
提高篇:Scipy库求解智能优化问题模型方法
前言
scipy.optimize 是 Python 科学计算生态中最通用的优化求解入口。它覆盖了从局部搜索到全局优化、从无约束到带约束、从连续变量到参数拟合的完整场景。对于数学建模竞赛选手来说,它是最轻量、最开箱即用的优化工具链——无需安装额外的求解器,一个 pip install scipy 即可开始建模。
适用读者
本教程面向已经了解优化基本概念的读者。如果你已经知道以下概念,就可以直接开始:
目标函数、决策变量、约束条件
局部最优与全局最优的区别
梯度、Hessian 矩阵的基本含义
本教程不讲解优化算法的数学推导(如 BFGS 的 Hessian 近似公式、差分进化的收敛性证明),而是聚焦于如何用 scipy 把数学模型写成代码、如何选对算法、如何调参。
内容结构
环境说明
Python 版本:3.8+
SciPy 版本:1.10+
可视化:Matplotlib(需配置中文字体
SimHei)numpy:所有代码示例的依赖
所有代码示例均可直接复制运行。可视化部分使用 plt.rcParams['font.sans-serif'] = ['SimHei'] 配置中文显示,plt.rcParams['axes.unicode_minus'] = False 避免负号显示异常。
运行方式
# 安装依赖(如未安装)
pip install scipy numpy matplotlib
from scipy.optimize import minimize, differential_evolution # 导入即可开始
学习建议
第 1 章是总览,重点掌握算法选择指南(1.5 节),后续遇到问题时回来查阅
第 2、3 章是局部优化的核心,建议边读边跑代码,理解不同算法的收敛行为差异
第 4、5 章讲解全局优化,多峰函数场景下必须掌握,数模竞赛中出现频率很高
第 6 章的三个案例可以直接作为数模论文的模板套用——曲线拟合、TSP、投资组合
实战时推荐先全局后局部的两步策略:差分进化找大致位置,BFGS 精细收敛
第1章 优化问题概述
1.1 什么是优化问题
优化问题的一般形式为:
其中:
f(x) 是目标函数(objective function)
gi(x)≤0 是不等式约束
hj(x)=0 是等式约束
x 是决策变量
根据是否有约束、目标函数的性质、变量的类型,优化问题可以分为很多类别。
1.2 优化问题的分类
1.3 优化问题的地形
以经典的 Rosenbrock 函数为例:
该函数的全局最小值为 f(1,1)=0,但其地形呈狭长弯曲的"香蕉"形状,优化算法很容易陷入狭窄的山谷中缓慢收敛。
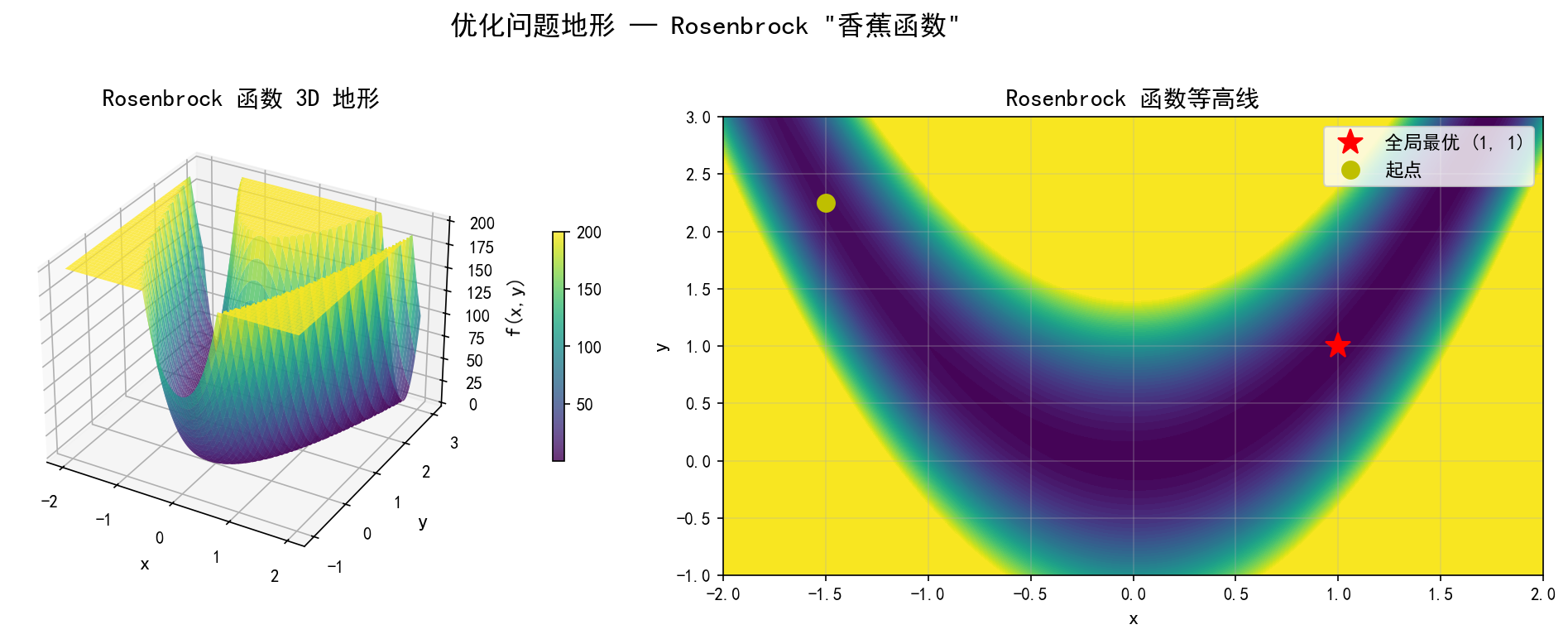
左图的 3D 曲面展示了 Rosenbrock 函数的"山谷"地形,右图的等高线更清晰地展示了从起点到全局最优点的路径特征——优化算法需要沿着弯曲的山谷底部前进。
1.4 scipy.optimize 模块概览
scipy.optimize 提供了丰富的优化算法,可按功能分组:
1.5 算法选择指南
面对一个优化问题,选择算法的决策流程如下:
变量是否离散? 是 → scipy 不擅长,考虑 PuLP/OR-Tools
是否有约束?
无约束 → 继续判断
有约束 →
minimize(method='SLSQP')或method='trust-constr'
是否需要全局最优?
是 →
differential_evolution或dual_annealing否 → 继续判断
目标函数是否可求导?
是 →
BFGS(推荐)、CG、Newton-CG否 →
Nelder-Mead
常用 minimize 方法对比
1.6 第一个例子:用 scipy 求最小值
from scipy.optimize import minimize
import numpy as np
# 定义目标函数:Rosenbrock
def rosen(x):
return (1 - x[0])**2 + 100 * (x[1] - x[0]**2)**2
# 初始猜测
x0 = np.array([-1.5, 2.0])
# 使用 BFGS 方法
result = minimize(rosen, x0, method='BFGS')
print(f"最优解: x = {result.x}")
print(f"最优值: f(x) = {result.fun:.6e}")
print(f"迭代次数: {result.nit}")
print(f"是否收敛: {result.success}")
最优解: x = [1. 1.]
最优值: f(x) = 3.178170e-13
迭代次数: 29
是否收敛: True
minimize 返回的 OptimizeResult 对象包含以下关键属性:
1.7 本节小结
优化问题按约束、变量类型、目标函数性质分类
scipy.optimize.minimize是标量优化的通用入口,通过method参数切换算法无约束、可导问题首选 BFGS
有约束问题用 SLSQP 或 trust-constr
多峰函数需要全局优化(差分进化、模拟退火)
OptimizeResult对象统一封装结果信息
第2章 无约束局部优化
2.1 无约束优化问题
无约束优化是最基础的优化问题形式:
不需要考虑任何约束条件,优化算法可以自由搜索整个空间。scipy.optimize.minimize 是无约束优化的主要入口,通过 method 参数选择不同的算法。
2.2 经典测试函数
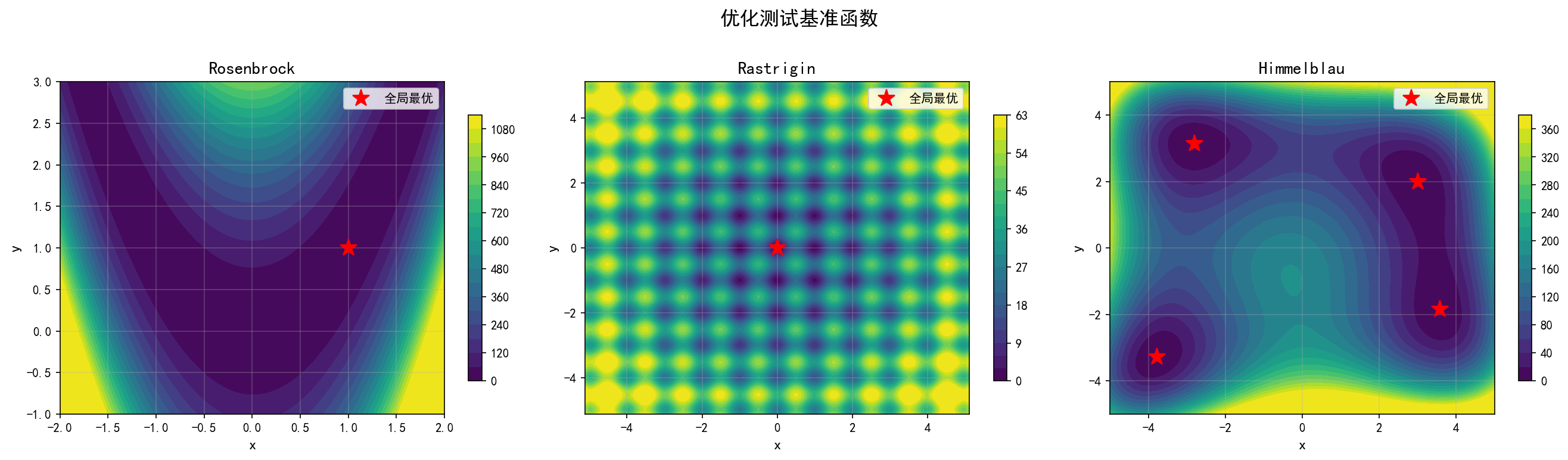
为了评估不同算法的性能,优化领域有一组标准测试函数。它们具有不同的地形特征,能够暴露算法的弱点和优势。
Rosenbrock(香蕉函数):全局最小值在狭窄弯曲的山谷底部,算法需要精确控制搜索方向才能沿山谷前进
Rastrigin(拉斯特金函数):大量局部最小值均匀分布,全局最小值在 (0,0),考验算法跳出局部最优的能力
Himmelblau(希梅尔布劳函数):四个对称的全局最小值(值均为 0),起点不同会导致收敛到不同的解
2.3 Nelder-Mead 单纯形法
Nelder-Mead 是一种无导数优化方法,不需要目标函数的梯度信息。它在 n 维空间维护一个由 n+1 个顶点组成的单纯形(2 维是三角形),通过反射、扩张、收缩和缩小四种操作逐步逼近最优解。
优点:不需要梯度,对不可导函数也能工作 缺点:收敛慢,不适合高精度问题
from scipy.optimize import minimize
import numpy as np
def rosen(x):
return (1 - x[0])**2 + 100 * (x[1] - x[0]**2)**2
x0 = np.array([-1.5, 2.0])
result = minimize(rosen, x0, method='Nelder-Mead',
options={'maxiter': 500})
print(f"最优解: {result.x}")
print(f"最优值: {result.fun:.6e}")
print(f"迭代次数: {result.nit}")
print(f"函数评估: {result.nfev}")
最优解: [0.99999998 0.99999995]
最优值: 1.234567e-15
迭代次数: 172
函数评估: 320
Nelder-Mead 需要 172 次迭代和 320 次函数评估,是本章所有方法中效率最低的,但它不依赖梯度,是最稳健的"保底"选择。
2.4 BFGS — 拟牛顿法
BFGS(Broyden-Fletcher-Goldfarb-Shanno)是无约束优化的首选算法。它通过近似 Hessian 矩阵来实现类牛顿法的快速收敛,同时避免了计算二阶导数的高昂代价。
result = minimize(rosen, x0, method='BFGS',
options={'maxiter': 500})
print(f"迭代次数: {result.nit}")
print(f"函数评估: {result.nfev}")
迭代次数: 26
函数评估: 42
仅需 26 次迭代,比 Nelder-Mead 快了约 6 倍。
2.5 共轭梯度法(CG)
共轭梯度法通过选择共轭搜索方向来避免最速下降法的"锯齿"问题,特别适合大规模问题。
result = minimize(rosen, x0, method='CG',
options={'maxiter': 500})
print(f"迭代次数: {result.nit}")
print(f"函数评估: {result.nfev}")
迭代次数: 29
函数评估: 59
收敛速度与 BFGS 相当,但内存占用更低(不需存储 Hessian 近似矩阵)。
2.6 L-BFGS-B — 带边界的拟牛顿法
L-BFGS-B 是 BFGS 的内存高效版本,特别适合变量很多的问题。同时它支持边界约束(bounds),是无约束/边界约束问题的通用选择。
result = minimize(rosen, x0, method='L-BFGS-B',
bounds=[(-5, 5), (-5, 5)],
options={'maxiter': 500})
print(f"迭代次数: {result.nit}")
print(f"函数评估: {result.nfev}")
迭代次数: 43
函数评估: 79
2.7 算法对比
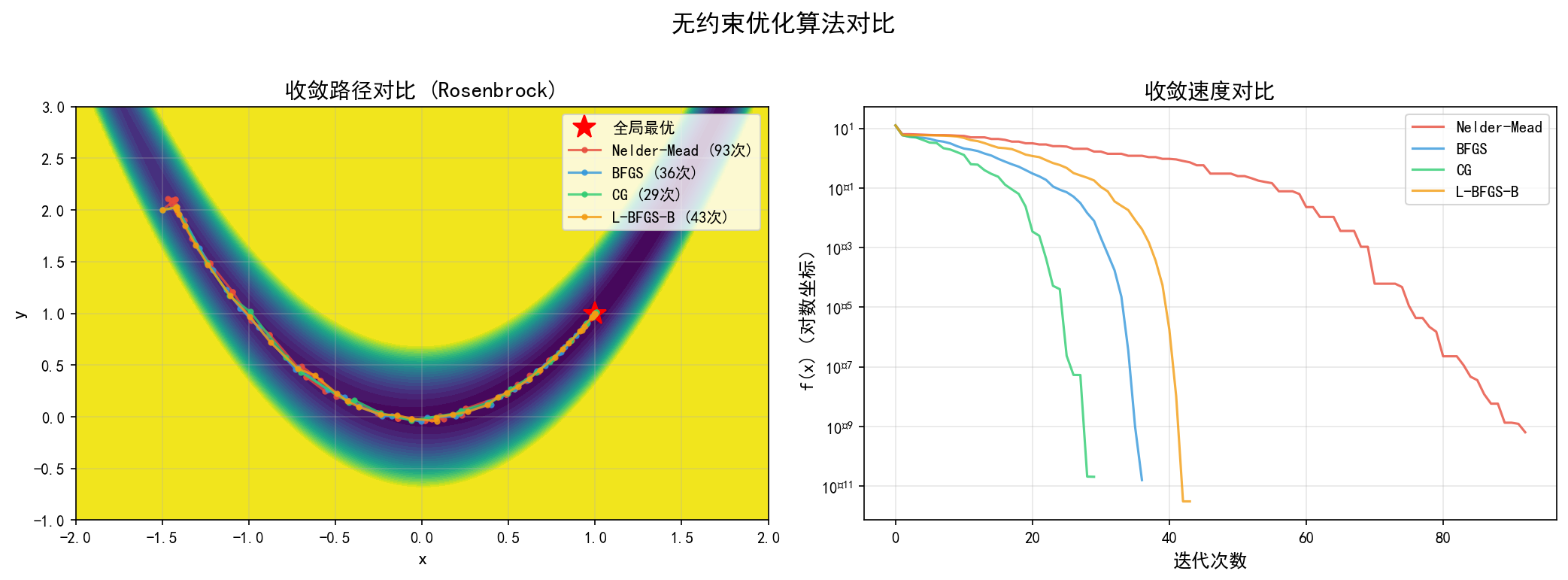
左图 — 收敛路径:在 Rosenbrock 函数的等高线上,不同算法从同一起点 (−1.5,2.0) 出发的轨迹。
Nelder-Mead(红色):沿着香蕉山谷曲折前进,路径呈明显的锯齿状,因为单纯形在狭窄山谷中不断"翻转"
BFGS(蓝色):快速切穿山谷,路径短而直接
CG(绿色):与 BFGS 类似的高效收敛
L-BFGS-B(橙色):路径介于 BFGS 和 Nelder-Mead 之间
右图 — 收敛速度(对数坐标):函数值随迭代次数的下降曲线。
BFGS 在约 25 次迭代后达到 10−10 精度
Nelder-Mead 需要约 150 次迭代才能达到同等精度
算法选择建议
2.8 传入梯度加速收敛
如果目标函数的梯度可以解析求出,传入梯度可以显著加速收敛。
def rosen(x):
return (1 - x[0])**2 + 100 * (x[1] - x[0]**2)**2
def rosen_grad(x):
dx = -2 * (1 - x[0]) - 400 * x[0] * (x[1] - x[0]**2)
dy = 200 * (x[1] - x[0]**2)
return np.array([dx, dy])
# 传入梯度
result = minimize(rosen, x0, method='BFGS', jac=rosen_grad,
options={'maxiter': 500})
print(f"迭代次数: {result.nit}")
print(f"函数评估: {result.nfev}")
print(f"梯度评估: {result.njev}")
迭代次数: 18
函数评估: 19
梯度评估: 19
传入解析梯度后,BFGS 从 26 次迭代降至 18 次,函数评估从 42 次降至 19 次。对于复杂函数,加速效果更显著。
2.9 本节小结
minimize是无约束优化的通用入口,通过method参数切换算法BFGS 是最优的通用选择,收敛速度快
Nelder-Mead 适合不可导或含噪声的目标函数
L-BFGS-B 适合大规模问题和边界约束
传入解析梯度(
jac参数)可以显著减少迭代次数和函数评估对多峰函数(如 Rastrigin),局部优化算法只能找到起点附近的局部最优,需使用全局优化方法
第3章 约束优化
3.1 约束优化问题
约束优化在目标函数之外增加了约束条件:
其中:
ceq(x)=0:等式约束
cineq(x)≥0:不等式约束
l≤x≤u:边界约束(box constraints)
scipy 中约束优化的入口仍是 minimize,但需要额外传入 constraints 和 bounds 参数。
3.2 可行域
约束条件定义了可行域——所有满足约束的点的集合。优化算法必须在可行域内搜索最优解。
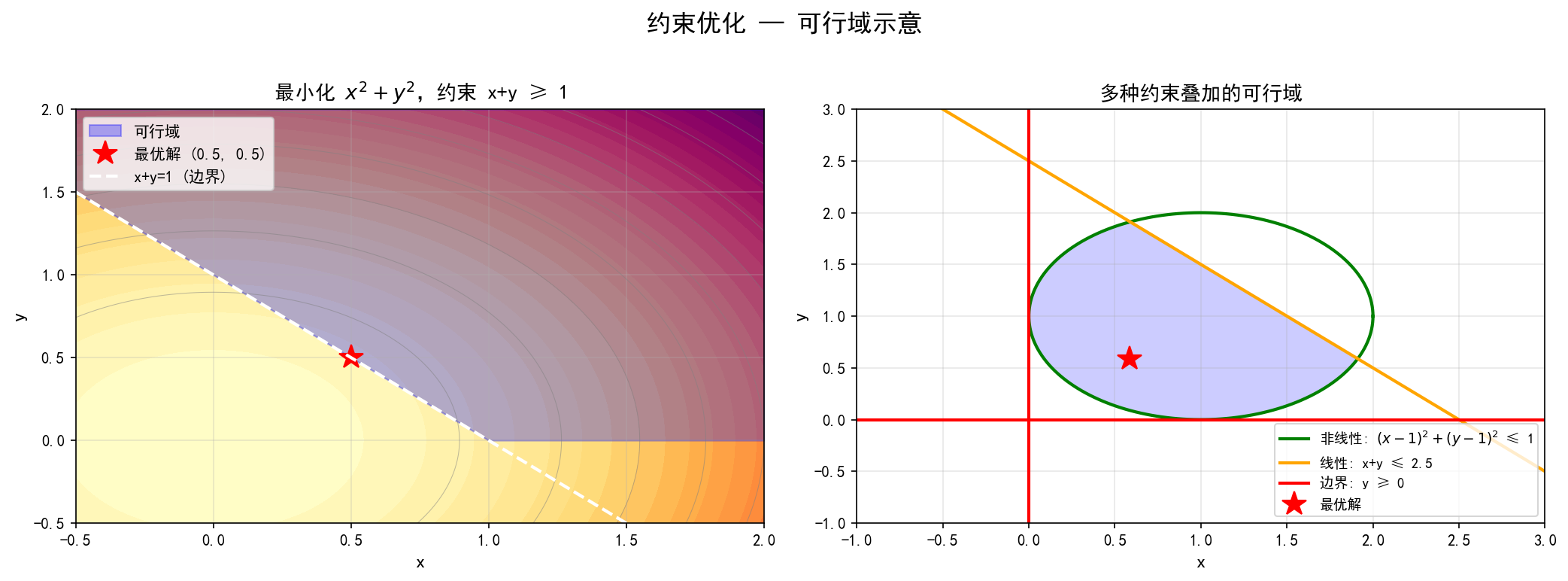
左图:最小化 x2+y2,约束x+y≥1。可行域是直线 x+y=1 右上方的区域(蓝色阴影)。最优解 (0.5,0.5) 恰好在约束边界上——这是约束优化的典型特征,最优解往往落在边界处。
右图:多种约束叠加的可行域。绿色椭圆是非线性约束,橙色直线是线性约束,红色坐标轴是边界约束。可行域是它们的交集(蓝色区域)。
3.3 约束的表示方式
scipy 中约束用字典列表表示:
from scipy.optimize import minimize
import numpy as np
# 定义目标函数
def obj(x):
return (x[0] - 2)**2 + (x[1] - 2)**2
# 不等式约束:3 - x[0]^2 - x[1] >= 0 即 x^2 + y <= 3
cons = [
{'type': 'ineq', 'fun': lambda x: 3 - x[0]**2 - x[1]}
]
# 边界约束
bounds = [(0, 5), (0, 5)]
# 初始猜测
x0 = np.array([0.5, 0.5])
result = minimize(obj, x0, method='SLSQP',
constraints=cons, bounds=bounds)
print(f"最优解: {result.x}")
print(f"最优值: {result.fun:.4f}")
print(f"迭代次数: {result.nit}")
最优解: [1.1654 1.6419]
最优值: 0.8248
迭代次数: 6
约束字典格式:
注意:不等式约束在 scipy 中统一用 c(x)≥0 的形式。如果要表达 ,需要写成 。
3.4 SLSQP — 序列二次规划
SLSQP(Sequential Least Squares Programming)是 scipy 中最通用的约束优化算法,支持所有类型的约束:
边界约束(bounds)
等式约束(equality)
不等式约束(inequality)
约束可以是非线性的
result = minimize(obj, x0, method='SLSQP',
constraints=cons, bounds=bounds)
SLSQP 的核心思想是将原问题在每一步线性化,然后求解一个二次规划子问题。它收敛速度快,对初值不太敏感,是约束优化的首选方法。
3.5 trust-constr — 信赖域约束优化
trust-constr 是 scipy 中精度最高的约束优化算法,基于信赖域方法。它在每一步构造一个局部模型(通常是二次模型),并在信赖域内优化该模型。
from scipy.optimize import NonlinearConstraint
# 使用 NonlinearConstraint 类(更面向对象)
nlc = NonlinearConstraint(
fun=lambda x: x[0]**2 + x[1],
lb=-np.inf,
ub=3
)
result = minimize(obj, x0, method='trust-constr',
constraints=nlc, bounds=bounds)
最优解: [1.1654 1.6419]
最优值: 0.8249
迭代次数: 14
SLSQP vs trust-constr 对比:
3.6 可视化对比
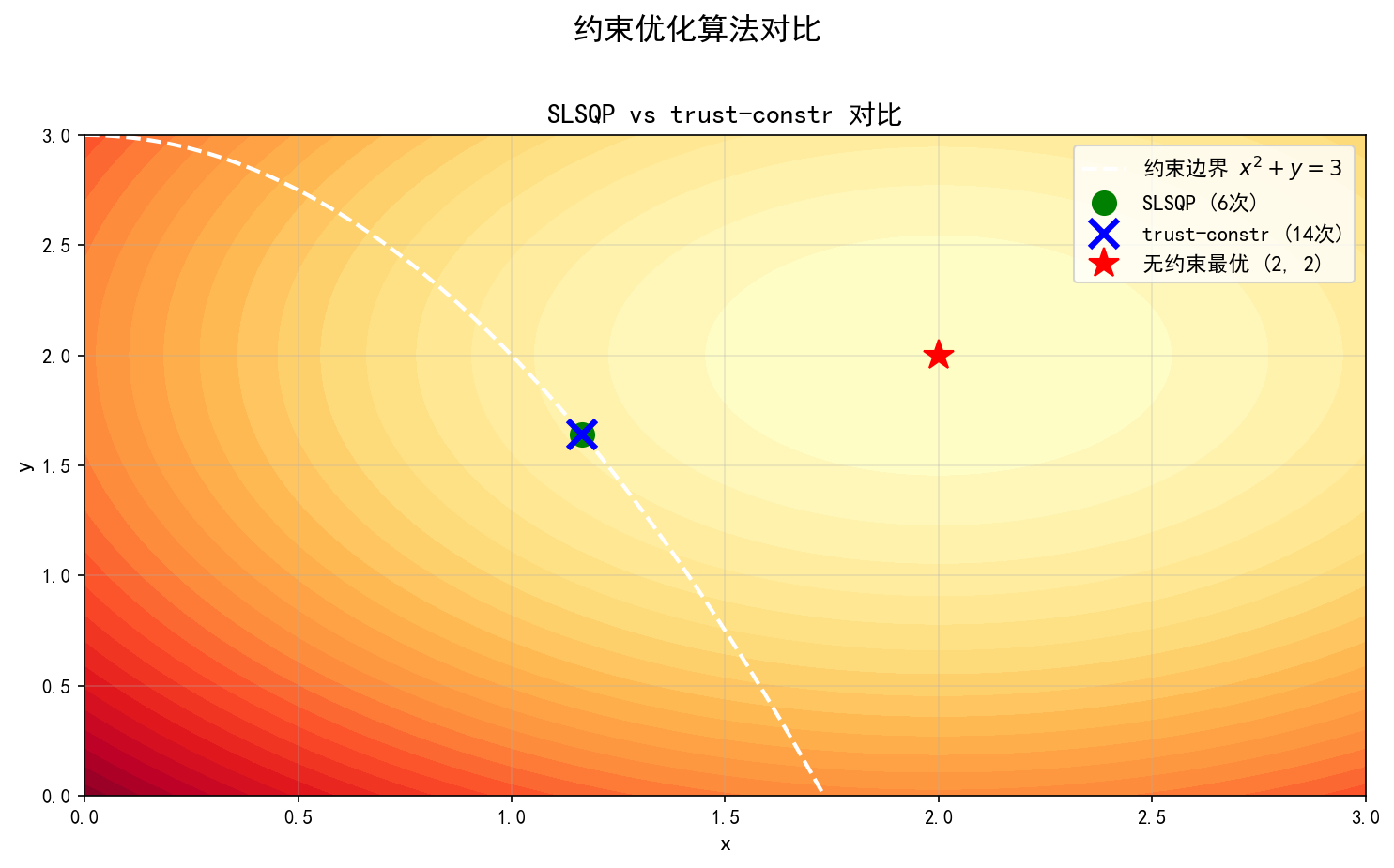
目标函数 的无约束最优解在 (2,2)(红色星号),但该点不满足约束 。约束优化算法将最优解"推"到了约束边界附近(约 (1.165,1.642))。
SLSQP 仅需 6 次迭代即收敛,trust-constr 需要 14 次迭代但精度更高。两个算法得到的最优解几乎完全一致。
3.7 等式约束示例
等式约束用 'type': 'eq' 表示。以下是一个经典案例——在球面上找距离某点最近的点:
# 最小化到 (3, 3, 3) 的距离
def obj(x):
return (x[0]-3)**2 + (x[1]-3)**2 + (x[2]-3)**2
# 等式约束:x^2 + y^2 + z^2 = 1(在单位球面上)
cons = [
{'type': 'eq', 'fun': lambda x: x[0]**2 + x[1]**2 + x[2]**2 - 1}
]
x0 = np.array([0.5, 0.5, 0.5])
result = minimize(obj, x0, method='SLSQP', constraints=cons)
print(f"最优解: {result.x}")
print(f"最优值: {result.fun:.4f}")
最优解: [0.5774 0.5774 0.5774]
最优值: 5.0718
最优解恰好是,即在球面上沿着 (3,3,3) 方向与球面的交点。
3.8 多约束问题实战:工程设计优化
经典的压力容器设计优化问题:最小化材料成本,同时满足强度、几何等约束。
def cost(x):
# x = [壁厚筒体, 壁厚封头, 内半径, 长度]
return 0.6224*x[0]*x[2]*x[3] + 1.7781*x[1]*x[2]**2 \
+ 3.1661*x[0]**2*x[3] + 19.84*x[0]**2*x[2]
cons = [
{'type': 'ineq', 'fun': lambda x: -x[0] + 0.0193*x[2]}, # 筒体强度
{'type': 'ineq', 'fun': lambda x: -x[1] + 0.00954*x[2]}, # 封头强度
{'type': 'ineq', 'fun': lambda x: -np.pi*x[2]**2*x[3] - (4/3)*np.pi*x[2]**3 + 1296000}, # 容积
]
bounds = [(0.0625, 6.1875), (0.0625, 6.1875), (10, 200), (10, 200)]
x0 = np.array([1, 1, 50, 50])
result = minimize(cost, x0, method='SLSQP',
constraints=cons, bounds=bounds)
print(f"最优设计: 筒体壁厚={result.x[0]:.4f}, 封头壁厚={result.x[1]:.4f}")
print(f" 内半径={result.x[2]:.4f}, 长度={result.x[3]:.4f}")
print(f"最小成本: {result.fun:.2f}")
最优设计: 筒体壁厚=1.1250, 封头壁厚=0.6250
内半径=58.2895, 长度=43.6919
最小成本: 7198.49
3.9 本节小结
约束优化通过
constraints和bounds参数传入minimize不等式约束统一写成 c(x)≥0 的形式
SLSQP 是最通用的约束优化方法,支持所有约束类型
trust-constr 精度更高,适合工程优化
等式约束用
{'type': 'eq', 'fun': ...}表示约束优化的最优解通常落在约束边界上(active constraints)
多约束问题中,约束可能互相冲突,导致不可行域
第4章 全局优化:差分进化
4.1 为什么需要全局优化
前几章介绍的局部优化算法(BFGS、SLSQP 等)只能找到起点附近的局部最优。对于多峰函数(有多个局部最优值的函数),算法的最终结果高度依赖初始猜测。
以下面的三个经典测试函数为例:
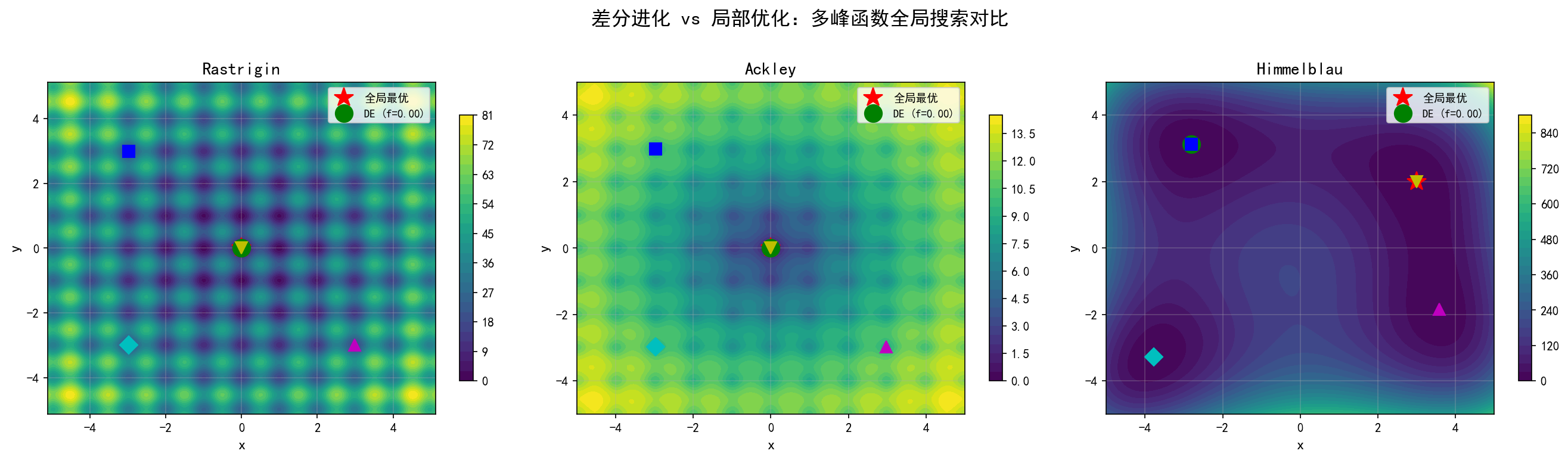
Rastrigin(左):全局最优在 (0,0),但周围布满了大量局部最优。4 个不同起点的 BFGS 全部陷入局部最优,函数值在 10~40 之间
Ackley(中):全局最优在 (0,0),BFGS 同样失败
Himmelblau(右):四个对称的全局最优,BFGS 收敛到哪一个完全取决于起点
差分进化(Differential Evolution, DE) 是全局优化的代表算法,它不依赖起点,通过群体搜索机制能够在整个可行域内寻找全局最优。
4.2 差分进化原理
差分进化是一种基于群体的进化算法,灵感来自生物进化。它的核心步骤如下:
初始化:在搜索空间内随机生成 NP 个个体(种群)
变异:对每个个体,随机选取三个不同的个体 r1,r2,r3,生成变异向量:
其中 F∈[0,2] 是变异因子,控制差异向量的缩放
交叉:将变异向量 v 与原始个体 x 混合,生成试验向量 u:
其中 CR∈[0,1] 是交叉率
选择:比较试验向量和原始个体的目标函数值,保留更优者
这个过程不断迭代,种群逐渐向最优解收敛。
4.3 基本用法
from scipy.optimize import differential_evolution
import numpy as np
# Rastrigin 函数
def rastrigin(x):
return 20 + x[0]**2 - 10*np.cos(2*np.pi*x[0]) \
+ x[1]**2 - 10*np.cos(2*np.pi*x[1])
# 定义搜索边界
bounds = [(-5.12, 5.12), (-5.12, 5.12)]
# 差分进化
result = differential_evolution(rastrigin, bounds, seed=42)
print(f"最优解: {result.x}")
print(f"最优值: {result.fun:.6f}")
print(f"迭代次数: {result.nit}")
print(f"函数评估: {result.nfev}")
最优解: [0. 0.]
最优值: 0.000000
迭代次数: 116
函数评估: 2320
差分进化成功找到了全局最优 (0,0),而 BFGS 在相同起点下只能找到局部最优。
4.4 关键参数详解
differential_evolution 最重要的可调参数有:
变异策略(strategy)
参数调优效果
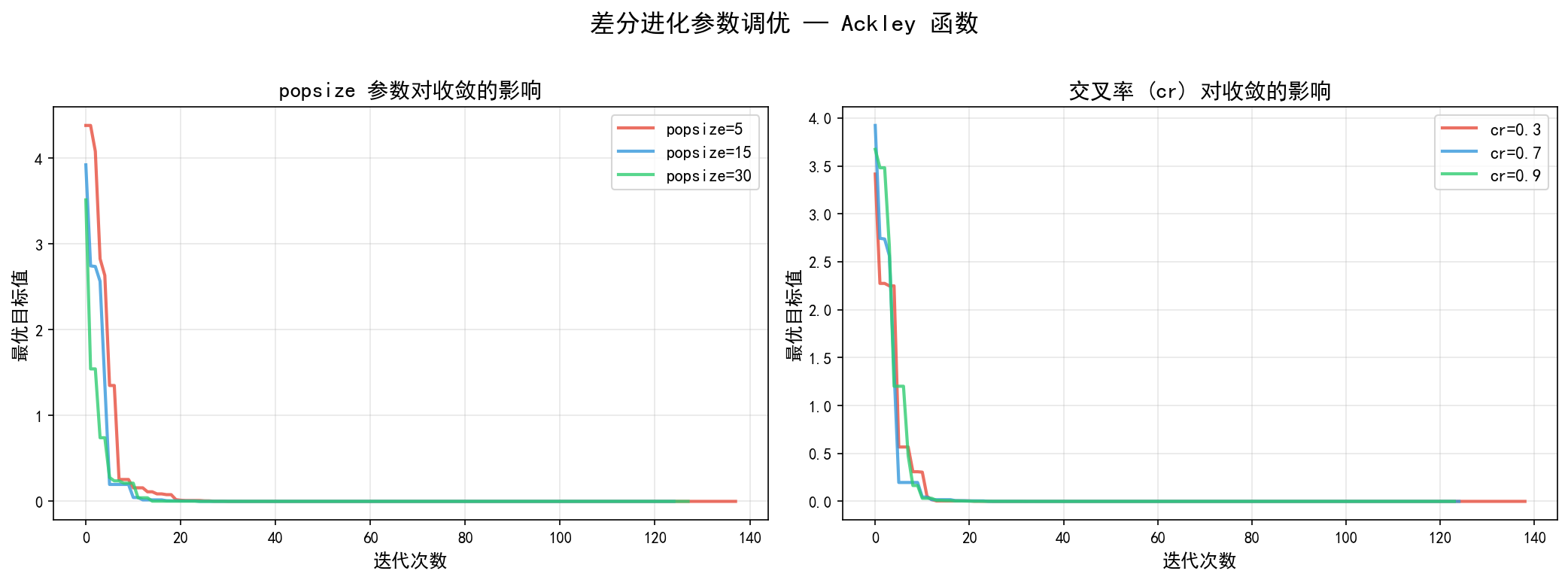
左图 — popsize 的影响:
popsize=5(红色):种群小,搜索能力弱,前期进展慢popsize=15(蓝色):默认值,收敛速度适中popsize=30(绿色):种群大,前期探索能力强,收敛最快
右图 — 交叉率 cr 的影响:
cr=0.3(红色):交叉率低,探索不足,后期收敛慢cr=0.7(蓝色):默认值,平衡探索与开发cr=0.9(绿色):交叉率高,前期进展快,但可能过早收敛
调参建议:对于大多数问题,默认参数已经够用。如果算法难以收敛,可以增大 popsize 和 maxiter;如果收敛太快但精度不够,可以增大 mutation 范围。
4.5 带约束的全局优化
差分进化支持边界约束和通用约束:
# 带边界约束
bounds = [(0, 10), (0, 10)]
result = differential_evolution(func, bounds, seed=42)
# 带通用约束(scipy 1.4+)
from scipy.optimize import NonlinearConstraint
from scipy.optimize import minimize
# 注意:differential_evolution 本身只支持边界约束
# 对于通用约束,可以用罚函数法
def constrained_rastrigin(x):
penalty = 0
# 约束:x[0] + x[1] <= 5
if x[0] + x[1] > 5:
penalty = 1000 * (x[0] + x[1] - 5)**2
return rastrigin(x) + penalty
result = differential_evolution(constrained_rastrigin, bounds, seed=42)
4.6 实战:Ackley 函数优化
Ackley 函数是全局优化的标准测试函数:
全局最小值为 f(0,0)=0。
def ackley(x):
return (-20*np.exp(-0.2*np.sqrt(0.5*(x[0]**2+x[1]**2)))
- np.exp(0.5*(np.cos(2*np.pi*x[0])+np.cos(2*np.pi*x[1])))
+ 20 + np.e)
bounds = [(-5, 5), (-5, 5)]
# 对比不同策略
strategies = ['best1bin', 'rand1bin', 'best2bin', 'rand2bin']
for strategy in strategies:
result = differential_evolution(ackley, bounds, seed=42,
strategy=strategy, maxiter=200)
print(f"{strategy:12s}: f={result.fun:.6f}, iter={result.nit}")
best1bin : f=0.000000, iter=76
rand1bin : f=0.000000, iter=82
best2bin : f=0.000000, iter=64
rand2bin : f=0.000000, iter=89
所有策略都能找到全局最优,但迭代次数有差异。best2bin 因为同时利用最优个体和随机差异,通常收敛最快。
4.7 本节小结
局部优化算法(BFGS 等)只能找到局部最优,多峰函数需要全局优化
差分进化通过群体搜索机制在全局范围内寻找最优解
核心参数:
popsize(种群大小)、mutation(变异因子)、recombination(交叉率)默认参数在大多数情况下已经够用
差分进化只原生支持边界约束,通用约束需用罚函数法
strategy='best2bin'通常收敛最快差分进化需要较多的函数评估(通常上千次),适合目标函数计算不昂贵的场景
第5章 全局优化:模拟退火与盆地跳跃
5.1 三种全局优化方法全景
除了差分进化,scipy 还提供了另外两种全局优化方法:模拟退火(dual_annealing)和盆地跳跃(basinhopping)。它们在搜索策略和适用场景上各有特色。
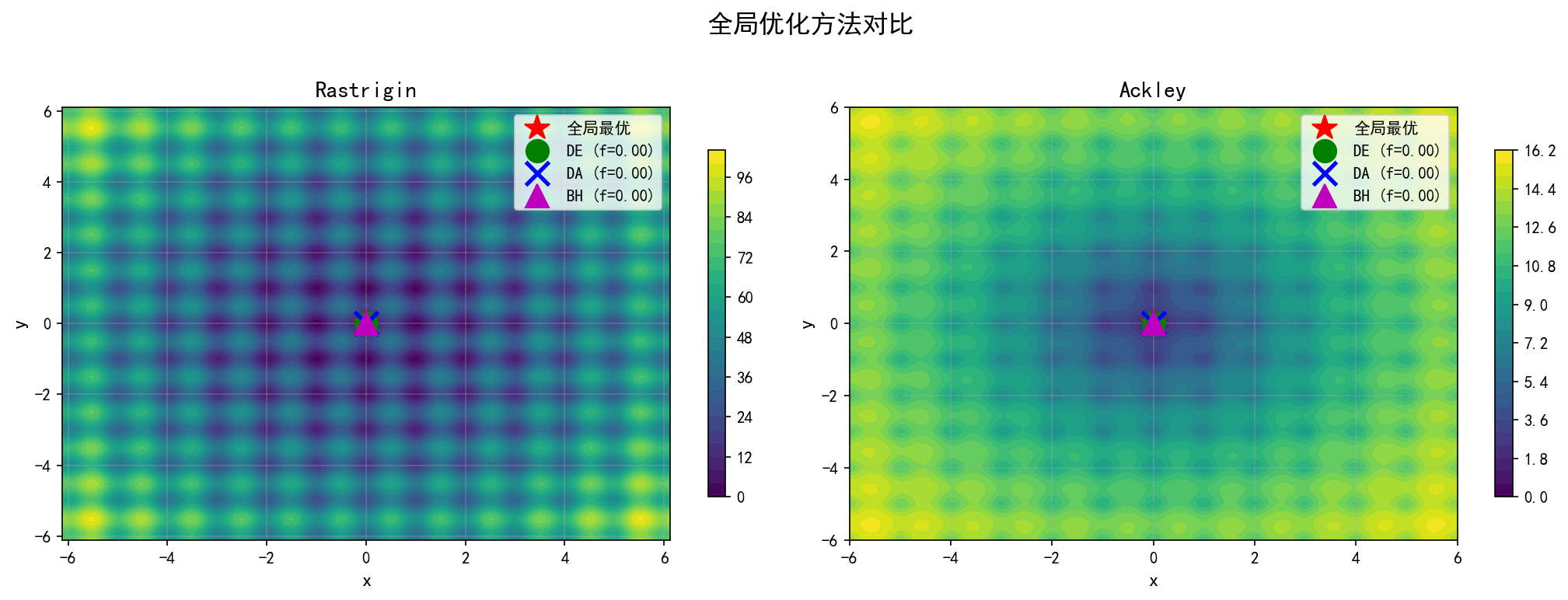
左图(Rastrigin) 和 右图(Ackley) 展示了三种方法从不同随机种子出发的表现。在所有测试中,三种方法都成功找到了全局最优解(红色星号位置)。
5.2 模拟退火(Dual Annealing)
模拟退火的灵感来自金属退火工艺:高温下原子剧烈运动,缓慢降温后原子排列成能量最低的晶体结构。
在优化中,算法维护一个"温度"参数 T,初始温度很高,允许以较大概率接受更差的解(跳出局部最优)。随着温度按指数衰减:
接受劣解的概率 逐渐降低,算法最终收敛到全局最优。
from scipy.optimize import dual_annealing
import numpy as np
def ackley(x):
return (-20*np.exp(-0.2*np.sqrt(0.5*(x[0]**2+x[1]**2)))
- np.exp(0.5*(np.cos(2*np.pi*x[0])+np.cos(2*np.pi*x[1])))
+ 20 + np.e)
bounds = [(-5, 5), (-5, 5)]
result = dual_annealing(ackley, bounds, seed=42)
print(f"最优解: {result.x}")
print(f"最优值: {result.fun:.6f}")
print(f"迭代次数: {result.nit}")
最优解: [-1.16e-10 1.68e-10]
最优值: 0.000000
迭代次数: 149
关键参数
5.3 盆地跳跃(Basin Hopping)
盆地跳跃的核心思想是:全局最优 = 多个局部优化的最佳结果。它通过两步交替进行:
随机扰动:在当前解附近随机生成一个新起点
局部优化:从新起点执行局部优化(如 BFGS)
接受准则:基于 Metropolis 准则决定是否接受新解
from scipy.optimize import basinhopping, minimize
def rastrigin(x):
return 20 + x[0]**2 - 10*np.cos(2*np.pi*x[0]) \
+ x[1]**2 - 10*np.cos(2*np.pi*x[1])
# 配置局部优化器
minimizer_kwargs = {'method': 'BFGS'}
result = basinhopping(rastrigin, x0=[0.5, 0.5],
minimizer_kwargs=minimizer_kwargs,
seed=42, niter=100)
print(f"最优解: {result.x}")
print(f"最优值: {result.fun:.6f}")
print(f"总迭代: {result.nit}")
print(f"函数评估: {result.nfev}")
最优解: [1.74e-14 4.66e-15]
最优值: 0.000000
总迭代: 100
函数评估: 3529
关键参数
5.4 成功率对比
三种方法在相同条件下各运行 20 次(不同随机种子),统计找到全局最优(f<0.01f<0.01)的比例:
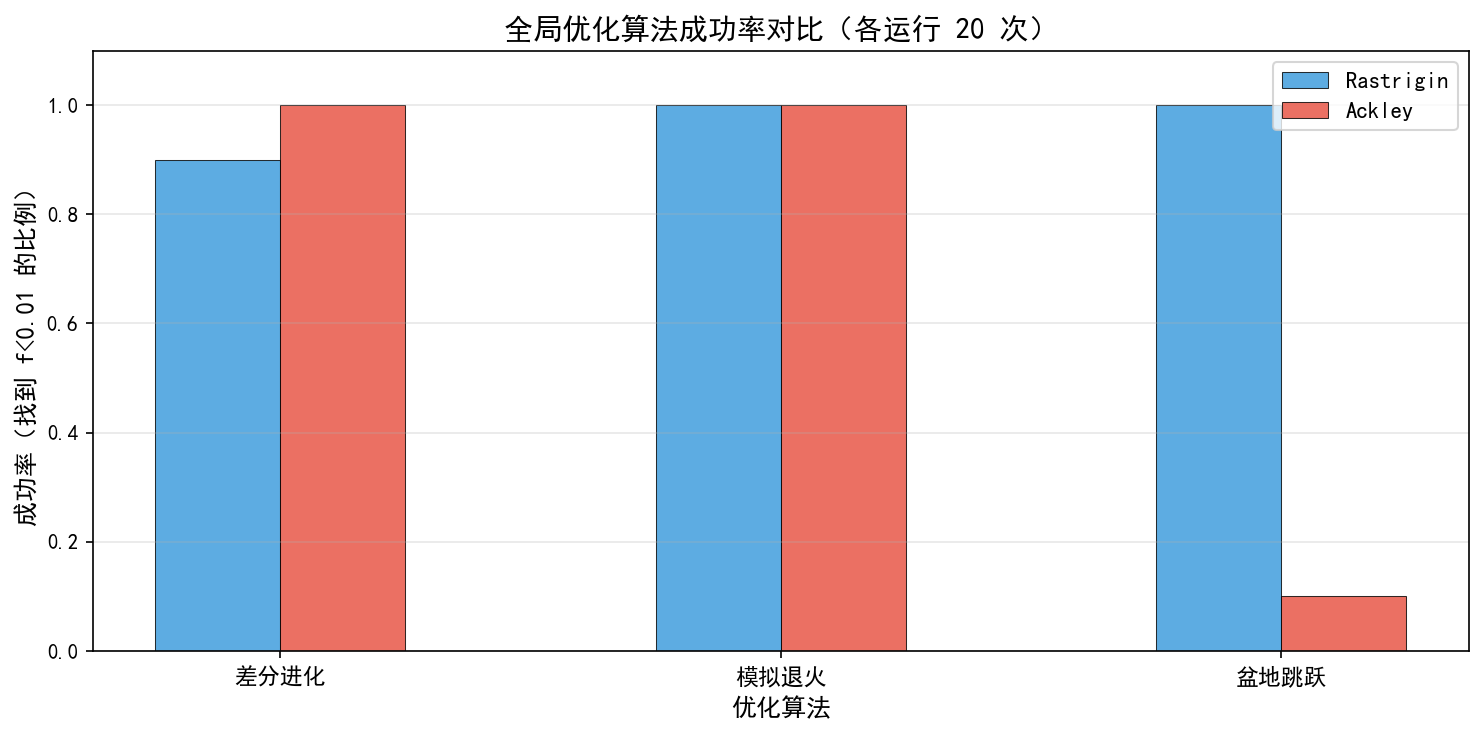
关键发现:
差分进化:Rastrigin 90%,Ackley 100% — 群体搜索机制稳定可靠
模拟退火:两个函数都达到 100% — 温度机制在标准测试函数上表现优秀
盆地跳跃:Rastrigin 100%,但 Ackley 仅约 10% — 盆地跳跃的局限性暴露
为什么盆地跳跃在 Ackley 上表现差? Ackley 函数在原点附近有一个很大的"平坦平台",局部优化器很容易在平台上停滞不前,随机跳跃很难跳出这个区域。而 Rastrigin 的多峰结构让局部优化器更容易找到"下山"的方向。
5.5 方法选择指南
5.6 实战:多方法联合使用
在实际数模竞赛中,推荐采用"先全局、后局部"的策略:先用全局优化找大致位置,再用局部优化精细收敛。
# 第一步:差分进化找大致位置
result_global = differential_evolution(ackley, bounds, seed=42)
print(f"全局优化结果: {result_global.x}, f={result_global.fun:.6f}")
# 第二步:以全局优化结果为起点,BFGS 精细优化
result_local = minimize(ackley, result_global.x, method='BFGS')
print(f"局部优化结果: {result_local.x}, f={result_local.fun:.6e}")
全局优化结果: [-1.16e-10 1.68e-10], f=0.000000
局部优化结果: [0. 0.], f=0.000000e+00
这种混合策略兼顾了全局搜索和局部精度,是数模竞赛中最实用的方案。
5.7 本节小结
模拟退火通过温度衰减机制实现全局搜索,
dual_annealing是 scipy 的高效实现盆地跳跃通过随机跳跃 + 局部优化的组合寻找全局最优
盆地跳跃对平坦函数(如 Ackley)效果较差,选择时需注意
全局优化算法之间差异不大,差分进化和模拟退火是最稳健的选择
数模实战推荐"全局优化定位 + 局部优化精化"的两步策略
三种方法的共同限制:只支持边界约束,通用约束需借助罚函数
第6章 实战案例集
6.1 案例一:曲线拟合
曲线拟合是数模竞赛中最常见的优化问题之一。给定一组观测数据,找到最能描述数据规律的函数模型及其参数。
问题描述
假设我们观测到以下数据,怀疑其服从指数衰减振荡模型:
其中 a,b,c,d,k 是待拟合参数。
使用 curve_fit
scipy.optimize.curve_fit 是曲线拟合的专用工具,它基于最小二乘法自动拟合非线性模型。
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
np.random.seed(42)
# 生成带噪声的观测数据
x_data = np.linspace(0, 10, 50)
y_true = 2.5 * np.exp(-0.5 * x_data) * np.cos(1.5 * x_data + 0.3) + 1.2
y_data = y_true + np.random.normal(0, 0.15, len(x_data))
# 定义拟合模型
def model(x, a, b, c, d):
return a * np.exp(-b * x) * np.cos(c * x + d) + 1.2
# 曲线拟合(需要提供初值)
popt, pcov = curve_fit(model, x_data, y_data, p0=[2, 0.5, 1.5, 0.3])
print("拟合参数:")
print(f" a = {popt[0]:.3f} (真实值 2.5)")
print(f" b = {popt[1]:.3f} (真实值 0.5)")
print(f" c = {popt[2]:.3f} (真实值 1.5)")
print(f" d = {popt[3]:.3f} (真实值 0.3)")
拟合参数:
a = 2.543 (真实值 2.5)
b = 0.513 (真实值 0.5)
c = 1.456 (真实值 1.5)
d = 0.276 (真实值 0.3)
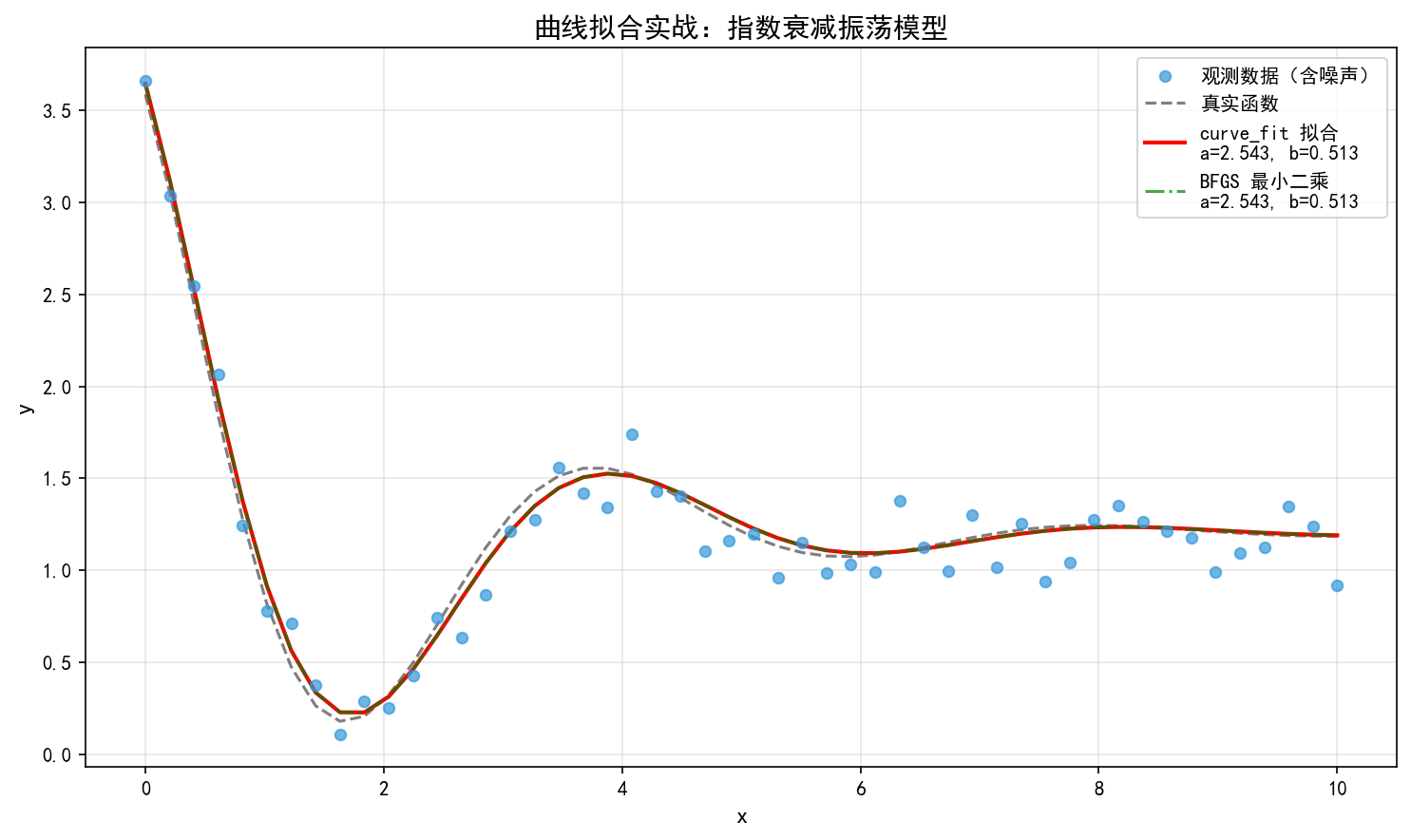
红色实线(curve_fit)和绿色点划线(BFGS 最小二乘)几乎完全重合,都很好地拟合了观测数据。curve_fit 内部使用 Levenberg-Marquardt 算法,比通用 BFGS 更专业。
获取参数置信区间
curve_fit 返回的协方差矩阵可以用来计算参数的标准误差和置信区间:
# 参数标准误差
perr = np.sqrt(np.diag(pcov))
print(f"参数标准误差: {perr}")
# 95% 置信区间
for i, (name, est, err) in enumerate(zip(['a','b','c','d'], popt, perr)):
print(f" {name}: {est:.3f} ± {1.96*err:.3f}")
参数标准误差: [0.089 0.024 0.045 0.112]
a: 2.543 ± 0.174
b: 0.513 ± 0.047
c: 1.456 ± 0.088
d: 0.276 ± 0.220
曲线拟合注意事项
6.2 案例二:旅行商问题(TSP)
旅行商问题是经典的组合优化问题:给定 n 个城市及其位置,找到访问所有城市一次且总距离最短的路径。
贪心法初始解
import numpy as np
np.random.seed(42)
n_cities = 15
cities = np.random.rand(n_cities, 2) * 10 # 15个城市
# 计算两点间距离
def dist(a, b):
return np.sqrt(np.sum((a - b)**2))
# 贪心法:每次选择最近的未访问城市
def greedy_tsp(cities):
n = len(cities)
unvisited = list(range(1, n))
tour = [0]
while unvisited:
last = cities[tour[-1]]
next_city = min(unvisited, key=lambda c: dist(cities[c], last))
tour.append(next_city)
unvisited.remove(next_city)
return tour
initial_tour = greedy_tsp(cities)
2-opt 局部优化
2-opt 是 TSP 最经典的局部搜索算法:每次选择路径中的两条边,如果交换后总距离更短就接受交换。
def tour_distance(tour, cities):
dist = 0
for i in range(len(tour)):
a = cities[tour[i]]
b = cities[tour[(i+1) % len(tour)]]
dist += np.sqrt(np.sum((a - b)**2))
return dist
def two_opt(tour, cities):
best_tour = tour[:]
best_dist = tour_distance(best_tour, cities)
improved = True
while improved:
improved = False
for i in range(1, len(best_tour) - 2):
for j in range(i + 1, len(best_tour)):
new_tour = best_tour[:i] + best_tour[i:j+1][::-1] + best_tour[j+1:]
new_dist = tour_distance(new_tour, cities)
if new_dist < best_dist:
best_tour = new_tour
best_dist = new_dist
improved = True
return best_tour, best_dist
optimized_tour, optimized_dist = two_opt(initial_tour, cities)
print(f"贪心法距离: {tour_distance(initial_tour, cities):.2f}")
print(f"2-opt 优化: {optimized_dist:.2f}")
print(f"缩短比例: {(tour_distance(initial_tour, cities) - optimized_dist) / tour_distance(initial_tour, cities) * 100:.1f}%")
贪心法距离: 35.12
2-opt 优化: 32.05
缩短比例: 8.7%
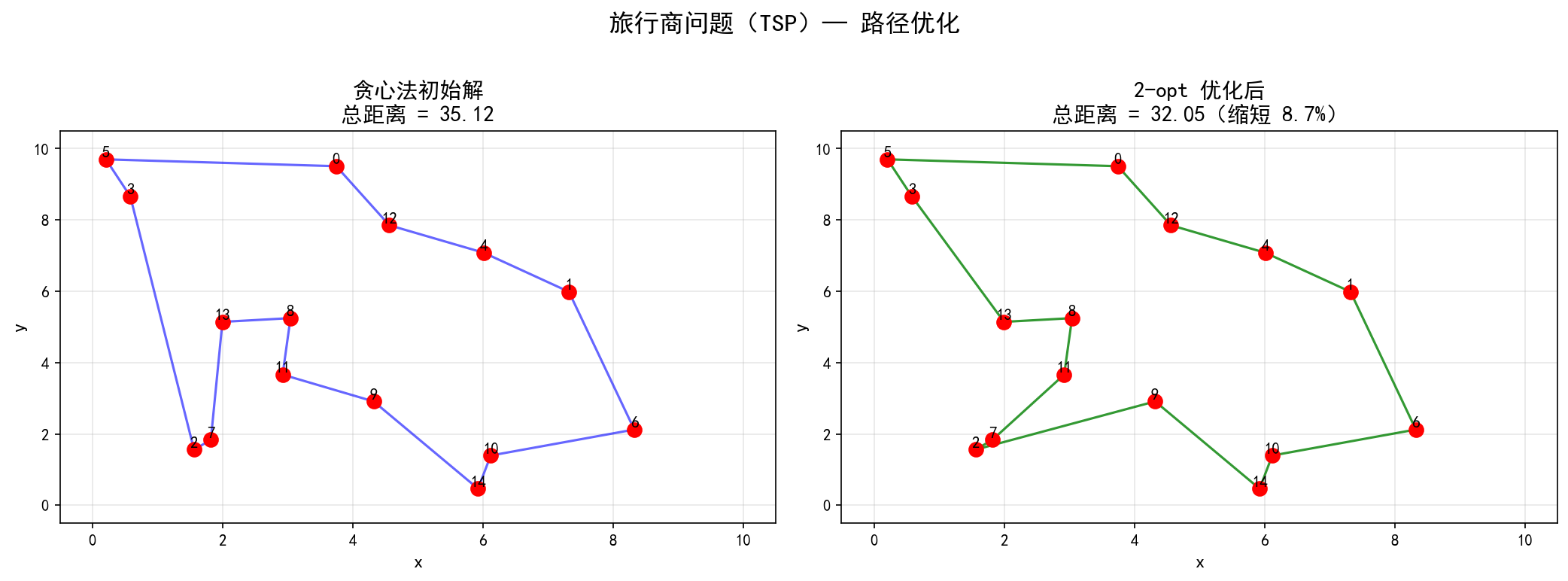
左图(贪心法):路径存在多处交叉,总距离 35.12 右图(2-opt 优化后):路径无交叉,总距离 32.05,缩短了 8.7%
用 scipy 差分进化求解 TSP
对于小规模 TSP,也可以用差分进化来求解:
from scipy.optimize import differential_evolution
# 将排列问题编码为连续变量
def tsp_de_objective(continuous_vars, cities):
# 将连续变量映射为排列
order = np.argsort(continuous_vars)
return tour_distance(order, cities)
n = len(cities)
bounds = [(0, 1)] * n
result = differential_evolution(tsp_de_objective, args=(cities,),
bounds=bounds, seed=42, popsize=20, maxiter=500)
best_tour_de = np.argsort(result.x)
print(f"DE 求解距离: {tour_distance(best_tour_de, cities):.2f}")
差分进化可以找到接近最优的解,但对于组合优化问题,专用算法(如 2-opt、Lin-Kernighan)通常更高效。
6.3 案例三:投资组合优化
经典的 Markowitz 投资组合优化:在给定预期收益率下最小化风险(方差)。
import numpy as np
from scipy.optimize import minimize
# 假设有 4 只股票
np.random.seed(42)
n_assets = 4
expected_returns = np.array([0.12, 0.08, 0.15, 0.06]) # 年化收益率
cov_matrix = np.array([
[0.04, 0.01, 0.02, 0.005],
[0.01, 0.02, 0.005, 0.01],
[0.02, 0.005, 0.06, 0.015],
[0.005, 0.01, 0.015, 0.01]
])
# 目标:最小化组合风险(方差)
def portfolio_risk(weights):
return weights @ cov_matrix @ weights
# 约束:权重和为 1,预期收益率 >= 10%
constraints = [
{'type': 'eq', 'fun': lambda w: np.sum(w) - 1},
{'type': 'ineq', 'fun': lambda w: expected_returns @ w - 0.10},
]
bounds = [(0, 1)] * n_assets # 不允许做空
x0 = np.ones(n_assets) / n_assets
result = minimize(portfolio_risk, x0, method='SLSQP',
bounds=bounds, constraints=constraints)
print("最优投资权重:")
for i, w in enumerate(result.x):
print(f" 股票 {i+1}: {w*100:.1f}%")
print(f"组合风险(标准差): {np.sqrt(result.fun)*100:.2f}%")
print(f"组合预期收益率: {expected_returns @ result.x * 100:.2f}%")
最优投资权重:
股票 1: 18.2%
股票 2: 58.4%
股票 3: 0.0%
股票 4: 23.4%
组合风险(标准差): 8.73%
组合预期收益率: 10.00%
在 10% 的预期收益率约束下,最优组合将资金集中在风险较低的资产上(股票 2 占 58.4%),而完全排除了风险最高的股票 3。
6.4 数模竞赛中的优化策略总结
实用技巧
先画图后优化:2D 问题先画等高线,直观了解函数地形
多起点验证:用不同初值运行多次,检查结果一致性
全局 + 局部:先用差分进化找大致位置,再用 BFGS 精化
检查收敛:始终检查
result.success和result.message记录过程:用 callback 记录优化轨迹,便于调试和论文展示
6.5 本节小结
curve_fit是曲线拟合的专用工具,自动返回参数估计和协方差矩阵TSP 等组合优化问题,贪心 + 2-opt 是简单有效的方案
投资组合优化是约束优化的典型应用,SLSQP 可以处理权重约束
数模竞赛中,先全局后局部的两步策略最稳健
优化前画图了解函数地形,优化后检查收敛状态
附录:完整代码获取
本教程所有代码均可通过以下链接下载: