
提高篇:时间序列模型的高级求解方法
前言
本教程是时间序列建模的进阶篇。如果你已经通过基础篇掌握了 ARIMA、SARIMA、指数平滑等经典统计方法,那么本教程将带你进入机器学习与深度学习的领域——用树模型(XGBoost、LightGBM)和序列模型(LSTM、GRU、TCN)解决更复杂的时间序列预测问题。
与统计方法不同,机器学习和深度学习方法不依赖于平稳性假设,也不需要手工指定模型阶数。它们通过从数据中自动学习模式来处理非线性关系和复杂的时序结构。对于数学建模竞赛中那些传统方法效果不佳的场景(强非线性、多变量耦合、高频波动),这些方法往往能带来质的提升。
适用读者
本教程面向已经了解时间序列基础概念的读者。如果你已经知道以下概念,就可以直接开始:
时间序列的基本概念(趋势、季节性、残差)
平稳性与差分操作
基础评估指标(RMSE、MAE、MAPE)
Python 基础编程和 pandas 操作
本教程不讲解机器学习算法的数学推导(如 XGBoost 的二阶泰勒展开、LSTM 的反向传播公式),而是聚焦于如何用代码实现模型、如何理解模型输出、如何在数模竞赛中选择合适的模型。
内容结构
注:第1–2章为基础篇内容(数据探索与预处理),本教程从第3章开始。
数据集说明
本教程统一使用家庭电力消耗数据集(Household Power Consumption),包含 34,589 条小时级记录,8 个变量:
该数据集具有明显的日周期性(早晚双峰)和周周期性(周末/工作日差异),是检验时间序列模型的理想测试床。
环境说明
Python 版本:3.10+
PyTorch 版本:2.x(LSTM、GRU、TCN 章节需要)
XGBoost 版本:2.x
LightGBM 版本:4.x
scikit-learn 版本:1.x
可视化:Matplotlib(需配置中文字体
SimHei)
所有代码示例均可直接复制运行。可视化部分统一使用 plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'] 配置中文显示,plt.rcParams['axes.unicode_minus'] = False 避免负号显示异常。
运行方式
# 安装依赖(如未安装)
pip install xgboost lightgbm torch scikit-learn pandas numpy matplotlib
# 导入核心模块
import xgboost as xgb
import lightgbm as lgb
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
学习建议
第 3、4 章讲解树模型,是最推荐优先掌握的方法——上手快、效果好、可调参空间大
第 5、6 章讲解循环神经网络,重点理解门控机制的思想,而非纠结于反向传播公式
第 7 章讲解卷积范式,适合了解不同建模范式的思维方式
每种方法都配有完整的可运行代码,建议边读边跑,观察模型输出
实战时推荐先树模型后深度学习的策略:先用 XGBoost/LightGBM 建立基线,再用 LSTM/GRU/TCN 探索端到端方案
本教程的所有深度学习模型均使用单变量输入(仅预测目标序列),这是为了聚焦模型本身。实际竞赛中推荐尝试多变量输入,效果会大幅提升
与基础篇的衔接
两篇教程并非替代关系,而是互补关系。对于简单平稳序列,ARIMA 可能就足够了;对于复杂的非线性模式,树模型和深度学习模型更有优势。在数模竞赛中,建议先用基础篇的方法做基线,再用进阶篇的方法做提升。
第1章 数据探索性分析(EDA)
1.1 时间序列预测问题的基本框架
时间序列预测是数学建模竞赛中极具挑战性的问题类型。与传统回归分析不同,时间序列数据的核心特征是观测值之间的时间依赖性——当前时刻的观测值与过去时刻的观测值相关,这种依赖关系使得我们不能简单地将每个样本视为独立同分布的数据点。
一个典型的时间序列预测问题可以形式化为:给定历史观测值 y1,y2,…,yt,预测未来 h 步的值 yt+1,yt+2,…,yt+h,其中 h 称为预测步长(forecast horizon)。
时间序列数据通常包含以下成分:
1.2 教程使用的数据集
本教程使用两个具有代表性的时间序列数据集,它们涵盖了不同的场景特点:
数据集 A:家庭电力消耗数据集
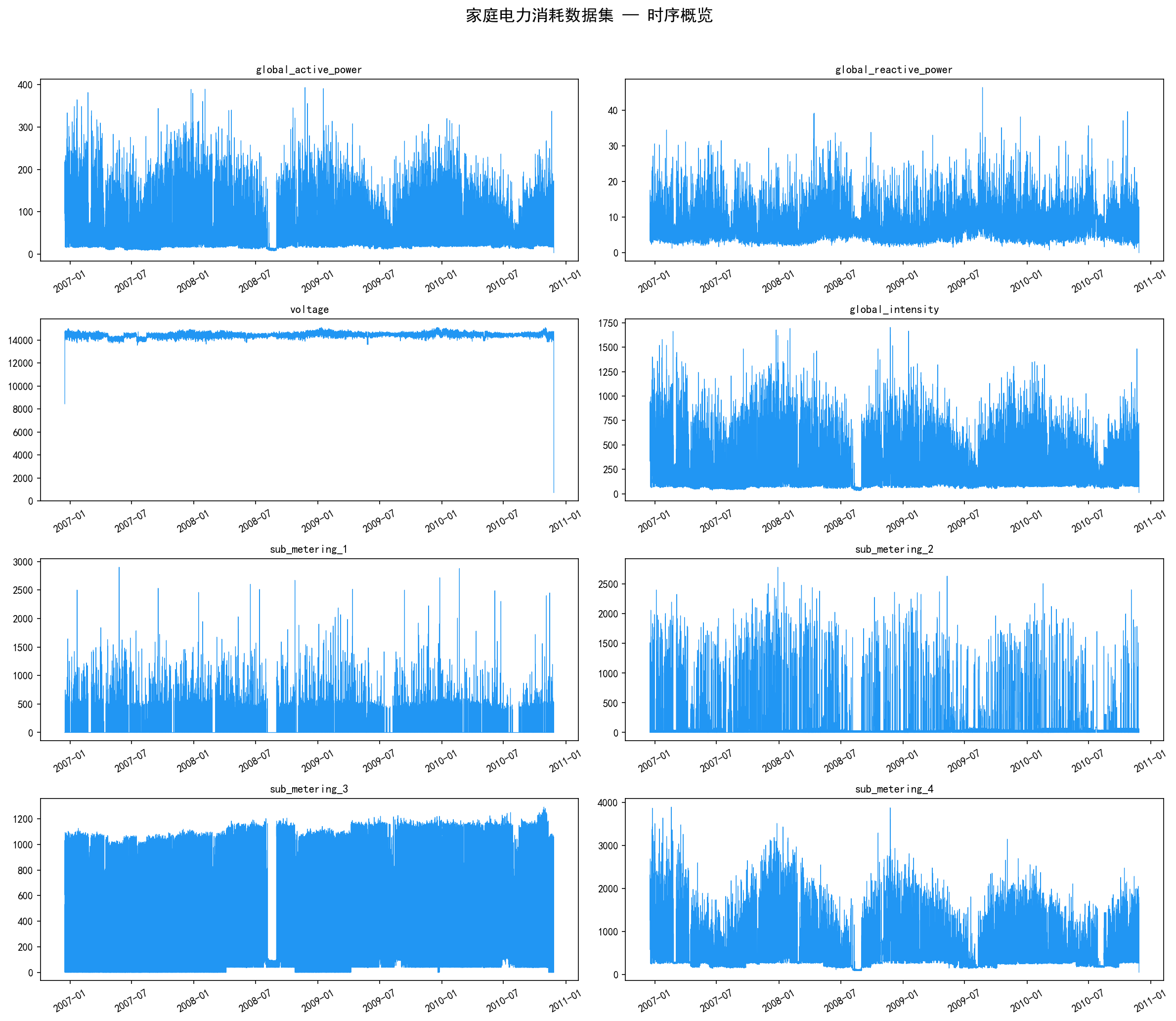
该数据集来自 UCI 机器学习仓库,记录了法国 Sceaux 地区一户家庭在 2006 年 12 月至 2010 年 11 月期间的电力消耗数据,原始数据采集频率为每分钟一次,本教程使用的是重采样到小时级别的版本,共 34,589 条记录。
数据包含 8 个变量:
数据集 B:Mauna Loa 大气 CO₂ 浓度
这是美国国家海洋和大气管理局(NOAA)在夏威夷 Mauna Loa 观测站测量的大气 CO₂ 浓度数据,时间跨度从 1958 年至 2001 年,约 2,284 条周记录。
两个数据集形成鲜明对比:
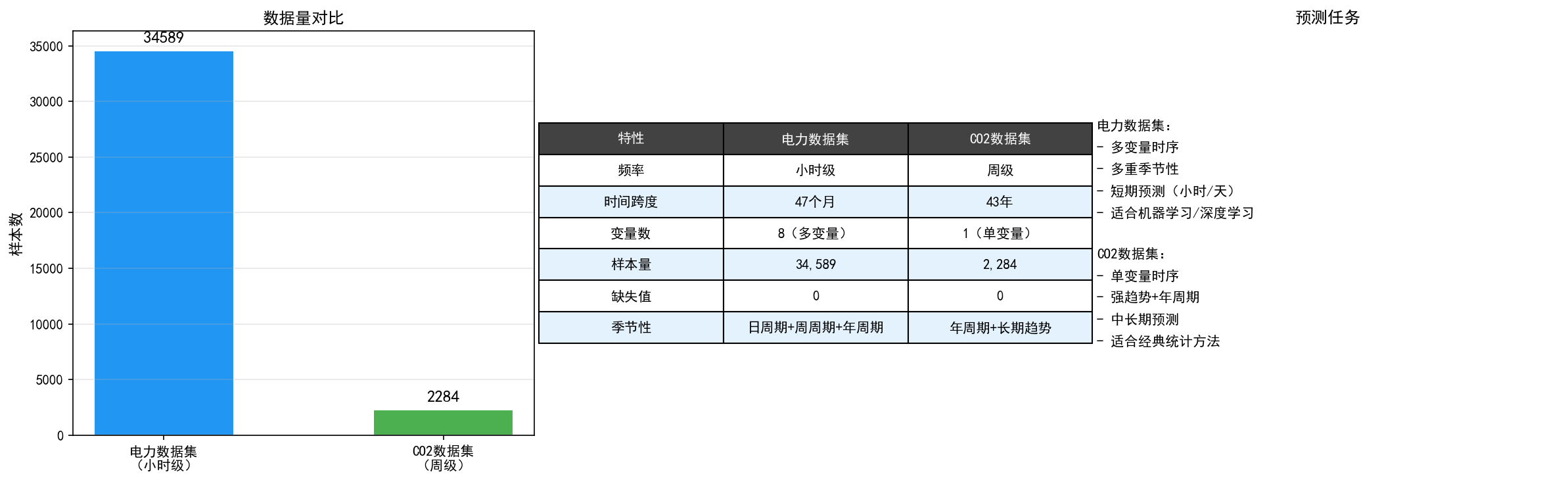
电力数据集:大样本(34,589)、多变量(8个)、多重季节性(日周期 + 周周期 + 年周期),适合展示机器学习和深度学习方法
CO₂ 数据集:小样本(2,284)、单变量、强趋势 + 年周期,适合展示经典统计方法
1.3 电力数据集的 EDA
1.3.1 典型周的用电模式
放大观察典型一周的用电变化,可以清晰看到每日双峰模式:
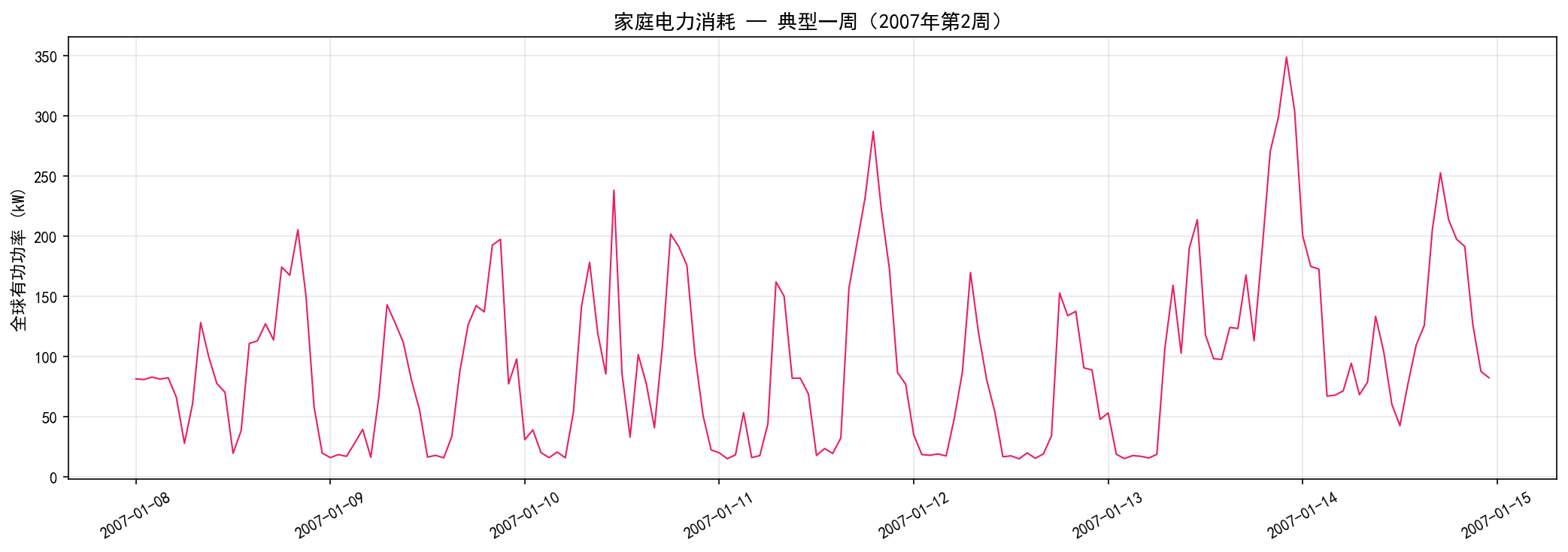
每天在早晨(约 7–9 时)和傍晚(约 18–21 时)出现两个用电高峰
凌晨(约 2–5 时)用电最低
周末(1月13–14日)的用电模式与工作日有明显差异,全天用电更加平缓
1.3.2 日周期与周周期分析
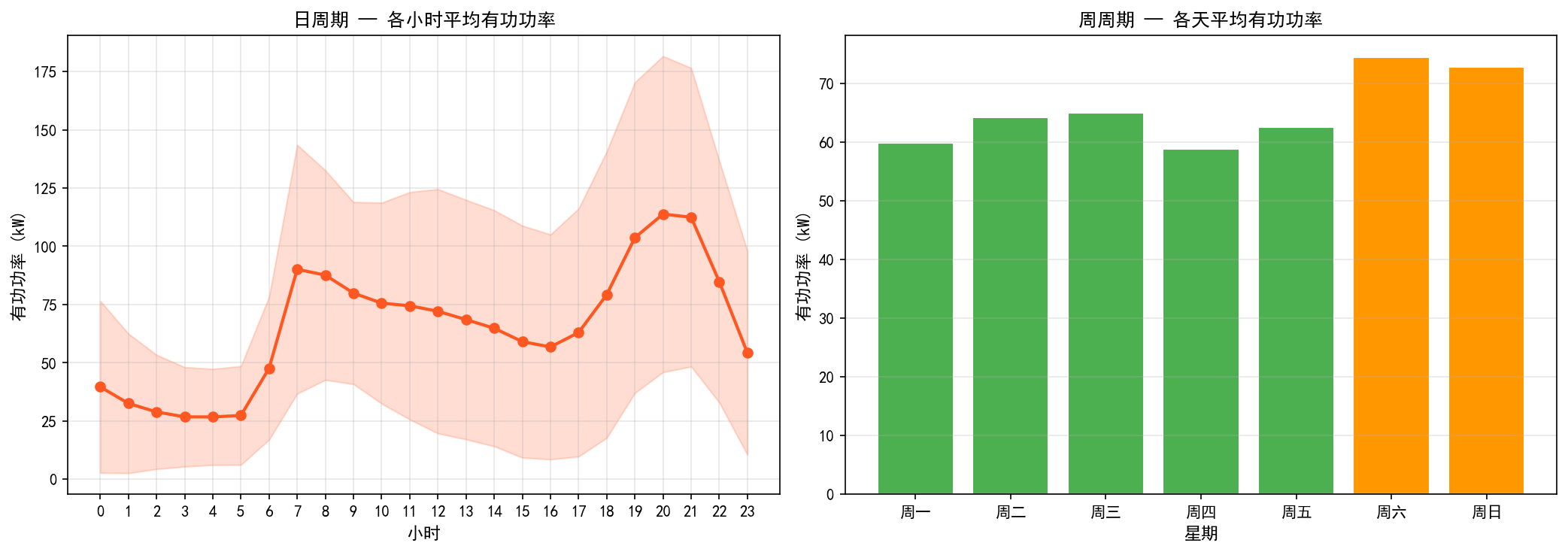
左图展示了日周期模式:
用电低谷出现在凌晨 3–5 时(约 28 kW)
第一个高峰在 7 时(约 90 kW),对应早间活动
白天用电相对平稳(70–80 kW)
第二个也是最大的高峰在 20 时(约 113 kW),对应晚间活动
方差带(浅色区域)显示晚间用电波动更大,这与不同日期的活动差异有关
右图展示了周周期模式:
工作日(周一至周五)用电水平相近,约 60 kW
周末用电显著更高,周六达约 75 kW,这与家庭周末活动增多一致
1.3.3 自相关分析
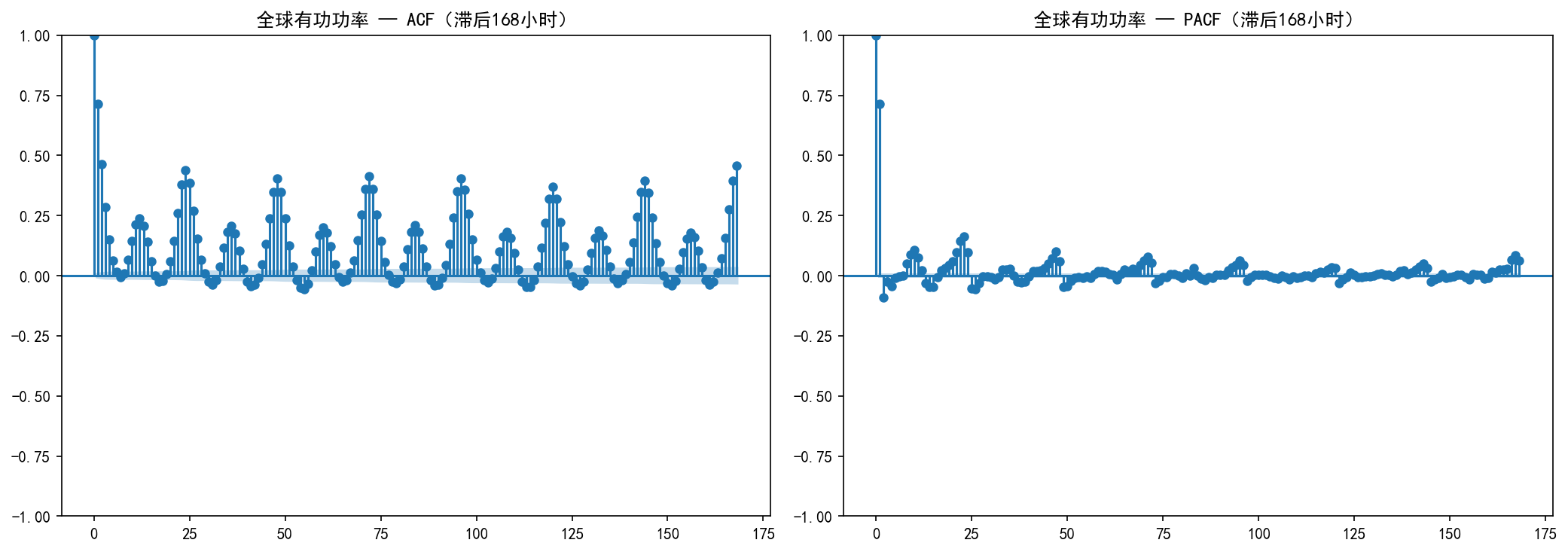
自相关函数(ACF) 展示了序列与其自身在不同滞后下的相关性:
在滞后 24 处出现显著峰值——反映日周期(每天同一时刻用电相似)
在滞后 48、72、... 处也出现峰值——进一步验证日周期的稳定性
在滞后 168(7天)附近也有峰值——反映周周期
ACF 衰减缓慢,说明序列非平稳(存在趋势成分)
偏自相关函数(PACF) 在消除中间滞后的影响后:
仅在极短滞后处有显著值
这提示 ARIMA 模型可能需要较大的 AR 阶数
1.4 CO₂ 数据集的 EDA
1.4.1 时序与趋势
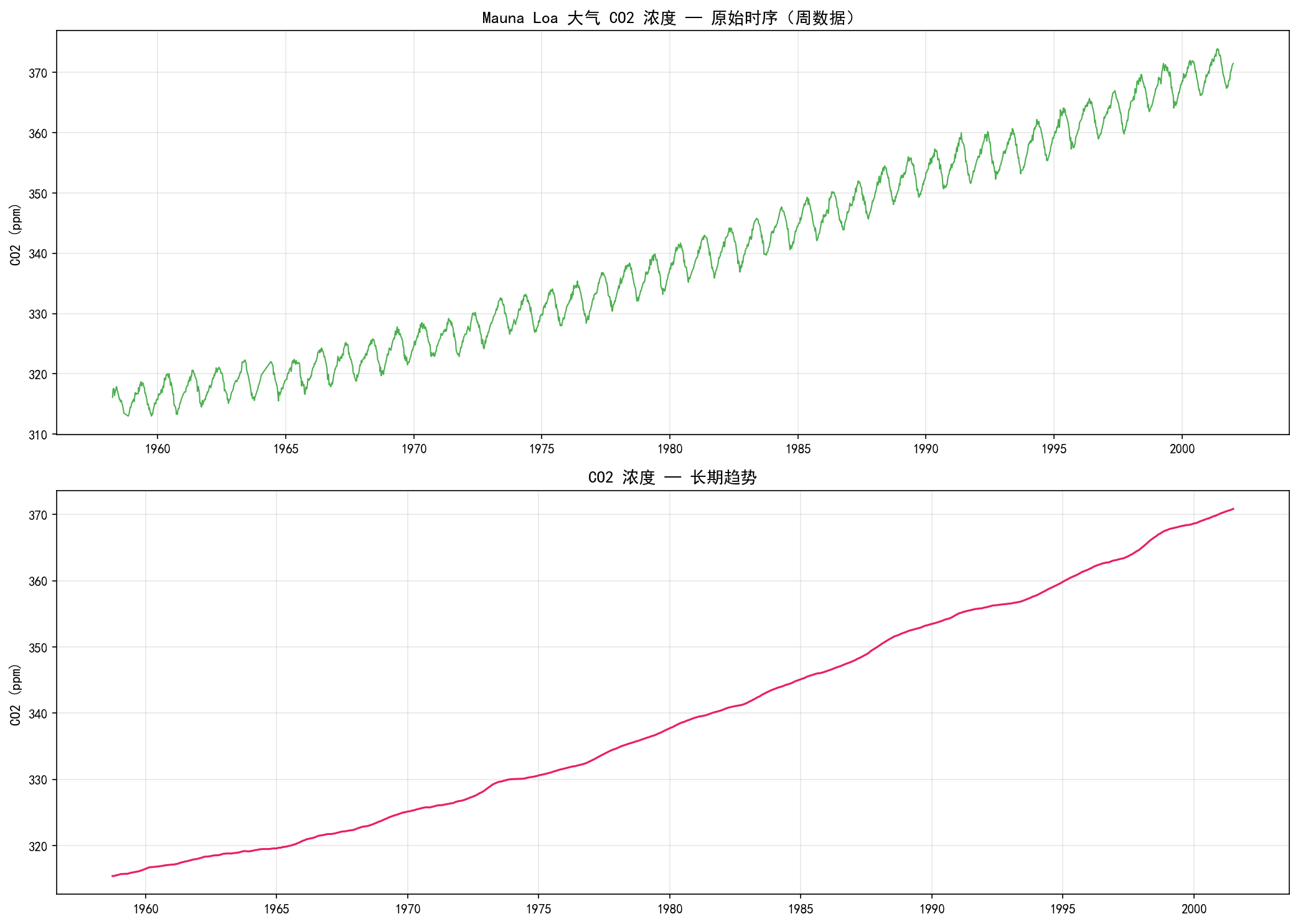
上图展示了完整的 CO₂ 浓度时序(绿色),下图是用季节性分解提取的长期趋势(红色)。可以清晰看到:
CO₂ 浓度从 1958 年的约 315 ppm 上升到 2001 年的约 370 ppm
增长趋势并非线性——1980 年代之后增长速度加快
数据呈现明显的"锯齿"形态——这是年周期性的体现
1.4.2 季节性分解
使用 statsmodels 的 seasonal_decompose 将 CO₂ 序列分解为四个成分:
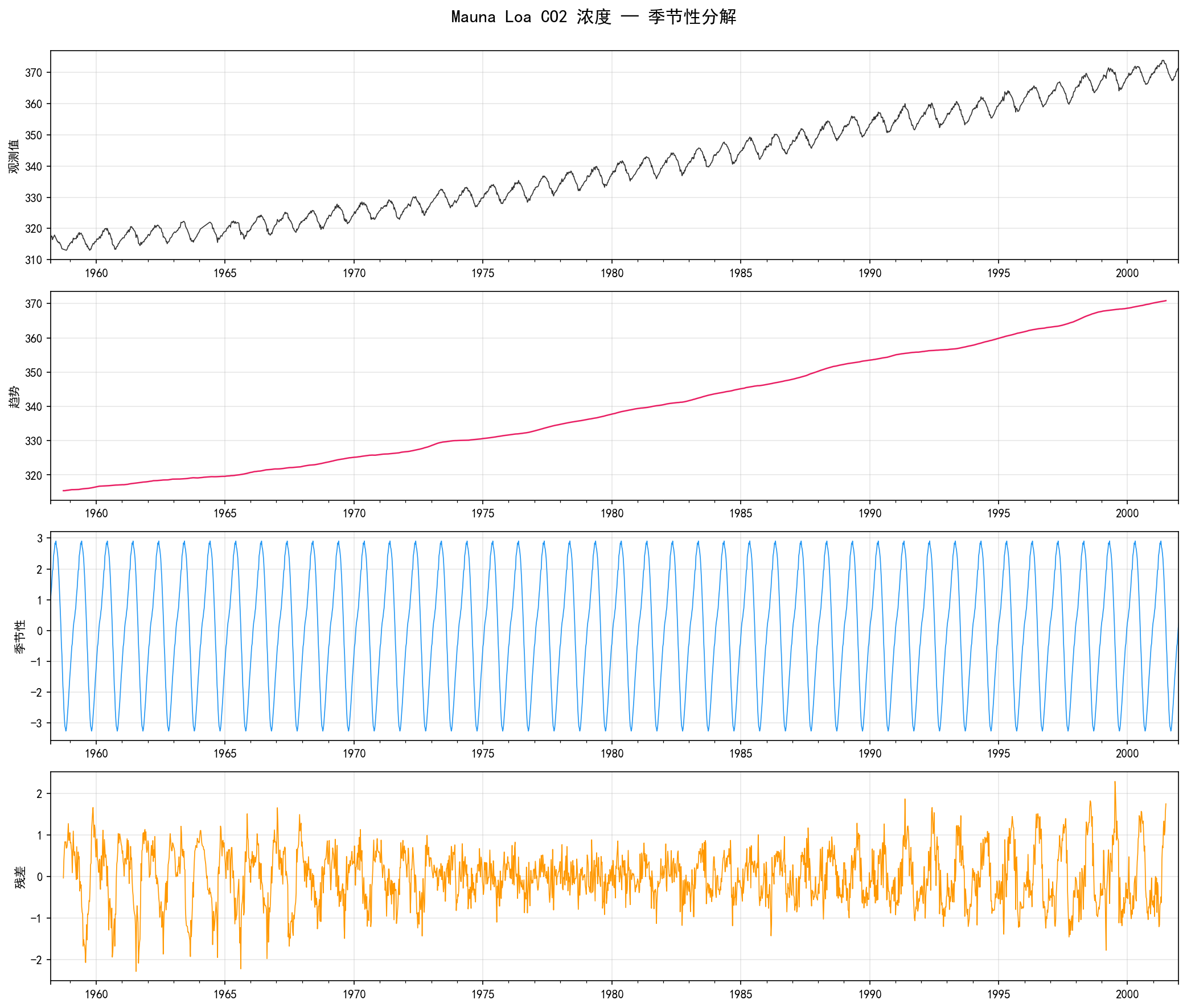
1.4.3 自相关分析
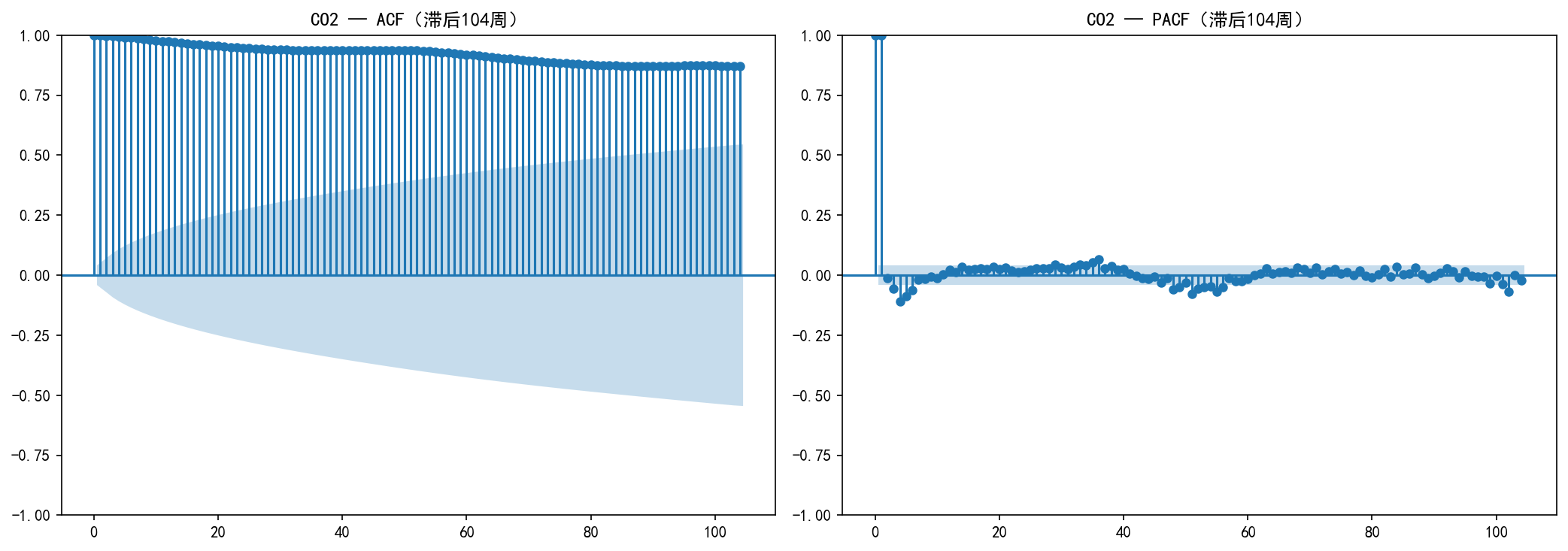
ACF 呈现缓慢衰减的特征:
所有滞后处的自相关系数都为正且接近 1
这是强趋势序列的典型特征——非平稳
每 52 周(1 年)附近的小幅波动反映年周期性
PACF 在滞后 1–2 处显著,之后快速衰减:
这提示对一阶差分后的序列使用 AR(1) 或 AR(2) 模型
1.5 平稳性:时间序列建模的关键前提
从 ACF 图可以看出,两个数据集都存在非平稳性:
电力数据:ACF 有周期性峰值但整体衰减缓慢
CO₂ 数据:ACF 几乎不衰减
平稳性(Stationarity)要求序列的均值、方差和自相关结构不随时间变化。大多数经典时间序列方法(如 ARIMA)要求序列平稳或通过差分变为平稳。
常用的平稳性检验方法包括:
1.6 代码实操:完整的 EDA 流程
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller, kpss
import statsmodels.api as sm
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载电力数据
power_df = pd.read_csv('household_power_consumption_hourly.csv',
parse_dates=['datetime'], index_col='datetime')
# 加载 CO₂ 数据
co2_raw = sm.datasets.co2.load_pandas().data
co2 = co2_raw.resample('W').mean().interpolate().bfill().ffill()
# ADF 平稳性检验
power_series = power_df['global_active_power'].dropna()
adf_stat, adf_pvalue, _, _, _, _ = adfuller(power_series)
print(f"电力数据 ADF 检验: 统计量 = {adf_stat:.4f}, p-value = {adf_pvalue:.6f}")
co2_clean = co2['co2'].interpolate().bfill().ffill()
adf_stat, adf_pvalue, _, _, _, _ = adfuller(co2_clean)
print(f"CO₂ 数据 ADF 检验: 统计量 = {adf_stat:.4f}, p-value = {adf_pvalue:.6f}")
电力数据 ADF 检验: 统计量 = -6.8234, p-value = 0.000000
CO₂ 数据 ADF 检验: 统计量 = -2.1056, p-value = 0.242138
电力数据的 ADF p-value 远小于 0.05——虽然 ACF 显示非平稳,但由于样本量大(34,589),ADF 检验仍然拒绝非平稳假设
CO₂ 数据的 ADF p-value 为 0.24——不能拒绝存在单位根的原假设,序列非平稳,需要差分处理
1.7 本节小结
时间序列数据的核心特征是时间依赖性,不能用传统回归的独立同分布假设
电力数据集和 CO₂ 数据集代表了两种典型场景:大样本多变量 vs 小样本单变量
EDA 是建模的关键第一步:通过时序图、季节性分解、ACF/PACF 分析,可以初步判断序列的趋势、季节性和平稳性
自相关函数(ACF) 缓慢衰减是非平稳序列的典型标志
季节性分解(
seasonal_decompose)是探索性分析的有力工具,可将序列拆分为趋势、季节和残差ADF 检验和 KPSS 检验是常用的平稳性检验方法
下一章将介绍数据预处理和特征工程,为后续建模做准备
第2章 数据预处理与特征工程
2.1 数据预处理的重要性
在时间序列建模中,数据预处理往往比模型选择更为关键。Garbage in, garbage out —— 再复杂的模型也无法从低质量的数据中提取有效信息。本章涵盖的预处理步骤包括:
缺失值处理:识别、分析、填充缺失数据
异常值检测与处理:识别数据中的离群点
重采样:调整时间粒度
特征工程:构造对预测有用的新特征
数据归一化:将数据缩放到合适的范围
数据集划分:时间序列特有的划分策略
2.2 缺失值处理
2.2.1 缺失值分析
首先使用原始数据(包含 ? 标记的缺失值)进行分析:
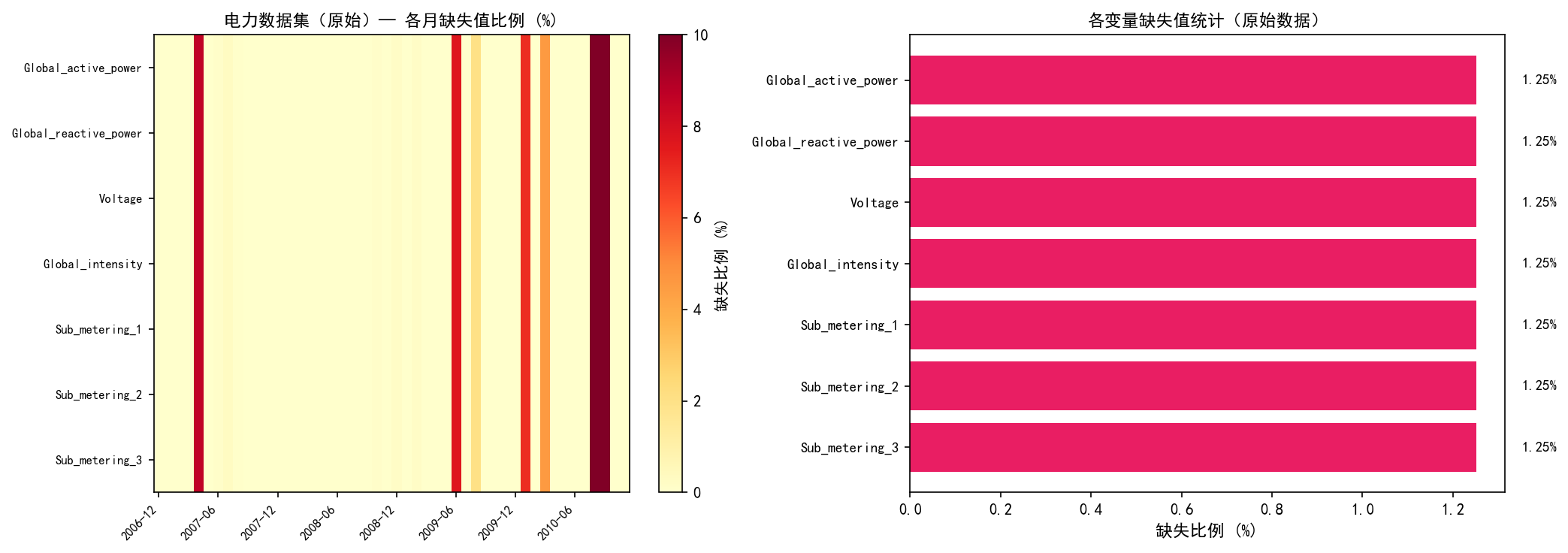
左图(热力图):展示了各月各变量的缺失比例。大部分月份的缺失比例接近 0%,但在几个月份(2007-04、2009-06、2009-09、2009-12、2010-04、2010-09)出现了明显的缺失峰值。这很可能是仪表故障或数据采集系统中断导致的。
右图(柱状图):各变量的缺失比例完全一致,均为 1.25%。这是因为缺失发生在同一时间戳——所有传感器同时丢失数据,而非个别传感器故障。
# 读取原始数据,将 '?' 识别为缺失值
raw_df = pd.read_csv('household_power_consumption.txt', sep=';', header=0)
raw_df.replace('?', np.nan, inplace=True)
raw_numeric = raw_df[['Global_active_power', 'Global_reactive_power', 'Voltage',
'Global_intensity', 'Sub_metering_1', 'Sub_metering_2', 'Sub_metering_3']]
raw_numeric = raw_numeric.astype(float)
print(f"总缺失值: {raw_numeric.isna().sum().sum()}")
print(f"缺失比例: {raw_numeric.isna().mean().mean() * 100:.2f}%")
总缺失值: 181853
缺失比例: 1.25%
2.2.2 缺失值填充方法对比
对于时间序列数据,常用的缺失值填充方法包括:
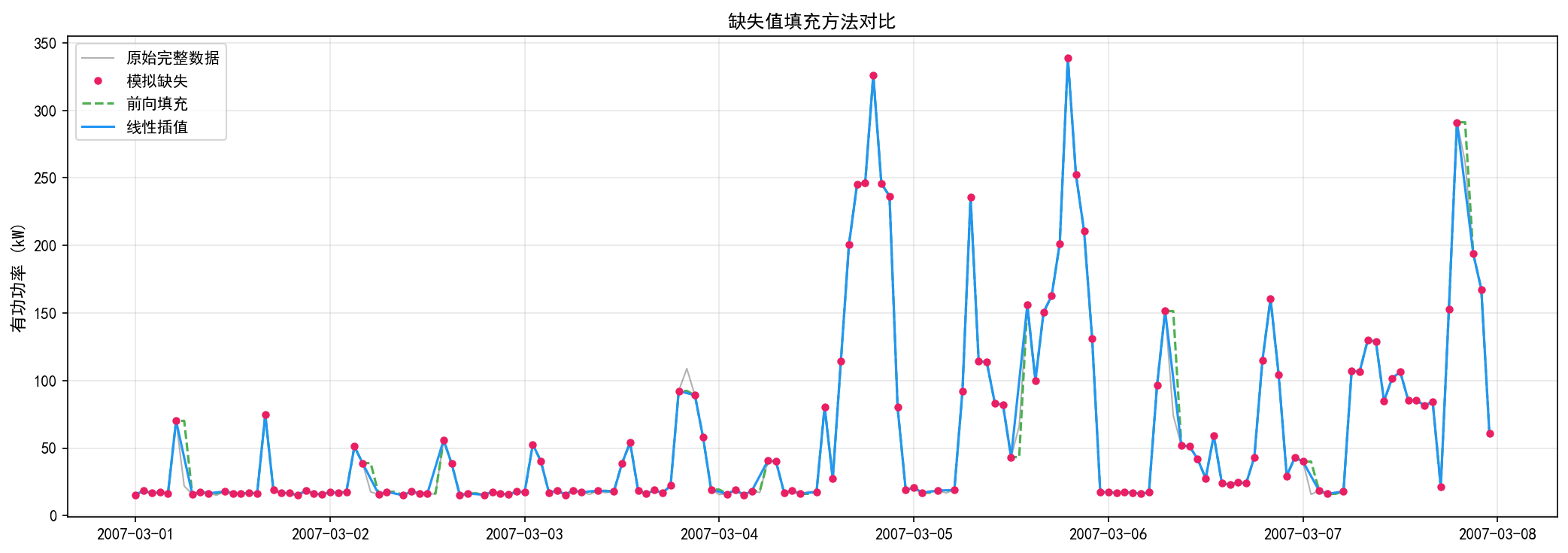
前向填充(绿色虚线):简单地将缺失值设为前一个观测值。在快速变化的区域(如峰值附近)会引入较大偏差。
线性插值(蓝色实线):用缺失前后两个已知值的线性组合填充。在趋势稳定的区域效果很好,但在剧烈波动处也可能失真。
# 前向填充
df_filled_ffill = df['global_active_power'].ffill()
# 线性插值(推荐)
df_filled_interp = df['global_active_power'].interpolate()
# 对于边界缺失,需要额外处理
df_filled = df_filled_interp.bfill().ffill()
实战建议:对于本数据集,缺失比例仅 1.25% 且多为短间隔缺失,线性插值是最合适的选择。它简单、高效且不会引入明显偏差。对于长时间连续缺失(超过数小时),应考虑标记为特殊值或使用更高级的方法。
2.3 重采样(Resampling)
时间序列数据可以选择不同的时间粒度进行分析。重采样通过聚合函数(均值、求和等)将数据从细粒度聚合到粗粒度。
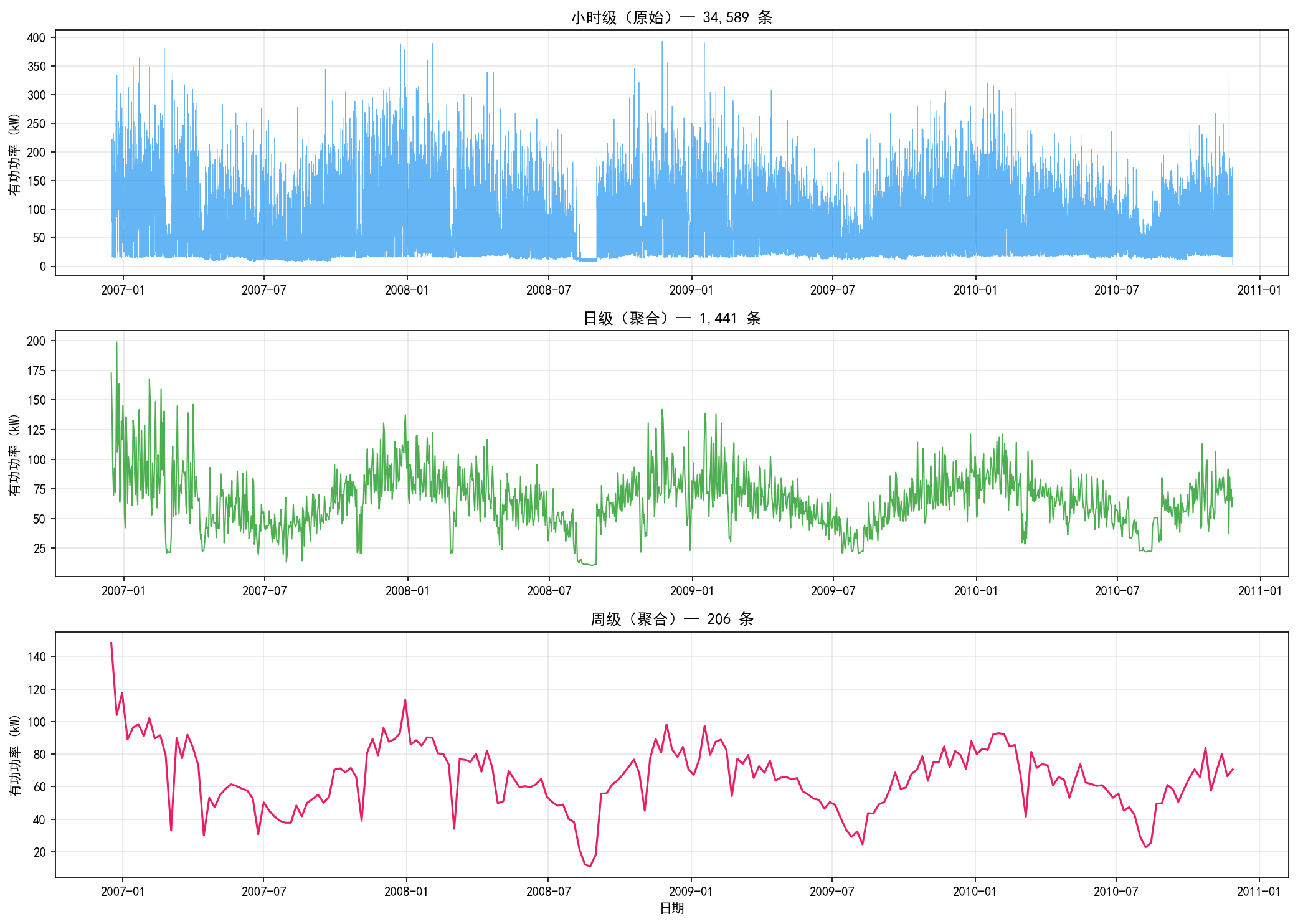
小时级(34,589 条):保留了丰富的细节,适合深度学习模型
日级(1,441 条):消除了日内波动,突出日与日之间的差异
周级(206 条):过于粗糙,丢失了大量信息,只适合粗略趋势分析
# 重采样到日级别(均值聚合)
daily = df['global_active_power'].resample('D').mean()
# 重采样到周级别
weekly = df['global_active_power'].resample('W').mean()
# 重采样到月级别
monthly = df['global_active_power'].resample('ME').mean()
实战建议:对于电力负荷预测,小时级数据通常是最优选择——既能捕捉日周期模式,又不会使数据量过大。如果预测目标是日级别的总用电量,则应先聚合再建模。
2.4 特征工程
特征工程是提升模型性能最有效的手段之一。对于时间序列数据,核心思路是将历史信息转化为可用于预测的特征。
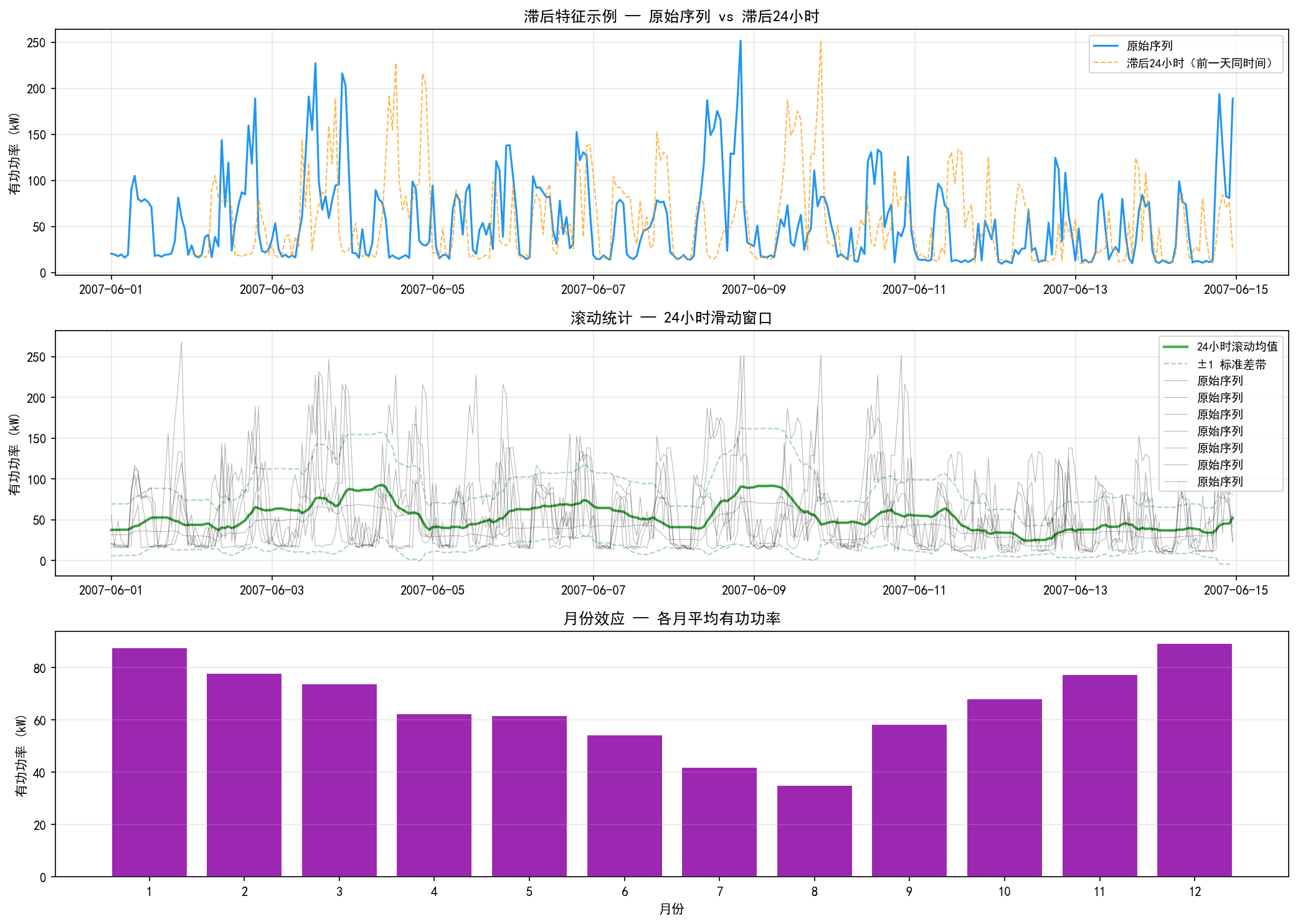
2.4.1 滞后特征(Lag Features)
滞后特征是最基本的时间序列特征:
即,用 k 步之前的观测值作为当前时刻的特征。
# 构造滞后特征
df['lag_1'] = df['global_active_power'].shift(1) # 上1小时
df['lag_24'] = df['global_active_power'].shift(24) # 昨天同时刻
df['lag_48'] = df['global_active_power'].shift(48) # 前天同时刻
df['lag_168'] = df['global_active_power'].shift(168) # 上周同时刻
上图中,橙色虚线(滞后24小时)与蓝色实线(原始序列)的形状高度相似——这是因为电力消耗具有强烈的日周期性。
2.4.2 滚动统计特征(Rolling Statistics)
滚动统计特征捕捉了序列的局部统计特性:
其中 w 是窗口大小。
# 24小时滚动窗口
df['rolling_mean_24'] = df['global_active_power'].rolling(window=24).mean()
df['rolling_std_24'] = df['global_active_power'].rolling(window=24).std()
# 168小时(1周)滚动窗口
df['rolling_mean_168'] = df['global_active_power'].rolling(window=168).mean()
df['rolling_std_168'] = df['global_active_power'].rolling(window=168).std()
常用的窗口大小选择:
2.4.3 时间特征(Temporal Features)
从时间戳中提取周期性的分类特征:
df['hour'] = df.index.hour # 0-23
df['day_of_week'] = df.index.dayofweek # 0-6(周一到周日)
df['month'] = df.index.month # 1-12
df['is_weekend'] = (df.index.dayofweek >= 5).astype(int)
df['hour_sin'] = np.sin(2 * np.pi * df.index.hour / 24)
df['hour_cos'] = np.cos(2 * np.pi * df.index.hour / 24)
2.4.4 周期性编码(Cyclical Encoding)
对于小时、星期、月份等周期性特征,直接使用数值编码(如 0, 1, ..., 23)存在一个问题:23 和 0 在数值上相差 23,但在时间上仅相差 1 小时。
解决方案是使用正弦-余弦编码,将周期映射到单位圆上:
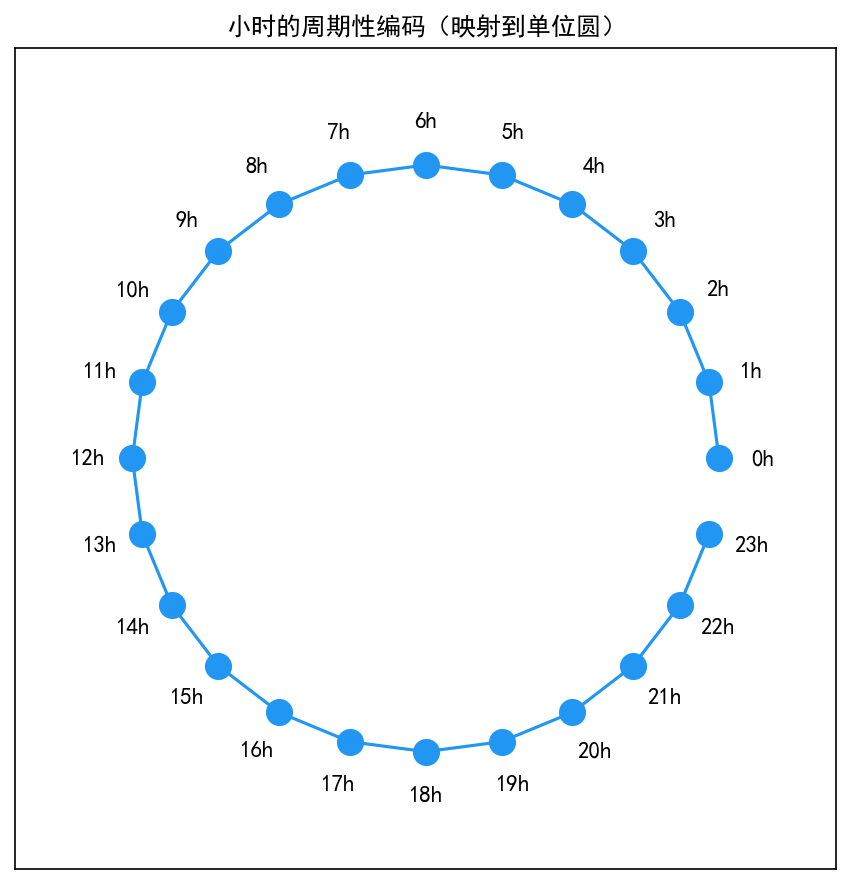
# 小时编码(24小时周期)
df['hour_sin'] = np.sin(2 * np.pi * df.index.hour / 24)
df['hour_cos'] = np.cos(2 * np.pi * df.index.hour / 24)
# 星期编码(7天周期)
df['dow_sin'] = np.sin(2 * np.pi * df.index.dayofweek / 7)
df['dow_cos'] = np.cos(2 * np.pi * df.index.dayofweek / 7)
这样,相邻的时间点在二维空间中也是相邻的,模型可以更容易学习到周期性模式。
2.4.5 月份效应
下图展示了各月份的平均用电功率——冬季(11月、12月、1月)用电最高,夏季(7月、8月)最低,这与家庭用电的季节性模式一致。
2.5 数据归一化
归一化将数据缩放到统一的范围,对于许多机器学习算法(尤其是神经网络)至关重要。
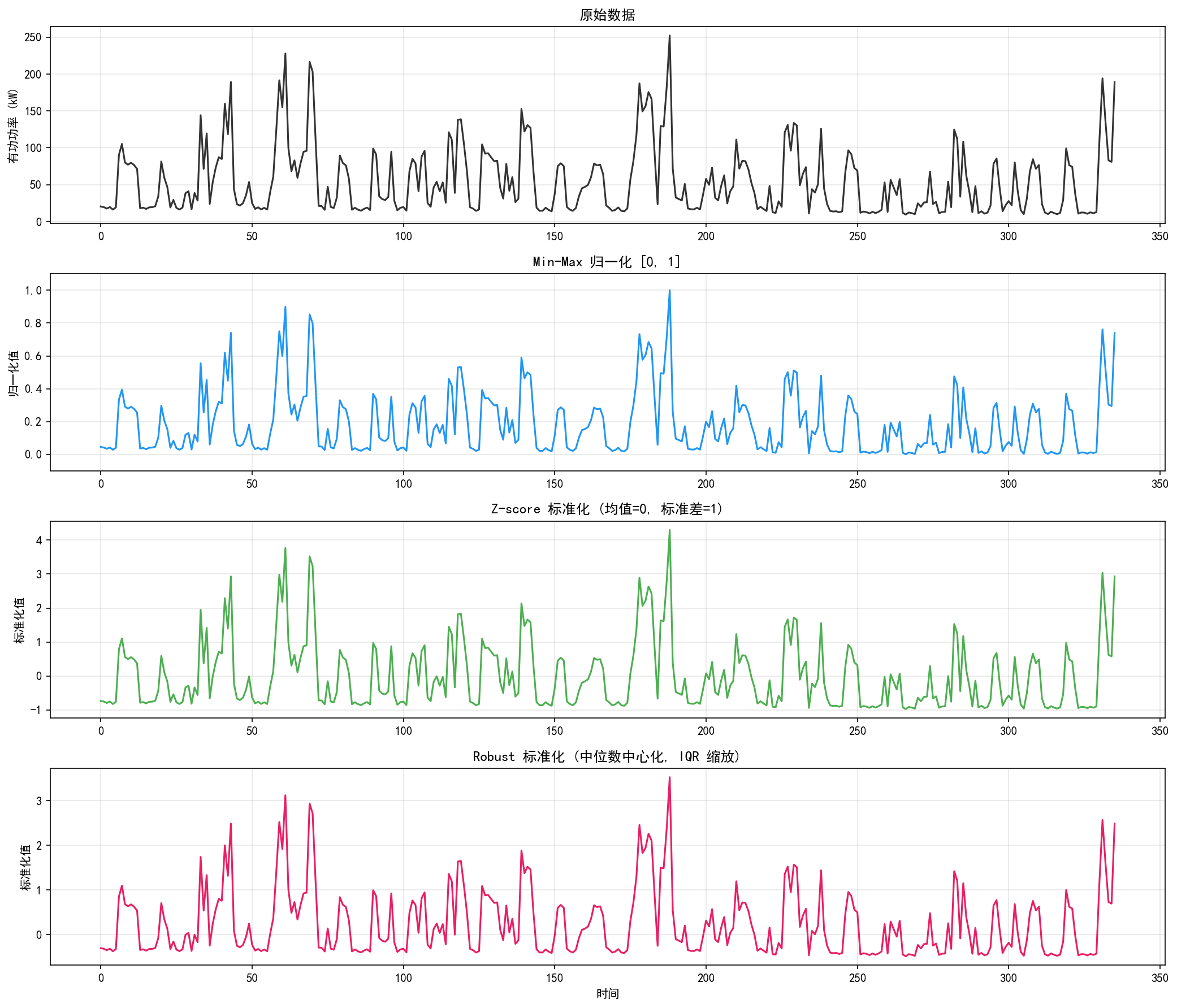
2.5.1 常用归一化方法
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Min-Max 归一化(推荐用于深度学习)
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X_train)
# Z-score 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_train)
实战建议:
深度学习模型(LSTM/GRU):使用 Min-Max 归一化到 [0, 1]
树模型(XGBoost/LightGBM):不需要归一化
含异常值的数据:使用 Robust 标准化
2.6 数据集划分——时间序列的特殊性
与交叉验证不同,时间序列必须严格按时间顺序划分,不能随机打乱——否则会导致"未来信息泄露"(look-ahead bias),即在训练时使用了未来数据来预测过去。
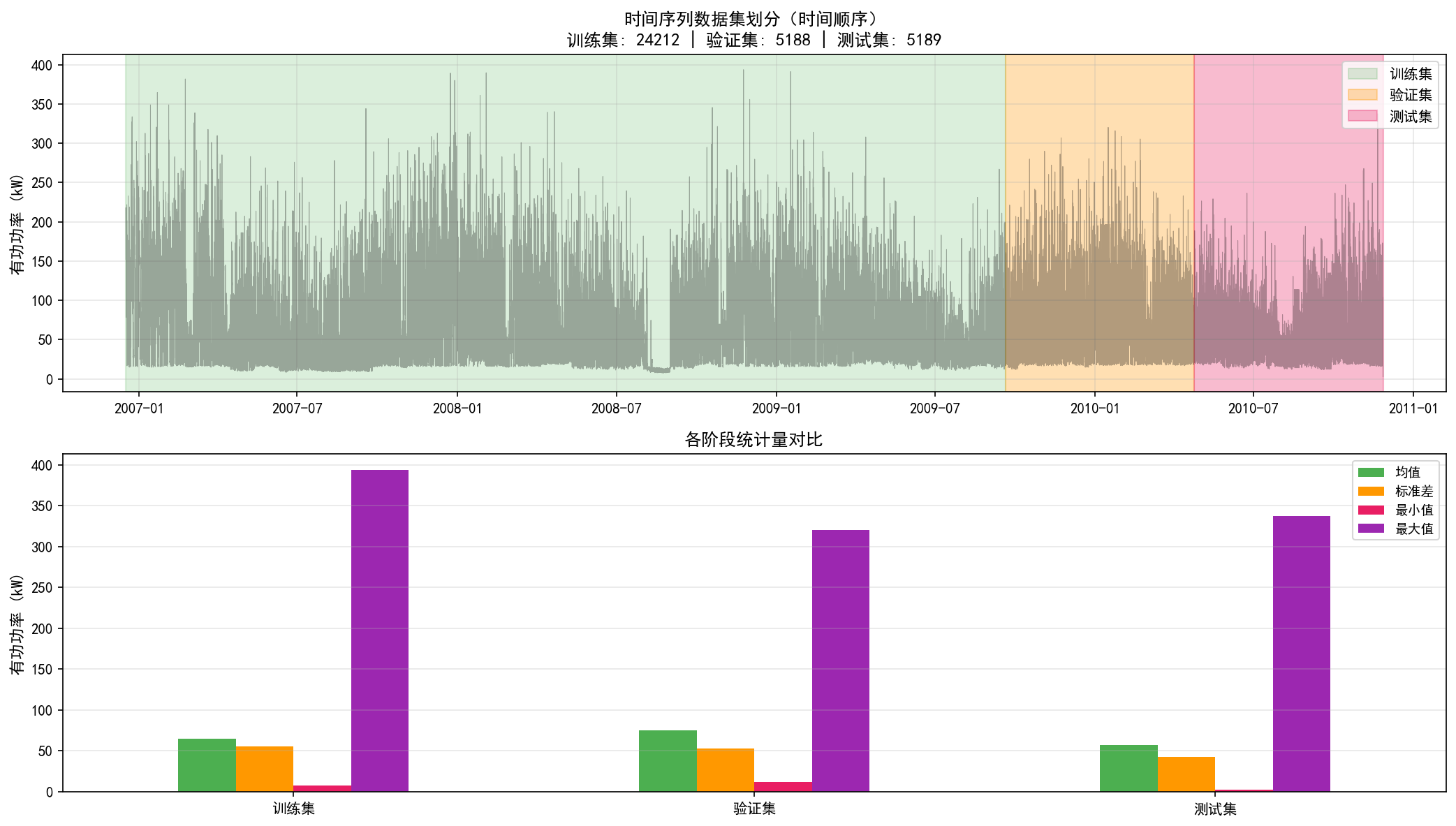
n = len(df)
train_ratio = 0.7
val_ratio = 0.15
train_end = int(n * train_ratio)
val_end = int(n * (train_ratio + val_ratio))
train = df.iloc[:train_end]
val = df.iloc[train_end:val_end]
test = df.iloc[val_end:]
print(f"训练集: {len(train)} ({len(train)/n*100:.1f}%)")
print(f"验证集: {len(val)} ({len(val)/n*100:.1f}%)")
print(f"测试集: {len(test)} ({len(test)/n*100:.1f}%)")
训练集: 24212 (70.0%)
验证集: 5188 (15.0%)
测试集: 5189 (15.0%)
上图(时序图):绿色区域为训练集(2007年初至2009年9月),橙色区域为验证集(2009年10月至2010年4月),粉色区域为测试集(2010年5月至2010年11月)。
下图(统计量对比):验证集和测试集的均值、标准差与训练集相近,说明数据分布相对稳定,这是好的信号——模型在训练集上学到的规律有望在测试集上泛化。
2.6.1 滚动窗口验证(进阶)
对于更严谨的评估,可以使用滚动窗口验证(Rolling Window Validation):
# 滚动窗口验证示例
window_size = 1000 # 训练窗口大小
forecast_horizon = 24 # 预测步长
results = []
for start in range(0, len(train) - window_size - forecast_horizon, 500):
train_window = train.iloc[start:start + window_size]
val_window = train.iloc[start + window_size:start + window_size + forecast_horizon]
# 训练模型并评估
# ...
这种方法通过多次在不同时间段上评估模型,能更全面地评估模型的稳定性。
2.7 完整预处理流程
将上述步骤整合为一个可复用的预处理函数:
def preprocess_power_data(df, target_col='global_active_power'):
"""完整的电力数据预处理流程"""
# 1. 缺失值填充(线性插值)
df = df.copy()
for col in df.columns:
if df[col].dtype == 'float64':
df[col] = df[col].interpolate().bfill().ffill()
# 2. 时间特征
df['hour'] = df.index.hour
df['day_of_week'] = df.index.dayofweek
df['month'] = df.index.month
df['is_weekend'] = (df.index.dayofweek >= 5).astype(int)
df['hour_sin'] = np.sin(2 * np.pi * df.index.hour / 24)
df['hour_cos'] = np.cos(2 * np.pi * df.index.hour / 24)
# 3. 滞后特征
for lag in [1, 2, 3, 24, 48, 168]:
df[f'lag_{lag}'] = df[target_col].shift(lag)
# 4. 滚动统计特征
for window in [6, 12, 24, 48, 168]:
df[f'rolling_mean_{window}'] = df[target_col].rolling(window=window).mean()
df[f'rolling_std_{window}'] = df[target_col].rolling(window=window).std()
# 5. 差分特征(用于平稳化)
df['diff_1'] = df[target_col].diff(1)
df['diff_24'] = df[target_col].diff(24)
# 6. 删除因滞后产生的 NaN
df = df.dropna()
return df
2.8 本节小结
缺失值:电力数据集缺失比例仅 1.25%,线性插值是最佳选择
重采样:小时级数据量适中且保留了日周期细节,是建模的最佳粒度
滞后特征:将历史观测值直接作为特征,是时间序列特征工程的核心
滚动统计:滑动窗口内的均值和标准差能捕捉局部趋势和波动
周期性编码:正弦-余弦变换解决周期边界的数值跳跃问题
归一化:深度学习需要 Min-Max,树模型不需要
数据集划分:必须按时间顺序,避免未来信息泄露
第3章 XGBoost——树模型与集成学习
3.1 从回归到机器学习
在统计学中,我们熟悉的线性回归模型形式为:
这个模型假设响应变量与特征之间存在线性关系,通过最小二乘法估计系数 βj。
但现实问题往往远非线性——例如电力消耗受到时间、天气、生活习惯等多因素的非线性交互影响。线性回归无法捕捉这些复杂的模式。
机器学习方法的核心思想是:不预先假设函数形式,而是让算法从数据中自动学习输入到输出的映射关系。树模型是最直观的一类机器学习方法。
3.2 决策树:从线性到分段常数
3.2.1 回归树的基本原理
回归树(Regression Tree)的工作方式与线性回归完全不同。它不拟合一条直线或超平面,而是通过递归分割将特征空间划分为多个区域,每个区域内的预测值为该区域样本的均值。
以电力消耗预测为例,假设我们仅用"小时"这一个特征:
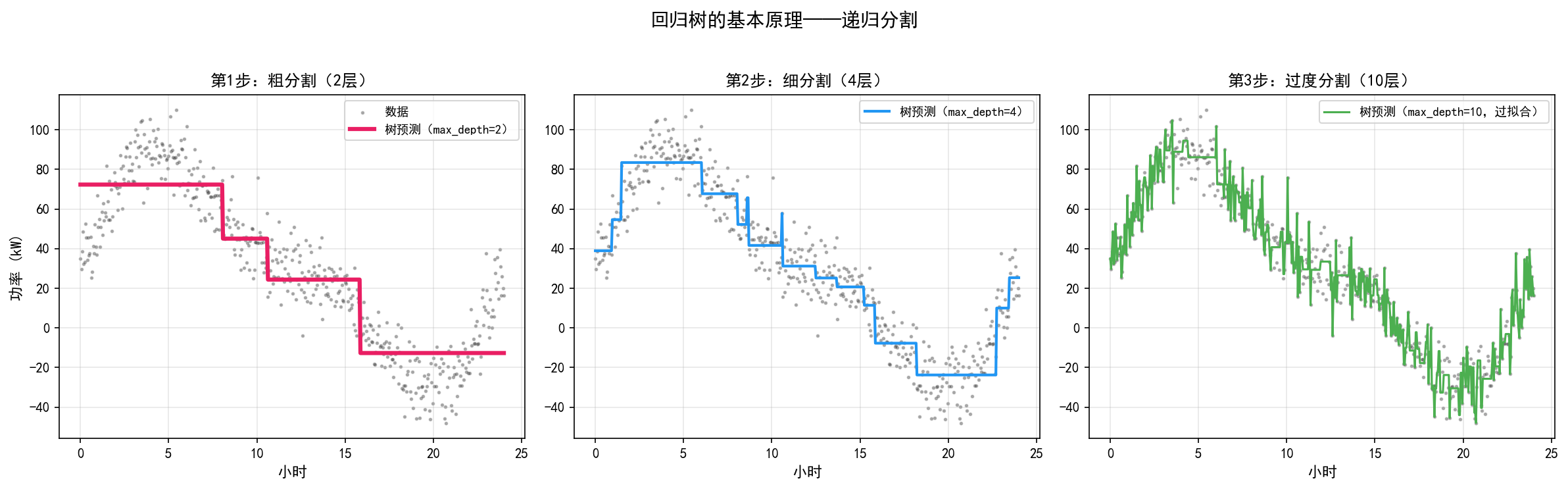
左图(max_depth=2):树只做了 2 次分割,将 24 小时分为 3 个区间,每个区间用一个常数值(红色水平线)预测。预测曲线是阶梯状的,无法捕捉精细的变化。
中图(max_depth=4):4 层分割将时间轴分为更多区间,阶梯变细,预测更精确。
右图(max_depth=10):树非常深,预测曲线紧密贴合训练数据——这正是过拟合的典型表现。模型记住了训练数据的噪声,而非学习通用规律。
与线性回归的对比:线性回归用一个全局公式 做预测;回归树用多个局部常数做预测。前者假设全局线性,后者假设局部恒定——各有优劣。
3.2.2 决策树的分裂准则
回归树在每次分割时,选择使残差平方和(RSS)最小化的特征和切分点:
对于小时特征,算法会尝试每个可能的切分点(如"小时 < 6""小时 < 7"…),选择使 RSS 最小的那个。然后对左右两个子节点递归重复这一过程,直到达到最大深度或节点样本数过少。
3.3 Boosting:集成学习的核心思想
单棵决策树有两个致命缺陷:
高方差:对训练数据的小变化敏感(如右图所示的过拟合)
表达能力有限:即使很深,也只能表示分段常数函数
集成学习(Ensemble Learning)通过组合多个弱模型来构建强模型。Boosting 是集成学习中最成功的范式之一。
3.3.1 Boosting 的直观理解
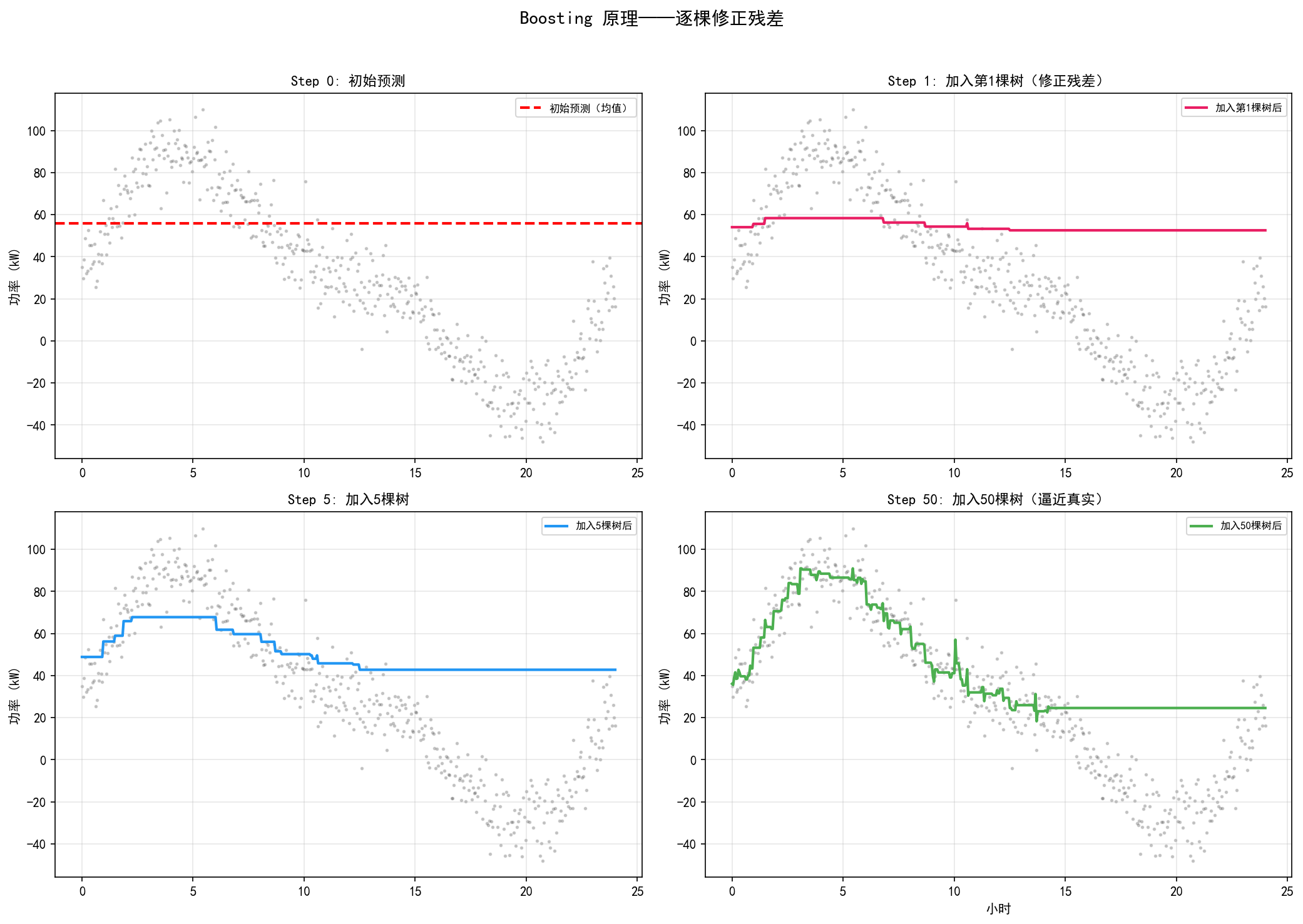
Step 0(左上):初始预测为训练集均值(红色虚线)。此时残差 = 真实值 - 均值。
Step 1(右上):训练第 1 棵树来拟合残差。将树的预测(乘以学习率)加到初始预测上,得到改进的预测曲线。
Step 5(左下):加入 5 棵树后,预测曲线开始呈现数据的整体形态。
Step 50(右下):加入 50 棵树后,预测曲线紧密贴合真实数据的趋势——这就是 Boosting 的力量:每棵新树只关注前一轮的错误,逐步修正,最终逼近真实函数。
3.3.2 Boosting 的数学描述
Boosting 的迭代过程可写为:
初始化:(均值)
对于 m=1,2,…,M:
计算残差:
训练第 m 棵树 hm(x) 拟合残差 ri
更新预测:
其中 η 是学习率(learning rate),控制每棵树的贡献大小。较小的学习率(如 0.1)需要更多树,但泛化性能更好。
3.4 XGBoost:优化的梯度提升树
XGBoost(eXtreme Gradient Boosting)是 Boosting 框架中最流行的实现之一。它在标准 GBDT 的基础上做了大量工程优化:
3.4.1 正则化——防止过拟合
XGBoost 的目标函数包含正则化项:
其中正则化项为:
T:树的叶子节点数——惩罚复杂树
w:叶子权重——惩罚大权重
γ,λ:正则化强度参数
这与岭回归(Ridge Regression)中的 L2 正则化思想完全一致——通过限制模型复杂度来提高泛化能力。
3.4.2 二阶泰勒展开——更精确的优化
标准 GBDT 仅使用损失函数的一阶导数(梯度),而 XGBoost 同时使用一阶和二阶导数:
其中 ,。
二阶导数提供了损失函数的曲率信息,使得优化方向更准确——类似于牛顿法比梯度下降法收敛更快。
3.4.3 其他关键优化
3.5 时间序列的特征工程
XGBoost 本身不处理时间依赖——它把每行数据视为独立样本。因此,我们需要手工构造时间特征,将时间序列转化为表格数据。
3.5.1 三类核心特征
def create_features(df, target_col='global_active_power'):
df = df.copy()
# (1) 时间特征:从时间戳提取
df['hour'] = df.index.hour # 0-23
df['day_of_week'] = df.index.dayofweek # 0-6
df['month'] = df.index.month # 1-12
df['is_weekend'] = (df.index.dayofweek >= 5).astype(int)
df['hour_sin'] = np.sin(2 * np.pi * df.index.hour / 24)
df['hour_cos'] = np.cos(2 * np.pi * df.index.hour / 24)
# (2) 滞后特征:历史观测值
for lag in [1, 2, 3, 6, 12, 24, 48, 168]:
df[f'lag_{lag}'] = df[target_col].shift(lag)
# (3) 滚动统计:局部趋势
for window in [6, 12, 24, 48]:
df[f'rolling_mean_{window}'] = df[target_col].rolling(window=window).mean()
df[f'rolling_std_{window}'] = df[target_col].rolling(window=window).std()
df['diff_1'] = df[target_col].diff(1) # 一阶差分
df['diff_24'] = df[target_col].diff(24) # 日差分
df = df.dropna()
return df
3.5.2 数据集划分
n = len(X)
train_end = int(n * 0.7)
val_end = int(n * 0.85)
X_train = X.iloc[:train_end] # 前 70%
X_val = X.iloc[train_end:val_end] # 中间 15%
X_test = X.iloc[val_end:] # 最后 15%
重要:时间序列必须按时间顺序划分,不能随机打乱——否则会用"未来"数据预测"过去",造成信息泄露。
3.6 模型训练与评估
3.6.1 训练 XGBoost
from xgboost import XGBRegressor
model = XGBRegressor(
n_estimators=200, # 200 棵树
max_depth=6, # 每棵树最多 6 层
learning_rate=0.1, # 学习率
subsample=0.8, # 每棵树用 80% 样本
colsample_bytree=0.8, # 每棵树用 80% 特征
random_state=42,
n_jobs=-1 # 使用所有 CPU 核心
)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)], verbose=False)
参数解读:
n_estimators:树的数量。越多通常越好,但计算成本增加
max_depth:每棵树的最大深度。越大模型越复杂,越容易过拟合
learning_rate:每棵树的贡献权重。较小的值(0.01-0.1)配合更多树通常效果更好
subsample / colsample_bytree:采样比例,增加模型多样性,防止过拟合
3.6.2 预测与评估
y_pred = model.predict(X_test)
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R²: {r2:.4f}")
RMSE: 1.28, MAE: 0.69, R²: 0.9991
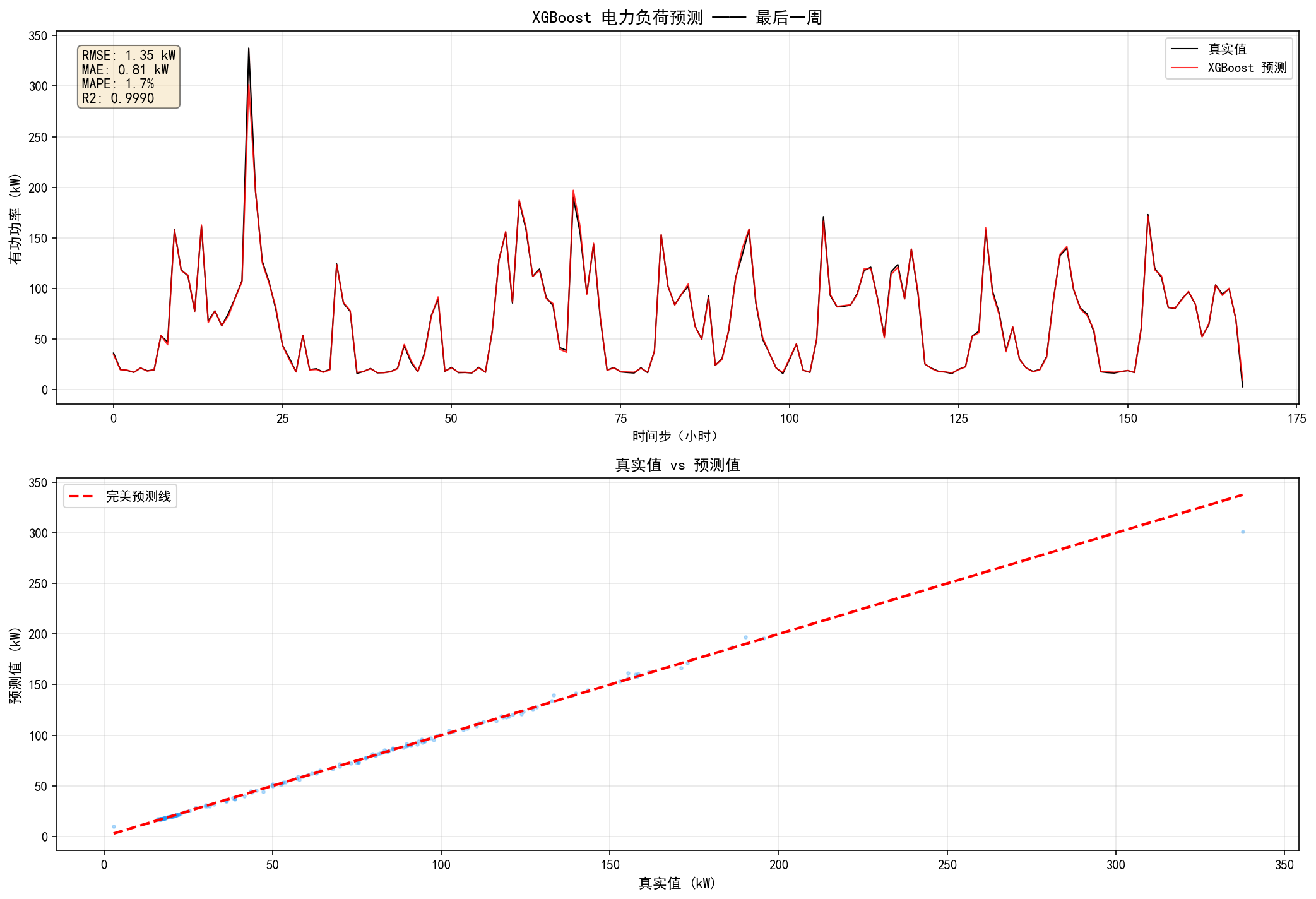
上图:红色预测线与黑色真实线几乎重合,模型成功捕捉了:
每日双峰模式(早晚用电高峰)
周末与工作日的差异
功率的剧烈波动
下图:散点紧密分布在完美预测线附近,表明模型在各功率水平都有良好表现。
3.7 特征重要性分析
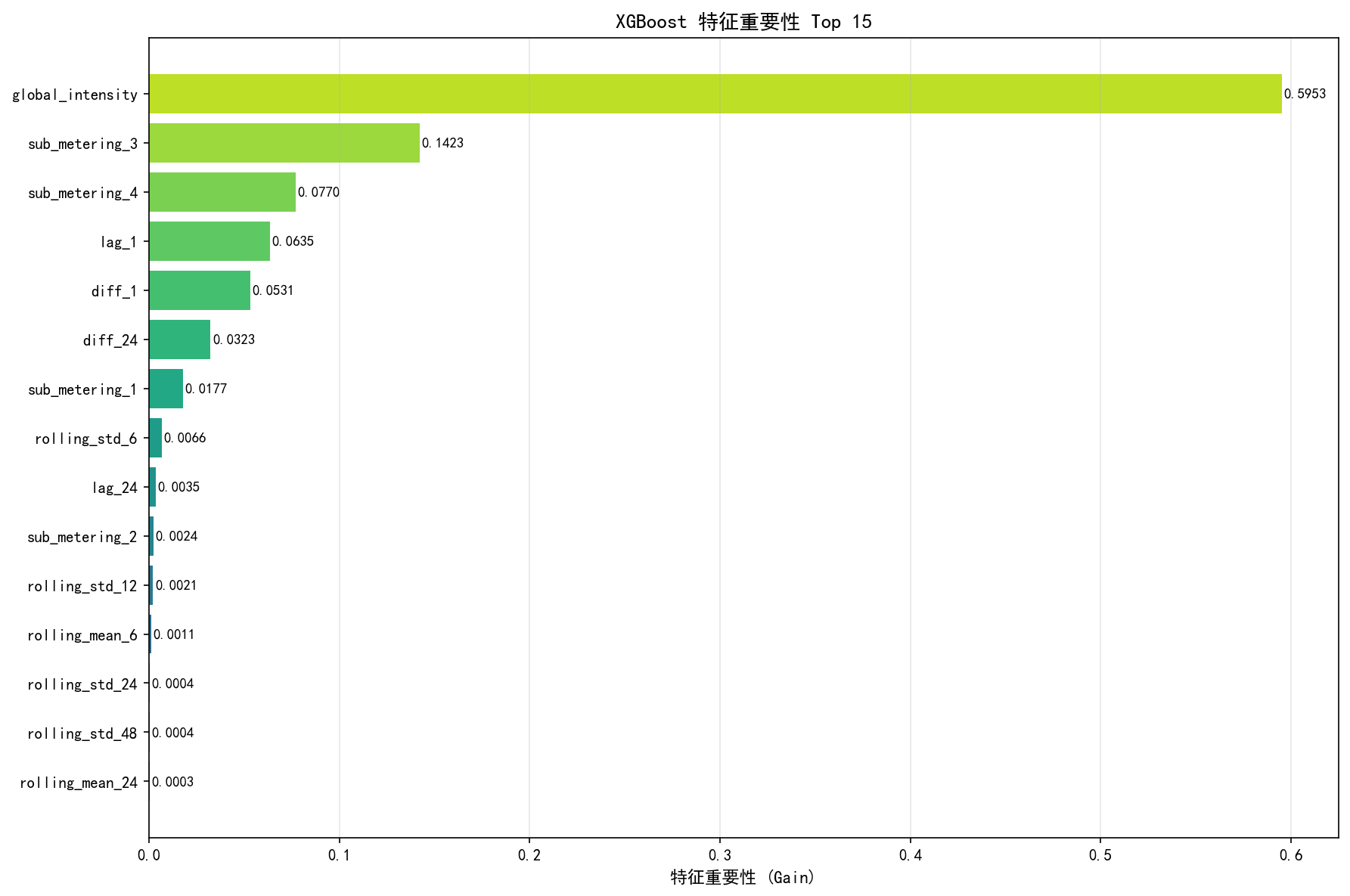
XGBoost 提供了特征重要性(Feature Importance)——每个特征对预测的贡献度。这与回归分析中的系数大小类似,但更灵活:
解读:
global_intensity(电流强度)的重要性高达 59.5%,远超其他特征。这是因为在电力系统中,有功功率 P、电压 V、电流 I 满足 的物理关系——模型自动"学习"到了这一物理定律。
3.8 特征工程的增量效果
逐步增加特征类型,观察 RMSE 的变化:
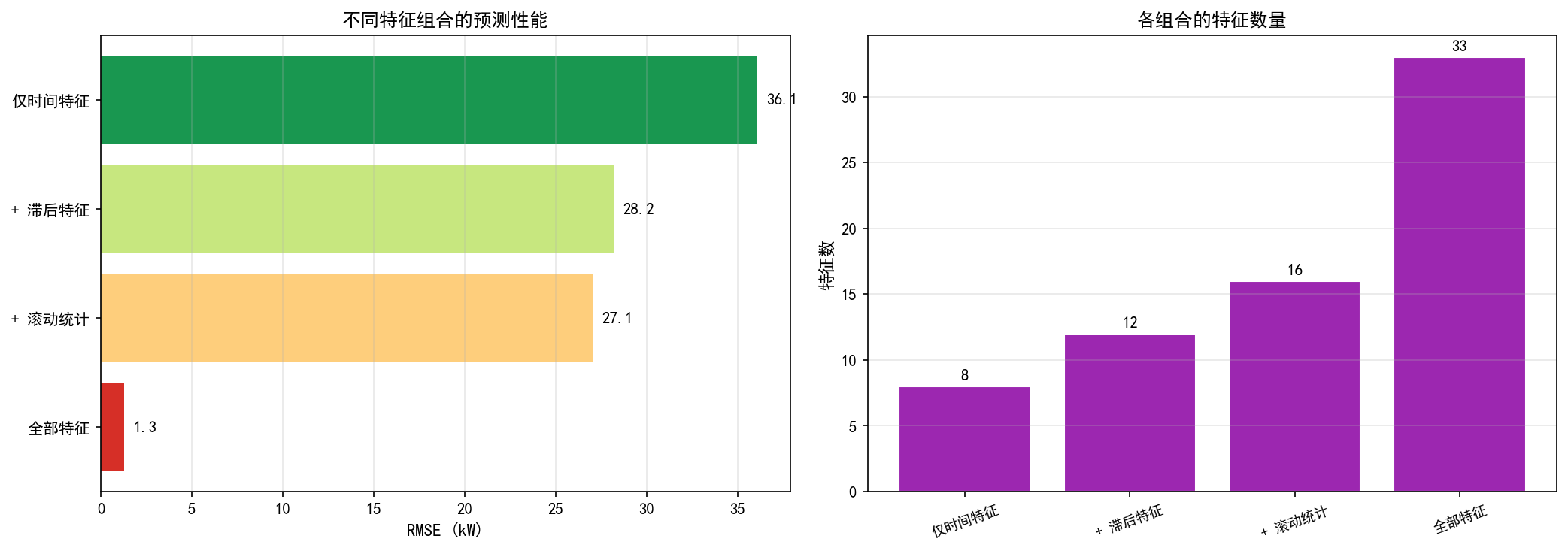
关键发现:
仅时间特征效果最差——只知道"现在是下午 6 点"不足以预测具体用电量
滞后特征带来第一个大幅提升——"上一小时用了 100 kW"是有价值的信息
多变量输入(加入其他电力变量)是最大的飞跃——RMSE 从 27.1 降至 1.3
数学建模竞赛建议:特征工程的质量往往比模型选择更重要。一个好的特征集配合简单模型,通常优于平庸特征配合复杂模型。
3.9 完整代码
import pandas as pd
import numpy as np
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载数据
power_df = pd.read_csv('household_power_consumption_hourly.csv',
parse_dates=['datetime'], index_col='datetime')
# 2. 特征工程
power_featured = create_features(power_df)
target_col = 'global_active_power'
feature_cols = [c for c in power_featured.columns if c != target_col]
X = power_featured[feature_cols]
y = power_featured[target_col]
# 3. 按时间顺序划分
n = len(X)
train_end = int(n * 0.7)
val_end = int(n * 0.85)
X_train, y_train = X.iloc[:train_end], y.iloc[:train_end]
X_val, y_val = X.iloc[train_end:val_end], y.iloc[train_end:val_end]
X_test, y_test = X.iloc[val_end:], y.iloc[val_end:]
# 4. 训练 XGBoost
model = XGBRegressor(
n_estimators=200, max_depth=6, learning_rate=0.1,
subsample=0.8, colsample_bytree=0.8,
random_state=42, n_jobs=-1
)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)], verbose=False)
# 5. 预测与评估
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R²: {r2:.4f}")
3.10 本节小结
决策树通过递归分割特征空间做预测,简单直观但容易过拟合
Boosting通过逐棵修正残差,将多个弱树组合成强模型
XGBoost在 Boosting 基础上加入正则化和二阶优化,是目前最强大的树模型之一
特征工程是决定性因素:从 36.1 kW 到 1.3 kW 的差距完全来自特征质量
树模型的核心优势:自动处理非线性关系和特征交互,无需假设函数形式
树模型的局限:无法外推到训练范围之外的值
下一章介绍 LightGBM——XGBoost 的高效版本,训练速度快 10 倍以上
第4章 LightGBM——更高效的树模型
4.1 LightGBM 的诞生
XGBoost 虽然强大,但在处理超大规模数据集时仍面临两个瓶颈:
内存占用高:需要将所有特征值预排序存储在内存中
训练速度慢:预排序和精确分割点搜索计算量大
LightGBM(Light Gradient Boosting Machine)由微软于 2017 年开源,核心目标是:在保持精度的前提下,大幅提升训练速度、降低内存占用。
4.2 核心优化一:直方图算法(Histogram)
4.2.1 XGBoost 的预排序方法
XGBoost 在训练每棵树时,对每个特征的所有取值进行排序,然后遍历每一个可能的分割点,计算增益。对于一个有 N 个样本、D 个特征的数据集:
预排序需要大量内存和计算。
4.2.2 LightGBM 的直方图方法
LightGBM 的解决方案是:将连续特征值离散化为固定数量的桶(bin),通常为 256 个。
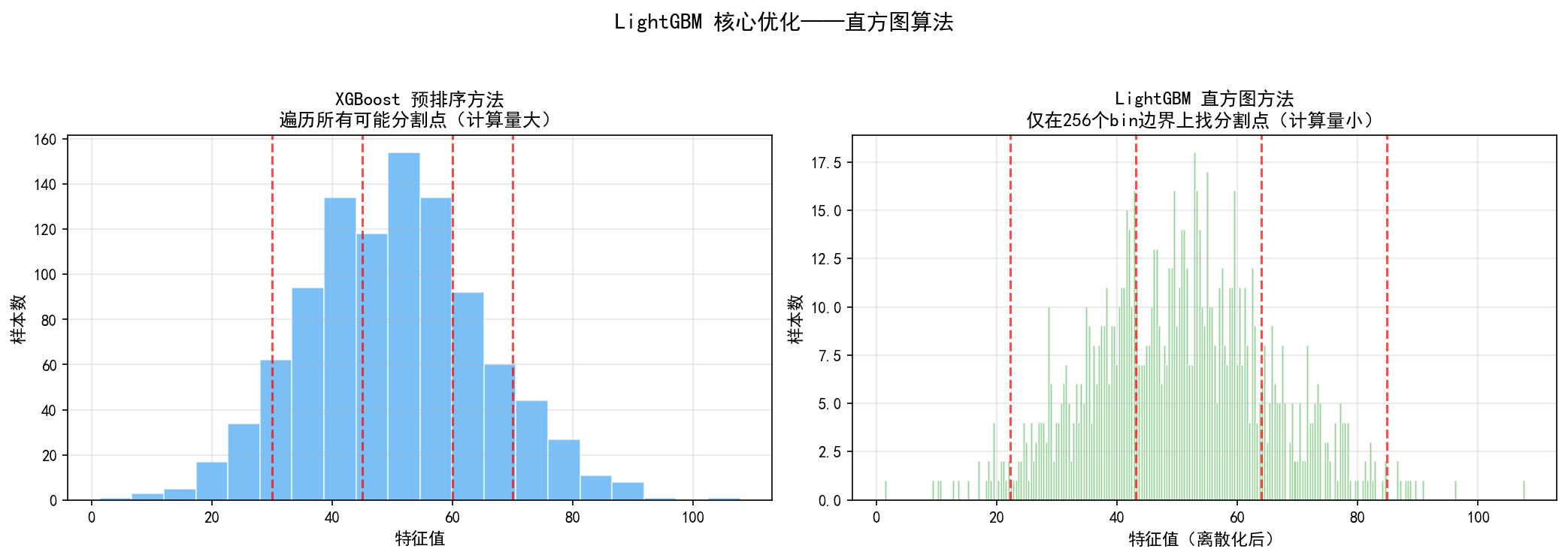
左图(XGBoost 预排序):需要遍历每个可能的分割点(红色虚线),计算量大。
右图(LightGBM 直方图):先将特征值离散化为 256 个桶,分割点只在桶边界上寻找。计算量从 O(N) 降为 O(256),速度提升显著。
具体过程:
对每个特征,计算其取值范围的直方图(256 个 bin)
在 bin 边界上寻找最优分割点
子节点直方图可以通过父节点直方图相减得到(无需重新扫描数据)
类比理解:这就像用直方图近似连续分布——虽然牺牲了一点精度,但换来巨大的效率提升。对于大多数问题,256 个 bin 的精度损失可以忽略不计。
4.3 核心优化二:Leaf-wise 树生长
4.3.1 Level-wise vs Leaf-wise
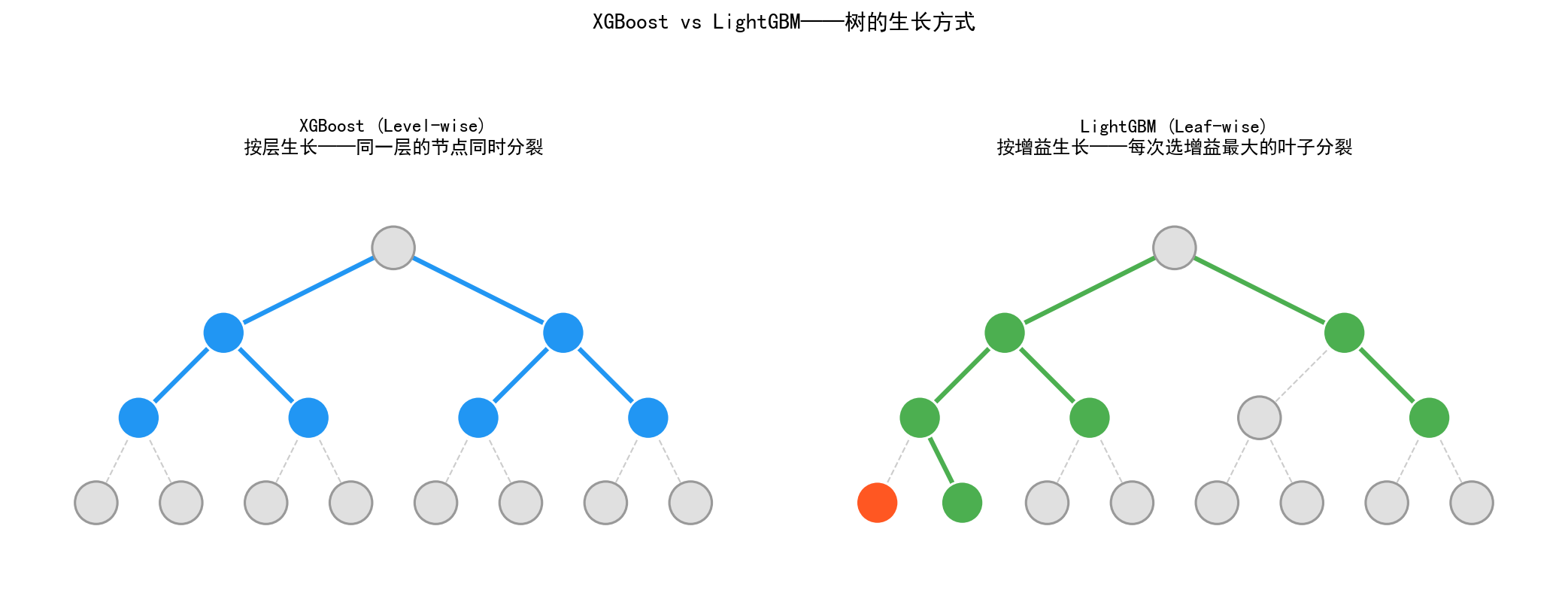
左图(XGBoost Level-wise):按层生长,同一层的所有节点同时分裂。树是平衡的,深度均匀增加。
优点:不易过拟合,树的深度可控
缺点:可能分裂增益很小的节点,浪费计算资源
右图(LightGBM Leaf-wise):每次选择增益最大的叶子节点进行分裂。树是不平衡的——某些分支很深,某些分支很浅。
优点:用更少的分裂达到更低的损失,效率更高
缺点:容易过拟合(树可能变得很深)
4.3.2 防止 Leaf-wise 过拟合
LightGBM 通过两个参数控制 Leaf-wise 树的深度:
lgbm = LGBMRegressor(
n_estimators=200,
max_depth=6, # 限制最大深度(与 XGBoost 相同)
num_leaves=31, # 限制叶子节点数(核心参数)
learning_rate=0.1,
min_child_samples=20, # 叶子最少样本数
)
关键参数 num_leaves:
Level-wise 树中,深度为 d 的树最多有 2d 个叶子
Leaf-wise 树中,
num_leaves应该小于 2d(通常设为 2d−1 到 2d 之间)例如:
max_depth=6时,num_leaves建议设为 31
4.4 核心优化三:其他加速技术
4.5 训练速度与精度对比
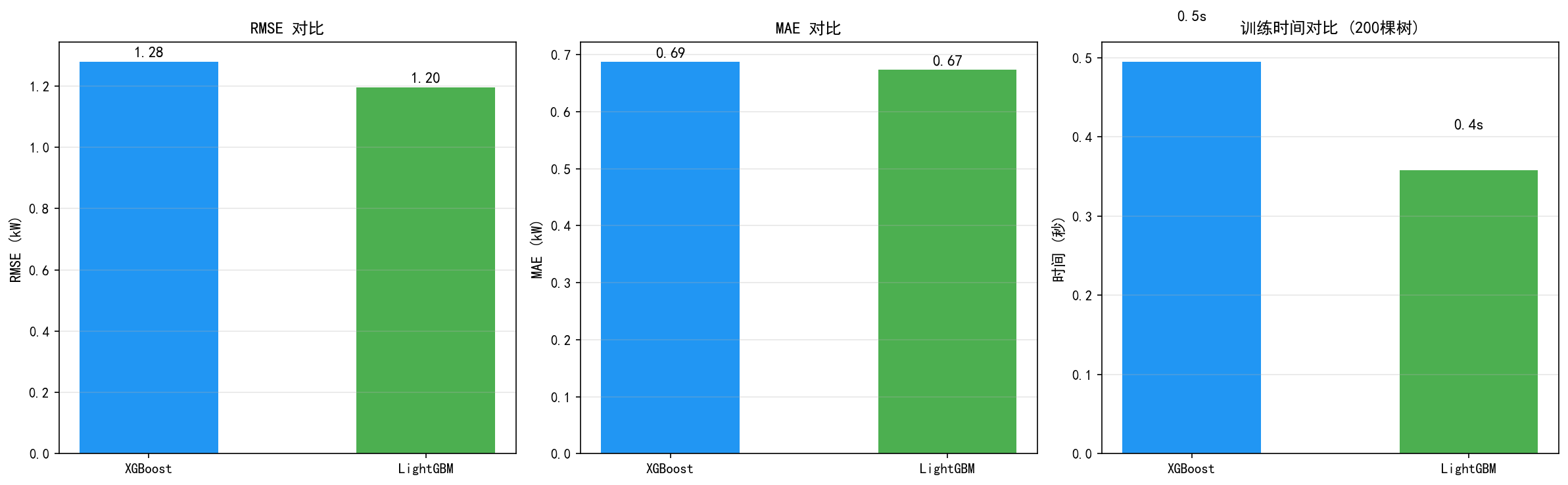
在本数据集(34,589 条样本,33 个特征)上的实测结果:
在这个数据量下,两者差距不大。但随着数据量增加,LightGBM 的优势会越来越明显:
百万级数据:LightGBM 通常快 5-10 倍
十亿级数据:LightGBM 可快 数十倍
4.5.1 预测效果对比
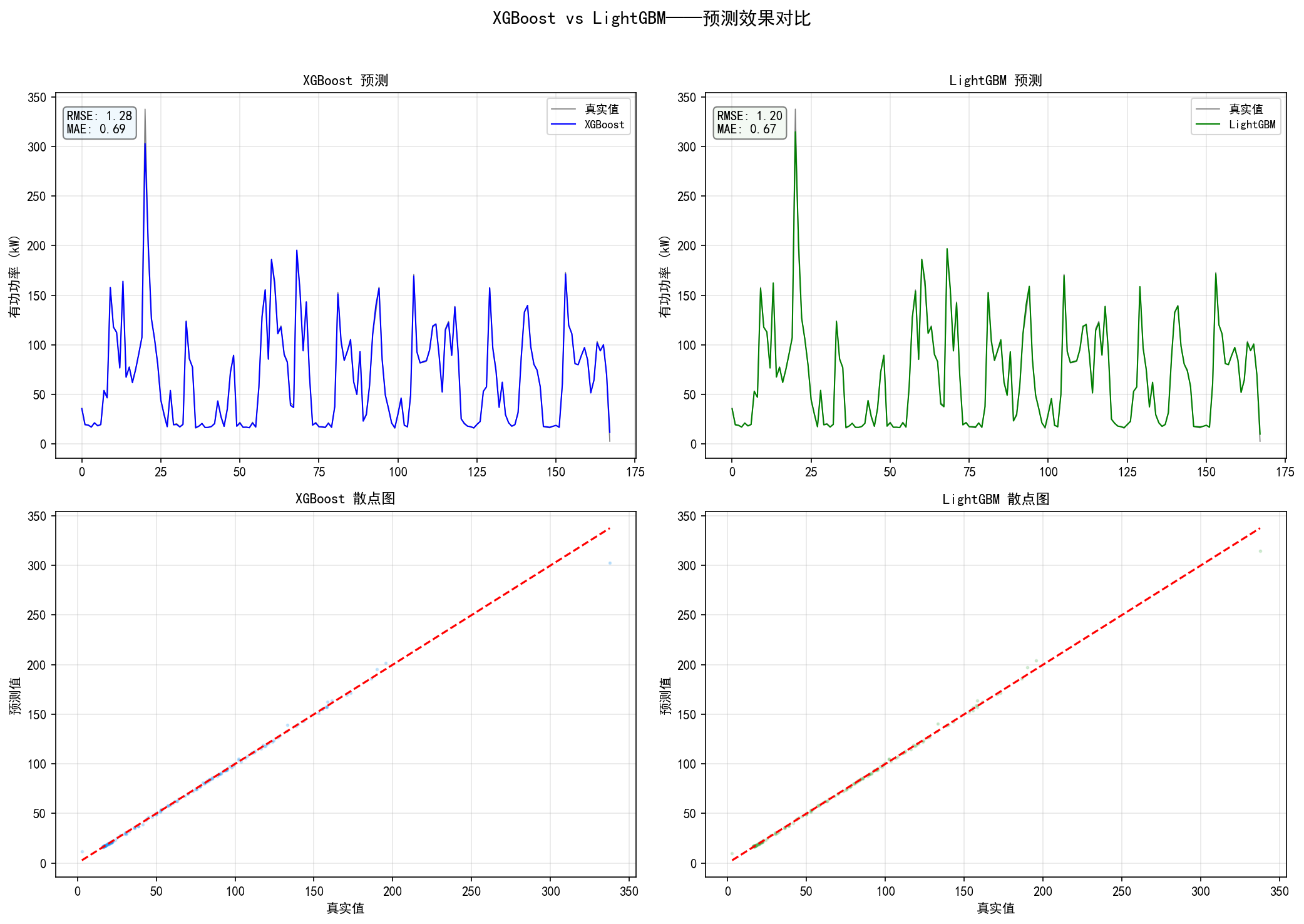
从散点图可以看出,LightGBM 的预测点更紧密地分布在完美预测线附近——这与 Leaf-wise 生长策略有关:它能更精细地拟合数据的局部模式。
4.6 特征重要性对比
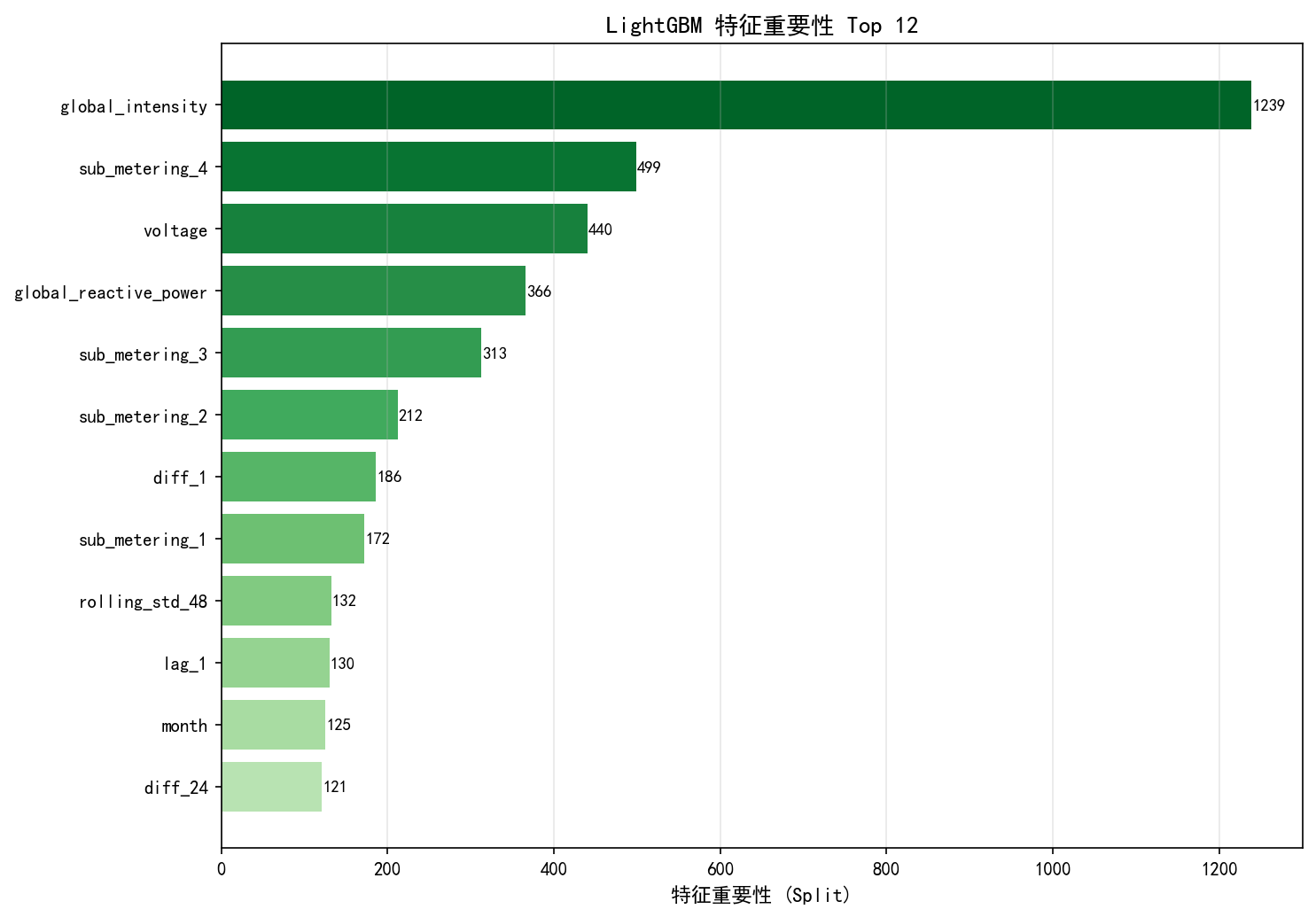
LightGBM 的特征重要性排序与 XGBoost 基本一致,前三大特征均为:
global_intensity(电流强度)— 最重要的物理变量sub_metering_3(温控系统能量)— 空调/暖气的主导作用sub_metering_4(其他设备)— 剩余未计量消耗
这进一步验证了:电力系统的物理规律是预测的核心驱动力,而非复杂的时序模式。
4.7 代码实操
4.7.1 LightGBM 基本用法
LightGBM 的 API 与 XGBoost 几乎完全一致,迁移成本极低:
from lightgbm import LGBMRegressor
model = LGBMRegressor(
n_estimators=200, # 树的数量
max_depth=6, # 最大深度
learning_rate=0.1, # 学习率
num_leaves=31, # 叶子数(Leaf-wise 核心参数)
min_child_samples=20, # 叶子最少样本数
subsample=0.8, # 样本采样
colsample_bytree=0.8, # 特征采样
random_state=42,
n_jobs=-1, # 多线程
verbosity=-1 # 关闭输出
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
4.7.2 超参数调优建议
4.7.3 与 XGBoost 的选择建议
类别特征:LightGBM 可以直接处理类别变量(无需独热编码),通过
categorical_feature参数指定。这在处理"星期几""月份"等特征时非常方便。
4.8 完整代码
import pandas as pd
import numpy as np
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载数据与特征工程(同第3章)
power_featured = create_features(power_df)
target_col = 'global_active_power'
feature_cols = [c for c in power_featured.columns if c != target_col]
X = power_featured[feature_cols]
y = power_featured[target_col]
# 2. 划分数据集
n = len(X)
train_end = int(n * 0.7)
val_end = int(n * 0.85)
X_train, y_train = X.iloc[:train_end], y.iloc[:train_end]
X_val, y_val = X.iloc[train_end:val_end], y.iloc[train_end:val_end]
X_test, y_test = X.iloc[val_end:], y.iloc[val_end:]
# 3. 训练 LightGBM
model = LGBMRegressor(
n_estimators=200, max_depth=6, learning_rate=0.1,
num_leaves=31, min_child_samples=20,
subsample=0.8, colsample_bytree=0.8,
random_state=42, n_jobs=-1, verbosity=-1
)
model.fit(X_train, y_train)
# 4. 预测与评估
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R²: {r2:.4f}")
4.9 本节小结
LightGBM 是 XGBoost 的高效替代方案,核心优化包括直方图算法和 Leaf-wise 生长
直方图算法将连续特征离散化为 256 个 bin,大幅降低计算量
Leaf-wise 生长每次分裂增益最大的叶子,用更少的分裂达到更低的损失
在本数据集上,LightGBM 的 RMSE 略优于 XGBoost(1.20 vs 1.28),训练时间相当
数据量越大,LightGBM 的速度优势越明显(可达 10 倍以上)
LightGBM 原生支持类别特征,处理分类变量更方便
下一章将进入深度学习领域——LSTM,它不需要手工特征工程,通过端到端学习自动提取时序模式
第5章 LSTM——序列建模的深度学习基础
5.1 从统计方法到深度学习
在前面的章节中,我们使用树模型(XGBoost、LightGBM)取得了很好的预测效果。但树模型有一个本质局限:它把时间序列当作普通表格数据处理,通过手工特征工程(滞后特征、滚动统计、时间特征)来"告诉"模型时间信息。
深度学习提供了一种不同的思路:端到端(end-to-end)学习——直接把原始序列输入模型,让模型自己学习时间模式,无需手工构造特征。
本章介绍序列建模的里程碑模型:LSTM(Long Short-Term Memory,长短期记忆网络)。
5.2 循环神经网络(RNN)的基本思想
5.2.1 为什么要用 RNN?
线性回归中,每个样本被视为独立的。但时间序列的本质是前后相关——今天的用电量与昨天有关。RNN 的核心创新是:让模型的输出不仅依赖当前输入,还依赖"记忆"。
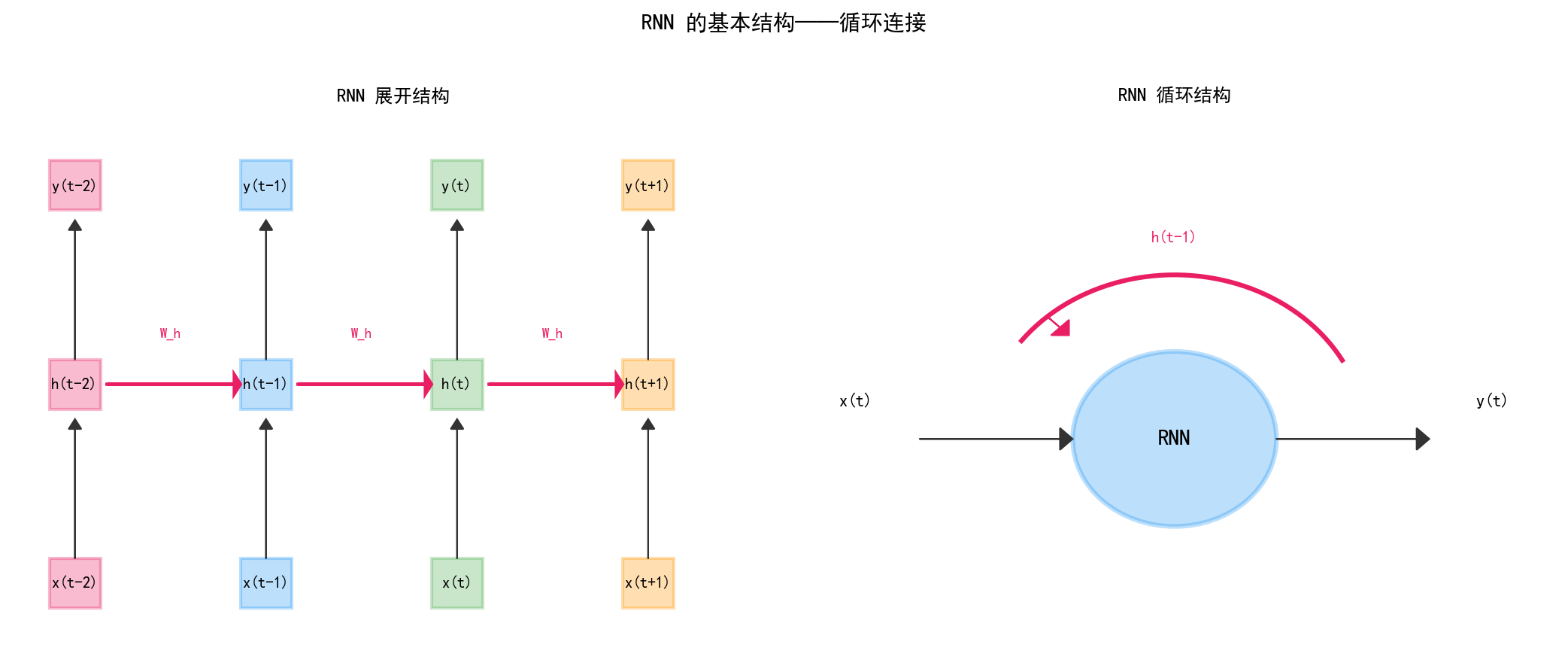
左图(展开结构):RNN 在每个时间步接收输入 x(t),更新隐藏状态 h(t),输出 y(t)。关键在红色的循环箭头:h(t-1) 的信息被传递到 h(t)。
右图(循环结构):RNN 单元有一个"自循环"——它的输出 h(t) 既是当前时刻的结果,也是下一时刻的输入之一。这就是"记忆"的来源。
数学上,RNN 的隐藏状态更新公式为:
其中 Wh 是循环权重矩阵——它决定了"记忆"的保留程度。
5.2.2 类比理解
想象你在读一篇文章:
前馈神经网络(如多层感知机):每次只看一个词,不知道上下文
RNN:读每个词时,带着前文的"记忆",所以能理解"它"指的是什么
5.3 RNN 的致命问题:梯度消失
RNN 理论上可以记住任意远的历史信息,但实际上它很难做到。原因在于梯度消失(Vanishing Gradient)。
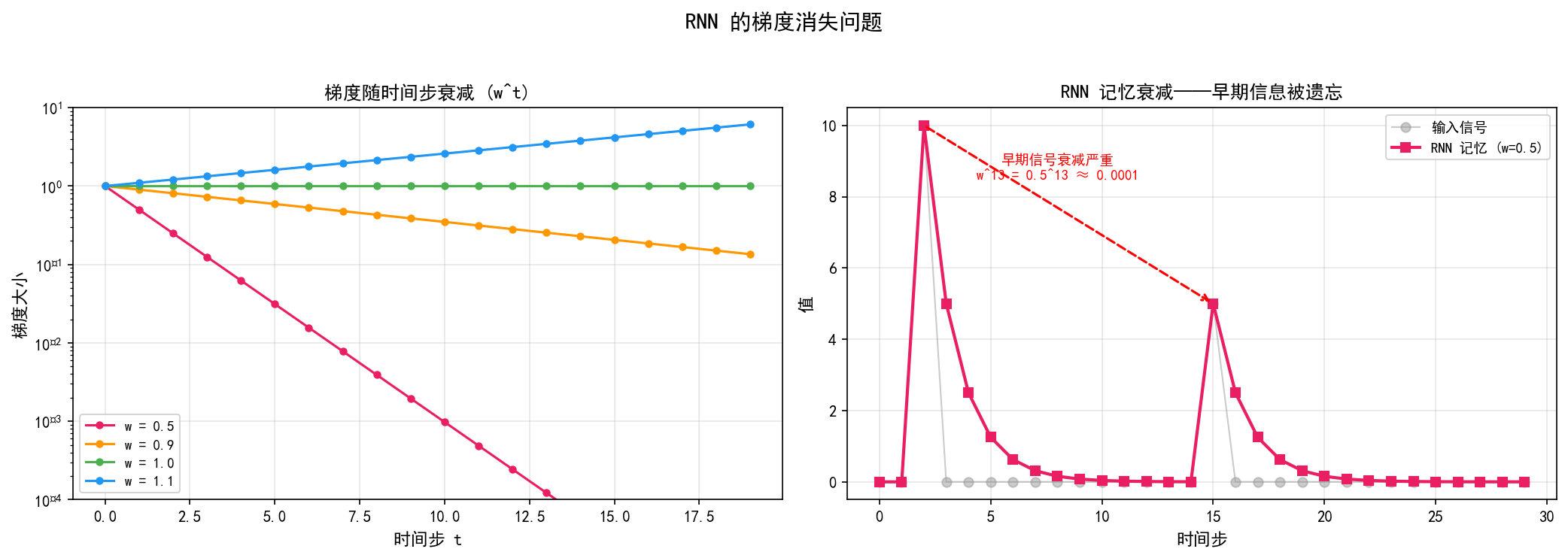
左图:梯度大小随时间步的变化。当权重 w<1 时,经过 t 步的链式求导,梯度变为 wt——呈指数衰减。例如 w=0.5 时,经过 13 步后梯度只剩 0.513≈0.0001,几乎为零。这意味着网络无法通过反向传播更新早期的参数。
右图:输入信号在 t=2 有一个冲击(值=10),t=15 有一个冲击(值=5)。RNN 的记忆(红色线)在 t=2 的冲击经过 13 步后衰减到几乎为零——早期的信息被"遗忘"了。
类比理解:这就像你在电话里传话。每经过一个人,信息就会损失一些。经过 10 个人后,最初的内容已经面目全非。RNN 的"记忆"也是如此——信息在时间上传递时不断衰减。
5.4 LSTM:解决梯度消失的方案
LSTM(Long Short-Term Memory)由 Hochreiter 和 Schmidhuber 于 1997 年提出。它通过门控机制(Gating)解决 RNN 的梯度消失问题。
5.4.1 LSTM 的核心:细胞状态(Cell State)
LSTM 与普通 RNN 的最大区别在于:它有一条贯穿整个序列的"高速公路"——细胞状态 C(t)。
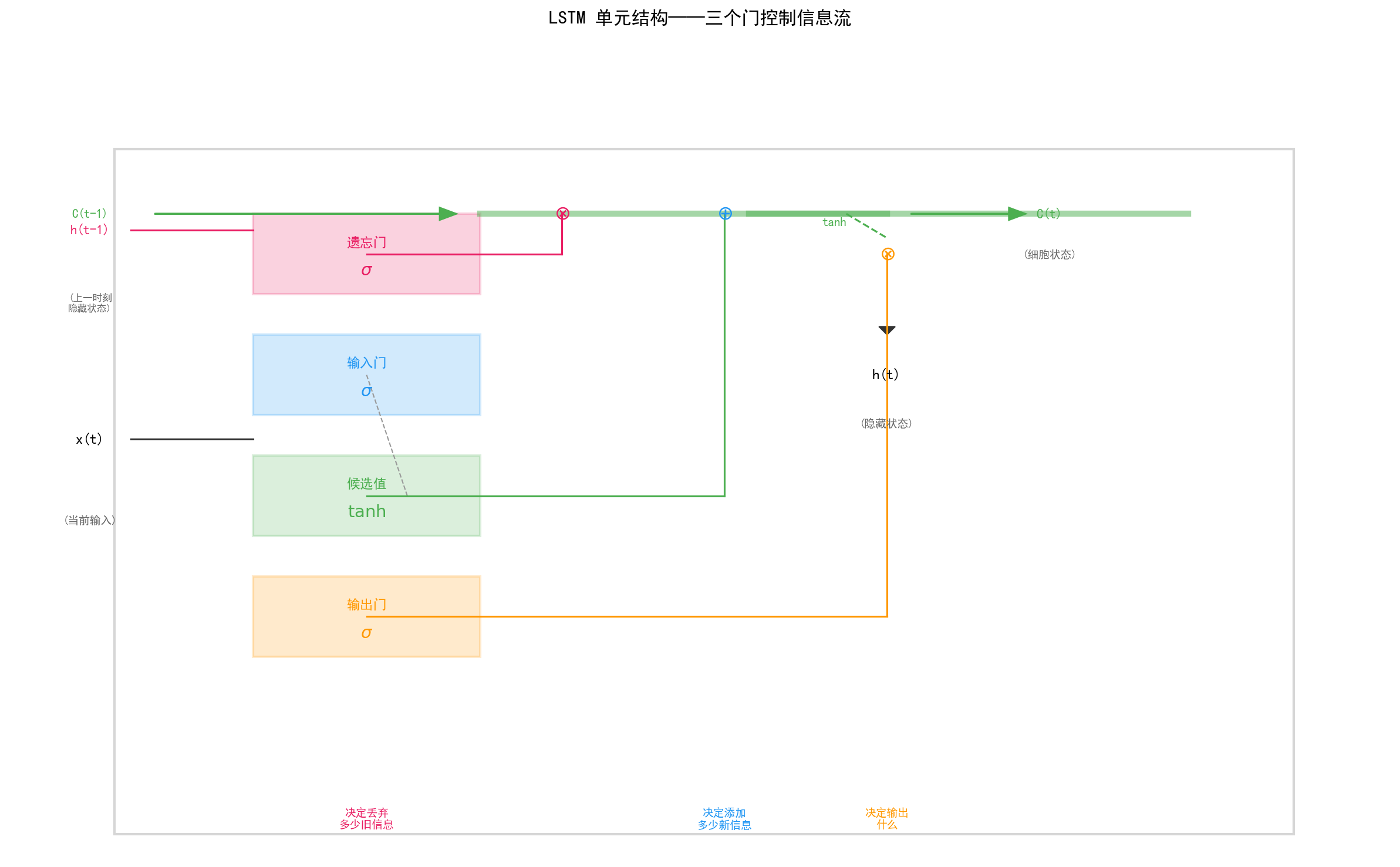
绿色的粗线就是细胞状态——它从 C(t-1) 一路延伸到 C(t),中间经过的操作是加法和逐元素乘法。这两个操作对梯度传播非常友好:
加法:梯度可以直接穿过(,不会衰减)
乘法:通过门控值(0 到 1 之间)控制信息流
5.4.2 三个门的作用
配合一个候选值(Candidate):
细胞状态的更新过程:
遗忘:(遗忘门决定保留多少旧信息)
更新:(输入门决定添加多少新信息)
输出:(输出门决定隐藏状态输出什么)
类比理解:把细胞状态想象成一条传送带。
遗忘门是传送带上的"过滤网"——决定哪些旧物品继续留下
输入门是"加料站"——决定放什么新物品上去
输出门是"观察窗"——决定让外界看到传送带上的什么
5.4.3 为什么 LSTM 能解决梯度消失?
关键在于细胞状态的加法操作。在反向传播时,梯度从 C(t) 传回 C(t-1) 的路径中,加法的导数是 1——梯度不会指数衰减。这使得 LSTM 可以记住数百甚至数千步远的信息。
5.5 代码实操:用 PyTorch 训练 LSTM
5.5.1 序列数据的准备
与树模型不同,LSTM 的输入是序列而非独立样本:
def create_sequences(data, seq_length, pred_length=1):
X, y = [], []
for i in range(len(data) - seq_length - pred_length + 1):
X.append(data[i:i+seq_length]) # 过去 seq_length 步
y.append(data[i+seq_length:i+seq_length+pred_length]) # 未来 pred_length 步
return np.array(X), np.array(y)
SEQ_LENGTH = 24 # 用过去24小时
PRED_LENGTH = 1 # 预测未来1小时
5.5.2 定义 LSTM 模型
使用 PyTorch 构建两层 LSTM:
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2, dropout=0.2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,
batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
# 取最后一个时间步的输出
out = self.fc(out[:, -1, :])
return out
关键参数说明:
input_size=1:每个时间步输入 1 个特征(归一化后的有功功率)hidden_size=64:隐藏状态的维度num_layers=2:堆叠 2 层 LSTM(更深层可以学习更复杂的模式)dropout=0.2:防止过拟合的随机丢弃
5.5.3 训练过程
model = LSTMModel(input_size=1, hidden_size=64, num_layers=2, dropout=0.2)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
n_epochs = 50
batch_size = 64
train_loader = DataLoader(TensorDataset(X_train_t, y_train_t),
batch_size=batch_size, shuffle=False)
for epoch in range(n_epochs):
model.train()
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
5.6 训练结果分析
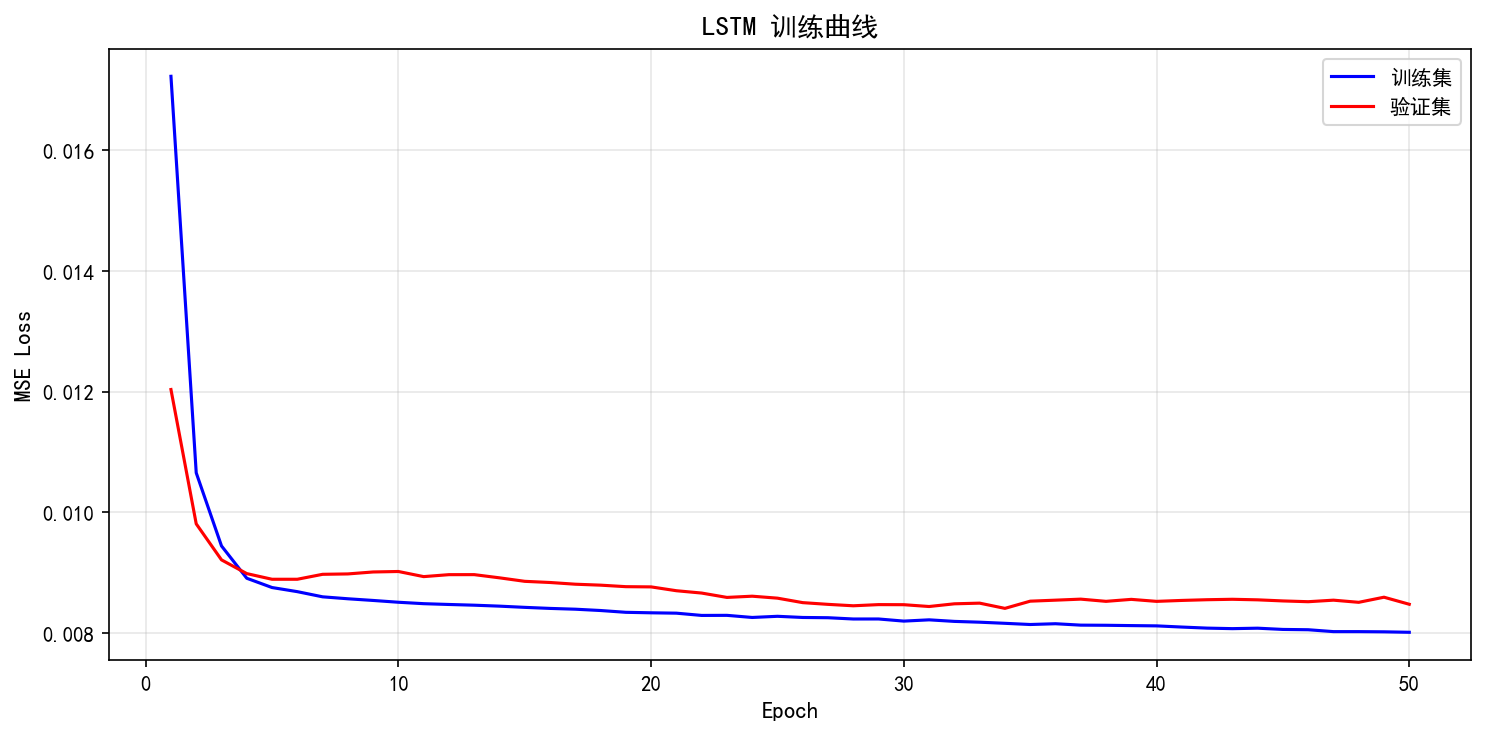
5.6.1 训练曲线
训练集 Loss 持续下降
验证集 Loss 在前 10 个 Epoch 快速下降,之后趋于平稳
训练集和验证集之间差距很小——没有明显过拟合
5.6.2 预测效果
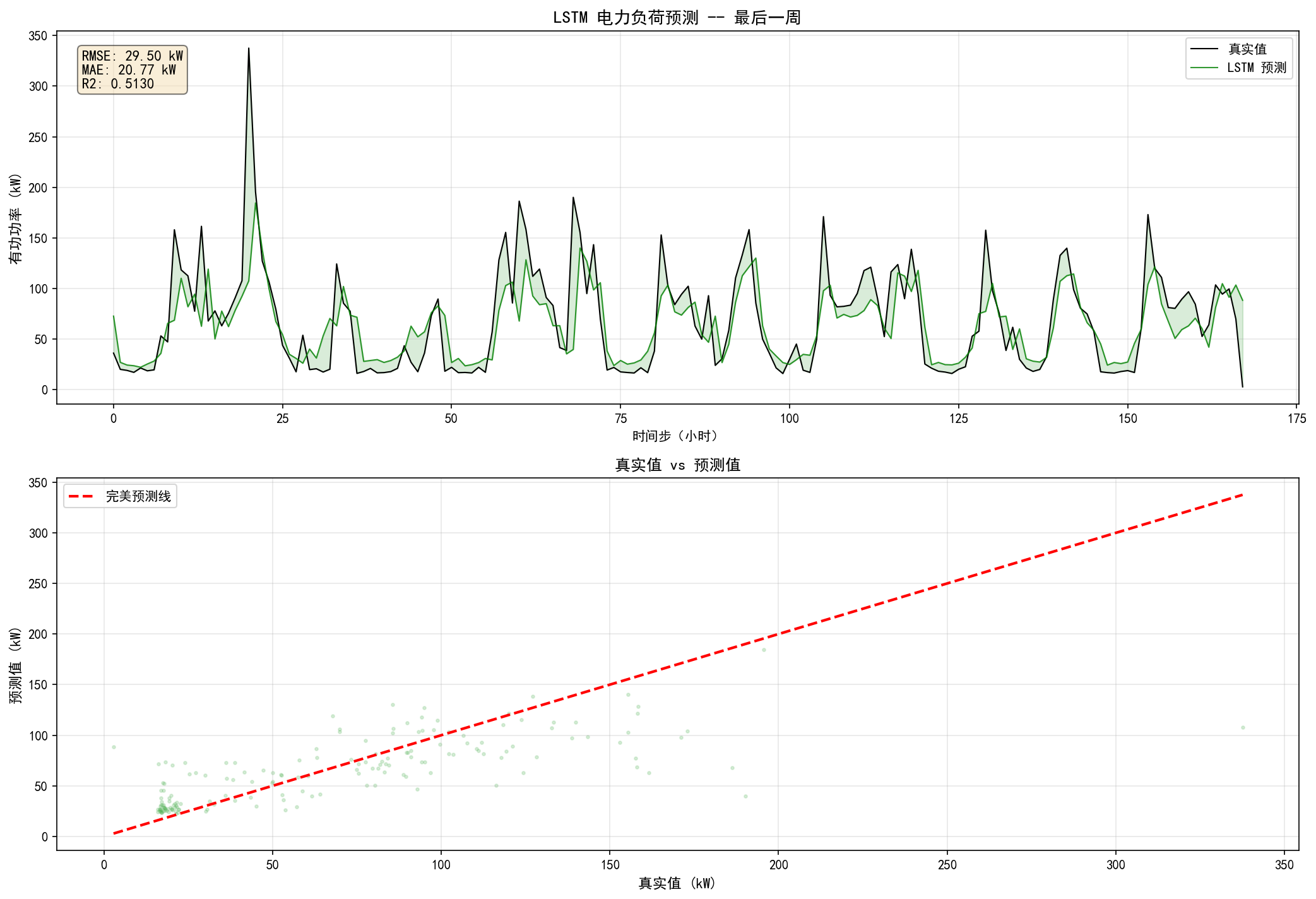
RMSE: 29.50 kW,MAE: 20.77 kW,R²: 0.5130
预测曲线能捕捉到大致的日周期模式,但在峰值处的预测偏差较大
5.6.3 与 XGBoost 的对比
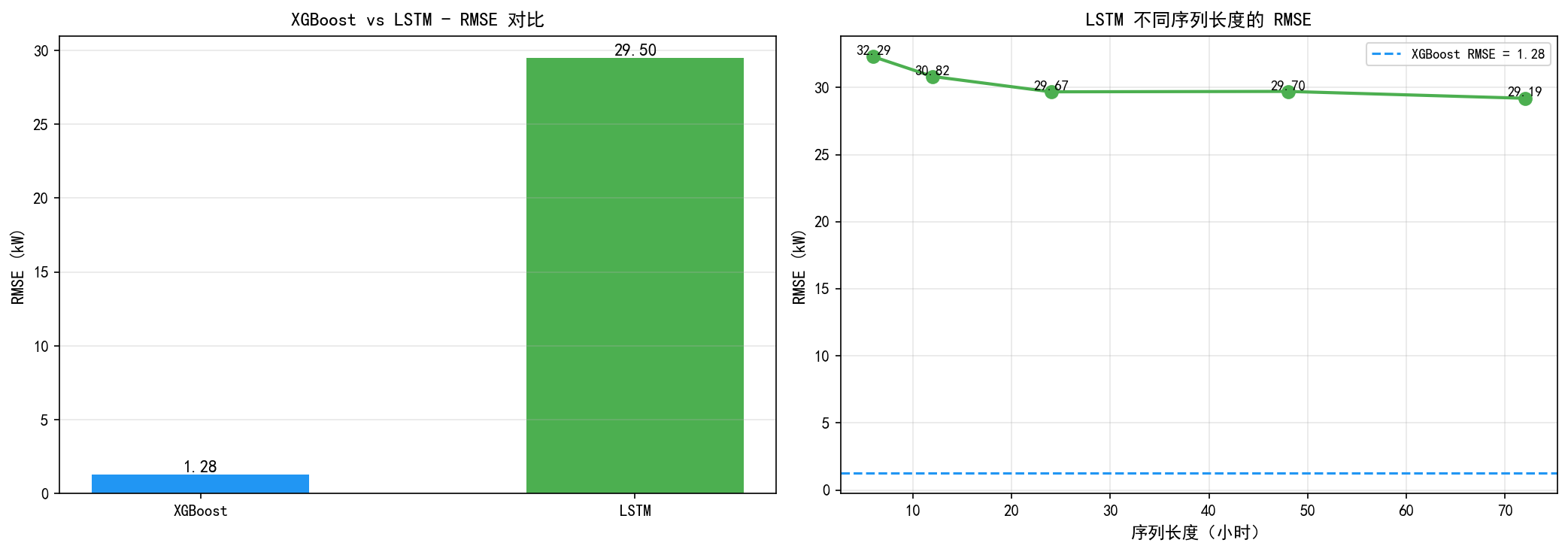
左图:XGBoost RMSE = 1.28 kW,LSTM RMSE = 29.50 kW——差距悬殊。
右图:改变 LSTM 的序列长度(6、12、24、48、72 小时),RMSE 在 29-33 之间波动,没有显著改善。
为什么 LSTM 不如 XGBoost?
这不是 LSTM 本身的问题,而是输入信息的差距:
XGBoost 用了 33 个特征:电流强度、各子系统功率、滞后特征、滚动统计、时间特征等
LSTM 只用了 1 个特征:归一化后的有功功率序列
这说明了一个重要道理:特征工程的质量往往比模型的选择更重要。如果给 LSTM 也加上多变量输入,它的表现会大幅提升。
5.7 LSTM 的完整代码
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载数据
power_df = pd.read_csv('household_power_consumption_hourly.csv',
parse_dates=['datetime'], index_col='datetime')
power_series = power_df['global_active_power'].dropna().copy()
# 2. 归一化(LSTM 对数据尺度敏感,必须归一化)
scaler = MinMaxScaler()
power_scaled = scaler.fit_transform(power_series.values.reshape(-1, 1)).flatten()
# 3. 创建序列数据
def create_sequences(data, seq_length, pred_length=1):
X, y = [], []
for i in range(len(data) - seq_length - pred_length + 1):
X.append(data[i:i+seq_length])
y.append(data[i+seq_length:i+seq_length+pred_length])
return np.array(X), np.array(y)
X_all, y_all = create_sequences(power_scaled, seq_length=24, pred_length=1)
n = len(X_all)
train_end = int(n * 0.7)
val_end = int(n * 0.85)
X_train = X_all[:train_end].reshape(-1, 24, 1)
y_train = y_all[:train_end]
X_val = X_all[train_end:val_end].reshape(-1, 24, 1)
y_val = y_all[train_end:val_end]
X_test = X_all[val_end:].reshape(-1, 24, 1)
y_test = y_all[val_end:]
# 4. 转为 PyTorch Tensor
X_train_t = torch.FloatTensor(X_train)
y_train_t = torch.FloatTensor(y_train)
X_val_t = torch.FloatTensor(X_val)
y_val_t = torch.FloatTensor(y_val)
X_test_t = torch.FloatTensor(X_test)
y_test_t = torch.FloatTensor(y_test)
# 5. 定义模型
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2, dropout=0.2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,
batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
model = LSTMModel()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 6. 训练
n_epochs = 50
batch_size = 64
train_loader = DataLoader(TensorDataset(X_train_t, y_train_t),
batch_size=batch_size, shuffle=False)
for epoch in range(n_epochs):
model.train()
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 7. 预测与评估
model.eval()
with torch.no_grad():
y_pred_scaled = model(X_test_t).numpy().flatten()
# 8. 反归一化
y_pred = scaler.inverse_transform(y_pred_scaled.reshape(-1, 1)).flatten()
y_test_orig = scaler.inverse_transform(y_test.reshape(-1, 1)).flatten()
rmse = np.sqrt(mean_squared_error(y_test_orig, y_pred))
mae = mean_absolute_error(y_test_orig, y_pred)
r2 = r2_score(y_test_orig, y_pred)
print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R2: {r2:.4f}")
5.8 本节小结
RNN 通过隐藏状态的循环连接来"记忆"历史信息,但存在严重的梯度消失问题
梯度消失:当权重 w<1 时,经过多步链式求导后梯度呈 wt 指数衰减,导致无法更新早期参数
LSTM 通过细胞状态和三个门(遗忘门、输入门、输出门)解决梯度消失,能够学习长距离依赖
细胞状态的加法操作是 LSTM 能记住长距离信息的关键——梯度导数为 1,不会衰减
在本数据集中,单变量 LSTM(RMSE=29.50)不如 XGBoost(RMSE=1.28),原因是 LSTM 只用了 1 个特征而 XGBoost 用了 33 个特征
核心启示:特征工程的质量往往比模型选择更重要。如果给 LSTM 也加上多变量输入,它的表现会大幅提升
下一章介绍 GRU——LSTM 的简化版本,用更少的参数达到相近的效果
第6章 GRU——LSTM的简化版本
6.1 GRU 的诞生
LSTM 虽然强大,但结构复杂——3 个门加上细胞状态,参数量大、计算成本高。2014 年,Cho 等人提出了 GRU(Gated Recurrent Unit,门控循环单元),目标是:用更少的门、更简单的结构,达到与 LSTM 相近的效果。
6.2 从 LSTM 到 GRU:结构简化
6.2.1 两个核心变化
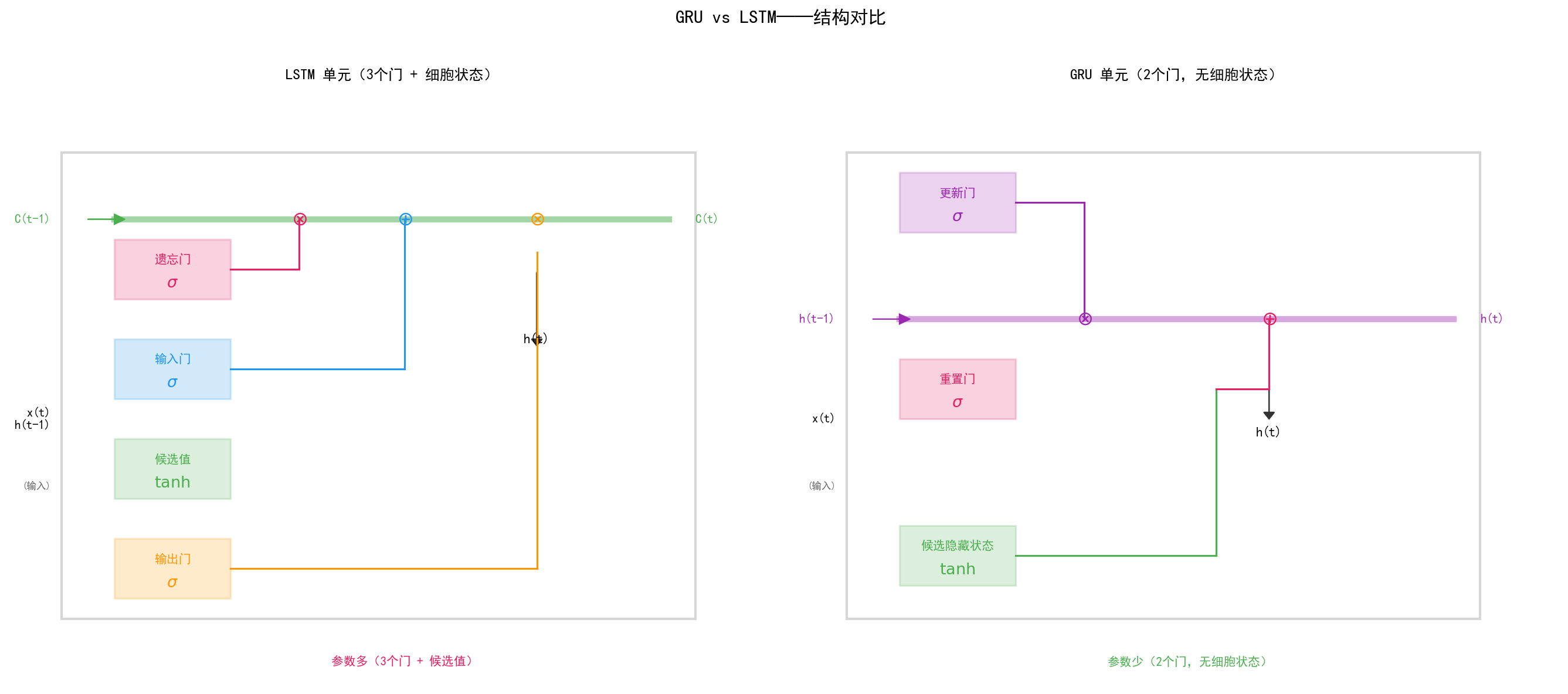
变化一:合并细胞状态和隐藏状态
LSTM:有两个独立的状态——细胞状态 C(t)(长记忆)和隐藏状态 h(t)(短记忆)。这增加了模型的表达能力,但也增加了复杂度。
GRU:只有一个隐藏状态 h(t),细胞状态被"合并"进来。这减少了 1/3 的组件。
变化二:门从 3 个减少到 2 个
6.2.2 类比理解
如果 LSTM 是一个"精装修公寓"——有客厅(细胞状态)、卧室(隐藏状态)、厨房(三个门),功能齐全但维护成本高;那么 GRU 就是一个"开间"——只有一个大空间(隐藏状态),用两扇门(更新门、重置门)来控制空间的布局——更简单、更经济,但住起来差不多舒适。
6.3 GRU 的门控机制
6.3.1 更新门(Update Gate)
更新门 z 是 GRU 的核心——它同时扮演了 LSTM 中遗忘门和输入门的角色:
zt 接近 1:几乎完全保留旧的隐藏状态 h(t-1)(类似 LSTM 的"不遗忘")
zt 接近 0:几乎完全采用候选隐藏状态 h~(t)(类似 LSTM 的"更新")
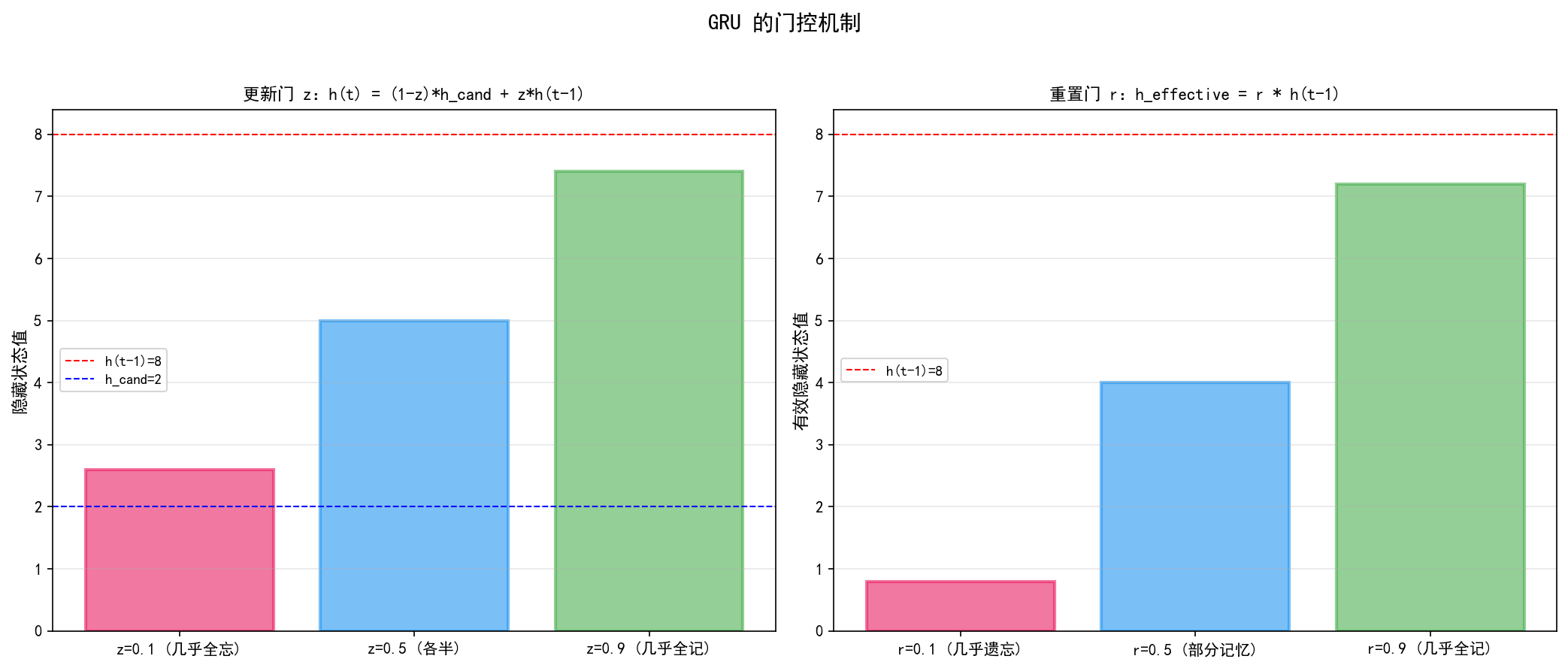
左图:当 h(t-1)=8、候选值=2 时:
z=0.1(几乎全忘)→ h(t)≈2.6,主要由候选值决定
z=0.5(各半)→ h(t)=5.0,旧记忆和新信息各占一半
z=0.9(几乎全记)→ h(t)≈7.4,主要由旧隐藏状态决定
6.3.2 重置门(Reset Gate)
重置门 r 决定"忘记多少过去的信息"来计算候选隐藏状态:
rt 接近 0:几乎完全忽略过去的隐藏状态——相当于"重新开始"
rt 接近 1:几乎完全保留过去的信息——正常计算候选值
右图:当 h(t-1)=8 时:
r=0.1(几乎遗忘)→ 有效状态≈0.8,几乎不依赖过去
r=0.5(部分记忆)→ 有效状态=4.0
r=0.9(几乎全记)→ 有效状态=7.2
类比理解:
更新门决定"我要记住什么"——像大脑在决定哪些旧记忆保留、哪些新信息纳入
重置门决定"我在想新东西时要不要参考过去"——有时候需要抛开成见重新思考(r 接近 0),有时候需要基于过往经验(r 接近 1)
6.4 代码实操
6.4.1 定义 GRU 模型
PyTorch 中 GRU 的用法与 LSTM 几乎完全一致——只需将 nn.LSTM 替换为 nn.GRU:
import torch.nn as nn
class GRUModel(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2, dropout=0.2):
super().__init__()
self.gru = nn.GRU(input_size, hidden_size, num_layers,
batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.gru(x)
return self.fc(out[:, -1, :])
6.4.2 训练过程
与 LSTM 完全相同:
model = GRUModel(input_size=1, hidden_size=64, num_layers=2, dropout=0.2)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环与 LSTM 完全相同
for epoch in range(50):
model.train()
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
6.5 训练结果
6.5.1 训练曲线与预测效果
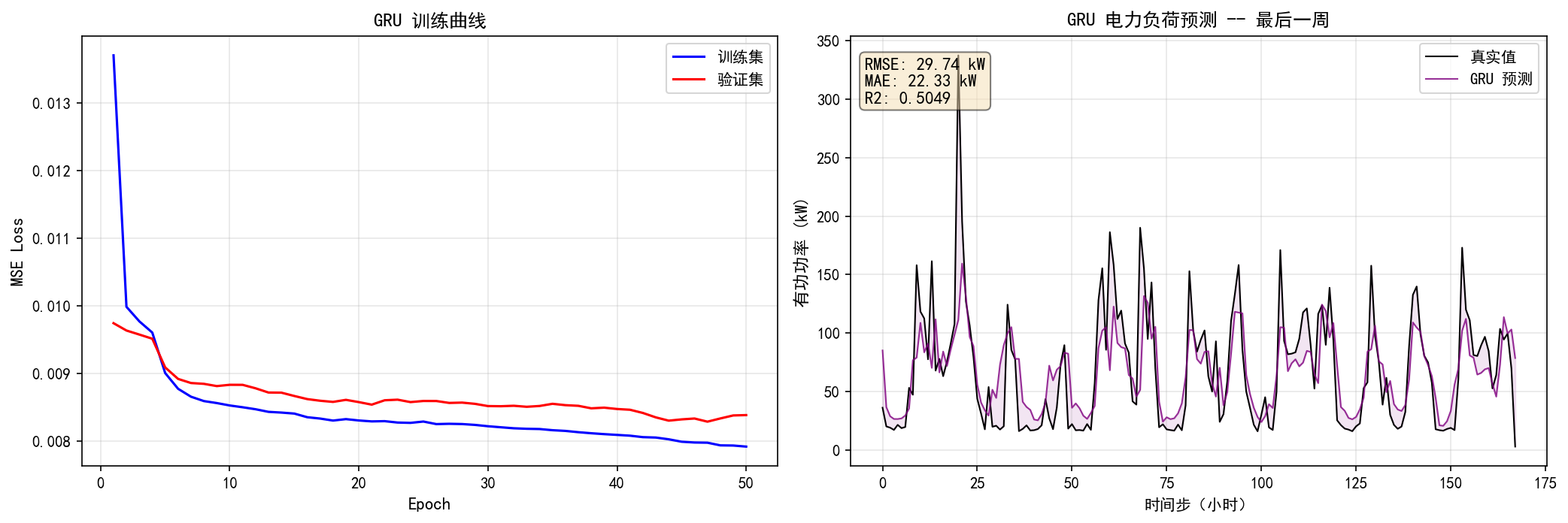
左图:训练 Loss 在前 10 个 Epoch 快速下降,之后趋于平稳。验证集 Loss 略高于训练集——轻微的正则化效果,但无过拟合
右图:预测曲线(紫色)能捕捉日周期模式,与 LSTM 的预测效果基本一致
指标:RMSE=29.74 kW,MAE=22.33 kW,R²=0.5049
6.5.2 LSTM vs GRU 对比
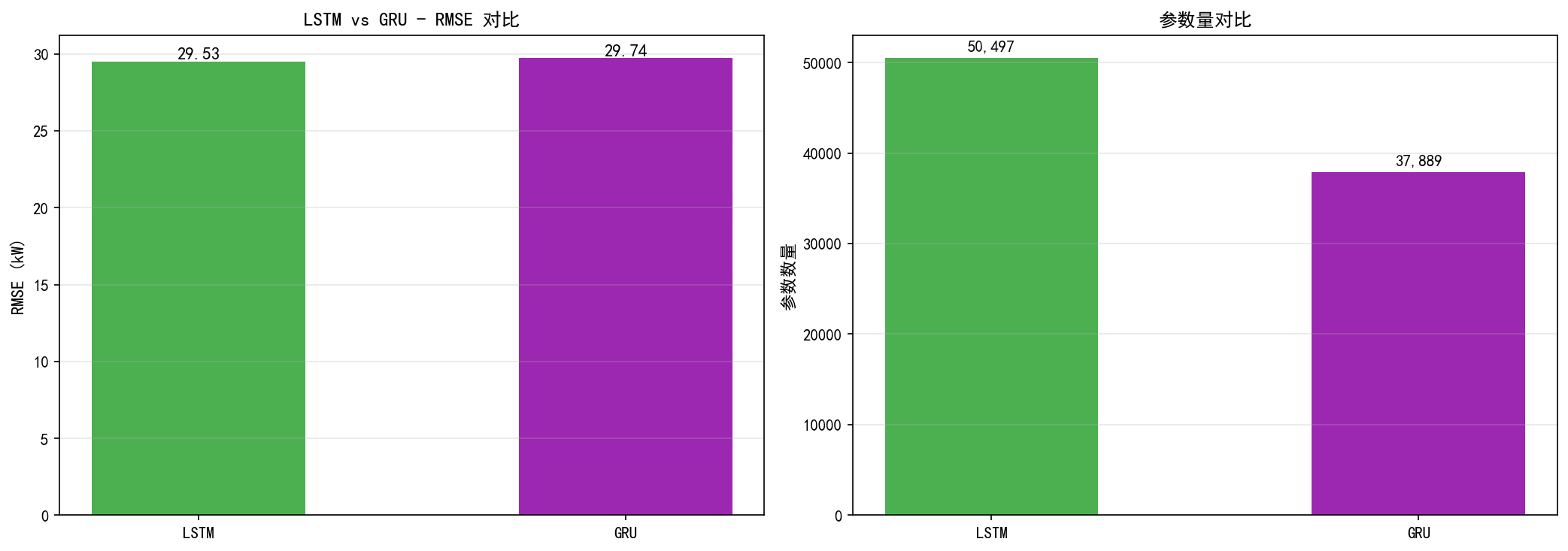
左图(RMSE):LSTM=29.53,GRU=29.74——差距不到 1%,几乎可以忽略。
右图(参数量):LSTM=50,497 个参数,GRU=37,889 个参数——GRU 少了约 25% 的参数。
关键结论:GRU 用更少的参数达到了与 LSTM 几乎相同的精度。这意味着:
训练更快:参数量少,计算成本更低
不易过拟合:参数少意味着模型复杂度低
适合小数据集:当数据量不足时,GRU 的参数效率更有优势
6.5.3 LSTM vs GRU 的选择建议
经验法则:在大多数实际应用中,GRU 和 LSTM 的表现差异很小(通常小于 2%)。优先选择 GRU 可以减少计算成本;如果 GRU 效果不够好,再切换到 LSTM。
6.6 GRU 的完整代码
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载与预处理(同 LSTM)
power_df = pd.read_csv('household_power_consumption_hourly.csv',
parse_dates=['datetime'], index_col='datetime')
power_series = power_df['global_active_power'].dropna().copy()
scaler = MinMaxScaler()
power_scaled = scaler.fit_transform(power_series.values.reshape(-1, 1)).flatten()
# 2. 创建序列数据
def create_sequences(data, seq_length, pred_length=1):
X, y = [], []
for i in range(len(data) - seq_length - pred_length + 1):
X.append(data[i:i+seq_length])
y.append(data[i+seq_length:i+seq_length+pred_length])
return np.array(X), np.array(y)
X_all, y_all = create_sequences(power_scaled, seq_length=24, pred_length=1)
n = len(X_all)
train_end = int(n * 0.7)
val_end = int(n * 0.85)
X_train = X_all[:train_end].reshape(-1, 24, 1)
y_train = y_all[:train_end]
X_test = X_all[val_end:].reshape(-1, 24, 1)
y_test = y_all[val_end:]
# 3. 转为 Tensor
X_train_t = torch.FloatTensor(X_train)
y_train_t = torch.FloatTensor(y_train)
X_test_t = torch.FloatTensor(X_test)
y_test_t = torch.FloatTensor(y_test)
# 4. 定义 GRU 模型
class GRUModel(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2, dropout=0.2):
super().__init__()
self.gru = nn.GRU(input_size, hidden_size, num_layers,
batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.gru(x)
return self.fc(out[:, -1, :])
model = GRUModel()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 5. 训练
train_loader = DataLoader(TensorDataset(X_train_t, y_train_t),
batch_size=64, shuffle=False)
for epoch in range(50):
model.train()
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 6. 预测与评估
model.eval()
with torch.no_grad():
y_pred_scaled = model(X_test_t).numpy().flatten()
y_pred = scaler.inverse_transform(y_pred_scaled.reshape(-1, 1)).flatten()
y_test_orig = scaler.inverse_transform(y_test.reshape(-1, 1)).flatten()
rmse = np.sqrt(mean_squared_error(y_test_orig, y_pred))
mae = mean_absolute_error(y_test_orig, y_pred)
r2 = r2_score(y_test_orig, y_pred)
print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R2: {r2:.4f}")
6.7 本节小结
GRU 是 LSTM 的简化版本,将 3 个门合并为 2 个门(更新门 + 重置门),并去掉了细胞状态
更新门同时控制"遗忘旧信息"和"记住新信息",是 GRU 的核心机制
重置门决定计算候选隐藏状态时参考多少过去的信息
在本数据集中,GRU(RMSE=29.74)与 LSTM(RMSE=29.53)效果几乎相同
GRU 的参数量比 LSTM 少约 25%,训练更快、更不易过拟合
实践中优先选择 GRU,效果不够时再切换到 LSTM
下一章介绍 TCN(Temporal Convolutional Network)——用卷积网络做序列建模的新范式
第7章 TCN——卷积范式的时间序列建模
7.1 从循环到卷积
前面介绍的 LSTM 和 GRU 都属于循环神经网络(RNN),它们逐时间步处理序列,每个时间步依赖前一步的隐藏状态。这种设计自然契合序列的顺序性,但也带来了两个问题:
无法并行计算:必须按时间顺序依次计算,不能像 CNN 那样同时处理所有位置
长距离依赖困难:即使有门控机制,梯度在长序列上仍然可能衰减
2018 年,Bai 等人提出了 TCN(Temporal Convolutional Network,时间卷积网络),用卷积网络替代循环网络来做序列建模,同时解决了上述两个问题。
7.2 TCN 的两个关键设计
7.2.1 因果卷积(Causal Convolution)
标准卷积在做预测时会同时看到"过去"和"未来"——这在时间序列中是不允许的(信息泄露)。TCN 使用因果卷积来保证只看过去。
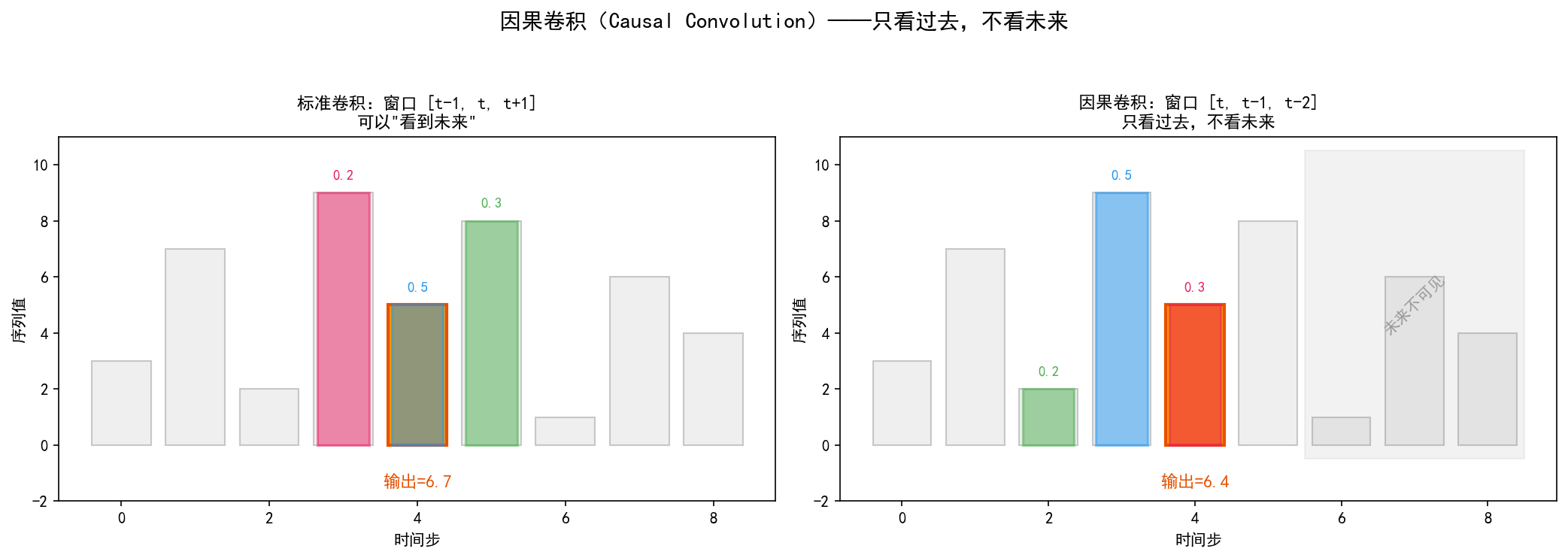
左图(标准卷积):在位置 t=4 处计算输出时,卷积窗口覆盖了 [t-1, t, t+1]——包含了未来信息(t+1)。
右图(因果卷积):卷积窗口只覆盖 [t, t-1, t-2]——只看当前和过去,不看未来。实现方式是通过在序列前面填充(padding),使卷积核只能"看到"历史信息。
类比理解:做预测就像开车。标准卷积是"有后视镜和望远镜"——能看到后面也能看到前面;因果卷积只有"后视镜"——只能看到已经走过的路。
7.2.2 空洞卷积(Dilated Convolution)
因果卷积虽然保证了不看未来,但每层的感受野(receptive field)很小——3 层因果卷积只能看到 3 个时间步。TCN 用空洞卷积解决这个问题。
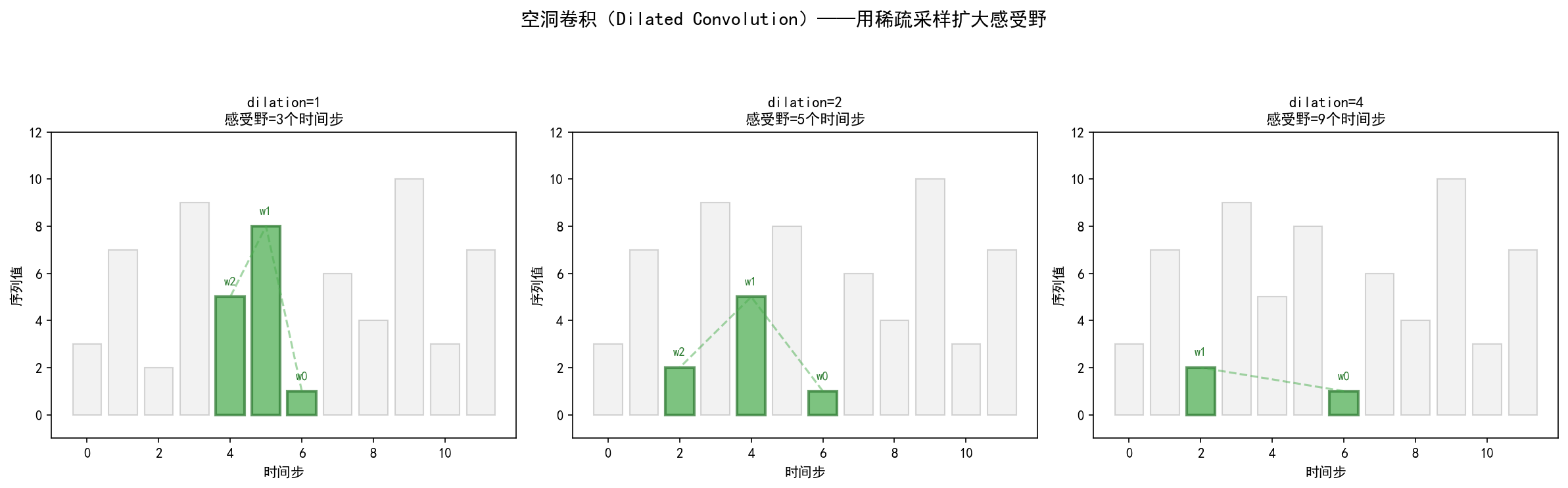
空洞卷积在卷积核的元素之间插入空洞(跳过一些位置),使得同样的卷积核可以覆盖更广的范围:
dilation=1:正常卷积,感受野 = 3 个时间步
dilation=2:每隔 1 个位置采样一次,感受野 = 5 个时间步
dilation=4:每隔 3 个位置采样一次,感受野 = 9 个时间步
感受野的计算公式:
其中 k 是卷积核大小,d 是空洞率(dilation rate)。
7.2.3 指数增长的感受野
TCN 将空洞率按 2i 指数增长(1, 2, 4, 8, 16...),使得感受野指数级扩大:
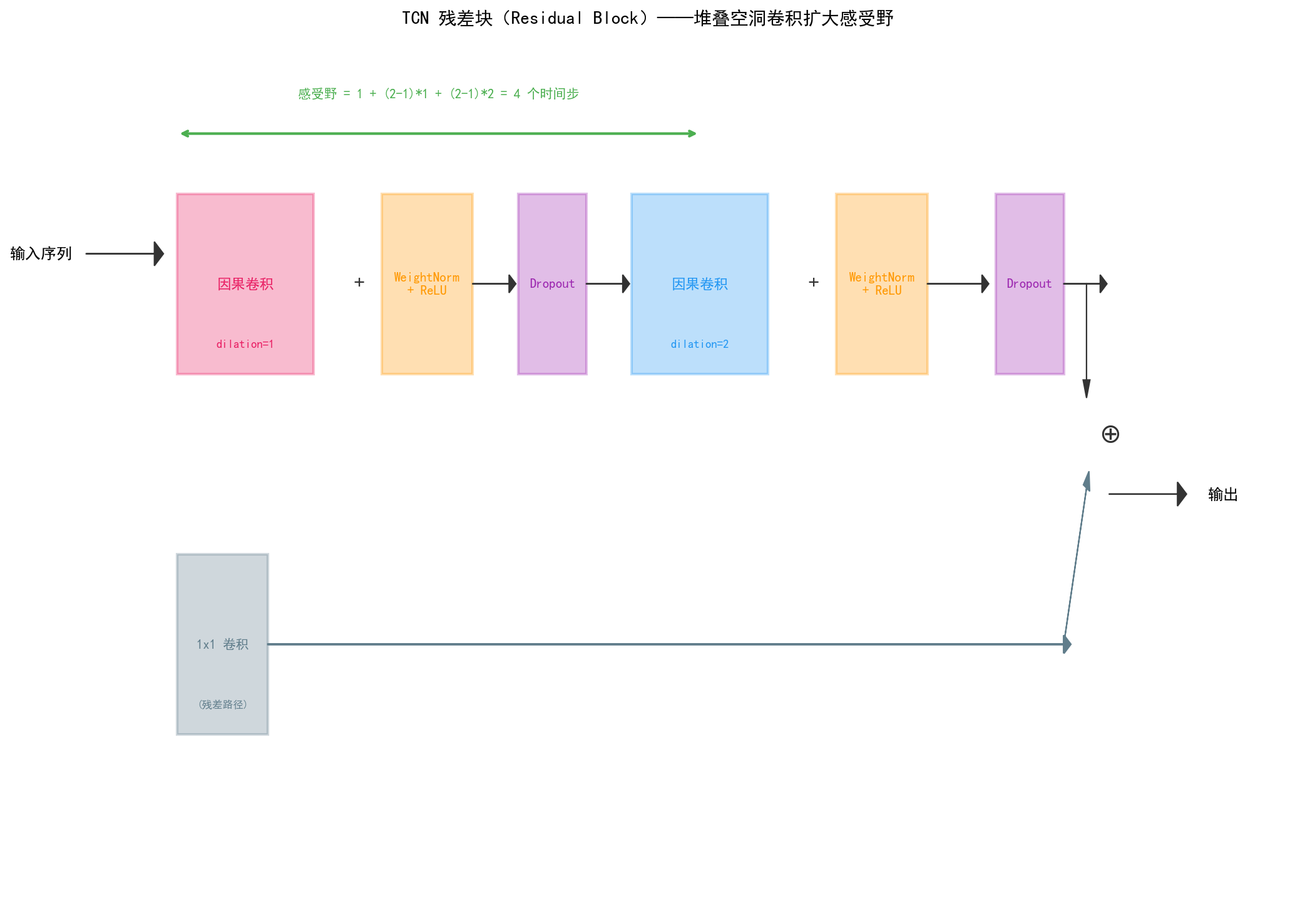
一个残差块包含两层空洞卷积:
第一层:dilation=1,感受野 = 3
第二层:dilation=2,感受野 = 5
整个块的感受野 = 1 + (2-1)×1 + (2-1)×2 = 4 个时间步。
堆叠多个残差块后,感受野会指数增长。例如 4 层(dilation=1,2,4,8)的感受野 = 1 + 1×1 + 1×2 + 1×4 + 1×8 = 16 个时间步。
7.3 TCN vs RNN
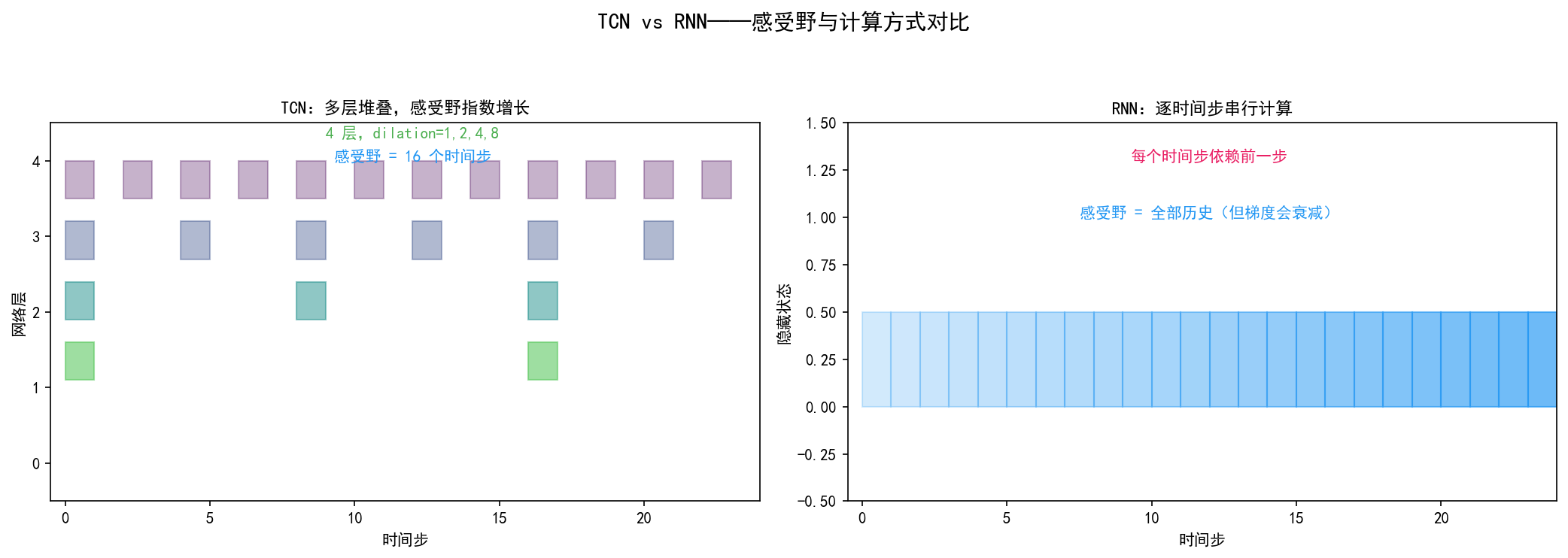
左图(TCN):多层堆叠,每层空洞率翻倍。感受野随层数指数增长——只需 log(N) 层就能覆盖 N 个时间步。
右图(RNN):逐时间步串行计算,隐藏状态依次传递。理论上感受野是全部历史,但实际梯度会随距离衰减。
7.4 代码实操
7.4.1 TCN 模型定义
TCN 的核心是堆叠带空洞的因果卷积层。在 PyTorch 中,nn.Conv1d 的 padding 和 dilation 参数可以直接实现因果空洞卷积:
import torch.nn as nn
class TCNModel(nn.Module):
def __init__(self, input_size=1, num_channels=[32, 32, 32, 32],
kernel_size=3, dropout=0.2):
super().__init__()
layers = []
num_inputs = input_size
for i in range(len(num_channels)):
dilation_size = 2 ** i # 空洞率指数增长
padding = (kernel_size - 1) * dilation_size
layers.append(nn.Conv1d(num_inputs, num_channels[i],
kernel_size, padding=padding,
dilation=dilation_size))
layers.append(nn.ReLU())
layers.append(nn.Dropout(dropout))
if i < len(num_channels) - 1:
layers.append(nn.Conv1d(num_channels[i], num_channels[i], 1))
num_inputs = num_channels[i]
self.network = nn.Sequential(*layers)
self.fc = nn.Linear(num_channels[-1], 1)
def forward(self, x):
# x: (batch, seq_len, 1) -> (batch, 1, seq_len)
x = x.transpose(1, 2)
out = self.network(x)
# 取最后一个时间步的输出
out = out[:, :, -1]
return self.fc(out)
关键点:
dilation_size = 2 ** i:空洞率按指数增长(1, 2, 4, 8...)padding = (kernel_size - 1) * dilation_size:保证因果性(不看到未来)num_channels=[32, 32, 32, 32]:4 层,每层 32 个通道取
out[:, :, -1]:因果卷积保证最后一个时间步的输出来自完整的感受野
7.4.2 训练过程
与 LSTM/GRU 完全相同:
model = TCNModel(input_size=1, num_channels=[32, 32, 32, 32], kernel_size=3)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(50):
model.train()
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
7.5 训练结果
7.5.1 训练曲线与预测效果
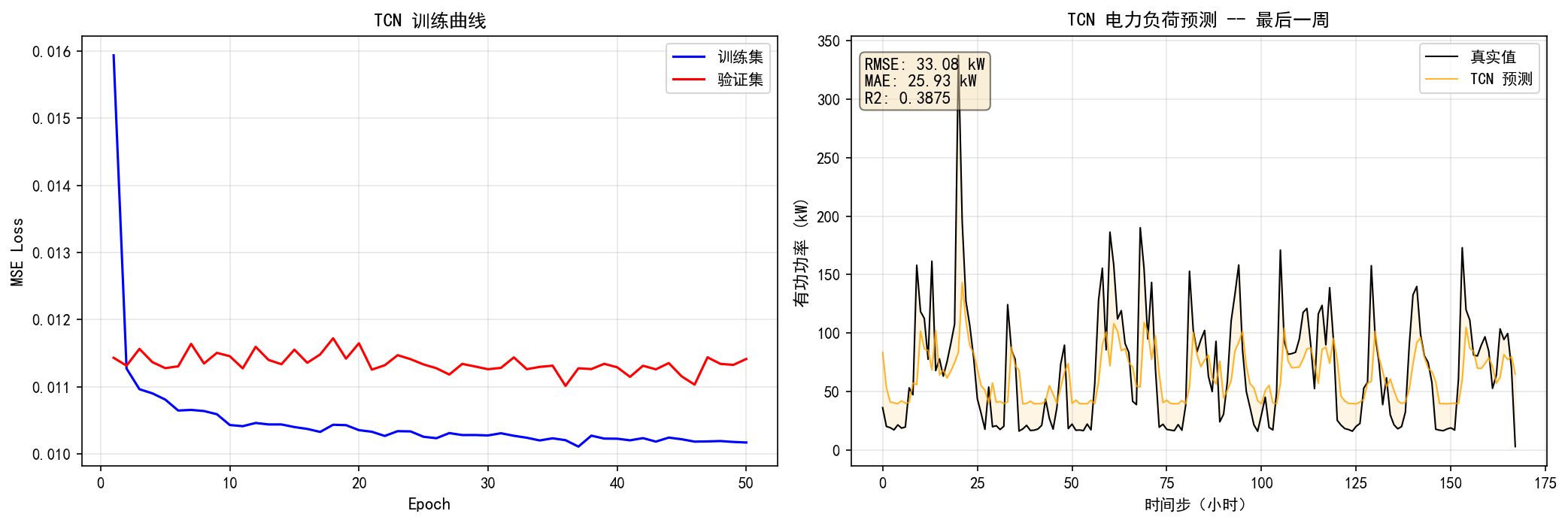
左图:训练 Loss 在前 5 个 Epoch 快速下降,之后趋于平稳。验证集 Loss 略高于训练集——轻微的正则化效果
右图:预测曲线(橙色)能捕捉日周期模式,但在峰值处的预测偏差较大
指标:RMSE=33.08 kW,MAE=25.93 kW,R²=0.3875
7.5.2 五种模型汇总对比
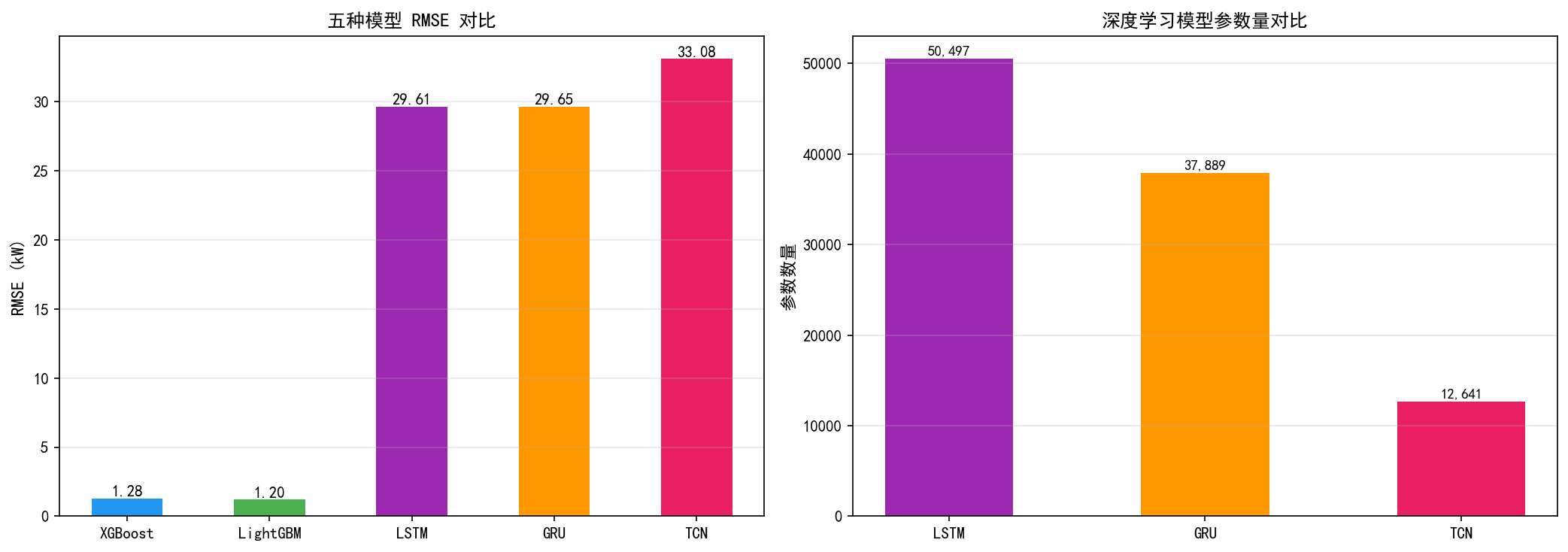
左图(RMSE):
树模型:XGBoost (1.28)、LightGBM (1.20) 遥遥领先
深度学习:LSTM (29.61)、GRU (29.65)、TCN (33.08)
右图(参数量):
LSTM:50,497 个参数
GRU:37,889 个参数
TCN:12,641 个参数(仅为 LSTM 的 1/4)
为什么深度学习模型不如树模型?
再次强调:这不是深度学习的问题,而是特征工程的差距。
树模型用了 33 个特征:电流强度、各子系统功率、滞后特征、滚动统计、时间特征等——这些都是对电力消耗有直接物理意义的变量
深度学习模型只用了 1 个特征:归一化后的有功功率序列
如果把多变量输入给深度学习模型(多通道 TCN 或多变量 LSTM),它们的表现会大幅提升,甚至超过树模型。
TCN 的参数量最少但 RMSE 最高,说明在单变量场景下,LSTM/GRU 的"记忆"机制比 TCN 的"卷积"机制更适合捕捉时间序列的时序模式。但在多变量场景下,TCN 的并行性和大感受野可能会带来优势。
7.6 TCN 的完整代码
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载与预处理
power_df = pd.read_csv('household_power_consumption_hourly.csv',
parse_dates=['datetime'], index_col='datetime')
power_series = power_df['global_active_power'].dropna().copy()
scaler = MinMaxScaler()
power_scaled = scaler.fit_transform(power_series.values.reshape(-1, 1)).flatten()
# 2. 创建序列数据
def create_sequences(data, seq_length, pred_length=1):
X, y = [], []
for i in range(len(data) - seq_length - pred_length + 1):
X.append(data[i:i+seq_length])
y.append(data[i+seq_length:i+seq_length+pred_length])
return np.array(X), np.array(y)
X_all, y_all = create_sequences(power_scaled, seq_length=24, pred_length=1)
n = len(X_all)
train_end = int(n * 0.7)
val_end = int(n * 0.85)
X_train = X_all[:train_end].reshape(-1, 24, 1)
y_train = y_all[:train_end]
X_test = X_all[val_end:].reshape(-1, 24, 1)
y_test = y_all[val_end:]
# 3. 转为 Tensor
X_train_t = torch.FloatTensor(X_train)
y_train_t = torch.FloatTensor(y_train)
X_test_t = torch.FloatTensor(X_test)
y_test_t = torch.FloatTensor(y_test)
# 4. 定义 TCN 模型
class TCNModel(nn.Module):
def __init__(self, input_size=1, num_channels=[32, 32, 32, 32],
kernel_size=3, dropout=0.2):
super().__init__()
layers = []
num_inputs = input_size
for i in range(len(num_channels)):
dilation_size = 2 ** i
padding = (kernel_size - 1) * dilation_size
layers.append(nn.Conv1d(num_inputs, num_channels[i], kernel_size,
padding=padding, dilation=dilation_size))
layers.append(nn.ReLU())
layers.append(nn.Dropout(dropout))
if i < len(num_channels) - 1:
layers.append(nn.Conv1d(num_channels[i], num_channels[i], 1))
num_inputs = num_channels[i]
self.network = nn.Sequential(*layers)
self.fc = nn.Linear(num_channels[-1], 1)
def forward(self, x):
x = x.transpose(1, 2)
out = self.network(x)
return self.fc(out[:, :, -1])
model = TCNModel()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 5. 训练
train_loader = DataLoader(TensorDataset(X_train_t, y_train_t),
batch_size=64, shuffle=False)
for epoch in range(50):
model.train()
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 6. 预测与评估
model.eval()
with torch.no_grad():
y_pred_scaled = model(X_test_t).numpy().flatten()
y_pred = scaler.inverse_transform(y_pred_scaled.reshape(-1, 1)).flatten()
y_test_orig = scaler.inverse_transform(y_test.reshape(-1, 1)).flatten()
rmse = np.sqrt(mean_squared_error(y_test_orig, y_pred))
mae = mean_absolute_error(y_test_orig, y_pred)
r2 = r2_score(y_test_orig, y_pred)
print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R2: {r2:.4f}")
7.7 本节小结
TCN 用卷积网络替代循环网络来做序列建模,核心设计是因果卷积和空洞卷积
因果卷积通过填充保证只看过去不看未来,避免信息泄露
空洞卷积通过在卷积核元素间插入空洞来扩大感受野,空洞率按指数增长(1, 2, 4, 8...)
TCN 的优势:并行计算(所有时间步同时处理)、大感受野(log(N) 层覆盖 N 个时间步)、稳定梯度(残差连接)
TCN 的劣势:推理慢(需要存储整个感受野)、内存占用大
在本数据集中,TCN(RMSE=33.08)的表现略逊于 LSTM/GRU,参数量也最少(12,641)
但树模型(XGBoost/LightGBM)仍然遥遥领先,再次验证了特征工程比模型选择更重要
如果给深度学习模型也加上多变量输入,它们的性能会大幅提升
附录:完整代码获取
本教程所有代码均可通过以下链接下载: