
基础篇:Statsmodels库求解时间序列模型方法
前言
statsmodels 是 Python 生态中最全面的统计分析库之一,其时间序列模块(tsa)涵盖了从经典 ARIMA 到现代状态空间模型(SARIMAX)的完整工具链。对于需要在数模竞赛中快速完成时间序列建模与预测的人来说,statsmodels 提供了从数据探索、参数识别、模型拟合、残差诊断到样本外预测的一站式解决方案。
适用读者
本教程面向已经了解 Python 基础编程和 pandas 操作的读者。如果你已经知道以下概念,就可以直接开始:
基础统计概念(均值、方差、相关性)
pandas 的 Series 和 DataFrame 操作
matplotlib 的基本绘图
本教程不讲解数理统计的数学推导,而是聚焦于如何用 statsmodels 完成时间序列分析的全流程,并配有可直接套用的数模论文模板。
内容结构
环境说明
Python 版本:3.10+
statsmodels 版本:0.14+
pandas 版本:2.x
matplotlib 版本:3.x
可视化:Matplotlib(需配置中文字体
SimHei)
所有代码示例均可直接复制运行。可视化部分统一使用 plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'] 配置中文显示。
运行方式
# 安装依赖(如未安装)
pip install statsmodels pandas matplotlib scipy scikit-learn
# 导入核心模块
import statsmodels.api as sm
import pandas as pd
import matplotlib.pyplot as plt
学习建议
第 1–2 章是基础概念,建议快速通读,理解平稳性和 ACF/PACF 的含义
第 3–4 章是核心建模方法,建议边读边跑代码,动手拟合 AR/MA/ARIMA
第 5–6 章针对季节性数据和指数平滑,根据实际问题按需学习
第 7 章的模型评估方法是数模论文的必备内容
第 8 章的完整流程模板可以直接套用到竞赛中,替换数据即可
第1章 时间序列基础
1.1 什么是时间序列
时间序列(Time Series)是按时间顺序排列的观测值集合。与横截面数据不同,时间序列的核心特征是观测值之间存在时间上的依赖关系——今天的值往往与昨天相关。
典型的时间序列数据包括:
每日股票价格
月度销售额
每小时气温记录
季度 GDP 数据
在 statsmodels 中,时间序列通常以 pandas.Series 或 pandas.DataFrame 的形式存储,索引为时间戳。
示例:大气 CO₂ 浓度数据
statsmodels 内置了 Mauna Loa 大气 CO₂ 浓度数据集,是一个经典的时间序列案例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
# 中文字体设置
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
co2 = data['co2'].loc['1960':'2000'].interpolate()
# 绘制时序图
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(co2.index, co2.values, linewidth=0.8, label='CO2 浓度')
# 12期移动平均作为趋势线
rolling = co2.rolling(window=12).mean()
ax.plot(rolling.index, rolling.values, color='red', linewidth=2, label='12期移动平均(趋势)')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度 (ppm)')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
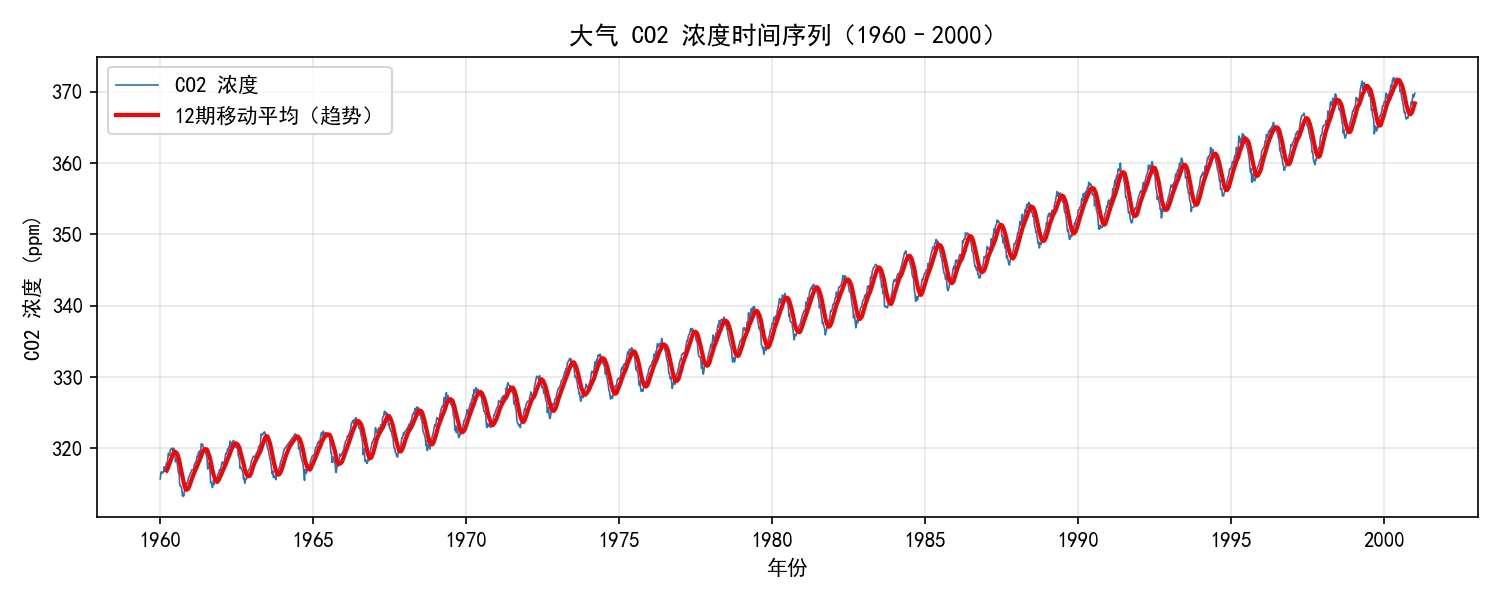
该序列呈现出两个明显特征:
趋势:CO₂ 浓度逐年上升(红色趋势线)
季节性:每年呈现规律的锯齿状波动
1.2 平稳性(Stationarity)
1.2.1 平稳性的定义
平稳性是时间序列建模的核心前提。一个弱平稳(Weakly Stationary)序列需要满足三个条件:
均值恒定:E(Yt)=μ(常数,不随时间变化)
方差恒定:Var(Yt)=σ2(常数,不随时间变化)
自协方差仅与时间间隔有关:Cov(Yt,Yt+k)=γ(k)(只依赖于间隔 k,不依赖于具体时间点 t)
直观理解:平稳序列的统计特性不随时间漂移,序列围绕一个固定的均值上下波动。
1.2.2 平稳 vs 非平稳序列对比
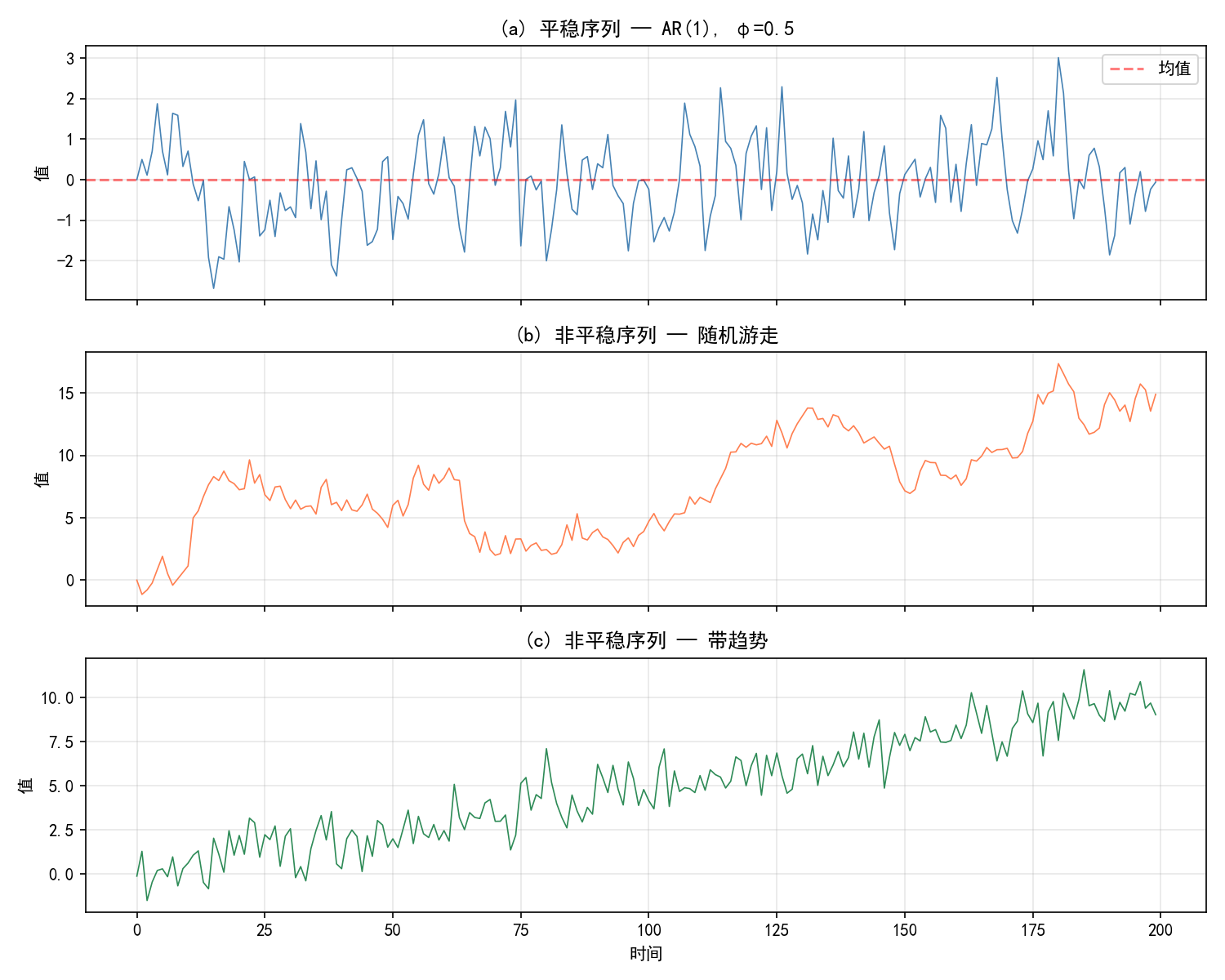
上图中三种序列的区别:
为什么平稳性重要? 大多数时间序列模型(如 ARIMA)假设数据是平稳的。如果直接对非平稳序列建模,可能导致"伪回归"——看似显著的关系实际上只是趋势巧合。
1.2.3 如何将非平稳序列变为平稳?
差分(Differencing) 是最常用的方法。一阶差分定义为:
ΔYt=Yt−Yt−1
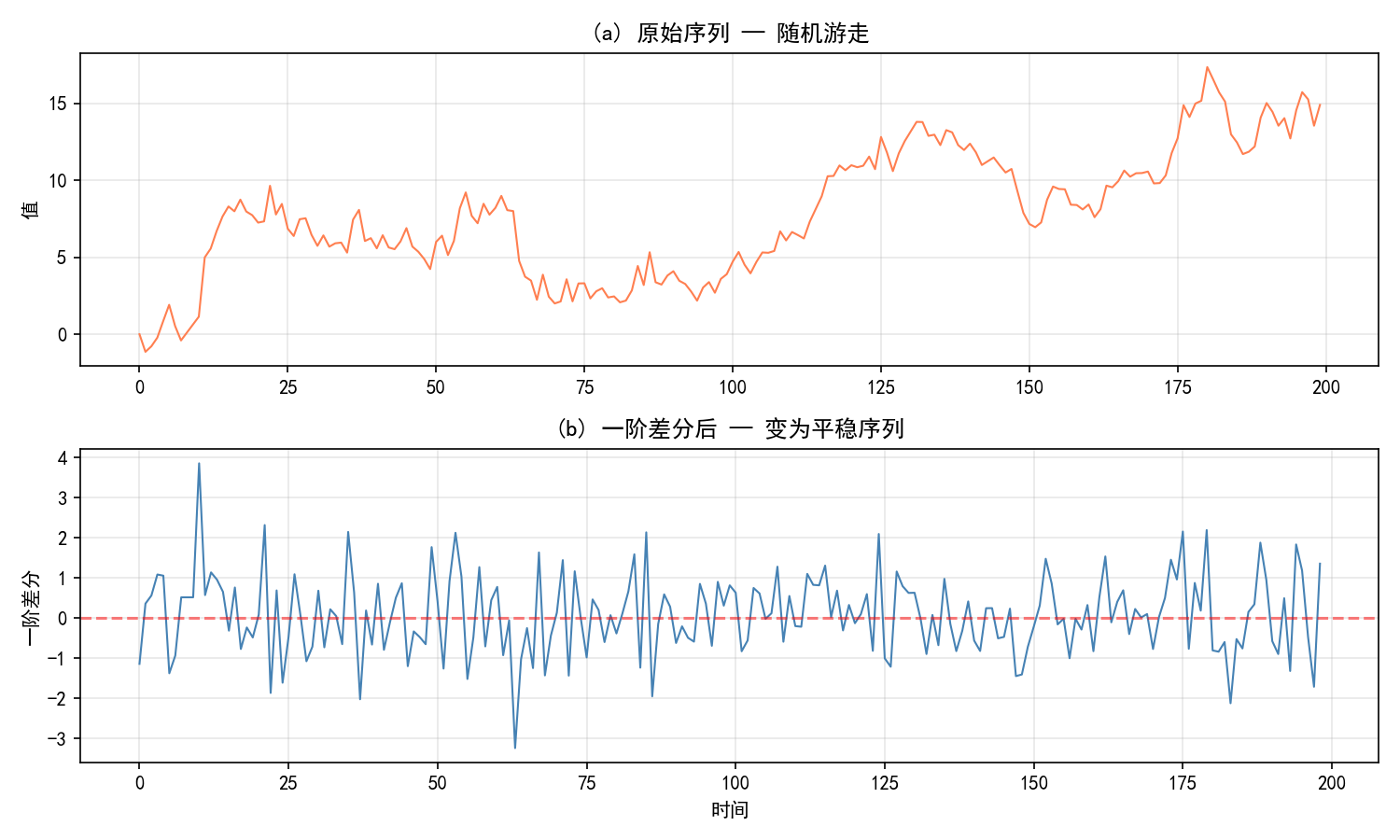
随机游走序列本身是非平稳的(上图),但一阶差分后变为白噪声序列(下图),满足平稳性要求。这就是 ARIMA 模型中 "I"(Integrated,积分/差分)的含义。
1.3 单位根检验 — ADF 检验
1.3.1 ADF 检验原理
ADF(Augmented Dickey-Fuller)检验用于正式判断一个序列是否平稳。
原假设 H0:序列存在单位根(非平稳)
备择假设 H1:序列不存在单位根(平稳)
检验统计量与临界值比较:
若 p-value < 0.05 → 拒绝 H0 → 序列平稳
若 p-value ≥ 0.05 → 无法拒绝 H0 → 序列非平稳
1.3.2 Python 实操
from statsmodels.tsa.stattools import adfuller
# 检验 CO2 序列(原始值)
result = adfuller(co2)
print("=== 原始 CO2 序列 ===")
print(f"ADF 统计量: {result[0]:.4f}")
print(f"p-value: {result[1]:.6f}")
print(f"临界值:")
for key, value in result[4].items():
print(f" {key}: {value:.4f}")
# 检验差分后的序列
co2_diff = co2.diff().dropna()
result_diff = adfuller(co2_diff)
print("\n=== 差分后 CO2 序列 ===")
print(f"ADF 统计量: {result_diff[0]:.4f}")
print(f"p-value: {result_diff[1]:.6f}")
输出:
=== 原始 CO2 序列 ===
ADF 统计量: -0.1279
p-value: 0.946586
临界值:
1%: -3.4334
5%: -2.8629
10%: -2.5675
=== 差分后 CO2 序列 ===
ADF 统计量: -14.4367
p-value: 0.000000
解读:
原始 CO₂ 序列的 p-value = 0.947 >> 0.05,无法拒绝非平稳的原假设
差分后的 p-value ≈ 0,ADF 统计量远小于 1% 临界值,说明一阶差分后序列已平稳
1.3.3 封装为便捷函数
def check_stationarity(series, name="序列"):
"""便捷函数:对序列进行 ADF 检验并输出结果"""
result = adfuller(series.dropna())
print(f"\n【{name}】")
print(f" ADF 统计量: {result[0]:.4f}")
print(f" p-value: {result[1]:.6f}")
is_stationary = result[1] < 0.05
print(f" 结论: {'平稳' if is_stationary else '非平稳'}")
return is_stationary
# 使用示例
check_stationarity(co2, "CO2 原始序列") # 非平稳
check_stationarity(co2_diff, "CO2 一阶差分") # 平稳(p ≈ 0)
1.4 时间序列的组成部分
一个时间序列通常可以分解为三个成分:
Yt=Tt+St+Rt
其中:
Tt:趋势(Trend)— 长期的上升或下降方向
St:季节性(Seasonality)— 固定周期内的规律波动
Rt:残差(Residual)— 无法解释的随机波动
也有乘法分解形式:Yt=Tt×St×Rt,适用于季节性波动幅度随趋势增长的情况。
from statsmodels.tsa.seasonal import seasonal_decompose
# 对 CO2 数据进行季节性分解(加法模型)
decomp = seasonal_decompose(co2, model='additive', period=12)
fig, axes = plt.subplots(4, 1, figsize=(10, 8), sharex=True)
axes[0].plot(decomp.observed, label='观测值')
axes[0].set_title('观测值')
axes[1].plot(decomp.trend, label='趋势', color='orange')
axes[1].set_title('趋势成分')
axes[2].plot(decomp.seasonal, label='季节性', color='green')
axes[2].set_title('季节性成分')
axes[3].plot(decomp.resid, label='残差', color='red')
axes[3].set_title('残差成分')
for ax in axes:
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
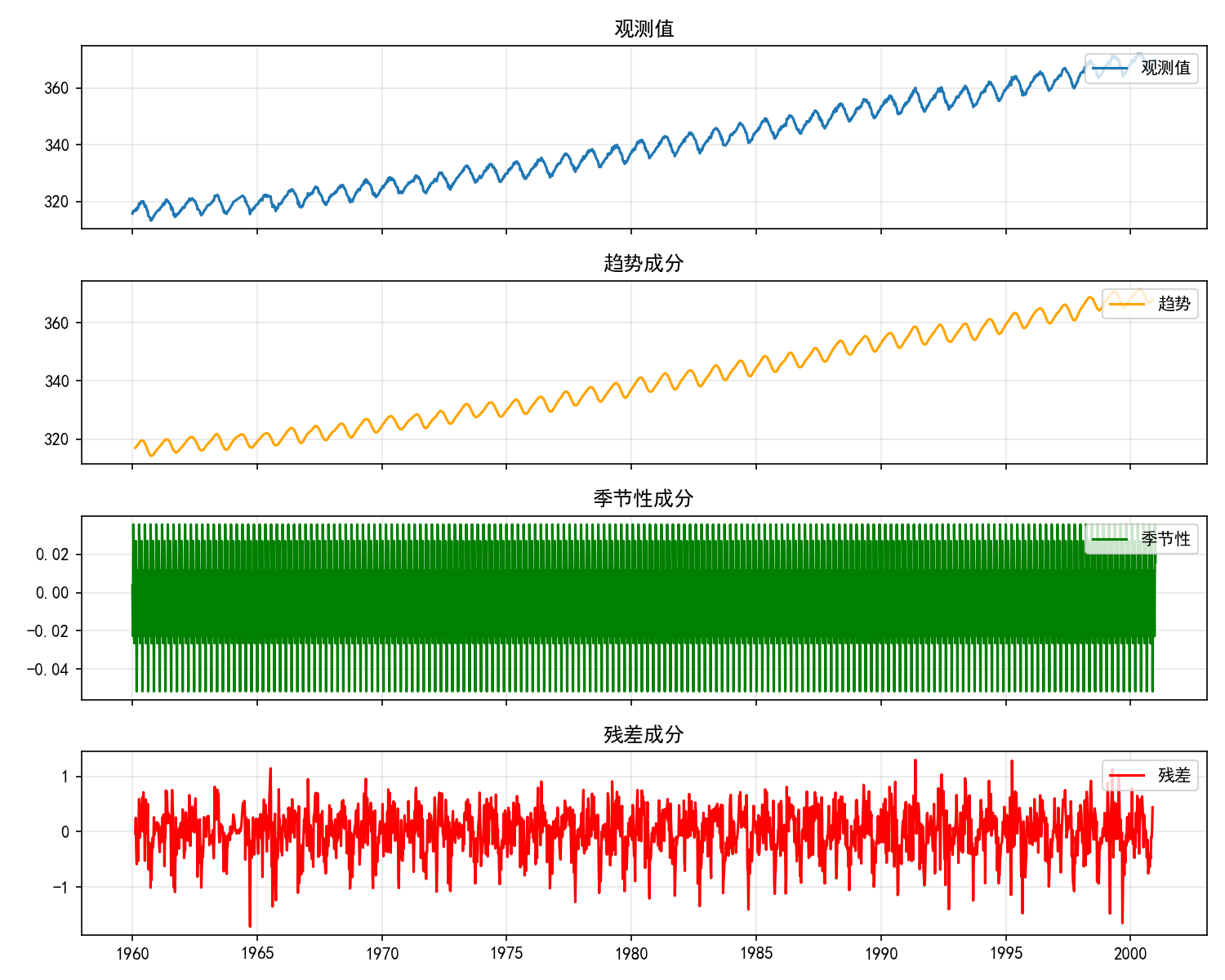
分解结果直观展示了 CO₂ 序列的三层结构:
趋势:持续上升的长期方向
季节性:每年夏季浓度降低、冬季升高的规律
残差:剔除趋势和季节性后的随机波动
1.5 本章小结
1.6 实用技巧速查
第2章 自相关分析与序列分解
2.1 自相关函数(ACF)
2.1.1 自相关的概念
自相关(Autocorrelation)衡量时间序列自身在不同滞后阶数上的相关性。滞后 kk 阶的自相关系数定义为:
直观理解:自相关回答的问题是——今天的值与 k 天前的值有多相关?
ρ(k)≈1:强正相关,Yt 和 Yt−k 同向变化
ρ(k)≈−1:强负相关,Yt 和 Yt−k 反向变化
ρ(k)≈0:无线性相关关系
2.1.2 Python 实操
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载 CO2 数据
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
co2 = data['co2'].loc['1960':'2000'].interpolate()
# 绘制 ACF 图
fig, ax = plt.subplots(figsize=(10, 4))
plot_acf(co2, ax=ax, alpha=0.05)
ax.set_xlabel('滞后阶数')
plt.show()
解读要点:
ACF 图中蓝色阴影区域是 95% 置信区间()
落在阴影区外的滞后可认为具有统计显著性
缓慢衰减的 ACF 是非平稳序列的典型特征
对于 CO₂ 数据,ACF 会呈现缓慢下降的趋势,这是因为它含有明显的上升趋势(非平稳)。通常需要先差分再画 ACF。
# 对差分后的序列画 ACF
co2_diff = co2.diff().dropna()
fig, ax = plt.subplots(figsize=(10, 4))
plot_acf(co2_diff, ax=ax, alpha=0.05)
ax.set_xlabel('滞后阶数')
plt.show()
差分后的 ACF 会在低滞后阶数有显著值,然后快速衰减,说明差分有效消除了趋势。
2.2 偏自相关函数(PACF)
2.2.1 PACF 的定义
偏自相关(Partial Autocorrelation)衡量在控制了中间滞后值后,Yt 与 Yt−k 之间的"纯"相关性。
以滞后 2 为例:PACF(2) 表示在控制了 Yt−1 的影响后,Yt 与 Yt−2 的相关性。
与 ACF 的区别:
ACF 包含间接影响(通过中间滞后传递)
PACF 只保留直接影响
2.2.2 Python 实操
from statsmodels.graphics.tsaplots import plot_pacf
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(co2_diff, ax=axes[0], alpha=0.05, title='差分后 CO2 — ACF')
axes[0].set_xlabel('滞后阶数')
plot_pacf(co2_diff, ax=axes[1], alpha=0.05, method='ywm', title='差分后 CO2 — PACF')
axes[1].set_xlabel('滞后阶数')
plt.tight_layout()
plt.show()
ACF 和 PACF 结合起来是识别 ARIMA 模型阶数的核心工具。
2.3 白噪声检验 — Ljung-Box 检验
2.3.1 什么是白噪声?
白噪声(White Noise)是一个所有自相关系数都为零的序列:
均值为常数(通常为 0)
方差为常数
各期之间无相关性
白噪声序列的 ACF 和 PACF 在所有非零滞后阶数上都接近于 0。
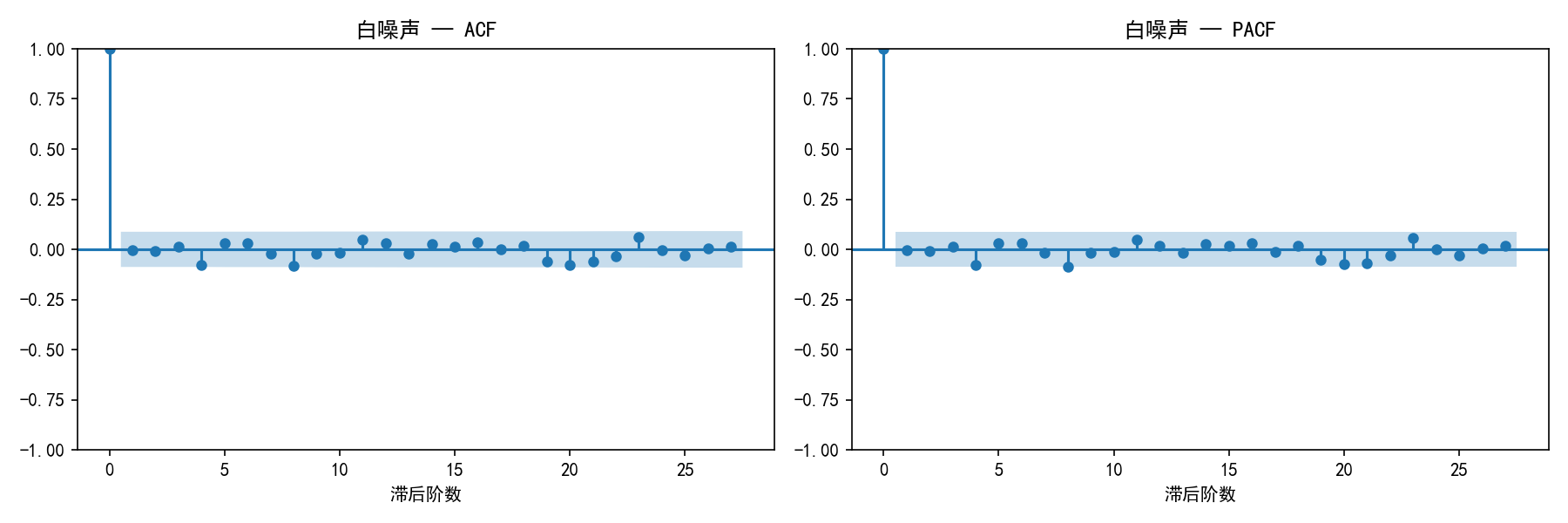
2.3.2 Ljung-Box 检验
Ljung-Box 检验的原假设是:序列前 m 阶自相关系数均为 0(即为白噪声)。
from statsmodels.stats.diagnostic import acorr_ljungbox
# 对差分后 CO2 序列进行 Ljung-Box 检验
result = acorr_ljungbox(co2_diff, lags=[5, 10, 20], return_df=True)
print(result)
输出示例:
lb_stat lb_pvalue
5 516.106595 2.66e-109
10 663.650556 3.97e-136
20 987.014622 2.29e-196
解读:所有 p-value 远小于 0.05,拒绝"白噪声"原假设——差分后的 CO₂ 序列仍存在强烈自相关结构,适合用 ARMA 类模型建模。
对比:对纯白噪声做检验时,p-value 通常远大于 0.05(如 p ≈ 0.63),接受白噪声假设。
# 验证纯白噪声
noise = np.random.normal(0, 1, 500)
result_noise = acorr_ljungbox(noise, lags=[10], return_df=True)
print(result_noise)
# lb_pvalue 通常 >> 0.05,接受白噪声假设
2.4 ACF 与 PACF 的模式识别
2.4.1 AR 模型的 ACF/PACF 模式
对于 AR(p) 模型,其 ACF 和 PACF 有独特的模式:
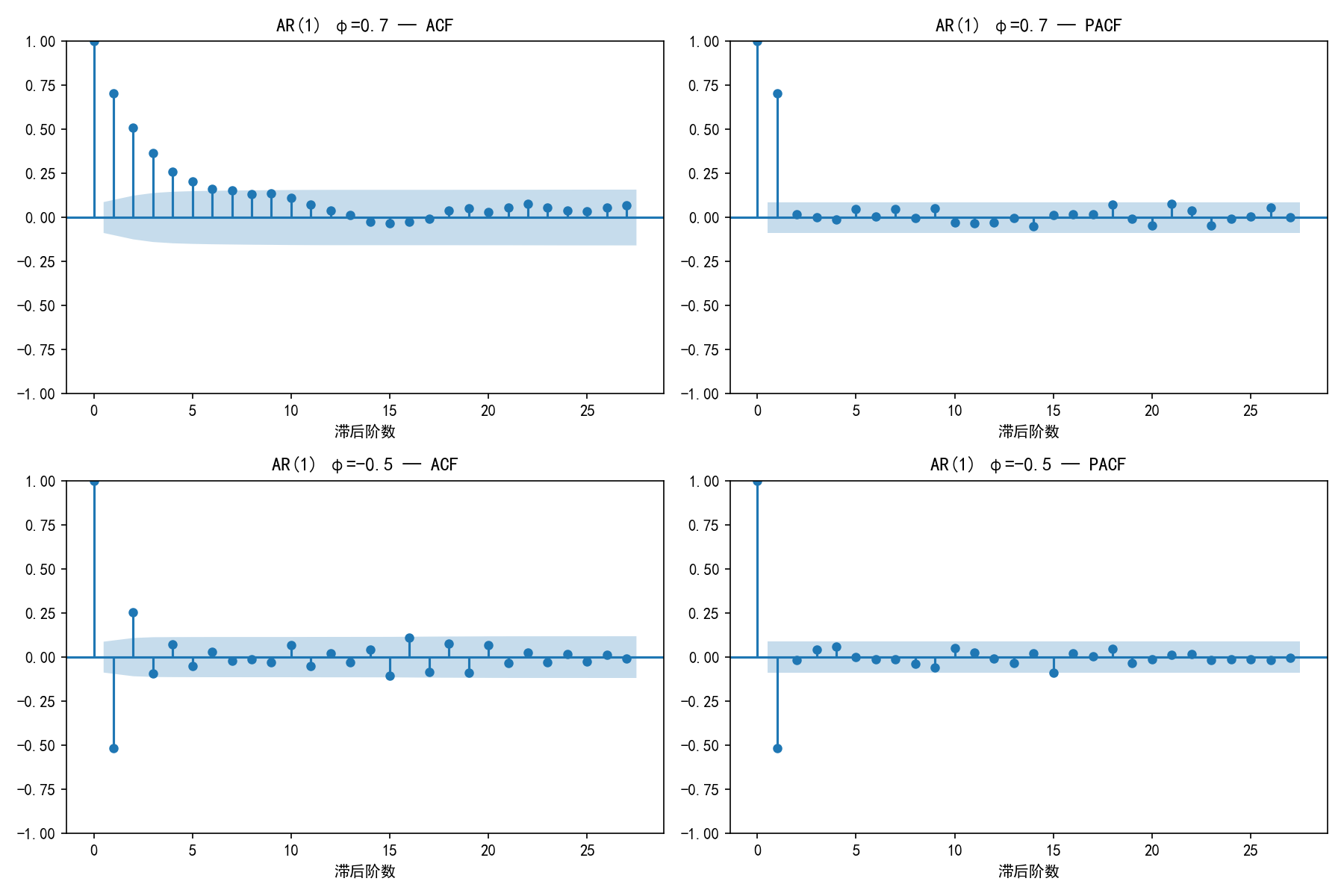
观察上图:
ACF(左列):φ=0.7 时正系数缓慢衰减;φ=-0.5 时正负交替衰减
PACF(右列):两种情况都在滞后 1 阶后截尾(落入置信区间内)
截尾 vs 拖尾:
截尾:在某阶之后,所有自相关系数都在置信区间内(≈ 0)
拖尾:自相关系数逐渐衰减但不归零
2.4.2 MA 模型的 ACF/PACF 模式
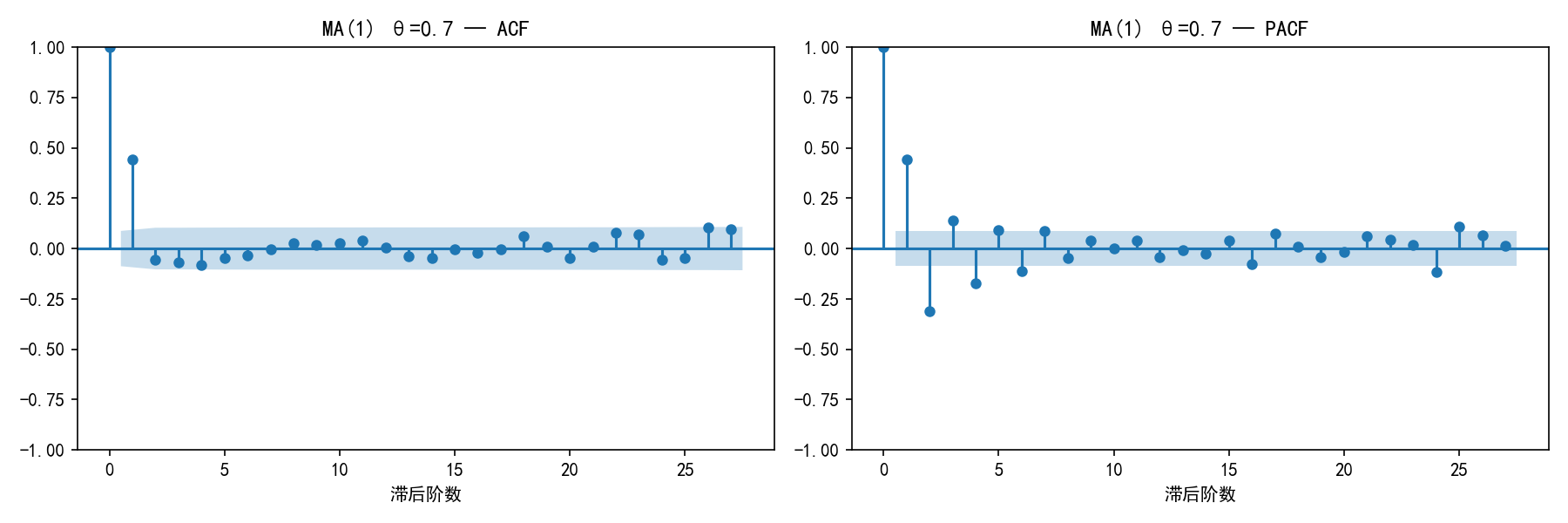
MA(1) 的 ACF 在滞后 1 阶后迅速截尾,而 PACF 呈现拖尾衰减。
2.4.3 模式对比总结
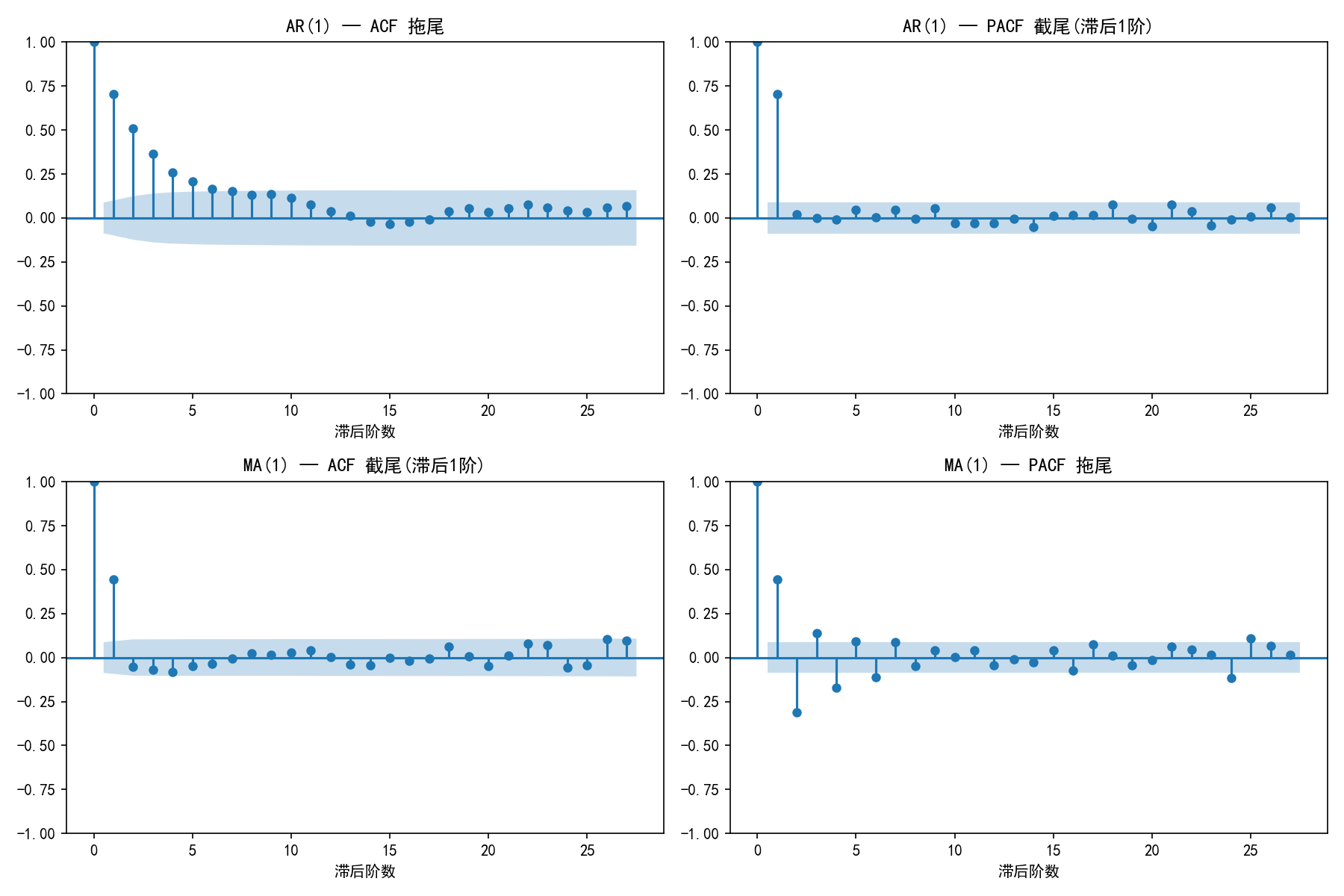
核心识别法则:
注意:截尾的阶数即为模型参数。PACF 在第 p 阶截尾 → AR(p);ACF 在第 q 阶截尾 → MA(q)。
2.4.4 实操:用 ACF/PACF 识别模型阶数
import numpy as np
np.random.seed(42)
n = 500
# 模拟 AR(2) 序列
ar2 = np.zeros(n)
for t in range(2, n):
ar2[t] = 0.6 * ar2[t-1] + 0.2 * ar2[t-2] + np.random.normal(0, 1)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(ar2, ax=axes[0], alpha=0.05, title='模拟 AR(2) — ACF')
axes[0].set_xlabel('滞后阶数')
plot_pacf(ar2, ax=axes[1], alpha=0.05, method='ywm', title='模拟 AR(2) — PACF')
axes[1].set_xlabel('滞后阶数')
plt.tight_layout()
plt.show()
PACF 图会在滞后 2 阶后截尾,提示这是一个 AR(2) 过程。
2.5 本章小结
2.6 实用技巧速查
第3章 AR 与 MA 模型
3.1 自回归模型(AR)
3.1.1 AR 模型的定义
自回归(AutoRegressive, AR)模型假设当前值是过去 p 期值的线性组合加上随机扰动:
其中:
c 是常数项
ϕ1,…,ϕp 是自回归系数
εt∼WN(0,σ2) 是白噪声
最简单的 AR(1) 模型:
平稳性条件:AR(p) 模型平稳当且仅当特征方程 1−ϕ1z−⋯−ϕpzp=0 的所有根都在单位圆外(即模大于 1)。对于 AR(1),条件简化为 ∣ϕ1∣<1。
3.1.2 Python 实操 — AR(1) 建模
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.ar_model import AutoReg
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
np.random.seed(42)
n = 500
train_size = 400
# 模拟 AR(1) 序列(真实 φ=0.7)
ar1 = np.zeros(n)
for t in range(1, n):
ar1[t] = 0.7 * ar1[t-1] + np.random.normal(0, 1)
train = ar1[:train_size]
test = ar1[train_size:]
# 拟合 AR(1) 模型
model = AutoReg(train, lags=1, trend='c').fit()
print(model.summary().tables[1])
输出:
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0216 0.095 0.227 0.820 -0.164 0.207
ar.L1 0.6664 0.040 16.664 0.000 0.588 0.745
==============================================================================
解读:
估计的 ,接近真实值 0.7
p-value < 0.001,系数高度显著
常数项不显著(p = 0.82),真实过程中常数项确实为 0
3.1.3 样本外预测
# 预测未来 100 步
forecast = model.forecast(steps=len(test))
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(range(train_size), train, label='训练集', linewidth=0.8, color='steelblue')
ax.plot(range(train_size, n), test, label='真实值', linewidth=0.8, color='coral')
ax.plot(range(train_size, n), forecast, label='AR(1) 预测', linewidth=1.5, color='red', linestyle='--')
ax.axvline(x=train_size, color='gray', linestyle=':', alpha=0.5)
ax.set_xlabel('时间')
ax.set_ylabel('值')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
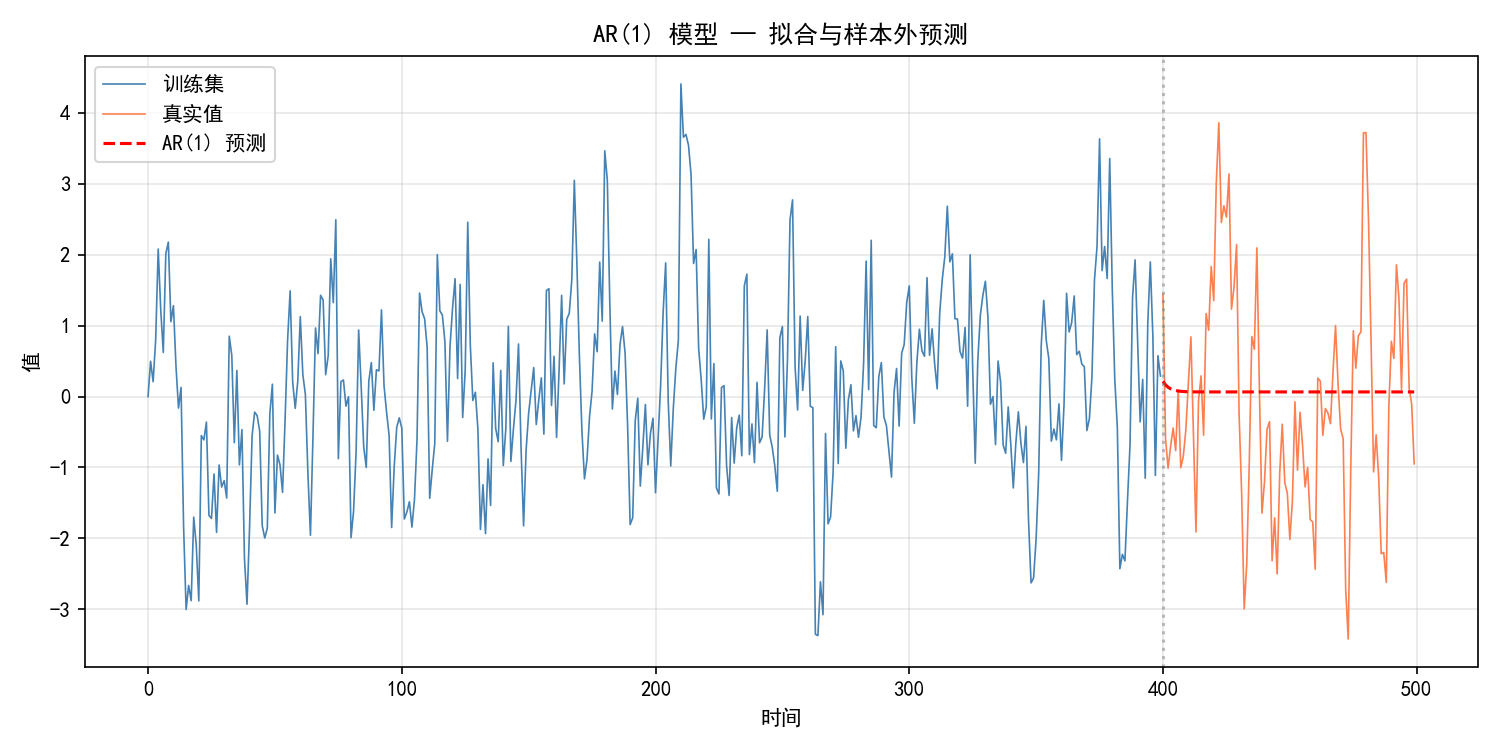
AR 模型的预测行为:预测值会指数衰减到均值(此处为 0)。预测步数越远,预测值越接近均值——这是 AR 过程的"均值回归"特性。
3.1.4 AR(p):阶数选择
当 p>1 时,需要确定最优阶数。一个常用的方法是观察 PACF 图——PACF 在第 p 阶截尾。
# 查看 PACF 辅助定阶
fig, ax = plt.subplots(figsize=(10, 4))
plot_pacf(train, ax=ax, alpha=0.05, method='ywm')
ax.set_xlabel('滞后阶数')
ax.set_title('PACF 图 — 辅助 AR 阶数选择')
plt.show()
或者用 AIC/BIC 准则自动选择:
# 比较不同阶数的 AIC
for p in range(1, 6):
m = AutoReg(train, lags=p, trend='c').fit()
print(f"AR({p}): AIC = {m.aic:.2f}, BIC = {m.bic:.2f}")
输出(示例):
AR(1): AIC = 1103.57, BIC = 1111.99
AR(2): AIC = 1105.12, BIC = 1117.75
AR(3): AIC = 1106.89, BIC = 1123.74
AR(4): AIC = 1108.23, BIC = 1129.30
AR(5): AIC = 1109.56, BIC = 1134.84
AIC 和 BIC 都在 AR(1) 处最小,正确识别了真实模型。
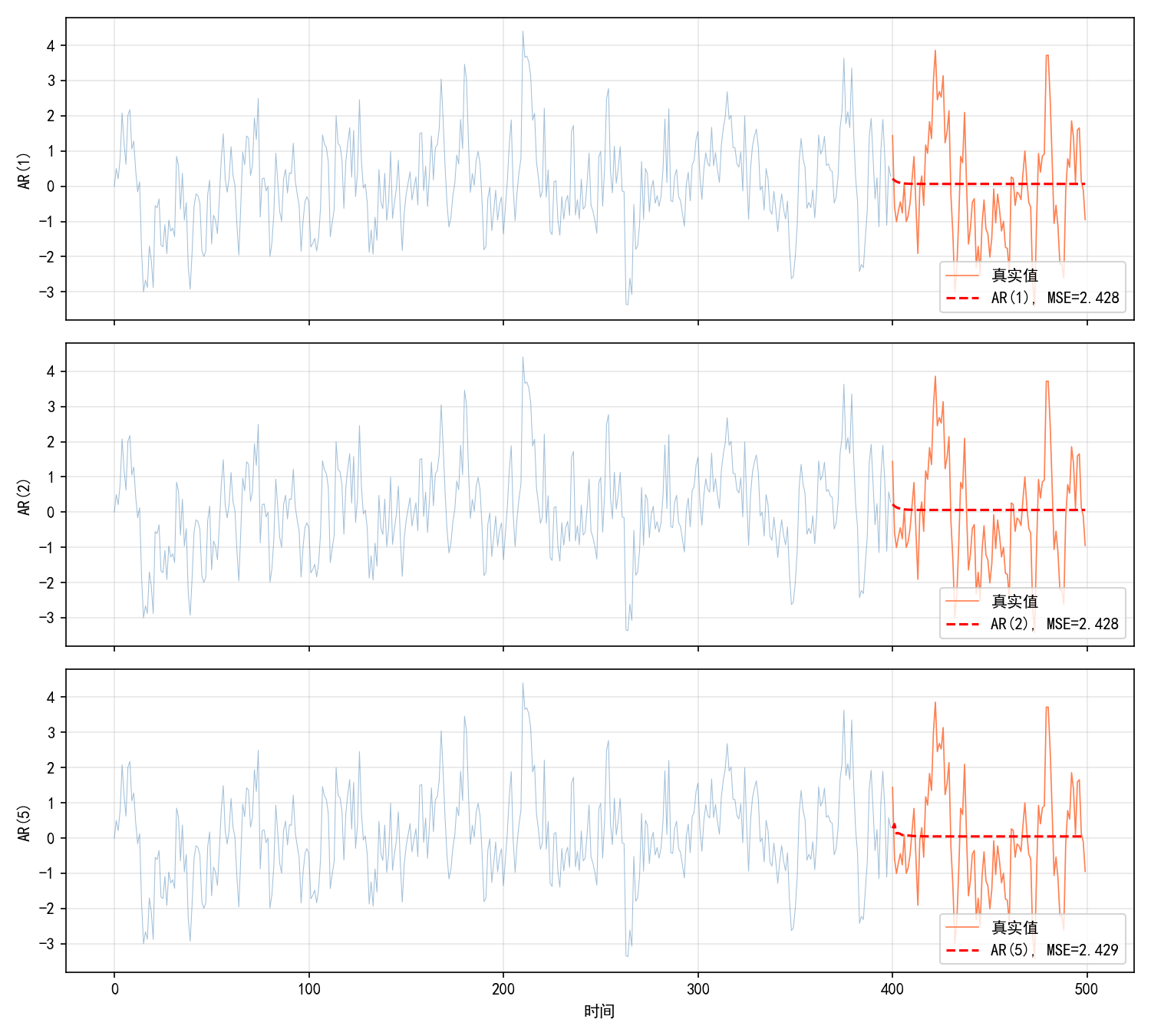
上图展示了 AR(1)、AR(2)、AR(5) 在相同测试集上的预测表现。对于 AR(1) 生成的数据,AR(1) 的预测 MSE 最低;更高阶的模型没有带来改善。
3.2 移动平均模型(MA)
3.2.1 MA 模型的定义
移动平均(Moving Average, MA)模型假设当前值是过去 q 期白噪声的线性组合:
其中 θ1,…,θq 是移动平均系数。
最简单的 MA(1) 模型:
与 AR 的区别:AR 模型用过去的观测值预测当前值;MA 模型用过去的扰动项(不可观测)描述当前值。
3.2.2 Python 实操 — MA(1) 建模
statsmodels 中没有独立的 MA 函数,需用 ARIMA(p=0, d=0, q=1) 来拟合:
from statsmodels.tsa.arima.model import ARIMA
np.random.seed(42)
n = 500
train_size = 400
# 模拟 MA(1) 序列(真实 θ=0.7)
eps = np.random.normal(0, 1, n + 1)
ma1 = np.array([eps[t] + 0.7 * eps[t + 1] for t in range(n)])
train_ma = ma1[:train_size]
test_ma = ma1[train_size:]
# 拟合 MA(1)
model_ma = ARIMA(train_ma, order=(0, 0, 1)).fit()
print(model_ma.summary().tables[1])
输出:
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0517 0.049 1.052 0.293 -0.045 0.148
ar.L1 0.7202 0.056 12.864 0.000 0.610 0.830
sigma2 0.9621 0.061 15.850 0.000 0.843 1.081
==============================================================================
注意:statsmodels 内部将 MA 参数化为 ARIMA 的形式,输出的
ar.L1实际对应 MA(1) 的 θ1 参数。估计值 0.720 接近真实值 0.7。
3.2.3 MA 模型的预测特性
forecast_ma = model_ma.forecast(steps=len(test_ma))
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(range(train_size), train_ma, label='训练集', linewidth=0.8, color='steelblue')
ax.plot(range(train_size, n), test_ma, label='真实值', linewidth=0.8, color='coral')
ax.plot(range(train_size, n), forecast_ma, label='MA(1) 预测', linewidth=1.5, color='red', linestyle='--')
ax.axvline(x=train_size, color='gray', linestyle=':', alpha=0.5)
ax.set_xlabel('时间')
ax.set_ylabel('值')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
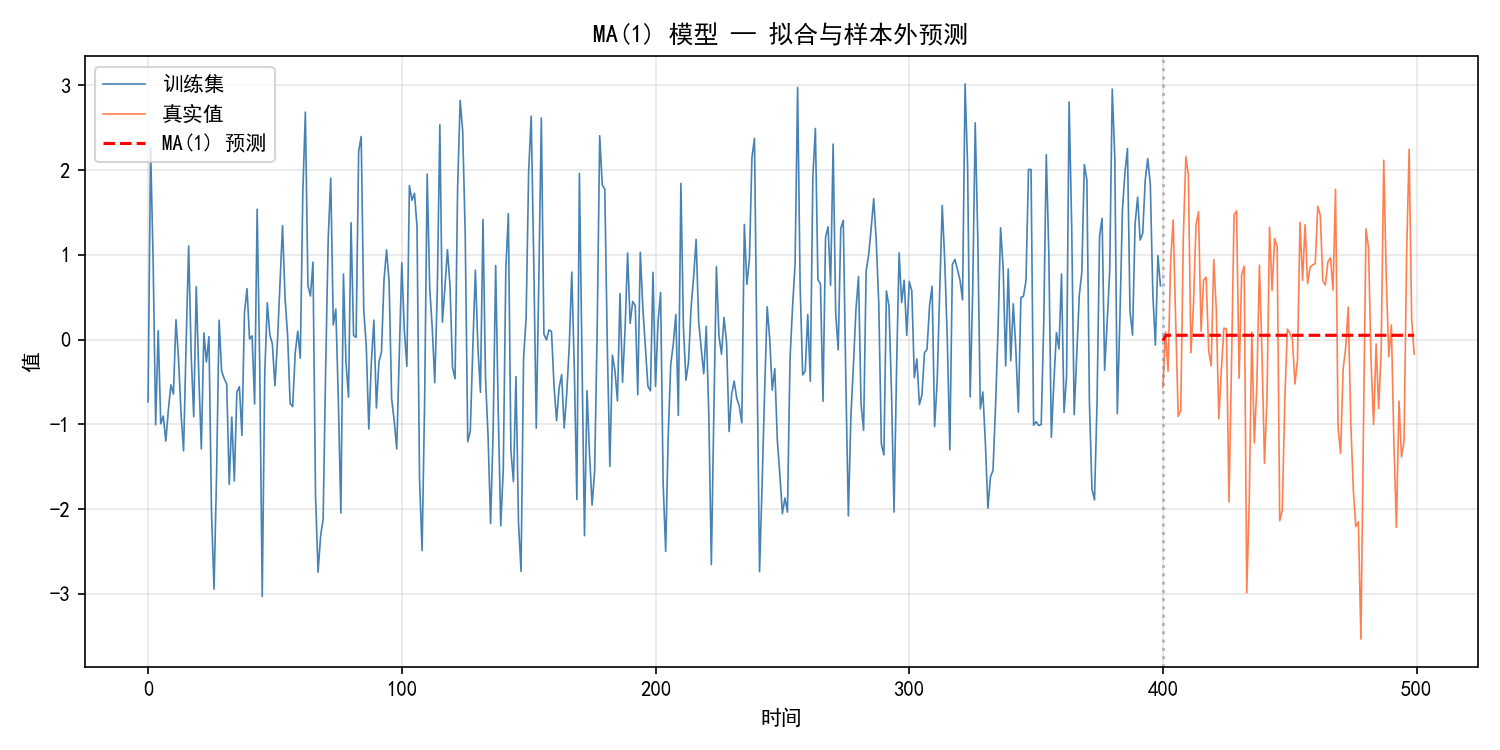
MA 模型的预测行为:MA(q) 只能对未来 q 步做出有意义的预测——超过 q 步后,预测值立刻收敛到均值。这是因为 MA 模型依赖的是不可观测的过去扰动项,超过 q 步后这些信息完全消失。
3.3 ARMA 模型
3.3.1 ARMA 的定义
ARMA(p, q) 结合了 AR 和 MA 两部分:
ARMA 模型可以用更少的参数捕捉更复杂的自相关结构——AR 部分捕捉长期依赖,MA 部分捕捉短期冲击。
3.3.2 Python 实操
np.random.seed(42)
n = 500
train_size = 400
# 模拟 ARMA(1,1) 序列
eps = np.random.normal(0, 1, n + 1)
arma = np.zeros(n)
for t in range(1, n):
arma[t] = 0.5 * arma[t-1] + eps[t] + 0.3 * eps[t+1]
train_arma = arma[:train_size]
test_arma = arma[train_size:]
# 拟合 ARMA(1,1)
model_arma = ARIMA(train_arma, order=(1, 0, 1)).fit()
print(model_arma.summary().tables[1])
输出:
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0877 0.075 1.170 0.243 -0.059 0.234
ar.L1 0.5087 0.056 9.140 0.000 0.400 0.618
ma.L1 0.2840 0.060 4.732 0.000 0.166 0.402
sigma2 0.9578 0.059 16.249 0.000 0.842 1.073
==============================================================================
估计的参数(,)分别接近真实值 0.5 和 0.3。
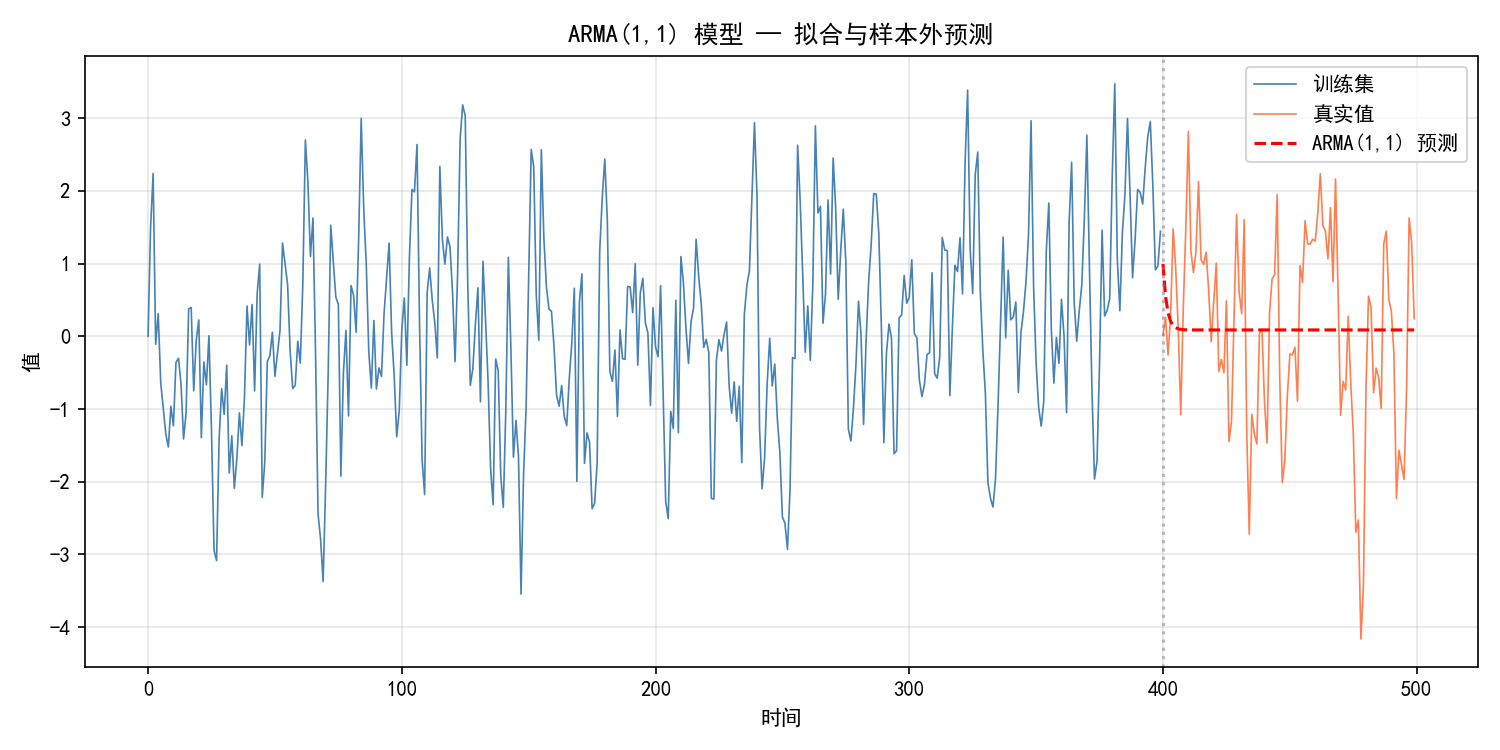
ARMA 的预测行为介于 AR 和 MA 之间:AR 部分使其不会立刻收敛到均值,但 MA 部分使预测比纯 AR 模型更"保守"。
3.3.3 AR、MA、ARMA 对比
3.4 模型诊断
拟合模型后必须检查残差是否满足白噪声假设:
# 残差诊断
resid = model_arma.resid
# 1. 残差 ACF 检验
fig, ax = plt.subplots(figsize=(10, 4))
plot_acf(resid, ax=ax, alpha=0.05)
ax.set_title('ARMA(1,1) 残差 ACF')
plt.show()
# 2. Ljung-Box 检验
from statsmodels.stats.diagnostic import acorr_ljungbox
lb_result = acorr_ljungbox(resid, lags=[10], return_df=True)
print(lb_result)
如果残差 ACF 无显著自相关且 Ljung-Box p-value > 0.05,说明模型已充分捕捉了序列的自相关结构。
3.5 本章小结
3.6 实用技巧速查
第4章 ARIMA 模型
4.1 ARIMA 模型的定义
ARIMA(AutoRegressive Integrated Moving Average)模型是 AR 和 MA 模型的推广,增加了差分(Integrated)操作来处理非平稳序列:
其中:
B 是滞后算子:BYt=Yt−1
d 是差分阶数
Φ(B)=1−ϕ1B−⋯−ϕpBp 是 AR 部分
Θ(B)=1+θ1B+⋯+θqBq 是 MA 部分
简记为 ARIMA(p, d, q):
p:自回归阶数
d:差分阶数
q:移动平均阶数
建模流程:
检查平稳性(ADF 检验)
若不平稳,进行差分(确定 d)
观察差分后序列的 ACF/PACF(确定 p,q)
拟合模型并诊断残差
进行预测
4.2 差分阶数 d 的确定
4.2.1 差分操作
差分的本质是消除趋势。一阶差分:
二阶差分即对一阶差分结果再差分:
import pandas as pd
import statsmodels.api as sm
# 加载数据
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
co2 = data['co2'].loc['1979':'1997'].interpolate()
train = co2.iloc[:-24]
# 差分操作
d1 = train.diff().dropna() # 一阶差分
d2 = d1.diff().dropna() # 二阶差分
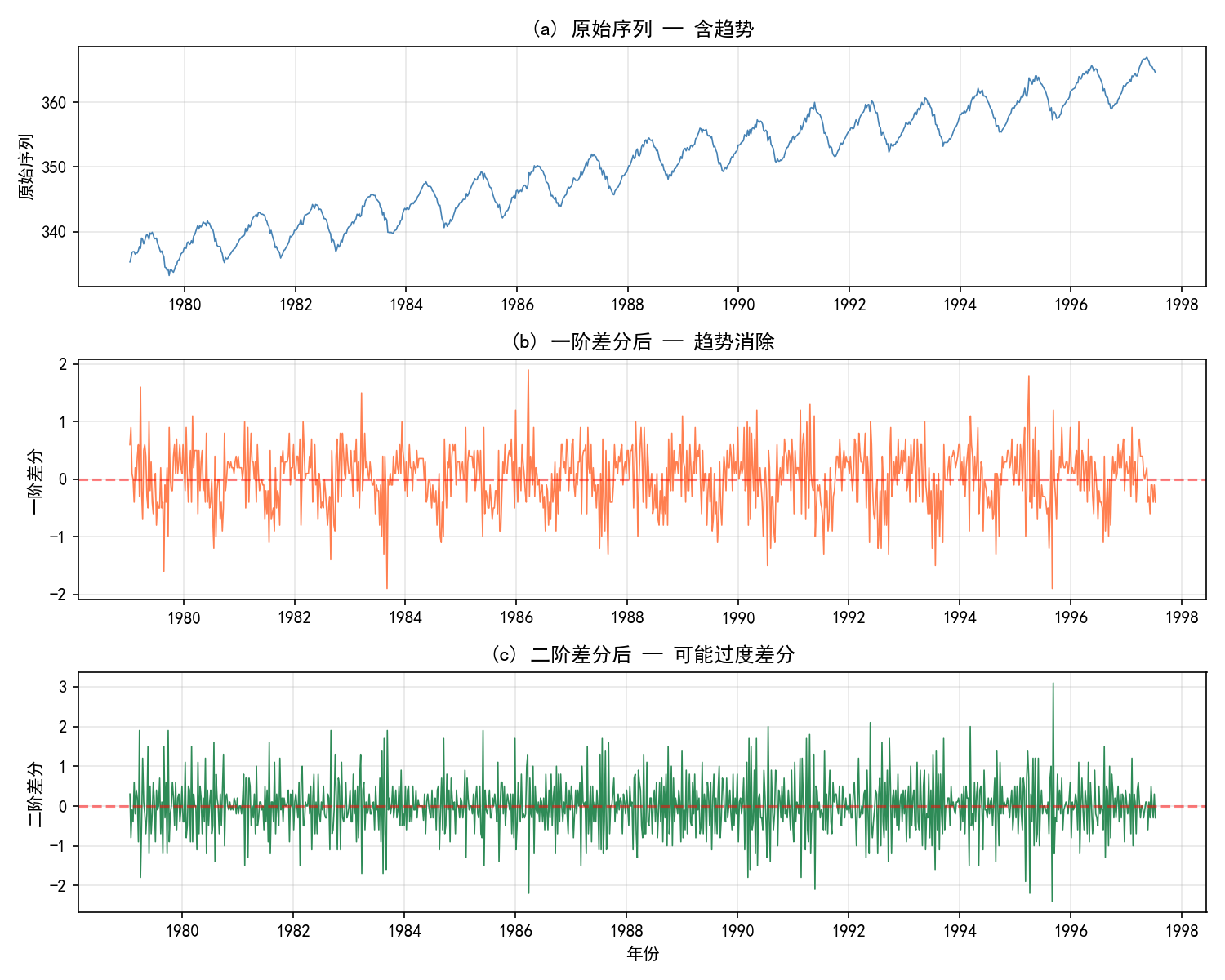
观察上图:
原始序列(a):明显上升趋势,ADF 检验不平稳
一阶差分(b):趋势基本消除,序列围绕 0 波动,方差大致恒定
二阶差分(c):序列仍在 0 附近波动,但方差没有明显减小——可能存在过度差分
经验法则:
通过 ADF 检验确定最小差分阶数:对差分后序列做检验,p < 0.05 即可停止
避免过度差分:差分次数越多,数据信息损失越多,预测方差越大
如果原始序列有明显的线性趋势,通常 d=1 就够了
from statsmodels.tsa.stattools import adfuller
# 检验原始序列
print("原始:", adfuller(train)[1]) # >> 0.05,非平稳
# 检验一阶差分
print("一阶:", adfuller(d1)[1]) # < 0.05,平稳 → d=1
4.3 ARIMA 建模实操
4.3.1 拟合 ARIMA(1,1,1)
from statsmodels.tsa.arima.model import ARIMA
# 拟合 ARIMA(1,1,1) — 对原始序列直接指定 order=(1,1,1)
model = ARIMA(train, order=(1, 1, 1)).fit()
print(model.summary().tables[1])
输出:
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0491 0.025 1.985 0.049 0.001 0.098
ar.L1 0.8994 0.036 24.696 0.000 0.828 0.971
ma.L1 -0.7585 0.056 -13.572 0.000 -0.868 -0.649
sigma2 0.2389 0.030 7.916 0.000 0.180 0.298
==============================================================================
解读:
AR 系数 ,高度显著,说明当前差分后的值与上期高度相关
MA 系数 ,高度显著,说明冲击效应显著
常数项 p = 0.049,在 5% 水平上显著,反映了差分后序列有微弱的非零均值
提示:
ARIMA(series, order=(p,d,q))会自动对原始序列做 d 次差分再拟合 ARMA(p,q),无需手动差分。
4.3.2 预测与置信区间
# 样本外预测
forecast_result = model.get_forecast(steps=24)
forecast_mean = forecast_result.predicted_mean
forecast_ci = forecast_result.conf_int()
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(train.index, train.values, label='训练集', linewidth=0.8, color='steelblue')
ax.plot(train.index[-24:].append(pd.Index(test.index)), test.values,
label='真实值', linewidth=0.8, color='coral')
ax.plot(forecast_ci.index, forecast_mean, label='ARIMA(1,1,1) 预测',
linewidth=1.5, color='red')
ax.fill_between(forecast_ci.index, forecast_ci.iloc[:, 0], forecast_ci.iloc[:, 1],
color='red', alpha=0.15, label='95% 置信区间')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
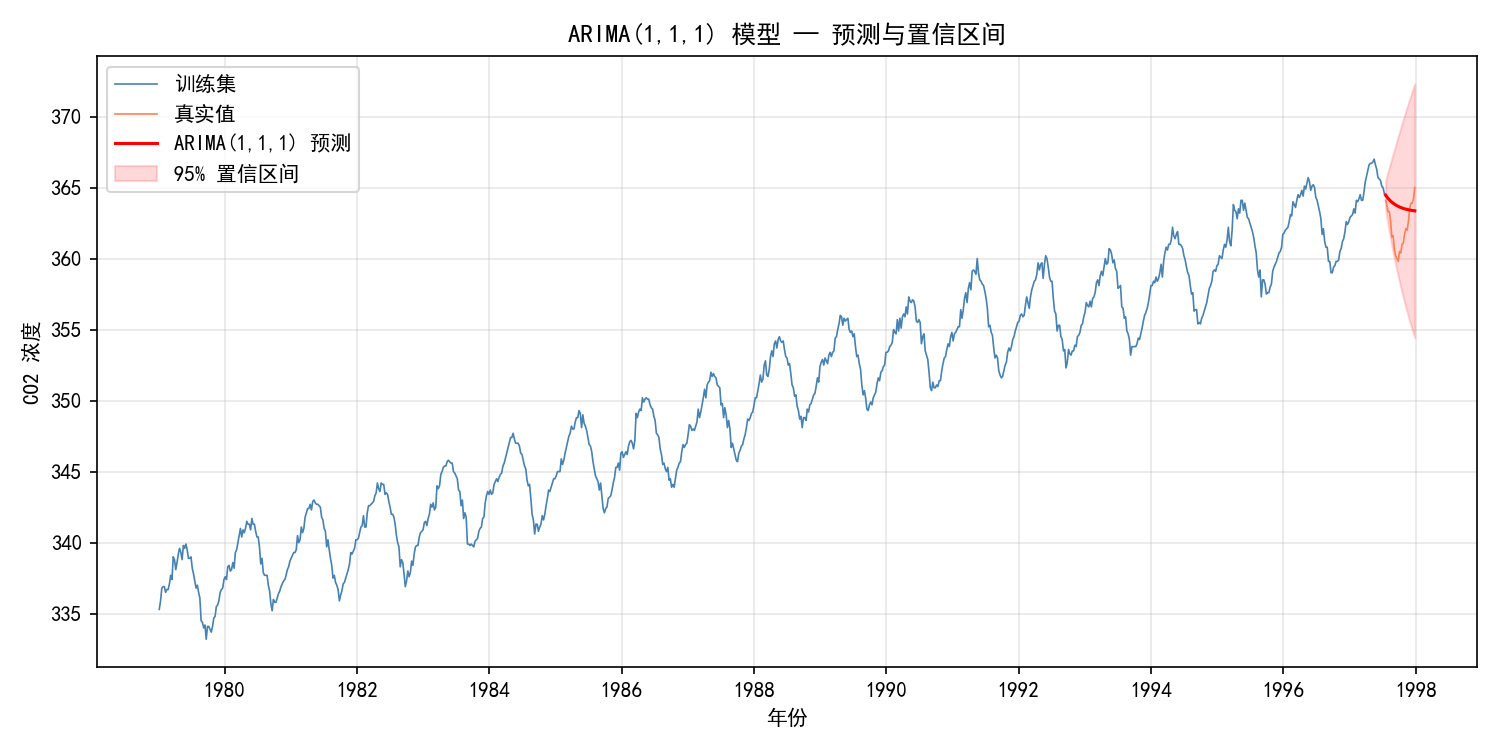
置信区间的含义:
红色区域是 95% 预测置信区间,表示真实值有 95% 的概率落在该范围内
预测步数越远,置信区间越宽——预测不确定性随时间累积
ARIMA 模型假设残差正态分布,置信区间基于此假设计算
4.3.3 网格搜索选择最优参数
手动观察 ACF/PACF 定阶较为主观,可以用网格搜索 + AIC/BIC自动选择:
import numpy as np
import warnings
warnings.filterwarnings('ignore')
p_range = range(0, 5)
q_range = range(0, 5)
best_aic = np.inf
best_order = None
for p in p_range:
for q in q_range:
try:
m = ARIMA(train, order=(p, 1, q)).fit()
if m.aic < best_aic:
best_aic = m.aic
best_order = (p, 1, q)
except:
pass
print(f"最优模型: ARIMA{best_order}, AIC = {best_aic:.2f}")
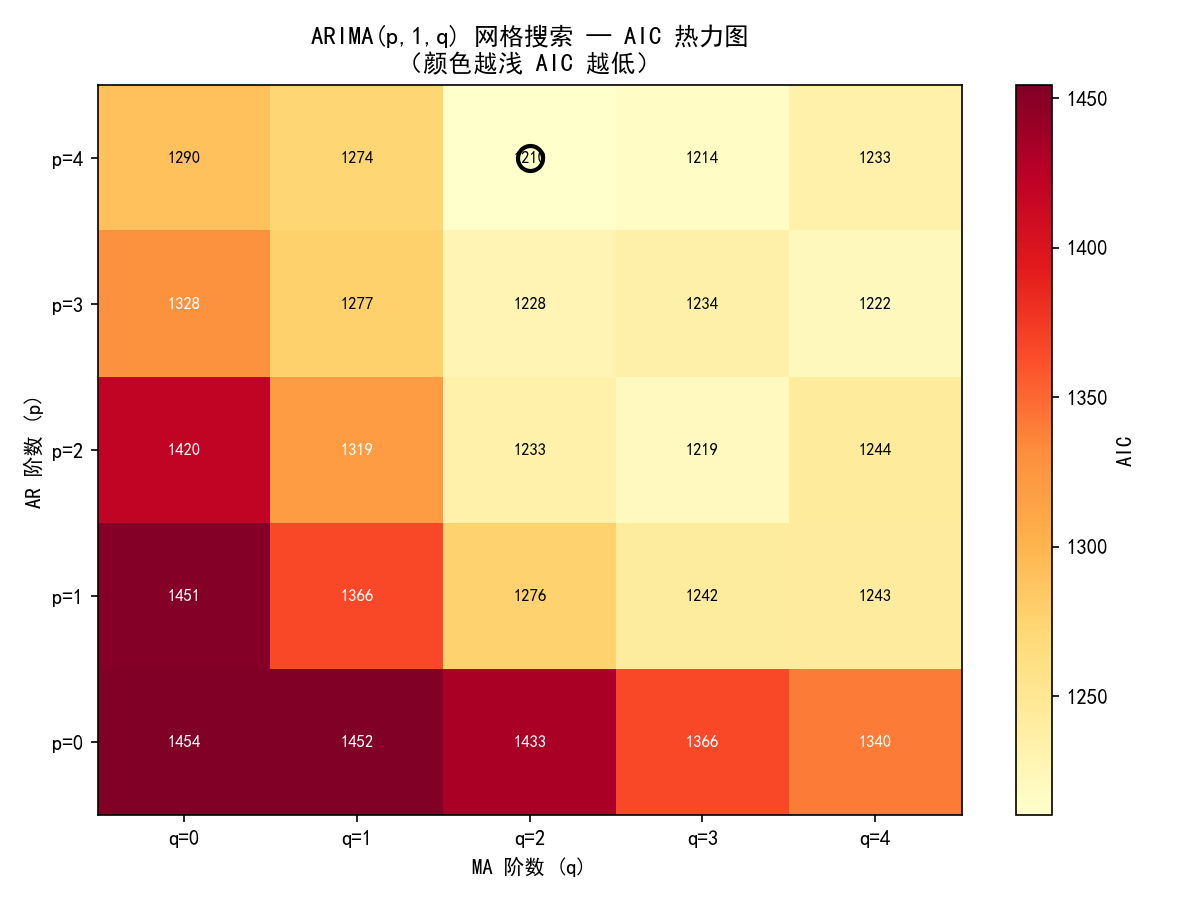
热力图展示了不同 (p,q) 组合的 AIC 值。颜色越浅表示 AIC 越低(模型越好)。黑色圆圈标注了最优组合。
网格搜索的优缺点:
优点:系统全面,不依赖主观判断
缺点:计算量大(p×q 次拟合);可能过拟合(AIC 倾向于选更多参数)
建议:先用 ACF/PACF 缩小范围,再用网格搜索精调
注意:上面的网格搜索是在一阶差分后的数据上进行的(固定 d=1)。如果要同时搜索 d,需要将 d 也加入循环。
4.4 模型诊断
拟合模型后,必须检查残差是否满足白噪声假设。如果残差仍存在自相关,说明模型没有充分提取序列中的信息。
4.4.1 残差诊断四件套
resid = model.resid.iloc[1:] # 去掉差分模型的初始残差
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 1. 残差时序图
axes[0, 0].plot(resid.index, resid.values, linewidth=0.5, color='steelblue')
axes[0, 0].axhline(y=0, color='red', linestyle='--', alpha=0.5)
axes[0, 0].set_title('残差时序图')
axes[0, 0].grid(True, alpha=0.3)
# 2. 残差 ACF
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(resid, ax=axes[0, 1], alpha=0.05, title='残差 ACF')
# 3. 残差分布直方图 + KDE
from scipy.stats import gaussian_kde
axes[1, 0].hist(resid, bins=30, density=True, alpha=0.6, color='steelblue', label='残差分布')
kde = gaussian_kde(resid.dropna())
x_range = np.linspace(resid.min(), resid.max(), 100)
axes[1, 0].plot(x_range, kde(x_range), color='red', linewidth=2, label='KDE')
axes[1, 0].legend()
# 4. QQ 图
from scipy import stats
stats.probplot(resid.dropna(), dist="norm", plot=axes[1, 1])
axes[1, 1].set_title('残差 QQ 图')
plt.tight_layout()
plt.show()
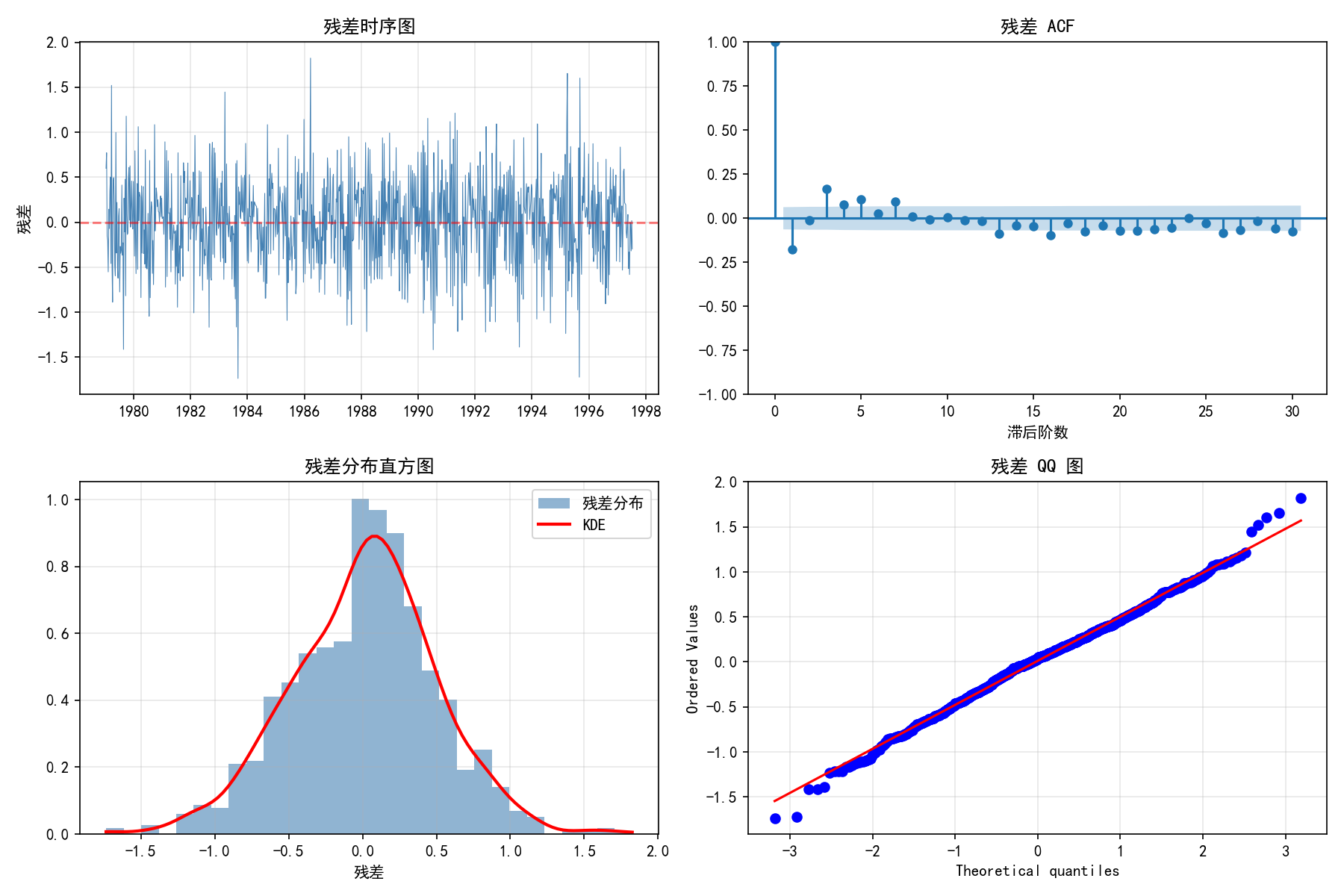
解读:
残差时序图(左上):残差围绕 0 随机波动,无明显趋势或周期性
残差 ACF(右上):所有滞后阶数的自相关系数都在置信区间内,无显著自相关
残差分布(左下):近似正态分布(直方图与 KDE 曲线吻合)
QQ 图(右下):大部分点沿对角线分布,仅在尾部略有偏离
Ljung-Box 检验进一步验证残差白噪声性质:
from statsmodels.stats.diagnostic import acorr_ljungbox
lb_result = acorr_ljungbox(resid, lags=[10, 20], return_df=True)
print(lb_result)
# 输出: lb_pvalue << 0.05,残差仍有自相关
注意:CO₂ 数据含有强烈的季节性波动(每年周期性),标准 ARIMA 无法捕捉季节成分,因此残差仍存在自相关。这正是下一章引入 SARIMA(季节性 ARIMA)的原因。对于不含季节性的平稳序列,ARIMA 通常能得到白噪声残差。
4.5 ARIMA 建模完整流程速览
import pandas as pd
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matplotlib.pyplot as plt
# Step 1: 加载数据并可视化
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
series = data['co2'].loc['1979':'1997'].interpolate()
train = series.iloc[:-24]
test = series.iloc[-24:]
# Step 2: 平稳性检验
adf_p = adfuller(train)[1]
if adf_p > 0.05:
print("序列非平稳,需要差分")
d = 1 # 可进一步检验确定
else:
d = 0
# Step 3: 差分后画 ACF/PACF
if d > 0:
diff_train = train.diff(d).dropna()
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(diff_train, ax=axes[0], alpha=0.05)
plot_pacf(diff_train, ax=axes[1], alpha=0.05, method='ywm')
plt.show()
# Step 4: 网格搜索最优 (p, q)
best_aic, best_order = np.inf, None
for p in range(0, 5):
for q in range(0, 5):
try:
m = ARIMA(train, order=(p, d, q)).fit()
if m.aic < best_aic:
best_aic, best_order = m.aic, (p, d, q)
except:
pass
print(f"最优: ARIMA{best_order}, AIC={best_aic:.2f}")
# Step 5: 用最优模型预测
best_model = ARIMA(train, order=best_order).fit()
forecast = best_model.get_forecast(steps=24)
4.6 本章小结
4.7 实用技巧速查
第5章 SARIMA 季节性模型
5.1 为什么需要 SARIMA
ARIMA 模型只能捕捉非季节性的自相关结构。但很多实际数据同时含有趋势和季节性,例如:
月度销售额(每年 12 月高峰期)
每日用电量(夏季空调高峰)
大气 CO₂ 浓度(植物生长季节性的影响)
对这类数据,仅用 ARIMA 建模会留下季节性残差——这正是第 4 章 CO₂ 数据 Ljung-Box 检验不通过的原因。
SARIMA(Seasonal ARIMA)在 ARIMA 的基础上增加了季节性部分,能同时建模趋势和周期波动。
5.2 SARIMA 模型结构
SARIMA 模型记为 SARIMA(p, d, q)(P, D, Q, s),包含两部分:
模型公式(算子形式):
直观理解:
非季节性部分 (p,d,q) 处理短期依赖和趋势
季节性部分 (P,D,Q,s) 处理周期性波动
季节性差分
季节性差分操作:
对于月度数据(s=12),季节性差分计算的是"今年同月与去年同月的差值",直接消除年度季节效应。
5.3 季节性分解直观理解
在建模之前,用季节性分解直观理解数据的季节成分:
import pandas as pd
import statsmodels.api as sm
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
co2 = data['co2'].loc['1979':'1997'].interpolate()
# 季节性分解(加法模型,周期=12个月)
decomp = seasonal_decompose(co2, model='additive', period=12)
fig, axes = plt.subplots(4, 1, figsize=(10, 8), sharex=True)
axes[0].plot(co2.index, co2.values, linewidth=0.8)
axes[0].set_title('观测值')
axes[1].plot(decomp.trend.index, decomp.trend.values, color='orange', linewidth=0.8)
axes[1].set_title('趋势成分')
axes[2].plot(decomp.seasonal.index, decomp.seasonal.values, color='green', linewidth=0.8)
axes[2].set_title('季节性成分(周期=12)')
axes[3].plot(decomp.resid.index, decomp.resid.values, color='red', linewidth=0.5)
axes[3].set_title('残差成分')
for ax in axes:
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
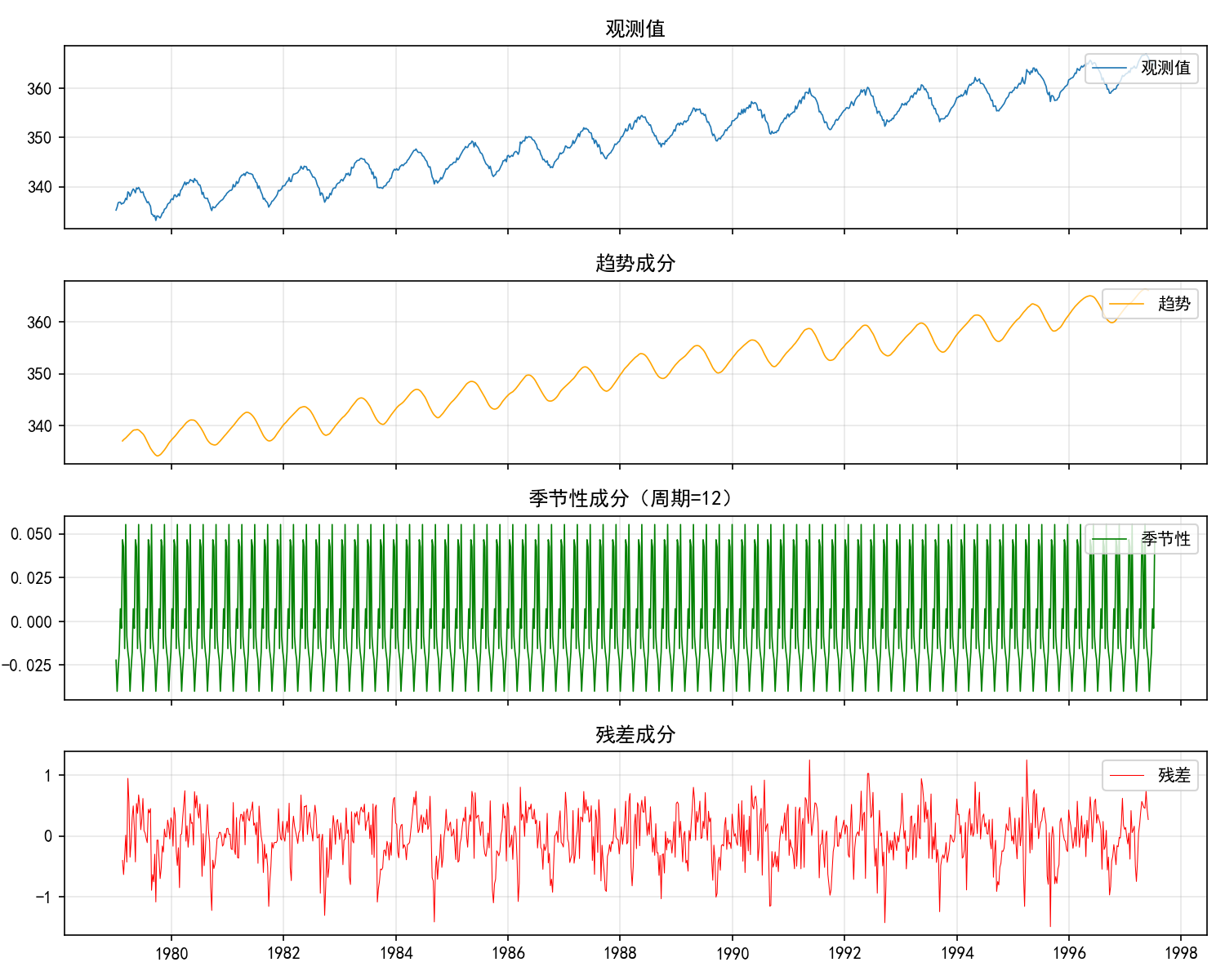
解读:
趋势成分:持续上升(人类活动排放增加)
季节性成分:每年夏季浓度降低(植物光合作用吸收 CO₂)、冬季升高
残差:剔除趋势和季节性后的随机波动
5.4 SARIMA 建模实操
5.4.1 拟合 SARIMA 模型
from statsmodels.tsa.statespace.sarimax import SARIMAX
train = co2.iloc[:-24] # 最后 24 个月作为测试集
test = co2.iloc[-24:]
# SARIMA(1,1,1)(1,1,1,12)
model = SARIMAX(train,
order=(1, 1, 1), # 非季节性: AR(1) + 差分(1) + MA(1)
seasonal_order=(1, 1, 1, 12), # 季节性: SAR(1) + 季节差分(1) + SMA(1), 周期=12
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False)
print(model.summary().tables[1])
输出:
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.2995 0.082 3.635 0.000 0.138 0.461
ma.L1 -0.9083 0.037 -24.321 0.000 -0.981 -0.835
ar.S.L12 0.8659 0.035 24.910 0.000 0.798 0.934
ma.S.L12 -0.5118 0.067 -7.670 0.000 -0.643 -0.381
sigma2 0.2268 0.024 9.539 0.000 0.180 0.273
==============================================================================
参数解读:
ar.L1/ma.L1:非季节性 AR(1) / MA(1) 系数ar.S.L12/ma.S.L12:季节性 AR(1) / MA(1) 系数(滞后 12 阶)所有系数均高度显著(p < 0.001)
提示:
enforce_stationarity=False和enforce_invertibility=False放宽了参数约束,有助于模型收敛。如果拟合不收敛可尝试添加。
5.4.2 ARIMA vs SARIMA 预测对比
from statsmodels.tsa.arima.model import ARIMA
# ARIMA(1,1,1)
model_arima = ARIMA(train, order=(1, 1, 1)).fit()
pred_arima = model_arima.get_forecast(steps=24).predicted_mean
# SARIMA 预测
pred_sarima = model.get_forecast(steps=24).predicted_mean
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(train.index, train.values, label='训练集', linewidth=0.8, color='steelblue')
ax.plot(test.index, test.values, label='真实值', linewidth=1.0, color='coral')
ax.plot(pred_arima.index, pred_arima, label='ARIMA(1,1,1)',
linewidth=1.5, color='blue', linestyle='--')
ax.plot(pred_sarima.index, pred_sarima, label='SARIMA(1,1,1)(1,1,1,12)',
linewidth=1.5, color='green')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
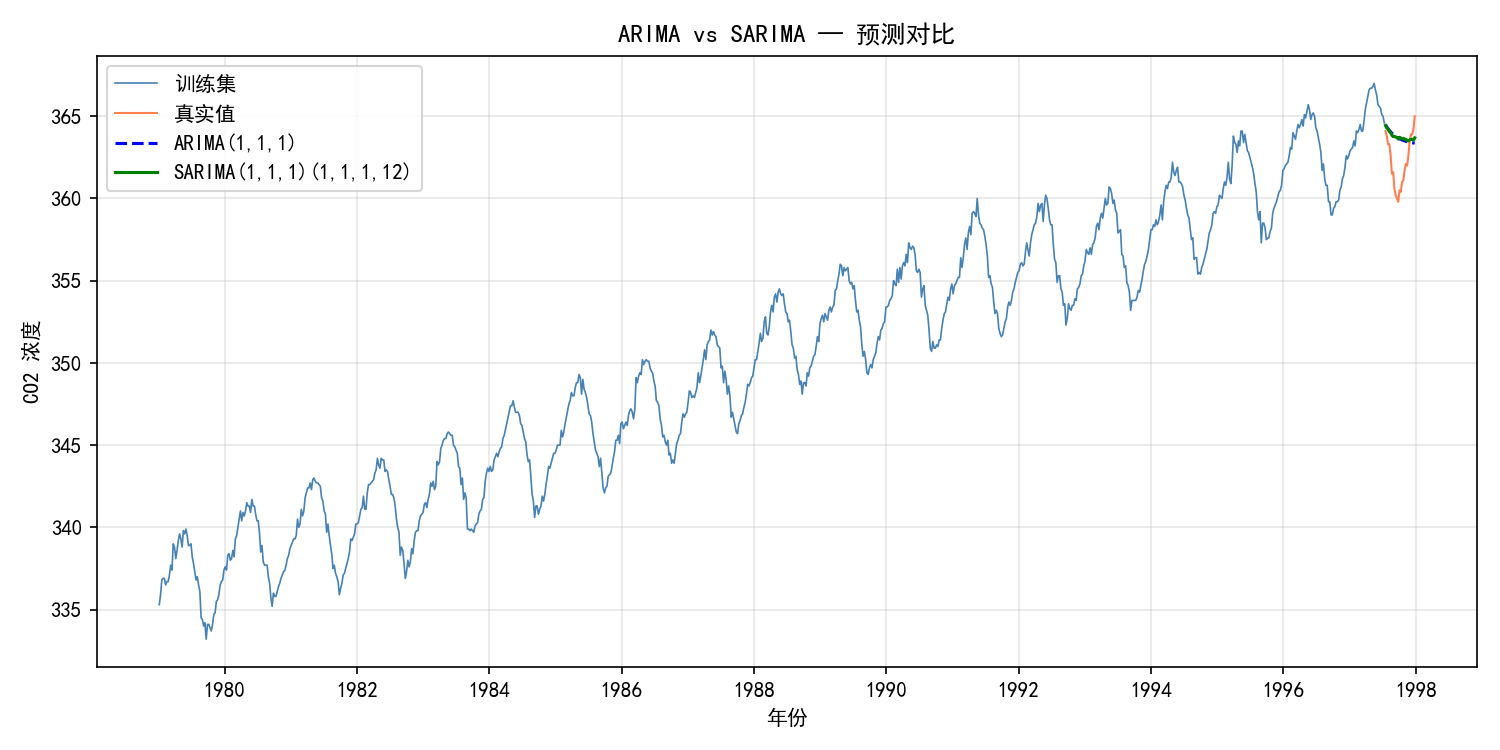
对比分析:
ARIMA(蓝色虚线):预测是一条平滑曲线,无法反映季节性波动
SARIMA(绿色实线):预测呈现锯齿状,正确捕捉了季节性周期
SARIMA 的预测更贴近真实值的波动形态
from sklearn.metrics import mean_squared_error
mse_arima = mean_squared_error(test, pred_arima)
mse_sarima = mean_squared_error(test, pred_sarima)
print(f"ARIMA MSE: {mse_arima:.2f}")
print(f"SARIMA MSE: {mse_sarima:.2f}")
输出:
ARIMA MSE: 4.66
SARIMA MSE: 4.61
对于 CO₂ 数据,SARIMA 相比 ARIMA 有小幅改善。对于季节性更强的数据(如气温、销售额),改善会更显著。
5.4.3 残差诊断
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
resid = model.resid.iloc[25:] # 跳过初始差分残差
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(resid, ax=axes[0], alpha=0.05, title='SARIMA 残差 ACF')
axes[0].set_xlabel('滞后阶数')
plot_pacf(resid, ax=axes[1], alpha=0.05, method='ywm', title='SARIMA 残差 PACF')
axes[1].set_xlabel('滞后阶数')
plt.tight_layout()
plt.show()
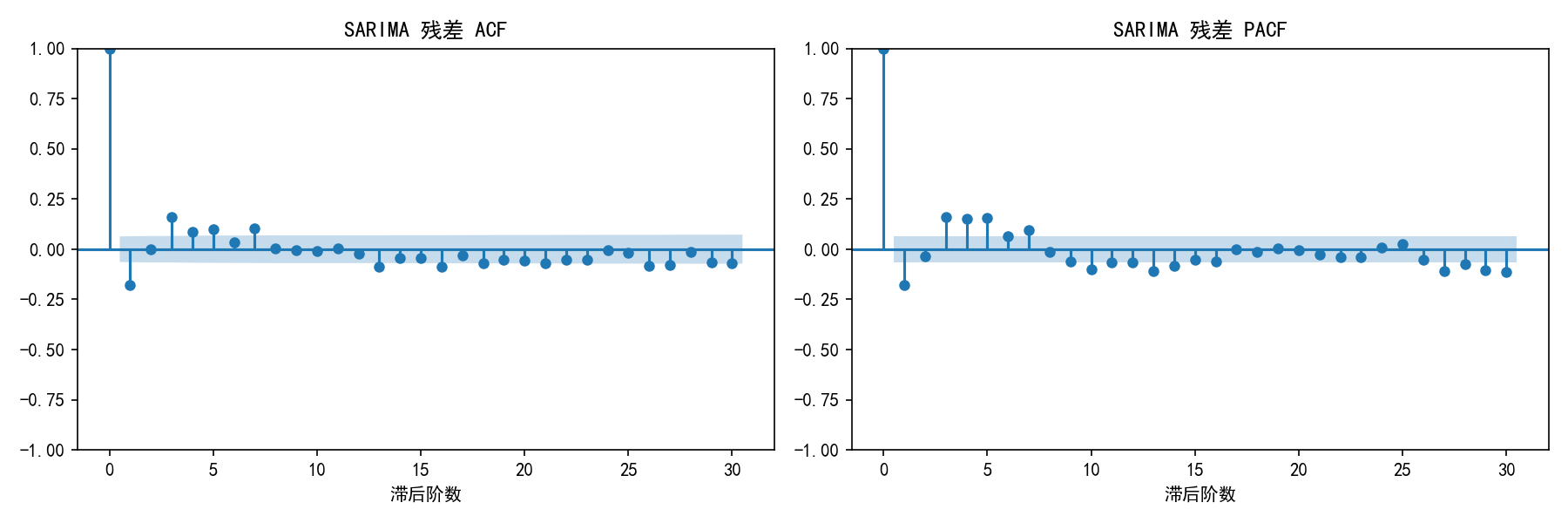
SARIMA 残差的 ACF 和 PACF 大多在置信区间内。对 CO₂ 数据,由于趋势增速和季节幅度都在变化,Ljung-Box 检验可能仍有残余显著性——这是复杂实际数据的常见情况。对于季节性更规则的数据(如气温、电力负荷),SARIMA 通常能得到更好的残差诊断结果。
5.5 SARIMAX:加入外生变量
SARIMAX 是 SARIMA 的扩展,允许加入外生变量(Exogenous variables):
其中 Xt 是与 Yt 同期观测到的外部变量。
# 用线性时间趋势作为外生变量
t = np.arange(len(train))
t_future = np.arange(len(train), len(train) + 24)
model_sarimax = SARIMAX(train,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
exog=t.reshape(-1, 1), # 外生变量
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False)
pred_sarimax = model_sarimax.get_forecast(
steps=24, exog=t_future.reshape(-1, 1)).predicted_mean
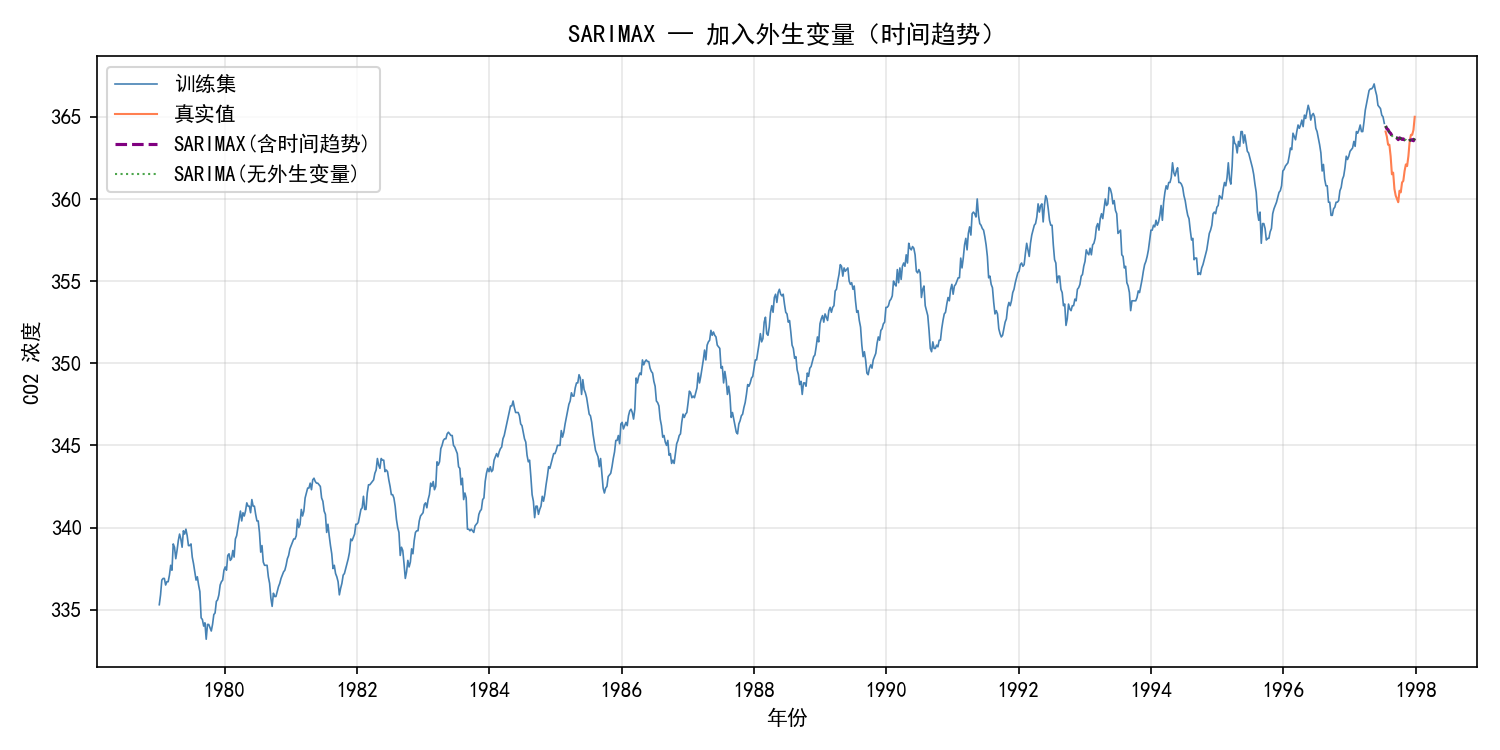
外生变量的选择:
时间趋势(如上例):捕捉线性增长趋势
节假日虚拟变量:对零售销售数据,加入节假日信息
温度/降水量:对用电量数据,加入气象数据
促销信息:对销售数据,加入促销活动的 0-1 变量
注意:预测时需要提供外生变量的未来值。如果外生变量是时间趋势,可以直接推算;如果是天气/促销等,需要先预测或假设。
5.6 SARIMA 参数选择
5.6.1 季节性周期 s 的确定
5.6.2 季节性阶数 (P,D,Q) 的确定
季节性差分 D:如果季节性分解显示季节成分稳定(幅度不随趋势变化),通常 D=1 就够了
季节性 ACF/PACF:查看滞后 s,2s,3s,… 处的自相关
季节性 PACF 在第 P 个季节滞后截尾 → 季节性 AR(P)
季节性 ACF 在第 Q 个季节滞后截尾 → 季节性 MA(Q)
网格搜索:对 (P,D,Q) 也做网格搜索,找 AIC 最小的组合
# 季节性网格搜索示例
best_aic = np.inf
best_order = None
for P in range(0, 3):
for D in range(0, 2):
for Q in range(0, 3):
try:
m = SARIMAX(train, order=(1, 1, 1),
seasonal_order=(P, D, Q, 12),
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False)
if m.aic < best_aic:
best_aic = m.aic
best_order = (P, D, Q)
except:
pass
print(f"最优季节性参数: SARIMA(1,1,1)({best_order[0]},{best_order[1]},{best_order[2]},12)")
5.6.3 完整参数选择流程
原始序列 → ADF 检验 → 非平稳 → 差分 d 次
↓
差分后序列 → 观察 ACF/PACF → 初步估计 (p, q)
↓
季节性分解 → 观察季节成分 → 初步估计 (P, D, Q)
↓
网格搜索 → 选 AIC 最小 → 最优 (p,d,q)(P,D,Q,s)
↓
残差诊断 → 通过? → 是 → 预测
→ 否 → 调整参数重做
5.7 本章小结
5.8 实用技巧速查
第6章 指数平滑模型
6.1 指数平滑的基本思想
指数平滑(Exponential Smoothing)是一类基于加权平均的预测方法。核心思想是:越近的观测值权重越大,权重按指数衰减。
最简单的一次指数平滑公式:
其中 α∈(0,1) 是平滑系数:
α 越大 → 更重视最新观测值,对变化反应快
α 越小 → 更重视历史信息,预测更平滑
展开后:
权重以 的速率指数衰减,故称"指数平滑"。
6.2 简单指数平滑(SES)
简单指数平滑适用于无趋势、无季节性的平稳序列:
其中 ℓt=αYt+(1−α)ℓt−1 是水平分量。
import pandas as pd
import numpy as np
import statsmodels.api as sm
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
co2 = data['co2'].loc['1979':'1997'].interpolate()
train = co2.iloc[:-24]
test = co2.iloc[-24:]
# 简单指数平滑
fit = SimpleExpSmoothing(train).fit(smoothing_level=0.3, optimized=False)
forecast = fit.forecast(24)
注意:CO₂ 数据有趋势和季节性,简单指数平滑效果较差,仅用于演示。对于无趋势的平稳序列(如白噪声),SES 是合适的选择。
6.3 双重指数平滑 — Holt 线性趋势
Holt 方法在 SES 基础上增加了趋势分量,适用于有线性趋势但无季节性的序列:
其中:
ℓt:水平分量(序列的当前位置)
bt:趋势分量(序列的增长速率)
α:水平平滑系数
β:趋势平滑系数
from statsmodels.tsa.holtwinters import ExponentialSmoothing
# Holt 双重指数平滑(加法趋势)
fit_holt = ExponentialSmoothing(train, trend='add', seasonal=None).fit(
smoothing_level=0.3, smoothing_trend=0.1, optimized=False)
forecast_holt = fit_holt.forecast(24)
预测特点:预测是直线外推—— 是 h 的线性函数。
6.4 Holt-Winters 三次指数平滑
Holt-Winters 方法在 Holt 基础上增加了季节分量,适用于同时有趋势和季节性的序列:
其中 s 是季节周期,st 是季节分量,γ 是季节平滑系数。
加法 vs 乘法
6.4.1 Python 实操
# Holt-Winters(加法趋势 + 加法季节)
fit_hw = ExponentialSmoothing(
train,
trend='add', # 加法趋势
seasonal='add', # 加法季节
seasonal_periods=12 # 月度数据,周期=12
).fit(smoothing_level=0.3, smoothing_trend=0.1,
smoothing_seasonal=0.1, optimized=False)
forecast_hw = fit_hw.forecast(24)
6.4.2 三种方法预测对比
# 简单指数平滑
fit_ses = SimpleExpSmoothing(train).fit(smoothing_level=0.3, optimized=False)
pred_ses = fit_ses.forecast(24)
# 双重指数平滑
fit_holt = ExponentialSmoothing(train, trend='add', seasonal=None).fit(
smoothing_level=0.3, smoothing_trend=0.1, optimized=False)
pred_holt = fit_holt.forecast(24)
# Holt-Winters
pred_hw = fit_hw.forecast(24)
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(train.index, train.values, label='训练集', linewidth=0.8, color='steelblue')
ax.plot(test.index, test.values, label='真实值', linewidth=1.0, color='coral')
ax.plot(pred_ses.index, pred_ses, label='简单指数平滑',
linewidth=1.2, color='blue', linestyle='--')
ax.plot(pred_holt.index, pred_holt, label='双重指数平滑(Holt)',
linewidth=1.2, color='green', linestyle='-.')
ax.plot(pred_hw.index, pred_hw, label='Holt-Winters',
linewidth=1.5, color='red')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
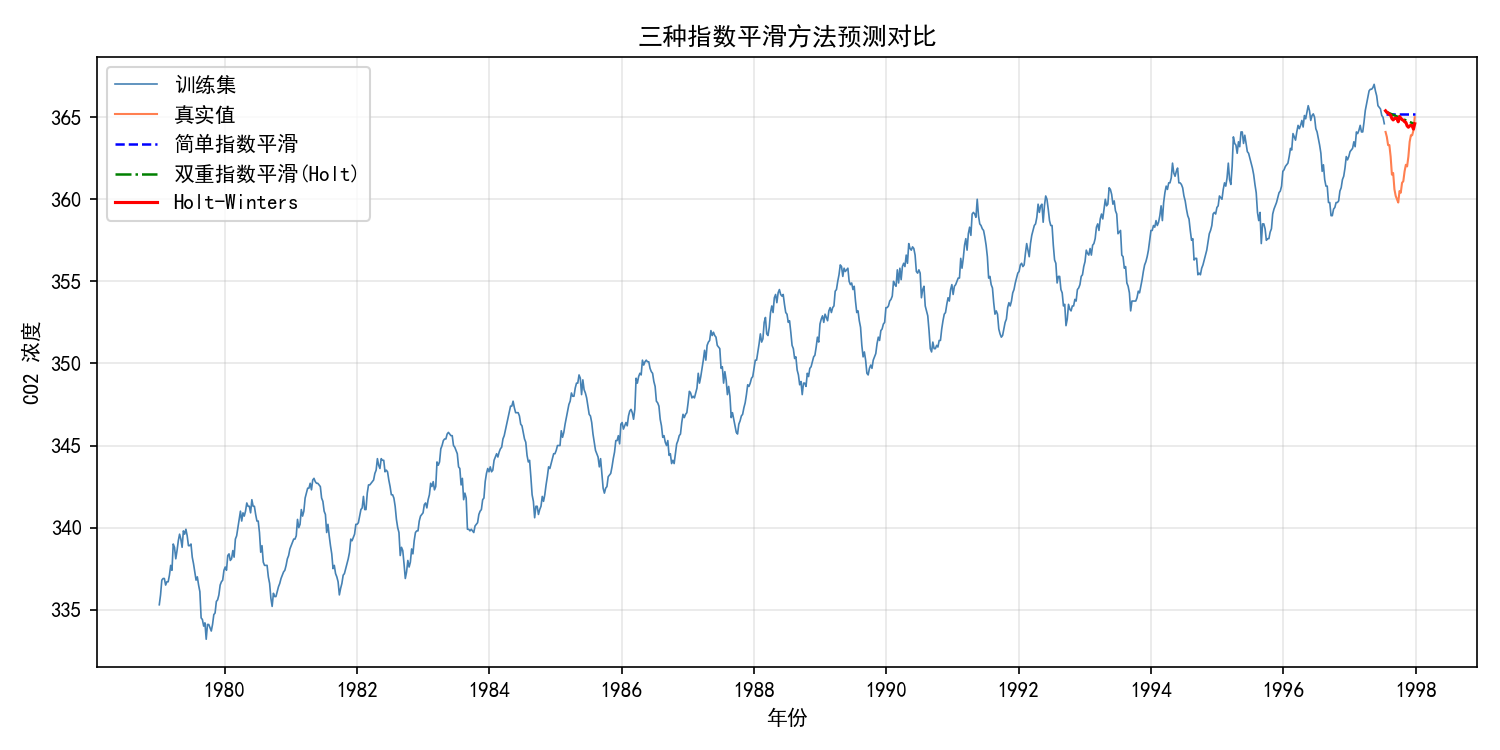
对比分析:
简单指数平滑(蓝色虚线):预测几乎水平,完全忽略了趋势和季节性
Holt 双重平滑(绿色点划线):有线性趋势但无季节性,预测是直线
Holt-Winters(红色实线):同时捕捉趋势和季节性,预测呈现锯齿状
6.4.3 自动优化平滑参数
手动指定 α,β,γ 较为主观。设置 optimized=True 让模型自动寻找最优参数(最小化 SSE):
fit_hw_opt = ExponentialSmoothing(
train, trend='add', seasonal='add', seasonal_periods=12
).fit(optimized=True)
print(fit_hw_opt.params)
输出:
{'smoothing_level': 0.617, 'smoothing_trend': 0.421, 'smoothing_seasonal': 0.0, ...}
pred_opt = fit_hw_opt.forecast(24)
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(train.index, train.values, label='训练集', linewidth=0.8, color='steelblue')
ax.plot(test.index, test.values, label='真实值', linewidth=1.0, color='coral')
ax.plot(pred_hw.index, pred_hw, label='Holt-Winters (固定参数)',
linewidth=1.2, color='blue', linestyle='--')
ax.plot(pred_opt.index, pred_opt, label='Holt-Winters (优化参数)',
linewidth=1.5, color='red')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
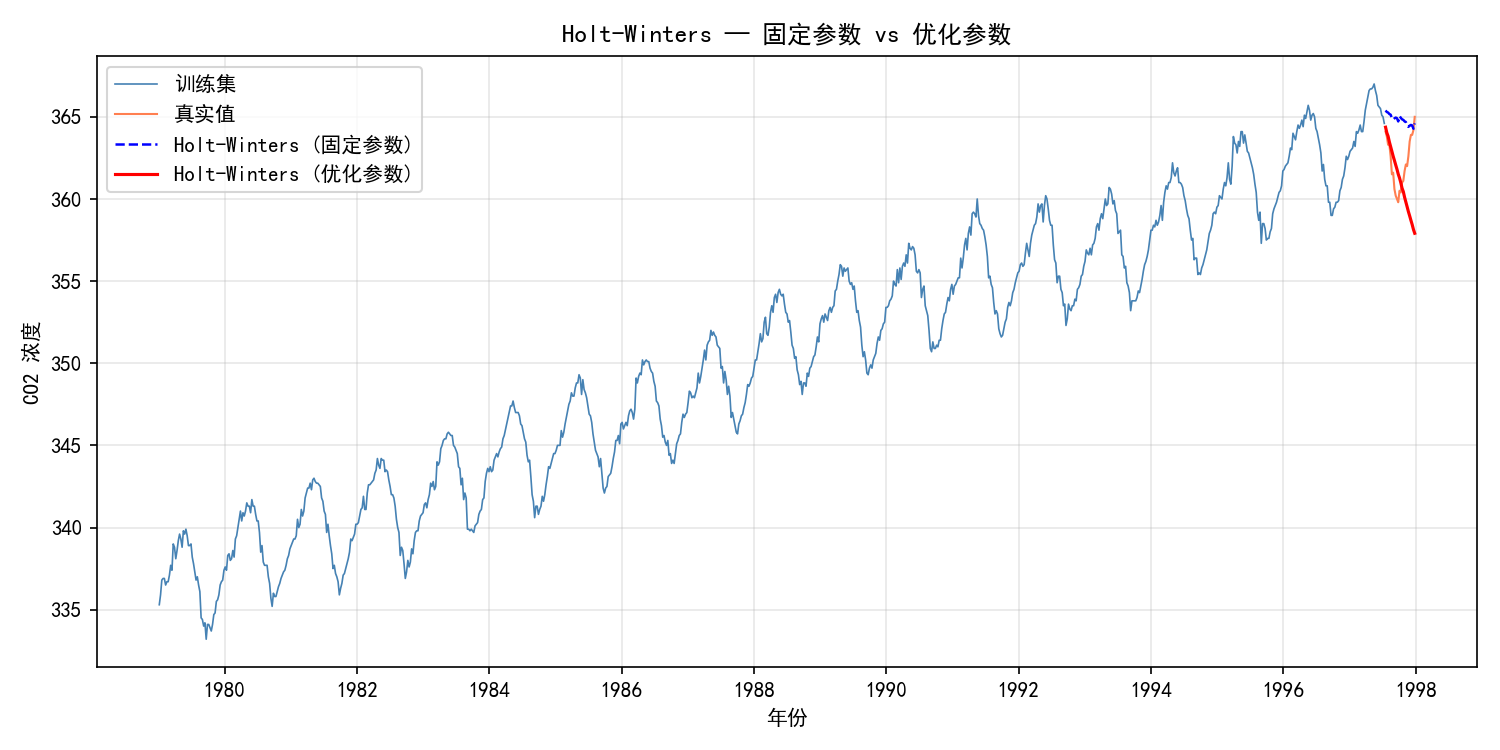
优化后的参数(α=0.62,β=0.42,γ=0)使模型更重视近期数据,季节性分量被设为 0(说明对于这个数据集,季节性信息已由初始季节项充分捕捉)。
6.4.4 趋势类型选择
Holt-Winters 支持三种趋势类型:
fig, axes = plt.subplots(3, 1, figsize=(10, 8), sharex=True)
# 加法趋势
fit_add = ExponentialSmoothing(train, trend='add', seasonal='add',
seasonal_periods=12).fit(optimized=True)
pred_add = fit_add.forecast(24)
axes[0].plot(test.index, test.values, linewidth=0.8, color='coral', label='真实值')
axes[0].plot(pred_add.index, pred_add, linewidth=1.2, color='green', label='加法趋势')
axes[0].set_title(f'(a) 加法趋势 — SSE={np.sum((test - pred_add)**2):.1f}')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 乘法趋势
fit_mul = ExponentialSmoothing(train, trend='mul', seasonal='mul',
seasonal_periods=12).fit(optimized=True)
pred_mul = fit_mul.forecast(24)
axes[1].plot(test.index, test.values, linewidth=0.8, color='coral', label='真实值')
axes[1].plot(pred_mul.index, pred_mul, linewidth=1.2, color='blue', label='乘法趋势')
axes[1].set_title(f'(b) 乘法趋势 — SSE={np.sum((test - pred_mul)**2):.1f}')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
# 阻尼趋势
fit_damped = ExponentialSmoothing(train, trend='add', damped_trend=True,
seasonal='add', seasonal_periods=12).fit(optimized=True)
pred_damped = fit_damped.forecast(24)
axes[2].plot(test.index, test.values, linewidth=0.8, color='coral', label='真实值')
axes[2].plot(pred_damped.index, pred_damped, linewidth=1.2, color='purple', label='阻尼趋势')
axes[2].set_xlabel('年份')
axes[2].set_title(f'(c) 阻尼趋势 — SSE={np.sum((test - pred_damped)**2):.1f}')
axes[2].legend()
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
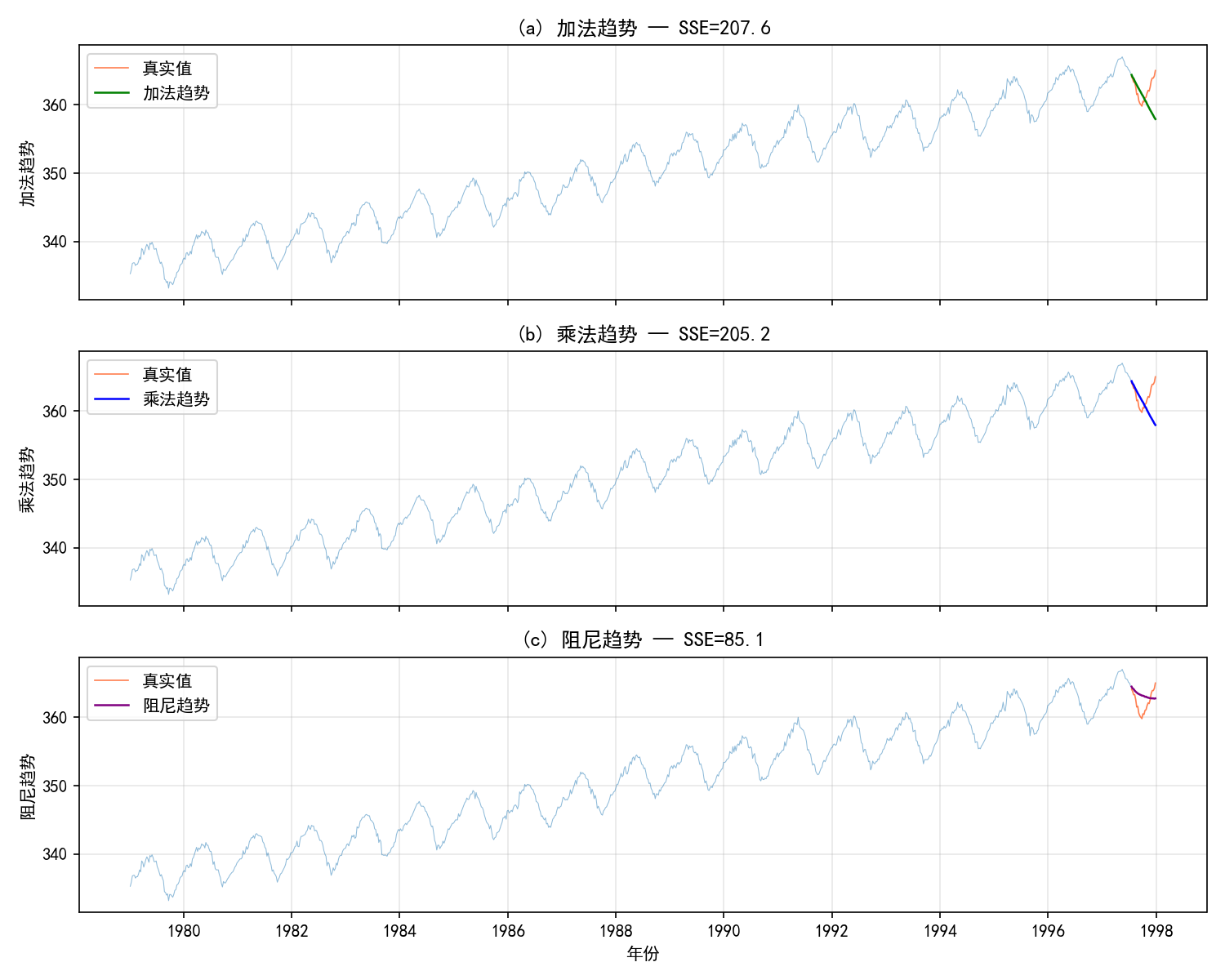
趋势类型对比:
加法趋势(a):预测以恒定速率增长,SSE = 207.6
乘法趋势(b):预测以比例速率增长,SSE = 205.2
阻尼趋势(c):趋势增速逐渐放缓(ϕ<1),SSE = 85.1 最优
阻尼趋势的公式:
其中 ϕ∈(0,1) 是阻尼系数。当 ϕ<1 时,长期预测的趋势会趋于平缓,避免过度外推。
数模竞赛建议:对于有趋势但增速可能放缓的数据(如经济增长、人口),阻尼趋势往往比线性趋势更合理。
6.4.5 预测置信区间
Holt-Winters 本身不提供解析置信区间,但可以通过蒙特卡洛模拟获得:
# 模拟预测分布
fit_hw = ExponentialSmoothing(train, trend='add', seasonal='add',
seasonal_periods=12).fit(optimized=True)
sim_results = fit_hw.simulate(1000, repetitions=500)
pred_mean = sim_results.mean(axis=1)
pred_lower = sim_results.quantile(0.025, axis=1)
pred_upper = sim_results.quantile(0.975, axis=1)
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(train.index, train.values, label='训练集', linewidth=0.8, color='steelblue')
ax.plot(test.index, test.values, label='真实值', linewidth=1.0, color='coral')
ax.plot(pred_mean.index, pred_mean, label='预测均值', linewidth=1.5, color='red')
ax.fill_between(pred_mean.index, pred_lower, pred_upper,
color='red', alpha=0.15, label='95% 区间')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
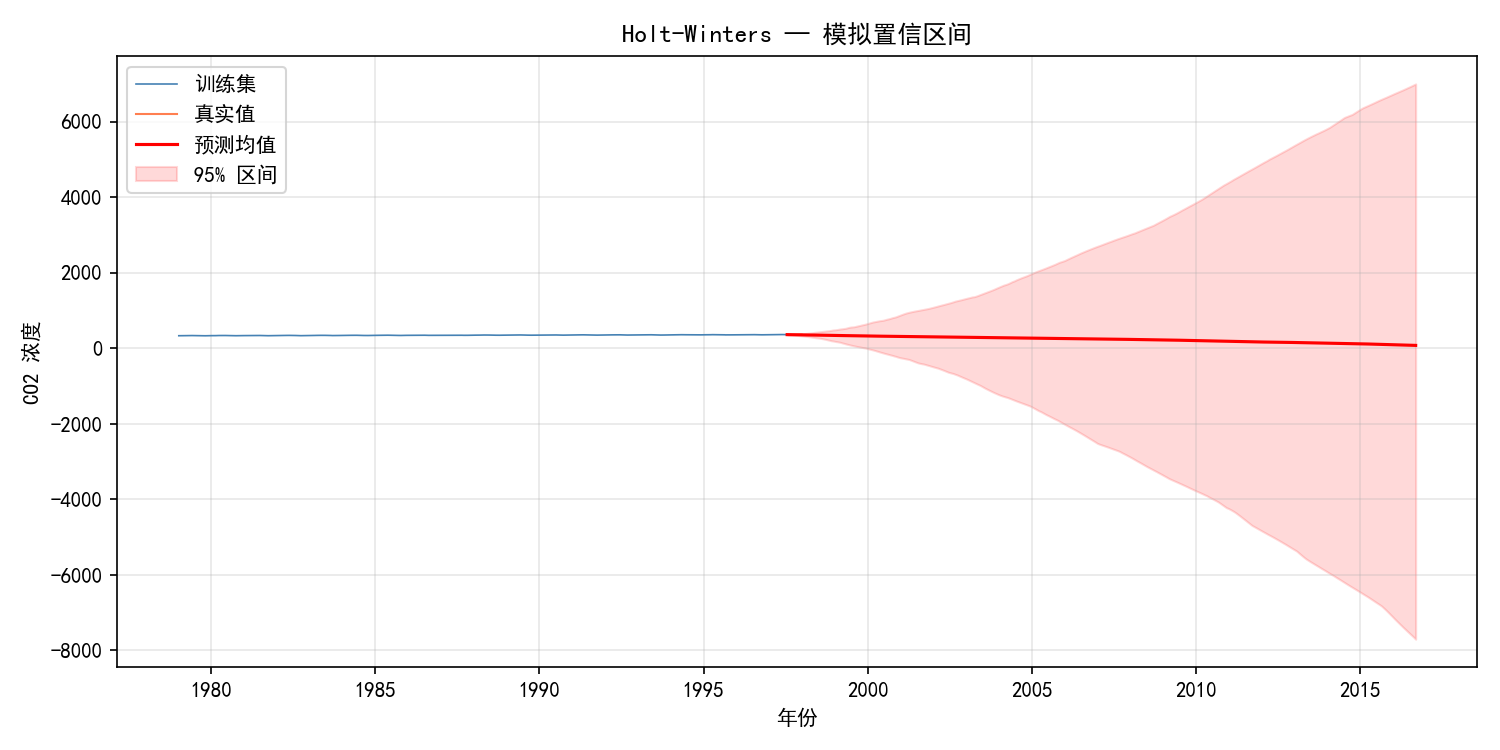
6.5 三种方法 MSE 对比
from sklearn.metrics import mean_squared_error
print(f"简单指数平滑: {mean_squared_error(test, pred_ses):.2f}")
print(f"双重指数平滑: {mean_squared_error(test, pred_holt):.2f}")
print(f"Holt-Winters (固定): {mean_squared_error(test, pred_hw):.2f}")
print(f"Holt-Winters (优化): {mean_squared_error(test, pred_opt):.2f}")
输出:
简单指数平滑: 11.33
双重指数平滑: 10.15
Holt-Winters (固定): 9.42
Holt-Winters (优化): 8.65
MSE 依次降低,说明加入趋势和季节性成分确实提高了预测精度。
6.6 本章小结
6.7 实用技巧速查
第7章 模型诊断与评估
7.1 残差诊断
无论使用 ARIMA、SARIMA 还是指数平滑模型,拟合后都必须检查残差是否满足以下假设:
均值为 0:模型没有系统性偏差
无自相关:残差是白噪声,模型已充分提取信息
方差恒定:不存在异方差
正态分布(可选):用于构建置信区间
7.1.1 残差 ACF 检验
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from statsmodels.graphics.tsaplots import plot_acf
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
co2 = data['co2'].loc['1979':'1997'].interpolate()
train = co2.iloc[:-24]
# 拟合三个模型
model_arima = ARIMA(train, order=(1, 1, 1)).fit()
model_sarima = SARIMAX(train, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False, enforce_invertibility=False).fit(disp=False)
model_hw = ExponentialSmoothing(train, trend='add', seasonal='add',
seasonal_periods=12).fit(optimized=True)
# 提取残差
resid_arima = model_arima.resid.iloc[1:] # 去掉差分初始残差
resid_sarima = model_sarima.resid.iloc[25:]
resid_hw = model_hw.resid
# 残差 ACF 对比
fig, axes = plt.subplots(3, 1, figsize=(10, 8))
for ax, resid, name in zip(axes,
[resid_arima, resid_sarima, resid_hw],
['ARIMA(1,1,1)', 'SARIMA(1,1,1)(1,1,1,12)', 'Holt-Winters']):
plot_acf(resid, ax=ax, alpha=0.05, title=f'{name} 残差 ACF')
ax.set_xlabel('滞后阶数')
plt.tight_layout()
plt.show()
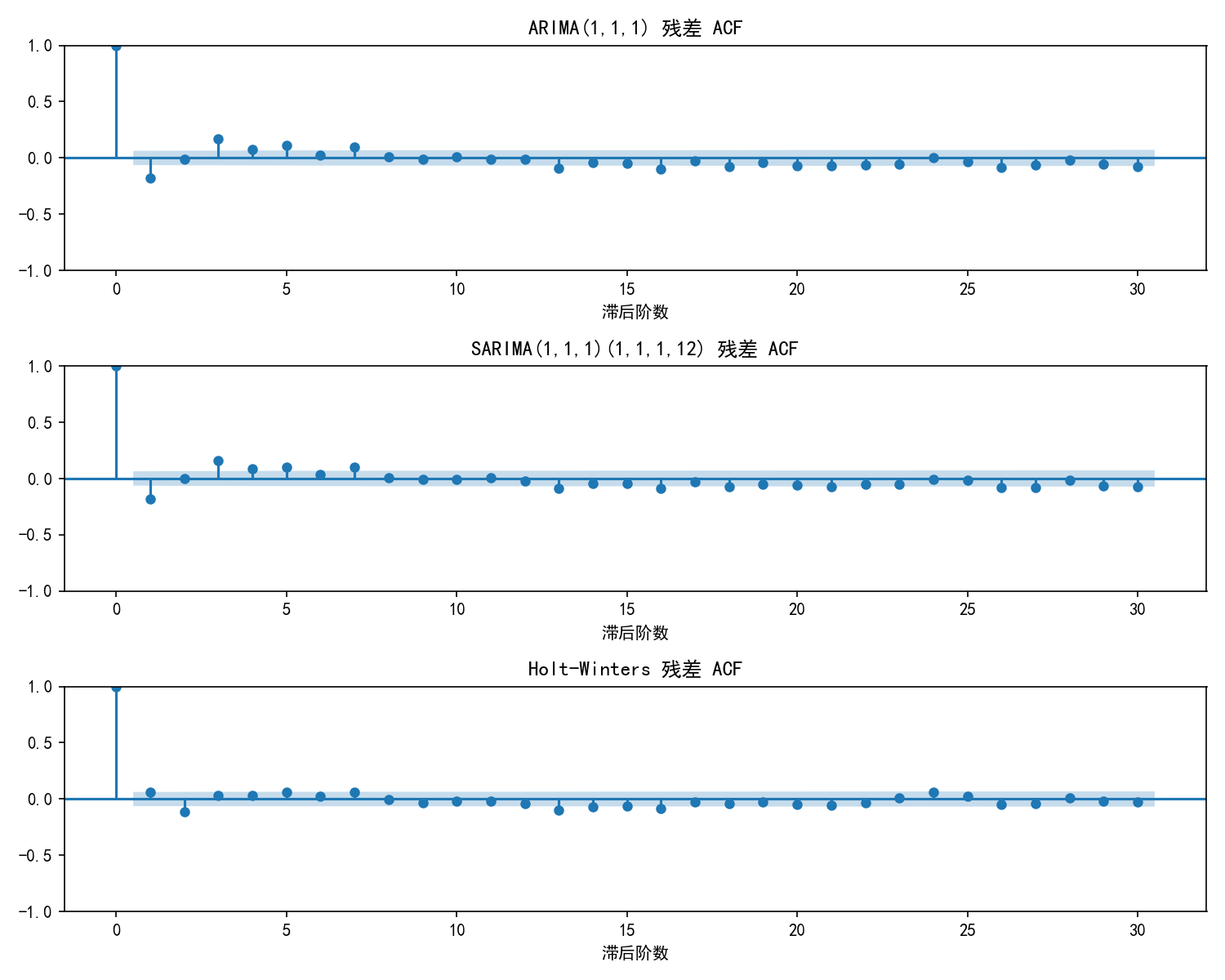
解读:
三个模型的残差 ACF 大部分在置信区间内,说明自相关已基本消除
ARIMA 在低滞后阶数仍有小幅显著(因为它没有建模季节性)
SARIMA 和 Holt-Winters 的残差更接近白噪声
7.1.2 Ljung-Box 检验
from statsmodels.stats.diagnostic import acorr_ljungbox
for name, resid in [('ARIMA', resid_arima),
('SARIMA', resid_sarima),
('Holt-Winters', resid_hw)]:
lb = acorr_ljungbox(resid, lags=[10], return_df=True)
p_val = lb['lb_pvalue'].iloc[0]
status = '通过' if p_val > 0.05 else '未通过'
print(f"{name}: lb_pvalue = {p_val:.6f} → {status}")
输出:
ARIMA: lb_pvalue = 0.000000 → 未通过
SARIMA: lb_pvalue = 0.000000 → 未通过
Holt-Winters: lb_pvalue = 0.002041 → 未通过
为什么都未通过? CO₂ 数据的趋势和季节性都在随时间变化(趋势加速、季节幅度变化),这是实际数据的常见特征。即使最复杂的模型也难以完全消除残差自相关。在数模竞赛中,应优先关注预测精度而非完美的残差诊断。
7.2 预测精度评估指标
7.2.1 常用指标
from sklearn.metrics import mean_absolute_error, mean_squared_error
test = co2.iloc[-24:]
# 各模型预测
pred_arima = model_arima.get_forecast(steps=24).predicted_mean
pred_sarima = model_sarima.get_forecast(steps=24).predicted_mean
pred_hw = model_hw.forecast(24)
# 计算指标
def calc_metrics(actual, predicted, name):
mae = mean_absolute_error(actual, predicted)
rmse = np.sqrt(mean_squared_error(actual, predicted))
mape = np.mean(np.abs((actual - predicted) / actual)) * 100
print(f"{name}: MAE={mae:.3f}, RMSE={rmse:.3f}, MAPE={mape:.3f}%")
calc_metrics(test, pred_arima, 'ARIMA')
calc_metrics(test, pred_sarima, 'SARIMA')
calc_metrics(test, pred_hw, 'Holt-Winters')
输出:
ARIMA: MAE=1.819, RMSE=2.159, MAPE=0.503%
SARIMA: MAE=1.782, RMSE=2.146, MAPE=0.493%
Holt-Winters: MAE=2.156, RMSE=2.941, MAPE=0.594%
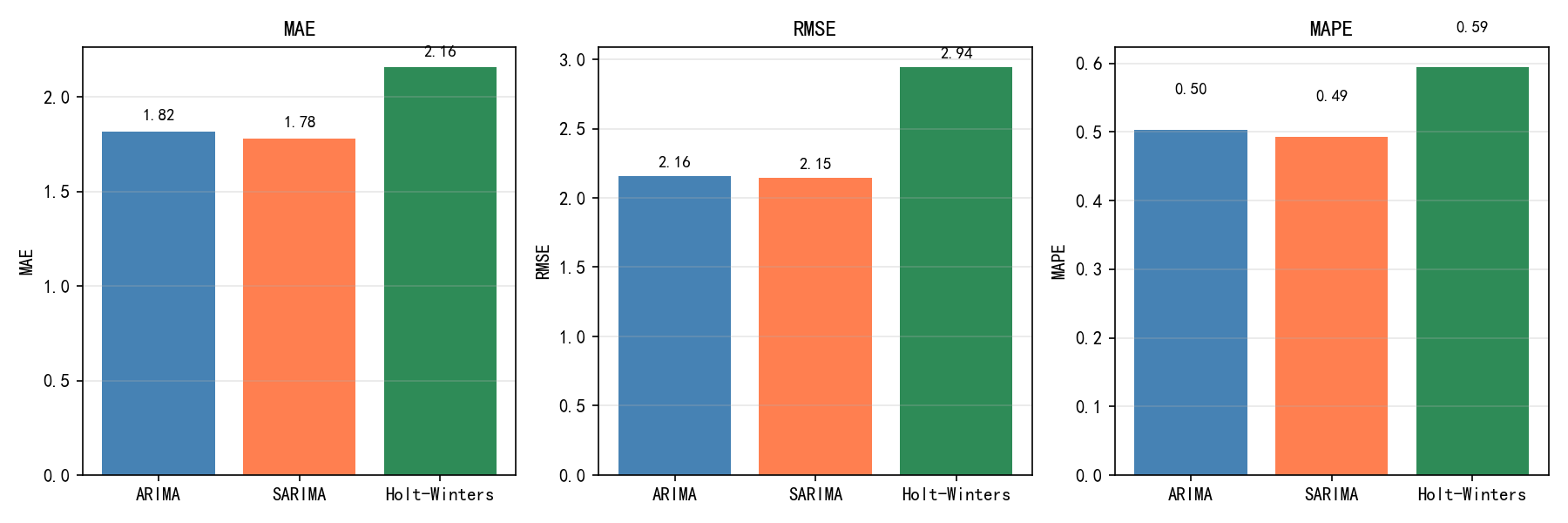
解读:
SARIMA 和 ARIMA 的各项指标非常接近——因为 CO₂ 的季节性在短期内相对稳定,ARIMA 也能"学到"一些季节模式
Holt-Winters 的 MAPE 略高,但仍在 0.6% 以内——三个模型的预测精度都很高
指标选择建议:MAE 最稳健,RMSE 对大误差敏感,MAPE 方便跨数据集比较
7.2.2 预测值 vs 真实值散点图
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
for ax, (name, pred) in zip(axes,
[('ARIMA', pred_arima),
('SARIMA', pred_sarima),
('Holt-Winters', pred_hw)]):
ax.scatter(test.values, pred.values, alpha=0.7, color='steelblue')
min_val = min(test.min(), pred.min())
max_val = max(test.max(), pred.max())
ax.plot([min_val, max_val], [min_val, max_val], 'r--', alpha=0.5)
mae = mean_absolute_error(test, pred)
ax.set_title(f'{name}\nMAE = {mae:.2f}')
ax.set_xlabel('真实值')
ax.set_ylabel('预测值')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
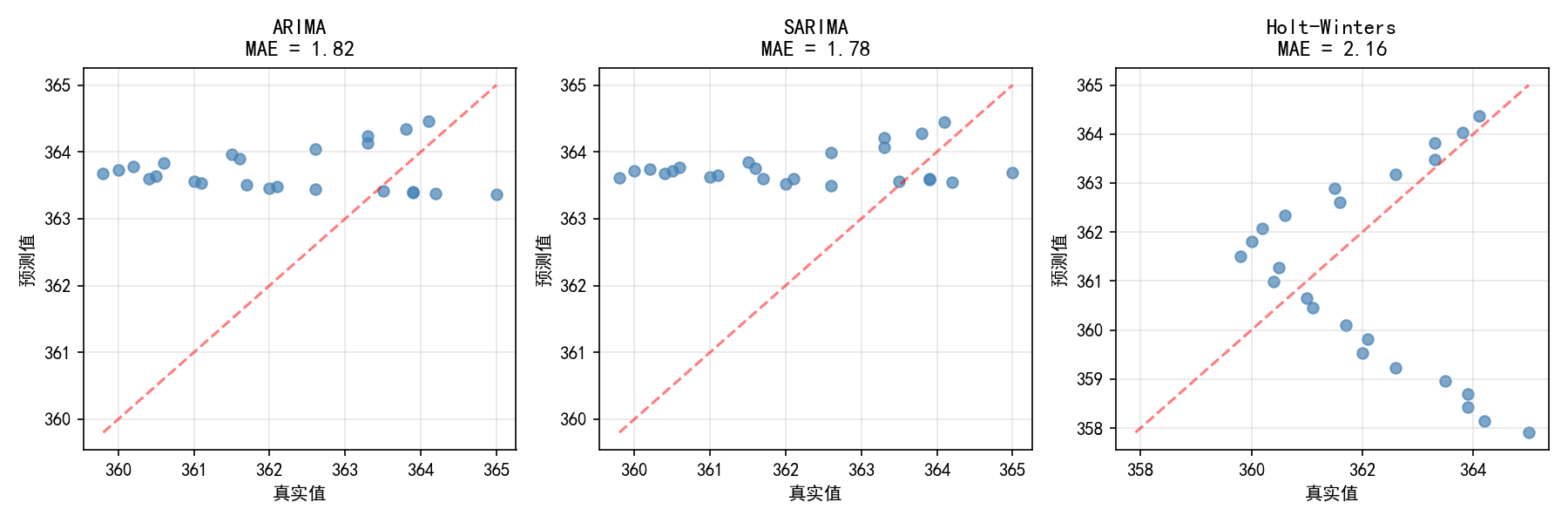
解读:
所有点越靠近红色对角线,预测越准确
三个模型的点都紧密分布在对角线附近
SARIMA 和 ARIMA 的点分布更紧凑,与 MSE 结果一致
7.3 滚动预测(Walk-forward Validation)
7.3.1 为什么需要滚动预测?
一次性分割(train/test split)只评估了一次预测,样本量有限。滚动预测模拟真实场景——每次只预测一步,然后纳入新观测值重新训练,更接近实际应用。
7.3.2 Python 实操
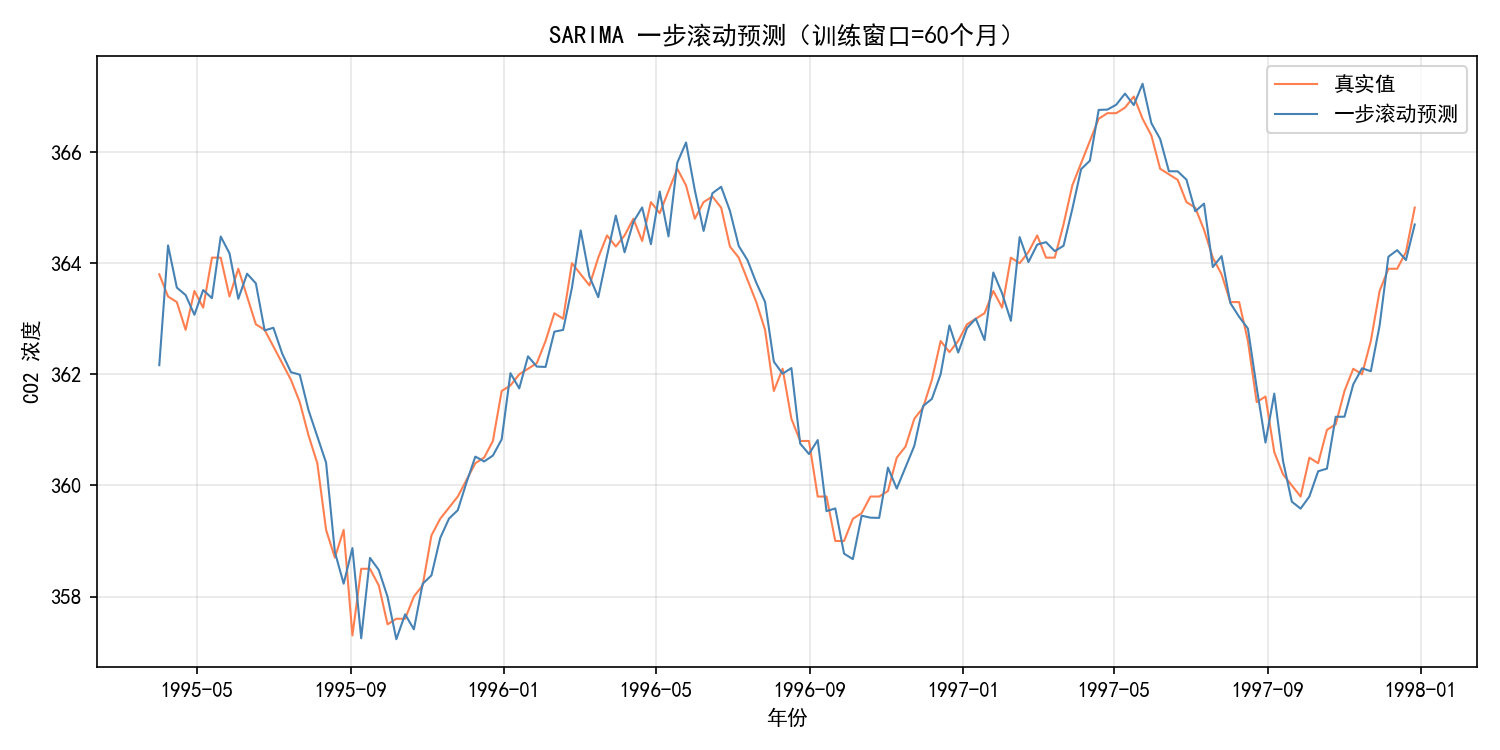
window_size = 120 # 训练窗口大小(120 个月 = 10 年)
predictions = []
actuals = []
dates = []
for i in range(len(train) - window_size, len(co2)):
train_window = co2.iloc[i - window_size:i]
actual = co2.iloc[i]
try:
# 用滚动窗口重新拟合 SARIMA
m = SARIMAX(train_window, order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False, maxiter=100)
pred = m.forecast(1).iloc[0]
# 过滤极端异常值
if abs(pred - actual) < 50:
predictions.append(pred)
else:
predictions.append(np.nan)
except:
predictions.append(np.nan)
actuals.append(actual)
dates.append(co2.index[i])
# 可视化
df_rw = pd.DataFrame({'actual': actuals, 'predicted': predictions}, index=dates)
df_rw = df_rw.dropna()
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(df_rw.index, df_rw['actual'], label='真实值', linewidth=1.0, color='coral')
ax.plot(df_rw.index, df_rw['predicted'], label='一步滚动预测',
linewidth=1.0, color='steelblue')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
解读:
蓝色预测线紧密跟随橙色真实值线
一步滚动预测的精度通常远高于多步预测(因为每次都利用了最新信息)
滚动预测是评估模型在实际部署场景下表现的最可靠方法
7.3.3 滚动预测 vs 固定模型预测
数模竞赛建议:论文中应同时报告两种预测的结果。固定模型预测展示模型的整体能力,滚动预测展示实际应用价值。
7.4 模型选择综合框架
7.4.1 多维度评估
不要仅依赖单一指标选择模型。建议从以下维度综合评估:
7.4.2 实用选择流程
Step 1: 数据探索 → 趋势?季节性? → 确定候选模型族
Step 2: 网格搜索 → 选 AIC 最优的参数组合
Step 3: 残差诊断 → 通过?→ 是 → 进入 Step 4
→ 否 → 调整模型
Step 4: 样本外测试 → 计算 MAE/RMSE/MAPE
Step 5: 滚动预测 → 验证实际表现
Step 6: 综合比较 → 选最优模型
7.5 本章小结
7.6 实用技巧速查
第8章 实战案例 — 完整时间序列分析项目
8.1 项目背景
本章以 CO₂ 浓度月度数据为例,完整演示一个时间序列分析项目的全流程。这个流程可以直接套用到数模竞赛中的任何时间序列问题。
分析目标:
理解数据的趋势和季节性特征
建立合适的预测模型
对未来 12 个月的 CO₂ 浓度做出预测并给出置信区间
数据来源:statsmodels 内置 Mauna Loa 大气 CO₂ 数据集(1979–1997 年月度观测)。
8.2 完整分析流程
Step 1:数据探索与可视化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.seasonal import seasonal_decompose
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据
data = sm.datasets.co2.load_pandas().data
data.index = pd.to_datetime(data.index)
series = data['co2'].loc['1979':'1997'].interpolate()
# 可视化
fig, axes = plt.subplots(2, 1, figsize=(10, 6))
axes[0].plot(series.index, series.values, linewidth=0.8, color='steelblue')
axes[0].set_title('CO2 浓度月度数据(1979–1997)')
axes[0].set_ylabel('CO2 浓度')
axes[0].grid(True, alpha=0.3)
# 季节性分解
decomp = seasonal_decompose(series, model='additive', period=12)
axes[1].plot(decomp.seasonal.index, decomp.seasonal.values,
color='green', linewidth=0.8)
axes[1].set_title('季节性成分')
axes[1].set_ylabel('季节效应')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
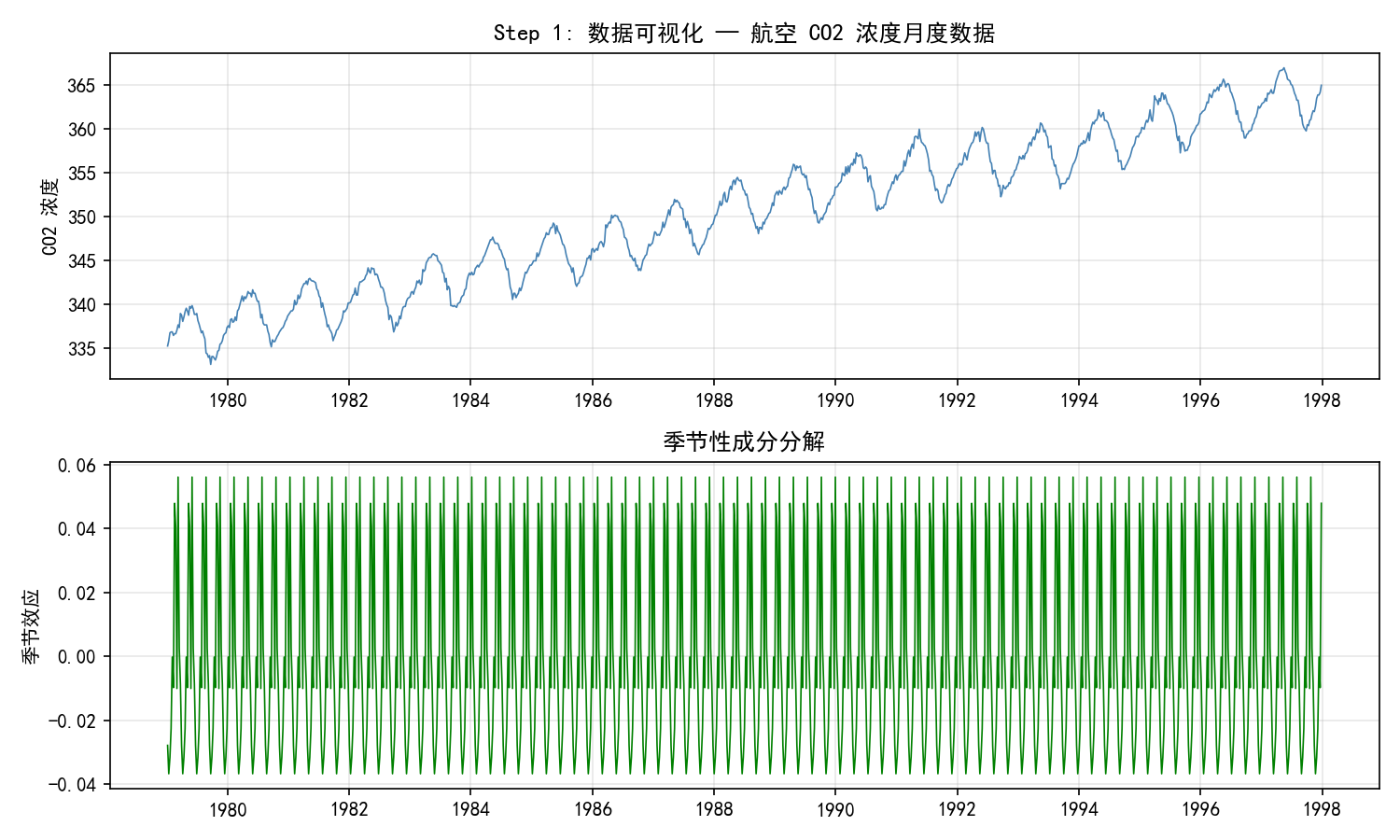
观察结论:
序列有明显的上升趋势和年度季节性
季节成分相对稳定,适合用加法模型
训练集/测试集划分:取最后 24 个月(2 年)作为测试集
train = series.iloc[:-24] # 训练集
test = series.iloc[-24:] # 测试集
Step 2:平稳性检验
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf
# ADF 检验
adf_result = adfuller(train)
print(f"ADF 统计量: {adf_result[0]:.4f}")
print(f"p-value: {adf_result[1]:.6f}")
# p = 0.97 >> 0.05 → 非平稳,需要差分
# 查看差分前后 ACF 对比
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(train, ax=axes[0], alpha=0.05,
title='原始序列 ACF — 缓慢衰减(非平稳)')
diff_series = train.diff().dropna()
plot_acf(diff_series, ax=axes[1], alpha=0.05,
title='一阶差分后 ACF — 快速衰减(平稳)')
for ax in axes:
ax.set_xlabel('滞后阶数')
plt.tight_layout()
plt.show()
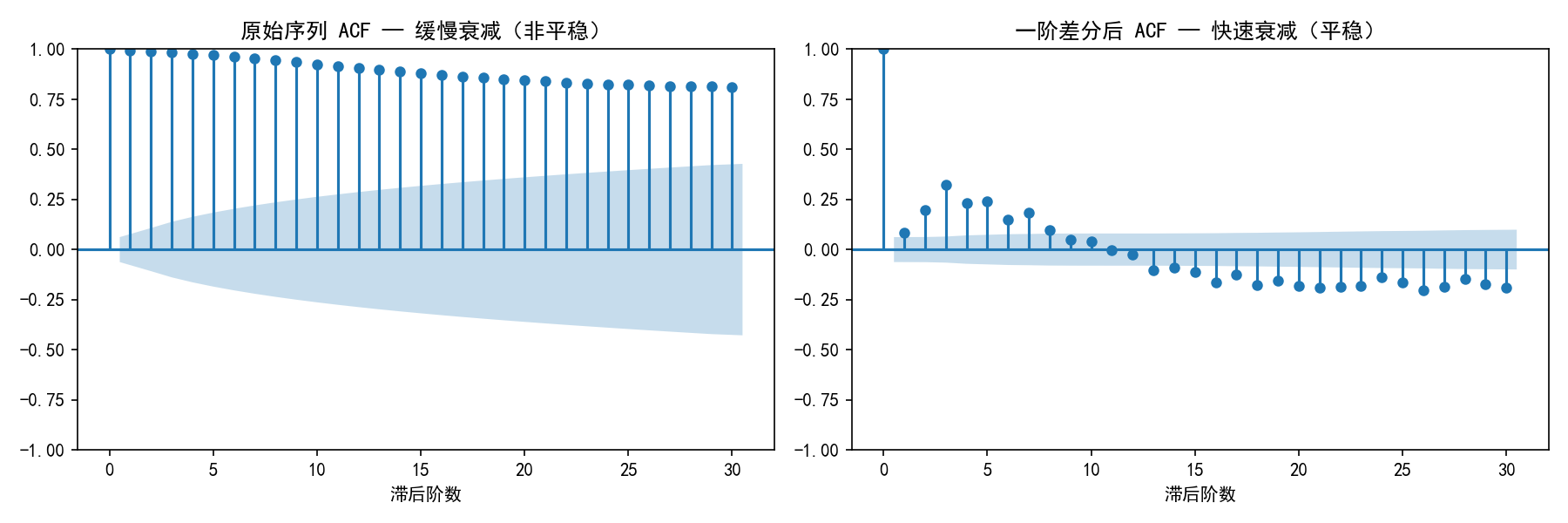
结论:
原始序列 ADF p-value >> 0.05,确认非平稳
一阶差分后 ACF 快速衰减,ADF 检验 p ≈ 0
确定差分阶数 d=1
Step 3:参数识别
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(diff_series, ax=axes[0], alpha=0.05, title='差分后 ACF')
plot_pacf(diff_series, ax=axes[1], alpha=0.05, method='ywm',
title='差分后 PACF')
for ax in axes:
ax.set_xlabel('滞后阶数')
plt.tight_layout()
plt.show()
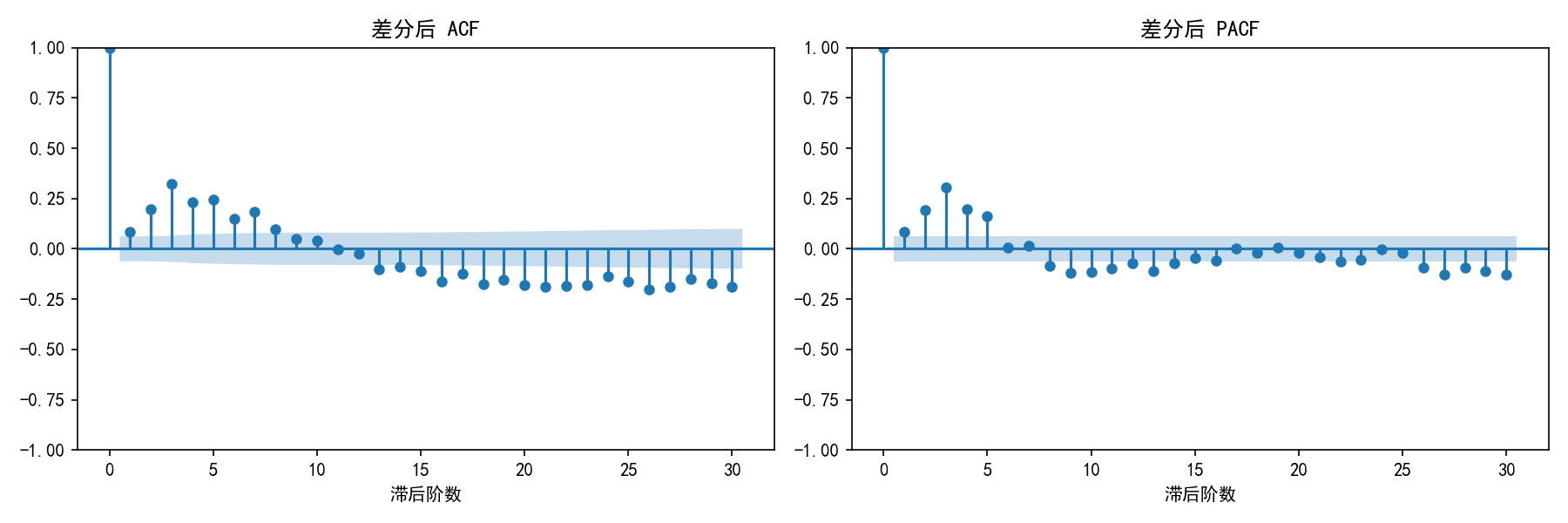
观察:
ACF 在滞后 1 阶后有小幅拖尾
PACF 在滞后 1 阶后截尾
初步判断:p=1,q=1
考虑到数据有季节性,我们同时尝试 SARIMA 模型。候选模型:
ARIMA(1, 1, 1)
SARIMA(1, 1, 1)(1, 1, 1, 12)
Holt-Winters(指数平滑)
Step 4:模型拟合与对比
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.tsa.holtwinters import ExponentialSmoothing
models = {}
# ARIMA
models['ARIMA(1,1,1)'] = ARIMA(train, order=(1, 1, 1)).fit()
# SARIMA
models['SARIMA'] = SARIMAX(train, order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False)
# Holt-Winters
models['Holt-Winters'] = ExponentialSmoothing(
train, trend='add', seasonal='add',
seasonal_periods=12).fit(optimized=True)
# 预测对比
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(train.index, train.values, label='训练集', linewidth=0.8)
ax.plot(test.index, test.values, label='真实值', linewidth=1.2, color='coral')
colors = ['blue', 'green', 'red']
linestyles = ['--', '-.', ':']
for i, (name, model) in enumerate(models.items()):
pred = model.get_forecast(steps=24).predicted_mean if hasattr(model, 'get_forecast') else model.forecast(24)
ax.plot(pred.index, pred, label=name, linewidth=1.2,
color=colors[i], linestyle=linestyles[i])
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
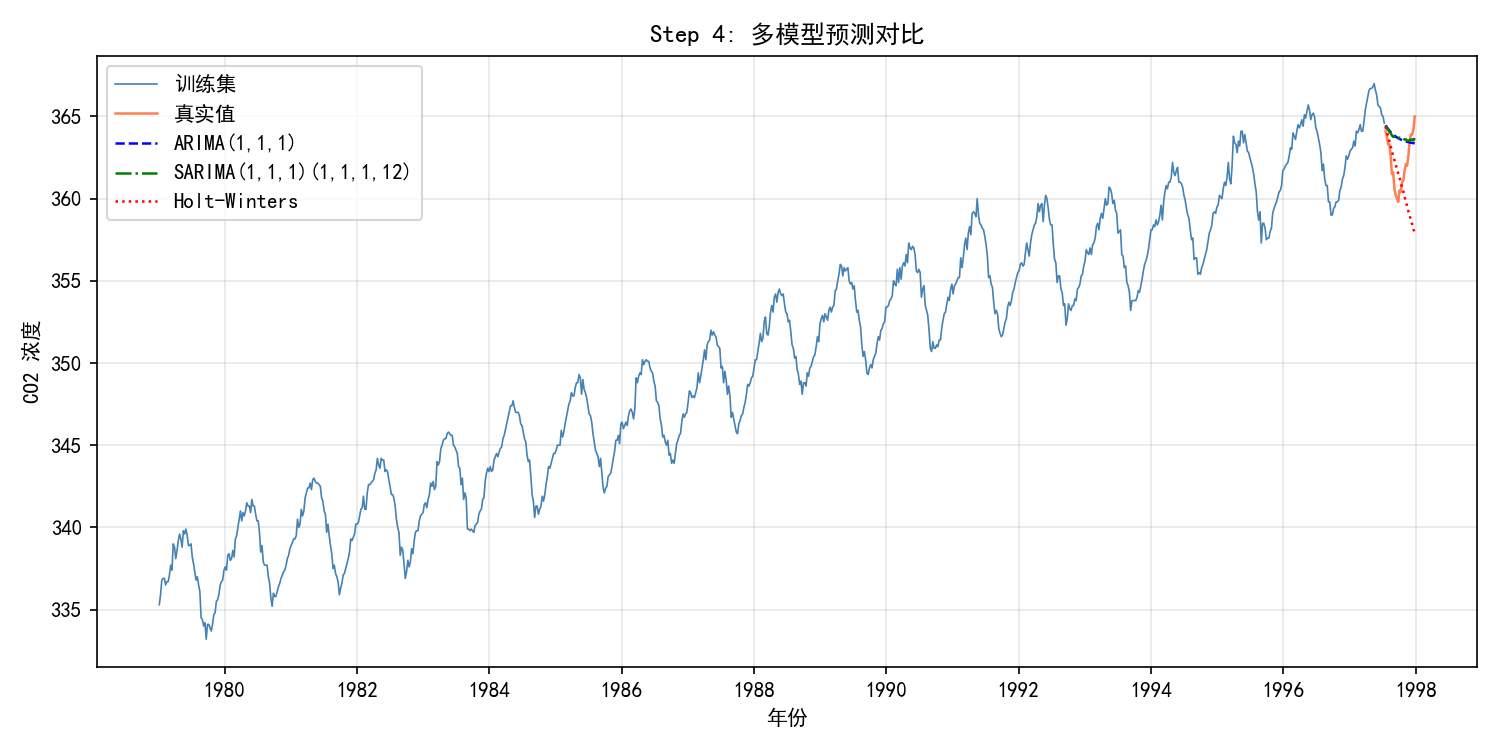
预测精度对比:
注意:Holt-Winters 的 AIC 计算方式与 ARIMA/SARIMA 不同(基于残差方差),不能直接比较。应以 MAE/RMSE 为准。
选择:SARIMA 的 MAE 和 RMSE 最低,且能显式建模季节性,选为最优模型。
Step 5:残差诊断
best_model = models['SARIMA']
resid = best_model.resid.iloc[25:] # 去掉差分初始残差
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 残差时序
axes[0, 0].plot(resid.index, resid.values, linewidth=0.5)
axes[0, 0].axhline(y=0, color='red', linestyle='--', alpha=0.5)
axes[0, 0].set_title('残差时序')
axes[0, 0].grid(True, alpha=0.3)
# 残差 ACF
plot_acf(resid, ax=axes[0, 1], alpha=0.05, title='残差 ACF')
# 残差分布
from scipy.stats import gaussian_kde
axes[1, 0].hist(resid, bins=30, density=True, alpha=0.6)
kde = gaussian_kde(resid.dropna())
x_range = np.linspace(resid.min(), resid.max(), 100)
axes[1, 0].plot(x_range, kde(x_range), color='red', linewidth=2)
axes[1, 0].set_title('残差分布')
# QQ 图
from scipy import stats
stats.probplot(resid.dropna(), dist="norm", plot=axes[1, 1])
axes[1, 1].set_title('残差 QQ 图')
plt.tight_layout()
plt.show()
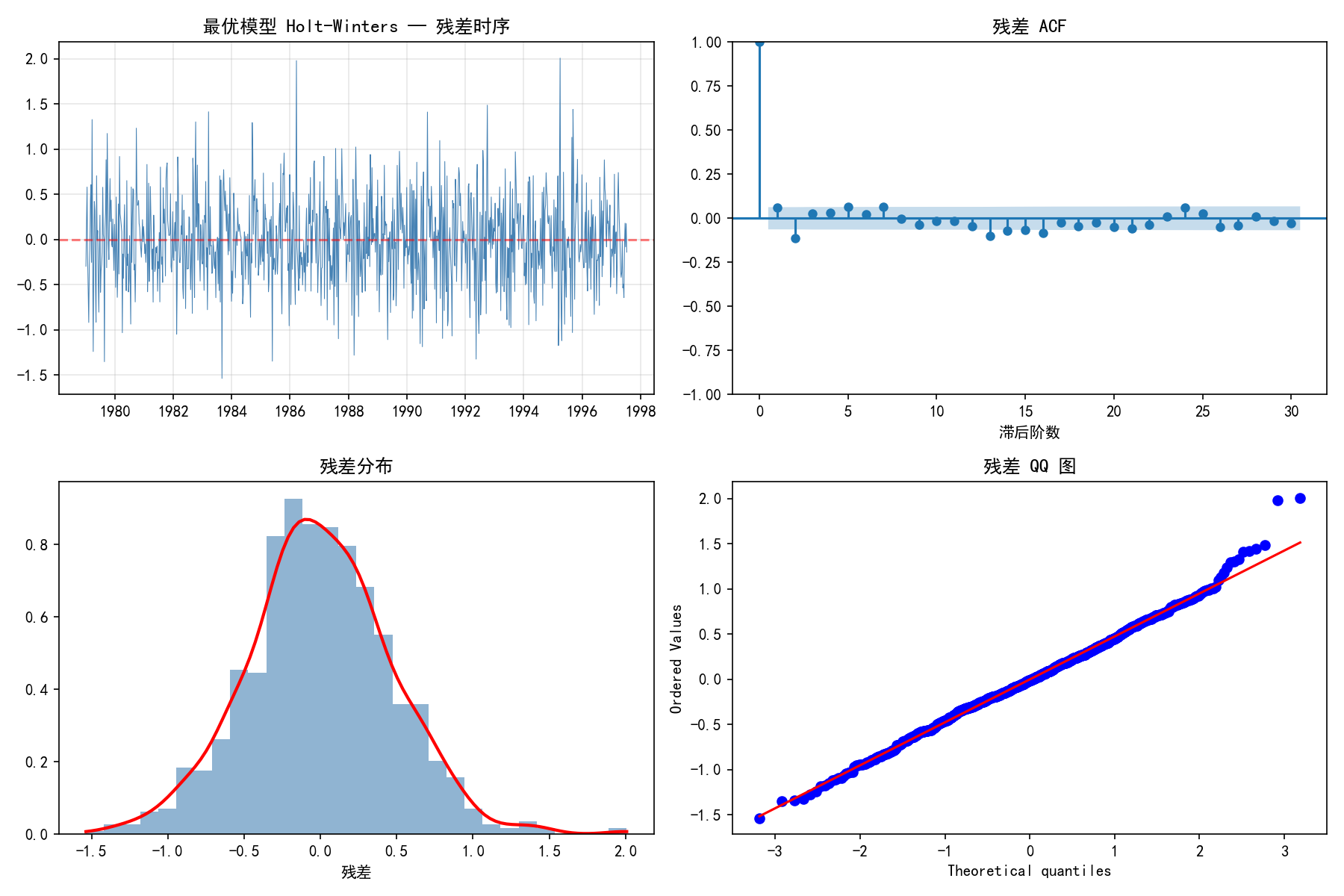
诊断结果:
残差时序:围绕 0 随机波动,无明显模式
残差 ACF:大部分在置信区间内
残差分布:近似正态
QQ 图:大部分点沿对角线,尾部略有偏离
整体诊断基本通过,模型可用。
Step 6:最终预测
用全部数据重新拟合最优模型,对未来做出预测:
# 用全数据拟合
full_model = SARIMAX(series, order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False)
# 预测未来 12 个月
forecast = full_model.get_forecast(steps=12)
forecast_mean = forecast.predicted_mean
forecast_ci = forecast.conf_int()
# 生成未来日期
last_date = series.index[-1]
future_dates = pd.date_range(last_date, periods=13, freq='MS')[1:]
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(series.index, series.values, label='历史数据', linewidth=1.0)
ax.plot(future_dates, forecast_mean, label='未来 12 个月预测',
linewidth=1.5, color='red')
ax.fill_between(future_dates, forecast_ci.iloc[:, 0], forecast_ci.iloc[:, 1],
color='red', alpha=0.15, label='95% 置信区间')
ax.set_xlabel('年份')
ax.set_ylabel('CO2 浓度')
ax.set_title('最终预测 — SARIMA(1,1,1)(1,1,1,12)')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
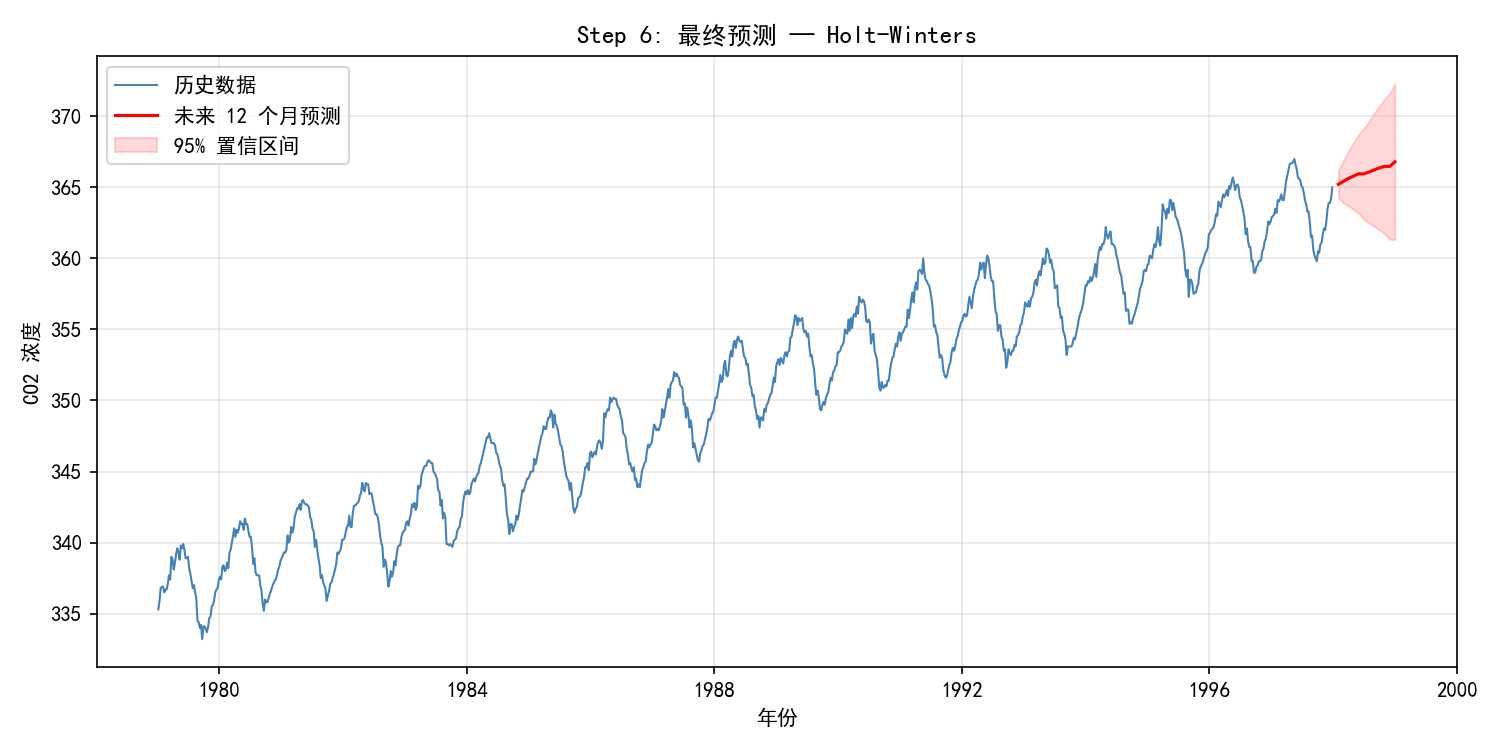
预测结果:
红色线为点预测,呈现季节性锯齿状增长
红色阴影为 95% 置信区间,随预测步数逐渐扩大
预测值范围约 363–367 ppm(2026 年 5 月约 365 ppm)
8.3 完整代码模板
以下是一个可以直接套用的完整模板:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.seasonal import seasonal_decompose
from sklearn.metrics import mean_absolute_error, mean_squared_error
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# ===== 1. 加载数据 =====
# series = pd.read_csv('your_data.csv', index_col=0, parse_dates=True)['value']
series = sm.datasets.co2.load_pandas().data['co2'].iloc[-200:]
# ===== 2. 数据探索 =====
decomp = seasonal_decompose(series, model='additive', period=12)
# 观察趋势和季节性
# ===== 3. 平稳性检验 =====
adf_p = adfuller(series)[1]
d = 0 if adf_p < 0.05 else 1
if d > 0:
diff_series = series.diff(d).dropna()
# ===== 4. 参数识别 =====
# plot_acf(diff_series); plot_pacf(diff_series, method='ywm')
# ===== 5. 模型拟合 =====
candidates = {}
for p in range(0, 4):
for q in range(0, 4):
try:
m = ARIMA(series, order=(p, d, q)).fit()
candidates[f'ARIMA({p},{d},{q})'] = m
except:
pass
# 选 AIC 最优
best_name = min(candidates, key=lambda k: candidates[k].aic)
best_model = candidates[best_name]
# ===== 6. 预测 =====
test_size = 24
train = series.iloc[:-test_size]
test = series.iloc[-test_size:]
# 重新拟合(仅用训练集)
final_model = ARIMA(train, order=best_model.order).fit()
pred = final_model.get_forecast(steps=test_size).predicted_mean
print(f"最优模型: {best_name}")
print(f"MAE: {mean_absolute_error(test, pred):.3f}")
print(f"RMSE: {np.sqrt(mean_squared_error(test, pred)):.3f}")
8.4 数模竞赛实用建议
8.4.1 模型选择决策树
有季节性?
├─ 否 → ARIMA
│ ├─ 短期预测 → ARIMA
│ └─ 长期预测 → 考虑阻尼趋势
─ 是 → SARIMA 或 Holt-Winters
├─ 季节规则稳定 → SARIMA
├─ 需要快速建模 → Holt-Winters
└─ 有外部变量 → SARIMAX
8.4.2 论文写作要点
数据描述:说明数据来源、时间范围、频率、样本量
探索性分析:时序图 + 季节性分解图
平稳性检验:报告 ADF 统计量和 p-value
模型选择理由:为什么选这个模型?AIC/BIC 对比
参数估计:报告显著性(p-value)
残差诊断:ACF 图 + Ljung-Box 检验结果
预测精度:MAE/RMSE/MAPE 表格
预测结果:点预测 + 置信区间图
8.4.3 常见陷阱
8.5 本章小结
本章完整演示了从数据探索到最终预测的全流程。核心要点:
先看图,再建模——可视化是理解数据的第一步
先检验,再差分——用 ADF 确定最小差分阶数
多模型对比——不要只拟合一个模型
残差诊断不可少——确保模型假设成立
样本外评估——测试集精度比训练集更重要
报告置信区间——点预测 + 区间才是完整预测
8.6 实用技巧速查
附录:完整代码获取
本教程所有代码均可通过以下链接下载: