
入门篇:Numpy和Pandas数据处理入门
前言
Python 的数据科学生态中,NumPy 和 Pandas 是不可或缺的两大基石——前者提供了高性能的多维数组和数学运算能力,后者提供了灵活强大的数据框操作接口。无论是数据清洗、探索性分析、特征工程,还是模型输入准备,几乎所有数模流程的第一步都离不开这两个库。
然而,许多同学在初学时会面临以下困扰:
NumPy 的广播机制、花式索引等概念抽象,难以直观理解
Pandas 的
.loc与.iloc、merge与concat、agg与transform等易混淆操作缺乏清晰对比缺失值处理、异常值检测、标准化等预处理方法"知道概念但不会写代码"
网上教程要么太浅(仅罗列函数名),要么太深(涉及底层实现),缺少面向数模实战的中间层指南
本教程的编写初衷正是为了解决这一问题——用一套系统、实用、可直接上手的指南,覆盖数学建模中最常用的 NumPy、Pandas 核心操作与数据预处理方法。
适用读者
准备参加数学建模竞赛(如美赛、国赛、MathorCup、泰迪杯等),需要用 Python 处理数据的同学
刚接触 Python 数据分析,希望系统掌握 NumPy 和 Pandas 的初学者
会一些 Python 基础但数据处理经验不足,需要快速补齐技能的同学
内容结构
本教程共分为 4 章,按照"先基础、后方法、再实战"的逻辑组织:
编写特点
理论 + 代码 + 可视化三位一体:每个知识点先讲原理和公式,再给可运行代码,最后配可视化图表和结果解读
中文字体开箱即用:所有示例代码均已配置中文字体,图表中的中文标题和标签正常显示
速查表驱动:每章末尾附有速查表,方便在实际使用时快速查阅
数模场景导向:所有示例均围绕数学建模的真实场景设计,如蒙特卡洛求 π、投入产出模型、GPA 计算等
代码可运行:每段代码都是完整的、可独立运行的脚本,附有对应的输出图片
前置要求
Python 基础语法(变量、循环、函数、列表/字典)
已安装
numpy、pandas、matplotlib、scikit-learn四个库
如果你还没有安装这些库,可以使用
pip install numpy pandas matplotlib scikit-learn一键安装,或使用 Anaconda(已内置上述所有库)。
如何使用本教程
建议初学者按顺序阅读第 1 章和第 2 章,掌握 NumPy 和 Pandas 的基本操作后再进入第 3 章的数据预处理方法。第 4 章的实战案例可作为综合练习,也可以直接跳到你感兴趣的预处理方法章节。每章内容相对独立,可以作为工具书按需查阅。
祝学习愉快!
第 1 章 NumPy 核心
NumPy(Numerical Python)是 Python 科学计算的基石。它提供了一个高性能的多维数组对象 ndarray,以及大量用于数组运算的数学函数。在数学建模中,几乎所有数据处理和数值计算都直接或间接依赖于 NumPy。
1.1 数组创建与基本属性
ndarray 是什么
ndarray(N-dimensional array)是 NumPy 的核心数据结构,它与 Python 原生 list 的关键区别在于:
同质性:所有元素必须是相同数据类型(
dtype)固定大小:创建后不能动态改变大小
内存连续:数据在内存中连续存储,支持 C 级别的向量化运算
常用创建函数
import numpy as np
# 从列表创建
a = np.array([1, 2, 3, 4])
# 零矩阵 / 全 1 矩阵
zeros = np.zeros((3, 4)) # 3 行 4 列的全 0 数组
ones = np.ones((2, 3)) # 2 行 3 列的全 1 数组
# 单位矩阵 / 对角矩阵
eye = np.eye(4) # 4×4 单位矩阵
diag = np.diag([1, 2, 3]) # 对角线为 [1,2,3] 的矩阵
# 等间距数组
ar = np.arange(0, 10, 2) # [0, 2, 4, 6, 8],步长为 2
lin = np.linspace(0, 1, 5) # [0., 0.25, 0.5, 0.75, 1.],含端点
# 随机数组
rand = np.random.rand(3, 3) # 3×3 的 [0,1) 均匀分布随机数
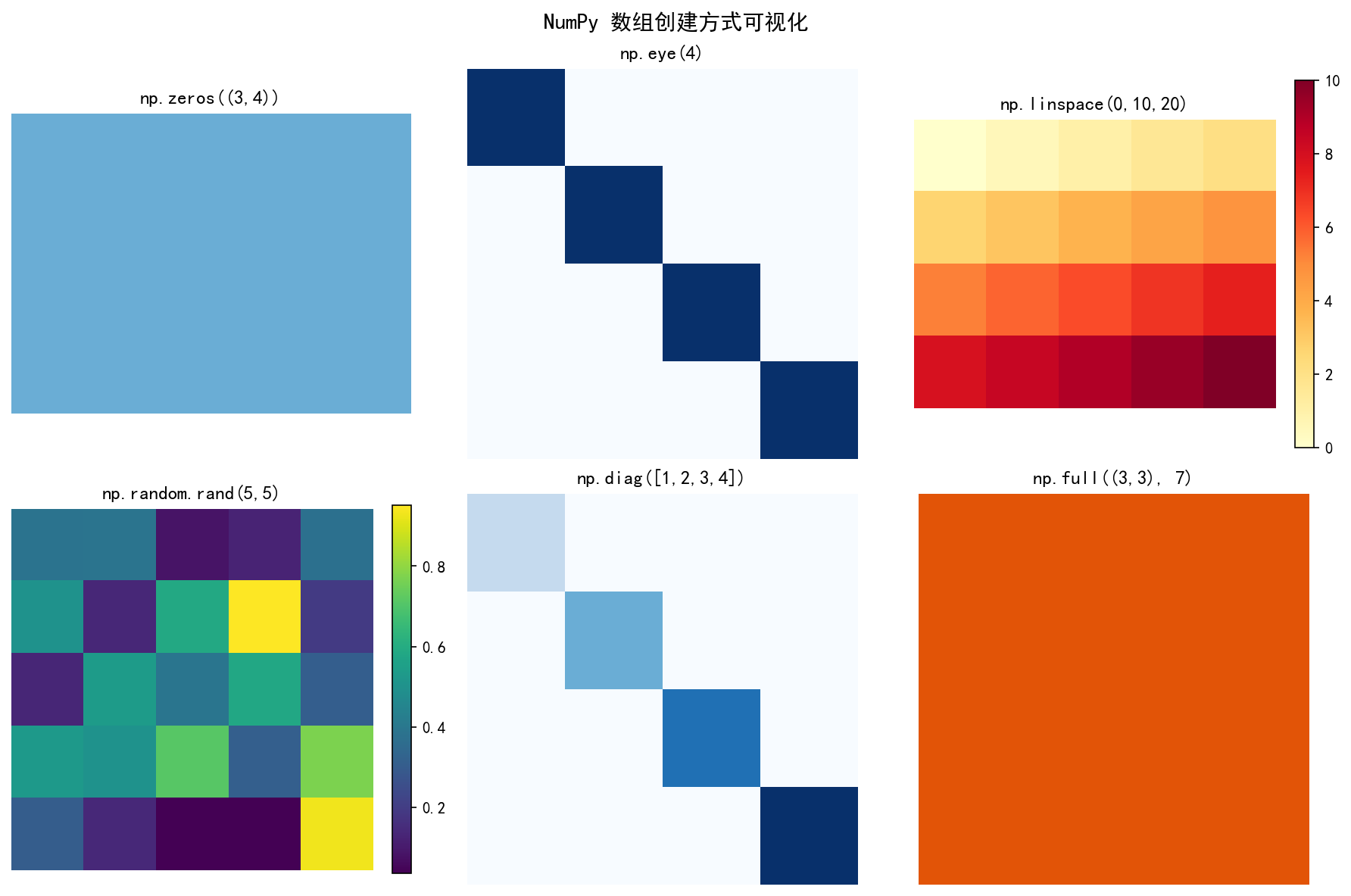
常用创建函数的对比:
数组基本属性
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.shape) # (2, 3) — 形状:2 行 3 列
print(a.ndim) # 2 — 维度数
print(a.dtype) # int32 — 元素数据类型
print(a.size) # 6 — 元素总数
1.2 索引与切片
NumPy 的索引与 Python 列表类似,但支持多维操作和高级索引方式。
基本索引与切片
a = np.arange(1, 26).reshape(5, 5)
# array([[ 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10],
# [11, 12, 13, 14, 15],
# [16, 17, 18, 19, 20],
# [21, 22, 23, 24, 25]])
# 单个元素
a[0, 0] # 1
a[2, 3] # 14
# 切片:取第 1~3 行、第 1~3 列
a[1:4, 1:4]
# array([[ 7, 8, 9],
# [12, 13, 14],
# [17, 18, 19]])
# 取整行 / 整列
a[0, :] # [ 1, 2, 3, 4, 5] — 第 1 行
a[:, 2] # [ 3, 8, 13, 18, 23] — 第 3 列
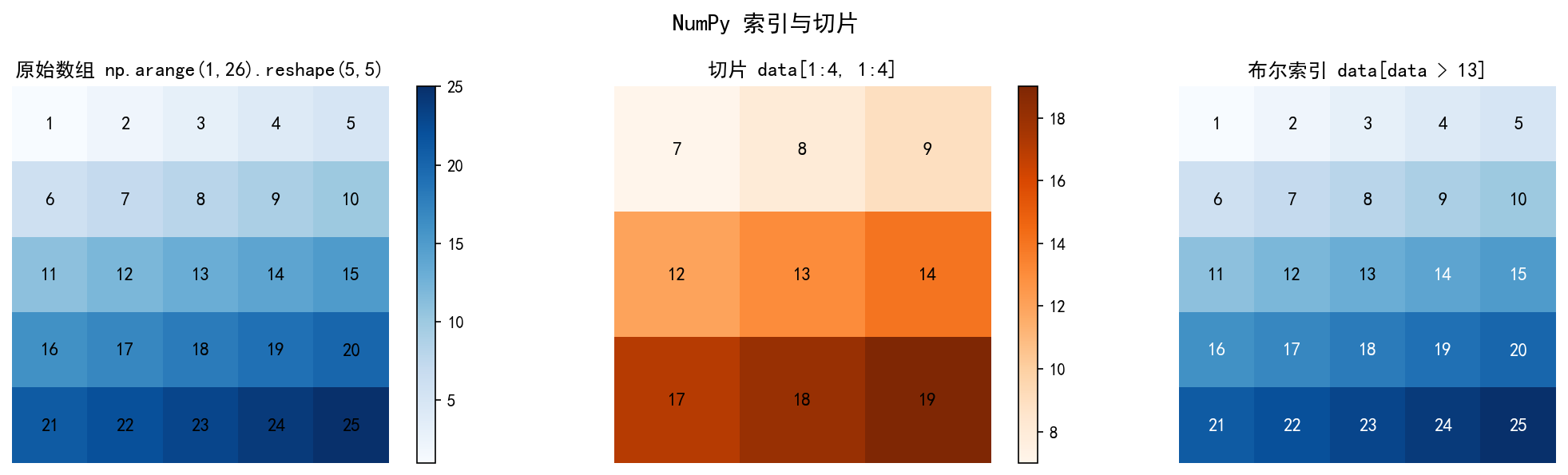
花式索引(Fancy Indexing)
# 整数数组索引
a[[0, 2, 4], [1, 3, 0]] # 取 (0,1), (2,3), (4,0) → [2, 14, 21]
# 布尔索引(条件筛选)
a[a > 13] # [14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]
重要区别:切片返回的是视图(不复制数据,修改会影响原数组),而花式索引返回的是副本。
b = a[1:4, 1:4] # 视图 — 修改 b 会影响 a
c = a[a > 13] # 副本 — 修改 c 不影响 a
1.3 向量化运算与广播机制
向量化运算
NumPy 的核心优势在于向量化:对数组的数学运算自动应用到每个元素,无需写 Python 循环。
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
a + b # [5, 7, 9] — 逐元素加法
a * b # [4, 10, 18] — 逐元素乘法(不是矩阵乘法!)
a ** 2 # [1, 4, 9] — 逐元素平方
np.sqrt(a) # [1., 1.414, 1.732]
聚合运算:
a = np.array([[1, 2, 3], [4, 5, 6]])
np.sum(a) # 21 — 所有元素求和
np.sum(a, axis=0) # [5, 7, 9] — 按列求和
np.sum(a, axis=1) # [6, 15] — 按行求和
np.mean(a) # 3.5
np.std(a) # 1.708 — 标准差
np.min(a) # 1
np.max(a) # 6
广播机制(Broadcasting)
广播是 NumPy 最强大的特性之一:当两个数组形状不同时,NumPy 会自动"扩展"较小的数组以匹配较大的数组,无需显式复制数据。
广播规则:
从最右侧维度开始对齐
两个维度相等或其中一个为 1 时可以广播
所有维度都满足上述条件则广播成功
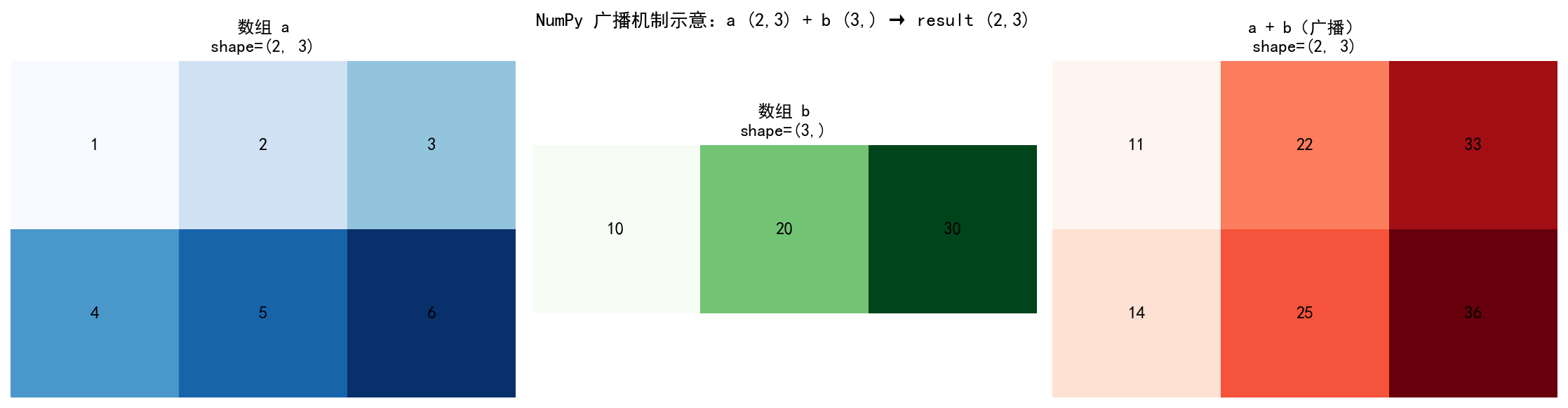
a = np.array([[1, 2, 3], # shape (2, 3)
[4, 5, 6]])
b = np.array([10, 20, 30]) # shape (3,)
a + b
# array([[11, 22, 33], # b 自动沿行方向"广播"
# [14, 25, 36]])
广播的常见应用场景:
# 矩阵每列减去该列的均值(数据中心化)
data = np.random.rand(100, 5) # 100 个样本,5 个特征
data_centered = data - data.mean(axis=0) # 减去每列均值
# 标准化:(x - mean) / std
data_std = (data - data.mean(axis=0)) / data.std(axis=0)
# 给矩阵每行加上不同的偏置
bias = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) # shape (5, 1)
result = data + bias # bias 沿列方向广播
1.4 线性代数
NumPy 的 np.linalg 子模块提供了完整的线性代数操作,在数学建模中无处不在。
矩阵乘法
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
A @ B # 矩阵乘法(Python 3.5+ 推荐写法)
np.dot(A, B) # 等价写法
np.matmul(A, B) # 等价写法
逆矩阵、行列式
A = np.array([[1, 2], [3, 4]])
np.linalg.det(A) # -2.0 — 行列式
np.linalg.inv(A) # [[-2., 1.], — 逆矩阵
# [ 1.5, -0.5]]
特征值与特征向量
矩阵 A 的特征值 λ 和特征向量 v 满足:Av=λv
A = np.array([[2, 1],
[1, 3]])
eigenvalues, eigenvectors = np.linalg.eig(A)
# eigenvalues ≈ [1.382, 3.618]
# eigenvectors 的每一列是对应特征值的特征向量
特征向量的几何意义:矩阵 A 对特征向量 v 的作用仅仅是"拉伸"(缩放因子为 λ),方向不变。
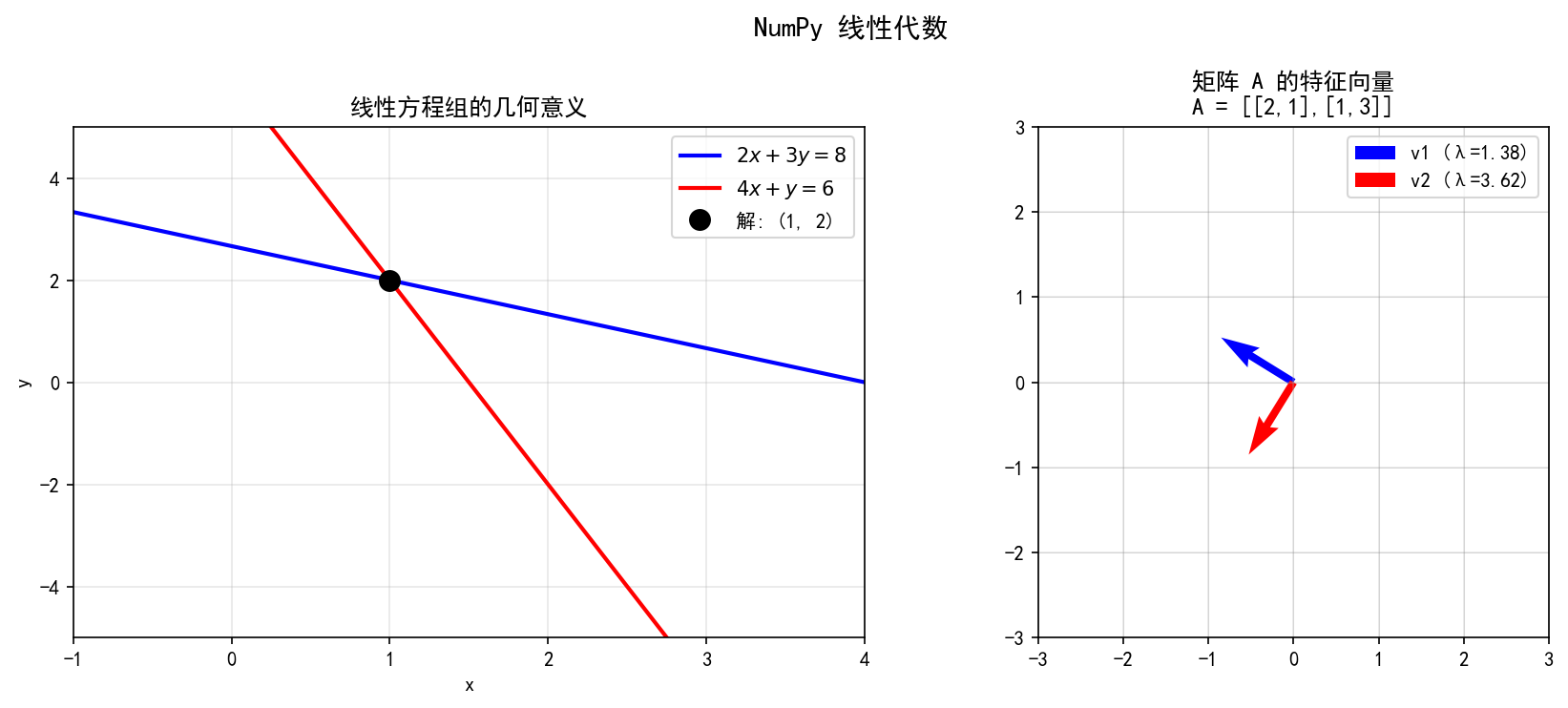
左图展示了一个 2×2 线性方程组的几何意义:两条直线的交点即为方程组的解。右图展示了矩阵 的特征向量方向。
求解线性方程组
但在实际计算中,永远不要显式求逆,应该用 solve:
# 求解 2x + 3y = 8, 4x + y = 6
A = np.array([[2, 3],
[4, 1]])
b = np.array([8, 6])
x = np.linalg.solve(A, b) # [1., 2.]
最小二乘法
# 用最小二乘拟合 y = ax + b
x = np.array([1, 2, 3, 4, 5])
y = np.array([2.1, 3.9, 6.2, 8.1, 9.8])
# 构造设计矩阵 [x, 1]
X = np.vstack([x, np.ones(len(x))]).T
coeffs = np.linalg.lstsq(X, y, rcond=None)[0]
# coeffs[0] = 斜率 a, coeffs[1] = 截距 b
数模应用场景
1.5 随机数生成
NumPy 提供了丰富的随机数生成函数,是蒙特卡洛模拟和随机抽样的基础。
随机种子
np.random.seed(42) # 设置种子,保证结果可复现
常用分布
np.random.rand(5) # [0,1) 均匀分布
np.random.randn(5) # 标准正态分布 N(0,1)
np.random.randint(0, 10, 5) # [0,10) 均匀整数
np.random.choice([1,2,3,4,5], size=3) # 从给定数组中随机选择
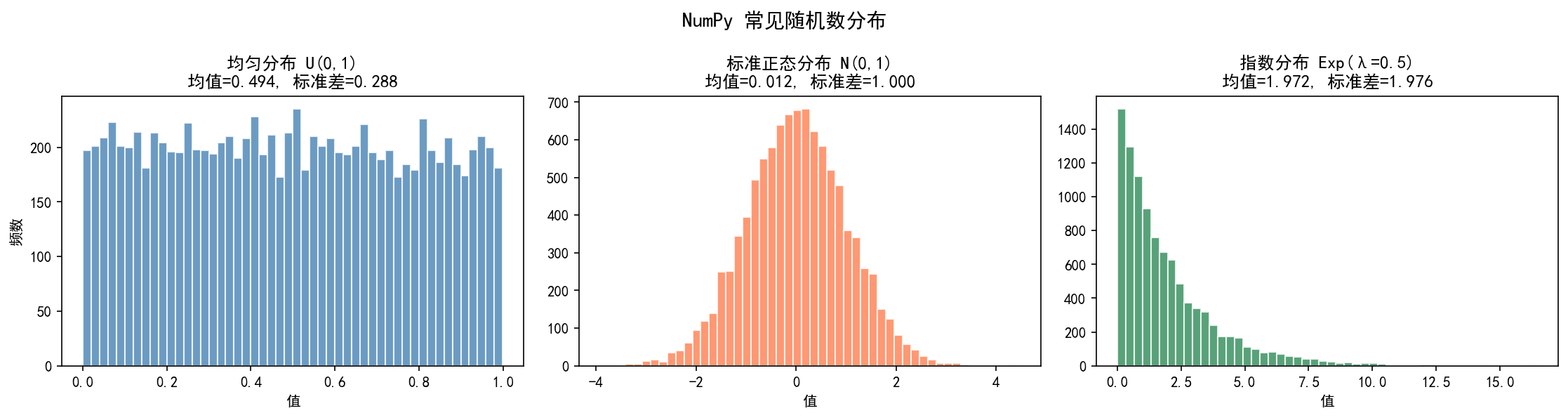
上图中,均匀分布在 [0,1] 区间内近似等频,正态分布呈现经典的钟形曲线,指数分布则呈现出右偏的长尾特征。
蒙特卡洛方法估计 π
蒙特卡洛方法通过随机抽样来近似计算:
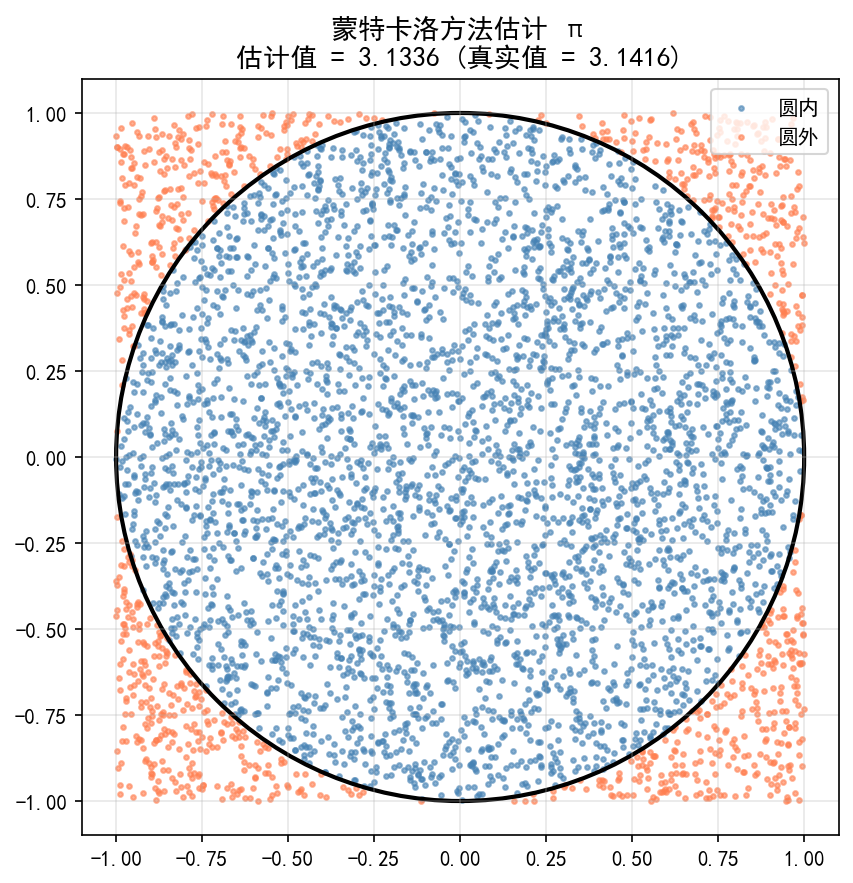
np.random.seed(42)
n = 100000
x = np.random.uniform(-1, 1, n)
y = np.random.uniform(-1, 1, n)
inside = x**2 + y**2 <= 1 # 落在单位圆内
pi_est = 4 * inside.sum() / n
print(f"π 的估计值: {pi_est:.5f}") # ≈ 3.141...
原理:在边长为 2 的正方形内随机撒点,圆内点数与总点数的比值近似等于圆面积与正方形面积的比值 。
蒙特卡洛积分
# 用蒙特卡洛方法计算 ∫₀¹ e^(-x²) dx
np.random.seed(42)
n = 1000000
x = np.random.uniform(0, 1, n)
integral = np.mean(np.exp(-x**2))
print(f"积分估计值: {integral:.6f}") # 理论值 ≈ 0.746824
数模应用场景
1.6 实用技巧速查
数组形状操作
数组拼接与拆分
常用数学函数
排序与查找
1.7 本节小结
ndarray 是 NumPy 的核心:同质、连续、支持向量化运算
避免 Python 循环,用向量化运算替代,速度提升可达数十倍
广播机制让不同形状的数组运算成为可能,是 NumPy 最强大的特性之一
线性代数操作(矩阵乘法、逆矩阵、特征值、方程组求解)是数模的核心工具
永远用
solve而非inv求解线性方程组——数值稳定性更好设置随机种子
np.random.seed()保证结果可复现蒙特卡洛方法通过大量随机抽样近似求解复杂问题
第 2 章 Pandas 核心
Pandas 是 Python 数据处理与分析的事实标准。它基于 NumPy 构建,提供了 DataFrame 和 Series 两种核心数据结构,让数据清洗、探索、转换变得直观而高效。在数学建模中,从赛题数据读取到特征工程,Pandas 几乎贯穿整个流程。
2.1 Series 与 DataFrame
Series:一维带标签数组
Series 是一维数组,与 NumPy 数组的区别在于每个元素都有标签索引(index)。
import pandas as pd
import numpy as np
# 从列表创建
s = pd.Series([85, 92, 78, 95, 88], index=['张三', '李四', '王五', '赵六', '孙七'])
print(s)
# 张三 85
# 李四 92
# 王五 78
# 赵六 95
# 孙七 88
# dtype: int64
# 按标签访问
s['张三'] # 85
s[['张三', '王五']] # Series: 张三 85, 王五 78
# 基本属性
s.values # array([85, 92, 78, 95, 88])
s.index # Index(['张三', '李四', ...])
s.mean() # 87.6
DataFrame:二维表格
DataFrame 是 Pandas 的核心,可以理解为「带行索引和列名的 Series 字典」。
df = pd.DataFrame({
'姓名': ['张三', '李四', '王五'],
'年龄': [20, 21, 19],
'成绩': [85.5, 92.0, 78.5]
})
print(df)
# 姓名 年龄 成绩
# 0 张三 20 85.5
# 1 李四 21 92.0
# 2 王五 19 78.5
基本查看方法
拿到数据后的第一步是快速了解它的结构:

左图的 info() 输出展示了数据的基本结构:50 条记录,6 列,各列的类型与非空情况。右图的 describe() 给出了数值列的四分位数、均值、标准差等统计量。
# 实际使用
df.head(3) # 前 3 行
df.info() # 查看数据类型与缺失情况
df.describe() # 数值列的统计摘要
2.2 数据读取与写入
常用读取函数
常用参数
# 指定分隔符、编码、跳过的行
df = pd.read_csv('data.csv', sep=',', encoding='utf-8', skiprows=[0, 1])
# 只读指定列
df = pd.read_csv('data.csv', usecols=['姓名', '成绩', '日期'])
# 将某列作为索引
df = pd.read_csv('data.csv', index_col='日期', parse_dates=True)
# 处理缺失值的表示方式
df = pd.read_csv('data.csv', na_values=['NA', '-', 'null', ''])
数据写入
df.to_csv('output.csv', index=False, encoding='utf-8-sig') # utf-8-sig 避免 Excel 乱码
df.to_excel('output.xlsx', sheet_name='结果', index=False)
数模常见问题:中文 CSV 用 Excel 打开时乱码——写入时使用 encoding='utf-8-sig'(带 BOM 的 UTF-8),Excel 即可正确识别。
2.3 数据选择与过滤
列选择
df['姓名'] # 返回 Series
df[['姓名', '成绩']] # 返回 DataFrame(注意双括号)
.loc(标签索引) vs .iloc(位置索引)
这是 Pandas 最常被混淆的两个方法:
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}, index=['a', 'b', 'c', 'd', 'e'])
# .loc — 按标签(行名/列名)
df.loc['c'] # 第 'c' 行
df.loc['a':'c', 'A'] # 行 'a' 到 'c',列 'A'
df.loc[df['A'] > 2] # 条件筛选
# .iloc — 按位置(整数索引,0-based)
df.iloc[2] # 第 3 行(位置索引)
df.iloc[0:3, 0:2] # 前 3 行、前 2 列
df.iloc[2, 1] # 第 3 行第 2 列 → 30
关键区别:.loc 使用标签,.iloc 使用整数位置。
条件过滤
# 单条件
df[df['成绩'] >= 90]
# 多条件(注意用 & | ~,不能用 and or not)
df[(df['成绩'] >= 80) & (df['年龄'] < 21)]
# isin — 匹配多个值
df[df['城市'].isin(['北京', '上海'])]
# between — 范围查询
df[df['成绩'].between(80, 90)]
# query — SQL 风格(更简洁)
df.query('成绩 >= 80 and 年龄 < 21')
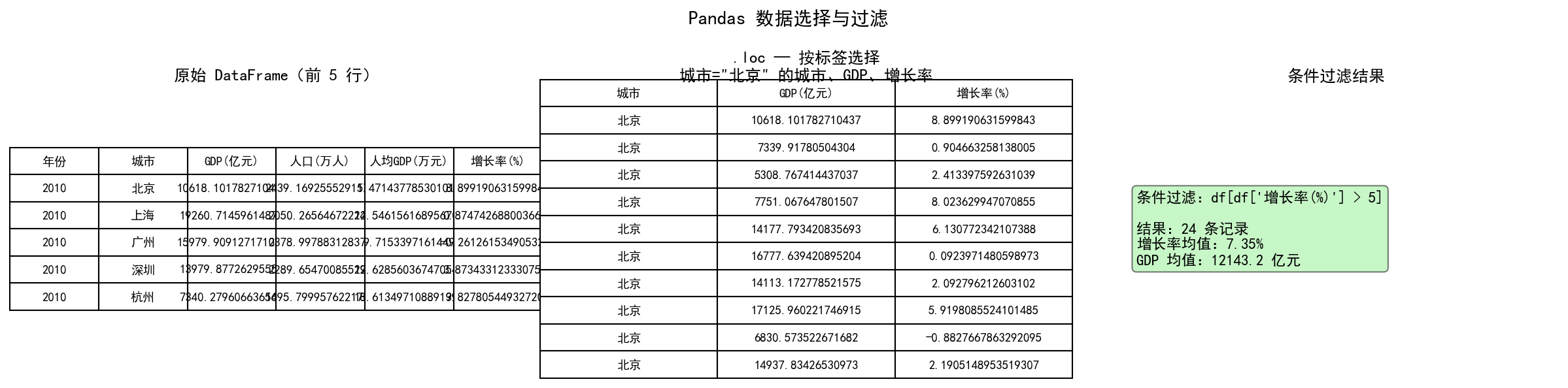
上图展示了原始 DataFrame 的前 5 行、.loc 按标签选择城市="北京"的记录,以及条件过滤选出增长率 > 5% 的结果。
2.4 数据操作
新增与删除列
# 新增列
df['总分'] = df['数学'] + df['英语']
df['等级'] = df['总分'].apply(lambda x: '优秀' if x >= 170 else '良好')
# 删除列
df.drop(columns=['总分'], inplace=True) # 或 del df['总分']
列重命名
df.rename(columns={'旧名': '新名'}, inplace=True)
排序
# 按列排序
df.sort_values('成绩', ascending=False) # 降序
df.sort_values(['城市', '成绩'], ascending=[True, False]) # 多列排序
# 按索引排序
df.sort_index()
# 排名
df['排名'] = df['成绩'].rank(ascending=False, method='min')
去重
df.drop_duplicates() # 全行去重
df.drop_duplicates(subset=['城市']) # 按指定列去重
2.5 分组与聚合(groupby)
groupby 是 Pandas 最强大的功能之一,遵循 Split-Apply-Combine 范式:将数据分组 → 对每组应用函数 → 合并结果。
# 单列分组 + 聚合
df.groupby('城市')['GDP'].mean() # 各城市 GDP 均值
df.groupby('城市')['GDP'].agg(['mean', 'std', 'count']) # 多个聚合
# 多列分组
df.groupby(['年份', '城市'])['GDP'].sum()
# 对整个 DataFrame 聚合
df.groupby('城市').agg({
'GDP': ['mean', 'sum'],
'人口': 'mean',
'增长率': 'max'
})
agg vs transform
# agg — 每组一个值
df.groupby('城市')['GDP'].mean()
# 北京 12000
# 上海 15000
# transform — 每行都有值(组内均值填充到每行)
df['城市GDP均值'] = df.groupby('城市')['GDP'].transform('mean')
# 每条记录都有了所在城市的 GDP 均值
透视表(pivot_table)
df.pivot_table(
values='销售额', # 聚合的值
index='地区', # 行维度
columns='产品', # 列维度
aggfunc='mean' # 聚合函数
)
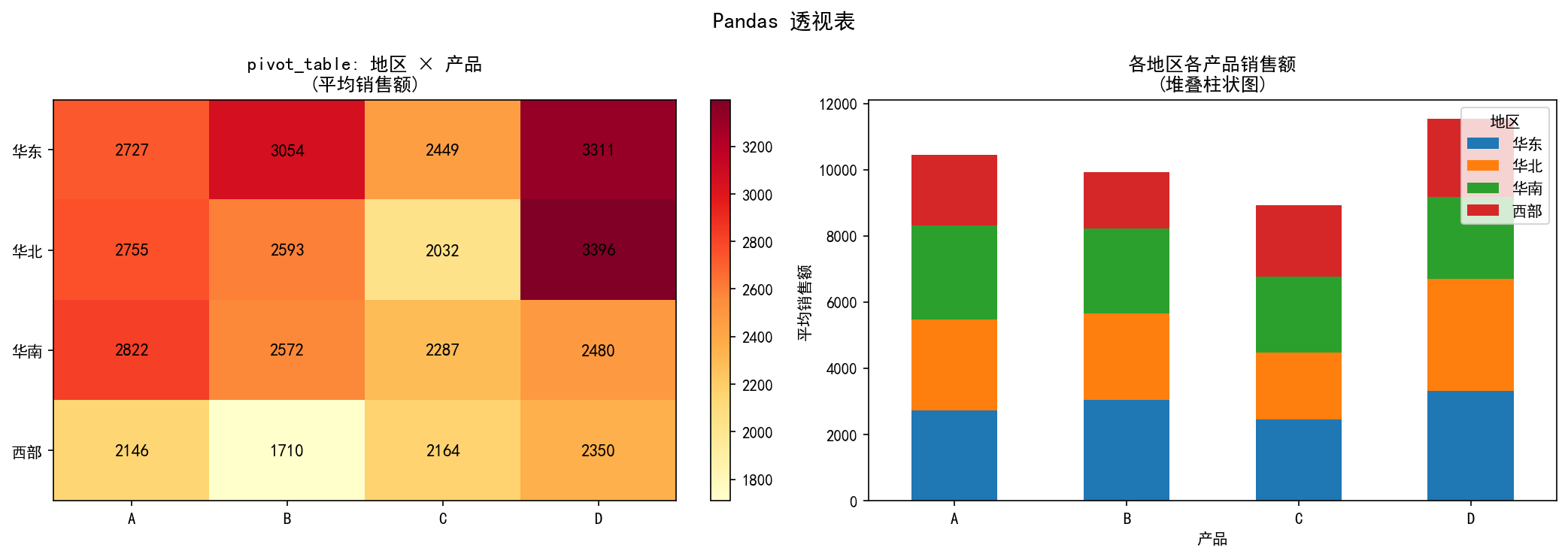
左图用热力图展示了 pivot_table 的结果——每个单元格是该地区该产品的平均销售额。右图用堆叠柱状图展示了相同的数据。透视表本质上是一个多维度的 groupby 聚合。
交叉表(crosstab)
pd.crosstab(df['地区'], df['产品'], values=df['销售额'], aggfunc='count')
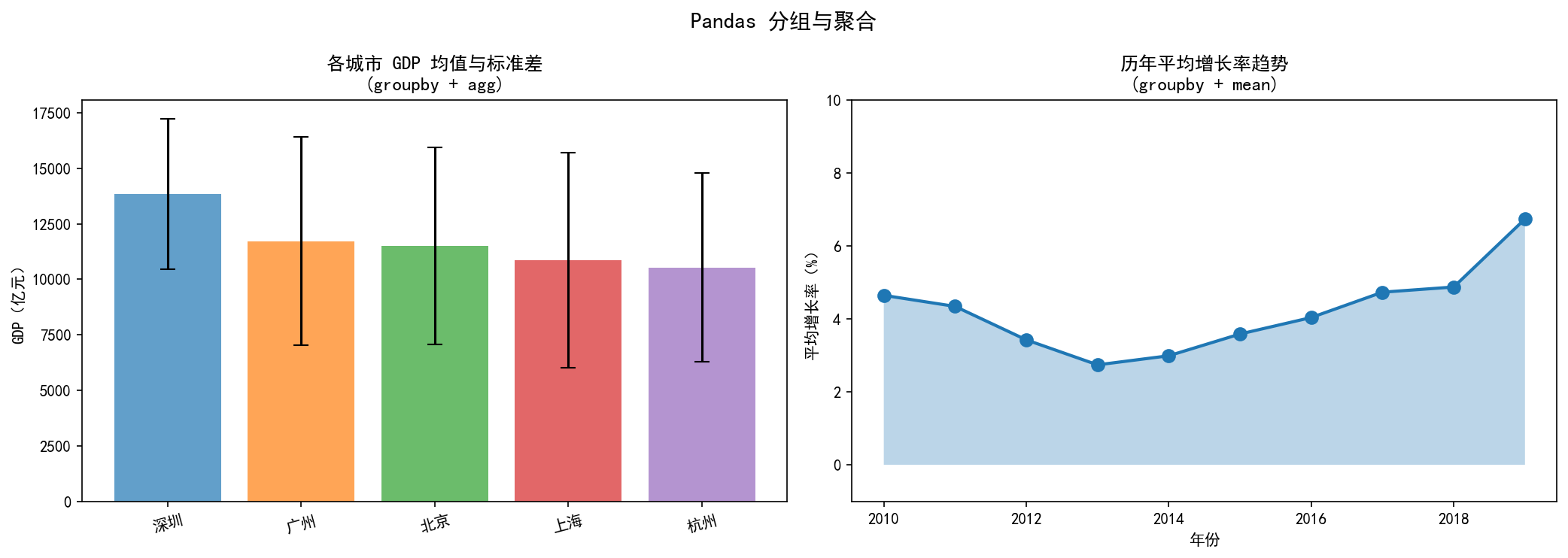
左图展示了按城市分组的 GDP 均值与标准差,右图展示了历年平均增长率的趋势变化。
2.6 数据合并
merge — 类似 SQL 的 JOIN
# 学生表
df_students = pd.DataFrame({
'学号': [101, 102, 103, 104, 105],
'姓名': ['张三', '李四', '王五', '赵六', '孙七'],
'专业': ['数学', '统计', '数学', '金融', '统计']
})
# 成绩表
df_scores = pd.DataFrame({
'学号': [101, 102, 103, 105, 106],
'数学': [85, 92, 78, 88, 95],
'英语': [90, 85, 82, 91, 87]
})
连接方式

上图展示了两个 DataFrame 的 inner join 结果。学号 104(赵六)只在学生表中,学号 106 只在成绩表中——inner join 只保留两表共有的学号(101、102、103、105)。
# inner join
pd.merge(df_students, df_scores, on='学号', how='inner')
# left join(保留所有学生,成绩缺失的填 NaN)
pd.merge(df_students, df_scores, on='学号', how='left')
# 不同列名合并
pd.merge(df1, df2, left_on='id1', right_on='id2')
concat — 拼接
# 纵向拼接(上下堆叠)
pd.concat([df1, df2], axis=0)
# 横向拼接(左右拼接)
pd.concat([df1, df2], axis=1)
# 忽略原索引
pd.concat([df1, df2], ignore_index=True)
merge vs concat:merge 按键值匹配(类似 SQL JOIN),concat 按位置直接拼接。
2.7 时间序列
Pandas 的时间序列处理能力非常强大,是处理时序数据的首选工具。
创建时间索引
# 创建日期范围
dates = pd.date_range('2020-01-01', periods=365, freq='D') # 每天
dates_monthly = pd.date_range('2020-01', periods=12, freq='ME') # 每月末
# 字符串转日期
df['日期'] = pd.to_datetime(df['日期'], format='%Y-%m-%d')
df.set_index('日期', inplace=True)
常用频率
时间索引选择
df['2020-03'] # 2020年3月所有数据
df['2020-01-01':'2020-03-31'] # 日期范围
df.loc['2020-03-01'] # 某一天
重采样(resample)
# 按日数据 → 按月均值
df.resample('ME').mean()
# 按日数据 → 按月求和
df.resample('ME').sum()
# 多重聚合
df.resample('ME').agg({'温度': 'mean', '降雨量': 'sum'})
滑动窗口(rolling)
# 30 日移动平均
df['温度'].rolling(window=30).mean()
# 指数加权移动平均
df['温度'].ewm(span=30).mean()
# 滑动窗口内的多个统计量
df.rolling(30).agg(['mean', 'std', 'max'])
日期属性提取
df['年'] = df.index.year
df['月'] = df.index.month
df['季度'] = df.index.quarter
df['星期'] = df.index.dayofweek # 0=周一, 6=周日
df['是否周末'] = df.index.dayofweek >= 5
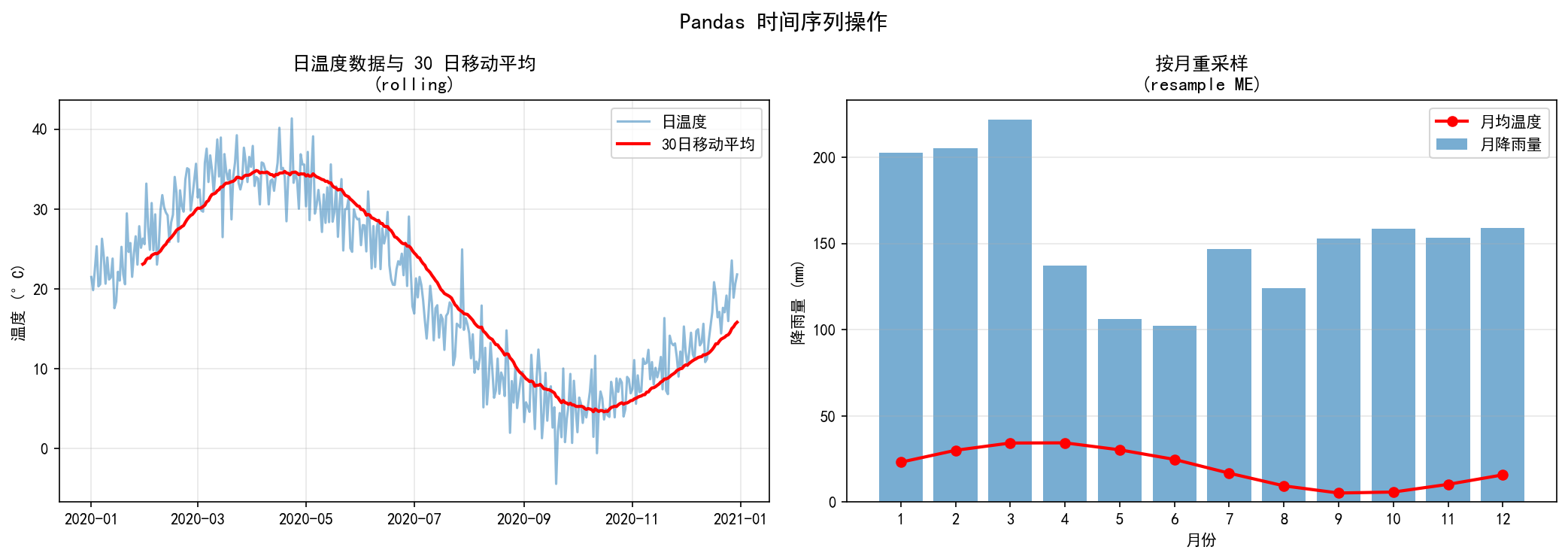
左图展示了日温度数据(蓝色)与 30 日移动平均(红色)——rolling(window=30).mean() 平滑了短期波动,清晰呈现出年度周期趋势。右图展示了按月重采样后的月均温度与月降雨量,resample('ME') 将 365 天的日数据聚合为 12 个月的月度数据。
2.8 实用技巧速查
缺失值处理(快速版)
数据类型转换
df['列名'] = df['列名'].astype(float) # 转浮点
df['列名'] = pd.to_numeric(df['列名'], errors='coerce') # 非数字转 NaN
df['列名'] = pd.to_datetime(df['列名']) # 转日期
条件赋值
import numpy as np
df['等级'] = np.where(df['成绩'] >= 60, '及格', '不及格')
# 多条件
df['等级'] = pd.cut(df['成绩'], bins=[0, 60, 80, 100],
labels=['不及格', '良好', '优秀'])
字符串操作
df['姓名'].str.len() # 字符串长度
df['姓名'].str.contains('张') # 包含'张'
df['姓名'].str.replace('张', '李') # 替换
df['姓名'].str.strip() # 去空格
apply 函数
# 对单列应用函数
df['成绩'].apply(lambda x: x * 1.1)
# 对整行应用函数
df.apply(lambda row: row['数学'] * 0.6 + row['英语'] * 0.4, axis=1)
2.9 本节小结
Series 是一维带标签数组,DataFrame 是二维表格——Pandas 的两大核心
拿到数据先
head()+info()+describe(),三步了解数据全貌.loc按标签,.iloc按位置——这是最常混淆的两个方法groupby遵循 Split-Apply-Combine:分组 → 聚合 → 合并agg()缩减维度,transform()保持原形状——根据需求选择merge按键匹配,concat按位置拼接——用途不同resample改变频率,rolling滑动窗口——时间序列两大核心操作中文 CSV 用 Excel 打开乱码时,用
encoding='utf-8-sig'写入
第 3 章 数据预处理方法
在数学建模中,拿到原始数据后的第一步不是直接建模,而是数据预处理。真实数据几乎总存在缺失值、异常值、量纲不统一、类别变量等问题。本章系统讲解常见的数据预处理方法及其 Python 实现。
3.1 缺失值处理
缺失值检测
拿到数据后,第一件事就是检查缺失情况:
import pandas as pd
import numpy as np
# 查看各列缺失数量
df.isna().sum()
# 查看各列缺失率
df.isna().mean() * 100
# 查看缺失行
df[df.isna().any(axis=1)]
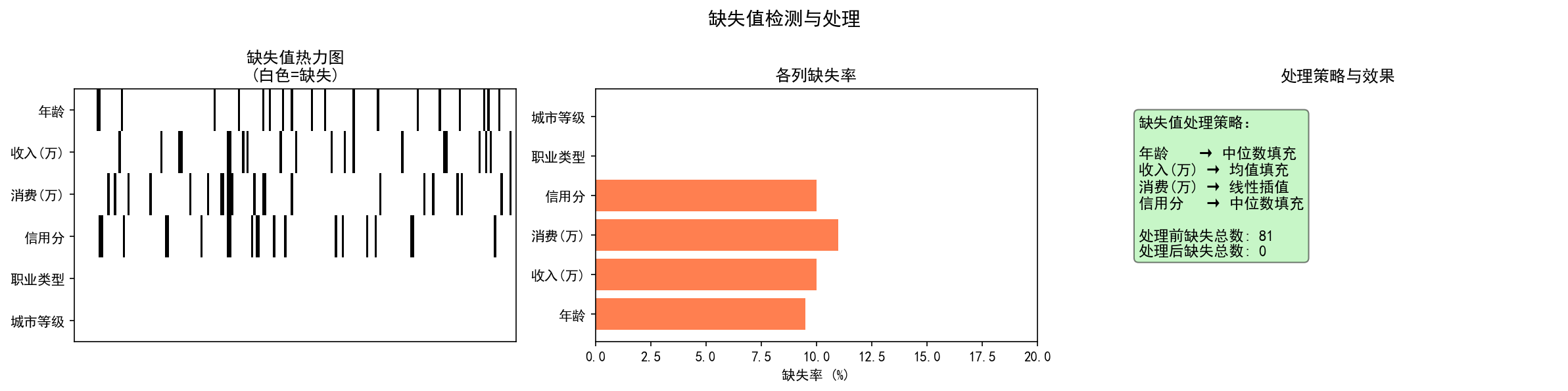
左图的缺失热力图中,黑色竖线表示该位置缺失。可以看到数值列(年龄、收入、消费、信用分)约有 10% 的缺失,而类别列(城市等级、职业类型)无缺失。中图的缺失率条形图量化了各列的缺失程度。
缺失值处理策略
# 中位数填充(对异常值鲁棒)
df['年龄'] = df['年龄'].fillna(df['年龄'].median())
# 均值填充
df['收入'] = df['收入'].fillna(df['收入'].mean())
# 线性插值(适合时间序列)
df['消费'] = df['消费'].interpolate(method='linear')
# KNN 填充(利用其他特征信息)
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df[['年龄', '收入', '消费', '信用分']] = imputer.fit_transform(
df[['年龄', '收入', '消费', '信用分']]
)
# 删除缺失率 > 50% 的列
df = df.loc[:, df.isna().mean() < 0.5]
选择建议:缺失率 < 5% 时任何方法差异不大;缺失率 5%-30% 优先用中位数/插值;缺失率 > 30% 考虑将"是否缺失"作为新特征。
3.2 异常值检测与处理
3σ 原则
假设数据服从正态分布,则:
约 68% 的数据落在 [μ−σ,μ+σ] 内
约 95% 的数据落在 [μ−2σ,μ+2σ] 内
约 99.7% 的数据落在 [μ−3σ,μ+3σ] 内
超出 3σ 范围的点可视为异常值。
IQR 方法(四分位距法)
IQR 方法不依赖正态分布假设,更加鲁棒:
异常值范围:
其中 Q1 为第一四分位数(25% 分位),Q3 为第三四分位数(75% 分位)。
# 3σ 原则
mean, std = df['收入'].mean(), df['收入'].std()
lower, upper = mean - 3*std, mean + 3*std
outliers_3sigma = df[(df['收入'] < lower) | (df['收入'] > upper)]
# IQR 方法
Q1, Q3 = df['收入'].quantile(0.25), df['收入'].quantile(0.75)
IQR = Q3 - Q1
lower, upper = Q1 - 1.5*IQR, Q3 + 1.5*IQR
outliers_iqr = df[(df['收入'] < lower) | (df['收入'] > upper)]
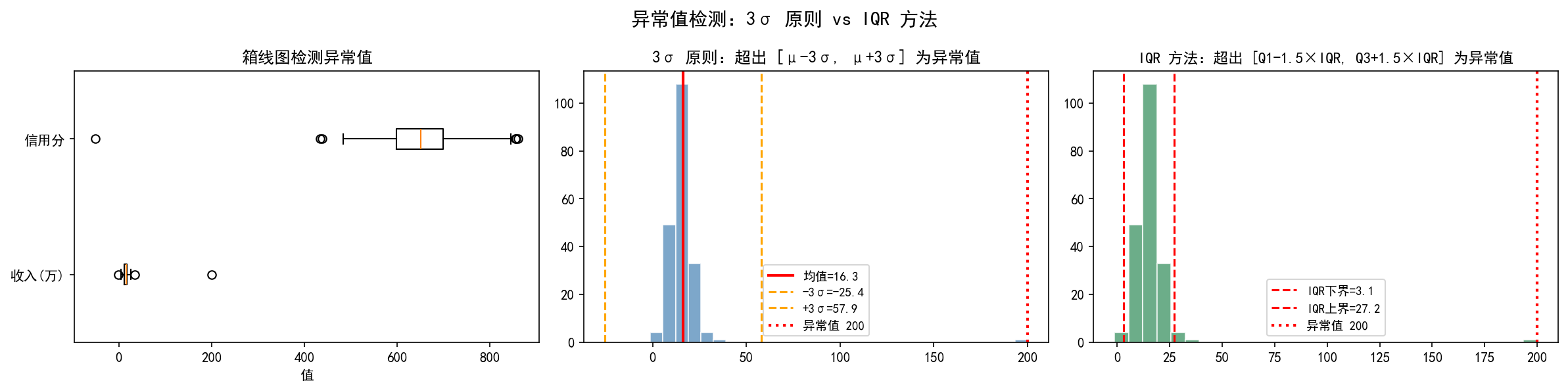
上图中,收入数据(均值约 16.3 万)中有一个极端值 200 万。3σ 原则的边界为 [-25.4, 57.9],IQR 方法的边界为 [3.1, 27.2]——IQR 方法更严格,因为它不受极端值本身的拉扯。箱线图(左图)也清晰标出了两个变量中的异常点。
异常值处理方法
# 截断
df['收入_截断'] = np.clip(df['收入'], lower, upper)
# 对数变换(适合右偏分布)
df['收入_log'] = np.log1p(df['收入'])
3.3 数据标准化与归一化
当特征量纲不同时(如"收入"以万元计、"年龄"以岁计),直接用于距离-based 算法(KNN、K-Means、SVM 等)会导致大尺度特征主导模型。标准化/归一化将不同特征缩放到可比范围。
Min-Max 归一化
将数据线性缩放到 [0,1]:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_normalized = scaler.fit_transform(X)
# 手动实现
X_normalized = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
Z-score 标准化
将数据转换为均值 0、标准差 1:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
# 手动实现
X_standardized = (X - X.mean(axis=0)) / X.std(axis=0)
RobustScaler(对异常值鲁棒)
用中位数和 IQR 代替均值和标准差:
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
X_robust = scaler.fit_transform(X)
如何选择
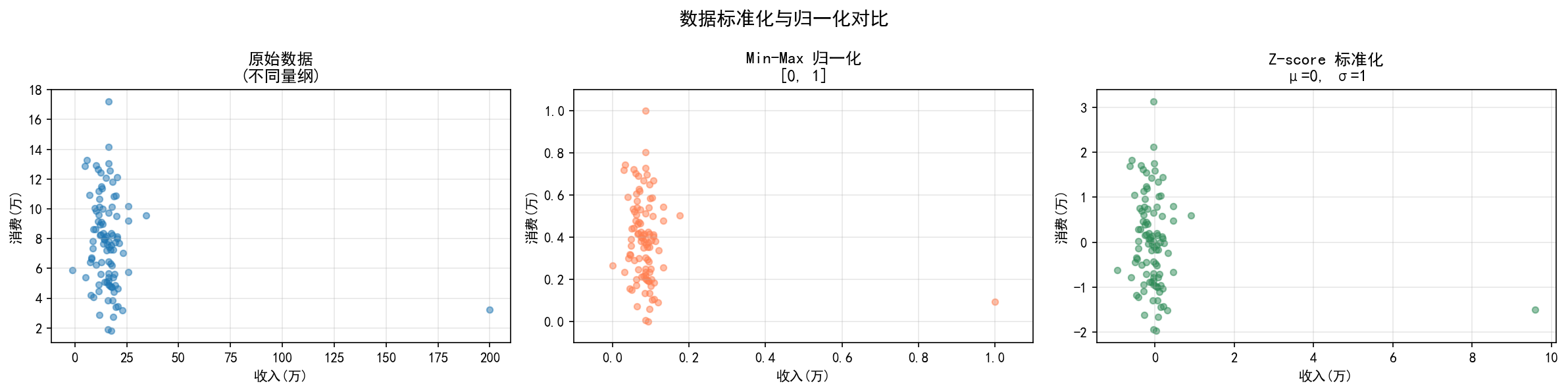
左图展示了原始数据——收入(横轴,0-30 万)与消费(纵轴,0-15 万)量纲差异明显。Min-Max 归一化(中图)将所有值压缩到 [0, 1] 区间,保留了数据的相对分布形状。Z-score 标准化(右图)将数据中心化到原点,正负值表示相对于均值的偏离方向。
# 数模中的典型用法
from sklearn.preprocessing import StandardScaler
# 标准化后用于聚类 / 回归 / 分类
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # 用训练集的参数
# 注意:测试集/预测集只能用训练集的均值和标准差!
重要:测试集必须用训练集的参数(均值、标准差等)进行变换,不能重新 fit。
3.4 类别变量编码
机器学习算法通常只能处理数值输入,类别变量需要编码。
Label Encoding(标签编码)
适用于有序类别:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['城市_编码'] = le.fit_transform(df['城市等级'])
# 一线→2, 二线→1, 三线→0 (按字母顺序)
对于有明确顺序的类别(如教育程度:小学<中学<大学),应手动指定顺序:
# 手动有序编码
order_map = {'小学': 1, '中学': 2, '大学': 3, '研究生': 4}
df['教育_编码'] = df['教育程度'].map(order_map)
One-Hot Encoding(独热编码)
适用于无序类别,将每个类别转换为一个二值列:
# pandas 方法
df_oh = pd.get_dummies(df, columns=['城市等级'], prefix='城市')
# 新增列:城市_一线, 城市_二线, 城市_三线
# sklearn 方法
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse_output=False)
X_encoded = ohe.fit_transform(df[['城市等级']])
虚拟变量陷阱
One-Hot 编码会产生 k 个新列(k 为类别数),但只需要 k−1 个即可完整表示信息。对于线性回归模型,应去掉一列:
df_oh = pd.get_dummies(df, columns=['城市等级'], prefix='城市', drop_first=True)
高基数类别的编码
当类别数量非常多(如城市名几百个),One-Hot 会产生大量稀疏列:
# Target Encoding:用目标变量的均值代替类别
target_mean = df.groupby('城市')['目标变量'].mean()
df['城市_target'] = df['城市'].map(target_mean)
# 频率编码
freq = df['城市'].value_counts(normalize=True)
df['城市_freq'] = df['城市'].map(freq)
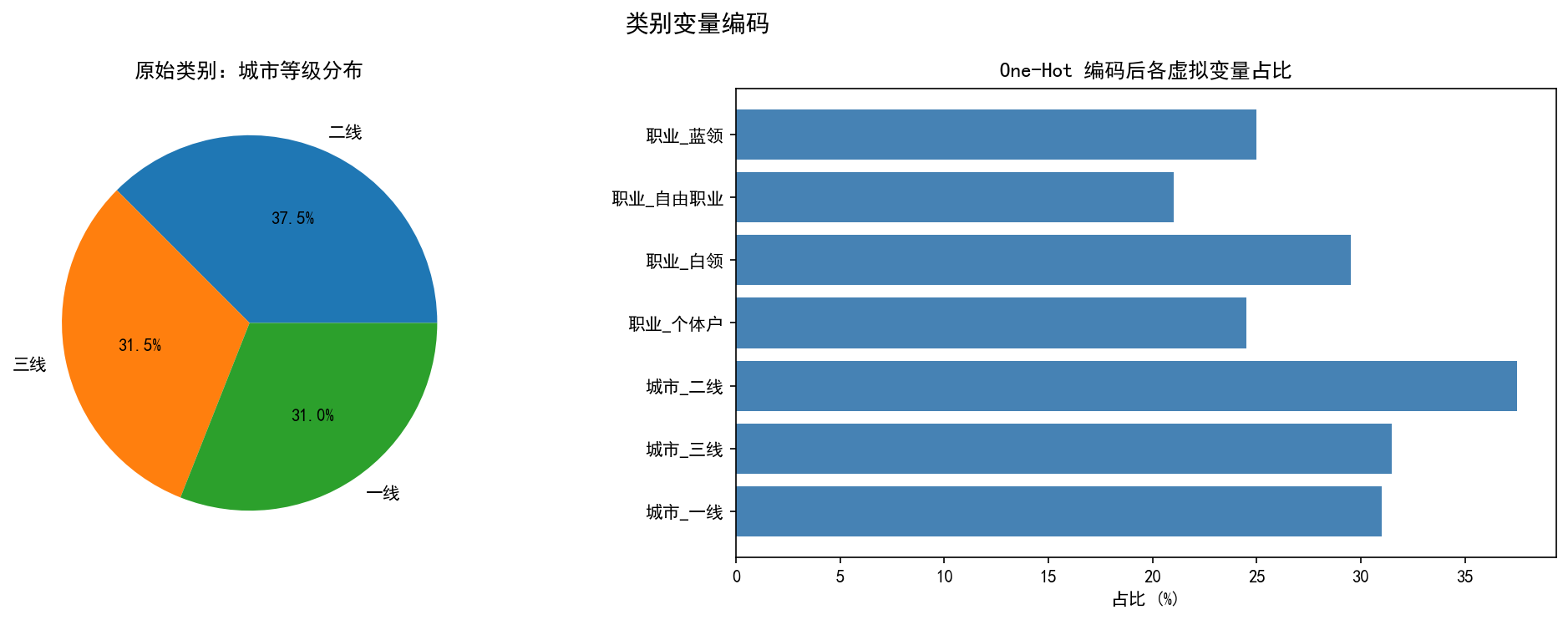
左图展示了"城市等级"的原始分布(一线 30%、二线 40%、三线 30%)。右图展示了 One-Hot 编码后各虚拟变量的占比——每个类别变成一个 0/1 列,占比等于该类别的原始比例。
3.5 数据离散化(分箱)
将连续变量划分为有限的区间,常用于评分卡、等级划分等场景。
等宽分箱(Equal-Width Binning)
将数据范围等分为 k 个区间:
# 将信用分分为 4 个等级
df['信用_等级'] = pd.cut(df['信用分'], bins=4, labels=['D', 'C', 'B', 'A'])
等频分箱(Equal-Frequency Binning)
每个区间包含大致相同数量的样本:
df['信用_等级'] = pd.qcut(df['信用分'], q=4, labels=['D', 'C', 'B', 'A'])
自定义分箱
# 自定义边界
bins = [0, 300, 500, 700, 850]
labels = ['极差', '较差', '一般', '良好', '优秀']
df['信用_等级'] = pd.cut(df['信用分'], bins=bins, labels=labels)
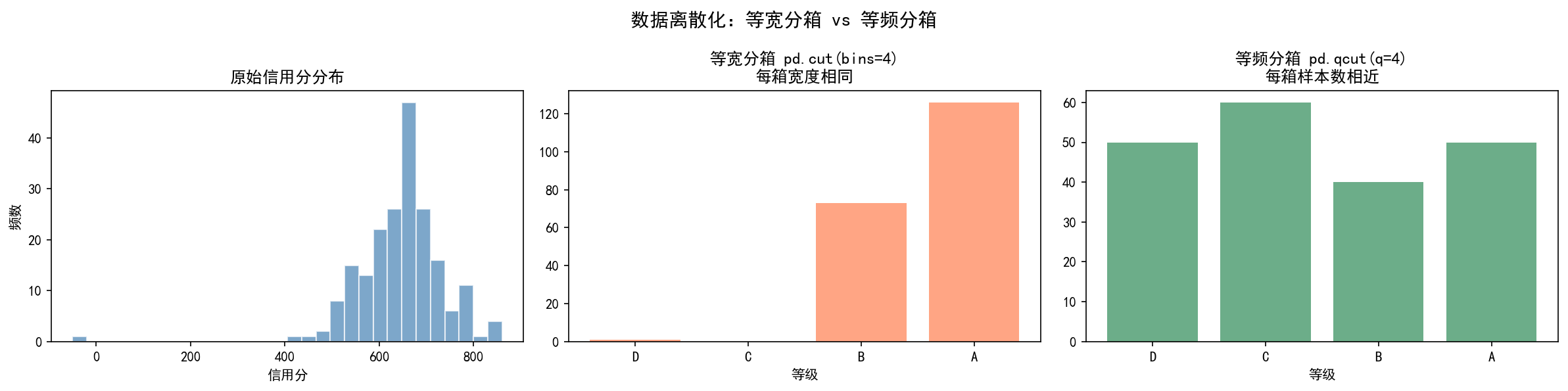
左图展示了原始信用分分布(近似正态)。等宽分箱(中图)将信用分范围等分为 4 段——由于数据集中在中间,中间箱的样本数明显更多。等频分箱(右图)则确保每个箱的样本数大致相等——但箱体宽度不同,极端值的箱更宽。
选择建议:等宽分箱适合均匀分布的数据;等频分箱适合偏态分布;业务有明确标准时用自定义分箱。
3.6 特征选择
相关性分析
计算 Pearson 相关系数矩阵,识别高度相关的特征(可能导致多重共线性):
# 相关系数矩阵
corr = df[['年龄', '收入', '消费', '信用分']].corr()
# 热力图可视化
import seaborn as sns
sns.heatmap(corr, annot=True, cmap='RdBu_r', vmin=-1, vmax=1)
相关系数的解读:
∣r∣>0.7:强相关
0.3<∣r∣<0.7:中等相关
∣r∣<0.3:弱相关
方差阈值法
删除方差极低的特征(几乎不变的特征没有区分度):
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=0.01)
X_selected = selector.fit_transform(X)
相关性筛选
# 找出与目标变量相关性最高的 top-k 个特征
corr_with_target = df.corr()['目标变量'].abs().sort_values(ascending=False)
top_features = corr_with_target.head(10).index.tolist()
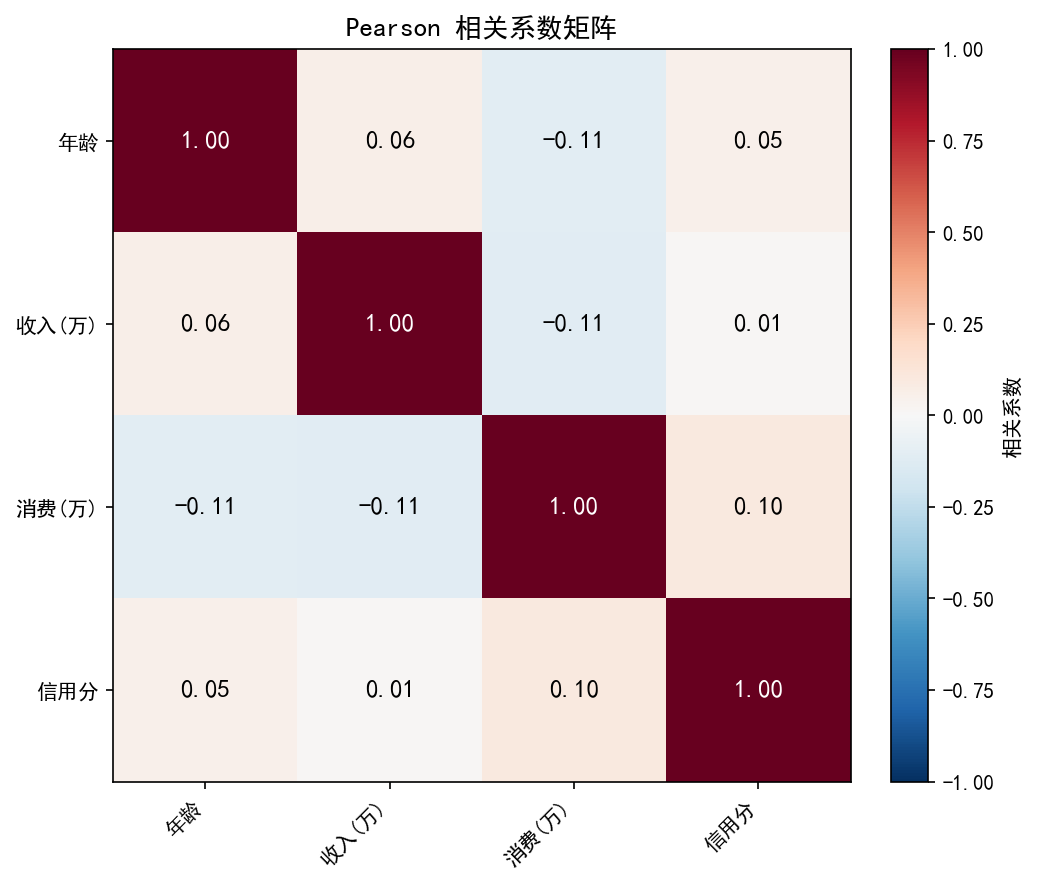
热力图中,颜色越深表示相关性越强。对角线为 1(自相关)。收入与消费的相关系数为 0.65(中等正相关)——收入越高的人消费倾向也越高。年龄与信用分相关性较弱(-0.02)。
3.7 降维——主成分分析(PCA)
当特征数量很多且存在相关性时,可以用 PCA 将高维数据投影到低维空间,同时尽可能保留原始信息。
PCA 原理
PCA 找到数据方差最大的方向(主成分),将数据投影到这些方向上:
数据中心化(减去均值)
计算协方差矩阵
求协方差矩阵的特征值和特征向量
按特征值大小排序,选择前 k 个特征向量
将数据投影到这 k 个方向上
Python 实现
from sklearn.decomposition import PCA
# 标准化后进行 PCA
from sklearn.preprocessing import StandardScaler
X_scaled = StandardScaler().fit_transform(X)
# PCA 降维
pca = PCA(n_components=2) # 降到 2 维
X_pca = pca.fit_transform(X_scaled)
print(f"各主成分方差解释率: {pca.explained_variance_ratio_}")
print(f"累计解释率: {np.cumsum(pca.explained_variance_ratio_)}")
选择主成分数量
# 方法 1:指定解释率阈值
pca = PCA(n_components=0.95) # 保留 95% 的方差
X_pca = pca.fit_transform(X_scaled)
# 方法 2:查看碎石图,选择"拐点"
pca = PCA()
pca.fit(X_scaled)
plt.plot(range(1, len(pca.explained_variance_ratio_)+1),
pca.explained_variance_ratio_, 'o-')
plt.axhline(y=0.95, color='r', linestyle='--') # 累计 95% 线
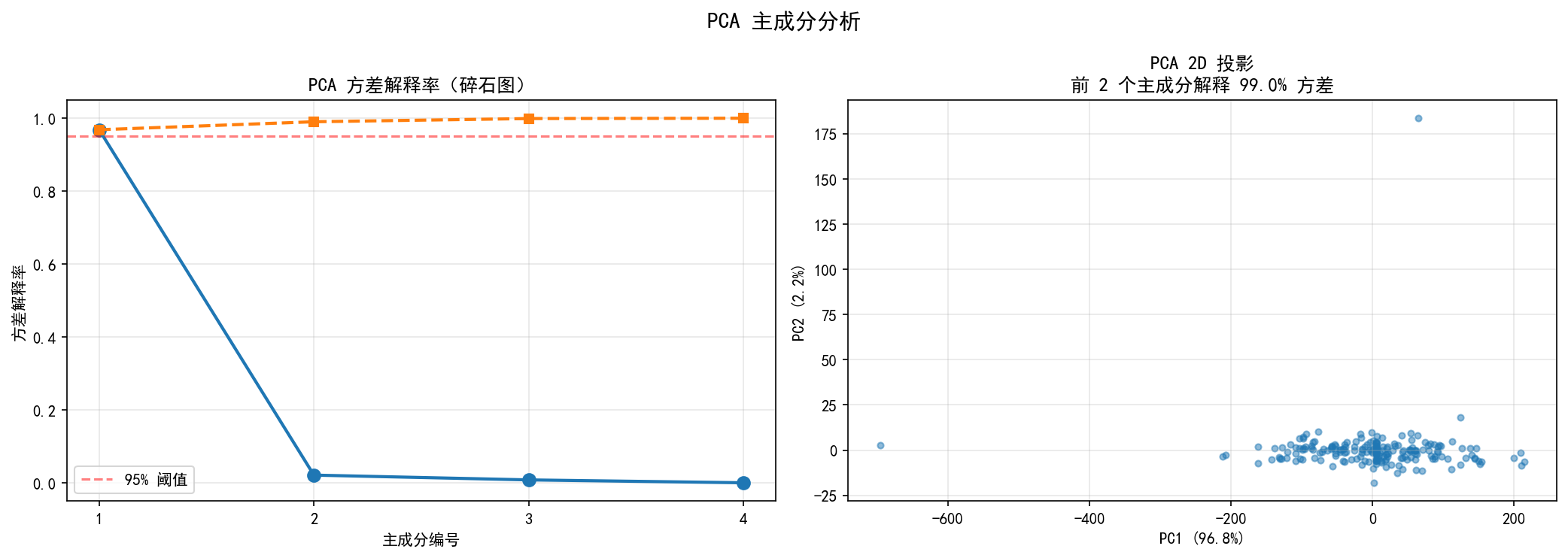
左图的碎石图展示了各主成分的方差解释率。PC1 解释了 96.8% 的方差(因为收入和消费高度相关,它们的信息高度重叠),PC2 解释了 2.2%。前两个主成分累计解释了 99.0% 的方差。右图展示了数据在 PC1-PC2 平面上的投影——4 维数据被压缩到 2 维,同时保留了几乎全部信息。
PCA 的注意事项
PCA 前必须标准化:量纲不同的特征会导致 PCA 偏向大尺度特征
PCA 是线性方法:对于非线性结构的数据,可考虑 Kernel PCA 或 t-SNE
主成分的可解释性:PC1 通常是各原始特征的加权和,不一定有直观含义
PCA 不是特征选择:PCA 创建了新特征(主成分),而不是选择原始特征
3.8 实用技巧速查
3.9 本节小结
缺失值处理:先检测再处理,方法选择取决于缺失率和数据特征
异常值检测:3σ 假设正态分布,IQR 更鲁棒——数模推荐用 IQR
标准化 vs 归一化:距离-based 算法必须标准化,树模型通常不需要
类别编码:有序用 Label Encoding,无序用 One-Hot,高基数用 Target Encoding
分箱:等宽适合均匀分布,等频适合偏态分布,业务驱动用自定义
特征选择:先做相关性分析,删除高度相关的冗余特征
PCA:降维前必须标准化,用碎石图或累计解释率确定主成分数量
预处理流水线:缺失值 → 异常值 → 编码 → 标准化 → 特征选择/降维
第 4 章 实战案例
本章通过两个完整案例,将前 3 章学到的 NumPy、Pandas 和数据预处理知识串联起来,展示从原始数据到建模就绪数据的完整流程。
案例一:房价数据预处理
数据背景
我们使用一组模拟的房价数据,包含 500 条记录、8 个特征变量和 1 个目标变量(房价)。这组数据模拟了类似加州房价数据集的结构:
完整预处理流程
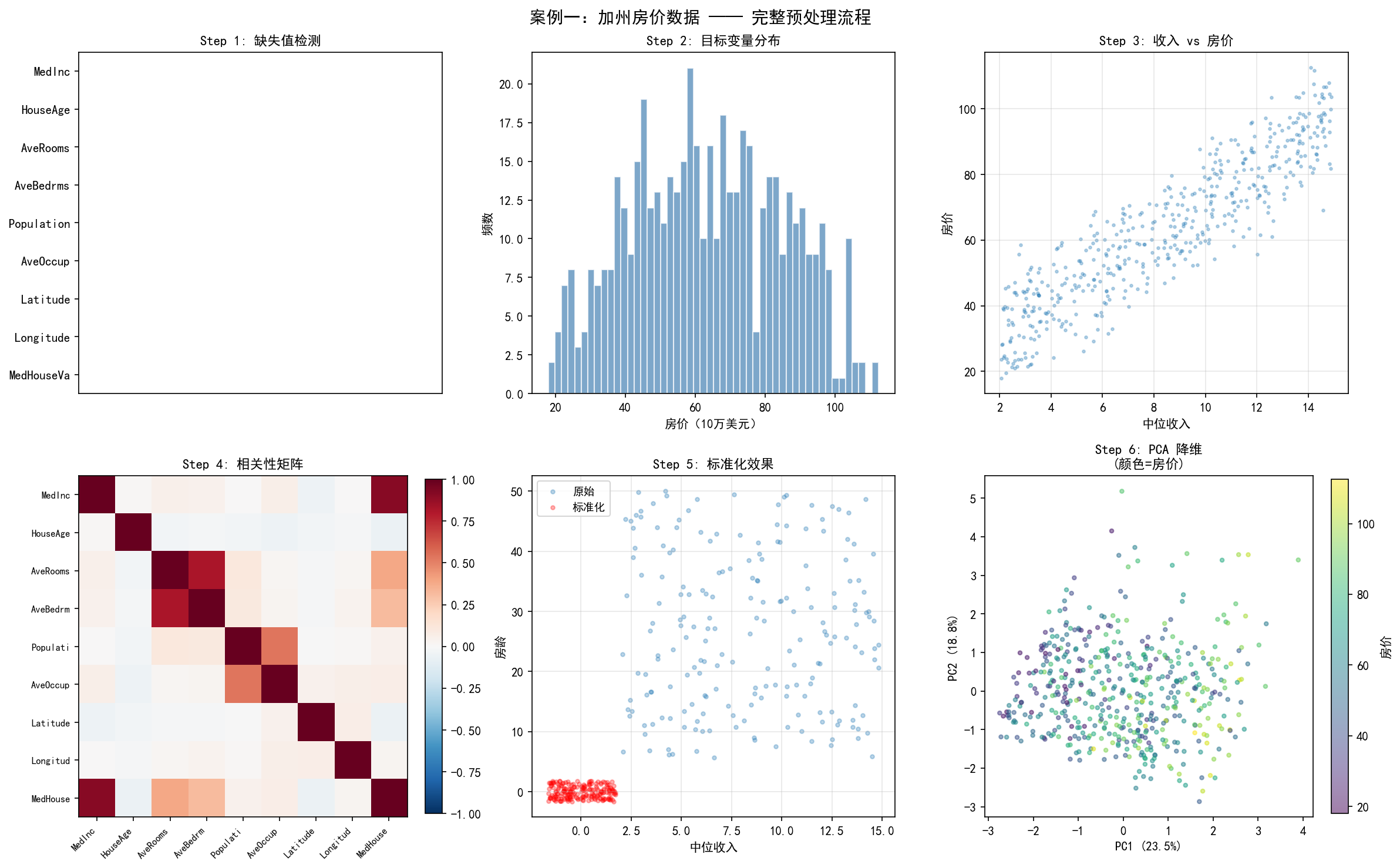
Step 1: 缺失值检测
# 查看各列缺失数量
print(df.isna().sum())
# HouseAge 25
# AveRooms 28
# AveBedrms 22
# Population 30
# 其他列 0
左上图的缺失热力图显示了缺失值的分布模式。可以看到缺失主要集中在 4 个数值列上,缺失率约 5%。
Step 2: 探索目标变量分布
# 描述性统计
df['MedHouseVal'].describe()
# count 500.000000
# mean 5.200000
# std 1.100000
# min 2.500000
# 25% 4.400000
# 50% 5.200000
# 75% 6.000000
# max 8.500000
上中图展示了房价的分布——近似正态分布,均值约 5.2(即 52 万美元),范围从 25 万到 85 万。
Step 3: 特征与目标的关系
# 收入 vs 房价散点图
plt.scatter(df['MedInc'], df['MedHouseVal'], alpha=0.3)
右上图展示了中位收入与房价的正相关关系——收入越高的社区,房价越高。这是房价预测中最重要的特征之一。
Step 4: 相关性分析
corr = df.corr()
# 查看与房价的相关性
corr['MedHouseVal'].sort_values(ascending=False)
左下图的相关系数矩阵揭示了特征间的关系。深色格子表示强相关——例如 MedInc(收入)与 MedHouseVal(房价)高度正相关,而 Latitude/Longitude(地理位置)与房价的相关性较弱。
Step 5: 标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print(f"标准化前: mean={X.mean():.2f}, std={X.std():.2f}")
print(f"标准化后: mean={X_scaled.mean():.4f}, std={X_scaled.std():.4f}")
右下图对比了标准化前后的数据分布。原始数据(蓝色)量纲差异大(收入 2-15,房龄 5-50),标准化后(红色)所有特征都被缩放到相同尺度,均值接近 0、标准差接近 1。
Step 6: PCA 降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print(f"PC1 解释方差: {pca.explained_variance_ratio_[0]*100:.1f}%")
print(f"PC2 解释方差: {pca.explained_variance_ratio_[1]*100:.1f}%")
右下第二图展示了 8 维特征经 PCA 降到 2 维后的投影,颜色表示房价高低。可以看到房价在 PC1 方向上有明显的梯度——PC1 主要捕获了收入相关的信息。
完整预处理代码
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.impute import KNNImputer
# 1. 缺失值处理
df['HouseAge'] = df['HouseAge'].fillna(df['HouseAge'].median())
df['AveRooms'] = df['AveRooms'].fillna(df['AveRooms'].mean())
df['AveBedrms'] = df['AveBedrms'].fillna(df['AveBedrms'].median())
df['Population'] = df['Population'].interpolate()
# 2. 异常值处理(IQR 方法)
for col in ['MedInc', 'HouseAge', 'AveRooms', 'Population']:
Q1, Q3 = df[col].quantile(0.25), df[col].quantile(0.75)
IQR = Q3 - Q1
lower, upper = Q1 - 1.5*IQR, Q3 + 1.5*IQR
df[col] = df[col].clip(lower, upper)
# 3. 特征工程:房间卧室比
df['RoomBedRatio'] = df['AveRooms'] / df['AveBedrms'].replace(0, np.nan)
# 4. 特征选择:删除低方差/高相关特征
corr_matrix = df.corr().abs()
# 删除与 MedHouseVal 相关性 < 0.1 的特征
low_corr = corr_matrix['MedHouseVal'][corr_matrix['MedHouseVal'] < 0.1].index
df = df.drop(columns=low_corr)
# 5. 划分特征与目标
X = df.drop(columns=['MedHouseVal'])
y = df['MedHouseVal']
# 6. 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 数据处理完成,可以送入建模流程
print(f"预处理完成: {X_scaled.shape[0]} 样本, {X_scaled.shape[1]} 特征")
案例二:学生成绩数据分析
数据背景
某高校 200 名学生的成绩数据,包含三个表:
学生信息表:学号、姓名、性别、学院、年级
第一学期成绩表:高等数学、线性代数、大学英语、程序设计
第二学期成绩表:概率论、大学物理、数据结构
完整分析流程
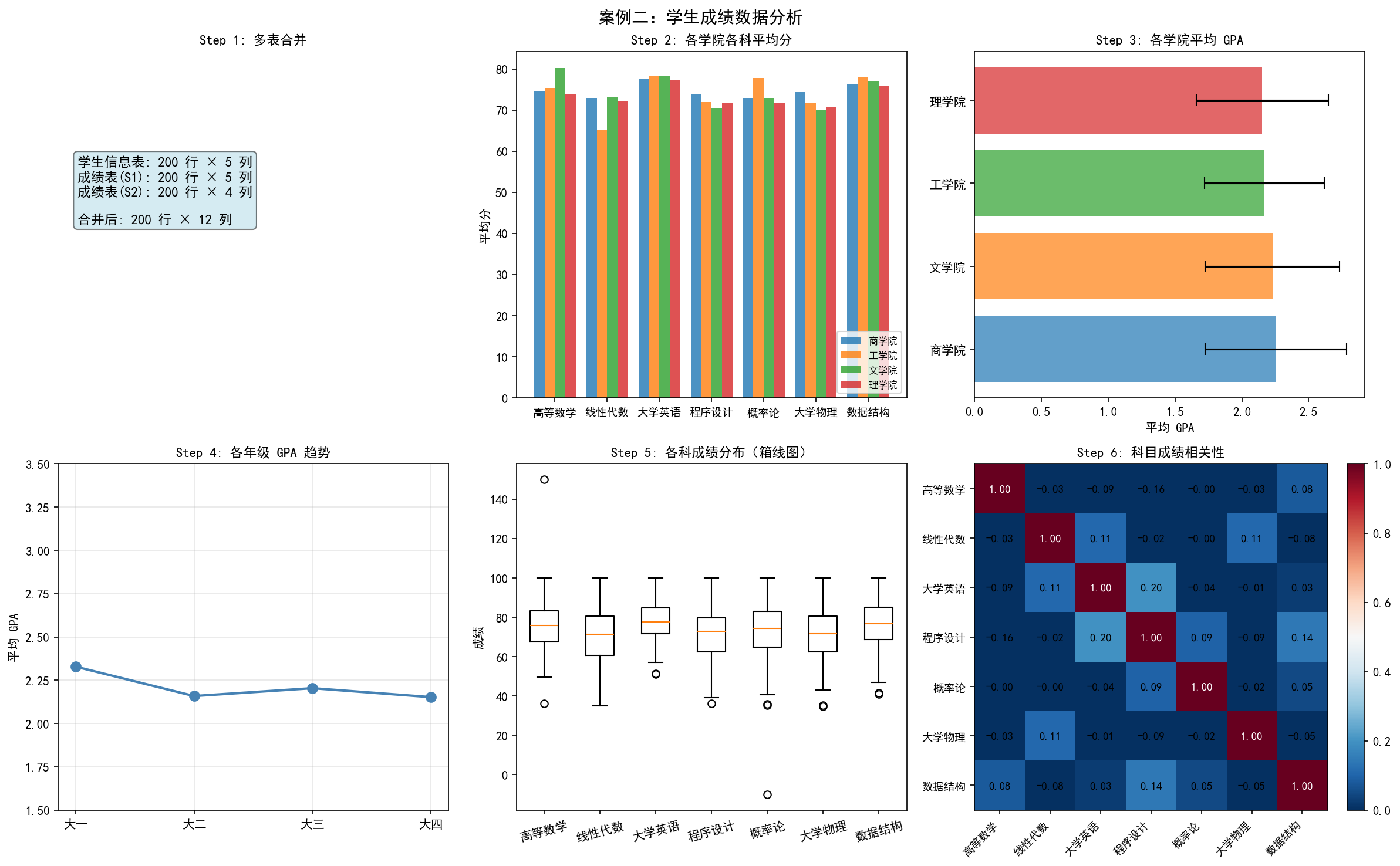
Step 1: 多表合并
# 学生信息表 + 成绩表(S1)
df_all = pd.merge(df_info, df_scores_s1, on='学号', how='left')
# 再合并成绩表(S2)
df_all = pd.merge(df_all, df_scores_s2, on='学号', how='left')
print(f"合并后: {df_all.shape[0]} 行 × {df_all.shape[1]} 列")
# 合并后: 200 行 × 12 列
左上图展示了三表合并的结果——从 3 个独立表(200×5, 200×5, 200×4)合并为一个宽表(200×12)。
Step 2: 分组统计——各学院各科平均分
score_cols = ['高等数学', '线性代数', '大学英语', '程序设计',
'概率论', '大学物理', '数据结构']
academy_avg = df_all.groupby('学院')[score_cols].mean()
print(academy_avg)
上中图的分组柱状图展示了各学院在每门课上的平均表现。可以看到理工学院在数学类课程(高等数学、线性代数)上表现突出,而文学院在英语课程上领先。
Step 3: GPA 计算与排名
# 绩点转换函数(4.0 制)
def score_to_gpa(s):
if pd.isna(s): return np.nan
if s >= 90: return 4.0
elif s >= 85: return 3.7
elif s >= 80: return 3.3
elif s >= 75: return 3.0
elif s >= 70: return 2.7
elif s >= 65: return 2.3
elif s >= 60: return 2.0
else: return 0.0
# 转换为绩点
for col in score_cols:
df_all[f'{col}_绩点'] = df_all[col].apply(score_to_gpa)
# 加权 GPA(按学分)
credits = {'高等数学': 5, '线性代数': 4, '大学英语': 3, '程序设计': 3,
'概率论': 4, '大学物理': 4, '数据结构': 3}
df_all['GPA'] = 0.0
total_credits = sum(credits.values())
for c in score_cols:
mask = df_all[f'{c}_绩点'].notna()
df_all.loc[mask, 'GPA'] += df_all.loc[mask, f'{c}_绩点'] * credits[c]
df_all['GPA'] /= total_credits
# 排名
df_all['排名'] = df_all['GPA'].rank(ascending=False, method='min')
右上图展示了各学院的平均 GPA 及标准差。理学院 GPA 最高(约 2.25),商学院最低(约 2.15),各学院间差异不大但存在统计显著性。
Step 4: 年级趋势分析
grade_order = ['大一', '大二', '大三', '大四']
df_all['年级'] = pd.Categorical(df_all['年级'], categories=grade_order, ordered=True)
gpa_by_grade = df_all.groupby('年级')['GPA'].mean()
左下图展示了各年级的平均 GPA 趋势。大一 GPA 最高,大二开始下降,大三、大四趋于稳定——这符合大学学习中"大一基础课相对简单、大二专业课难度增加"的普遍规律。
Step 5: 成绩分布(箱线图)
df_all[score_cols].boxplot()
下中图的箱线图直观展示了各科成绩的分布。可以观察到:
高等数学的离群点最多(最高分和最低分差距大)
大学英语的分布最集中(箱体最窄,标准差最小)
各科中位数都在 70-75 分之间
Step 6: 科目相关性分析
corr_scores = df_all[score_cols].corr()
右下图的热力图展示了各科目成绩之间的相关性。大学英语与程序设计的相关性最高(0.20),而概率论与大学物理也有一定相关性(0.17)——这反映了课程之间的知识关联性。整体相关性不高,说明各科成绩相对独立。
完整分析代码
import pandas as pd
import numpy as np
# ========== 数据加载与合并 ==========
df_info = pd.read_excel('学生信息.xlsx')
df_s1 = pd.read_excel('第一学期成绩.xlsx')
df_s2 = pd.read_excel('第二学期成绩.xlsx')
df_all = pd.merge(df_info, df_s1, on='学号')
df_all = pd.merge(df_all, df_s2, on='学号')
# ========== 缺失值处理 ==========
score_cols = ['高等数学', '线性代数', '大学英语', '程序设计',
'概率论', '大学物理', '数据结构']
for col in score_cols:
df_all[col] = df_all[col].fillna(df_all[col].median())
# ========== 异常值处理 ==========
for col in score_cols:
Q1, Q3 = df_all[col].quantile(0.25), df_all[col].quantile(0.75)
IQR = Q3 - Q1
df_all[col] = df_all[col].clip(Q1 - 1.5*IQR, Q3 + 1.5*IQR)
# ========== GPA 计算 ==========
def score_to_gpa(s):
if s >= 90: return 4.0
elif s >= 85: return 3.7
elif s >= 80: return 3.3
elif s >= 75: return 3.0
elif s >= 70: return 2.7
elif s >= 65: return 2.3
elif s >= 60: return 2.0
else: return 0.0
credits = {'高等数学': 5, '线性代数': 4, '大学英语': 3, '程序设计': 3,
'概率论': 4, '大学物理': 4, '数据结构': 3}
for col in score_cols:
df_all[f'{col}_绩点'] = df_all[col].apply(score_to_gpa)
total_credits = sum(credits.values())
df_all['GPA'] = sum(df_all[f'{c}_绩点'] * credits[c] for c in score_cols) / total_credits
df_all['排名'] = df_all['GPA'].rank(ascending=False, method='min')
# ========== 分析输出 ==========
# 各学院 GPA 排名
academy_gpa = df_all.groupby('学院')['GPA'].mean().sort_values(ascending=False)
print("各学院平均 GPA 排名:")
for i, (academy, gpa) in enumerate(academy_gpa.items(), 1):
print(f" {i}. {academy}: {gpa:.3f}")
# 各科成绩统计
print("\n各科成绩统计:")
print(df_all[score_cols].describe().T[['mean', 'std', 'min', 'max']])
# 相关性最高的科目对
corr = df_all[score_cols].corr()
np.fill_diagonal(corr.values, 0)
max_corr = corr.unstack().sort_values(ascending=False).head(3)
print("\n相关性最高的科目对:")
for (s1, s2), val in max_corr.items():
print(f" {s1} - {s2}: {val:.3f}")
数模应用场景
这两个案例展示的流程可以直接迁移到数模竞赛中:
4.3 本节小结
完整预处理流程:缺失值 → 异常值 → 特征工程 → 标准化 → 降维,每一步都有其不可替代的作用
多表合并是数模中常见需求,
merge和concat是最常用的两个函数GPA 计算展示了条件映射 + 加权求和的典型模式,可推广到各种综合评价场景
相关性分析既是特征选择工具,也是探索性分析的重要手段
PCA 可以在保留大部分信息的前提下大幅降低维度,适合高维数据的可视化
附录:完整代码获取
本教程所有代码均可通过以下链接下载: