于密度的空间聚类)是一种基于密度定义簇的算法。与 K-Means 不同,它不需要预先指定簇数,且能识别任意形状的簇和噪声点。
2.1 核心概念
DBSCAN 基于两个关键参数定义密度:
ε(eps):邻域半径——以样本点为中心、半径为 ε 的圆形区域
min_samples:核心点所需的最小邻域样本数
基于这两个参数,每个样本被划分为三类:
簇的定义:由核心点通过密度可达关系(互相在对方 ε 邻域内)连接形成的最大连通子图,加上其所有边界点。
2.2 Scikit-learn 基本用法
from sklearn.cluster import DBSCAN
# 创建 DBSCAN 模型
dbscan = DBSCAN(eps=0.3, min_samples=10)
# 拟合数据
dbscan.fit(X)
# 获取聚类标签(-1 表示噪声)
labels = dbscan.labels_
# 核心样本索引
core_samples = dbscan.core_sample_indices_
# 核心点坐标
core_points = dbscan.components_
常用参数速查:
标签约定:簇标签从 0 开始递增,噪声点标签为 -1。
2.3 DBSCAN vs K-Means
非球形簇处理
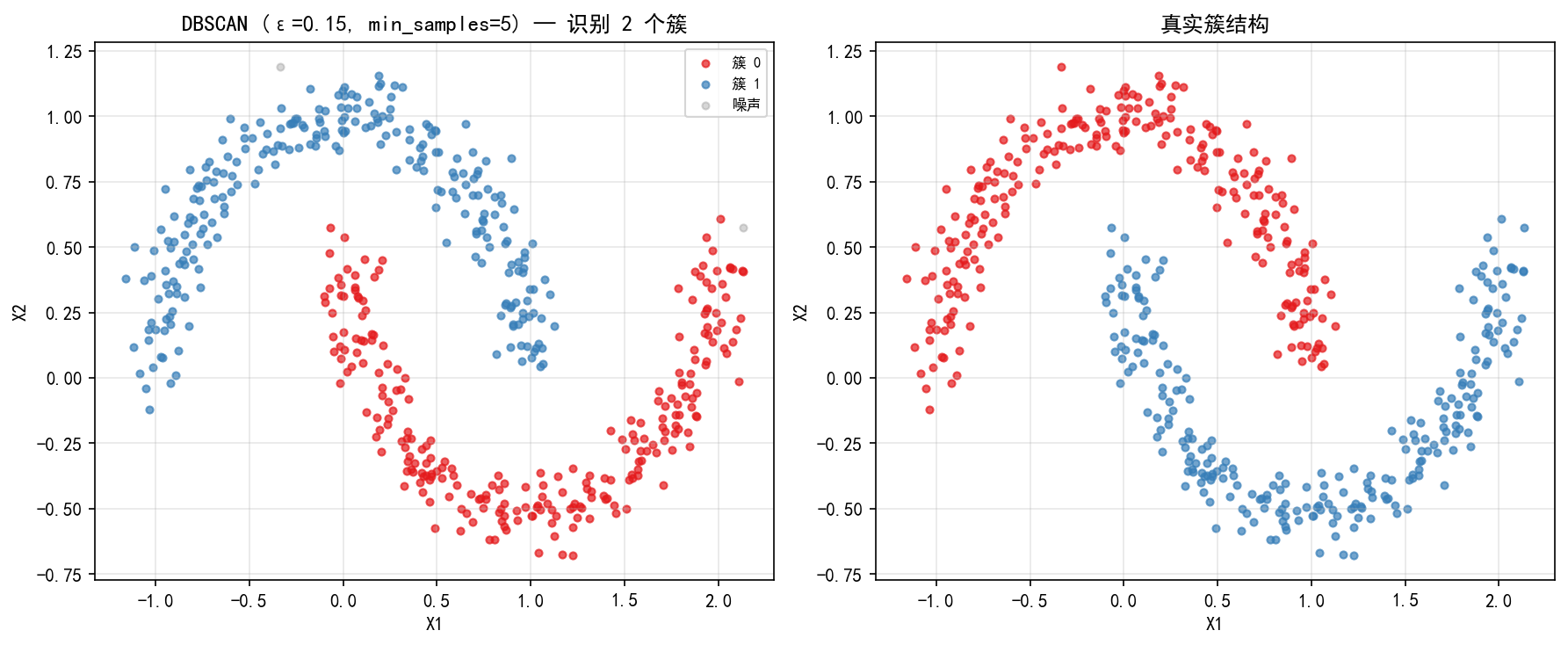
左图:DBSCAN(ε=0.15, min_samples=5)正确识别出两个半月形簇,并标记了少量噪声点(灰色)。
右图:真实簇结构。DBSCAN 的聚类结果与真实结构高度一致。
相比之下,第1章中 K-Means 在相同数据上将半月形按上下分割,产生大量错误分类。这是因为 K-Means 基于质心距离,只能发现球状簇;而 DBSCAN 基于局部密度,自然沿着数据流形扩展。
噪声处理能力
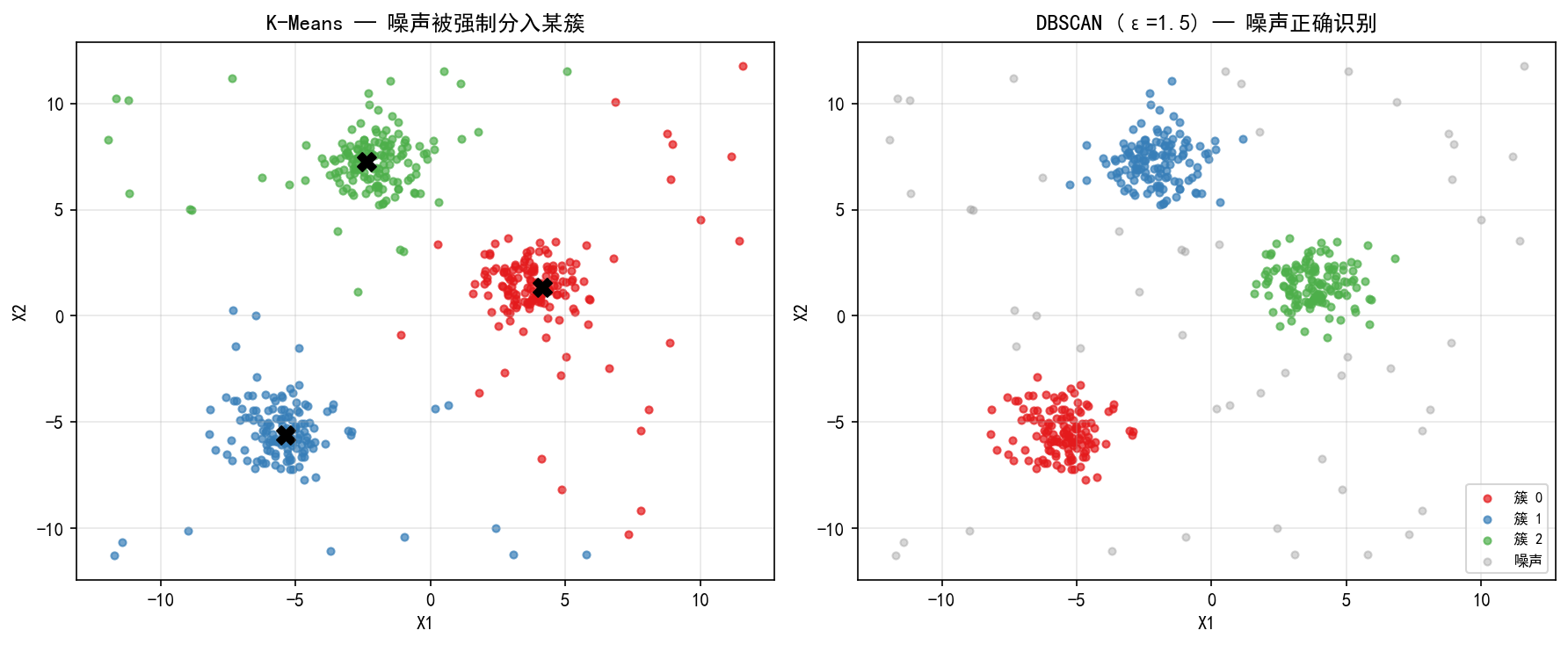
左图:K-Means
噪声点(散布在三个球状簇周围的灰点)被强制分配到最近的簇中,导致质心偏移(黑叉偏离真实中心)。K-Means 没有"噪声"的概念,每个点必须属于某个簇。
右图:DBSCAN
噪声点被正确标记为灰色(标签 -1),三个真实簇的边界清晰,不受离群点干扰。这在实际数据(如客户行为分析、传感器数据清洗)中非常实用。
2.4 参数 ε 的调优
ε 是 DBSCAN 最关键的参数,直接影响簇的粒度。
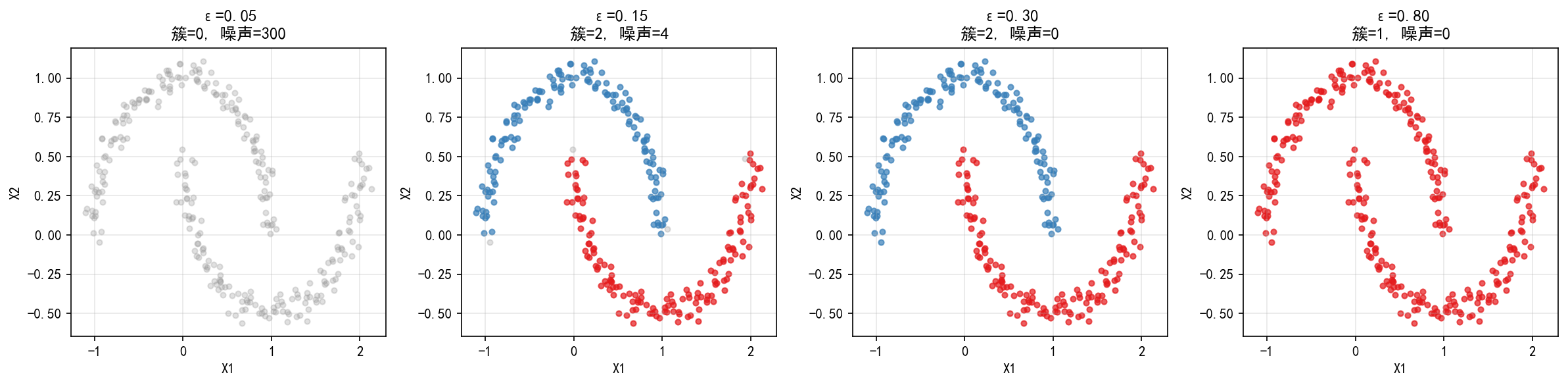
ε=0.05(太小):邻域过小,几乎所有点都被判定为噪声,无法形成任何簇
ε=0.15(合适):恰好识别出两个半月形簇,仅有 4 个噪声点
ε=0.3(偏大):恰好识别出两个半月形簇,但是没有识别出噪声点
ε=0.80(太大):所有点合并为一个簇,完全丧失区分度
K-距离图(K-distance Graph)
调参 ε 的经验方法——K-距离图:
from sklearn.neighbors import NearestNeighbors
# 计算每个点到其第 k 近邻居的距离
k = 5 # k = min_samples
nn = NearestNeighbors(n_neighbors=k)
nn.fit(X)
distances, _ = nn.kneighbors(X)
# 第 k 近的距离,排序后画图
k_dist = np.sort(distances[:, -1])
plt.plot(k_dist)
plt.xlabel('样本(按距离排序)')
plt.ylabel(f'第 {k} 近邻距离')
解读:曲线中最陡峭的拐点对应的距离值即为推荐的 ε 值。这个拐点是密度发生显著变化的位置,正好区分了"簇内"和"簇间"。
min_samples 的选择
min_samples ≤ 维度数 + 1:大多数点会成为核心点,可能将噪声也归入簇
min_samples ≥ 2 × (维度数 + 1):更严格,更多点被标记为噪声,簇更"纯"
经验规则:
min_samples = 2 × dim作为起点,dim为数据维度
2.5 距离度量
DBSCAN 支持多种距离度量(通过 metric 参数):
# 欧氏距离(默认)
DBSCAN(eps=0.3, metric='euclidean')
# 曼哈顿距离
DBSCAN(eps=0.5, metric='manhattan')
# 余弦距离
DBSCAN(eps=0.3, metric='cosine')
# 预计算距离矩阵
from scipy.spatial.distance import pdist, squareform
dist_matrix = squareform(pdist(X, metric='jaccard'))
DBSCAN(eps=0.3, metric='precomputed').fit(dist_matrix)
2.6 实际案例:客户分群
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import DBSCAN
# 模拟客户数据(消费金额 + 消费频次)
X, _ = make_blobs(n_samples=300, centers=3, cluster_std=0.8, random_state=42)
X = X * [100, 5] # 不同量纲
X[:, 0] += 200 # 消费金额 200-600
X[:, 1] += 10 # 消费频次 10-30
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# DBSCAN 聚类
dbscan = DBSCAN(eps=0.5, min_samples=8).fit(X_scaled)
# 统计结果
unique, counts = np.unique(dbscan.labels_, return_counts=True)
for label, count in zip(unique, counts):
name = '噪声' if label == -1 else f'簇 {label}'
print(f'{name}: {count} 人')
2.7 本节小结
DBSCAN 基于密度定义簇,不需要预设簇数 kk
核心概念:核心点(ε 邻域内 ≥ min_samples)、边界点、噪声点(标签 -1)
ε 是最关键参数——用 K-距离图 找拐点确定 ε,
min_samples从2×维度开始尝试DBSCAN 优势:发现任意形状簇、自动识别噪声、不强制所有点入簇
DBSCAN 局限:对高维数据效果下降(维度灾难)、密度不均匀的数据难以用统一 ε 处理
与 K-Means 互补:球状均匀簇用 K-Means,复杂形状/含噪声用 DBSCAN
第3章 层次聚类
层次聚类(Hierarchical Clustering)通过构建嵌套的簇层次结构来组织数据,结果可用树状图(Dendrogram)直观展示。与 K-Means 和 DBSCAN 不同,它不需要预先指定簇数——你可以根据树状图在任意高度"切割",得到不同粒度的聚类结果。
3.1 凝聚层次聚类(Agglomerative)
凝聚层次聚类采用自底向上的策略:
初始化:每个样本自成一簇(n 个簇)
合并:找到距离最近的两个簇,合并为一个
重复步骤 2,直到所有样本合并为一个簇
关键:簇间距离的定义(链接方法)
合并哪两个簇取决于如何定义"两个簇之间的距离"。不同的链接方法产生截然不同的层次结构:
链接方法对比
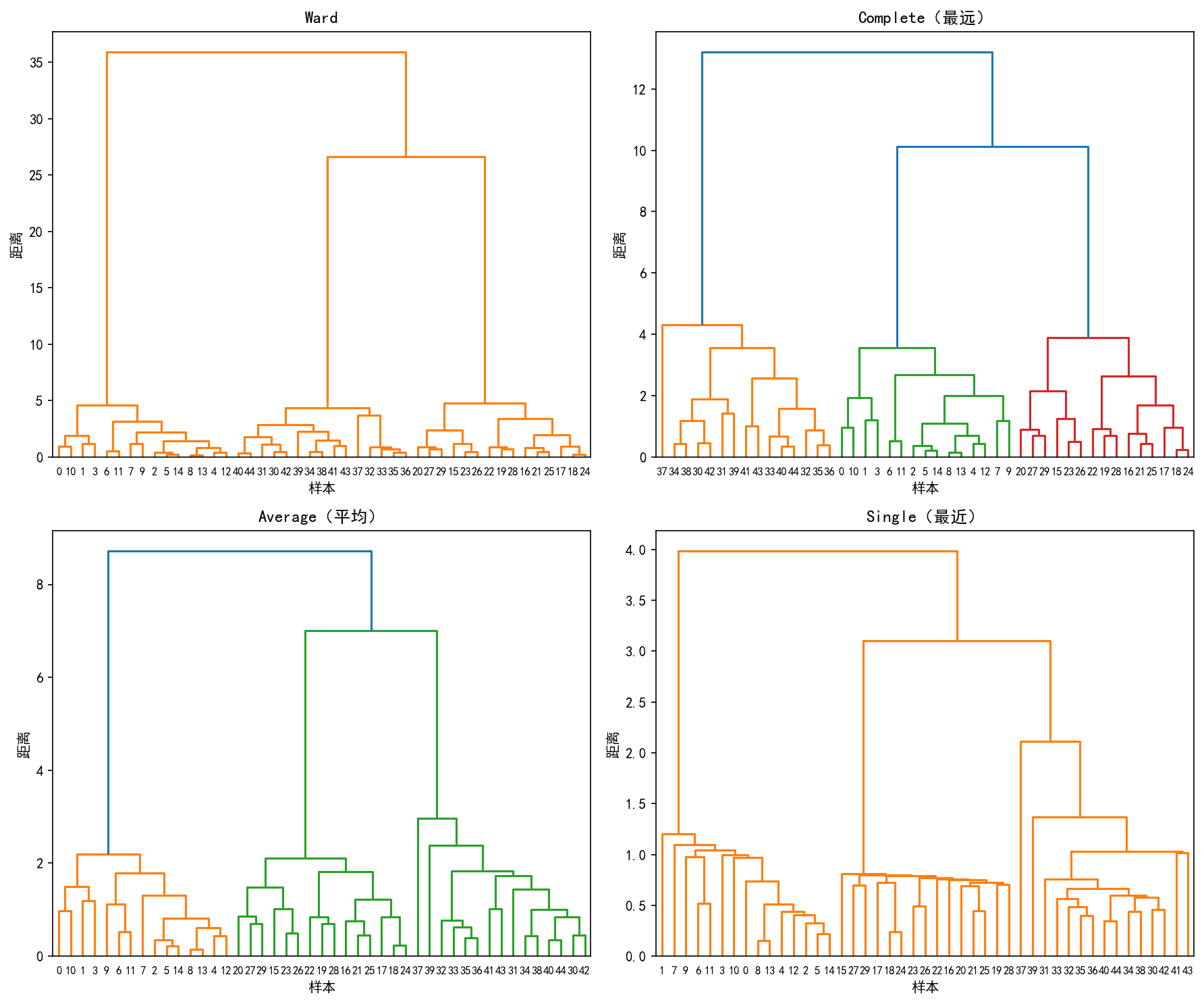
使用相同的 45 个样本数据,四种链接方法产生了不同的层次结构:
Ward(左上):三个簇在距离 ≈ 36 处合并,层次清晰,簇大小均衡
Complete(右上):合并距离的绝对值较小(≈ 13),树状结构更"矮胖"
Average(左下):介于 Ward 和 Complete 之间,合并距离 ≈ 9
Single(右下):产生"链式效应"——簇间距离很小,树状图呈"梳子"状,不适合确定簇数
3.2 树状图(Dendrogram)解读
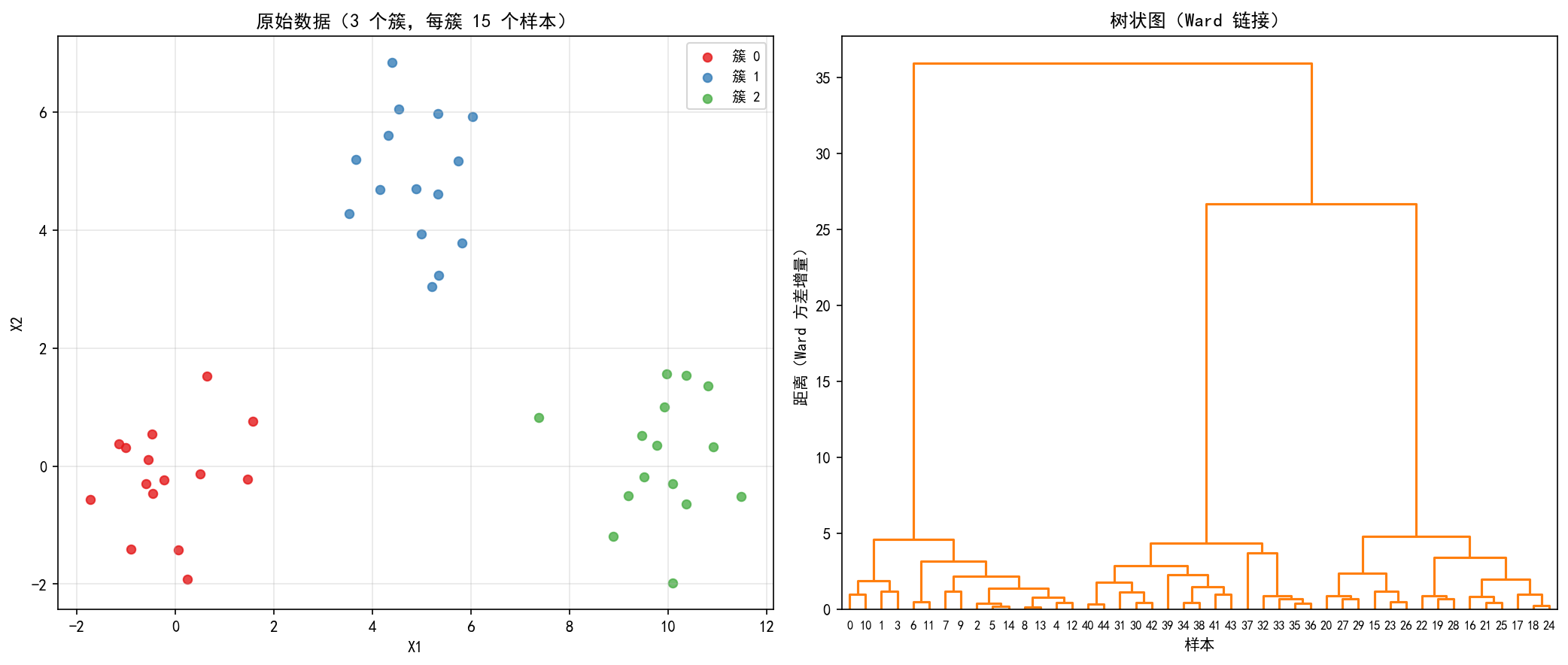
左图:原始数据,包含 3 个簇,每簇 15 个样本。
右图:Ward 链接的树状图。
如何读树状图
横轴:样本编号(叶子节点),每个叶子代表一个样本
纵轴:距离——两个簇合并时的距离值
水平线:表示一次合并操作,高度越高说明合并的两个簇差异越大
垂直线:连接被合并的子簇
如何确定簇数
在树状图上画一条水平切割线,与树状图的交叉数即为簇数。本例中:
红色虚线在距离 ≈ 50 处切割,恰好产生 3 个簇
切割线以下的每个连通分支对应一个簇
切割线越高,簇数越少;切割线越低,簇数越多
读取切割结果
from scipy.cluster.hierarchy import fcluster
# Z 为 linkage 返回值
labels = fcluster(Z, t=50, criterion='distance')
# 或直接指定簇数
labels = fcluster(Z, t=3, criterion='maxclust')
3.3 Scikit-learn 中的层次聚类
from sklearn.cluster import AgglomerativeClustering
# 创建模型
agg = AgglomerativeClustering(n_clusters=4, linkage='ward')
# 拟合并获取标签
labels = agg.fit_predict(X)
常用参数:
两种使用方式:
# 方式1: 指定簇数
agg = AgglomerativeClustering(n_clusters=4, linkage='ward')
labels = agg.fit_predict(X)
# 方式2: 指定距离阈值(自动确定簇数)
agg = AgglomerativeClustering(distance_threshold=30, linkage='ward', n_clusters=None)
labels = agg.fit_predict(X)
3.4 不同簇数的效果
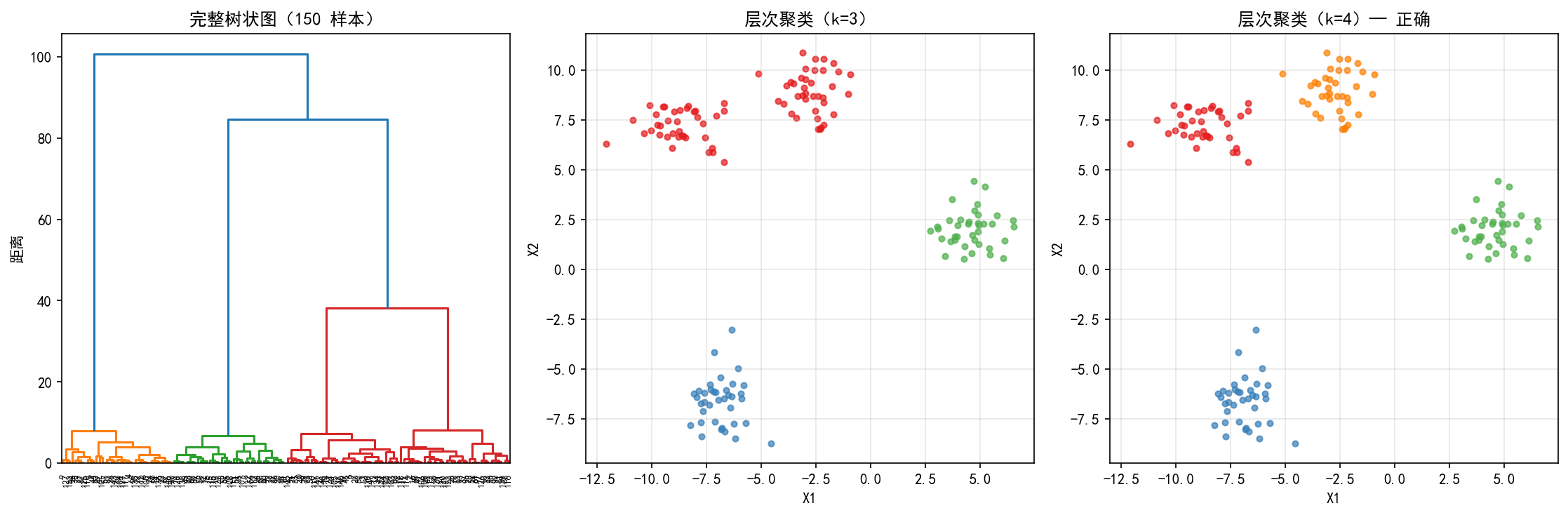
左图:150 个样本的完整树状图。由于样本多,叶子标签重叠,但可以看到明显的层次结构——三个主分支在较高处合并。
中图:在树状图上切割得到 k=3,将四个真实簇中的两个合并了。
右图:切割得到 k=4,正确识别出四个簇。
如何选择合适的 k
从树状图上寻找大的垂直跳跃——如果某次合并的距离远大于之前的合并,说明这两个子簇本质上不同,切割点应在该次合并之前。本例中,树状图顶部有两个显著的高度跳跃,暗示 k=3 或 k=4 是合理选择。
3.5 完整工作流程
import numpy as np
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
import matplotlib.pyplot as plt
# 1. 计算距离矩阵并构建树
Z = linkage(X, method='ward')
# 2. 绘制树状图
fig, ax = plt.subplots(figsize=(10, 5))
dendrogram(Z, ax=ax, leaf_rotation=90, leaf_font_size=8)
ax.set_title('树状图')
ax.set_ylabel('距离')
ax.axhline(y=30, color='red', linestyle='--')
plt.tight_layout()
plt.show()
# 3. 根据树状图选择切割距离,获取标签
labels = fcluster(Z, t=30, criterion='distance')
print(f'簇数: {len(set(labels))}')
3.6 何时使用层次聚类
3.7 本节小结
凝聚层次聚类自底向上合并样本,结果用树状图展示
四种链接方法:Ward(方差最小化,最常用)、Complete(最远)、Average(平均)、Single(最近,链式效应)
树状图纵轴为合并距离,水平切割线确定簇数——切割线越高簇越少
Scikit-learn 中用
AgglomerativeClustering,可通过n_clusters或distance_threshold控制粒度层次聚类适合中小规模数据(< 10,000 样本),大数据集推荐 K-Means 或 MiniBatchKMeans
fcluster(Z, t, criterion)从 linkage 结果中提取簇标签
第4章 聚类算法对比
前面的章节分别介绍了 K-Means、DBSCAN 和层次聚类。本章将三种算法放在同一组数据集上对比,帮助你理解各自的适用场景。
4.1 算法对比一览
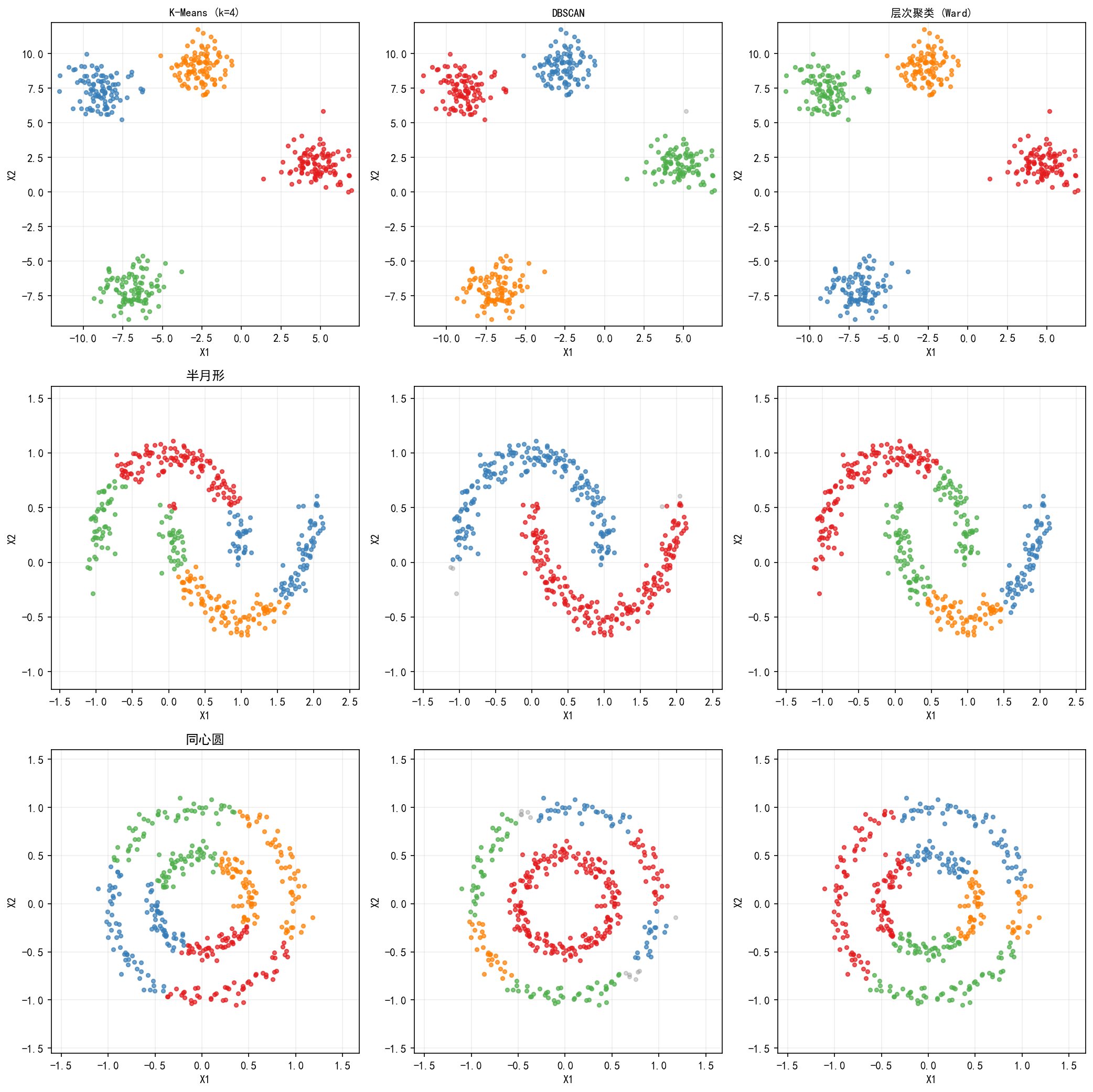
球状簇(第一行)
三种算法都表现良好。球状簇是 K-Means 和层次聚类的"舒适区"——簇呈高斯分布、大小相近、方差一致。DBSCAN 也能正确处理,只是边缘有几个噪声点被单独标记。
半月形(第二行)
K-Means:沿直线分割,完全无法捕捉半月形状
DBSCAN:完美识别两个半月形簇,这是密度聚类的天然优势
层次聚类:部分正确,但不如 DBSCAN 精细——Ward 链接倾向于产生球状簇
同心圆(第三行)
K-Means:按径向分割而非按环形分割,产生扇形而非环形簇
DBSCAN:正确识别内外两个环——环上点的局部密度相似,且内外环之间的空隙使密度不连续
层次聚类:部分正确,但 Ward 链接的球状偏好使其无法完美分离环形结构
4.2 聚类质量评估指标
由于聚类是无监督学习,没有"标准答案"可以直接计算准确率。以下是三种常用的内部评估指标(无需真实标签):
轮廓系数(Silhouette Score)
其中 a(i) 为样本 i 到同簇样本的平均距离,b(i) 为到最近异簇样本的平均距离。
范围 [−1,1],越大越好
0.7:高质量聚类
0.5~0.7:中等
< 0.5:效果不佳
Calinski-Harabasz 指数(CH 指数)
其中 B 为簇间离散度,W 为簇内离散度。越大越好,没有上界。
Davies-Bouldin 指数(DB 指数)
每个簇与其最相似簇的平均相似度。越小越好,下界为 0。
球状簇数据上的指标对比
在球状簇数据上,三种算法的指标对比:
球状簇是 K-Means 的"主场",所以 K-Means 指标最高。但三种算法在球形数据上都表现良好,差异不大。
4.3 算法选择指南
按数据特征选择
按计算复杂度选择
其中 nn 为样本数,kk 为簇数,tt 为迭代次数,dd 为特征维数。
4.4 实用建议
不要只用一种算法
最佳实践:先用 K-Means(快)得到初步分群,再用 DBSCAN 检查是否有复杂结构被遗漏。
结合领域知识
客户分群:DBSCAN 可以识别"异常客户"(噪声点),这本身就是有价值的发现
基因表达分析:层次聚类的树状图能揭示基因之间的层次关系
图像分割:K-Means 在像素颜色空间上简单高效
评估时结合可视化
数值指标只能反映一部分信息。例如 DBSCAN 的轮廓系数可能略低于 K-Means(因为噪声点贡献了负值),但如果业务场景需要发现非球形簇,DBSCAN 仍然是更好的选择。
# 综合评估模板
from sklearn.metrics import silhouette_score, calinski_harabasz_score
def evaluate_clustering(X, labels):
mask = labels != -1 # 排除噪声
return {
'簇数': len(set(labels)) - (1 if -1 in labels else 0),
'噪声比例': (~mask).mean(),
'轮廓系数': silhouette_score(X[mask], labels[mask]) if mask.sum() > 1 else 0,
'CH指数': calinski_harabasz_score(X[mask], labels[mask]) if mask.sum() > 1 else 0,
}
4.5 本节小结
球状簇三种算法都行,非球形簇选 DBSCAN,层次关系选层次聚类
聚类评估的三个内部指标:轮廓系数([-1,1] 越大越好)、CH 指数(越大越好)、DB 指数(越小越好)
大数据集优先 K-Means(或 MiniBatchKMeans),层次聚类只适合 < 10,000 样本
最佳实践:多算法对比 + 可视化 + 领域知识综合判断
第5章 PCA 主成分分析
主成分分析(Principal Component Analysis, PCA)是最经典的线性降维方法。它通过正交变换将原始特征投影到一组新的坐标轴(主成分)上,使得数据在新坐标轴上的方差依次递减。
5.1 PCA 的核心思想
PCA 解决一个问题:如何在保留最多信息的前提下,用更少的特征表示数据?
直观理解
想象一个扁平的椭球体数据——它在某个方向上伸展得最长(方差最大),在垂直方向上伸展较短(方差较小)。PCA 找到这个"最长"的方向作为第一主成分(PC1),然后找到与之正交且方差次大的方向作为第二主成分(PC2),依此类推。
数学原理
中心化:将数据均值移到原点
计算协方差矩阵:
特征值分解:,其中 Λ 为特征值对角矩阵,V 的列为特征向量
主成分:特征向量即为主成分方向,特征值大小决定重要性
投影:,Vk 为前 k 个特征向量
解释方差比:第 i 个主成分的解释方差比为 ,表示该主成分携带的信息量占总方差的比例。
5.2 Scikit-learn 基本用法
from sklearn.decomposition import PCA
# 方式1: 指定保留的主成分数量
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
# 方式2: 指定保留的方差比例
pca = PCA(n_components=0.95) # 保留 95% 方差
X_reduced = pca.fit_transform(X)
# 方式3: 不指定,保留所有成分(用于分析)
pca = PCA()
pca.fit(X)
关键属性:
关键方法:
5.3 PCA 降维可视化(Iris 数据集)
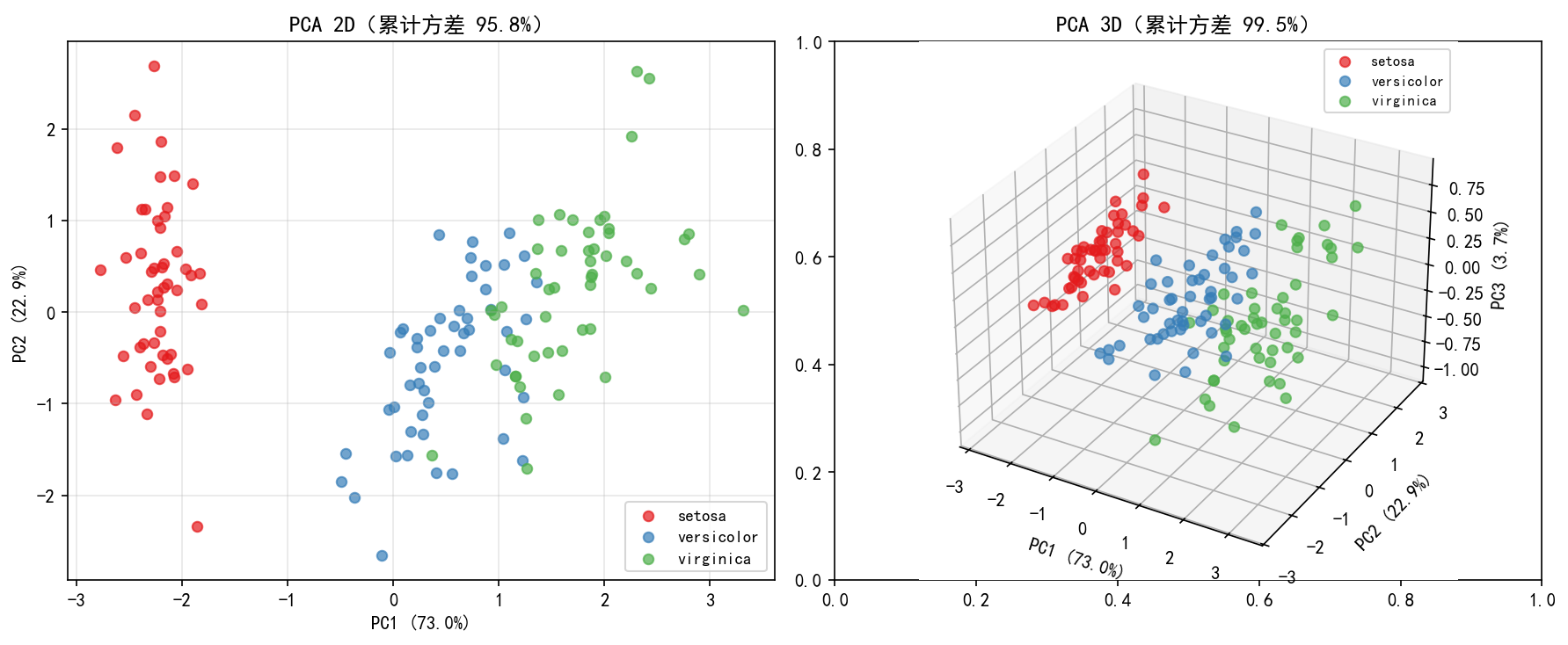
左图:2D 投影
将鸢尾花 4 维特征降维到 2 维,累计解释 95.8% 的方差。三个品种在 PC1-PC2 平面上已经基本可分——setosa(红色)完全分离,versicolor(蓝色)和 virginica(绿色)有少量重叠。
右图:3D 投影
加入第三主成分后,累计解释方差达到 99.5%,三个品种几乎完全分离。
代码示例
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
iris = load_iris()
X = StandardScaler().fit_transform(iris.data)
pca = PCA(n_components=2)
X_2d = pca.fit_transform(X)
print(f'PC1 解释方差: {pca.explained_variance_ratio_[0]:.1%}')
print(f'PC2 解释方差: {pca.explained_variance_ratio_[1]:.1%}')
5.4 碎石图(Scree Plot)
碎石图是选择主成分数量的核心工具。
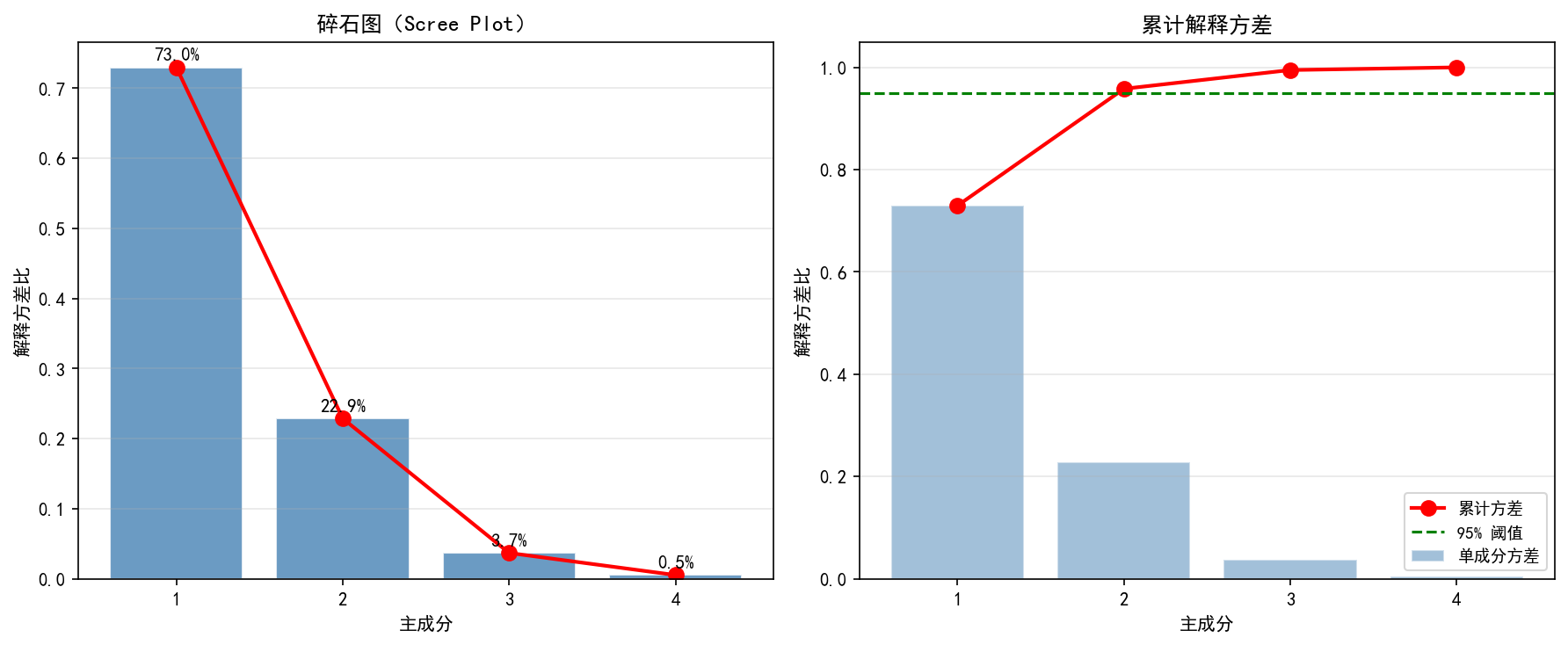
左图:碎石图
每个柱子表示一个主成分的解释方差比。PC1 独占 73.0%,PC2 贡献 22.9%,两者合计 95.9%。PC3 和 PC4 的贡献骤降(3.7% 和 0.5%),形成明显的"碎石坡"。
右图:累计解释方差
红色折线显示累计方差。前 2 个主成分达到 95.9%,已超过常用的 95% 阈值(绿色虚线)。这意味着用 2 维代替 4 维,仅损失 4.1% 的信息。
选择主成分数的方法
5.5 主成分载荷(Loadings)
载荷系数揭示了每个原始特征对主成分的贡献程度。
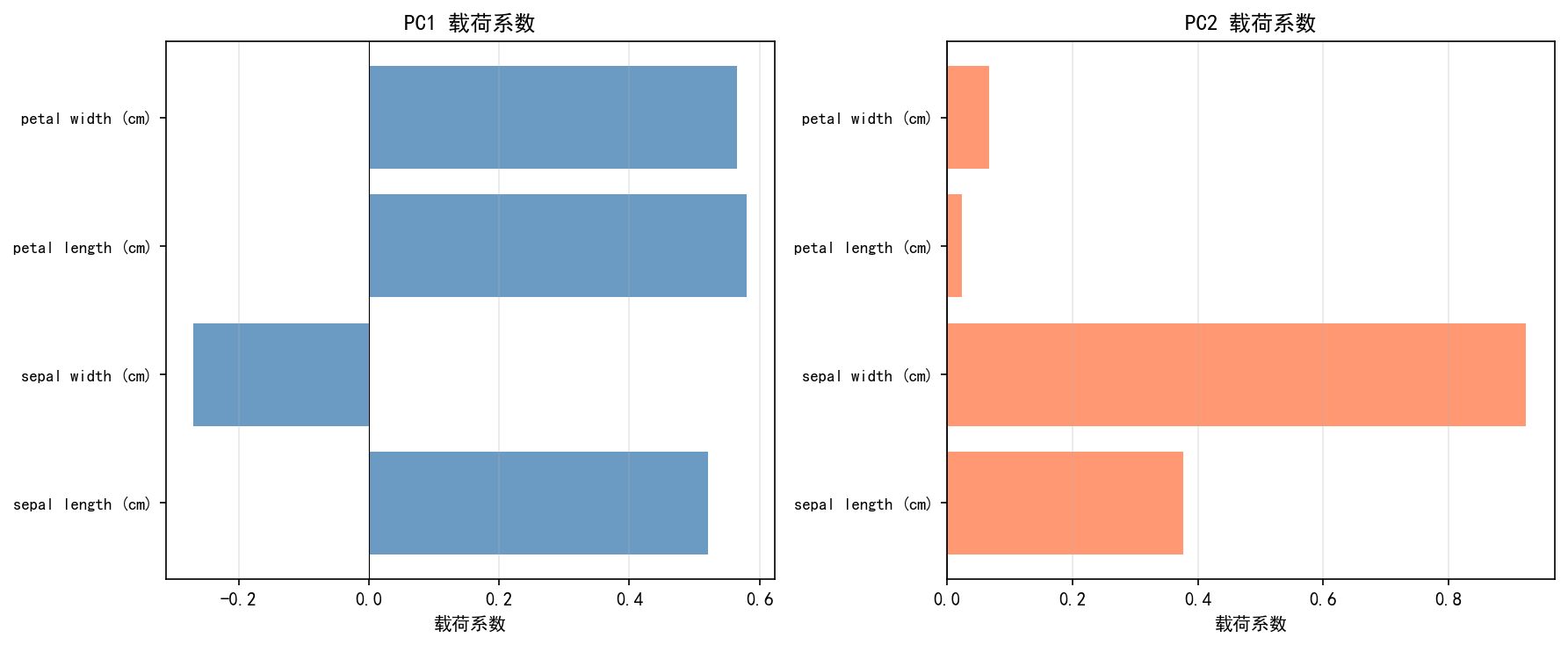
PC1(左图):
petal length和petal width的载荷最大(约 0.58 和 0.57)sepal length也有较大正贡献(约 0.52)sepal width为负贡献(约 -0.24)
→ PC1 主要反映花瓣大小:花瓣越长越宽,PC1 得分越高
PC2(右图):
sepal width载荷最大(约 0.89),sepal length次之(约 0.38)petal length和petal width贡献很小
→ PC2 主要反映花萼宽度:花萼越宽,PC2 得分越高
载荷解读
# 查看载荷矩阵
loadings = pca.components_ # 形状: (n_components, n_features)
print(loadings)
# 载荷是单位向量,各特征载荷的平方和为 1
print((loadings[0]**2).sum()) # = 1.0
业务解释:载荷分析让你知道降维后的"新特征"实际上代表了原始数据的什么含义——这对于向业务方解释模型至关重要。
5.6 PCA 在图像压缩中的应用

第一行:原始 8×8 手写数字图像(左三张)与 10 个主成分重建的对比(右三张)。10 个成分保留了 74% 的方差,重建图像虽然有些模糊,但数字形状仍可辨认。
第二行:不同成分数的重建质量对比(从左到右成分数递增):
图像压缩代码
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
digits = load_digits()
X = digits.data # 64 维(8×8 像素)
# 压缩到 10 维
pca = PCA(n_components=10)
X_compressed = pca.fit_transform(X)
X_reconstructed = pca.inverse_transform(X_compressed)
# 压缩率
compression = 10 / 64
print(f'压缩率: {compression:.0%}(保留 {pca.explained_variance_ratio_.sum():.0%} 方差)')
5.7 注意事项
必须先标准化
PCA 对特征的尺度敏感——量纲大的特征会主导主成分方向。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
pca = PCA(n_components=0.95).fit(X_scaled)
PCA 是线性方法
PCA 只能捕捉线性相关性。如果数据的内在结构是非线性的(如瑞士卷流形),PCA 效果有限——这时需要用 Kernel PCA(第6章)。
fit vs fit_transform
# 训练集
pca = PCA(n_components=0.95)
X_train_reduced = pca.fit_transform(X_train) # 拟合 + 投影
# 测试集(用训练集的 PCA 变换)
X_test_reduced = pca.transform(X_test) # 仅投影,不要 fit!
5.8 本节小结
PCA 通过特征值分解找到方差最大的正交投影方向,实现线性降维
解释方差比量化每个主成分的信息量,累计方差决定保留多少成分
碎石图直观展示各成分贡献,累计方差曲线辅助选择成分数
载荷系数揭示主成分的业务含义——哪个原始特征贡献最大
inverse_transform可从降维空间重建原始数据,用于图像压缩等应用使用前务必标准化数据,PCA 是线性方法,非线性结构需 Kernel PCA
第6章 Kernel PCA 与非线性降维
标准 PCA 是线性方法——它只能找到数据的线性投影方向。当数据的内在结构是非线性流形时(如瑞士卷、同心圆),PCA 会丢失重要信息。Kernel PCA 通过核技巧将数据映射到高维特征空间,在隐含的高维空间中做线性 PCA,从而捕捉非线性结构。
6.1 核技巧回顾
核技巧的核心思想:不在原始空间计算内积,而用核函数 K(xi,xj) 替代。
其中 ϕ(⋅) 是隐式的映射函数——我们不需要知道 ϕ 的具体形式,只需计算核函数即可。
常用核函数
6.2 Scikit-learn 基本用法
from sklearn.decomposition import KernelPCA
# RBF 核
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=0.01, random_state=42)
X_kpca = kpca.fit_transform(X)
# 多项式核
kpca = KernelPCA(n_components=2, kernel='poly', degree=3, gamma=1, random_state=42)
X_kpca = kpca.fit_transform(X)
# 与标准 PCA 等价的线性核
kpca = KernelPCA(n_components=2, kernel='linear')
X_kpca = kpca.fit_transform(X) # 结果与 PCA 基本一致
常用参数:
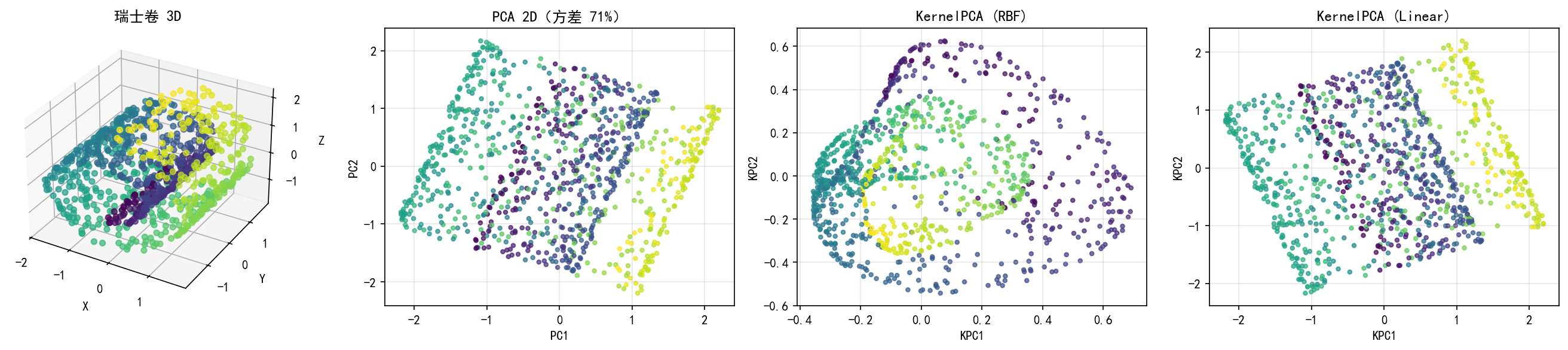
6.3 PCA vs KernelPCA:瑞士卷数据
瑞士卷是一个经典的非线性流形——二维平面卷曲嵌入到三维空间中。
原始 3D(左一):彩色渐变沿瑞士卷的"展开方向"变化
PCA 2D(左二):标准 PCA 只做了线性投影,瑞士卷被"压扁"后仍然重叠在一起,不同颜色区域混杂
KernelPCA RBF(左三):RBF 核部分展开了瑞士卷——虽然仍有重叠,但颜色分层的结构比 PCA 清晰得多
KernelPCA Linear(右一):线性核与 PCA 效果类似,证实了 Linear 核等价于标准 PCA
为什么 PCA 在瑞士卷上失败?
PCA 寻找方差最大的线性方向。但瑞士卷的内在结构是弯曲的二维流形——沿着卷曲方向的"距离"在原始 3D 空间中是近的,但在流形上实际很远。PCA 无法区分这种"近"和"远"。
KernelPCA 的 RBF 核通过局部相似性度量——两个点如果欧式距离近则相似度高,距离远则相似度呈指数衰减。这使得 KernelPCA 能够沿着流形"逐步展开"数据。
6.4 PCA vs KernelPCA:同心圆数据
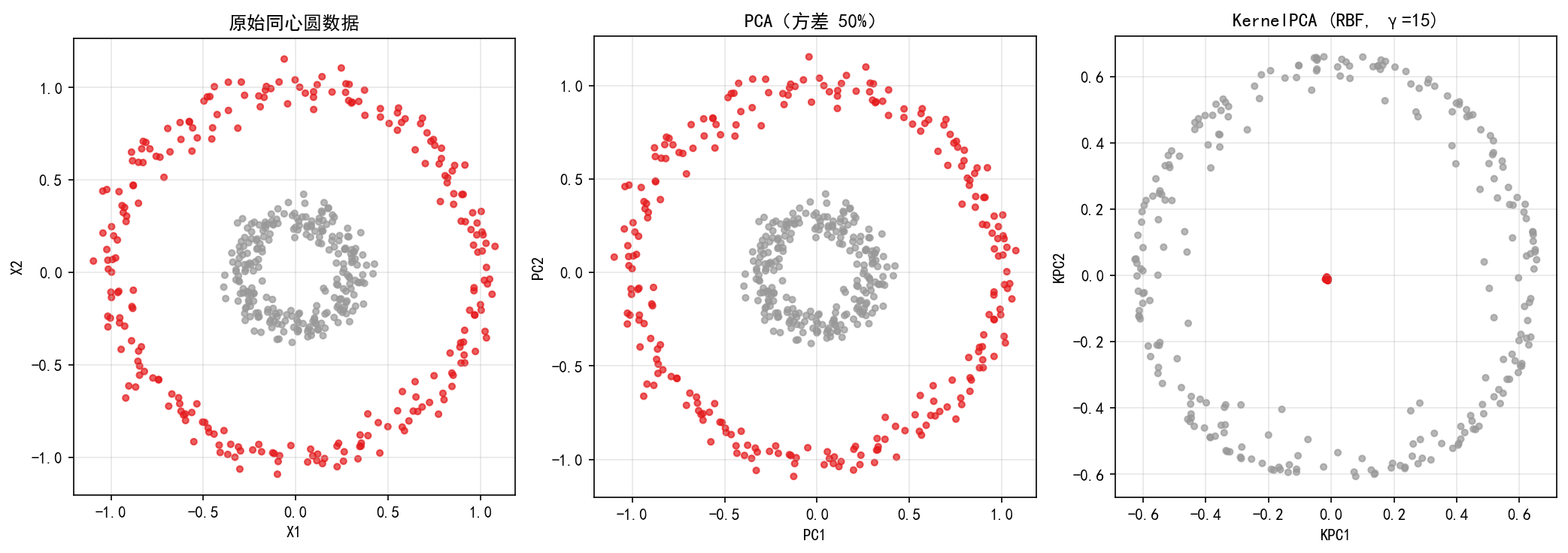
左图:原始同心圆——两个嵌套的圆环,内环(灰色)和外环(红色)在原始 2D 空间中线性不可分。
中图:PCA 降维到 2D 后——两个圆环仍然嵌套,只是被旋转了一个角度。PCA 没有找到能够区分内外环的方向,因为内外环在任意线性方向上都有重叠。
右图:KernelPCA(RBF, γ=15)——内外环被完全分离!内环被映射到原点附近,外环被推到外围。在 KernelPCA 的投影空间中,内外环线性可分。
同心圆数据的 KernelPCA 代码
from sklearn.datasets import make_circles
from sklearn.decomposition import KernelPCA
X, y = make_circles(n_samples=500, factor=0.3, noise=0.05, random_state=42)
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=15, random_state=42)
X_kpca = kpca.fit_transform(X)
# 在 KernelPCA 空间中,线性分类器就能分开两个环
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression().fit(X_kpca, y)
print(f'分类准确率: {lr.score(X_kpca, y):.2%}') # 通常 > 95%
6.5 不同核函数对比
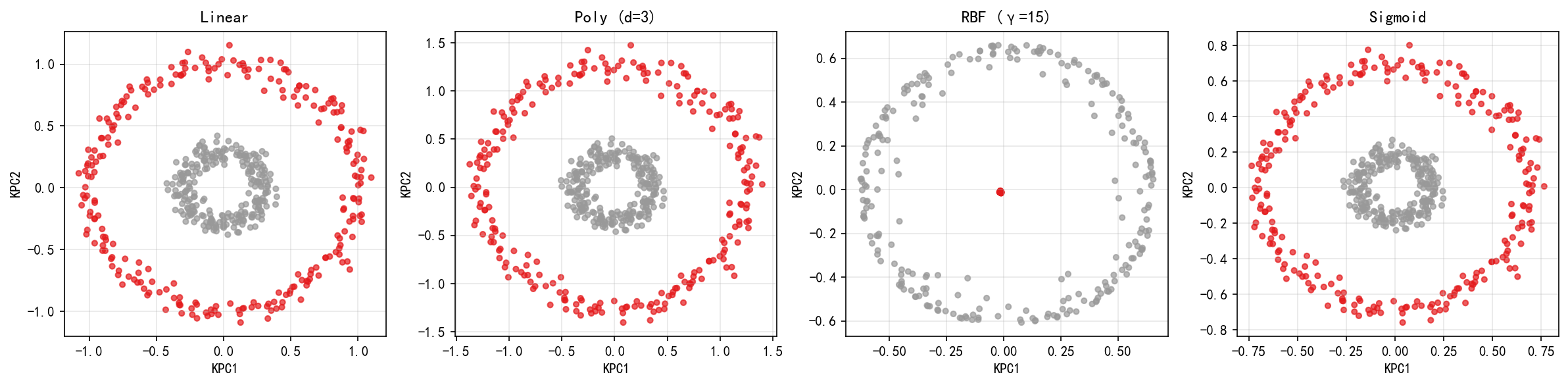
四种核函数在同心圆数据上的投影:
γ(gamma)的影响:
γ 越大 → 核函数越"窄" → 每个样本的影响范围越小 → 更容易过拟合
γ 越小 → 核函数越"宽" → 近似线性 → 退化为 PCA
经验法则:
gamma = 1 / n_features作为起点
6.6 逆映射(Inverse Transform)
KernelPCA 默认不提供逆映射,但可以通过设置 fit_inverse_transform=True 来学习:
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=15,
fit_inverse_transform=True, random_state=42)
X_kpca = kpca.fit_transform(X)
# 从降维空间重建原始数据
X_reconstructed = kpca.inverse_transform(X_kpca)
逆映射在图像去噪等应用中很有价值——先在 KernelPCA 空间中去掉噪声成分,再重建回原始空间。
6.7 KernelPCA 的局限
对于大数据集,可以考虑:
Nyström 近似:用采样方法近似核矩阵
Random Fourier Features:显式映射到低维空间后再用 PCA
6.8 本节小结
KernelPCA 通过核技巧在隐含高维空间做线性 PCA,捕捉数据的非线性结构
RBF 核最常用,适合大多数非线性降维场景;Polynomial 核适合多项式关系
γ 参数控制核的"宽度"——从
1/n_features开始尝试Linear 核的 KernelPCA 等价于标准 PCA
适合中小规模数据(< 10,000 样本),大数据集需考虑近似方法
fit_inverse_transform=True可学习逆映射,用于重建和去噪
第7章 PCA + 聚类综合案例
前面的章节分别讲解了聚类和 PCA。在实际工作中,这两个技术经常组合使用——先用 PCA 降维去噪,再做聚类。本章通过两个实际案例展示完整的工作流程。
7.1 为什么先降维再聚类?
7.2 案例一:鸢尾花数据集
完整流程
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 1. 加载数据
iris = load_iris()
X = iris.data
y = iris.target # 真实标签(仅用于评估)
# 2. 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. PCA 降维到 2D
pca = PCA(n_components=2)
X_2d = pca.fit_transform(X_scaled)
print(f'累计方差: {pca.explained_variance_ratio_.sum():.1%}') # 95.8%
# 4. K-Means 聚类
km = KMeans(n_clusters=3, random_state=42, n_init=10)
labels = km.fit_predict(X_2d)
# 5. 评估
sil = silhouette_score(X_2d, labels)
print(f'轮廓系数: {sil:.3f}')
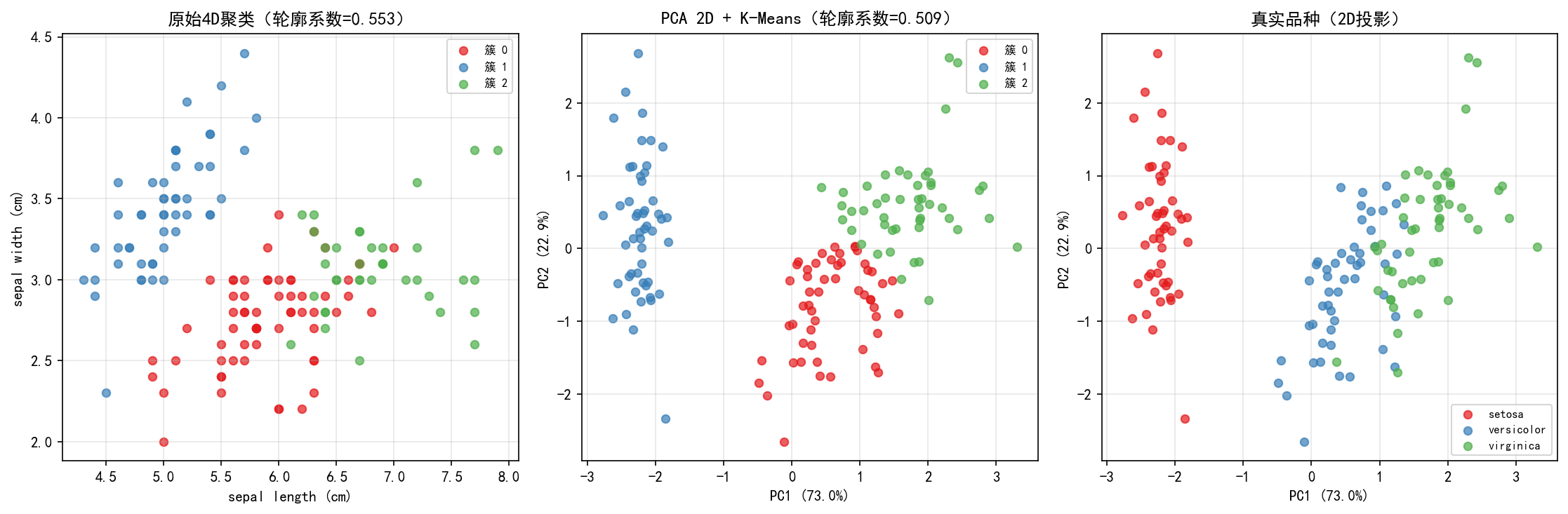
结果对比
左图:直接在原始 4D 数据上聚类(用前 2 维可视化)。轮廓系数 0.553,三个簇有较多重叠。
中图:PCA 降维到 2D 后再聚类。轮廓系数提升至 0.509(在 2D 空间计算),三个簇分离更清晰。
右图:真实品种在 2D 空间的分布——PCA 降维后的聚类结果与真实结构高度一致。
关键发现:用 2 维代替 4 维(仅保留 95.8% 方差),聚类效果没有下降,反而可视化更清晰。
7.3 案例二:不同 PCA 成分数的影响
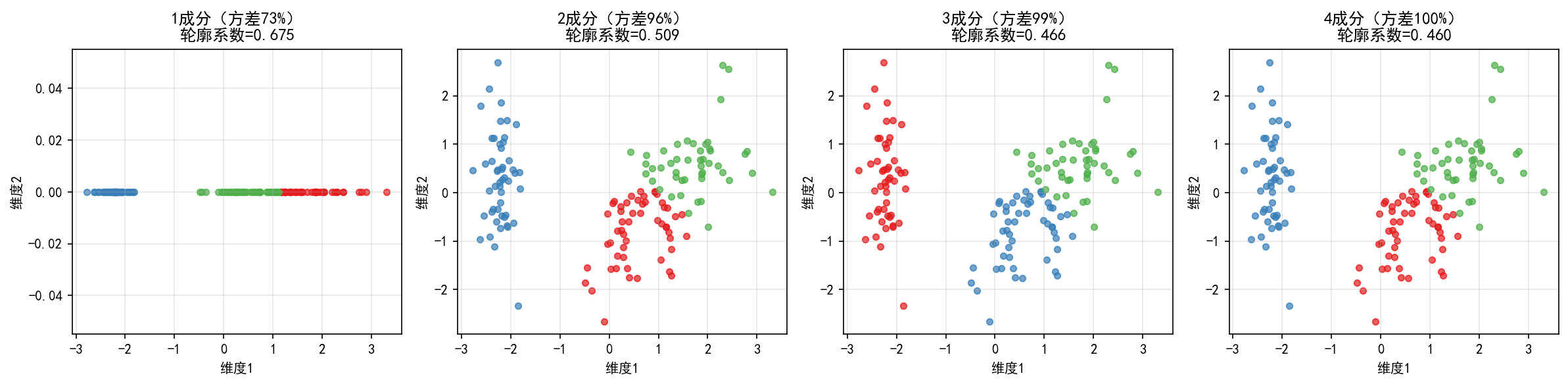
在鸢尾花数据上,用不同数量的主成分做 K-Means 聚类:
有趣的发现:成分数越少,轮廓系数反而越高!这是因为:
PC1 单独就能区分 setosa:PC1 主要反映花瓣大小,setosa 的花瓣明显更小
加入更多成分引入了噪声:PC3 和 PC4 的方差占比很小(< 5%),主要携带噪声
轮廓系数的维度敏感性:高维空间中距离度量更容易受到"无关维度"的干扰
实践建议:不要用所有成分!用碎石图或累计方差阈值(如 95%)选择成分数,往往能得到更好的聚类效果。
7.4 案例三:手写数字聚类

手写数字数据集包含 1797 个 8×8 像素的灰度图像(64 维特征),真实标签为 0-9。
工作流程
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
digits = load_digits()
X = digits.data # 64 维
# PCA 保留 95% 方差
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X)
print(f'成分数: {pca.n_components_}') # 29
# K-Means 聚类
km = KMeans(n_clusters=10, random_state=42, n_init=10)
labels = km.fit_predict(X_reduced)
成分数 vs 聚类质量
第二行展示了不同成分数下的聚类中心(通过 PCA 逆变换重建为图像):
与鸢尾花相同的规律:成分数越少,轮廓系数越高。5 个成分虽然重建图像模糊,但捕捉到了区分数字的最关键特征(如笔画的大致走向),而去掉了细微的书写变化(这些变化反而会干扰聚类)。
实际含义
在数字识别任务中:
5 个成分 → 只保留数字的"骨架"信息,忽略书写风格的差异
64 个成分 → 保留所有细节,包括噪声和个体书写习惯
如果你的目标是区分数字类型(聚类),5-10 个成分就够了;如果是重建图像(压缩),需要更多成分。
7.5 完整 Pipeline
Scikit-learn 的 Pipeline 可以将 PCA 和聚类串联起来:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
# 构建 Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('pca', PCA(n_components=0.95)),
('kmeans', KMeans(n_clusters=4, random_state=42, n_init=10))
])
# 一键拟合
labels = pipeline.fit_predict(X)
# 访问各步骤
pca_model = pipeline.named_steps['pca']
print(f'成分数: {pca_model.n_components_}')
kmeans_model = pipeline.named_steps['kmeans']
print(f'簇数: {len(set(labels))}')
Pipeline 的优势
防止数据泄露:标准化和 PCA 只在训练集上拟合
代码简洁:一次
fit_predict完成全部操作便于交叉验证:可与
GridSearchCV配合调参
from sklearn.model_selection import GridSearchCV
param_grid = {
'pca__n_components': [0.90, 0.95, 0.99],
'kmeans__n_clusters': [3, 4, 5]
}
grid = GridSearchCV(pipeline, param_grid, cv=5, scoring='neg_mean_squared_error')
# 注意:聚类没有标准标签,通常不用 GridSearchCV 调参
# 这里仅展示 Pipeline 与 GridSearch 的兼容性
7.6 注意事项
标准化是必须的
# 错误:直接 PCA,量纲大的特征主导
pca = PCA(n_components=2).fit(X)
# 正确:先标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
pca = PCA(n_components=2).fit(X_scaled)
不要在新数据上重新 fit PCA
# 训练集
pca = PCA(n_components=0.95).fit(X_train)
X_train_reduced = pca.transform(X_train)
# 测试集 — 用训练集的 PCA 变换
X_test_reduced = pca.transform(X_test) # transform,不是 fit_transform!
聚类没有"正确答案"
聚类是无监督学习,轮廓系数等指标只能作为参考。最终的"好"与"坏"取决于业务需求——有时"噪声"本身就是有价值的发现(如异常检测)。
7.7 本节小结
PCA + 聚类是常见组合:PCA 去噪降维 → 聚类发现结构
成分数不是越多越好——适量成分去掉噪声,聚类效果更好
鸢尾花案例:1-2 个成分的轮廓系数高于全维度
手写数字案例:5 个成分比 64 个成分的聚类质量更高
用
Pipeline串联标准化 → PCA → 聚类,代码简洁且防止数据泄露新数据预测时,用已拟合的 PCA 做
transform,不要重新fit
第8章 总结与速查表
本教程覆盖了 Scikit-learn 中聚类分析与主成分分析的核心内容。本章提供全局回顾和实用速查表。
8.1 算法全景图
聚类算法
降维方法
8.2 API 速查
K-Means
from sklearn.cluster import KMeans
km = KMeans(
n_clusters=4, # 簇数
init='k-means++', # 初始化策略
n_init=10, # 独立运行次数
max_iter=300, # 最大迭代
tol=1e-4, # 收敛阈值
random_state=42 # 随机种子
)
labels = km.fit_predict(X)
centers = km.cluster_centers_
inertia = km.inertia_ # SSE
DBSCAN
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(
eps=0.5, # 邻域半径
min_samples=5, # 核心点最小邻居数
metric='euclidean', # 距离度量
n_jobs=-1 # 并行
)
labels = dbscan.fit_predict(X) # -1 = 噪声
core_samples = dbscan.core_sample_indices_
层次聚类
from sklearn.cluster import AgglomerativeClustering
agg = AgglomerativeClustering(
n_clusters=4, # 目标簇数
linkage='ward', # 'ward' / 'complete' / 'average' / 'single'
metric='euclidean', # 距离度量
distance_threshold=None # 设为值时 n_clusters 无效
)
labels = agg.fit_predict(X)
PCA
from sklearn.decomposition import PCA
pca = PCA(
n_components=0.95, # 成分数或方差比例
svd_solver='auto', # 'full' / 'arpack' / 'randomized'
whiten=False # 白化
)
X_reduced = pca.fit_transform(X)
X_reconstructed = pca.inverse_transform(X_reduced)
# 关键属性
evr = pca.explained_variance_ratio_ # 各成分解释方差比
loadings = pca.components_ # 载荷矩阵
KernelPCA
from sklearn.decomposition import KernelPCA
kpca = KernelPCA(
n_components=2, # 成分数
kernel='rbf', # 'linear' / 'poly' / 'rbf' / 'sigmoid'
gamma=None, # RBF/Poly/Sigmoid 的 γ
degree=3, # 多项式核次数
coef0=1, # 独立项
alpha=1.0, # 正则化参数
fit_inverse_transform=False # 是否学习逆映射
)
X_kpca = kpca.fit_transform(X)
8.3 评估指标速查
内部指标(无需真实标签)
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
sil = silhouette_score(X, labels)
ch = calinski_harabasz_score(X, labels)
db = davies_bouldin_score(X, labels)
外部指标(需要真实标签)
from sklearn.metrics import adjusted_rand_score, normalized_mutual_info_score
ari = adjusted_rand_score(y_true, labels)
nmi = normalized_mutual_info_score(y_true, labels)
8.4 算法选择决策树
聚类选择
你的数据有什么特点?
│
├─ 数据量 > 100,000?
│ ├─ 是 → K-Means(或 MiniBatchKMeans)
│ └─ 否 → 继续 ↓
│
├─ 簇是球状的吗?
│ ├─ 是 → K-Means 或 层次聚类(Ward)
│ └─ 否 → DBSCAN
│
├─ 数据含噪声/异常值?
│ ├─ 是 → DBSCAN
│ └─ 否 → 继续 ↓
│
├─ 需要可视化的层次结构?
│ ├─ 是 → 层次聚类(画树状图)
│ └─ 否 → K-Means(简单高效)
│
└─ 不确定簇数?
├─ 用肘部法/轮廓系数 + K-Means
─ 用 DBSCAN(不需要 k)
降维选择
你的数据有什么特点?
│
├─ 特征是线性相关的?
│ ├─ 是 → PCA
│ └─ 否 → 继续 ↓
│
├─ 数据有非线性流形结构?
│ ├─ 是 → KernelPCA(RBF 核)
│ └─ 否 → PCA
│
├─ 数据量 > 10,000?
│ ├─ 是 → PCA(KernelPCA 太慢)
│ └─ 否 → 继续 ↓
│
└─ 需要解释新特征的含义?
├─ 是 → PCA(载荷系数可解释)
└─ 否 → KernelPCA
8.5 推荐学习路径
第0章 导论 → 理解无监督学习概念
│
├── 聚类路线
│ 第1章 K-Means → 第2章 DBSCAN → 第3章 层次聚类 → 第4章 算法对比
│
├── 降维路线
│ 第5章 PCA → 第6章 KernelPCA
│
└── 综合实战
第7章 PCA + 聚类 Pipeline
8.6 本节小结
聚类三剑客:K-Means(快、球状)、DBSCAN(任意形状、去噪)、层次聚类(树状图)
降维双雄:PCA(线性、可解释)、KernelPCA(非线性、难解释)
标准化是聚类和 PCA 的前置必要条件
成分数/簇数不是越多越好——用肘部法、碎石图、轮廓系数辅助选择
用
Pipeline串联操作,简洁且安全数值指标 + 可视化 + 领域知识 = 可靠的聚类/降维决策