
提高篇:Scikit-learn库求解传统机器学习模型方法
前言
Scikit-learn是 Python 生态中最成熟的机器学习库。它提供了一致的 API 接口、丰富的算法实现和完善的工具链,覆盖了从数据预处理、模型训练到评估优化的完整流程。对于学习机器学习的学生来说,sklearn 是最实用的入门工具。
适用读者
本教程面向学习数学建模的学生。如果你已经具备以下基础,就可以直接开始:
基本的 Python 编程能力
线性代数基础(矩阵运算、向量)
概率论基础(条件概率、期望、方差)
了解什么是监督学习(训练集/测试集的概念)
本教程不讲解算法的深层数学推导,而是聚焦于理解核心思想 + 用代码实现 + 知道何时使用哪个算法。
内容结构
环境说明
Python 版本:3.8+
sklearn 版本:1.5+
数据源:优先使用
sklearn.datasets内置的模拟数据(make_*系列),避免网络依赖可视化:Matplotlib + 中文字体适配
所有代码示例均可直接复制运行。每章配有独立的可视化脚本(scripts/chXX_*.py),生成对应章节的图片(images/chXX_*.png)。
运行方式
# 安装依赖(如未安装)
pip install scikit-learn matplotlib numpy
# 运行某章的可视化脚本
python scripts/ch01_linear_regression.py
# 导入核心模块
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score, r2_score
学习建议
按章节顺序阅读,第 1~3 章是基础,后续章节依赖这些概念
每章先理解核心思想,再动手跑代码,最后看可视化结果加深印象
每章结尾的"实用技巧速查"和"数模竞赛中的应用"可以快速回顾
第 9 章提供算法对比和选型指南,适合完成全部章节后作为总结
竞赛实战中:随机森林是最实用的"万金油",建议优先掌握
各章之间的关系
第1~2章建立回归和分类的基本范式
第3章是核心方法论:如何判断模型好不好、如何改进
第4~6章介绍三类不同思想的算法(基于距离、基于概率、基于几何)
第7~8章介绍树模型和集成学习,是实践中最常用的算法族
第9章将所有算法放在一起对比,提供选型决策框架
第1章 线性回归
1.1 线性回归的基本原理
线性回归(Linear Regression)是最基础、最常用的监督学习算法之一。其核心思想是用一个线性函数来拟合输入特征 X 与目标变量 y 之间的关系。
对于单个特征的情况:
其中 β0 是截距,β1 是斜率(回归系数),ε 是误差项。
对于多特征情况,矩阵形式为:
线性回归通过最小二乘法(Ordinary Least Squares, OLS)求解最优系数,即最小化残差平方和:
1.1.1 简单线性回归示例
import numpy as np
from sklearn.linear_model import LinearRegression
np.random.seed(42)
X = np.linspace(0, 10, 50).reshape(-1, 1)
y = 3 * X.ravel() + 5 + np.random.randn(50) * 3
model = LinearRegression().fit(X, y)
print(f'拟合直线: y = {model.coef_[0]:.2f}x + {model.intercept_:.2f}')
print(f'R² 评分: {model.score(X, y):.3f}')
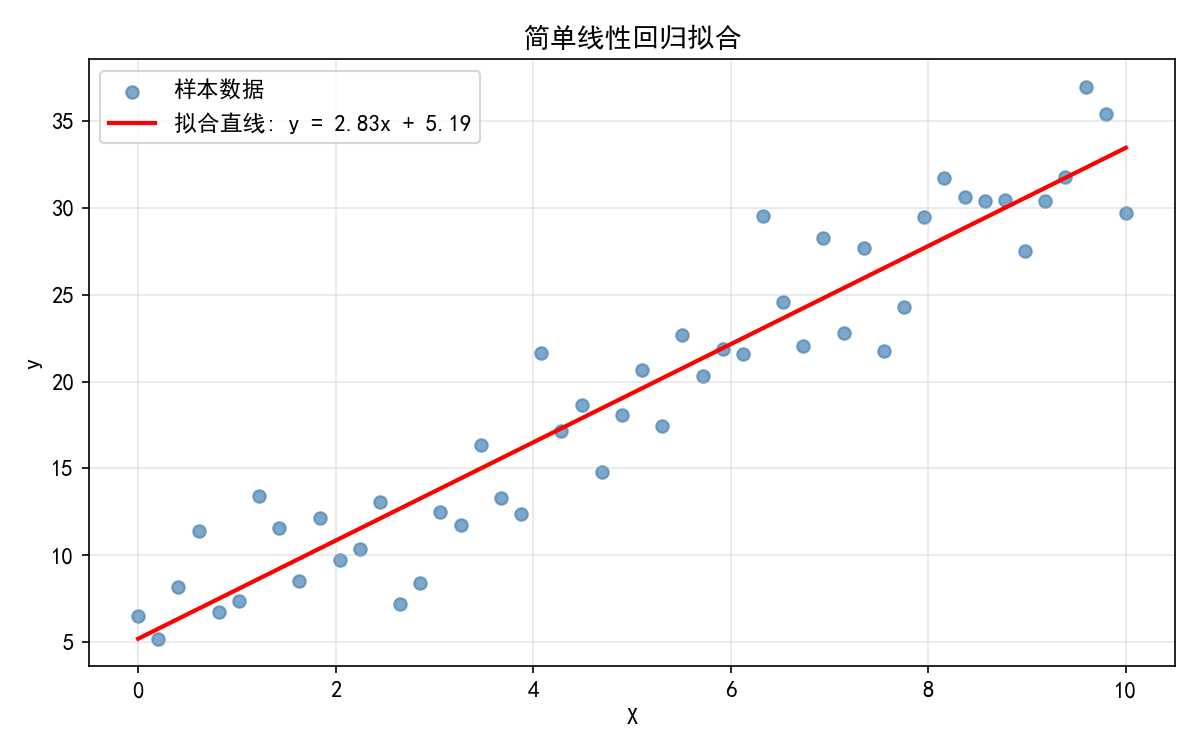
拟合结果:y=2.83x+5.19,与真实参数 y=3x+5 非常接近。 表明模型解释了约 89% 的方差。
1.2 评估指标
sklearn 提供了三种常用的回归评估指标:
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
y_pred = model.predict(X_test)
print(f'MSE: {mean_squared_error(y_test, y_pred):.3f}')
print(f'MAE: {mean_absolute_error(y_test, y_pred):.3f}')
print(f'R²: {r2_score(y_test, y_pred):.3f}')
1.3 正则化:Ridge、Lasso 与 ElasticNet
当特征数量多或特征之间存在共线性时,普通最小二乘容易过拟合。正则化通过在损失函数中加入惩罚项来约束系数大小。
1.3.1 三种正则化方法
损失函数形式:
Ridge:
Lasso:
ElasticNet:
1.3.2 系数收缩可视化
from sklearn.linear_model import Ridge, Lasso, ElasticNet
models = {
'普通最小二乘': LinearRegression(),
'Ridge (α=1)': Ridge(alpha=1.0),
'Ridge (α=10)': Ridge(alpha=10.0),
'Lasso (α=0.5)': Lasso(alpha=0.5),
'ElasticNet': ElasticNet(alpha=0.5, l1_ratio=0.5),
}
for name, mdl in models.items():
mdl.fit(X, y)
print(f'{name}: 系数绝对值之和 = {np.sum(np.abs(mdl.coef_)):.2f}')
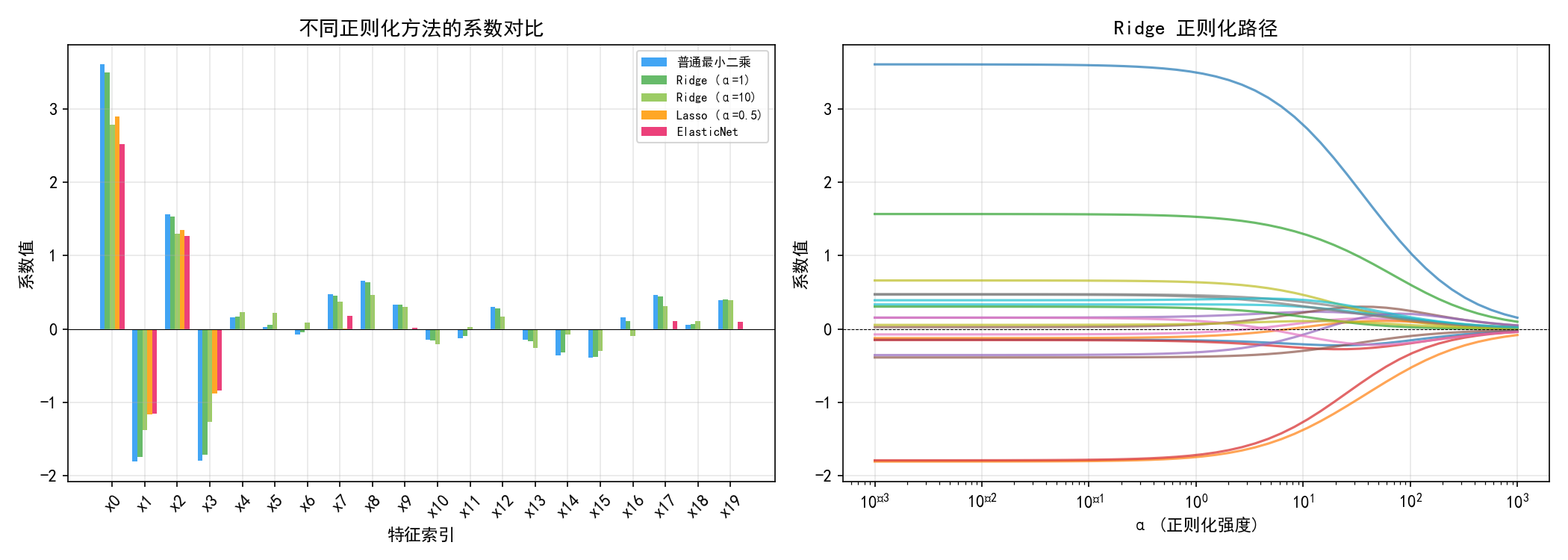
左图展示了不同方法对 20 个特征系数的影响:
普通最小二乘(蓝色):无约束,部分噪声特征也有较大系数
Ridge(绿色):所有系数均匀缩小,α 越大收缩越强
Lasso(橙色):将许多无关特征的系数压缩为零(特征选择效果)
ElasticNet(粉色):兼具 Ridge 的稳定性与 Lasso 的稀疏性
右图展示了 Ridge 正则化路径:随着 α 增大,所有系数逐渐趋近于零。
1.3.3 正则化路径
from sklearn.linear_model import Ridge
alphas = np.logspace(-3, 3, 50)
ridge_coefs = []
for a in alphas:
ridge = Ridge(alpha=a).fit(X, y)
ridge_coefs.append(ridge.coef_)
# 可视化不同 alpha 下的系数变化
for i in range(n_features):
plt.plot(alphas, ridge_coefs[:, i])
plt.xscale('log')
αα 的选择至关重要:
α→0:退化为普通最小二乘
α→∞:所有系数趋近于零(欠拟合)
通常通过交叉验证选择最优 α(见第3章)
1.4 多项式回归
当数据呈现非线性关系时,可以通过多项式特征扩展将线性回归应用于非线性问题:
sklearn 中通过 PolynomialFeatures 生成多项式特征:
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 三次多项式回归
poly_model = make_pipeline(PolynomialFeatures(degree=3), LinearRegression())
poly_model.fit(X_train, y_train)
# 等价于:
# poly = PolynomialFeatures(degree=3)
# X_poly = poly.fit_transform(X_train)
# model = LinearRegression().fit(X_poly, y_train)
1.4.1 欠拟合 vs 合适 vs 过拟合
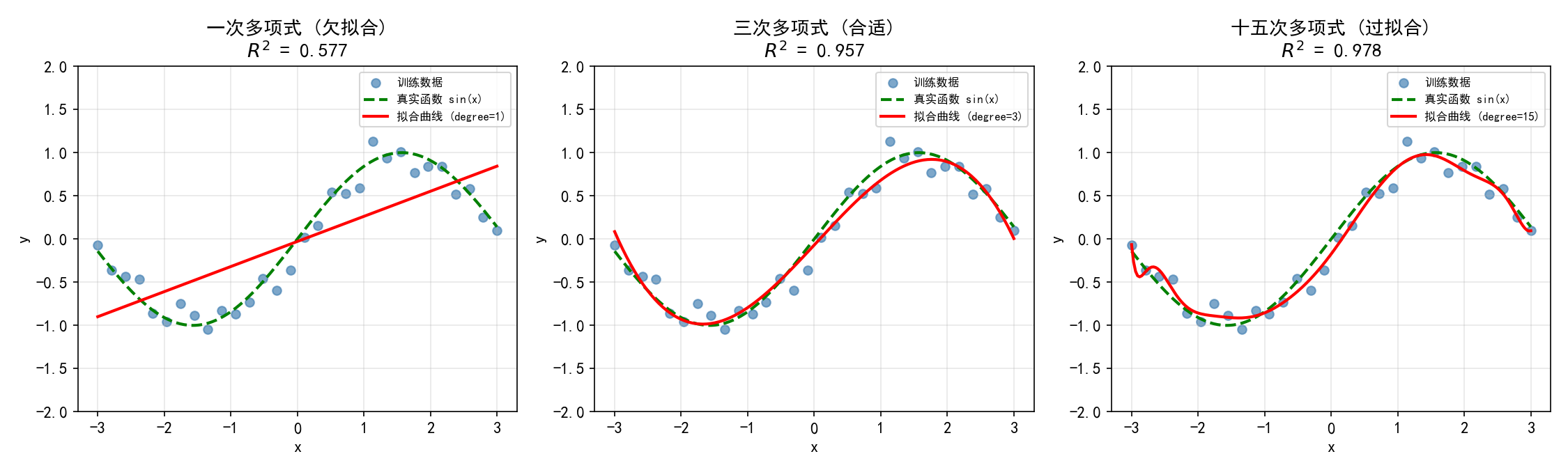
一次多项式(欠拟合):模型过于简单,无法捕捉数据的非线性模式,
三次多项式(合适):模型复杂度适中,很好地拟合了 sin(x) 的趋势,
十五次多项式(过拟合):模型过于复杂,训练集上 很高,但拟合曲线严重扭曲,在新数据上表现会很差
关键教训:训练集上的高 不代表模型好!过拟合的模型在测试集上会表现糟糕。需要通过交叉验证(第3章)来选择合适的多项式次数。
1.5 残差分析
残差 是模型诊断的重要工具。一个好的线性回归模型应满足:
残差均值为零,无明显趋势
残差服从正态分布
残差方差恒定(同方差性)
残差之间相互独立
# 拟合模型
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
lr = LinearRegression().fit(X_train, y_train)
y_pred = lr.predict(X_train)
residuals = y_train - y_pred
# 四宫格残差分析图
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# (1) 残差 vs 预测值 — 检查异方差性
# (2) 残差直方图 — 检查正态性
# (3) 真实值 vs 预测值 — 检查拟合质量
# (4) Q-Q 图 — 检查正态性
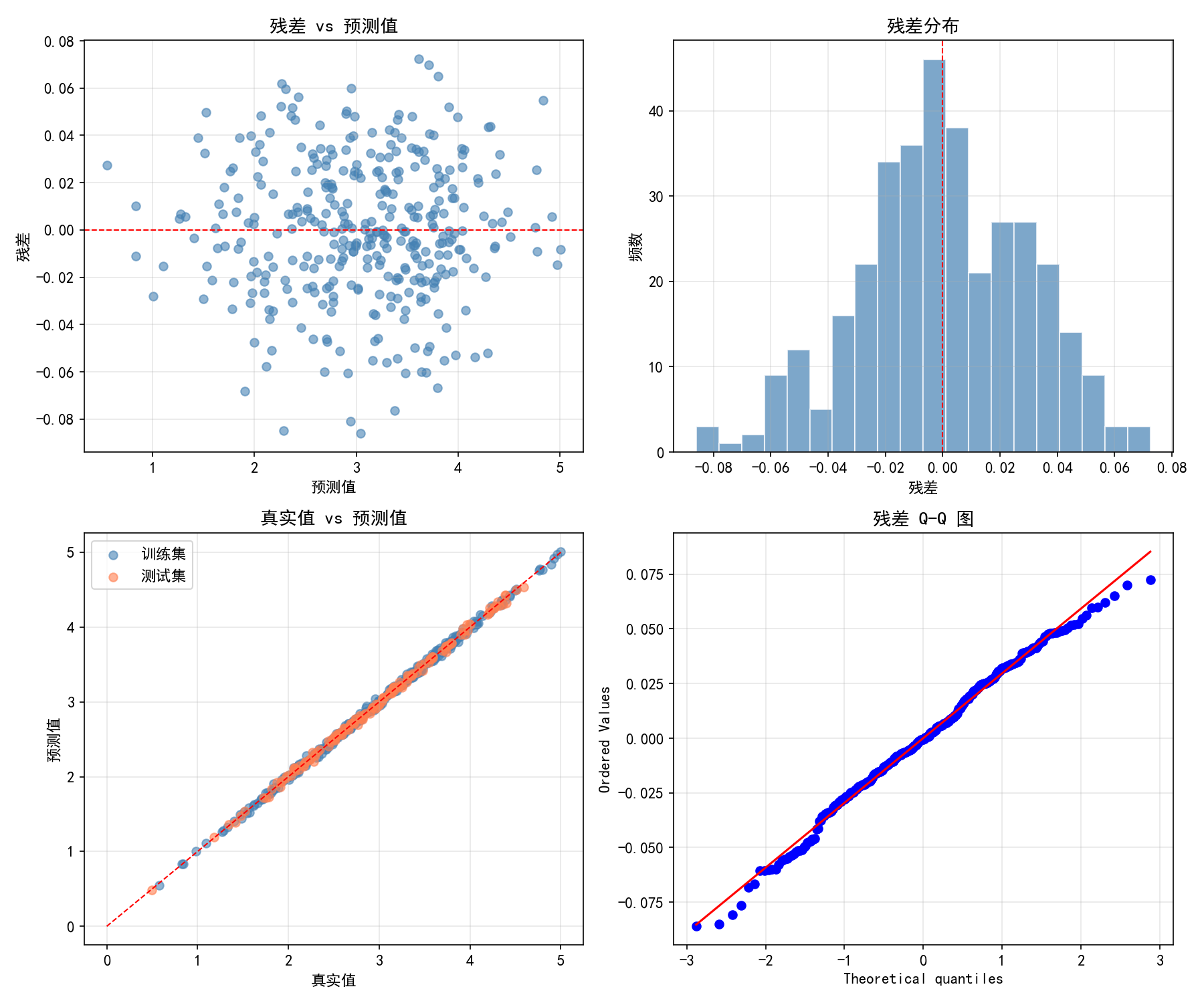
四宫格解读:
1.6 模型性能对比
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
model_list = {
'线性回归': LinearRegression(),
'Ridge (α=1)': Ridge(alpha=1),
'Lasso (α=0.1)': Lasso(alpha=0.1),
'多项式(deg=3)': make_pipeline(PolynomialFeatures(3), LinearRegression()),
}
for name, mdl in model_list.items():
mdl.fit(X_train, y_train)
y_p = mdl.predict(X_test)
print(f'{name}: R²={r2_score(y_test, y_p):.3f}, '
f'MSE={mean_squared_error(y_test, y_p):.2f}, '
f'MAE={mean_absolute_error(y_test, y_p):.2f}')
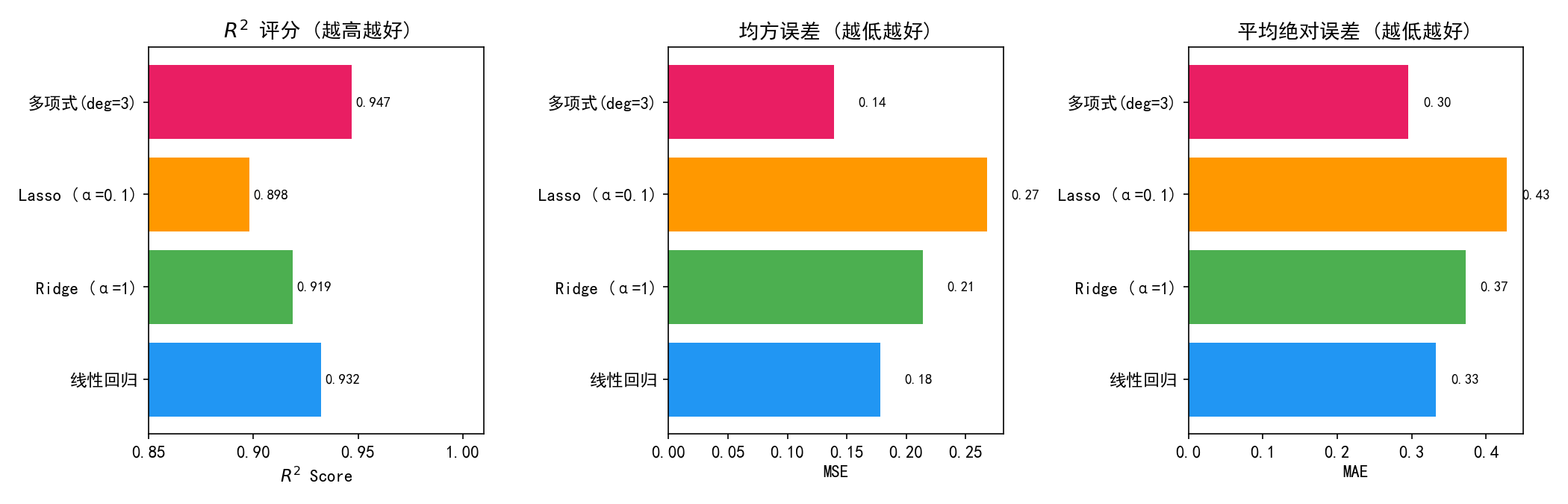
在这个非线性数据上():
多项式回归(deg=3) 表现最好(),因为它正确匹配了数据的真实结构
线性回归()由于数据有二次和三次项,存在一定偏差
Lasso 表现最差(),因为 L1 正则化过度压缩了系数
1.7 实用技巧速查
1.8 数模竞赛中的线性回归
在数学建模竞赛中,线性回归常用于:
趋势预测:基于历史数据拟合趋势线,外推未来值
因素分析:通过回归系数判断各因素对目标变量的影响程度
数据补全:用回归模型填补缺失值
基线模型:作为更复杂模型的对比基准
注意事项:
使用前务必检查变量之间的相关性(高相关特征会导致共线性)
对量纲差异大的特征进行标准化(
StandardScaler)通过残差分析验证模型假设是否成立
不要仅看 ,要结合 MSE/MAE 和业务意义综合评估
1.9 本节小结
线性回归通过最小二乘法拟合线性关系,是理解所有回归模型的基础
、MSE、MAE 是三种核心评估指标,各有侧重
Ridge 用 L2 惩罚防止过拟合,Lasso 用 L1 惩罚实现特征选择
多项式回归通过特征扩展处理非线性关系,但需注意过拟合风险
残差分析是诊断模型质量的必备工具:检查正态性、同方差性和独立性
数模竞赛中,线性回归常用于趋势预测和因素分析,需注意数据预处理和假设检验
第2章 逻辑回归
2.1 从线性回归到逻辑回归
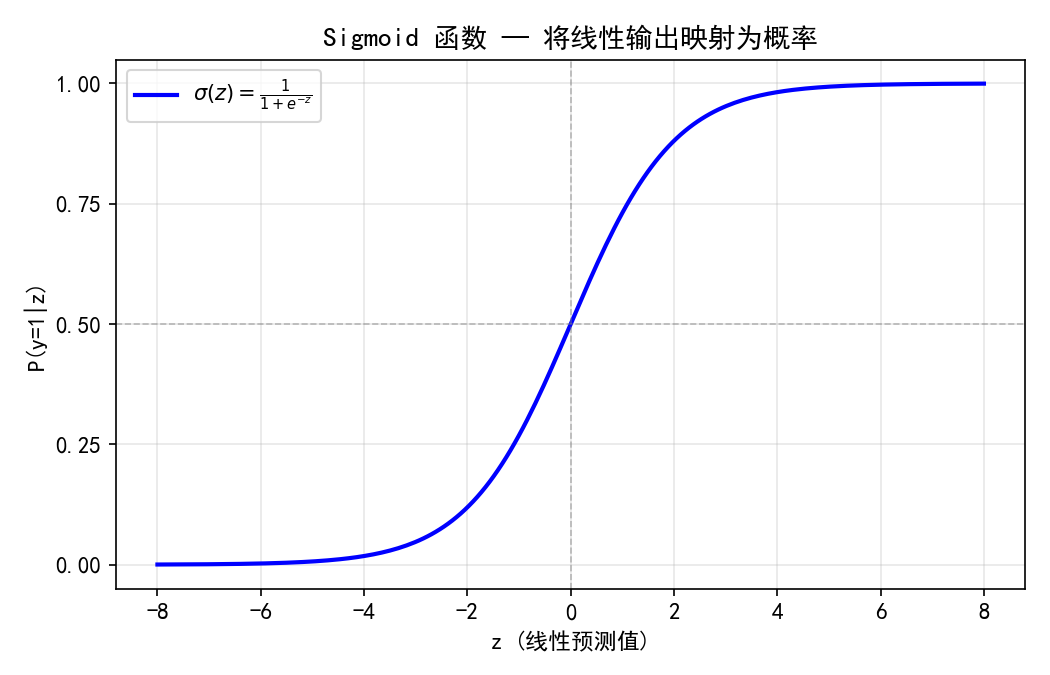
线性回归的输出是连续值,无法直接用于分类任务。逻辑回归(Logistic Regression)通过 Sigmoid 函数将线性输出映射到 [0,1] 区间,解释为样本属于正类的概率:
反解后得到 logit 变换:
这说明逻辑回归本质上是对 log-odds(对数几率)做线性建模。
2.1.1 Sigmoid 函数
当 z≫0 时,σ(z)→1(高概率为正类)
当 z≪0 时,σ(z)→0(高概率为负类)
当 z=0 时,σ(z)=0.5(决策阈值)
Sigmoid 的平滑特性使得逻辑回归可以输出概率估计,而不仅是硬分类标签。
2.2 二分类逻辑回归
2.2.1 基本用法
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=200, n_features=2, random_state=42)
lr = LogisticRegression().fit(X, y)
# 预测类别
y_pred = lr.predict(X_test)
# 预测概率
y_proba = lr.predict_proba(X_test) # 返回 [P(y=0), P(y=1)]
2.2.2 决策边界
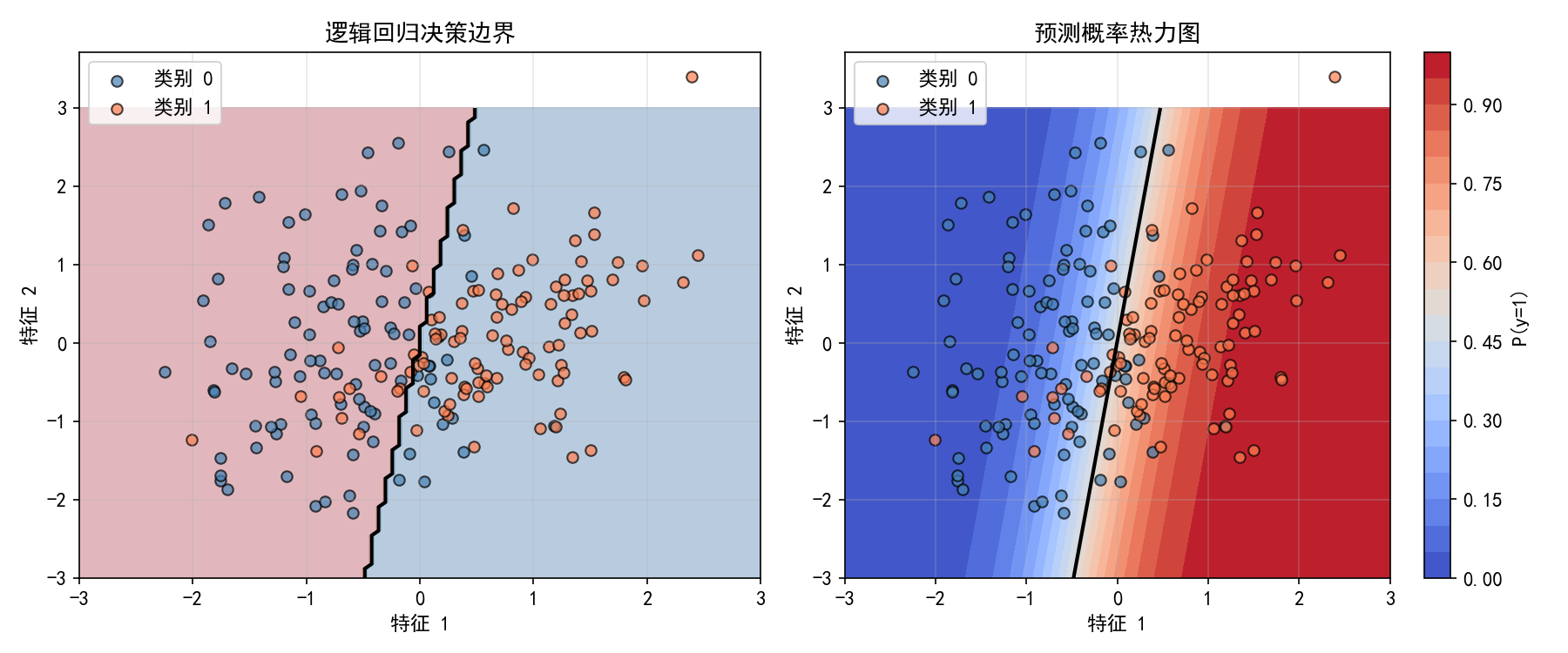
左图:逻辑回归在二维特征空间上构建了一条线性决策边界(黑色实线),将空间分为两个区域。
右图:概率热力图展示了模型对空间中每个点的置信度——蓝色区域表示低概率(负类),红色区域表示高概率(正类),决策边界对应概率 P(y=1)=0.5 的等高线。
注意:决策边界的线性特性源于线性预测器 。若需要非线性边界,可以结合多项式特征(见第1章)或使用核方法(见第6章 SVM)。
2.2.3 正则化参数 C 的影响
逻辑回归的正则化参数 C 是正则化强度 α 的倒数(C=1/α):
C 越大(正则化越弱):系数更大,决策边界更陡峭,容易过拟合
C 越小(正则化越强):系数被压缩,决策边界更平缓
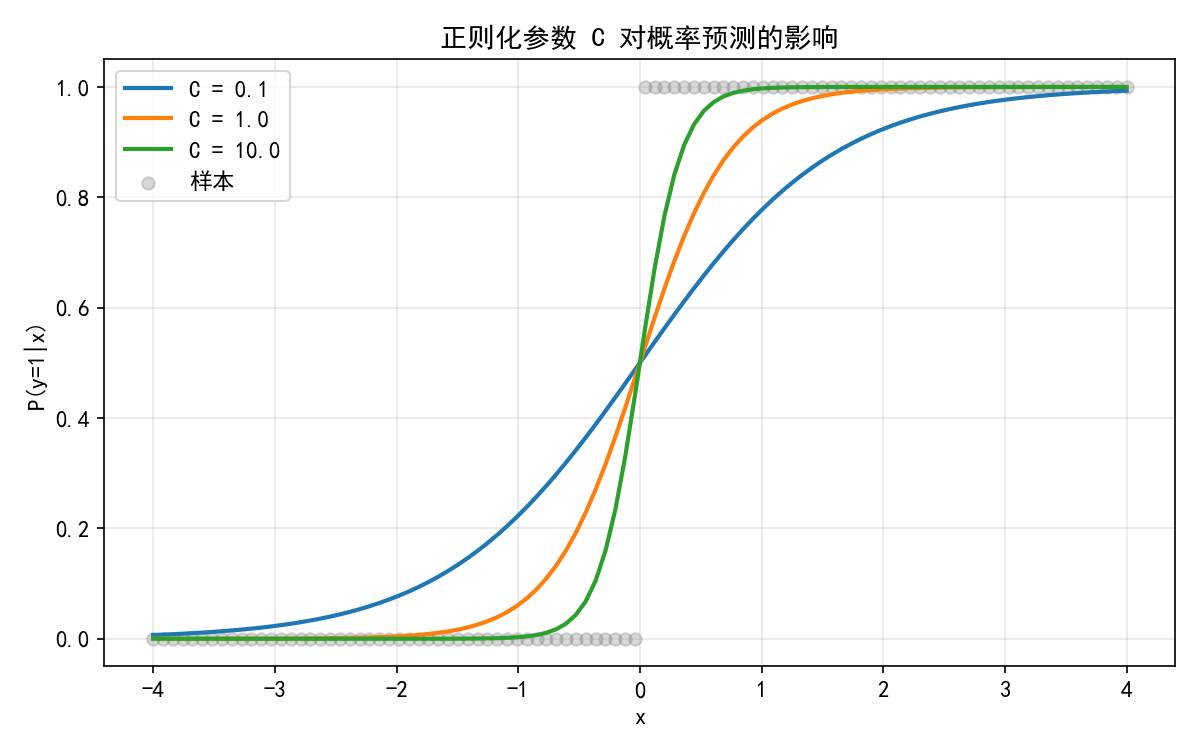
C = 0.1(强正则化):概率曲线平缓,模型"犹豫不决"
C = 1.0(默认):适中的置信度
C = 10.0(弱正则化):概率接近 0 或 1,模型非常自信
sklearn 默认使用 L2 正则化,默认
C=1.0。可通过penalty='l1'切换为 Lasso 风格,或通过penalty='elasticnet'同时使用 L1+L2(需solver='saga')。
2.3 多分类策略
当类别数 K>2 时,sklearn 的 LogisticRegression 支持两种策略:
在 sklearn 1.7+ 中,multi_class 参数已被移除,策略由 solver 自动决定:lbfgs/newton-cg/sag/saga 默认用 Multinomial;若需 OvR 可通过 OneVsRestClassifier 包装。
2.3.1 多分类可视化
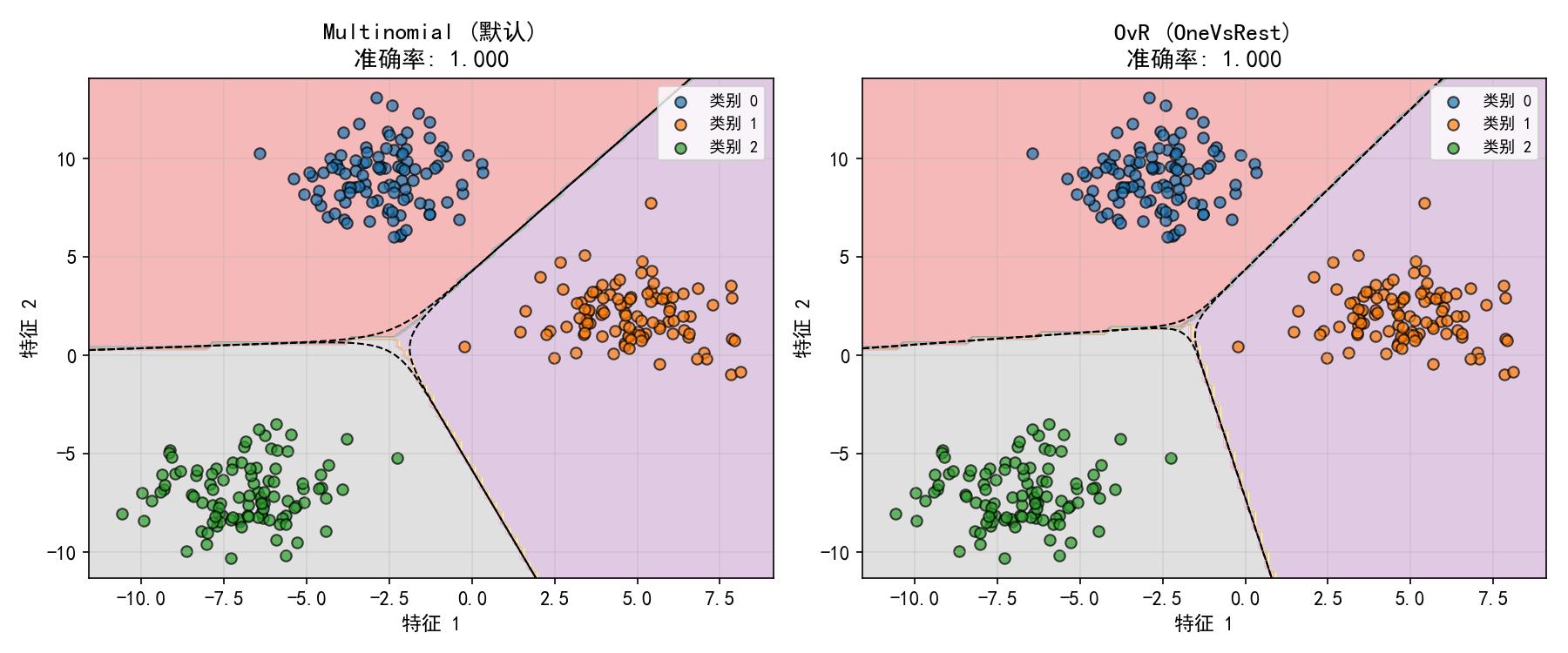
两个策略在这个三分类任务上都达到了 100% 的训练准确率。Multinomial 和 OvR 在简单数据集上差异不大,但在类别不平衡或复杂特征空间时,Multinomial 通常表现更好。
from sklearn.multiclass import OneVsRestClassifier
# Multinomial(默认)
lr_multi = LogisticRegression(solver='lbfgs', max_iter=1000).fit(X, y)
# OvR
lr_ovr = OneVsRestClassifier(LogisticRegression(solver='lbfgs', max_iter=1000)).fit(X, y)
2.4 模型评估:混淆矩阵与 ROC 曲线
2.4.1 混淆矩阵
from sklearn.metrics import confusion_matrix, classification_report
cm = confusion_matrix(y_test, y_pred)
print(classification_report(y_test, y_pred))
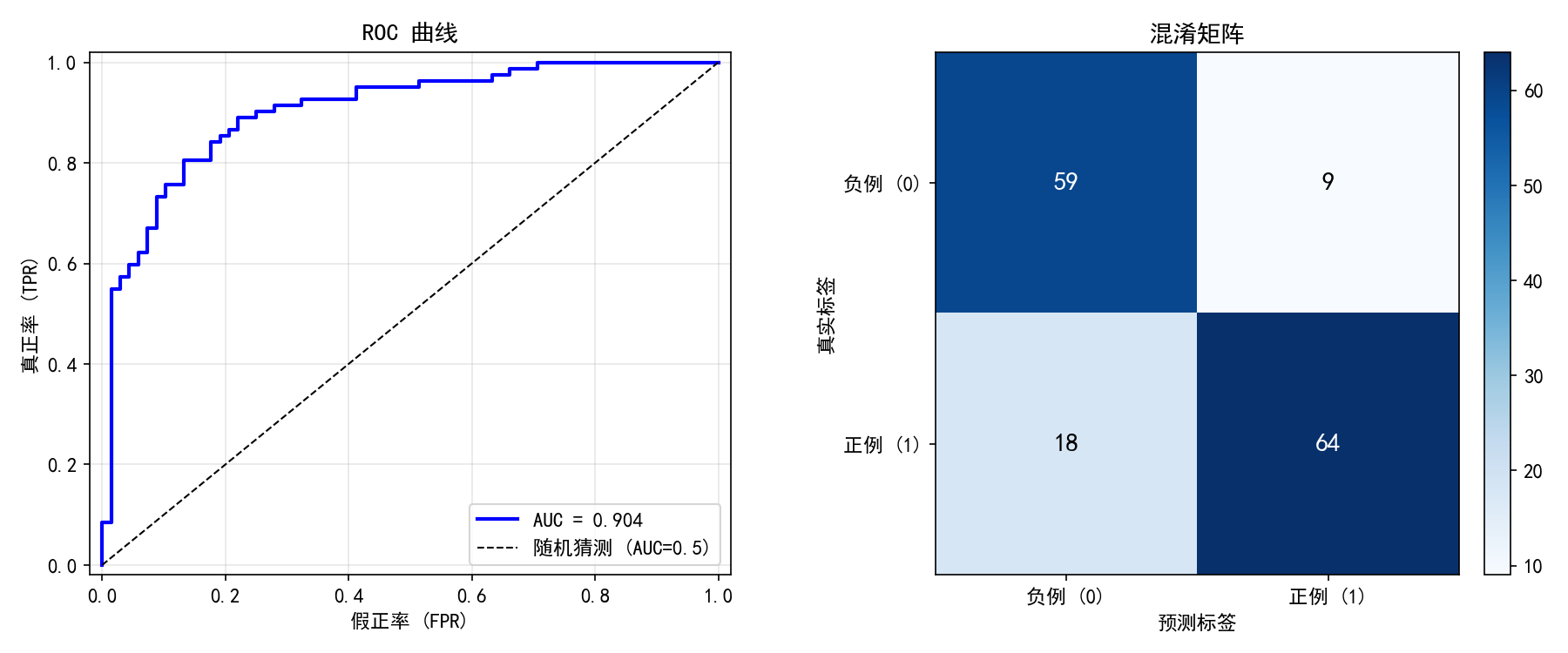
右图:混淆矩阵展示了 150 个测试样本的分类结果:
常用指标:
准确率 (Accuracy) =
精确率 (Precision) =
召回率 (Recall) =
F1 Score =
2.4.2 ROC 曲线与 AUC
左图:ROC 曲线展示了不同分类阈值下 真正率(TPR) 与 假正率(FPR) 的权衡。
对角线(虚线):随机猜测的基准线(AUC = 0.5)
曲线越靠近左上角:模型区分能力越强
AUC = 0.904:表示随机选取一个正例和一个负例,模型给正例打更高分的概率为 90.4%
AUC 的取值范围与含义:
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_score)
roc_auc = auc(fpr, tpr)
2.5 损失函数
逻辑回归使用 对数损失(Log Loss / Cross-Entropy)作为优化目标:
当真实标签 yi=1 但预测概率 时,损失趋近无穷大——模型会受到严厉惩罚
当预测准确时,损失接近零
这比使用 0-1 损失(分类错误计数)的优势在于:对数损失考虑了预测的置信度,即使分类正确,如果概率很低也会受到惩罚。
2.6 实用技巧速查
2.7 数模竞赛中的应用
逻辑回归在数学建模竞赛中常用于:
二分类预测:如"是否违约"、"是否患病"、"是否成交"
概率评分:输出概率可作为风险评分,辅助决策排序
因素分析:通过系数符号和大小(或优势比)判断各因素的影响方向与强度
基线模型:作为分类任务的基线,与决策树、SVM 等复杂模型对比
注意事项:
特征需标准化后再输入(特别是使用 L1/L2 正则化时)
类别不平衡时可使用
class_weight='balanced'共线性强的特征会导致系数不稳定——先用 Ridge 或做特征筛选
AUC 比准确率更适合评估不平衡数据的分类性能
2.8 本节小结
逻辑回归通过 Sigmoid 函数将线性输出映射为概率,可用于分类任务
决策边界是线性的,但可通过多项式特征扩展实现非线性分类
正则化参数 C 控制模型复杂度:C 越大越容易过拟合
多分类支持 Multinomial(softmax)和 OvR(一对多)两种策略
混淆矩阵拆解了分类结果的 TP/TN/FP/FN,ROC/AUC 衡量模型整体区分能力
对数损失函数同时考虑分类正确性和预测置信度
数模竞赛中,逻辑回归是分类任务的基线模型,优势在于可解释性强(系数→优势比)
第3章 模型改善与泛化
3.1 偏差-方差权衡
机器学习的核心挑战之一是偏差-方差权衡(Bias-Variance Tradeoff):
高偏差(欠拟合):模型过于简单,无法捕捉数据中的模式
高方差(过拟合):模型过于复杂,过度拟合训练数据的噪声
合适的模型:在偏差和方差之间找到平衡点
3.1.1 直观演示
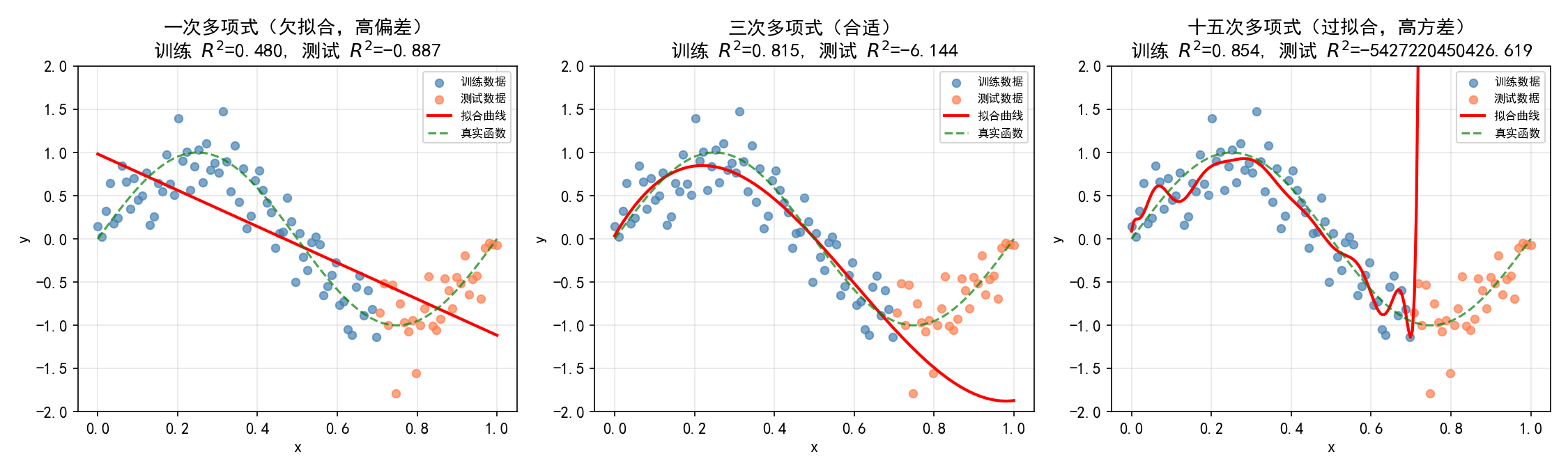
用不同次数的多项式回归拟合 sin(2πx)+ε:
注意:测试集 为负值意味着模型预测比直接用均值预测还差——这是严重过拟合的标志。
核心教训:训练集上的高评分 ≠ 好模型。评估泛化能力必须使用未见过的数据。
3.2 交叉验证
交叉验证(Cross-Validation)是评估模型泛化能力的黄金标准。其基本思想:将数据分为 K 折,轮流用其中一折做测试,其余做训练。
3.2.1 K 折交叉验证示意图
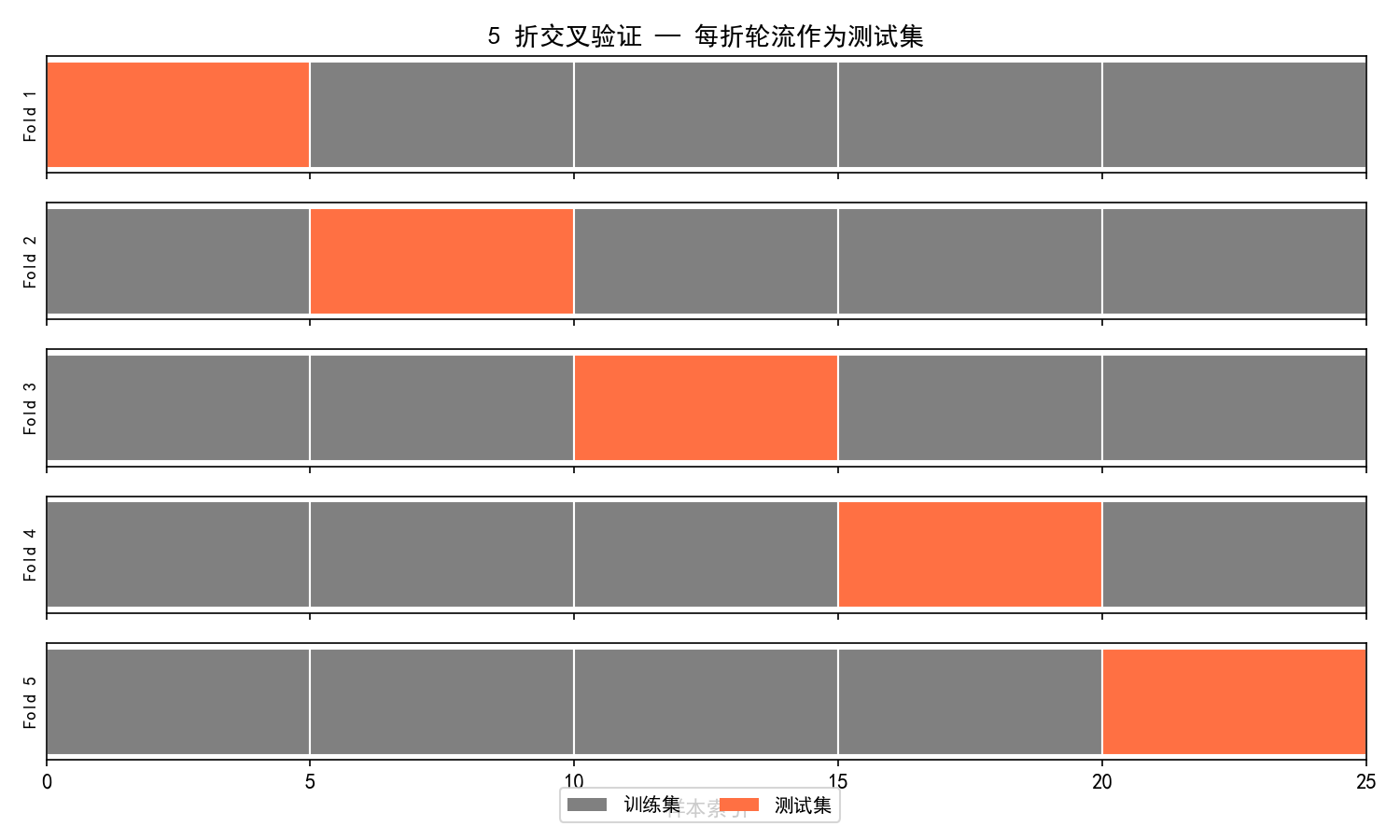
5 折交叉验证的过程:
将数据随机分为 5 等份
第 1 轮:Fold 1 做测试集,其余 4 折做训练集
第 2 轮:Fold 2 做测试集,其余 4 折做训练集
...依此类推,共 5 轮
最终评分 = 5 轮测试评分的平均值
from sklearn.model_selection import cross_val_score, KFold
# 5 折交叉验证
cv = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=cv, scoring='r2')
print(f'各折得分: {scores}')
print(f'平均得分: {scores.mean():.3f} (±{scores.std():.3f})')
为什么不用单次 train_test_split? 单次划分的结果高度依赖于随机种子。交叉验证用全部数据做测试,结果更稳定可靠。
3.2.2 常用交叉验证策略
from sklearn.model_selection import StratifiedKFold, TimeSeriesSplit
# 分层 K 折(分类任务推荐)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 时间序列交叉验证
tscv = TimeSeriesSplit(n_splits=5)
3.3 学习曲线
学习曲线展示了训练样本数量对模型性能的影响,帮助诊断偏差-方差问题。
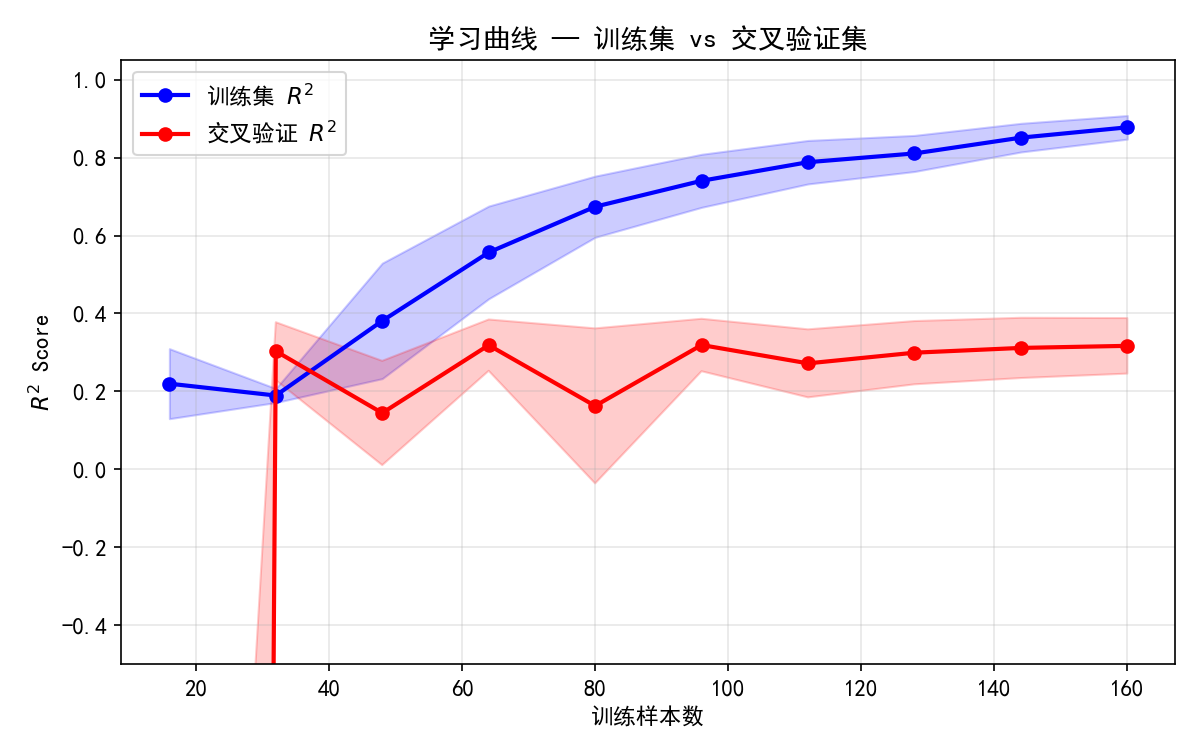
解读:
蓝色线(训练集 ):随样本数增加而上升,因为更多数据让模型拟合更好
红色线(交叉验证 ):始终低于训练集,反映泛化能力
两条线之间的间隙:间隙越大,过拟合越严重
如何诊断与改善
from sklearn.model_selection import learning_curve
train_sizes, train_scores, test_scores = learning_curve(
model, X, y,
train_sizes=np.linspace(0.1, 1.0, 10),
cv=5, scoring='r2'
)
3.4 验证曲线
验证曲线展示了单个超参数对模型性能的影响,用于选择最优超参数值。
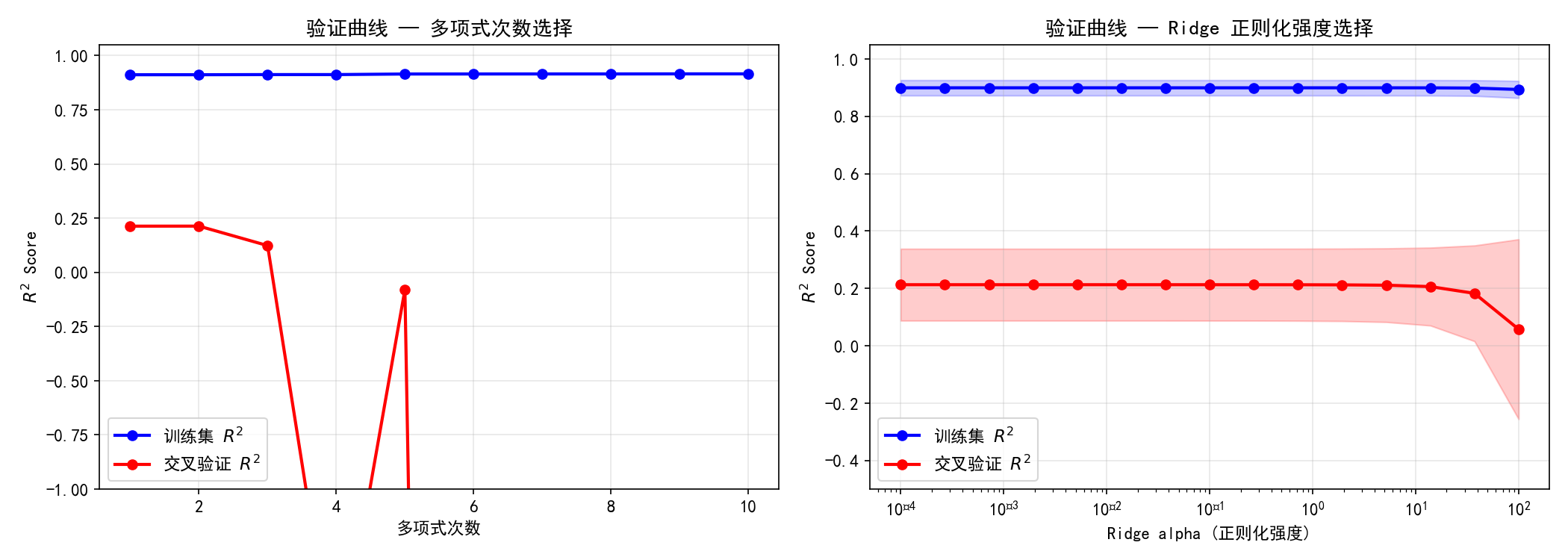
3.4.1 多项式次数选择(左图)
随着多项式次数增加:
训练 (蓝色):始终接近 1.0(线性数据用多项式拟合很容易完美)
交叉验证 (红色):在 degree=3 后急剧下降,说明高阶多项式严重过拟合
最佳选择:degree=1 或 2(CV 得分最高)
3.4.2 Ridge 正则化强度选择(右图)
随着 α 增大:
训练 :基本不变(线性模型对正则化不敏感)
交叉验证 :在 α≈30 后开始下降
最佳选择:α 在 10−4 到 101 之间均可,过小会过拟合,过大会欠拟合。
from sklearn.model_selection import validation_curve
train_scores, test_scores = validation_curve(
Ridge(), X, y,
param_name='alpha',
param_range=np.logspace(-4, 2, 15),
cv=5, scoring='r2'
)
3.5 模型对比的交叉验证
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_val_score, KFold
cv = KFold(n_splits=5, shuffle=True, random_state=42)
models = {
'Linear': LinearRegression(),
'Poly(3)': make_pipeline(PolynomialFeatures(3), LinearRegression()),
'Ridge(α=1)': Ridge(alpha=1.0),
'Ridge(α=10)': Ridge(alpha=10.0),
}
for name, mdl in models.items():
scores = cross_val_score(mdl, X, y, cv=cv, scoring='r2')
print(f'{name}: μ={scores.mean():.3f} (±{scores.std():.3f})')
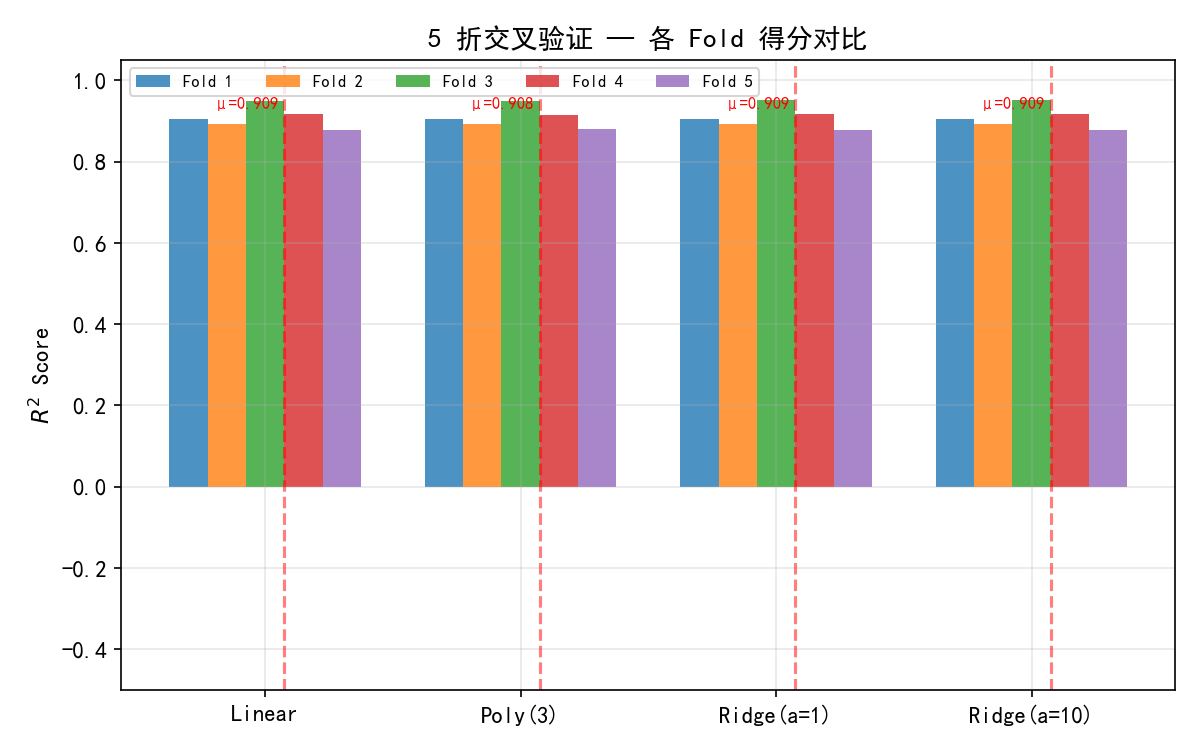
在这个线性数据集上:
Linear、Poly(3)、Ridge(α=1) 表现相近(≈0.909)
Ridge(α=10) 略低(≈0.909),强正则化导致轻微欠拟合
各 Fold 之间分数波动小,说明模型稳定
对于线性数据,简单线性回归已经足够,不需要多项式扩展或强正则化。交叉验证帮助我们避免了"以为复杂模型一定更好"的误区。
3.6 正则化与交叉验证的结合
在实际应用中,正则化参数(如 Ridge 的 α)通常通过交叉验证自动选择:
from sklearn.linear_model import RidgeCV
# RidgeCV 内置交叉验证,自动选择最优 alpha
ridge_cv = RidgeCV(alphas=[0.01, 0.1, 1.0, 10.0, 100.0], cv=5)
ridge_cv.fit(X, y)
print(f'最优 alpha: {ridge_cv.alpha_}')
类似地,LassoCV 和 ElasticNetCV 也提供了内置交叉验证的版本。
3.7 实用技巧速查
3.8 数模竞赛中的模型改善
在数学建模竞赛中,模型改善的核心流程:
基线模型:先用最简单模型(如线性回归)建立基准
交叉验证:用 5 折或 10 折 CV 评估,不要只看单次 train_test_split
学习曲线诊断:判断是欠拟合还是过拟合
验证曲线调参:系统性地搜索最优超参数
模型对比:在同一 CV 设置下比较多个模型
注意事项:
数模竞赛中数据量通常有限,交叉验证比单次划分更可靠
不要盲目追求训练集上的高 ,泛化能力才是关键
记录所有实验结果,在论文中展示模型选择过程
3.9 本节小结
偏差-方差权衡是模型选择的核心:欠拟合需要更复杂模型,过拟合需要简化或正则化
交叉验证通过多次划分数据,提供更可靠的泛化能力评估
学习曲线诊断模型是欠拟合还是过拟合,指导数据收集与模型选择
验证曲线帮助选择最优超参数(如多项式次数、正则化强度)
训练集评分高 ≠ 好模型,交叉验证评分才是衡量泛化能力的标准
RidgeCV/LassoCV等内置 CV 的类可以自动选择最优正则化参数数模竞赛中,应建立"基线→诊断→调参→对比"的系统化流程
第4章 K 近邻
4.1 KNN 的基本原理
K 近邻(K-Nearest Neighbors, KNN)是最直观的机器学习算法之一。其核心思想:近朱者赤,近墨者黑——一个样本的类别(或值)由其最近的 K 个邻居决定。
4.1.1 算法流程
分类任务:
计算测试点到所有训练点的距离
找出距离最近的 K 个训练样本
统计这 K 个邻居的类别,投票决定测试点类别
回归任务:
计算测试点到所有训练点的距离
找出距离最近的 K 个训练样本
取这 K 个邻居目标值的平均值作为预测
4.1.2 原理可视化
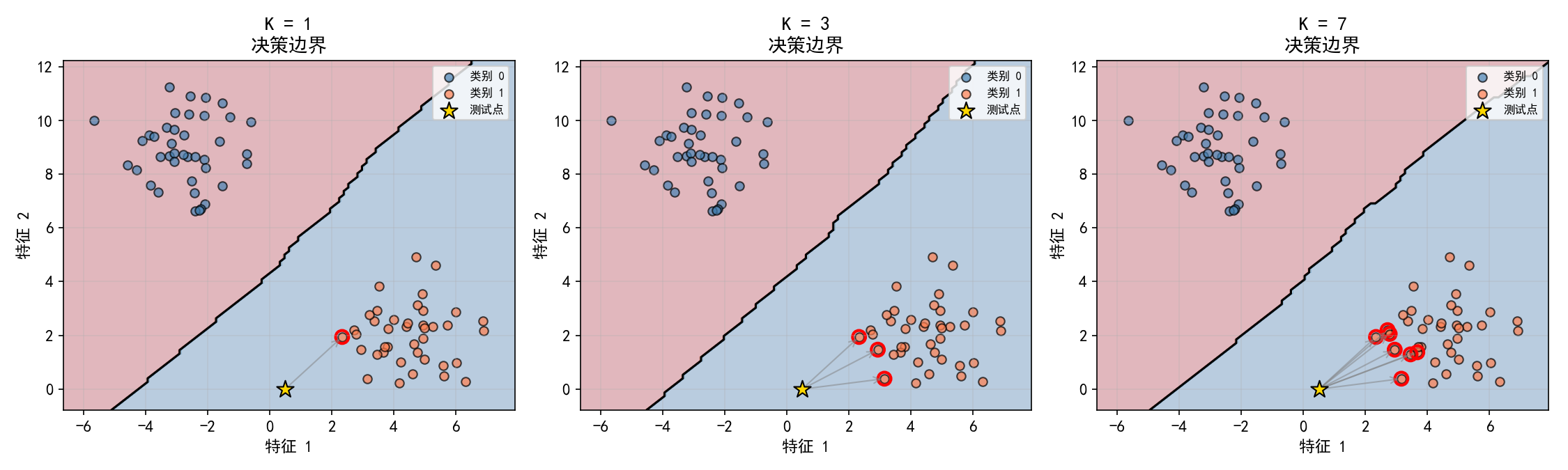
图中金色星星是待预测的测试点,灰色箭头指向其 K 个最近邻居(红色圆圈标记):
K=1:决策边界非常"破碎",只考虑最近的一个邻居,容易受噪声影响
K=3:考虑 3 个邻居的投票,决策边界更平滑
K=7:更多邻居参与投票,决策边界更加平滑,但可能丢失局部细节
from sklearn.neighbors import KNeighborsClassifier
# KNN 分类
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
# KNN 回归
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor(n_neighbors=5)
knn_reg.fit(X_train, y_train)
y_pred = knn_reg.predict(X_test)
4.2 K 值的选择
K 值是 KNN 唯一的(也是最重要的)超参数,直接影响模型的偏差-方差权衡:
4.2.1 K 值对性能的影响
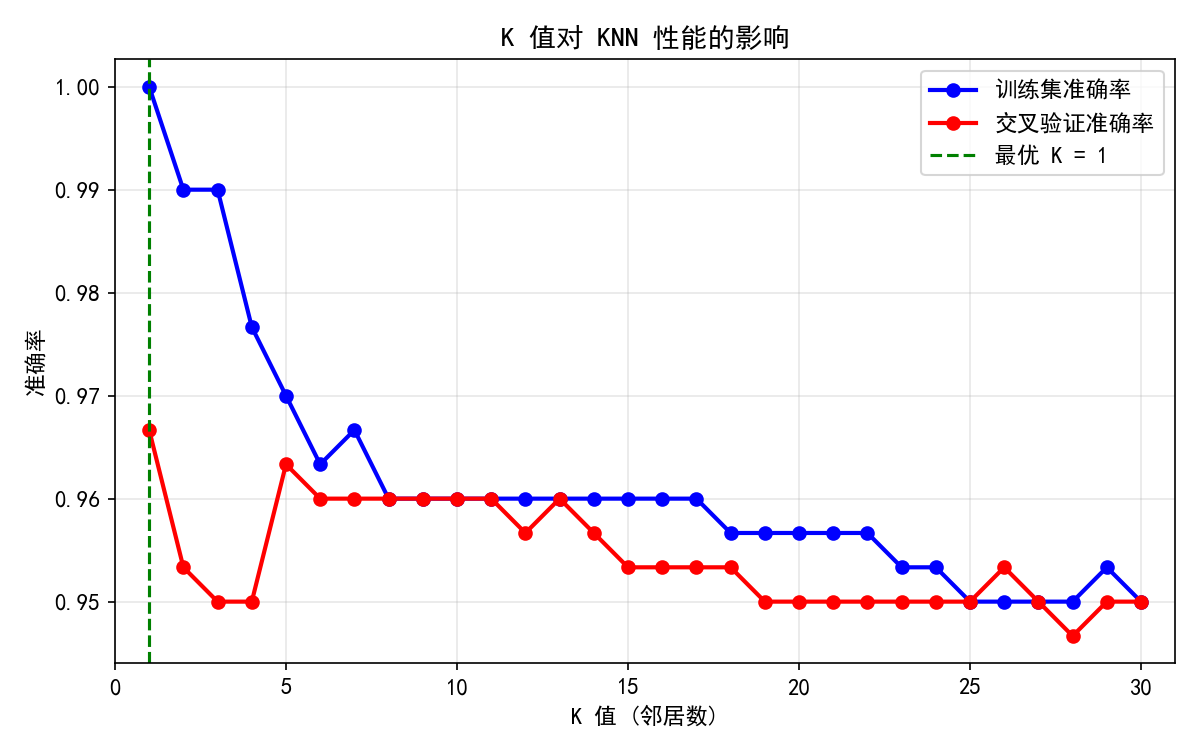
蓝色线(训练集准确率):K=1 时达到 100%(每个点都是自己的最近邻居),随 K 增大而下降
红色线(交叉验证准确率):反映真实泛化能力,K=1 时略低于最大值
在这个数据分离良好的例子中,K=1 的交叉验证表现也很好
经验法则:
K 通常取奇数(避免平票)
K≈n 是一个常用起点(n 为样本数)
必须通过交叉验证选择最优 K
4.3 距离度量
KNN 的核心是"距离"的计算方式。sklearn 支持多种距离度量:
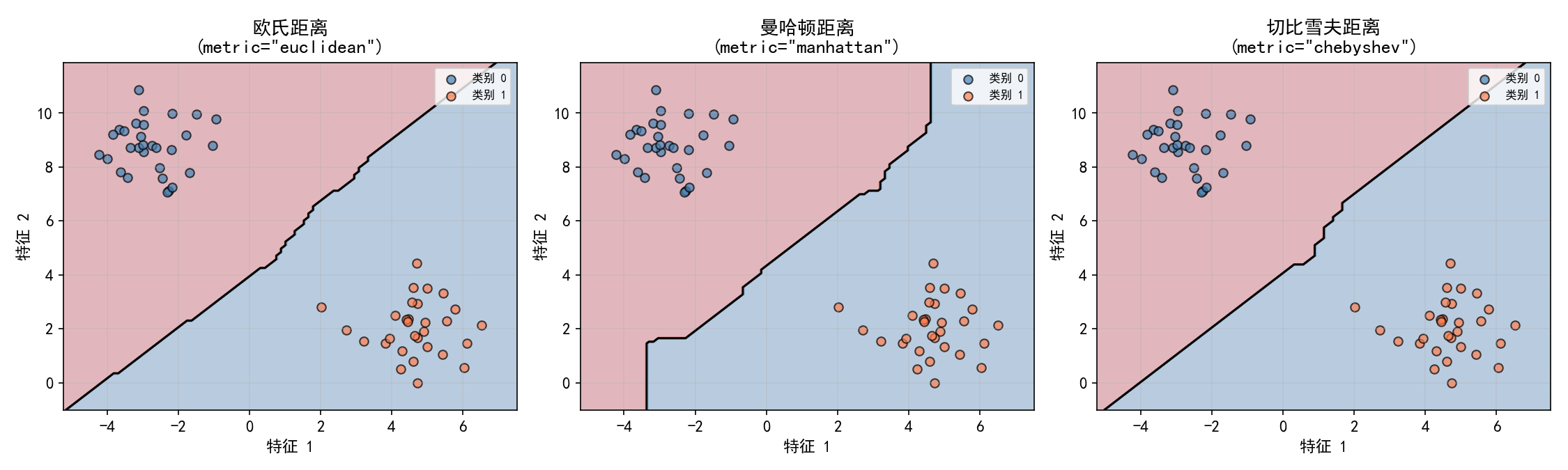
左图(欧氏距离):决策边界最平滑自然,是最常用的默认选择。
中图(曼哈顿距离):边界呈阶梯状,沿坐标轴方向更敏感。
右图(切比雪夫距离):只考虑最大差异维度,边界接近对角线。
# 使用不同距离度量
knn_euc = KNeighborsClassifier(n_neighbors=5, metric='euclidean')
knn_man = KNeighborsClassifier(n_neighbors=5, metric='manhattan')
knn_cheb = KNeighborsClassifier(n_neighbors=5, metric='chebyshev')
4.4 数据标准化的重要性
KNN 基于距离计算,因此对特征的量纲极度敏感。
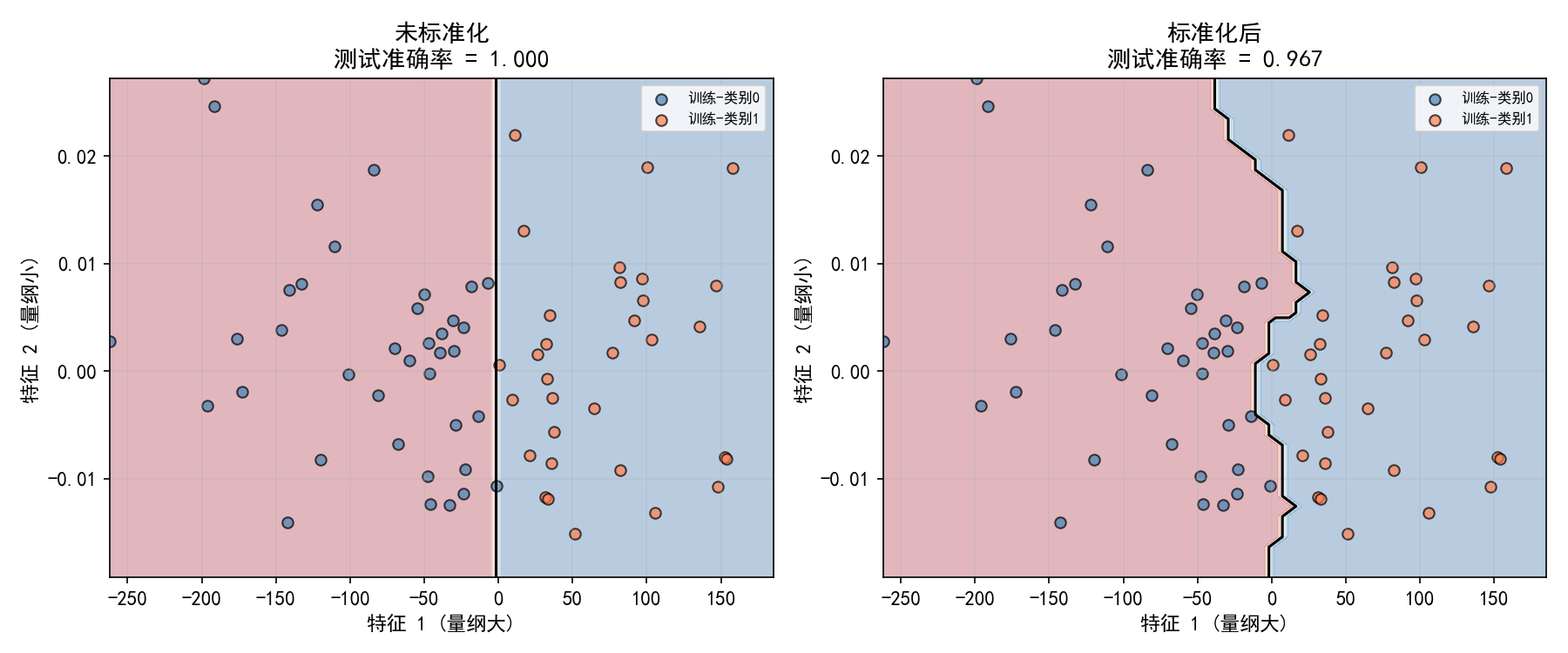
左图(未标准化):特征 1 的量纲约为特征 2 的 10000 倍,距离几乎完全由特征 1 决定,特征 2 的信息被忽略。决策边界是垂直直线。
右图(标准化后):两个特征对距离的贡献相当,决策边界能利用两个特征的信息。
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
# 推荐做法:标准化 + KNN
knn = make_pipeline(StandardScaler(), KNeighborsClassifier(n_neighbors=5))
knn.fit(X_train, y_train)
关键原则:使用 KNN 前,几乎总是需要标准化(
StandardScaler)或归一化(MinMaxScaler)。否则量纲大的特征会主导距离计算。
4.5 KNN 回归
KNN 同样可以用于回归任务——取 K 个最近邻居的目标值平均值:
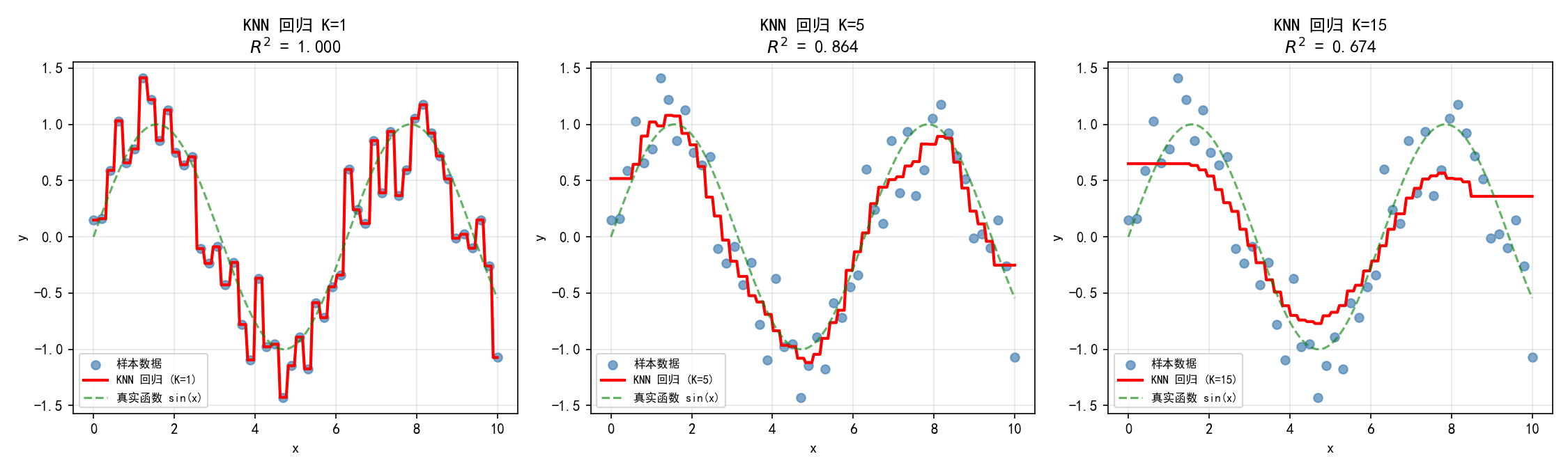
K=1:完美拟合训练数据(),但预测曲线呈阶梯状,严重过拟合
K=5:平滑地捕捉了 sin(x) 的趋势(),偏差-方差平衡良好
K=15:过度平滑,丢失了曲线细节(),欠拟合
4.6 KNN 的优缺点
优点
缺点
# 使用 KDTree 加速(自动选择)
knn = KNeighborsClassifier(n_neighbors=5, algorithm='auto') # 自动选择最优算法
# algorithm 可选: 'auto', 'ball_tree', 'kd_tree', 'brute'
4.7 实用技巧速查
4.8 数模竞赛中的应用
KNN 在数学建模竞赛中常用于:
模式识别:图像分类、手写数字识别(MNIST 经典例子)
推荐系统:基于用户/物品的 KNN 协同过滤
缺失值填充:用 K 个最近邻的均值/众数填补缺失值
异常检测:距离所有邻居都很远的点可能是异常值
注意事项:
数据量大时预测速度慢,竞赛中数据量通常可接受
必须标准化,否则结果不可信
高维数据(特征 > 50)效果可能很差,考虑先降维
K 值用交叉验证选择,不要凭感觉设
4.9 本节小结
KNN 基于"近朱者赤"的直觉:分类用投票,回归用平均
K 值是最关键的超参数:K 小→过拟合,K 大→欠拟合
距离度量决定"远近"的定义:欧氏最常用,曼哈顿对异常值鲁棒
标准化是必须的:KNN 对量纲极度敏感,量纲差异会扭曲距离计算
KNN 是懒惰学习(lazy learning):无训练过程,预测时计算所有距离
维度灾难是 KNN 的致命弱点:高维空间中所有点距离相近
数模竞赛中,KNN 适合中小规模数据、低维特征的分类和回归任务
第5章 朴素贝叶斯
5.1 贝叶斯定理
朴素贝叶斯(Naive Bayes)基于贝叶斯定理,是概率论在分类中的经典应用:
其中:
P(Ck):先验概率——类别 Ck 在总体中的比例
P(x∣Ck):似然——在类别 Ck 下观察到特征 x 的概率
P(Ck∣x):后验概率——观察到 x 后,属于类别 Ck 的概率
分类决策:选择后验概率最大的类别
5.1.1 从先验到后验
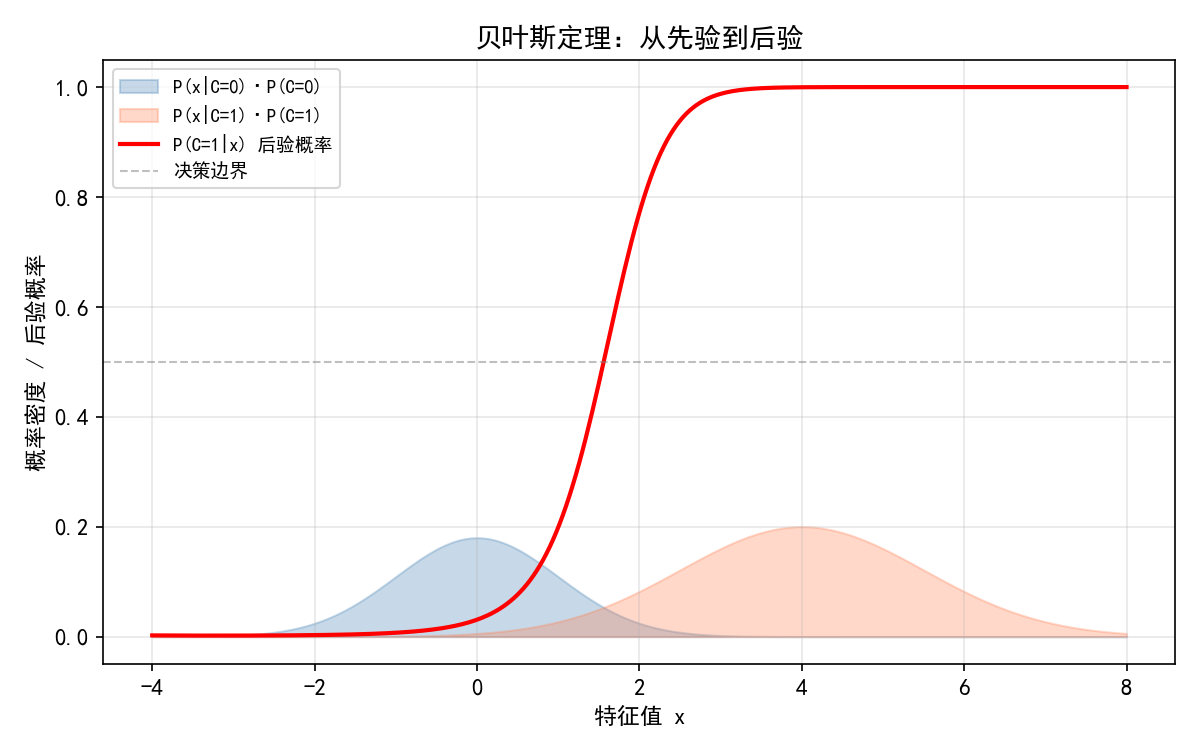
蓝色阴影:P(x∣C=0)⋅P(C=0)——类别 0 的加权似然
橙色阴影:P(x∣C=1)⋅P(C=1)——类别 1 的加权似然
红色曲线:后验概率 P(C=1∣x)——综合先验和似然后的分类置信度
灰色虚线:决策边界(后验概率 = 0.5)
关键观察:当 x 较小时,橙色阴影几乎为零,后验概率接近 0(确定为类别 0);当 x 较大时,蓝色阴影几乎为零,后验概率接近 1(确定为类别 1)。
5.2 "朴素"的假设
朴素贝叶斯的"朴素"(Naive)体现在一个强假设:各特征在给定类别下相互独立:
这个假设在现实中几乎总不成立,但朴素贝叶斯在实践中仍然有效,原因在于:
我们只需要比较各类别的后验概率大小,而非精确值
即使特征相关,独立假设仍能捕获主要的判别信息
计算简单,参数少,小数据上不易过拟合
sklearn 提供了三种朴素贝叶斯变体,对应不同的数据分布假设:
5.3 GaussianNB — 连续特征
GaussianNB 假设每个特征在每个类别下服从正态分布:
每个类别 k、每个特征 j 只需估计两个参数:均值 μkj 和方差 。
5.3.1 可视化
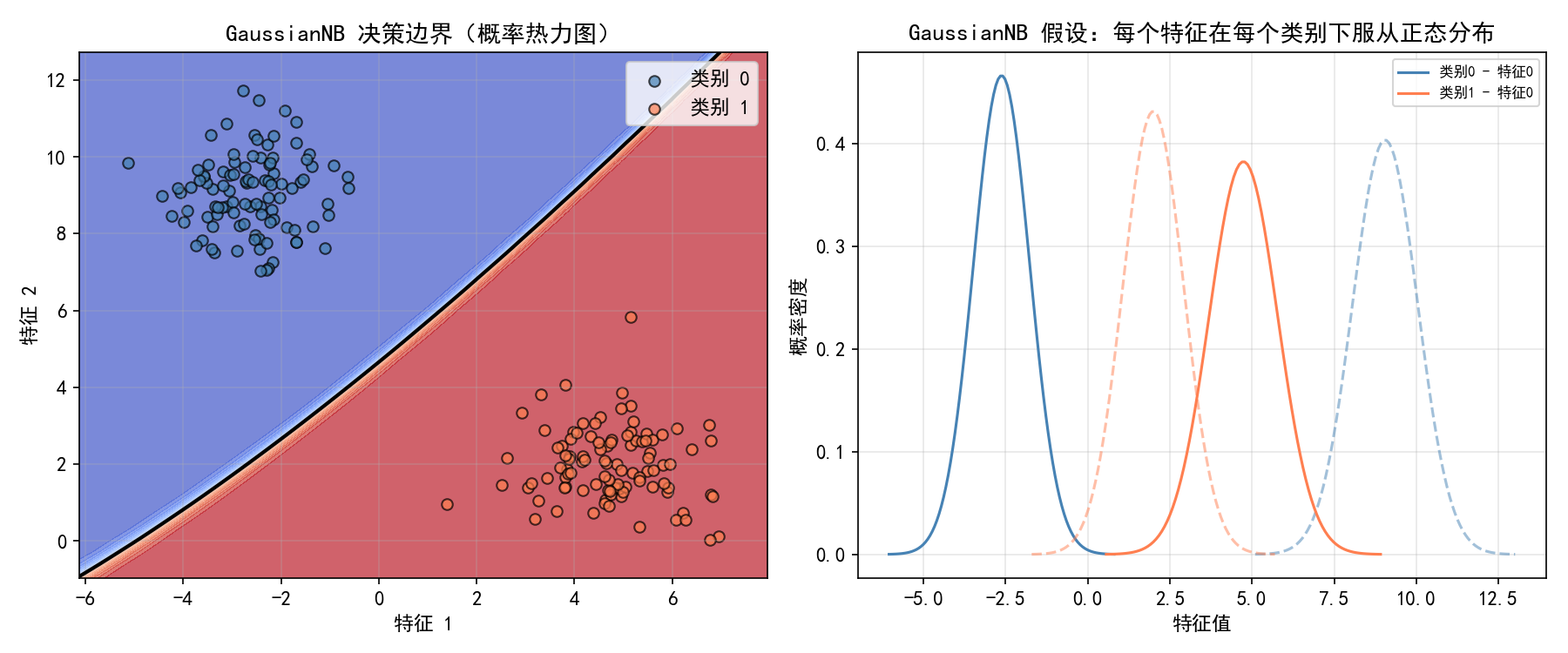
左图:决策边界——GaussianNB 产生二次决策边界(因为假设正态分布,边界是二次曲面)。概率热力图展示了后验概率的平滑过渡。
右图:GaussianNB 对每个类别的每个特征拟合的正态分布曲线。实线是特征 1,虚线是特征 2。两个类别的分布中心不同,方差也不同。
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB().fit(X_train, y_train)
y_pred = gnb.predict(X_test)
y_proba = gnb.predict_proba(X_test)
# 查看学到的参数
print('各类别先验概率:', gnb.class_prior_)
print('各类别特征均值:\n', gnb.theta_)
print('各类别特征方差:\n', gnb.var_)
5.4 MultinomialNB — 计数数据
MultinomialNB 假设特征服从多项分布,适用于离散计数数据,最经典的场景是文本分类。
5.4.1 文本分类示例
from sklearn.naive_bayes import MultinomialNB
# 模拟文档-词频矩阵
# 每行是一篇文档,每列是一个词的词频
X_train_counts = ... # shape: (n_docs, n_words)
y_train = ... # 类别标签
mnb = MultinomialNB().fit(X_train_counts, y_train)
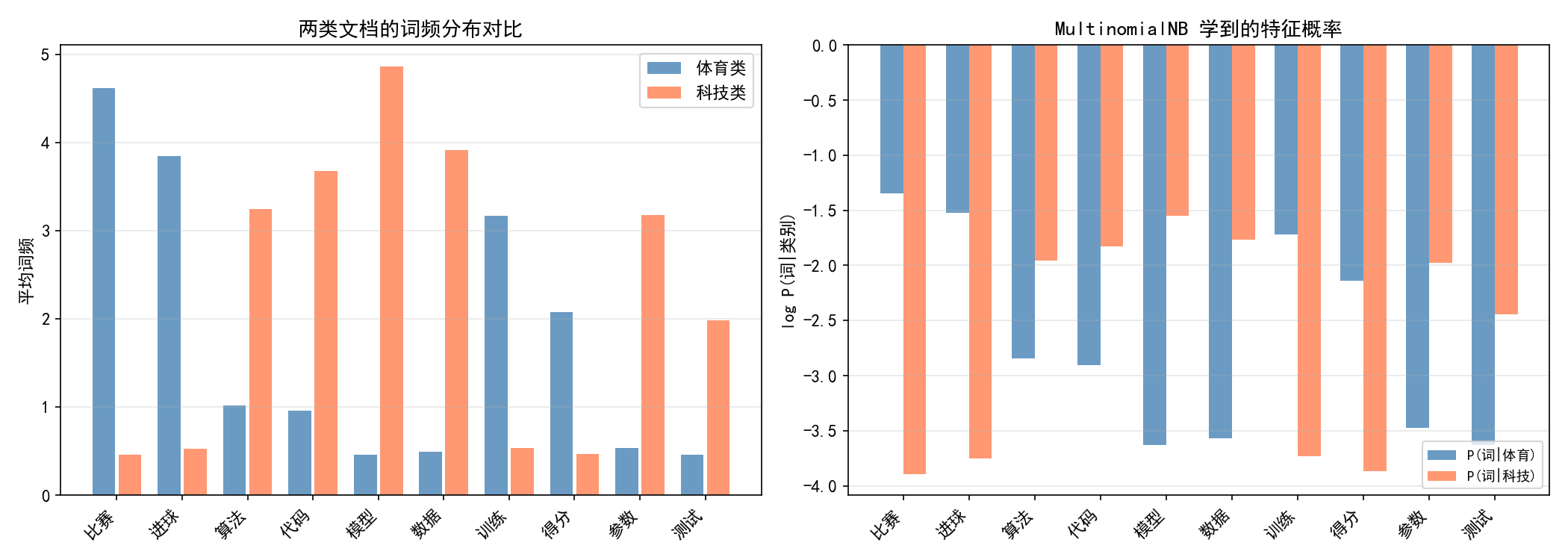
左图:两类文档的词频分布。体育类文档中"比赛"、"进球"、"训练"等词频高;科技类文档中"算法"、"代码"、"模型"等词频高。
右图:MultinomialNB 学到的对数概率 logP(词∣类别)。注意:
"比赛"在体育类的概率远高于科技类
"模型"在科技类的概率远高于体育类
这些对数概率直接用于分类决策
5.4.2 平滑(Smoothing)
MultinomialNB 使用 Laplace 平滑(默认 α=1.0)处理未见过的词:
其中 V 是词汇表大小。α=1 为 Laplace 平滑,α=0.5 为 Lidstone 平滑。
mnb = MultinomialNB(alpha=1.0) # 默认 Laplace 平滑
5.5 BernoulliNB — 二值特征
BernoulliNB 假设每个特征服从伯努利分布(0/1),适用于二值特征。与 MultinomialNB 不同,BernoulliNB 也考虑特征缺失(即 xj=0 的情况)。
5.5.1 垃圾邮件检测示例
from sklearn.naive_bayes import BernoulliNB
# 二值特征:邮件是否包含某些关键词
X_train = np.array([
[1, 0, 0, 0, 1, 0], # 有链接、无大写、无数字...
[0, 1, 1, 1, 0, 1], # ...
])
y_train = np.array([1, 0]) # 1=垃圾邮件, 0=正常
bnb = BernoulliNB().fit(X_train, y_train)
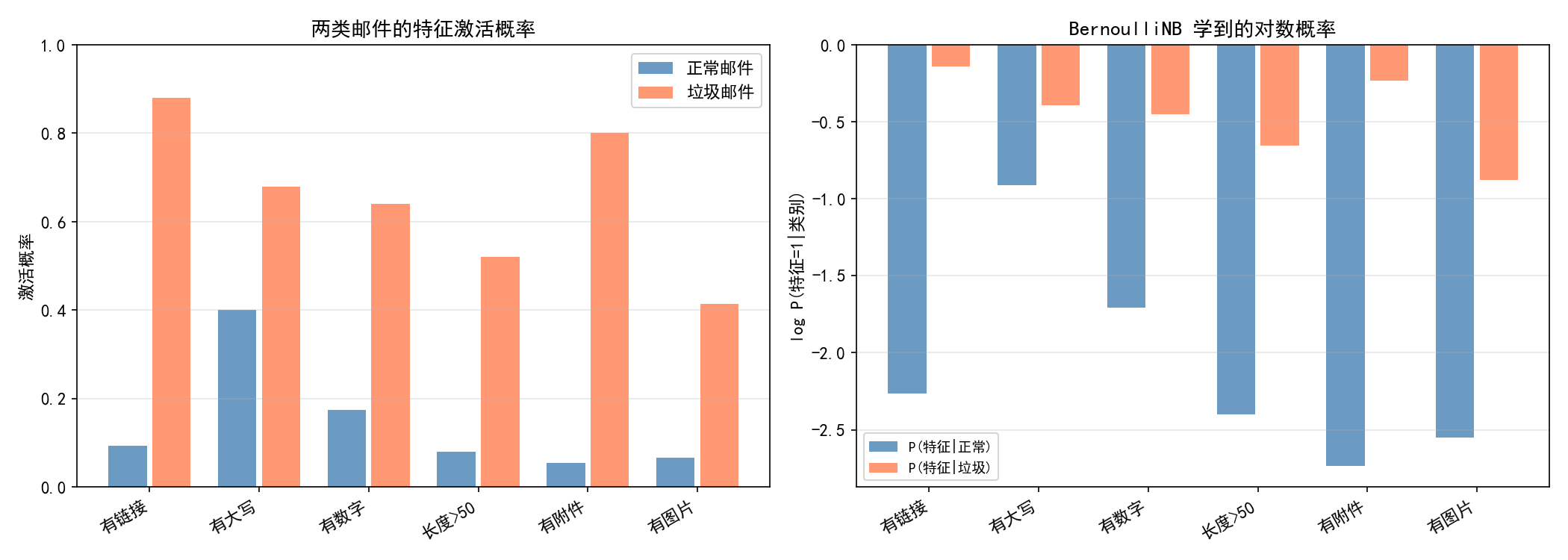
左图:两类邮件的特征激活概率。垃圾邮件更可能有链接(88%)、大写(68%)、附件(80%)等特征。
右图:BernoulliNB 学到的对数概率。例如"有附件"在垃圾邮件中的 logP 远高于正常邮件,是强判别特征。
5.5.2 BernoulliNB vs MultinomialNB
5.6 三种变体对比
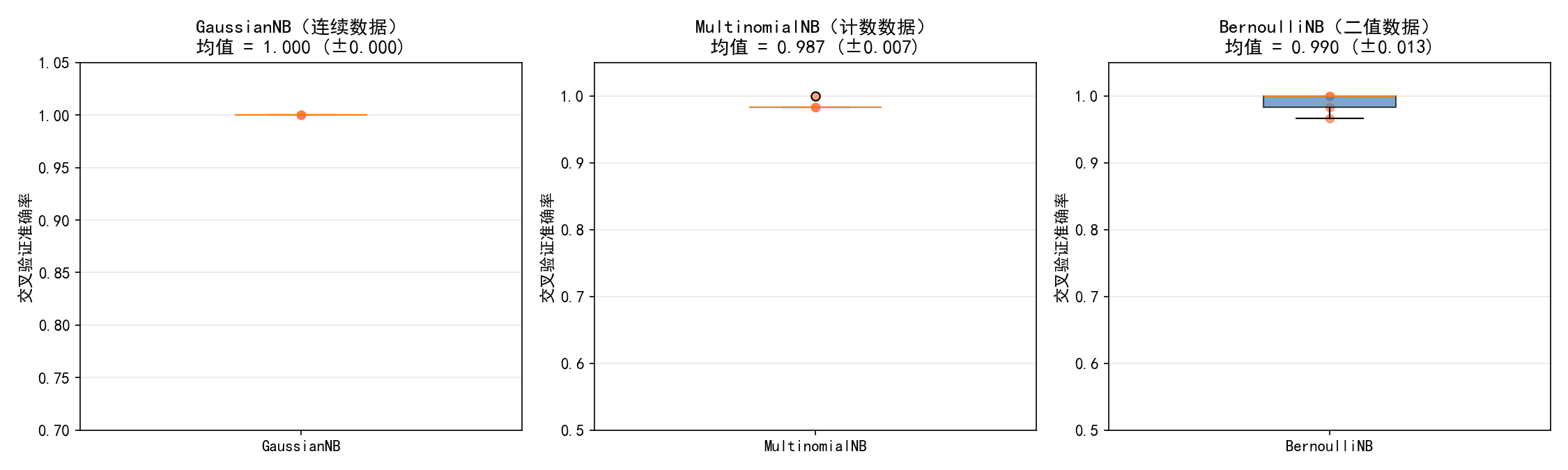
在各自适合的数据类型上,三种变体都表现优秀:
GaussianNB(连续数据):均值 = 1.000
MultinomialNB(计数数据):均值 = 0.987
BernoulliNB(二值数据):均值 = 0.990
关键教训:选择正确的 NB 变体比调参更重要。数据特征的类型决定了该用哪个变体。
5.7 实用技巧速查
5.8 数模竞赛中的应用
朴素贝叶斯在数学建模竞赛中常用于:
文本分类:新闻分类、情感分析、垃圾邮件检测(MultinomialNB 经典应用)
快速基线:训练极快,可作为分类任务的快速基线模型
增量学习:
partial_fit()支持流式数据(数据量太大无法一次加载时)多分类:天然支持多类别,无需 OvR/OvO 策略
注意事项:
特征独立假设通常不成立,但在实践中仍有效
GaussianNB 对异常值敏感(正态分布假设)
MultinomialNB 要求非负输入,使用前确保数据 ≥0
BernoulliNB 适用于二值化后的特征
朴素贝叶斯不能调参(除了平滑参数 α),性能上限有限
5.9 本节小结
朴素贝叶斯基于贝叶斯定理,用先验概率 × 似然计算后验概率
"朴素"指特征独立性假设——虽不现实但实践中有效
GaussianNB 假设正态分布,适合连续特征
MultinomialNB 假设多项分布,适合计数数据(如词频、文本分类)
BernoulliNB 假设伯努利分布,适合二值特征
选择正确的变体比调参更重要
训练速度极快,适合大数据和流式学习(
partial_fit)数模竞赛中,朴素贝叶斯是文本分类的首选和快速基线模型
第6章 支持向量机
6.1 SVM 的基本原理
支持向量机(Support Vector Machine, SVM)是机器学习中最优雅的算法之一。其核心思想:找到一个超平面,使得两类数据之间的间隔最大化。
6.1.1 最大间隔超平面
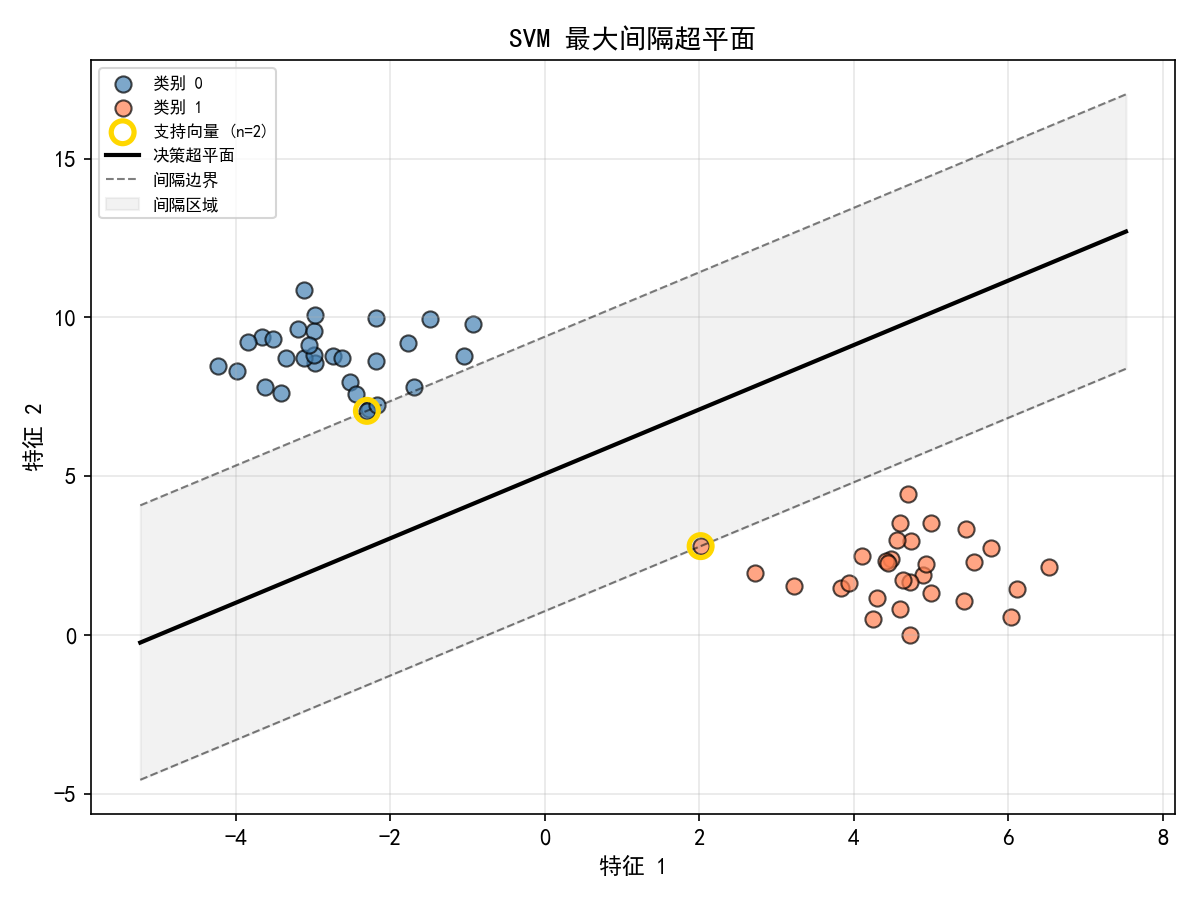
SVM 的决策超平面为 ,间隔边界为 。
黑色实线:决策超平面——分隔两类的最佳直线
黑色虚线:间隔边界——距离决策面最近的点所在的线
灰色区域:间隔(margin)——SVM 要最大化的区域
金色圆圈:支持向量(Support Vectors)——落在间隔边界上的样本点
关键洞察:决策边界只由支持向量决定,其他样本不影响结果。这就是 SVM 名称的由来。
数学上,SVM 求解以下优化问题:
6.1.2 软间隔
当数据不可完全线性可分时,SVM 引入松弛变量 ξi 允许部分样本违反间隔约束:
参数 C 控制间隔宽度与分类错误之间的权衡。
from sklearn.svm import SVC
# 线性 SVM 分类
svc = SVC(kernel='linear', C=1.0).fit(X_train, y_train)
# 查看支持向量
print('支持向量数:', len(svc.support_vectors_))
print('支持向量索引:', svc.support_)
6.2 核函数:从线性到非线性
当数据无法用直线分开时,SVM 通过核技巧(Kernel Trick)将数据映射到高维空间,在高维空间中寻找线性分隔超平面。
6.2.1 四种核函数对比
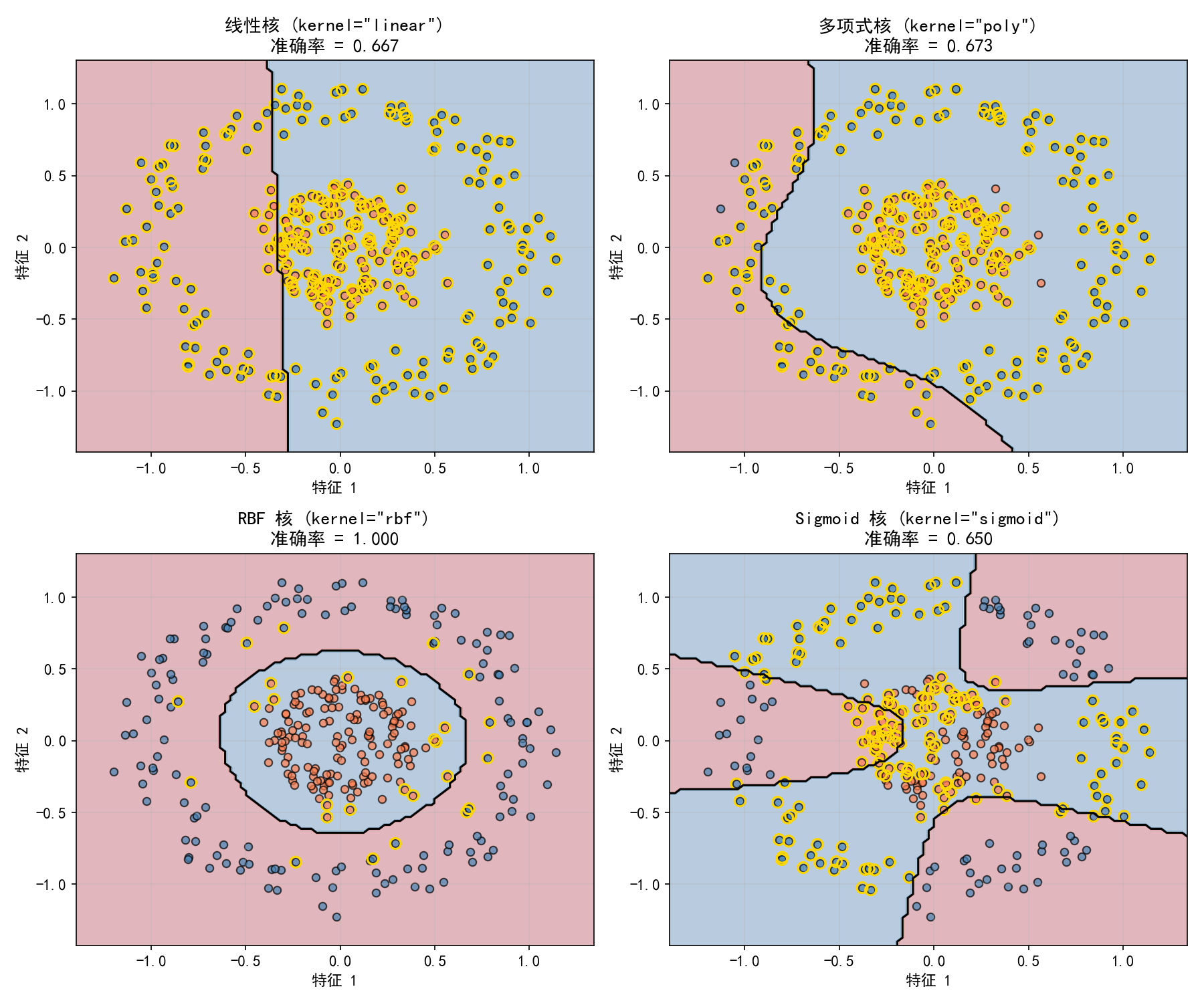
对同心圆数据集(线性不可分),四种核函数的表现:
线性核(左上):无法分开同心圆,准确率仅 66.7%
多项式核(右上):能拟合部分曲线边界,73.3%
RBF 核(左下):完美捕捉环形结构,100%
Sigmoid 核(右下):产生不规则边界,65.0%
# RBF 核(默认推荐)
svc = SVC(kernel='rbf', gamma='scale', C=1.0).fit(X, y)
# 多项式核
svc = SVC(kernel='poly', degree=3, gamma='scale', C=1.0).fit(X, y)
sklearn 默认
gamma='scale':。也可选'auto'()或直接指定数值。
6.3 正则化参数 C 的影响
C 是 SVM 最重要的超参数之一,控制间隔最大化与分类错误容忍度之间的权衡。
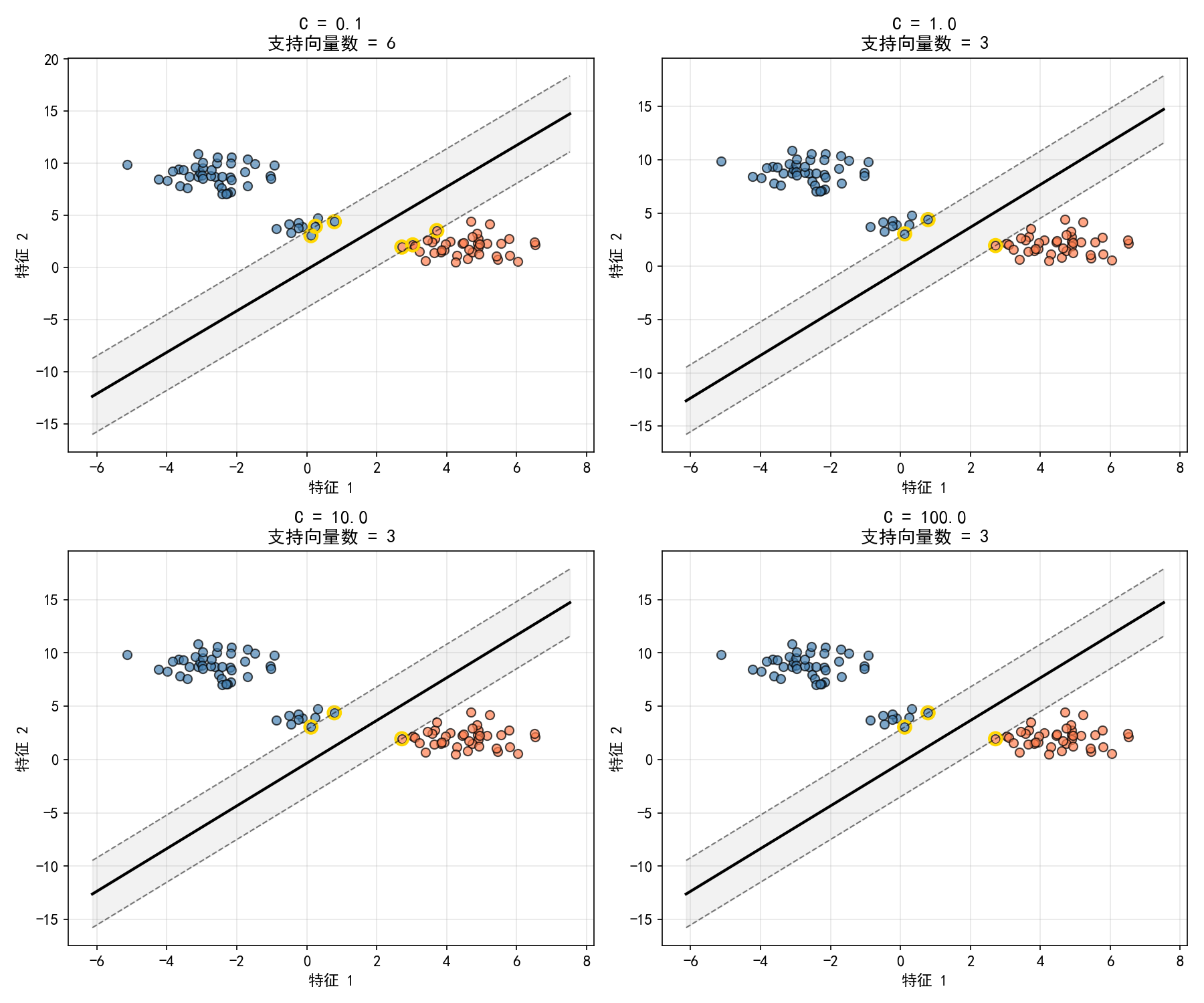
C 小:间隔宽,对噪声鲁棒,但可能欠拟合
C 大:间隔窄,训练准确率高,但可能过拟合
# C 的选择通常通过交叉验证
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10, 100]}
grid = GridSearchCV(SVC(kernel='rbf'), param_grid, cv=5)
grid.fit(X, y)
print('最优 C:', grid.best_params_)
6.4 RBF 核的 gamma 参数
RBF 核中 γ 控制单个样本的影响范围:
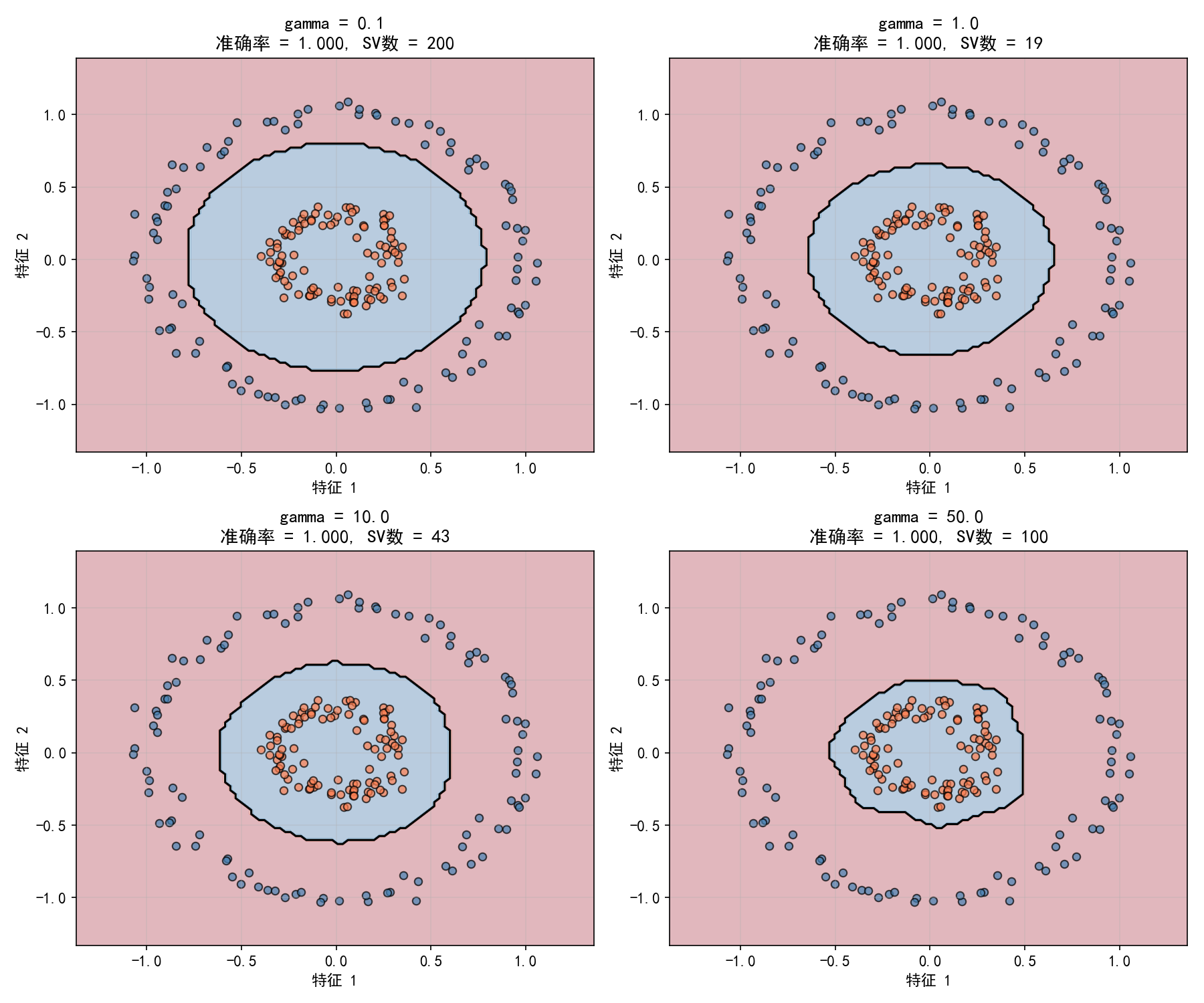
gamma 小:影响范围大,决策边界平滑,可能欠拟合
gamma 大:影响范围小,每个样本只影响局部区域,决策边界复杂,容易过拟合
经验法则:γ 和 C 通常需要联合调优。常用的搜索范围:C∈[0.1,1,10,100],γ∈[0.01,0.1,1,10]。
6.5 SVR — 支持向量回归
SVM 不仅用于分类,也用于回归(Support Vector Regression, SVR)。SVR 的目标是找到一个函数,使得大多数样本落在ε-管内:
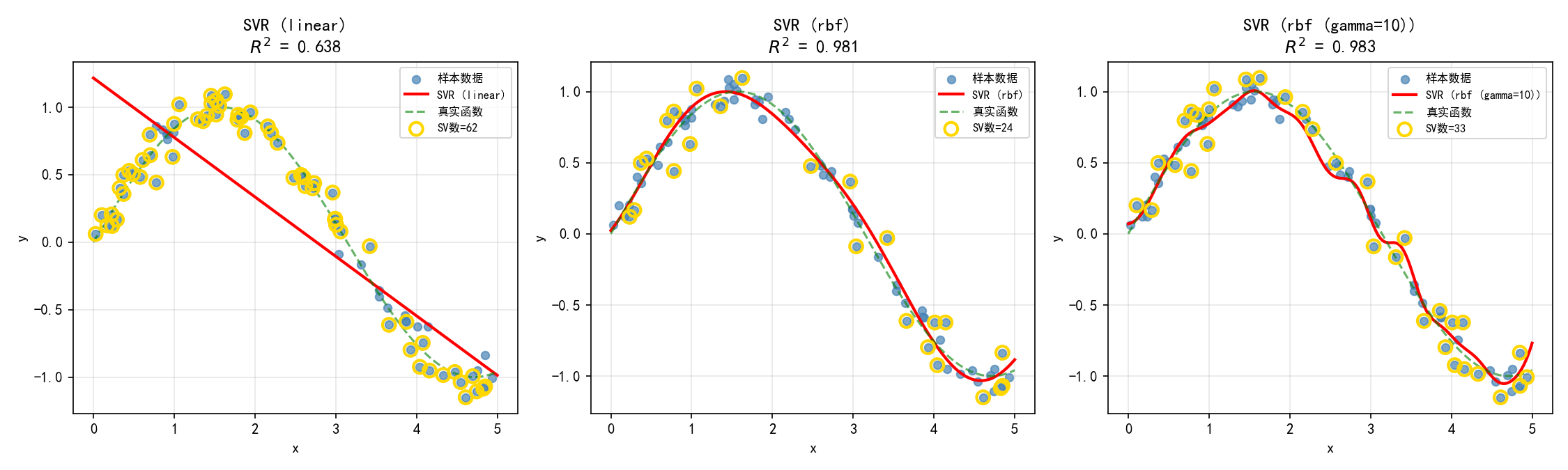
红色实线:SVR 拟合曲线
绿色虚线:真实函数 sin(x)
金色圆圈:支持向量——落在 ε-管外的样本
from sklearn.svm import SVR
svr = SVR(kernel='rbf', C=1.0, epsilon=0.1).fit(X_train, y_train)
y_pred = svr.predict(X_test)
SVR 的关键参数:
epsilon (ε):ε-管宽度,管内的预测误差不计损失
C:正则化强度,与分类 SVM 含义相同
6.6 LinearSVC vs SVC(kernel='linear')
sklearn 提供了两种线性 SVM 实现:
# 大数据推荐 LinearSVC
from sklearn.svm import LinearSVC
lsvc = LinearSVC(C=1.0, max_iter=10000).fit(X_train, y_train)
6.7 实用技巧速查
6.8 数模竞赛中的应用
SVM 在数学建模竞赛中常用于:
中小规模分类:数据量 < 10000 时,SVM 通常表现优秀
高维小样本:如基因表达数据、文本分类(核技巧在高维空间有效)
非线性模式识别:RBF 核可以拟合任意复杂边界
异常检测:
OneClassSVM用于无监督异常检测
注意事项:
必须标准化:SVM 对特征量纲敏感,特别是 RBF 核
大数据集训练慢( ~),> 50000 样本考虑
LinearSVCRBF 核的 C 和 γ 需联合调优
概率输出需要
probability=True,会额外开销
6.9 本节小结
SVM 通过最大化间隔找到最优分类超平面
支持向量是决定决策边界的少数关键样本
核技巧将线性不可分数据映射到高维空间:RBF 核是最通用的选择
C 参数控制间隔与错分的权衡:C 小→宽间隔(欠拟合),C 大→窄间隔(过拟合)
gamma 参数(RBF 核)控制单个样本的影响范围:gamma 小→平滑,gamma 大→复杂
LinearSVC是线性 SVM 的高效实现,适合大数据SVR 将 SVM 思想扩展到回归任务
数模竞赛中,SVM 是中小规模数据的强力分类器,需配合标准化使用
第7章 决策树
7.1 决策树的基本原理
决策树(Decision Tree)是一种树形结构的预测模型。其核心思想:通过一系列"如果-那么"规则将数据逐步划分,最终到达叶节点做出预测。
7.1.1 树的结构
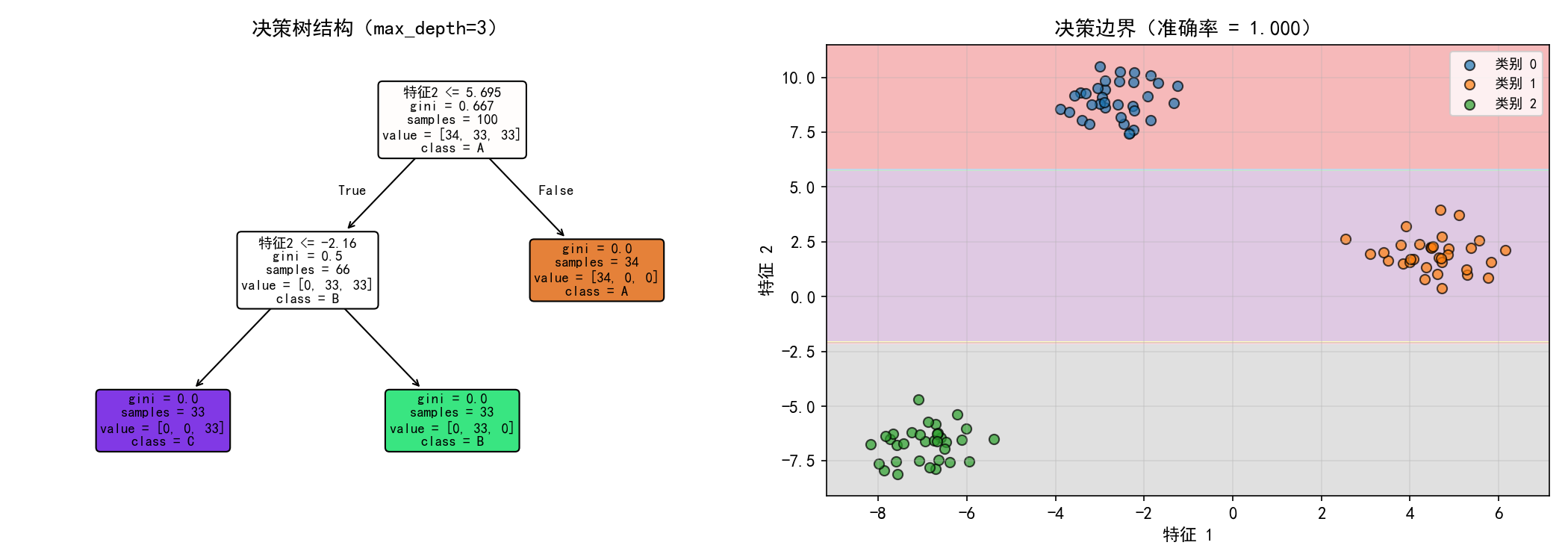
左图:一棵 max_depth=3 的决策树。每个节点包含:
分裂条件:如
特征2 <= 5.695gini:当前节点的不纯度
samples:该节点的样本数
value:各类别样本数
class:预测类别
右图:决策边界——决策树产生轴对齐的矩形边界(每次只在一个特征上切分)。
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(max_depth=3, random_state=42).fit(X_train, y_train)
y_pred = dt.predict(X_test)
7.2 分裂准则:基尼系数 vs 信息熵
决策树在每个节点选择最优分裂方式,目标是最大化子节点的不纯度降低。
7.2.1 两种不纯度指标
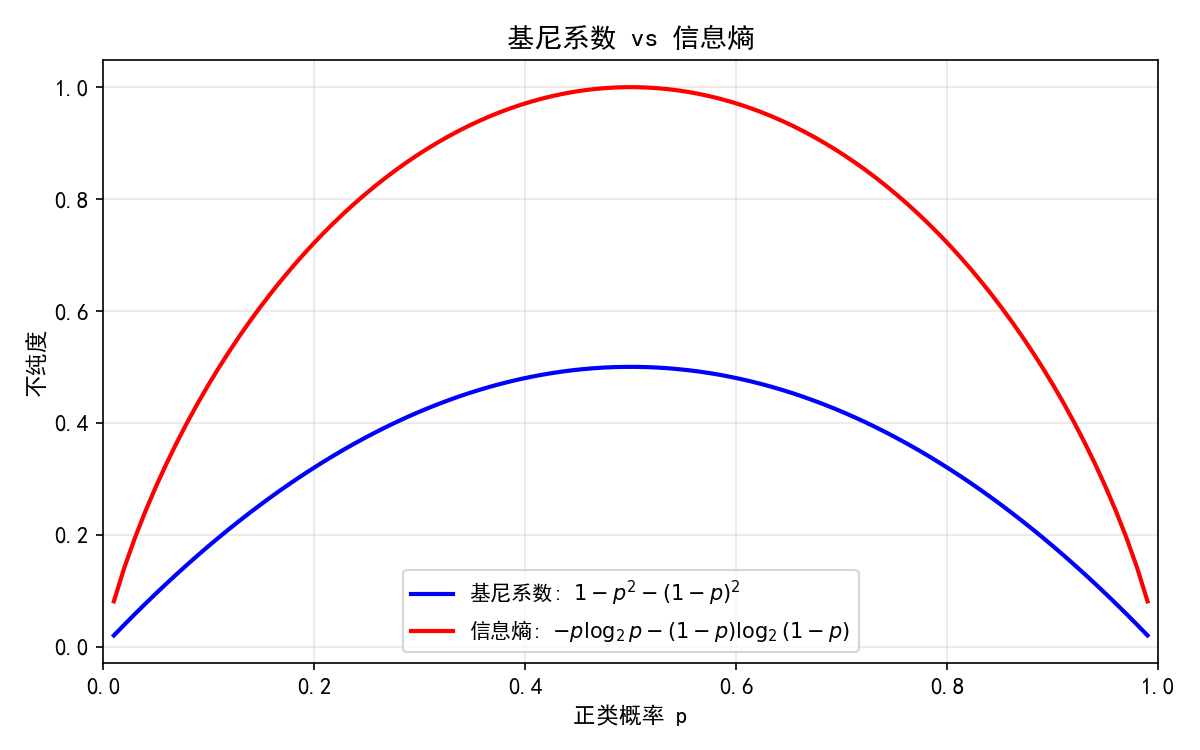
p=0 或 p=1(纯节点):两个指标都为 0
p=0.5(最不确定):两个指标都达到最大值
信息熵的峰值更高,对不纯度的惩罚更"敏感"
# 基尼系数(默认)
dt_gini = DecisionTreeClassifier(criterion='gini').fit(X, y)
# 信息熵
dt_entropy = DecisionTreeClassifier(criterion='entropy').fit(X, y)
实践中,两种准则的结果差异很小,基尼系数因计算更快而成为默认选择。
7.2.2 分裂过程
对于每个特征和每个可能的分裂点,计算信息增益(或基尼增益):
选择增益最大的特征和分裂点作为当前节点的分裂规则。
7.3 剪枝:防止过拟合
决策树最大的问题是容易过拟合——如果不加限制,树会一直生长到每个叶节点只包含一个样本(训练准确率 100%)。
7.3.1 预剪枝(Pre-pruning)
通过限制树的生长来防止过拟合:
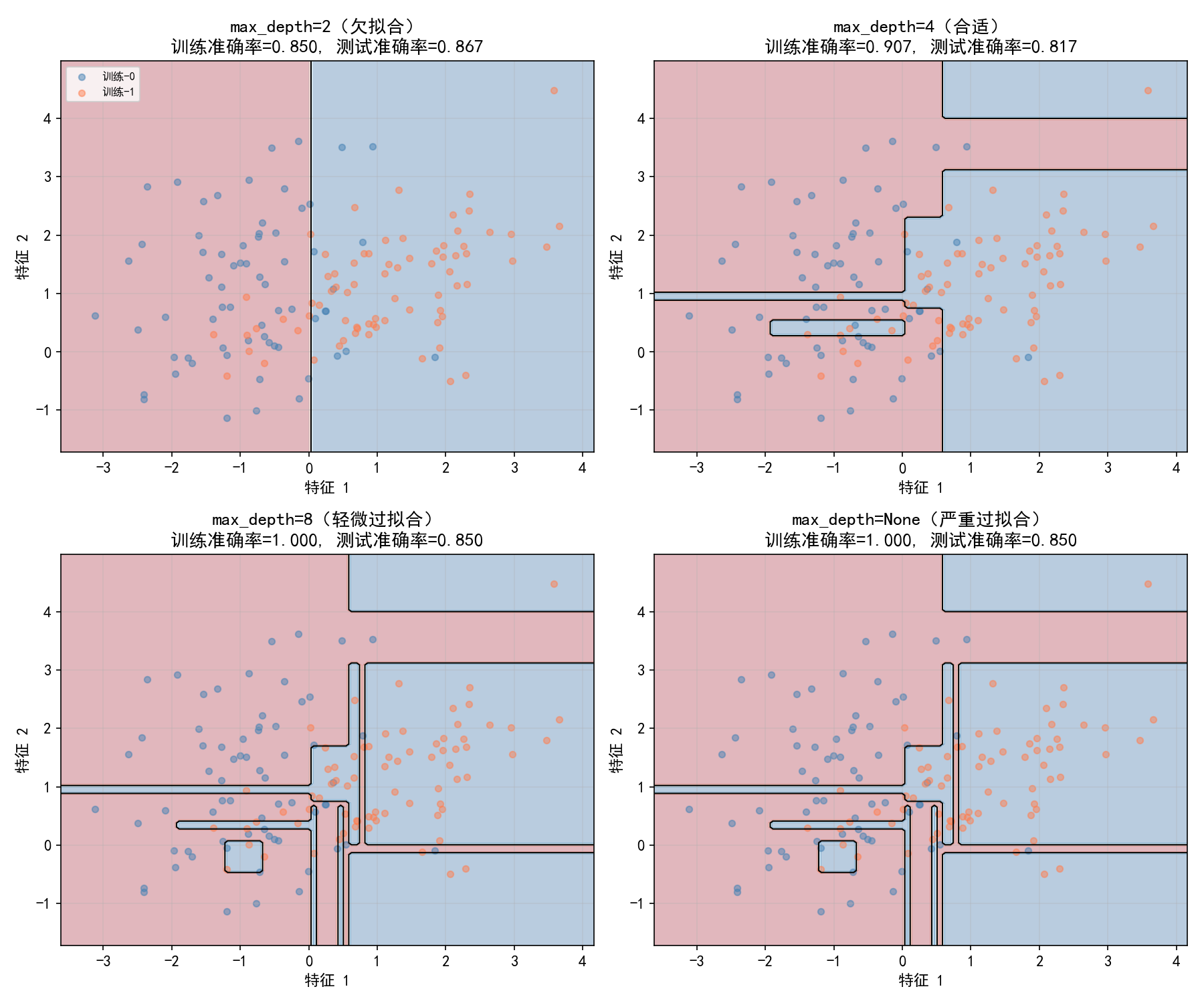
关键观察:训练准确率随深度单调增加,但测试准确率先升后降。需要通过交叉验证选择最优深度。
from sklearn.model_selection import cross_val_score
# 用交叉验证选择最优深度
depths = range(1, 20)
cv_scores = []
for d in depths:
dt = DecisionTreeClassifier(max_depth=d, random_state=42)
score = cross_val_score(dt, X, y, cv=5, scoring='accuracy').mean()
cv_scores.append(score)
best_depth = depths[np.argmax(cv_scores)]
7.3.2 后剪枝(Post-pruning)
先让树充分生长,再自底向上剪枝。sklearn 通过 ccp_alpha 参数实现 代价复杂度剪枝(Cost-Complexity Pruning):
# 获取剪枝路径
path = dt.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas = path.ccp_alphas[:-1] # 排除最后一个(空树)
# 对每个 alpha 评估
for alpha in ccp_alphas:
dt = DecisionTreeClassifier(ccp_alpha=alpha).fit(X_train, y_train)
7.4 决策树回归
决策树同样可用于回归任务:叶节点的预测值为该节点所有样本目标值的平均值。
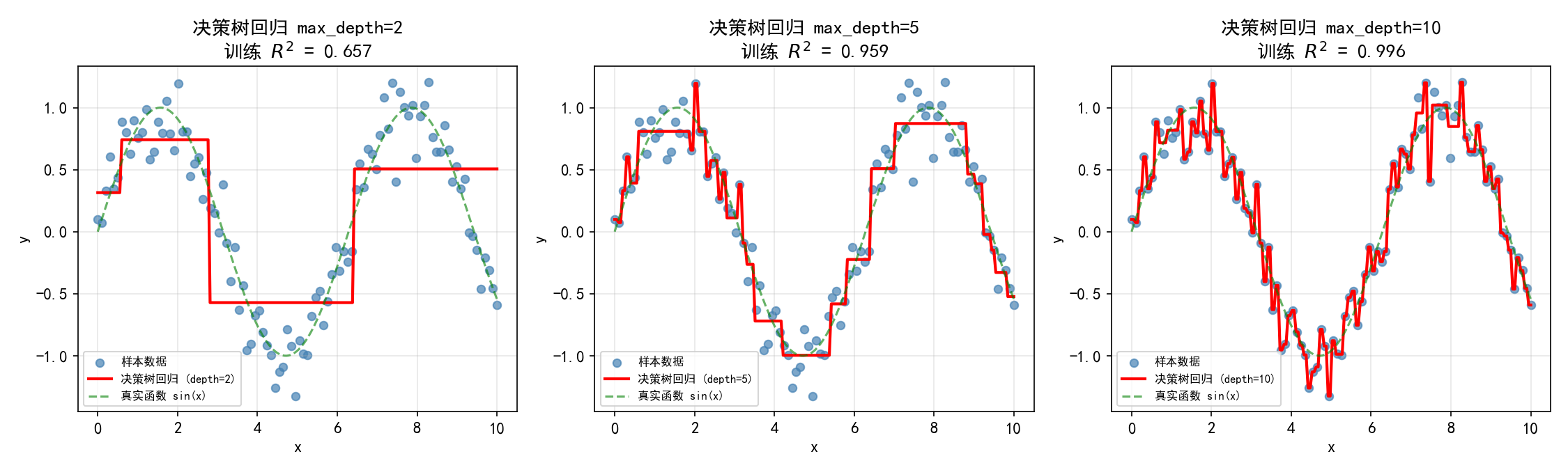
决策树回归的预测曲线呈阶梯状——这是树模型的本质特征:
max_depth=2:只有 4 个叶节点,阶梯粗糙,
max_depth=5:较好地拟合 sin(x),
max_depth=10:每个阶梯很窄,过拟合,训练
from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor(max_depth=5, random_state=42).fit(X_train, y_train)
y_pred = dtr.predict(X_test)
7.5 特征重要性
决策树可以输出每个特征的重要性评分,反映该特征在分裂中的贡献:
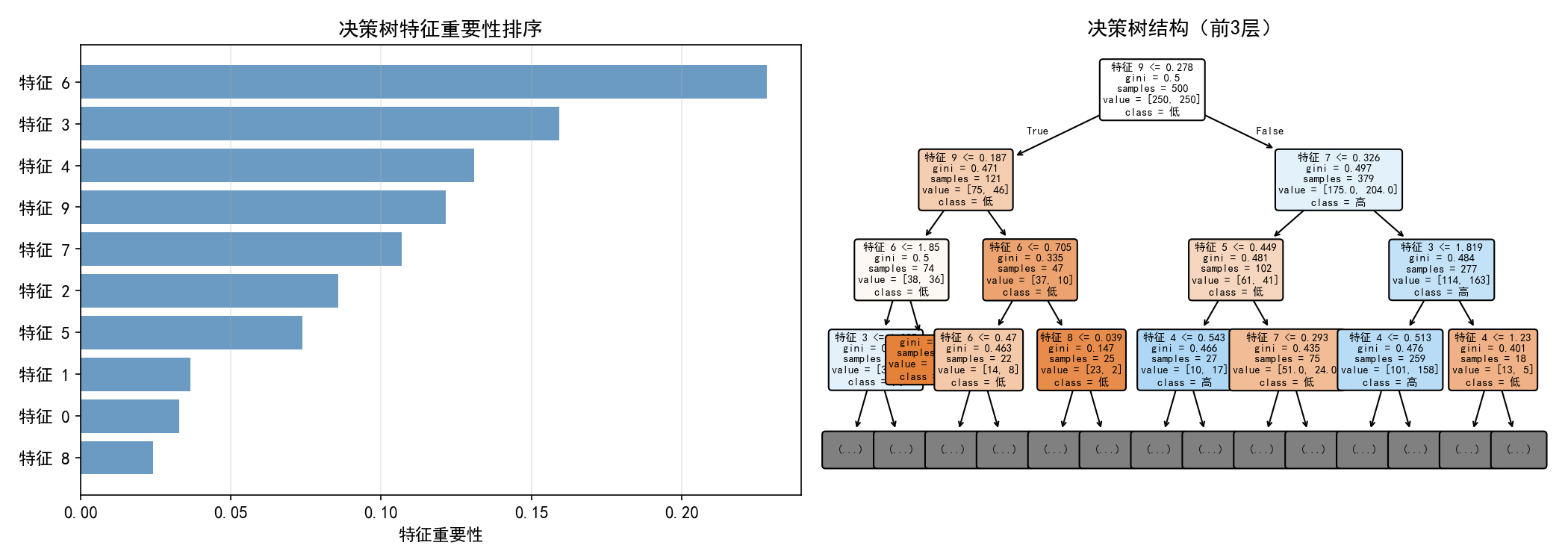
左图:特征 0、1、2(真实相关特征)的重要性远高于其他噪声特征(3~9)。这说明决策树具有隐式特征选择能力。
右图:树的前 3 层——可以看到特征 0 和特征 2 被用于顶层分裂,印证了它们的高重要性。
特征重要性的计算:
# 获取特征重要性
importances = dt.feature_importances_
# 排序
sorted_idx = np.argsort(importances)[::-1]
for i in sorted_idx:
print(f'特征 {i}: {importances[i]:.4f}')
7.6 决策树的优缺点
优点
缺点
7.7 实用技巧速查
7.8 数模竞赛中的应用
决策树在数学建模竞赛中常用于:
可解释性分析:在论文中直接展示决策规则,说服力强
特征重要性排序:快速识别关键影响因素
基线模型:简单、快速,作为复杂模型的对比基准
规则提取:将树的路径转化为业务规则
注意事项:
单一决策树容易过拟合,竞赛中更推荐用随机森林(第8章)
通过交叉验证选择
max_depth,不要凭感觉设random_state固定随机种子,保证结果可复现树的结构会随数据变化而剧烈变化,结论需谨慎解读
7.9 本节小结
决策树通过"如果-那么"规则递归划分数据,形成树形结构
基尼系数和信息熵是两种常用的不纯度指标,实践中差异不大
决策树极易过拟合,必须通过剪枝(max_depth、min_samples_leaf 等)控制复杂度
决策边界是轴对齐的矩形,无法表示斜线或对角线边界
决策树回归产生阶梯状预测曲线
特征重要性可用于隐式特征选择
决策树无需标准化、可解释性强,但稳定性差——随机森林是更好的选择
第8章 随机森林
8.1 Bagging 原理
随机森林(Random Forest)基于 Bagging(Bootstrap Aggregating)思想:从原始数据中有放回地抽取多个子样本,分别训练多棵决策树,最终通过投票(分类)或平均(回归)得到预测结果。
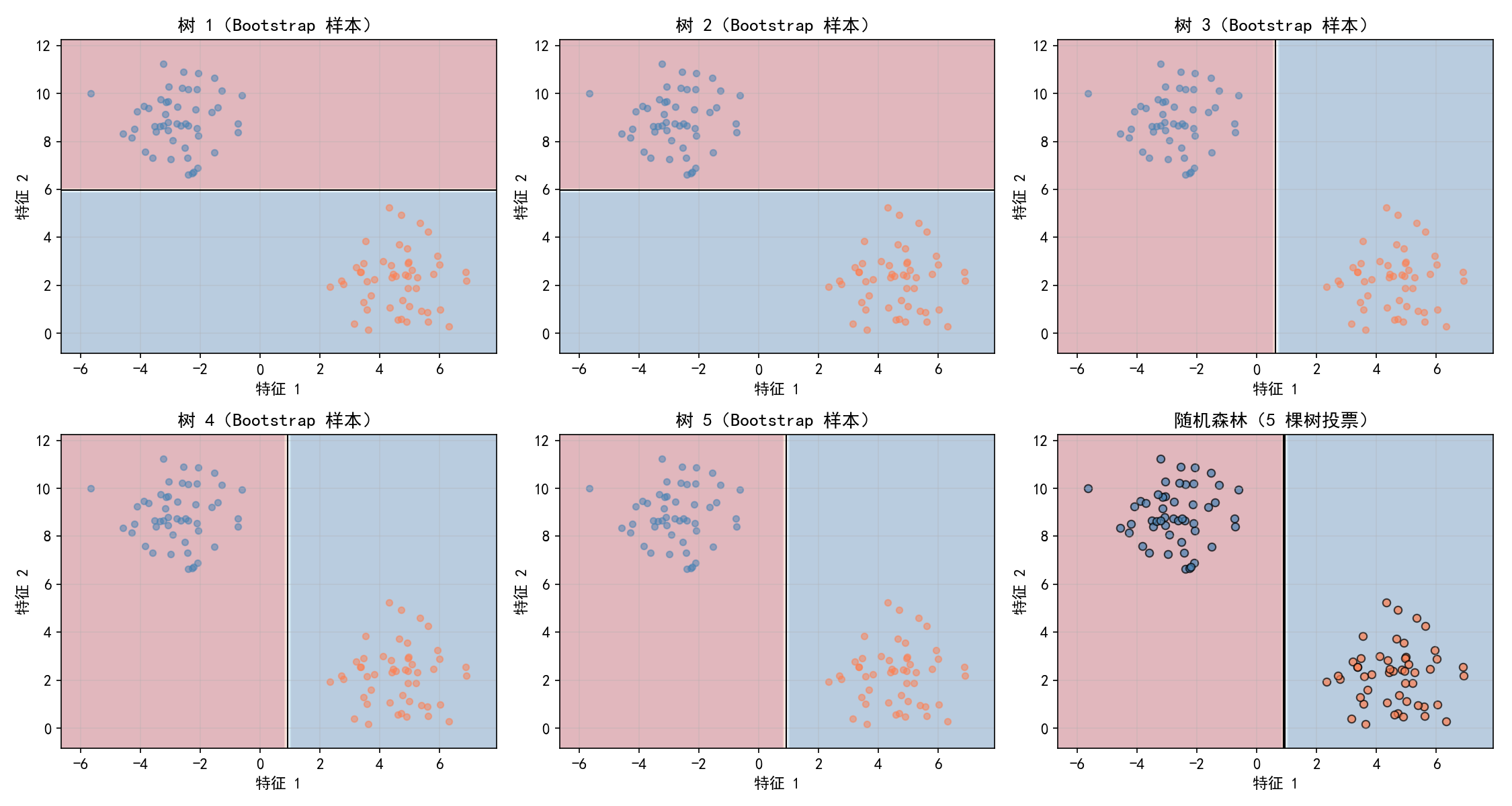
上排(树 1~3):每棵树基于不同的 Bootstrap 样本训练,得到的决策边界各不相同——有的以水平线分裂,有的以垂直线分裂。
下排(树 4~5 + 森林):前 4 棵树的边界方向也不一致。但右下角的随机森林(5 棵树投票)产生了一条更稳健、更接近真实边界的分割线。
关键洞察:单棵树的决策边界可能因为采样偏差而偏离真实分布,但多棵树的集体投票能抵消个体偏差,获得更稳定的预测。
Bagging 的核心步骤:
Bootstrap 采样:从 N 个样本中有放回地抽取 N 个样本(约 63.2% 的唯一样本)
训练:对每个 Bootstrap 样本训练一棵决策树
聚合:分类用多数投票,回归用平均值
from sklearn.ensemble import RandomForestClassifier, BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
# 方式一:直接用 RandomForestClassifier(推荐)
rf = RandomForestClassifier(n_estimators=100, random_state=42).fit(X_train, y_train)
# 方式二:用 BaggingClassifier 包装(更灵活)
bagging = BaggingClassifier(
estimator=DecisionTreeClassifier(),
n_estimators=100,
random_state=42
).fit(X_train, y_train)
随机森林在 Bagging 的基础上增加了特征随机性:每次分裂时只考虑随机选择的
max_features个特征,进一步增加树之间的差异(去相关性)。
8.2 单树 vs 随机森林
第7章讨论了决策树的优缺点,其中最大的问题是容易过拟合、不稳定。随机森林通过集成多棵树来解决这些问题。
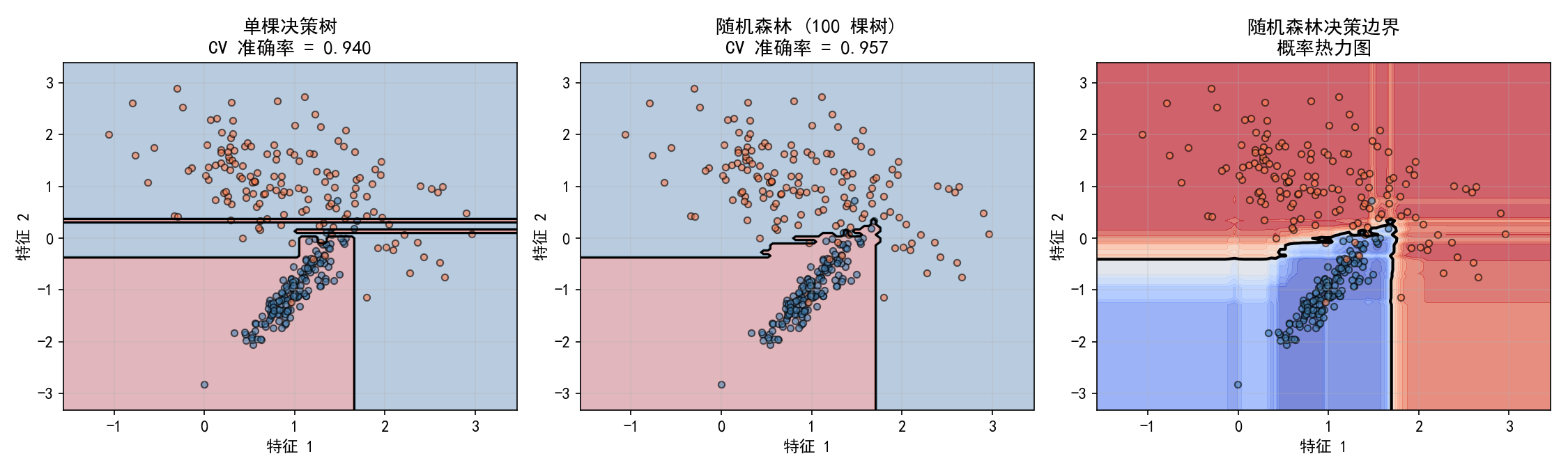
左图(单棵决策树):边界呈现典型的阶梯状,对个别噪声点过度敏感。
中图(随机森林 100 棵树):边界更平滑,CV 准确率更高。100 棵树的集体决策抵消了单棵树的偏差。
右图(概率热力图):随机森林的 predict_proba 输出概率值,颜色越红表示属于类别 1 的概率越高,越蓝表示属于类别 0 的概率越高。边界区域呈现渐变过渡,说明模型对边界附近样本的不确定性更大。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, random_state=42).fit(X_train, y_train)
# 硬预测
y_pred = rf.predict(X_test)
# 概率预测
y_prob = rf.predict_proba(X_test) # 返回每个类别的概率
# 各棵树的预测
for i, tree in enumerate(rf.estimators_[:3]):
print(f'树 {i}: {tree.predict(X_test[:5])}')
为什么随机森林不容易过拟合?
偏差-方差权衡:单棵深树方差大(对数据敏感),多棵树的平均降低方差
去相关性:特征随机选择使各棵树"看"到不同的特征子集,降低树之间的相关性
理论保证:Breiman (2001) 证明,随着树数量增加,泛化误差收敛到一个上界,不会无限增长
经验:增加树的数量通常不会导致过拟合,只会增加计算成本。一般 100~500 棵树已经足够。
8.3 OOB 误差
Bootstrap 采样中,约 36.8% 的样本未被选中(称为 Out-Of-Bag,OOB 样本)。这些样本可以用于评估模型,无需额外划分验证集。
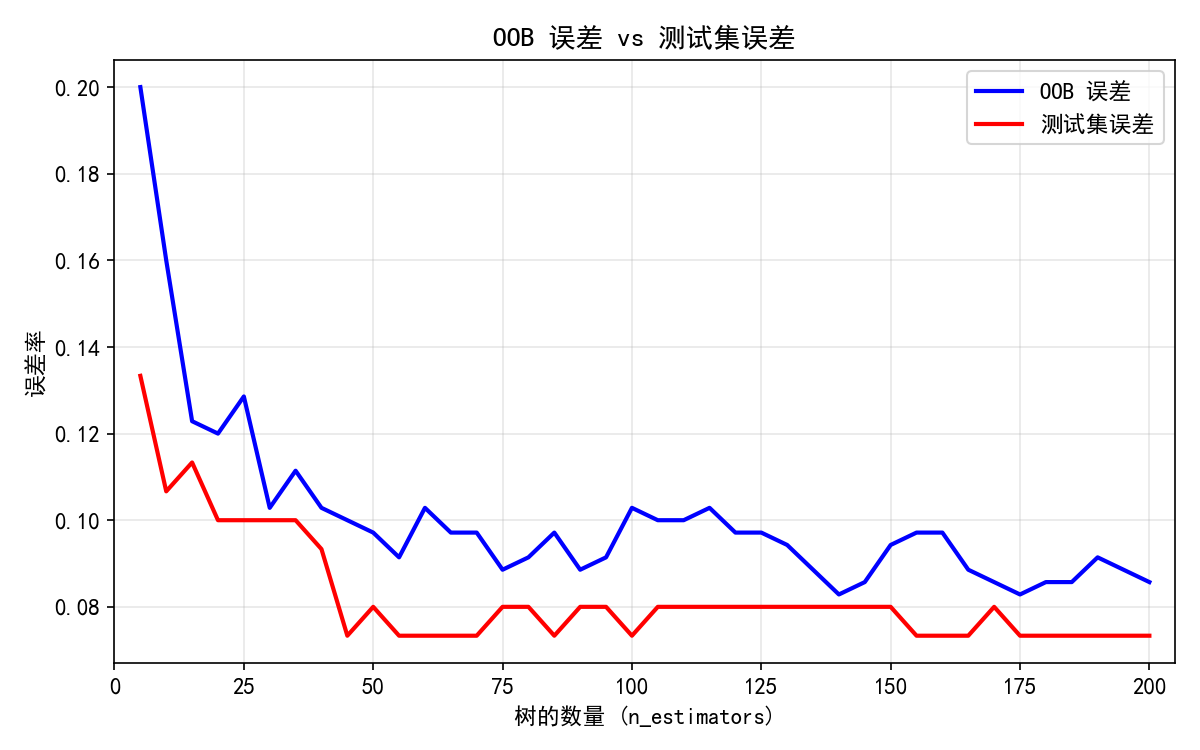
蓝色曲线(OOB 误差):用未参与训练的 OOB 样本评估误差。
红色曲线(测试集误差):用独立测试集评估误差。
两条曲线高度一致,说明 OOB 误差是泛化误差的可靠估计。
关键观察:
OOB 误差始终略高于测试误差(因为 OOB 样本更少,估计方差更大)
树数量达到 ~50 后,两条曲线都趋于平稳
继续增加树数量对性能提升有限
# 启用 OOB 评估
rf = RandomForestClassifier(n_estimators=100, oob_score=True, random_state=42)
rf.fit(X_train, y_train)
print(f'OOB 分数: {rf.oob_score_:.4f}')
print(f'OOB 误差: {1 - rf.oob_score_:.4f}')
实用建议:在数据量有限、不想浪费样本做验证集时,使用
oob_score=True是高效的评估方式。
8.4 特征重要性
随机森林可以评估每个特征对预测的贡献度:
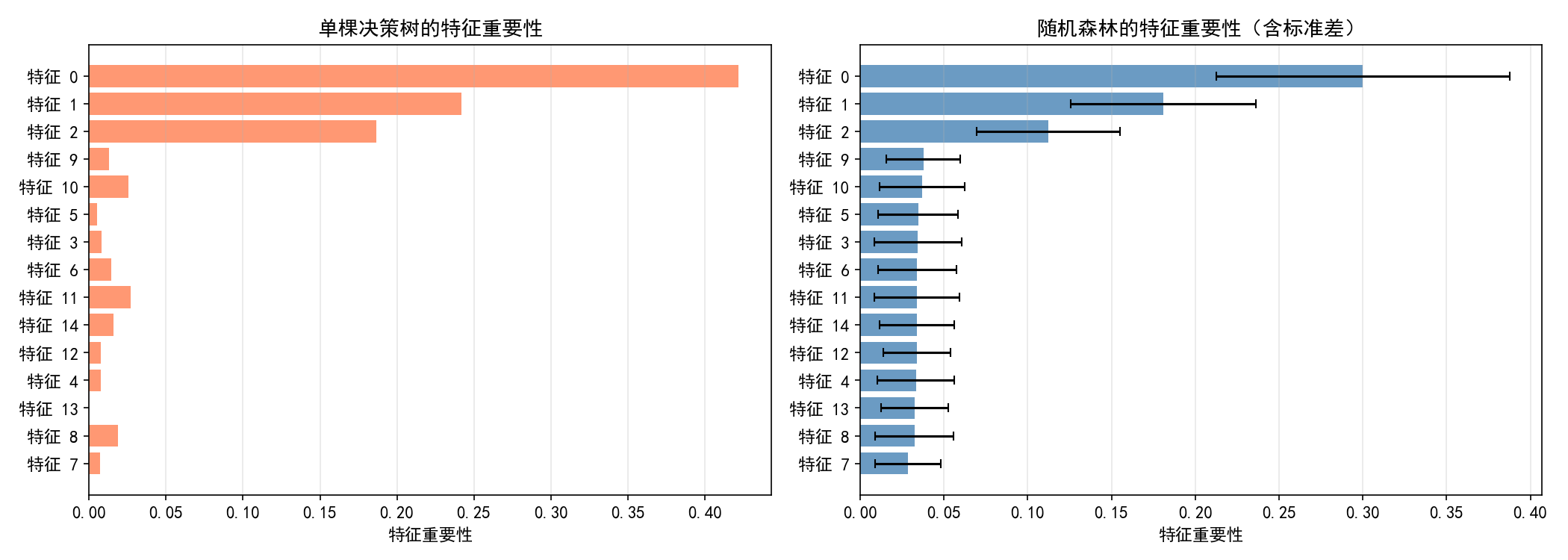
左图(单棵决策树):虽然特征 0、1、2(真实相关)重要性最高,但特征 8、11 等噪声特征也有不可忽视的重要性评分。单棵树的选择受随机性影响较大。
右图(随机森林 100 棵树):特征 0、1、2 的重要性显著高于其他噪声特征。更重要的是,每个特征都有误差棒(标准差),反映了不同树之间的一致性:
特征 0、1:误差棒短,说明所有树都一致认为它们重要
特征 2:误差棒稍长,说明不同树的评估有些差异
噪声特征(3~14):重要性接近,误差棒相似,说明随机森林能有效识别无关特征
特征重要性的计算
即:特征 j 在所有使用它的节点上,带来的不纯度降低量 × 该节点的样本比例,累加得到总重要性。
# 获取特征重要性
importances = rf.feature_importances_
# 排序并打印
sorted_idx = np.argsort(importances)[::-1]
for i in sorted_idx:
print(f'特征 {i}: {importances[i]:.4f}')
# 获取每棵树的重要性(用于计算标准差)
std = np.std([tree.feature_importances_ for tree in rf.estimators_], axis=0)
注意:基于不纯度的特征重要性对高基数类别特征有偏差(倾向于选择取值更多的特征)。如果需要更可靠的评估,可以使用
permutation_importance(排列重要性)。
8.5 随机森林回归
随机森林同样可用于回归任务。与决策树回归相比,随机森林的预测曲线更平滑:
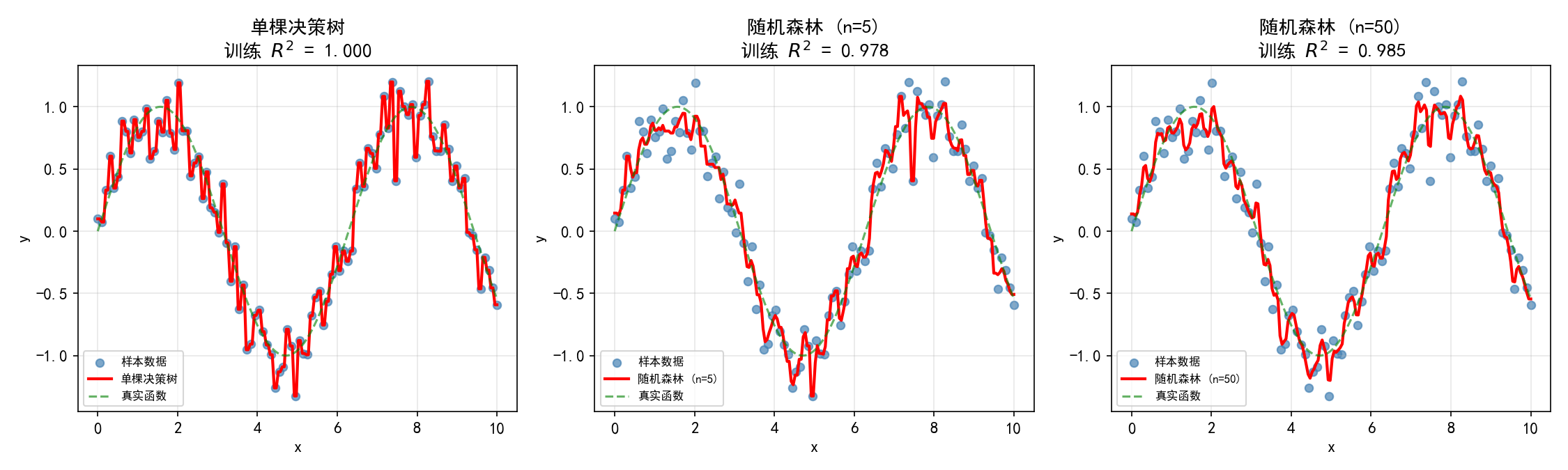
关键洞察:
单棵树会"记住"每个训练样本的位置,产生极窄的阶梯(过拟合)
多棵树的平均使预测更平滑,相当于对阶梯进行了"模糊"处理
树越多,阶梯越细密,越接近真实函数
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor(n_estimators=100, random_state=42).fit(X_train, y_train)
y_pred = rf_reg.predict(X_test)
# R² 分数
r2 = rf_reg.score(X_test, y_test)
随机森林回归的优势:
无需假设函数形式:不像线性回归要求线性关系
自动处理非线性:可以拟合任意复杂的关系
鲁棒性强:对异常值和噪声不敏感
无需标准化:对特征量纲不敏感
8.6 随机森林的重要参数
# 常用配置
rf = RandomForestClassifier(
n_estimators=200,
max_depth=None, # 让树充分生长
min_samples_leaf=2, # 每个叶节点至少 2 个样本
max_features='sqrt', # 每次分裂考虑 sqrt(n_features) 个特征
bootstrap=True,
oob_score=True,
n_jobs=-1, # 使用所有 CPU 核心
random_state=42
).fit(X_train, y_train)
8.7 实用技巧速查
8.8 数模竞赛中的应用
随机森林在数学建模竞赛中是最实用的算法之一:
强力的基线模型:无需调参即可获得很好的效果,适合作为基准
特征重要性分析:快速识别关键变量,为论文提供可解释性支撑
鲁棒性强:对缺失值、异常值、量纲不敏感,减少数据预处理工作量
无需标准化:省去了特征缩放步骤,简化流程
支持混合类型:可同时处理数值和类别特征
竞赛实战建议:
先用默认参数的随机森林跑一遍,通常已有不错效果
用 OOB 误差评估,节省样本
用特征重要性筛选变量,再训练更简洁的模型
如果时间允许,用
GridSearchCV调优n_estimators和max_features对于不平衡数据,设置
class_weight='balanced'
注意事项:
训练和预测速度较慢(相比逻辑回归),大数据集时考虑
n_jobs=-1概率输出可能不够校准(可配合
CalibratedClassifierCV使用)外推能力差:不能预测训练数据范围之外的值
8.9 本节小结
随机森林基于 Bagging 思想:Bootstrap 采样 + 多树投票/平均
在 Bagging 基础上增加了特征随机性(
max_features),进一步降低树间相关性随机森林比单棵决策树更稳定、泛化更好,且不易过拟合
OOB 误差利用未参与训练的样本评估模型,是验证集的可靠替代
特征重要性可用于变量筛选,随机森林给出的重要性比单棵树更可靠(有标准差)
随机森林回归比单树回归产生更平滑的预测曲线
主要参数:
n_estimators(树数量)、max_features(特征子集大小)、min_samples_leaf(叶节点最小样本)数模竞赛中,随机森林是开箱即用的强力工具:无需标准化、对异常值鲁棒、自带特征选择
第9章 算法综合对比
前面8章分别介绍了6类主流机器学习算法。本章将它们放在一起对比,帮助你在实际建模时做出合理选择。
9.1 分类性能对比
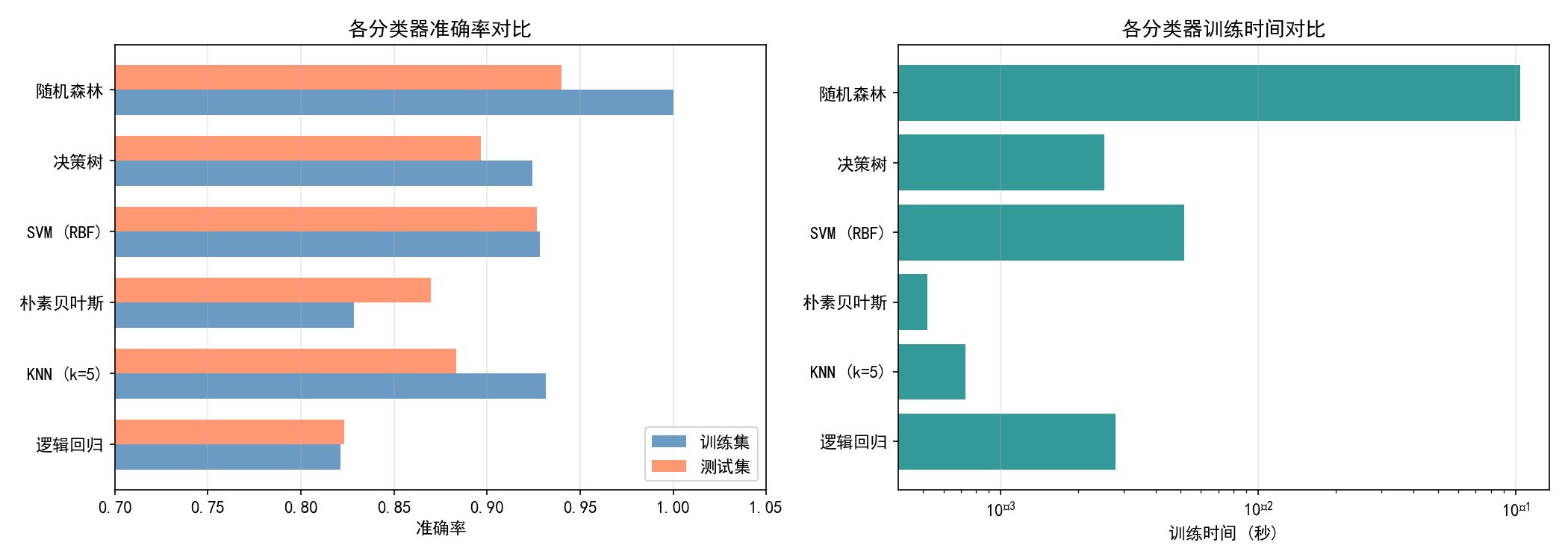
左图:准确率对比
在 1000 样本、10 特征的模拟数据集上:
关键结论:
随机森林在准确率上领先,是分类任务的"万金油"
SVM 表现接近随机森林,但训练时间更长
逻辑回归虽然准确率最低,但训练/测试差距最小(最不容易过拟合)
右图:训练时间(对数刻度)
经验法则:小数据集(< 5000 样本)优先 SVM 或随机森林;大数据集考虑逻辑回归、KNN 或 LinearSVC。
9.2 回归性能对比
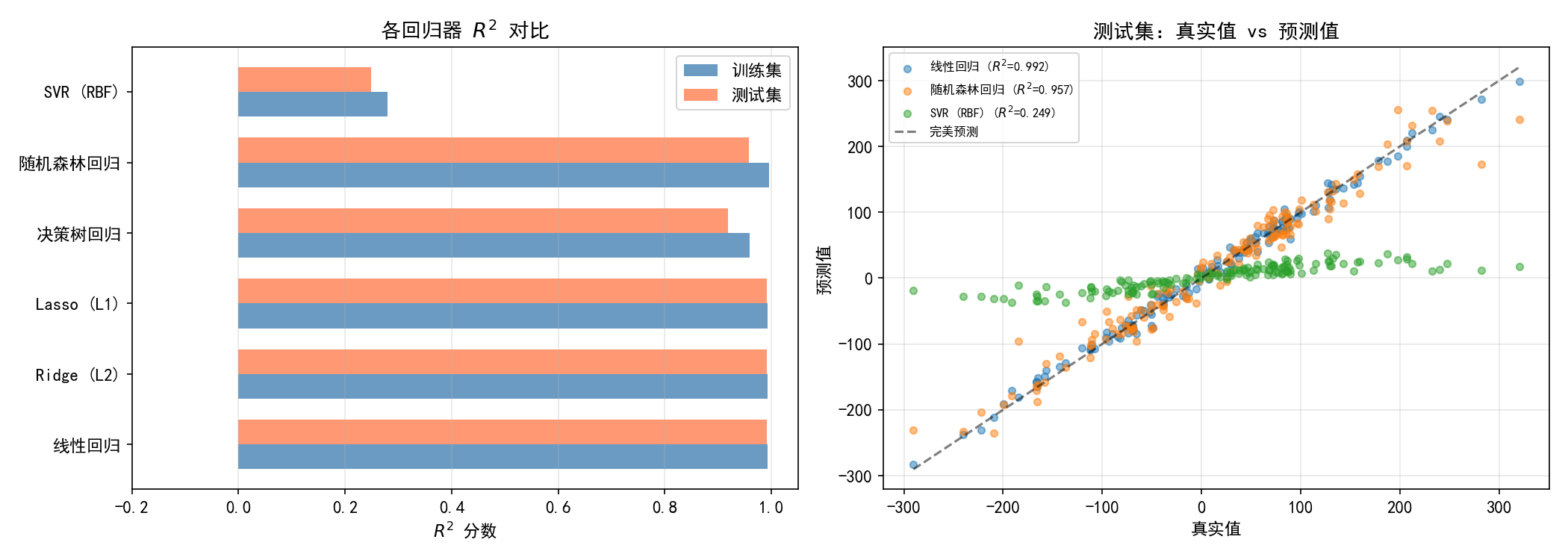
左图:R² 对比
在 500 样本、5 特征的线性回归数据集上(y = w·x + noise):
关键结论:
线性数据用线性模型——线性回归、Ridge、Lasso 几乎完美
树模型(决策树、随机森林)在纯线性关系上反而不如线性回归
SVR 对参数敏感,默认参数可能表现很差
右图:真实值 vs 预测值散点
线性回归(蓝色):几乎全部落在对角线上,R² = 0.992
随机森林回归(橙色):大部分靠近对角线,R² = 0.957
SVR (RBF)(绿色):严重偏离,R² = 0.249(需要调参)
经验法则:先试线性回归,如果 R² 低再尝试非线性模型(随机森林、SVR)。树模型适合非线性关系,线性模型适合线性关系。
9.3 决策边界对比
在同心圆数据集(线性不可分)上,6 种分类器的决策边界:
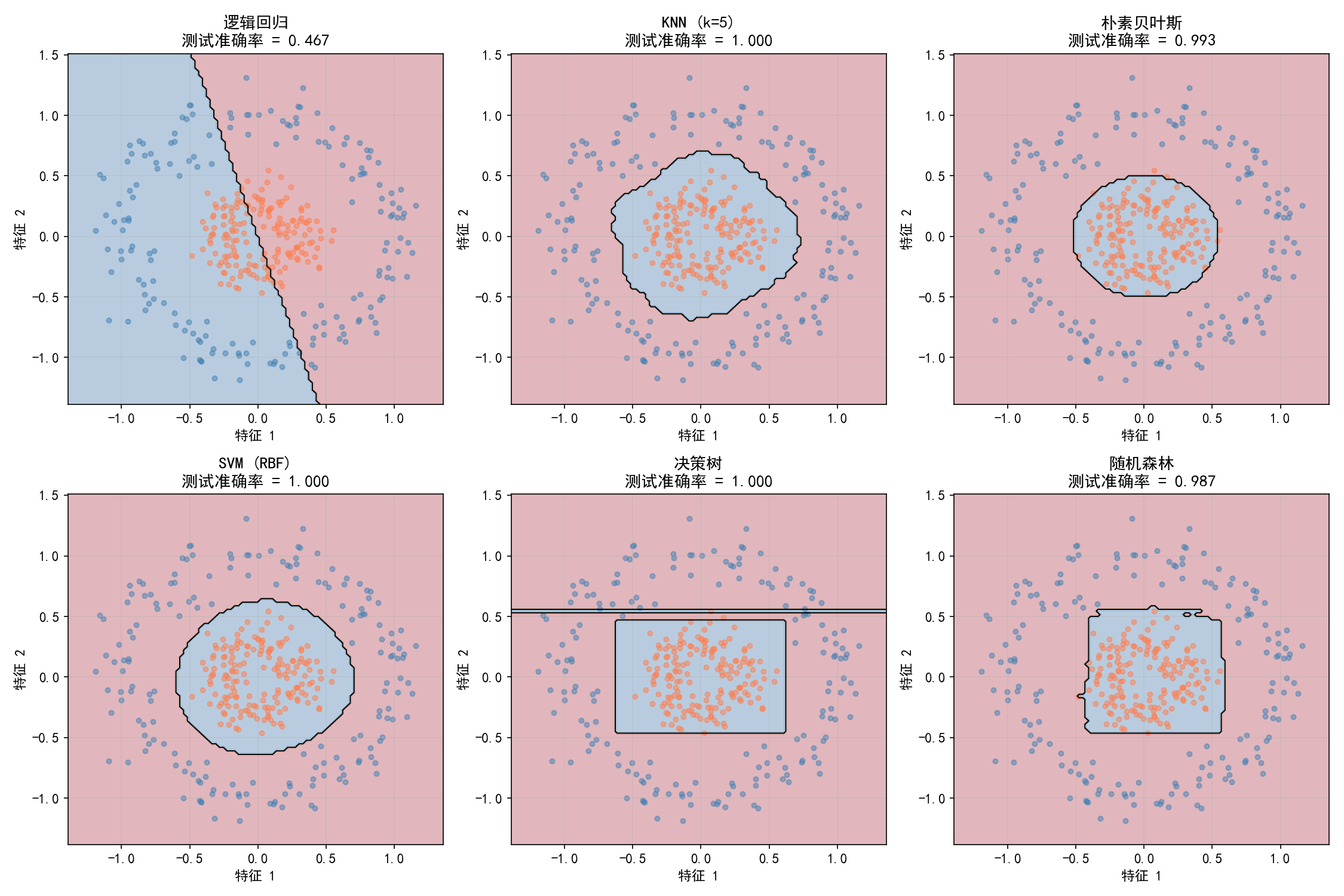
关键观察:
逻辑回归(左上):只能用直线分割,完全无法处理同心圆(46.7% 相当于随机猜测)
SVM (RBF)(左下)和 KNN(中上):完美捕捉环形结构
决策树(中下):虽然准确率 100%,但边界是阶梯状的矩形,缺乏"美感"
朴素贝叶斯(右上):假设特征服从高斯分布,产生椭圆边界,效果接近完美
启示:对于明显非线性的数据(如环形、螺旋形),逻辑回归完全失效,必须使用核方法(SVM)、集成方法(随机森林)或基于邻居的方法(KNN)。
9.4 学习曲线对比
学习曲线展示模型如何随数据量增加而提升:
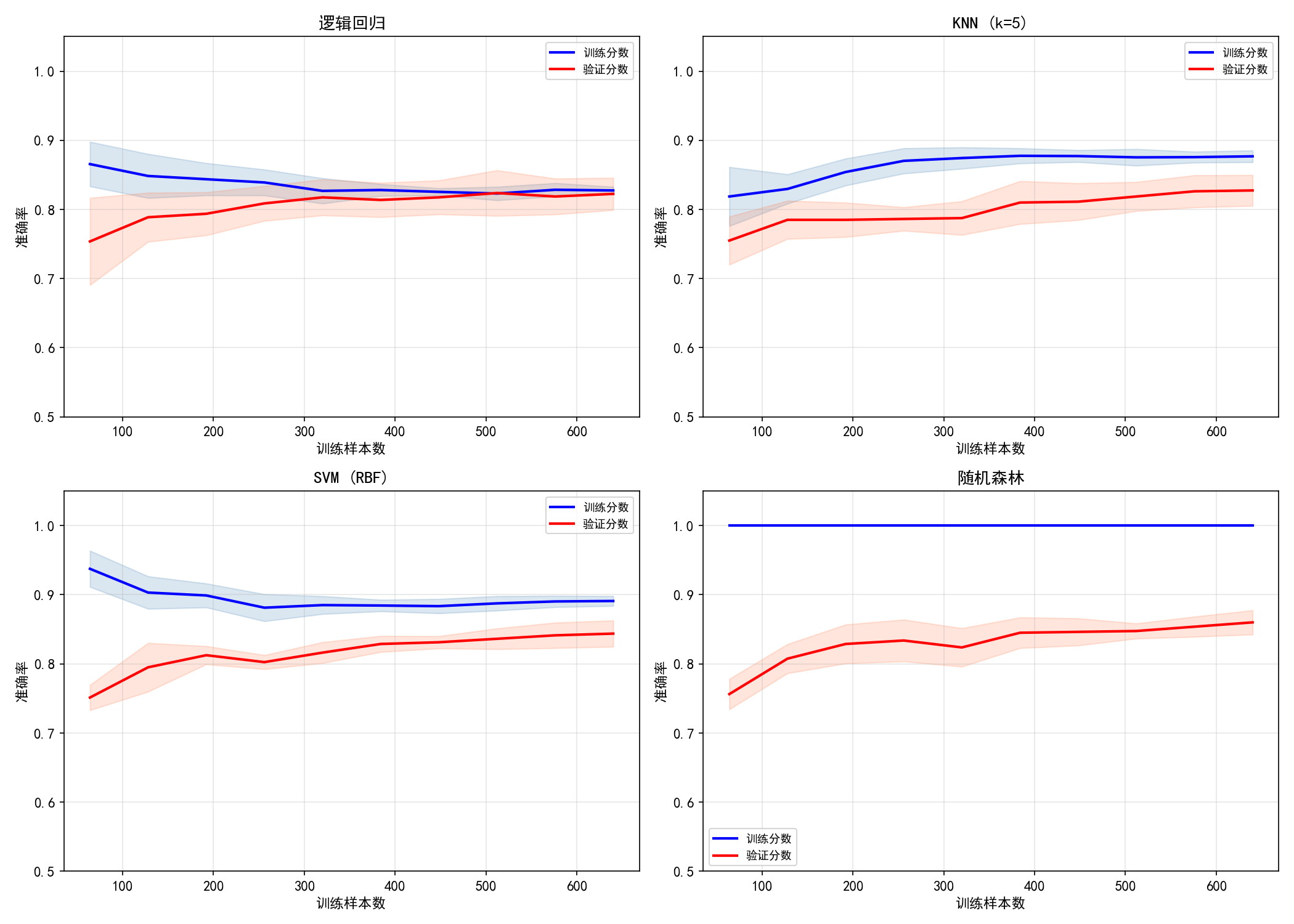
逻辑回归
训练分数从 ~0.87 缓慢下降到 ~0.84
验证分数从 ~0.75 缓慢上升到 ~0.83
两条线逐渐收敛:典型的高偏差(欠拟合)模式,增加数据量帮助有限
KNN (k=5)
训练分数稳定在 ~0.88,验证分数 ~0.83
两者差距小,说明 k=5 的选择不差
增加数据有轻微帮助
SVM (RBF)
训练分数从 ~0.92 下降到 ~0.89
验证分数从 ~0.77 上升到 ~0.85
差距在缩小:随着数据增加,SVM 的泛化能力提升
随机森林
训练分数稳定在 ~1.0(完美拟合)
验证分数从 ~0.75 稳步上升到 ~0.87
差距最大但在缩小:典型的树模型行为——训练完美,但泛化随数据量提升
四类曲线的解读
实战建议:画学习曲线是诊断模型问题的最快方式。如果验证分数还在上升,优先增加数据而不是调参。
9.5 算法选择指南
能力雷达图
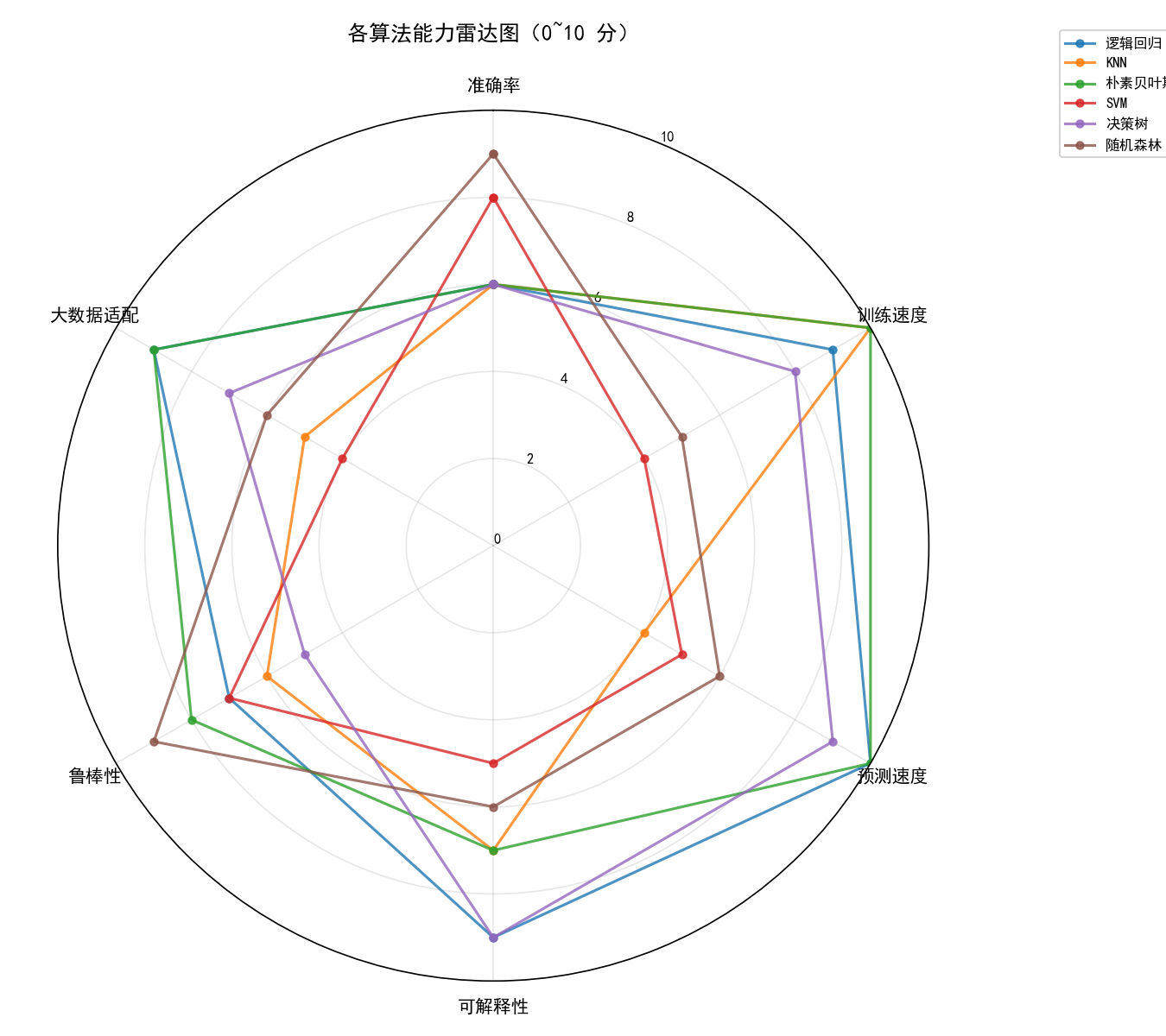
各维度评分(0~10,越高越好):
快速选择指南
按场景选择:
算法对比速查表
9.6 数模竞赛实战流程
在数学建模竞赛中,推荐的机器学习建模流程:
1. 数据探索 → 理解数据结构、分布、缺失值
↓
2. 数据预处理 → 缺失值填充、异常值处理、特征编码
↓
3. 特征工程 → 特征构造、特征选择、降维(如需要)
↓
4. Baseline → 随机森林(默认参数),快速得到基准分数
↓
5. 多模型对比 → 尝试 3~5 种算法,选择最优
↓
6. 参数调优 → GridSearchCV 优化选定模型
↓
7. 集成/堆叠 → 多模型融合(如需要进一步提升)
↓
8. 结果解释 → 特征重要性、SHAP 值、决策规则
核心原则:
先用随机森林跑 baseline,因为它几乎总是给出不错的结果
不要一开始就调参——先确保数据预处理正确
多模型对比比单模型调参更重要
最终论文中,用决策树或逻辑回归展示可解释结果,用随机森林/SVM 报告最优性能
9.7 本节小结
没有最好的算法,只有最适合的算法——选择取决于数据特征、规模、时间约束
随机森林是综合表现最稳定的算法:准确率高、鲁棒性强、几乎不需要调参
逻辑回归在小数据集上依然有价值:训练快、可解释、不易过拟合
SVM在中小规模非线性数据上表现出色,但大数据集上训练慢
KNN训练几乎为零成本,但预测慢且对标准化敏感
朴素贝叶斯在文本分类和高维稀疏数据上有独特优势
决策树可解释性最强,但单树容易过拟合,通常作为随机森林的组成部分
学习曲线是诊断模型问题的有效工具:验证分数持续上升 = 需要更多数据
数模竞赛中:随机森林 baseline → 多模型对比 → 参数调优 → 结果解释 是标准流程
附录:完整代码获取
本教程所有代码均可通过以下链接下载: