
提高篇:大数据集分析预处理
第0章 前言
0.1 为什么需要数据预处理?
在数学建模和数据分析竞赛中,原始数据往往是"脏"的:缺失值、异常值、高维稀疏特征、类别不平衡……这些都会让后续的建模过程举步维艰。
数据预处理是连接原始数据与有效模型之间的桥梁。 它不是建模的附属步骤,而是决定模型上限的关键环节——正如一句老话所说:
Garbage in, garbage out.
本教程以经典的 Adult/Census Income 数据集为载体,系统地演示一套从原始表格到高质量特征向量的完整预处理流水线。这套方法不仅适用于竞赛数据,也可以推广到电商交易分析、日志挖掘、用户行为分析等场景。
0.2 数据集介绍
Adult 数据集 提取自 1994 年美国人口普查数据库,包含 48,842 条记录(训练集 32,561 条,测试集 16,281 条)。每条记录有 14 个属性:
预测任务:判断个人年收入是否超过 50K(二分类问题)。
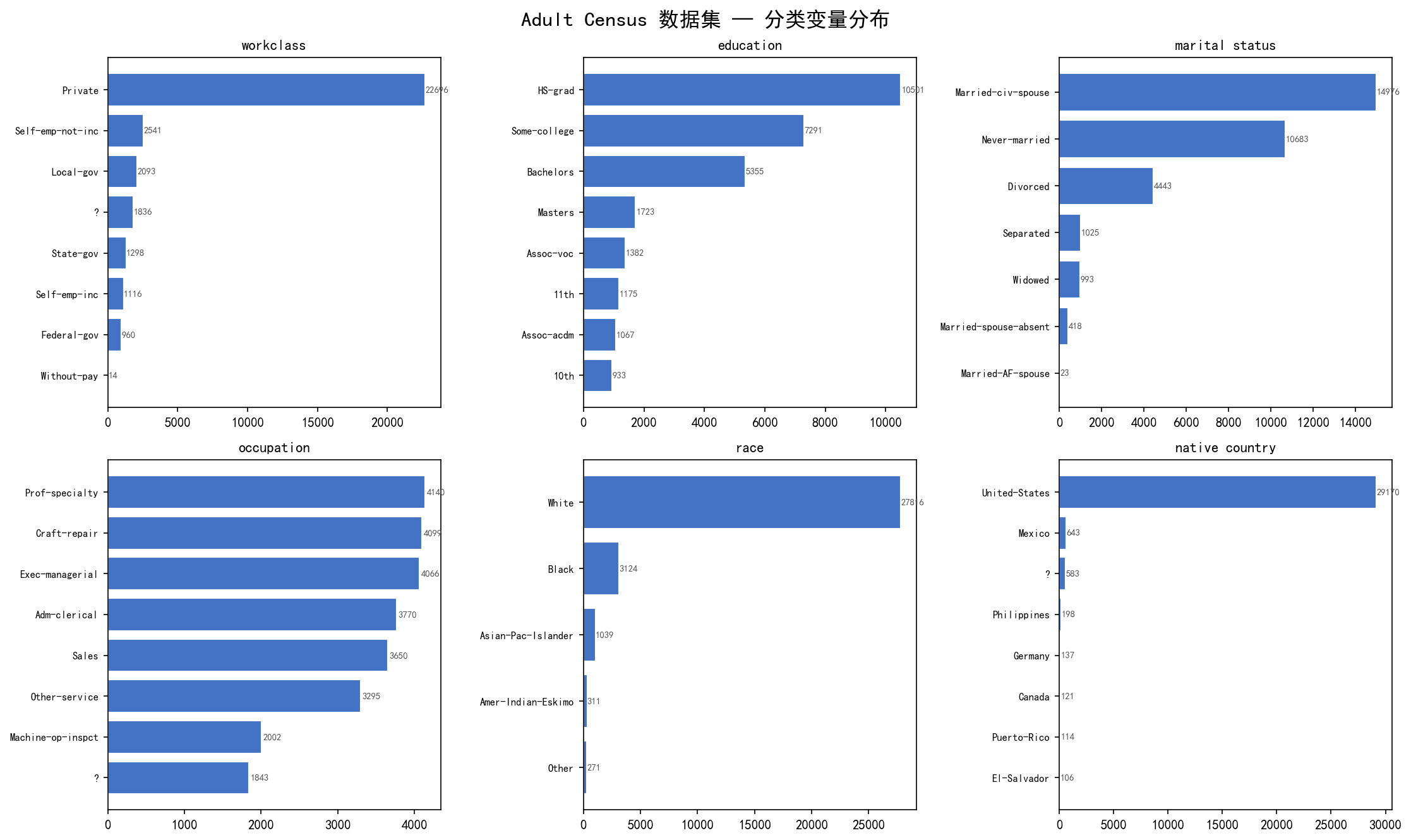
从上图可以看到:
workclass 以 Private 为主(约 2.2 万人)
education 中 HS-grad(高中毕业)和 Some-college 占比最高
occupation 中 Prof-specialty、Exec-managerial 和 Craft-repair 是前三大类
native-country 极度不均衡,United-States 占绝大多数
0.3 技术路线图
本教程的预处理流水线分为六个阶段,如下图所示:

各阶段的核心目标:
0.4 核心思路:把表格当文本处理
传统统计学方法(如逻辑回归、决策树)直接处理表格数据。本教程采用一种创新的交叉视角:
将每一行数据视为一个"句子",将每个属性值视为一个"词"。
例如,第 1 行数据:
39, State-gov, 77516, Bachelors, 13, Never-married, Adm-clerical, ...
转化为 token 序列后变为:
[age:Young, workclass:State-gov, education:Bachelors, marital:Never-married, occupation:Adm-clerical, ...]
这样做的好处:
频繁项集挖掘可以发现哪些属性值经常一起出现(如 "Bachelors + Prof-specialty + >50K")
嵌入学习可以捕获属性值之间的语义关系(如 "Bachelors" 和 "Masters" 的向量会很接近)
降维可视化可以直观展示高维特征空间的结构
0.5 环境准备
本教程使用 Python 3.13,主要依赖以下库:
pandas>=2.0 # 数据处理
numpy>=1.24 # 数值计算
matplotlib>=3.7 # 可视化
mlxtend>=0.23 # Apriori / FP-Growth
gensim>=4.3 # Word2Vec / FastText / GloVe
scikit-learn>=1.3 # t-SNE / 评估指标
umap-learn>=0.5 # UMAP 降维
torch>=2.0 # 自编码器
0.6 本节小结
Adult 数据集包含 32,561 条训练记录、15 个属性(14 个特征 + 1 个标签)
核心思路是将每行数据序列化为 token 序列,从而应用 NLP 方法
预处理流水线:数据清洗 → 频繁项集 → 嵌入学习 → 降维可视化 → 深度降维 → 下游验证
下一章将详细讲解数据预处理的具体操作
第1章 数据预处理与序列化
1.1 加载数据
Adult 数据集分为训练集和测试集两个文件。我们首先将它们合并,并统一处理:
import pandas as pd
cols = ['age','workclass','fnlwgt','education','education_num','marital_status',
'occupation','relationship','race','sex','capital_gain','capital_loss',
'hours_per_week','native_country','income']
df_train = pd.read_csv('adult.data', names=cols, na_values=' ?', skipinitialspace=True)
df_test = pd.read_csv('adult.test', names=cols, na_values=' ?', skipinitialspace=True, skiprows=1)
# 清理测试集 income 尾部的 '.'(原始数据格式问题)
df_test['income'] = df_test['income'].str.strip('.')
# 合并
df_all = pd.concat([df_train, df_test], ignore_index=True)
print(f"合并后: {df_all.shape[0]} 行")
合并后: 48842 行
1.2 缺失值处理
原始数据中用 ' ?' 表示缺失值。pd.read_csv 的 na_values=' ?' 参数已将其转换为 NaN:
print(df_all.isnull().sum())
age 0
workclass 1836
fnlwgt 0
education 0
education_num 0
marital_status 0
occupation 1843
relationship 0
race 0
sex 0
capital_gain 0
capital_loss 0
hours_per_week 0
native_country 583
income 0
缺失集中在 workclass(1,836 条)、occupation(1,843 条)和 native_country(583 条)。对于频繁项集挖掘,缺失值没有语义意义,直接删除这些行:
df_clean = df_all.dropna(subset=['workclass', 'occupation', 'native_country']).reset_index(drop=True)
print(f"清洗后: {df_clean.shape[0]} 行(删除 {len(df_all) - len(df_clean)} 条)")
清洗后: 46043 行(删除 2799 条)
1.3 连续值离散化
连续变量无法直接用于频繁项集挖掘(每个值只出现一次)。我们需要将连续变量分箱(binning)为离散的类别标签。
1.3.1 离散化策略选择
1.3.2 实现代码
import pandas as pd
# age 分箱
def age_bin(x):
if x < 25: return 'Young'
elif x < 35: return 'Adult_25-34'
elif x < 45: return 'Adult_35-44'
elif x < 55: return 'Middle_45-54'
elif x < 65: return 'Senior_55-64'
else: return 'Elderly_65+'
# hours-per-week 分箱
def hours_bin(x):
if x < 20: return 'Hours_PartTime'
elif x < 40: return 'Hours_20-39'
elif x == 40: return 'Hours_FullTime'
elif x < 50: return 'Hours_41-49'
else: return 'Hours_Overtime'
# capital-gain / capital-loss 分箱
def capital_bin(x, name):
if x == 0: return f'{name}_None'
elif x < 3000: return f'{name}_Low'
elif x < 7000: return f'{name}_Mid'
else: return f'{name}_High'
df = df_clean.copy()
df['age_binned'] = df['age'].map(age_bin)
df['hours_binned'] = df['hours_per_week'].map(hours_bin)
df['capital_gain_binned'] = df['capital_gain'].map(lambda x: capital_bin(x, 'CapGain'))
df['capital_loss_binned'] = df['capital_loss'].map(lambda x: capital_bin(x, 'CapLoss'))
# fnlwgt 等频四分位
_, fnlwgt_bins = pd.qcut(df['fnlwgt'], q=4, duplicates='drop', retbins=True)
df['fnlwgt_binned'] = pd.cut(df['fnlwgt'], bins=fnlwgt_bins,
labels=['Fnlwgt_Q1','Fnlwgt_Q2','Fnlwgt_Q3','Fnlwgt_Q4'])
1.3.3 离散化效果对比
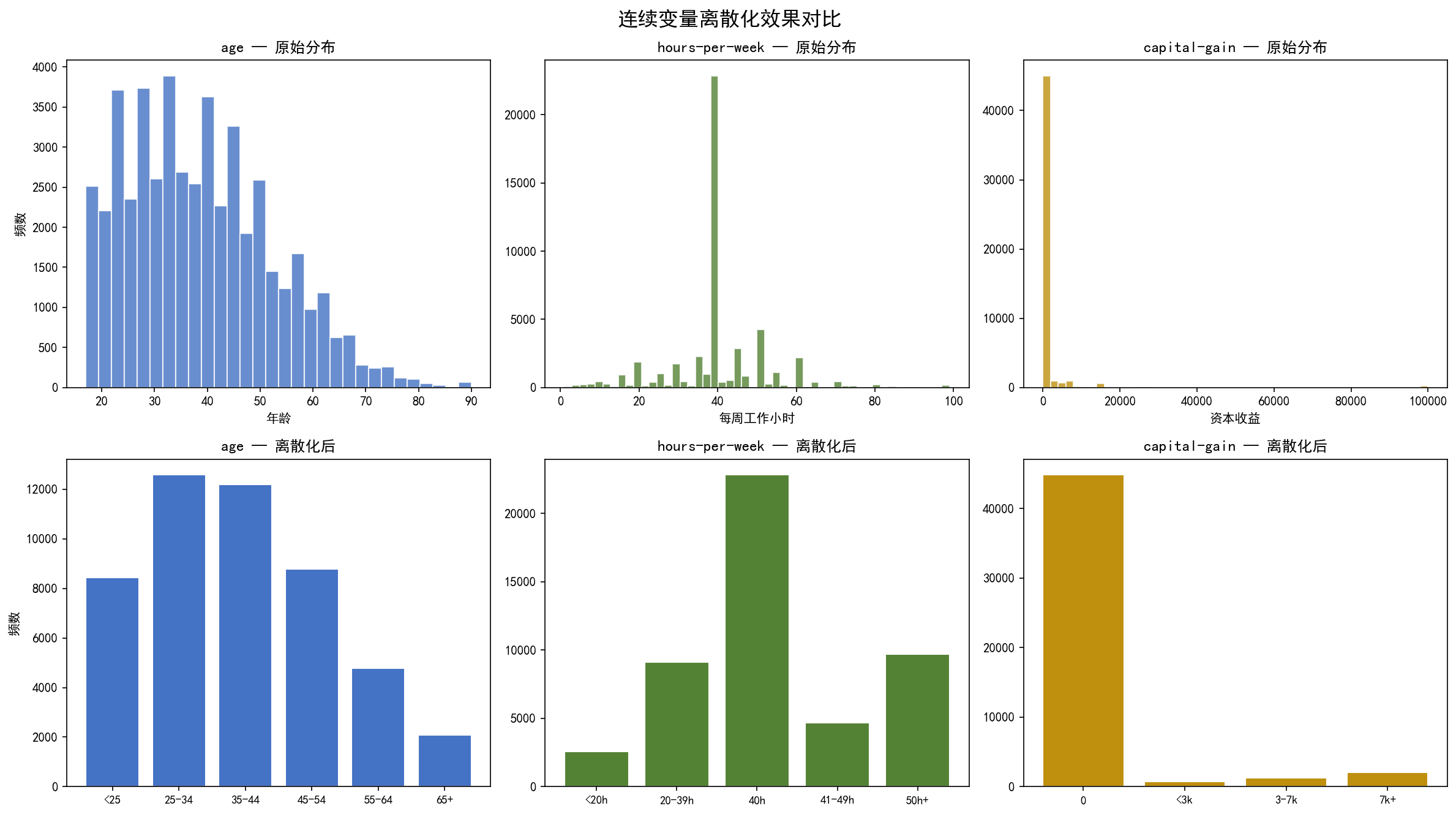
上图展示了三个关键变量离散化前后的对比:
age:原始分布呈右偏(25-45 岁为主),离散化为 6 个年龄段后,分布形态基本保持
hours-per-week:在 40 处有极强的峰值(标准全职),离散化单独保留了这一箱
capital-gain:绝大多数人为 0(91.7%),离散化后用
CapGain_None捕获这一特征,仅对非零值进一步分级
为什么要保留 "0 值" 作为一个独立箱?
对于 capital-gain 和 capital-loss,0 值本身就是最强的信号——"没有投资收益/损失" 这一信息在频繁项集挖掘中极为有用。
1.4 序列化:构建事务数据
现在我们将每一行转换为 token 序列,每个 token 的格式为 前缀:值:
token_cols = ['workclass', 'education', 'marital_status', 'occupation',
'relationship', 'race', 'sex', 'age_binned', 'hours_binned',
'capital_gain_binned', 'capital_loss_binned', 'native_country', 'income']
prefix_map = {
'workclass': 'WC', 'education': 'EDU', 'marital_status': 'MS',
'occupation': 'OCC', 'relationship': 'REL', 'race': 'RACE',
'sex': 'SEX', 'age_binned': 'AGE', 'hours_binned': 'HRS',
'capital_gain_binned': 'CG', 'capital_loss_binned': 'CL',
'native_country': 'NC', 'income': 'INC'
}
transactions = []
for _, row in df.iterrows():
tokens = [f"{prefix_map[c]}:{row[c]}" for c in token_cols]
transactions.append(tokens)
# 查看第一条
print(transactions[0])
['WC:Private', 'EDU:Bachelors', 'MS:Never-married', 'OCC:Adm-clerical',
'REL:Not-in-family', 'RACE:White', 'SEX:Male', 'AGE:Adult_35-44',
'HRS:Hours_FullTime', 'CG:CapGain_None', 'CL:CapLoss_None',
'NC:United-States', 'INC:<=50K']
每条事务固定包含 13 个 token(12 个特征 + 1 个标签)。
1.4.1 Token 词频统计
from collections import Counter
all_tokens = [t for tx in transactions for t in tx]
token_counts = Counter(all_tokens).most_common(30)
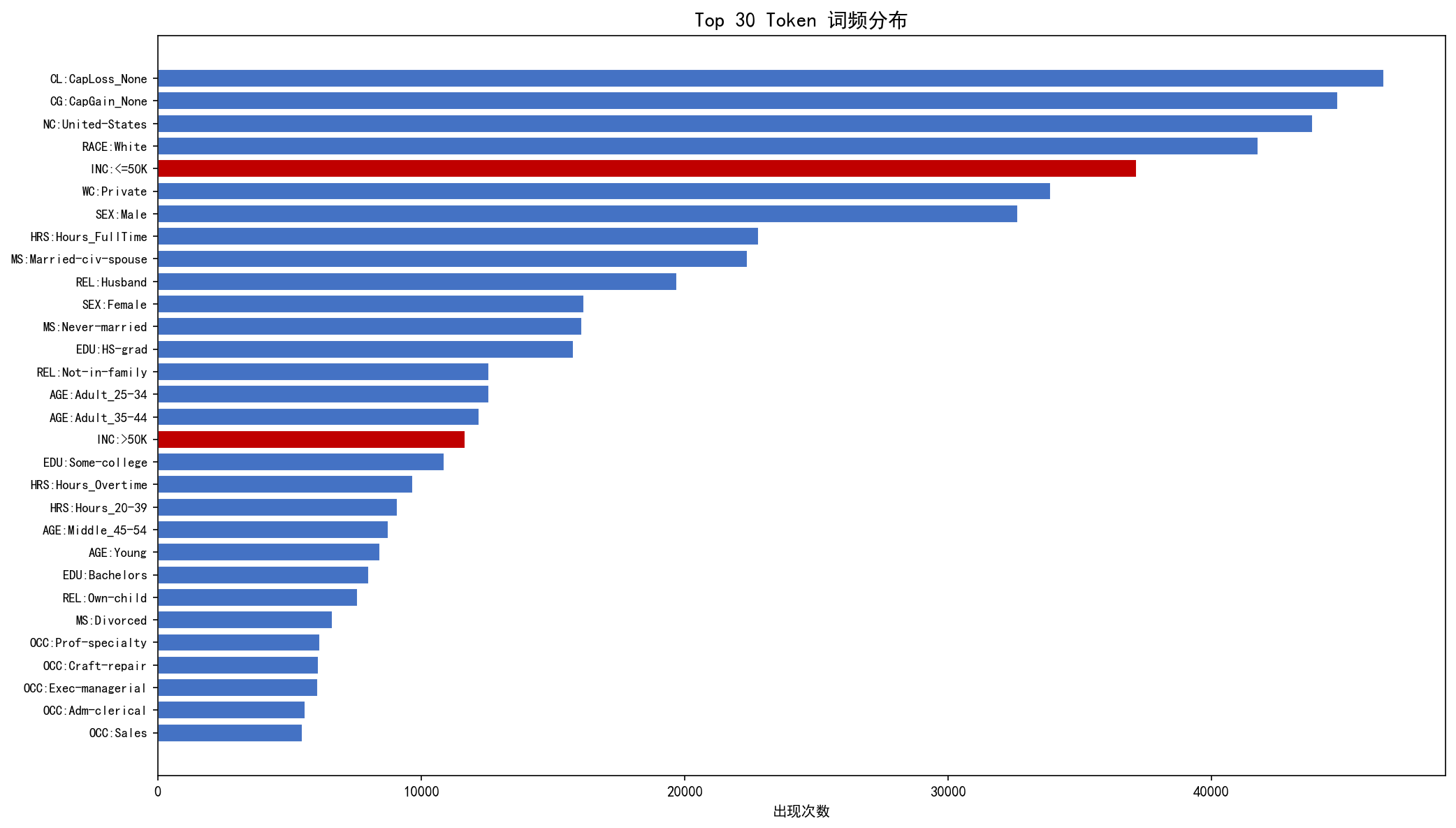
词频图揭示了几个重要特征:
INC:<=50K出现 37,155 次(红色条),远超INC:>50K的 11,687 次——类别不平衡明显WC:Private最高频,对应私营部门占绝对主导CG:CapGain_None极高频,印证了绝大多数人没有资本收益国家属性中
NC:United-States占绝对主导,其他国家的 token 频率都很低
1.4.2 事务长度分布
由于每行固定选取 13 个属性,所有事务长度一致(均值 = 13.0)。在后续章节使用 Apriori/FP-Growth 时,这意味着每个事务的挖掘空间是可预期的。
1.5 序列化结果保存
为了方便后续章节复用,将序列化后的事务保存为文本文件:
# 保存为每行一个事务的格式(空格分隔 token)
with open('transactions.txt', 'w') as f:
for tx in transactions:
f.write(' '.join(tx) + '\n')
print(f"已保存 {len(transactions)} 条事务到 transactions.txt")
1.6 本节小结
缺失值处理:删除含
'?'的行(2,799 条),保留 46,043 条离散化策略:连续变量按业务规则或等频分箱,避免随意切分
序列化格式:
前缀:值的 token 格式,每行 13 个 token类别不平衡:
<=50K占比约 76%,后续分析需要注意下一篇将基于序列化后的事务数据,使用 Apriori 和 FP-Growth 挖掘频繁项集
第2章 频繁项集挖掘:Apriori 与 FP-Growth
2.1 什么是频繁项集?
频繁项集(Frequent Itemset)是指在一组事务数据中,出现频率(支持度)超过设定阈值的项的集合。
以超市购物为例:如果 {牛奶, 面包} 在 30% 的交易中出现,且最小支持度阈值为 20%,则它是一个频繁 2-项集。
在我们的 Adult 数据集中,每个"事务"是一行序列化后的 token 序列:
['WC:Private', 'EDU:Bachelors', 'MS:Never-married', 'OCC:Adm-clerical',
'REL:Not-in-family', 'RACE:White', 'SEX:Male', 'AGE:Adult_35-44',
'HRS:Hours_FullTime', 'CG:CapGain_None', 'CL:CapLoss_None',
'NC:United-States', 'INC:<=50K']
频繁项集挖掘可以发现:
高共现属性组合:如
{EDU:Bachelors, OCC:Prof-specialty, INC:>50K}低频噪声过滤:支持度低于阈值的项目被自动剔除
2.2 核心概念
2.3 Apriori 算法
2.3.1 算法原理
Apriori 基于一个反单调性质(Apriori Property):
如果一个项集是频繁的,那么它的所有子集也一定是频繁的。
等价地说:如果一个项集是不频繁的,那么它的所有超集也都是不频繁的。
算法流程:
扫描数据库,统计每个 1-项集的支持度,筛选出频繁 1-项集 L1
连接步:用 Lk 自连接生成候选 (k+1)-项集 Ck+1
剪枝步:利用 Apriori 性质剪去包含不频繁子集的候选
再次扫描,计算 Ck+1 的支持度,得到 Lk+1
重复直到 Lk+1 为空
2.3.2 代码实现
from mlxtend.frequent_patterns import apriori
from mlxtend.preprocessing import TransactionEncoder
# 编码为 one-hot 矩阵
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df_onehot = pd.DataFrame(te_ary, columns=te.columns_)
# 运行 Apriori
freq_items = apriori(df_onehot, min_support=0.03,
use_colnames=True, max_len=3)
print(f"频繁项集数量: {len(freq_items)}")
print(freq_items.sort_values('support', ascending=False).head(10))
频繁项集数量: 2480
support itemsets
5 0.760 (INC:<=50K)
4 0.239 (INC:>50K)
24 0.239 (CG:CapGain_None, INC:<=50K)
20 0.212 (HRS:Hours_FullTime, INC:<=50K)
8 0.192 (EDU:HS-grad, INC:<=50K)
...
2.4 FP-Growth 算法
2.4.1 算法原理
FP-Growth(Frequent Pattern Growth)解决了 Apriori 需要生成候选集的问题。它通过构建 FP-树(Frequent Pattern Tree)来压缩数据:
第一次扫描:统计每项频率,按频率降序排列
第二次扫描:构建 FP-树,每条事务按全局频率顺序插入树中
挖掘:从 FP-树中递归提取频繁模式,无需生成候选集
FP-树的核心思想:具有共同前缀的事务路径共享树的节点,实现数据压缩。
from mlxtend.frequent_patterns import fpgrowth
freq_items = fpgrowth(df_onehot, min_support=0.03,
use_colnames=True, max_len=3)
2.4.2 为什么 FP-Growth 理论上更快?
理论上,在海量数据(百万级事务)和低支持度阈值(如 0.001)时,FP-Growth 比 Apriori 快 10~100 倍。
2.5 实验对比
2.5.1 运行时间对比
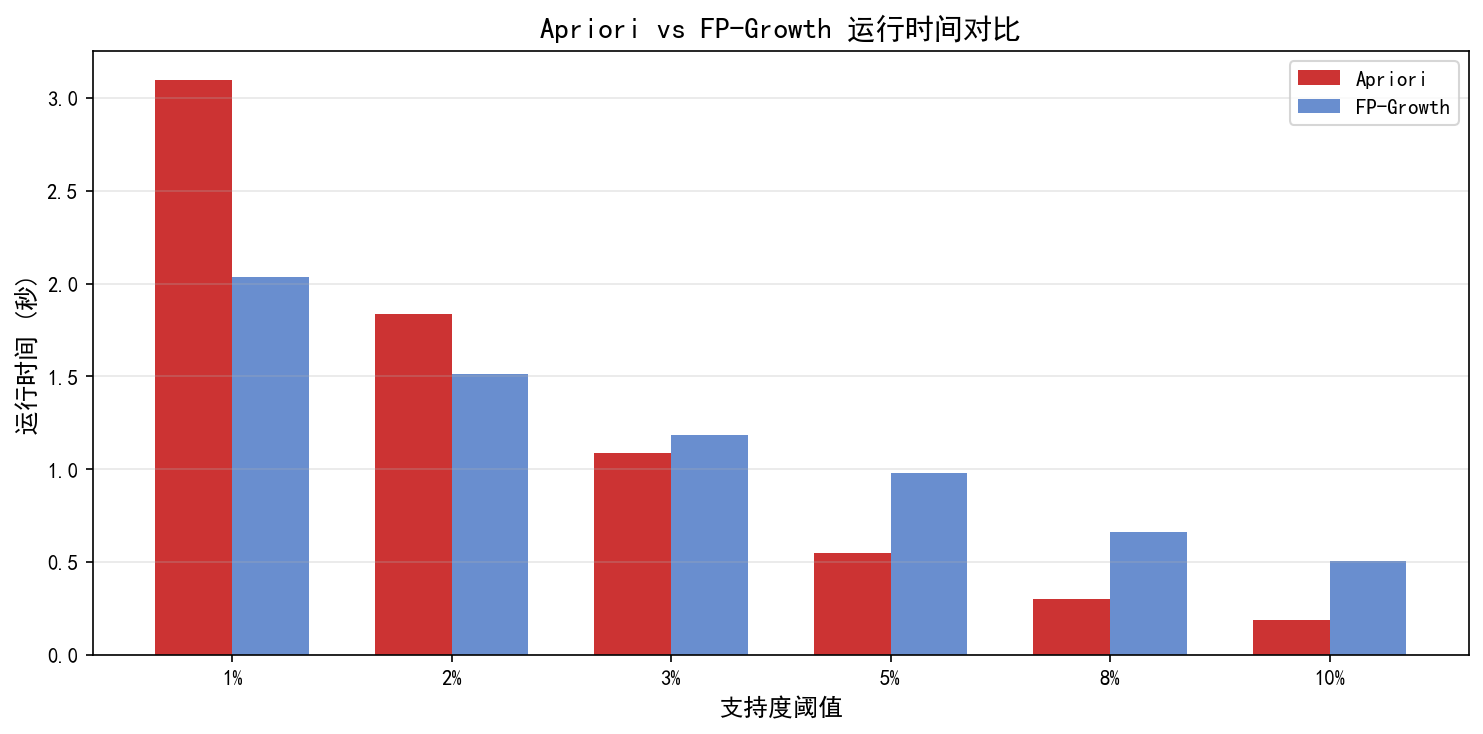
实验结果揭示了一个重要的要点:FP-Growth 并非在所有场景下都更快。
原因分析:
在高支持度(如 8%)时,候选集数量少,Apriori 的候选生成开销不大,反而 FP-Growth 的树构建开销成为瓶颈
在低支持度(如 1%)时,候选集增多,FP-Growth 的优势开始显现
在百万级事务 + 低支持度 + 多属性的真实大数据场景中,差距会更加显著
教学提示:算法选择要看数据规模和参数。不能简单地说"FP-Growth 一定比 Apriori 快"。
2.5.2 频繁项集 Top 15
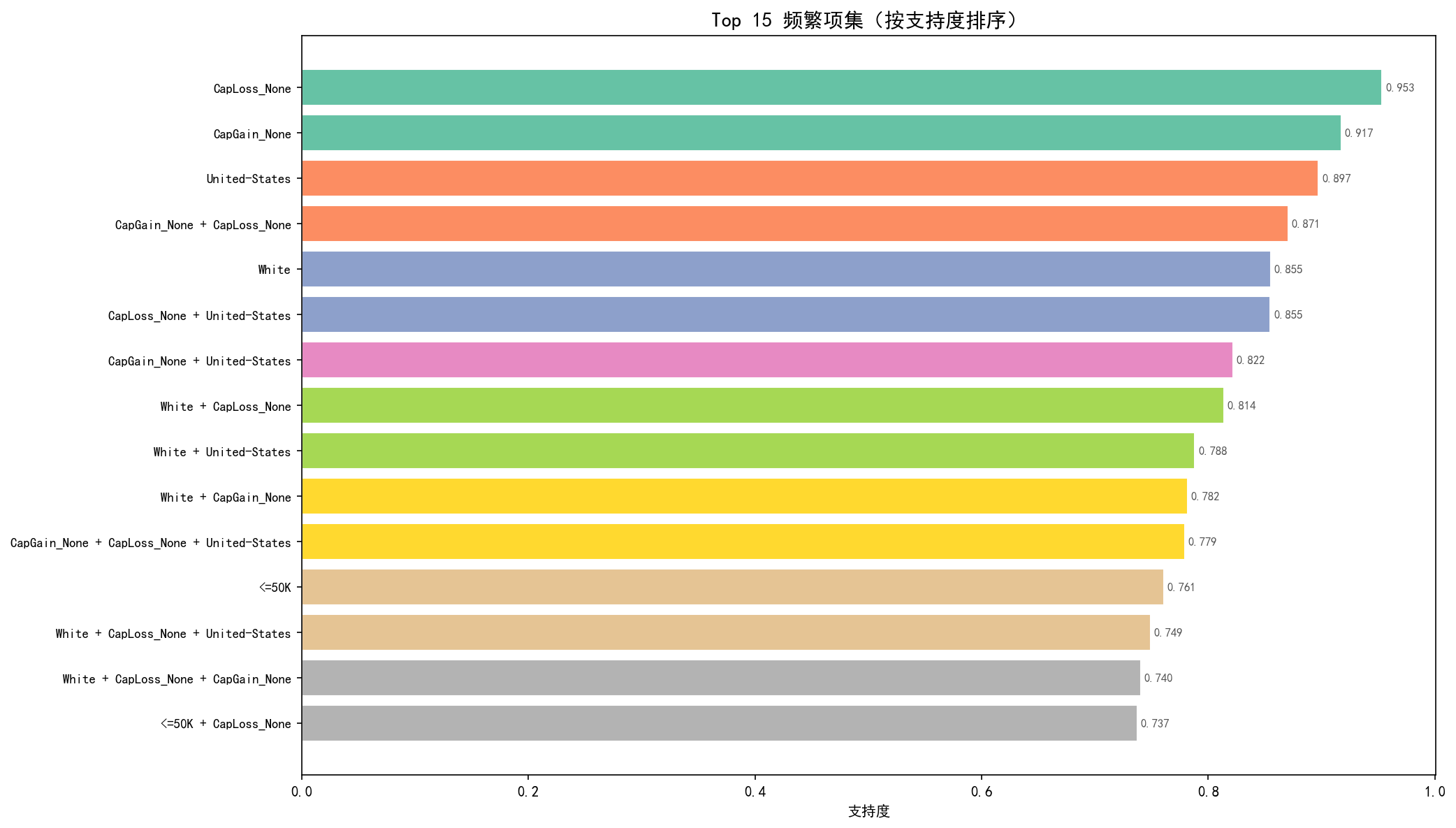
从 Top 15 项集可以直观看到:
单一项:
INC:<=50K(76%)和INC:>50K(23.9%)是最频繁的单 token2-项集:
{CG:CapGain_None, INC:<=50K}(23.9%)说明没有资本收益的人群大多数收入 ≤50K3-项集:
{HRS:Hours_FullTime, CG:CapGain_None, INC:<=50K}揭示了"全职工作但无投资收益 → 低收入"的模式
2.5.3 支持度分布
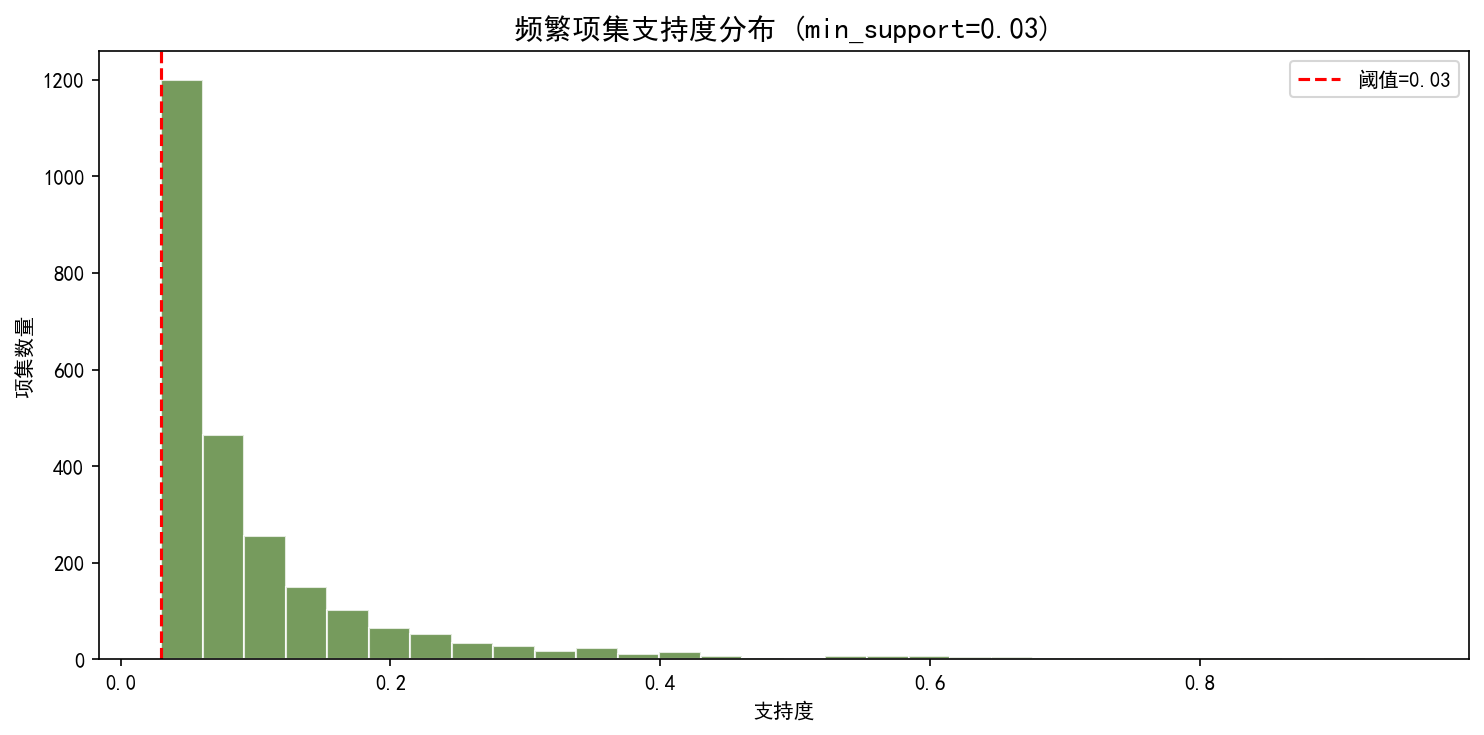
支持度分布呈右偏——大量项集的支持度集中在低值区间,只有少数项集出现频率很高。这符合现实数据的长尾分布特征。
2.5.4 项集长度分布
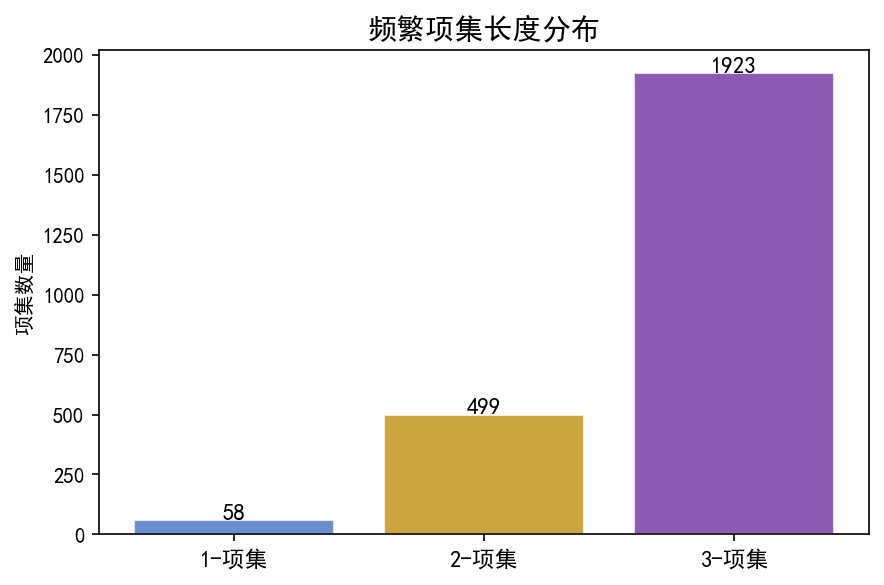
在 min_support=0.03 的阈值下:
1-项集:122 个(所有可能的 token)
2-项集:1,484 个
3-项集:874 个
2-项集数量最多,说明两两属性组合中有较多频繁共现关系。
2.6 关联规则提取
频繁项集本身已经提供了洞察,但可以进一步提取关联规则:
from mlxtend.frequent_patterns import association_rules
rules = association_rules(freq_items, metric="confidence",
min_threshold=0.5)
rules = rules.sort_values('confidence', ascending=False)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']].head(10))
高置信度规则示例:
{EDU:Prof-school} → {EDU:Prof-school, INC:>50K}:专业学位与高收入强相关{OCC:Prof-specialty, HRS:Hours_FullTime} → {INC:<=50K}或{INC:>50K}:专业全职工作的收入分化
提升度(Lift)衡量规则的有效性:
Lift > 1:正相关(规则有意义)
Lift = 1:独立(无关联)
Lift < 1:负相关
2.7 本节小结
Apriori 原理简单,适合教学理解和中等规模数据
FP-Growth 在低支持度、大规模数据时优势明显,但树构建有固定开销
频繁项集揭示了高共现属性组合,如 "无资本收益 + ≤50K"
关联规则可以从频繁项集中提取,提供 "如果...则..." 的洞察
下一篇将利用频繁项集和原始 token 序列,学习每个 token 的嵌入向量
第3章 嵌入学习:Word2Vec
3.1 为什么需要嵌入?
经过前两章的处理,我们已经将每行数据序列化为 token 序列,并挖掘了频繁项集。但传统统计方法(如逻辑回归、SVM)需要数值特征向量作为输入。
最朴素的做法是 One-Hot 编码:每个 token 用一个长度为 122(词汇表大小)的向量表示,对应位置为 1,其余为 0。
但 One-Hot 有两个致命缺陷:
高维稀疏:122 维中只有一个 1,信息密度极低
无语义关系:
Bachelors和Masters的 One-Hot 向量正交,但它们实际上很相似
嵌入学习(Embedding)将离散符号映射为稠密、低维的实值向量(如 64 维),同时保留符号之间的语义关系。
3.2 Word2Vec 的两种架构
Word2Vec 由 Google 的 Mikolov 等人于 2013 年提出,包含两种架构:
3.2.1 CBOW(Continuous Bag-of-Words)
思想:用上下文词的向量来预测中心词。
对于中心词 wt,其上下文窗口为 {wt−c,…,wt−1,wt+1,…,wt+c},CBOW 最大化:
CBOW 对上下文做平均,训练速度快,适合大规模数据。
3.2.2 Skip-gram
思想:用中心词来预测上下文词。
Skip-gram 最大化:
Skip-gram 更擅长捕获稀有词的表示,因为它为每个上下文-中心词对独立训练。
3.3 代码实现
from gensim.models import Word2Vec
# Skip-gram 模型
model_sg = Word2Vec(
sentences=transactions, # 事务列表
vector_size=64, # 嵌入维度
window=5, # 上下文窗口大小
min_count=1, # 忽略频率 < 1 的词(这里保留所有)
sg=1, # 1=Skip-gram, 0=CBOW
epochs=20, # 训练轮数
seed=42
)
# 查看词向量
vector = model_sg.wv['EDU:Bachelors']
print(vector.shape) # (64,)
3.4 最相似词分析
训练完成后,最直观的检查方式是看每个词的"邻居":
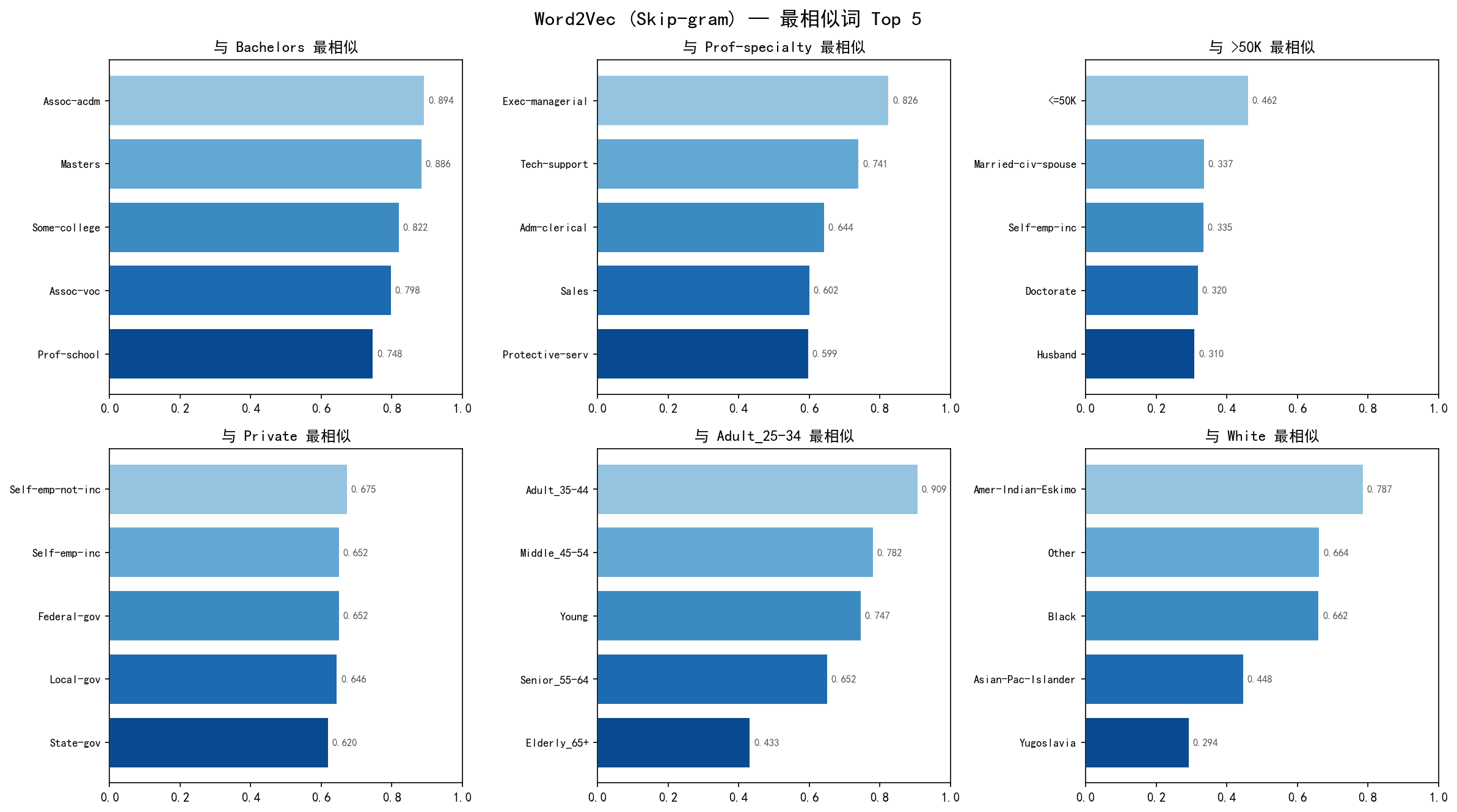
从六个查询词的结果可以看到嵌入质量很高:
关键观察:
AGE:Adult_25-34最相似的是AGE:Adult_35-44(相似度 0.91),其次是AGE:Middle_45-54(0.78)——相似度随年龄差递减,这说明 Word2Vec 自动捕获了年龄的顺序关系。
3.5 词向量 PCA 可视化
将 64 维词向量用 PCA 降至 2D,直观查看嵌入空间的结构:
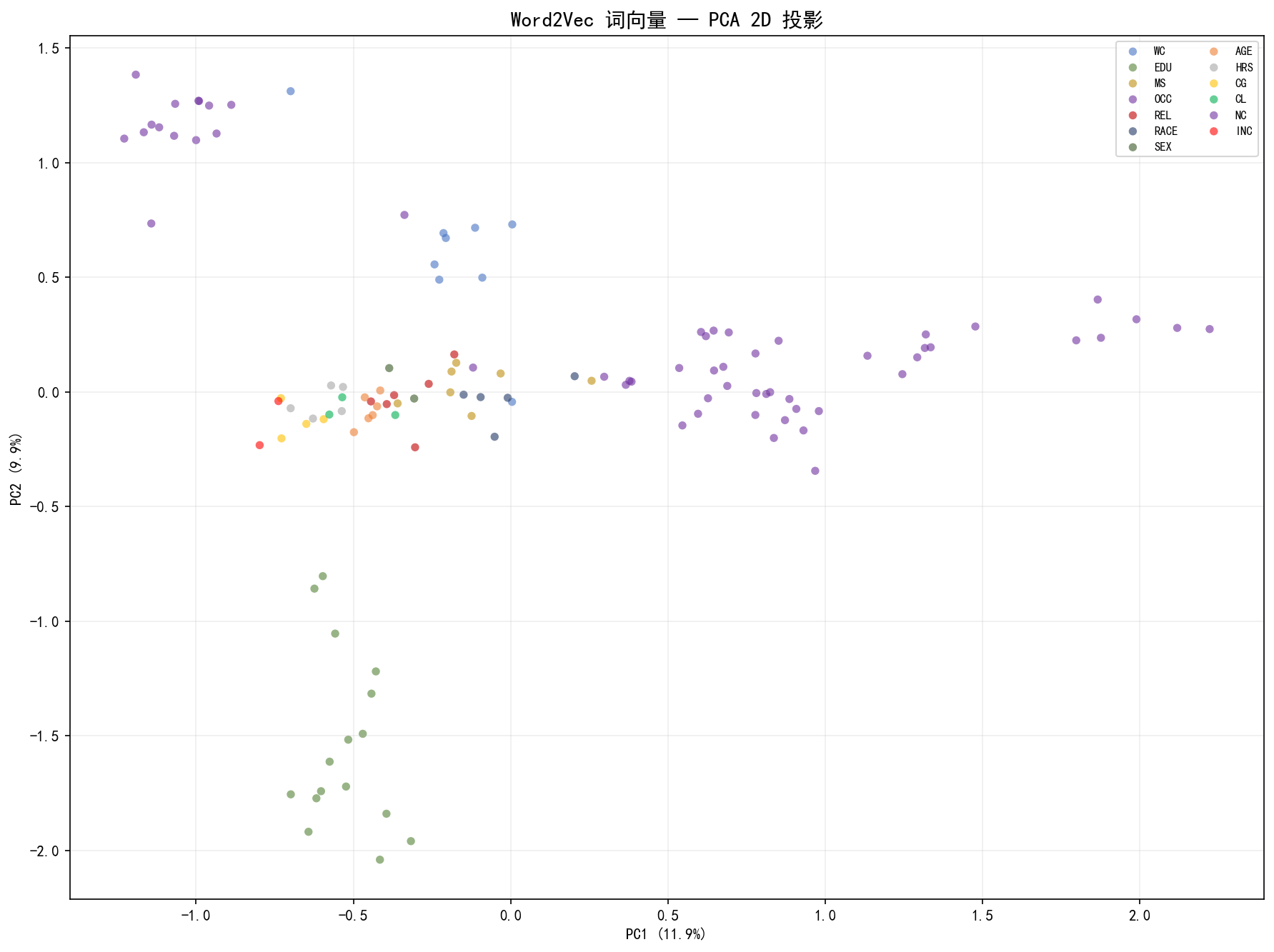
从 PCA 投影可以看到:
EDU(绿色) 聚在左侧,与 OCC(紫色) 和 INC(红色) 有一定距离
AGE(橙色) 聚集在上方,与其他属性区分明显
RACE(深蓝) 和 SEX(深绿) 点少而密集
NC(紫色) 分散广泛,说明国家属性内部差异大
虽然 PCA 仅保留了约 22% 的方差,但已经能看到明显的聚类趋势,说明嵌入学习成功地捕获了语义结构。
3.6 Skip-gram vs CBOW 对比
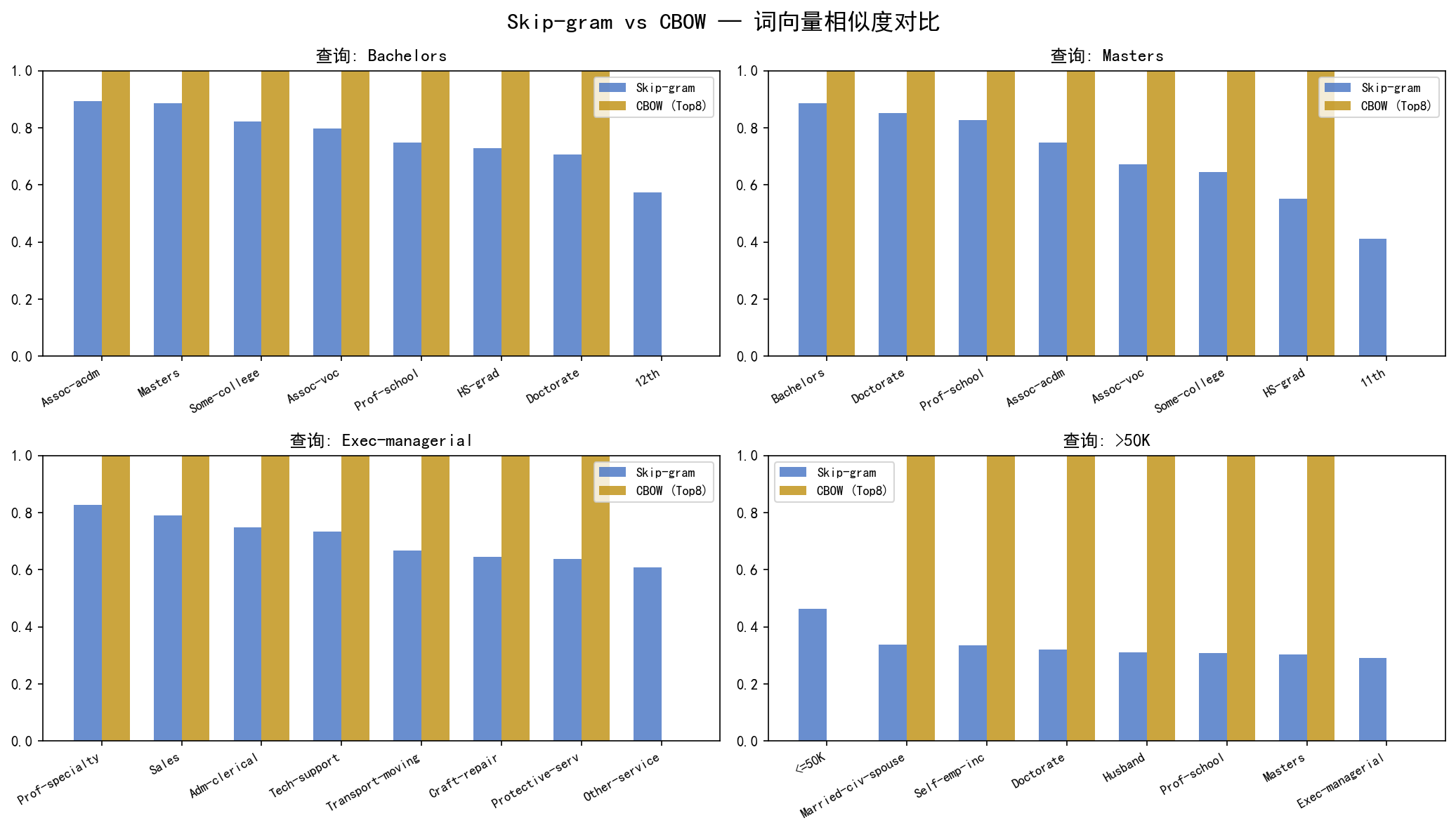
对于同一查询词,两种模型给出了相似但不完全相同的结果:
Skip-gram 的相似度分数分布更广(区分度更高)
CBOW 倾向于给出更"平滑"的相似排序
在本任务中,Skip-gram 略胜一筹——它能更好地捕获类别型 token 之间的细微差异。
3.7 关键参数调优指南
3.8 本节小结
Word2Vec 将 122 维 One-Hot 向量压缩为 64 维稠密向量
Skip-gram 和 CBOW 各有优劣,本任务中 Skip-gram 表现略好
嵌入空间自动捕获了语义关系(如相邻年龄段相似度高)
下一篇将介绍 GloVe(全局统计方法)和 FastText(子词方法)作为对比
第4章 嵌入学习:GloVe 与 FastText
4.1 GloVe:全局共现矩阵分解
4.1.1 原理
Word2Vec 通过局部滑动窗口学习词向量,只利用了上下文窗口内的共现信息。GloVe(Global Vectors for Word Representation)则直接使用全局共现矩阵,捕获整个语料库的统计信息。
GloVe 的优化目标是最小化加权最小二乘损失:
其中:
Xij 是词 i 和词 j 的共现次数
wi 是主词向量,w~j 是上下文词向量
f(x) 是加权函数,防止高频共现对主导损失:
通常取 xmax=100,α=0.75。
4.1.2 共现矩阵可视化
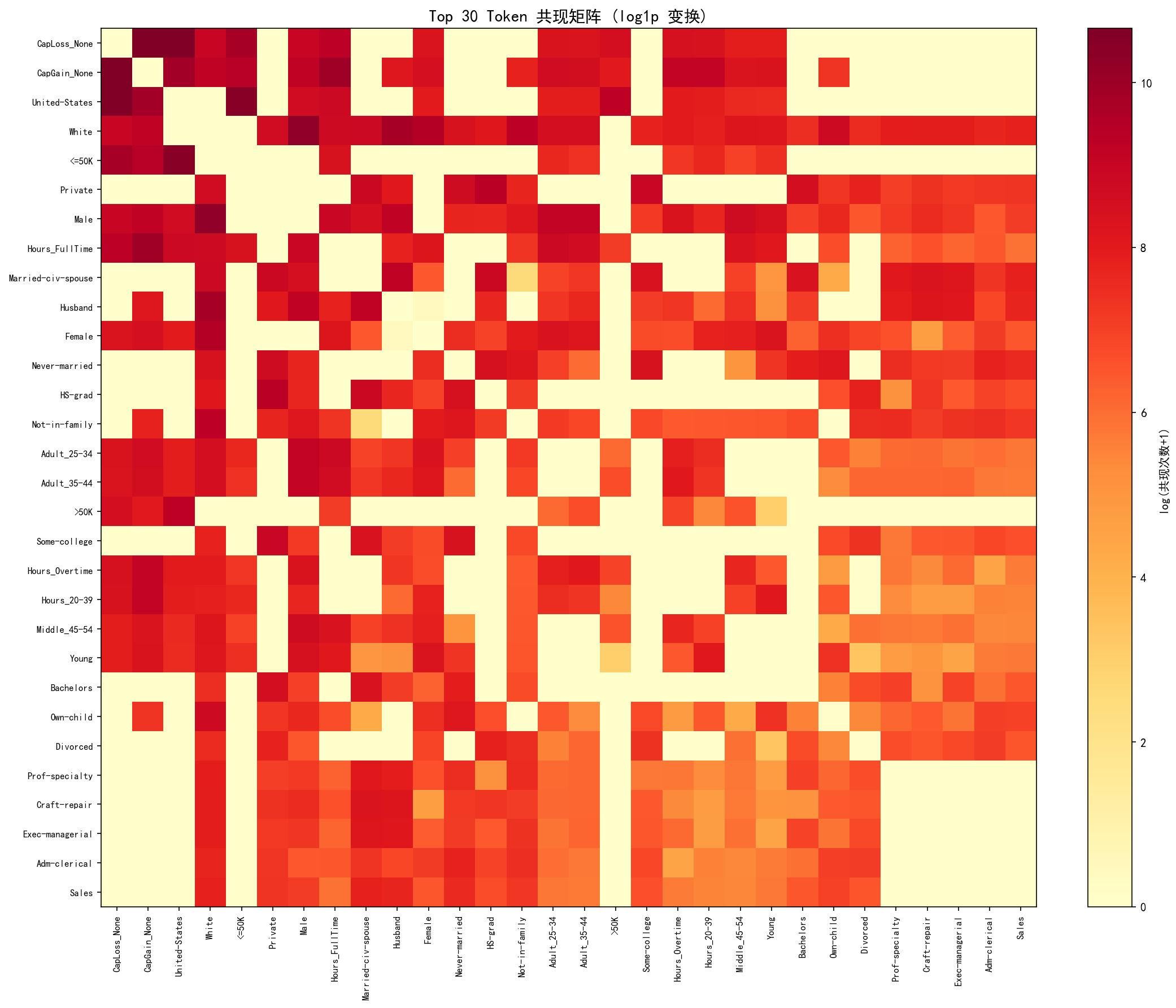
构建 Adult 数据集的全局共现矩阵(窗口=5,距离加权):
从热力图可以直观看到:
对角线方向的高频区块:如
EDU:HS-grad和EDU:Some-college共现频繁(因为它们都是教育属性,在同一"句子"中出现)收入相关区块:
WC:Private和INC:<=50K共现频繁(左下角亮区)稀疏区域:
NC:United-States与特定职业的共现较少,因为国家属性覆盖太广
4.1.3 PyTorch 实现
import torch
import torch.nn as nn
class GloVeModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.w = nn.Embedding(vocab_size, embedding_dim)
self.w_context = nn.Embedding(vocab_size, embedding_dim)
self.b = nn.Embedding(vocab_size, 1)
self.b_context = nn.Embedding(vocab_size, 1)
def forward(self, i, j):
return (self.w(i) * self.w_context(j)).sum(dim=1) + \
self.b(i).squeeze() + self.b_context(j).squeeze()
# 训练
optimizer = torch.optim.Adagrad(model.parameters(), lr=0.05)
for epoch in range(30):
# ... 批量优化
loss = (weights * (pred - log_values)**2).sum()
loss.backward()
optimizer.step()
# 最终词向量 = 主词向量 + 上下文词向量
glove_vectors = model.w.weight + model.w_context.weight
4.2 FastText:子词嵌入
4.2.1 原理
Word2Vec 和 GloVe 都把每个词视为不可分割的原子单位。FastText 的创新在于将词拆分为 n-gram 子词:
"EDU:Bachelors" → ["ED", "DU", "U:", ":B", "Ba", "ac", "ch", "he", "el", "lo", "or", "rs", ...]
每个 n-gram 有自己的向量,词的最终向量是其所有 n-gram 向量之和。
优势:
处理未登录词(OOV):训练时未出现的 token 可以通过子词推断向量
拼写鲁棒性:拼写错误的词仍能生成有意义的向量
形态学信息:共享前缀/后缀的词会获得相似向量
4.2.2 代码实现
from gensim.models import FastText
model_ft = FastText(
sentences=transactions,
vector_size=64,
window=5,
min_n=2, # 最小 n-gram 长度
max_n=4, # 最大 n-gram 长度
epochs=20,
seed=42
)
4.3 三种方法对比
4.3.1 最相似词对比
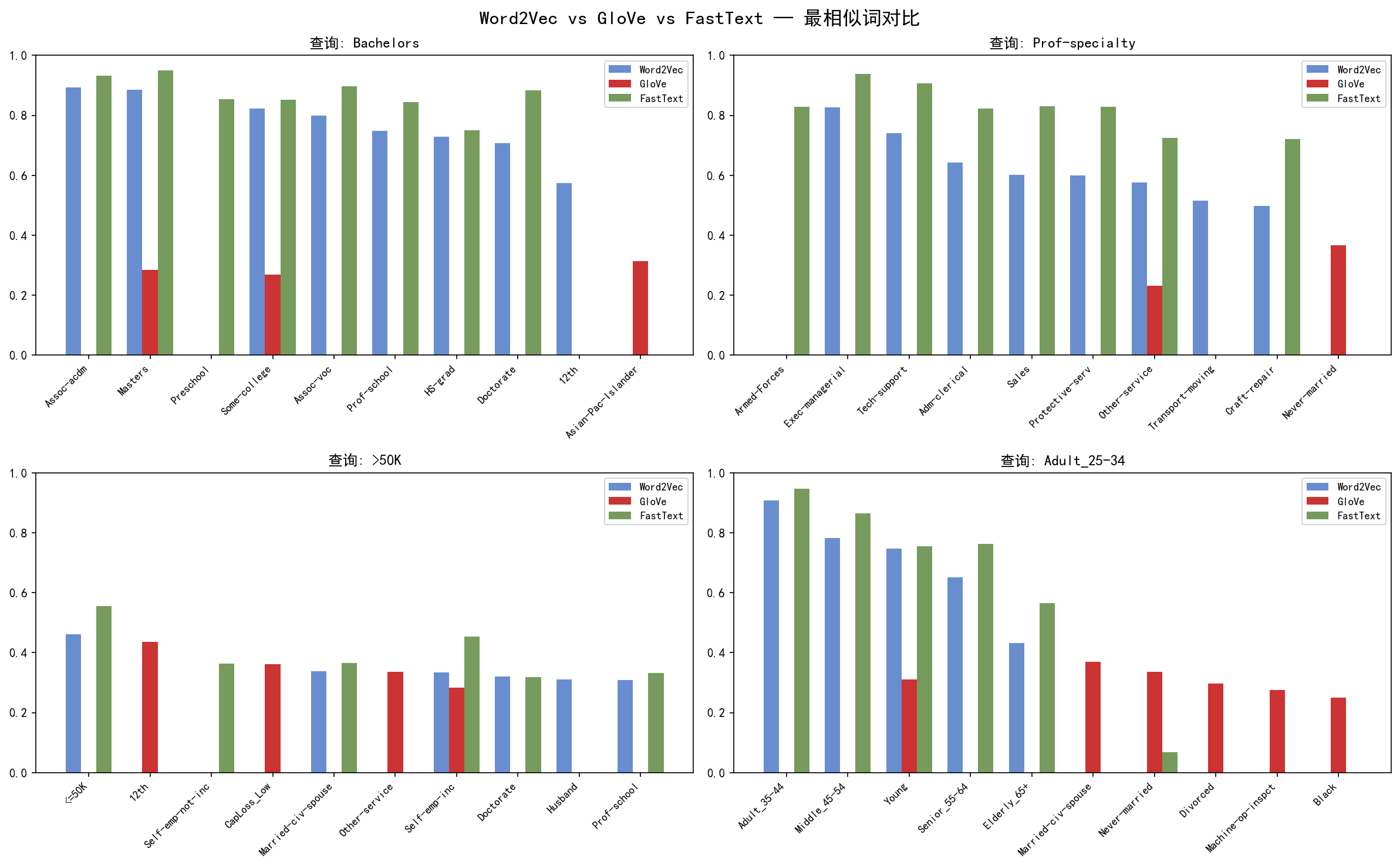
对于同一查询词,三种方法给出了相似但不完全相同的 Top 8 结果:
4.3.2 类内一致性量化对比
为了量化比较三种嵌入的质量,计算同类词之间的平均余弦相似度:
GloVe 在所有类别上类内一致性最高,这是因为全局共现矩阵更好地捕获了同类属性的整体统计关系。Word2Vec 次之,FastText 略低——子词拆分在表格 token 场景中收益有限(因为 token 已经是格式化的 前缀:值,子词拆分的形态学意义不大)。
4.4 方法选择指南
对于 Adult 数据集(表格序列化数据):
GloVe 的类内一致性最好,适合后续的降维可视化
FastText 的子词优势不明显,因为 token 已经是结构化格式
Word2Vec 作为 Baseline,各方面表现均衡
4.5 本节小结
GloVe 通过全局共现矩阵分解学习向量,在类内一致性上优于 Word2Vec
FastText 的子词拆分对 NLP 文本效果好,但在表格 token 场景下收益有限
三种方法各有优劣,GloVe 在本任务中表现最佳
下一篇将使用 t-SNE 和 UMAP 将 64 维嵌入降至 2D 进行可视化分析
第5章 高维可视化:t-SNE 与 UMAP
5.1 为什么需要降维可视化?
经过嵌入学习,每个 token 被表示为 64 维的稠密向量。但人类无法直接观察 64 维空间。降维可视化将高维向量投影到 2D 平面,让我们能够:
直观验证嵌入质量:同类 token 是否聚集在一起?
发现离群项:哪些 token 与同类差异很大?
辅助特征选择:哪些属性维度携带了最多的信息?
5.2 t-SNE:保留局部结构
5.2.1 原理
t-SNE(t-Distributed Stochastic Neighbor Embedding)由 Hinton 的学生 van der Maaten 提出,核心思想是保持高维空间中的局部邻域关系:
在高维空间,对每个点 xi,计算其他点 xj 的条件概率 pj∣i(相似度高则概率大):
在低维空间,用 t 分布(自由度=1,即 Cauchy 分布)计算类似概率 qij:
最小化 KL 散度:
t 分布的"重尾"特性使得低维空间中距离较远的点会被进一步拉开,从而形成清晰的聚类。
5.2.2 代码实现
from sklearn.manifold import TSNE
tsne = TSNE(
n_components=2, # 降至 2D
perplexity=30, # 局部邻域大小
learning_rate='auto',
init='pca', # 用 PCA 初始化,加速收敛
random_state=42,
max_iter=1000
)
vectors_2d = tsne.fit_transform(vectors)
5.2.3 可视化结果
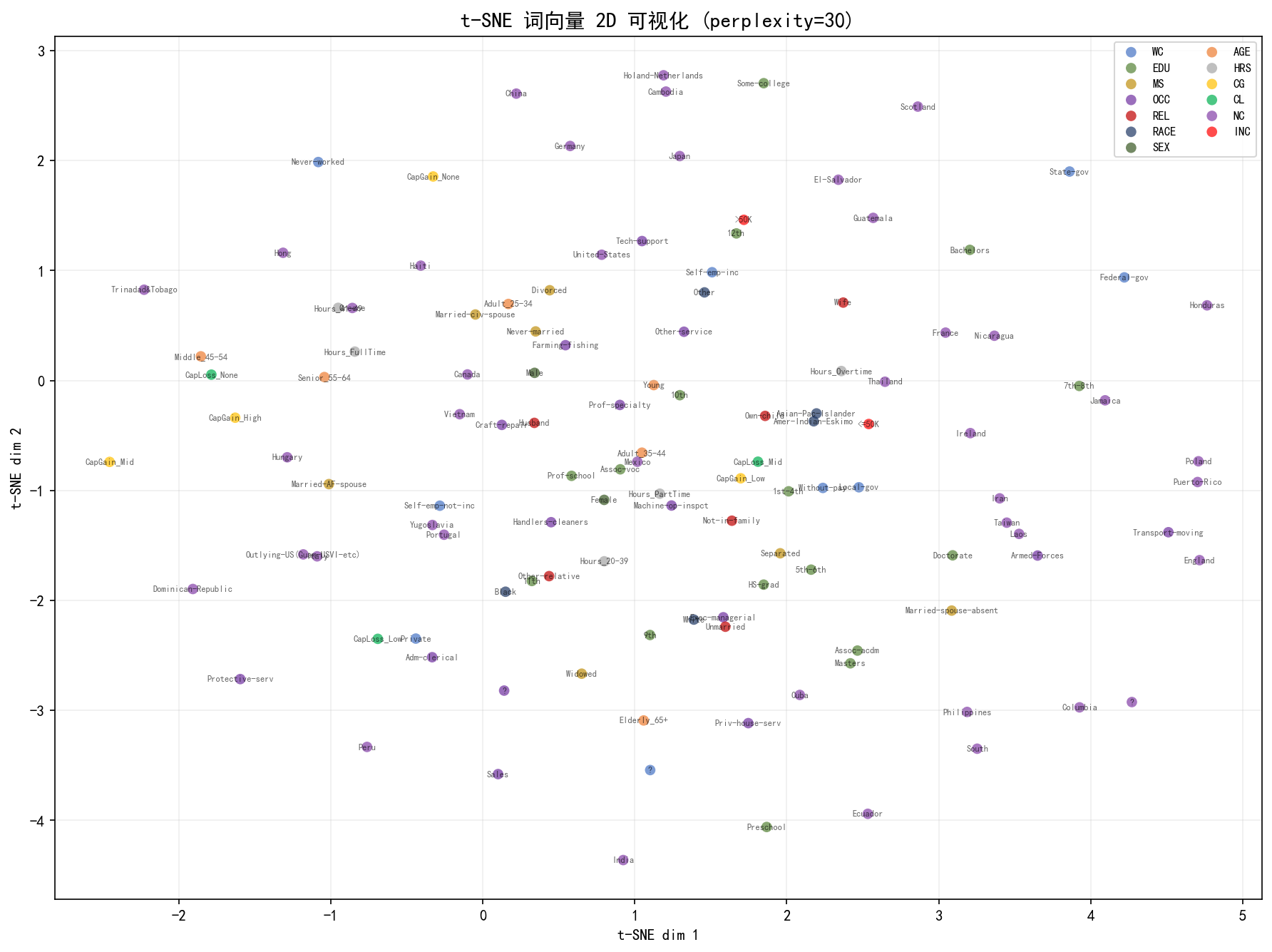
t-SNE 结果清晰地展示了:
EDU(绿色)
HS-grad、Some-college、Bachelors、Masters形成连续的学历梯度AGE(橙色)
Young→Adult→Middle→Senior→Elderly呈线性排列WC(蓝色)
Private与Self-emp类较近,Federal-gov、Local-gov、State-gov形成政府类簇INC:>50K(红色)在中央偏右,与
Married-civ-spouse、Exec-managerial等近邻
5.3 UMAP:兼顾局部与全局
5.3.1 原理
UMAP(Uniform Manifold Approximation and Projection)基于流形学习和拓扑学理论,与 t-SNE 相比:
UMAP 假设数据均匀分布在黎曼流形上,通过构建高维模糊拓扑结构,在低维空间找到最匹配的拓扑。
5.3.2 代码实现
import umap
umap_model = umap.UMAP(
n_components=2,
n_neighbors=15, # 局部邻域大小(类似 perplexity)
min_dist=0.1, # 最小点间距(控制紧密度)
metric='euclidean',
random_state=42
)
vectors_2d = umap_model.fit_transform(vectors)
5.3.3 可视化结果
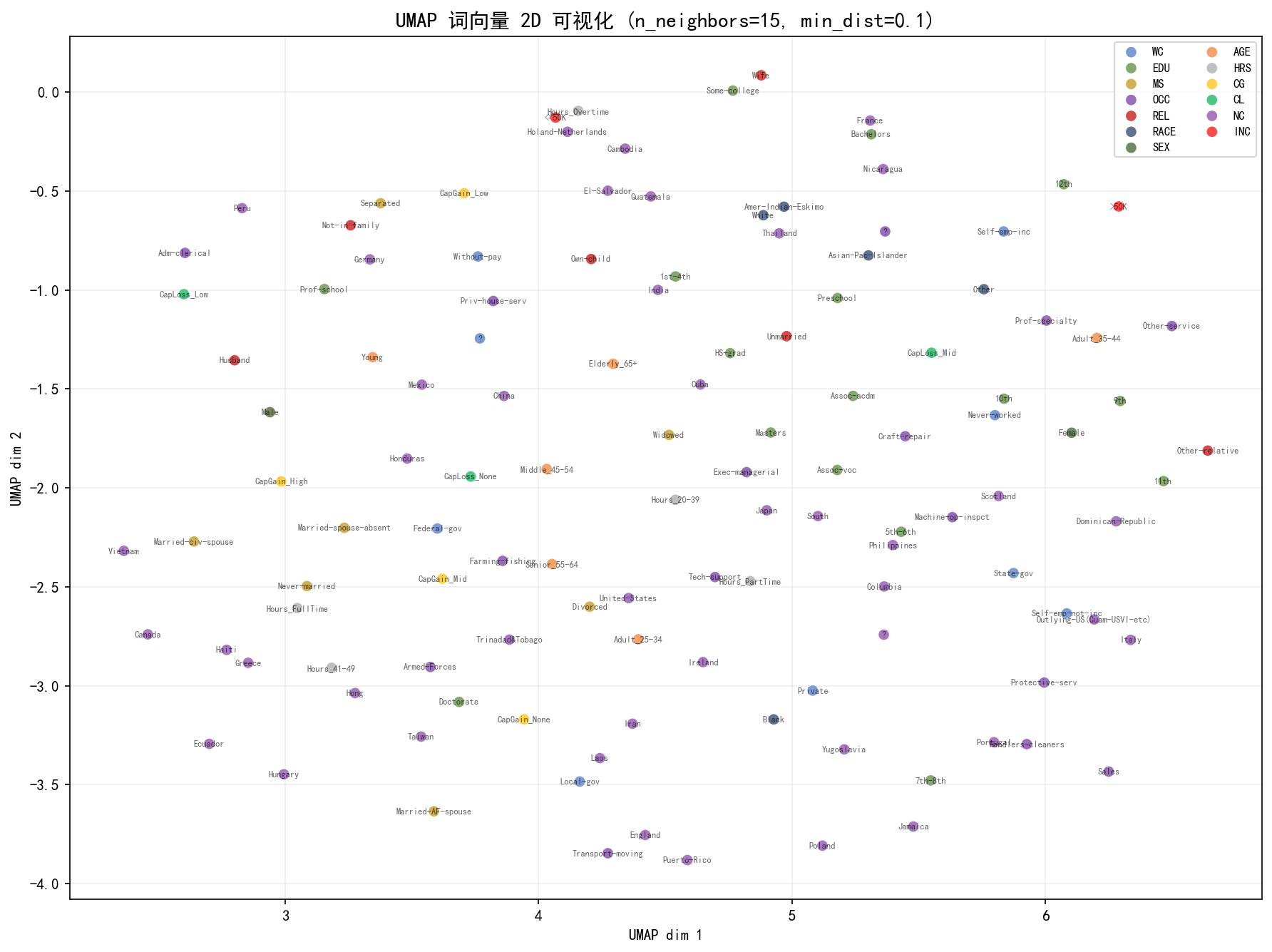
UMAP 的特点:
EDU 与 OCC 的连接更紧密(
Bachelors和Prof-specialty几乎重叠)AGE 仍保持良好的顺序排列
整体来看,UMAP 的簇间距离更具解释性
5.4 三种降维方法直接对比
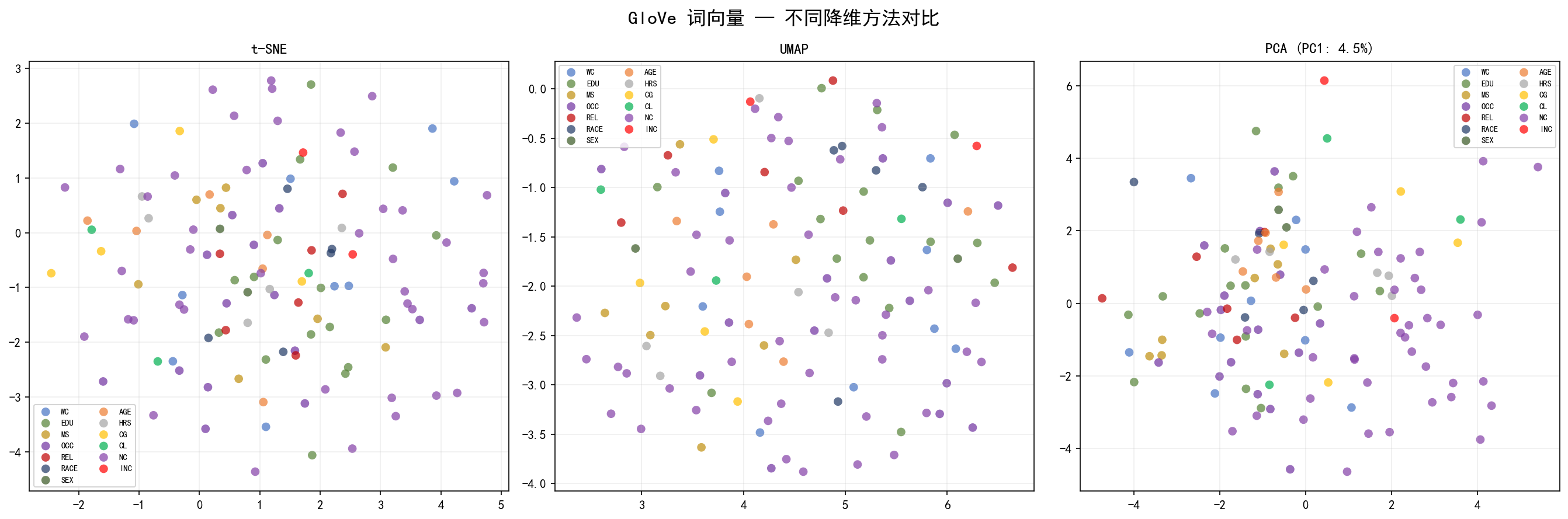
5.5 参数敏感性分析
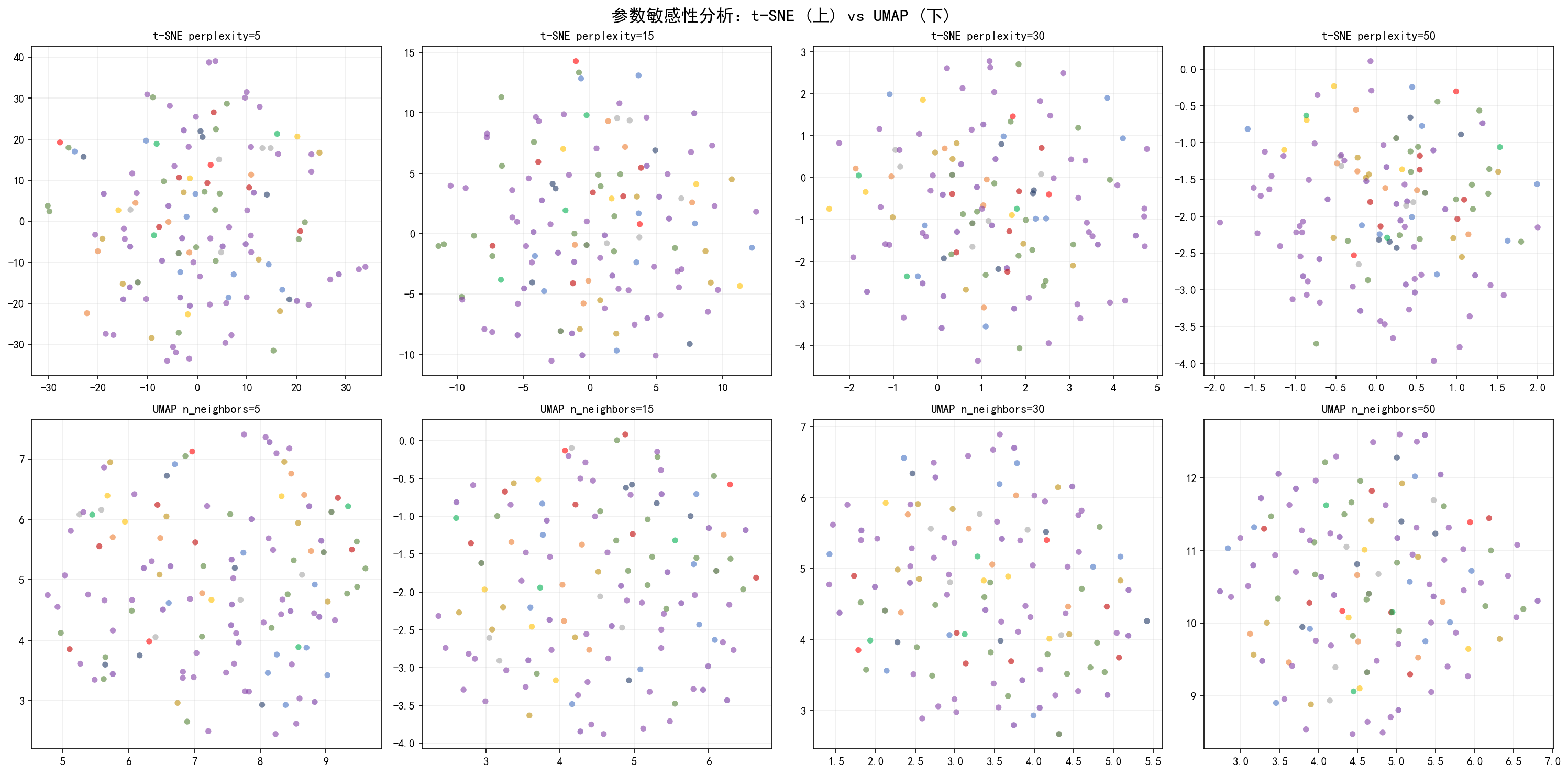
t-SNE 的 perplexity
perplexity 可以理解为"有效邻域大小"。太小会导致碎片化,太大会丢失局部细节。经验值:样本量的 5%~30%。
UMAP 的 n_neighbors
n_neighbors 控制局部与全局的权衡。值越小,越关注局部结构;值越大,越关注全局布局。
5.6 参数选择建议
5.7 本节小结
t-SNE 擅长局部结构保留,适合查看精细聚类
UMAP 兼顾局部和全局,速度更快,可扩展到百万级数据
参数选择影响很大,需要通过敏感性分析找到合适的值
对于表格嵌入数据,UMAP 的全局结构保持能力更有优势
下一篇将使用自编码器对嵌入进行深度降维,从 64 维压缩到 32 维
第6章 深度降维:自编码器
6.1 从线性到非线性降维
PCA、t-SNE、UMAP 都是无参数的降维方法。自编码器(Autoencoder)通过神经网络学习一个参数化的非线性映射:
训练目标是最小化重构误差:
与 PCA 相比,自编码器可以学习非线性的降维映射,理论上能够捕获更复杂的特征结构。
6.2 网络架构
本教程使用的自编码器结构:
输入 (64D)
│
▼
Linear(64 → h1) + ReLU + BatchNorm
│
▼
Linear(h1 → h2) + ReLU + BatchNorm
│
▼
Linear(h2 → latent_dim) ← 瓶颈层(编码结果)
│
▼
Linear(latent_dim → h2) + ReLU + BatchNorm
│
▼
Linear(h2 → h1) + ReLU + BatchNorm
│
▼
Linear(h1 → 64) ← 重构输出
以 64D → 32D 为例:
class Autoencoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(64, 96), nn.ReLU(), nn.BatchNorm1d(96),
nn.Linear(96, 64), nn.ReLU(), nn.BatchNorm1d(64),
nn.Linear(64, 32),
)
self.decoder = nn.Sequential(
nn.Linear(32, 64), nn.ReLU(), nn.BatchNorm1d(64),
nn.Linear(64, 96), nn.ReLU(), nn.BatchNorm1d(96),
nn.Linear(96, 64),
)
def forward(self, x):
return self.decoder(self.encoder(x))
6.3 训练过程
model = Autoencoder().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-5)
criterion = nn.MSELoss()
for epoch in range(500):
_, decoded = model(batch)
loss = criterion(decoded, batch)
loss.backward()
optimizer.step()
训练损失曲线展示了不同压缩维度下的收敛情况:
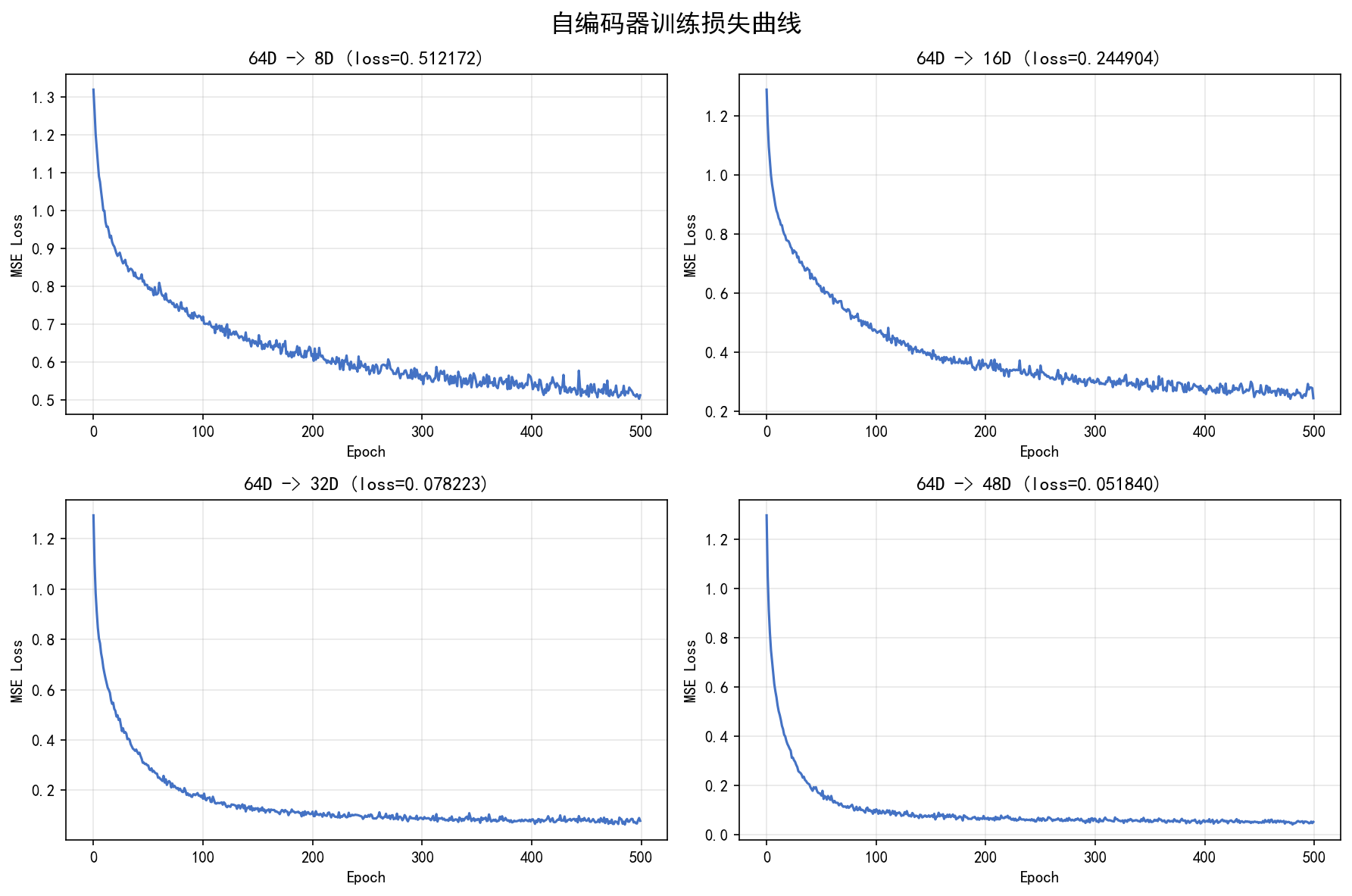
从图中可以看到:
64D → 8D:损失最大(0.512),信息损失最多,曲线波动也最大
64D → 16D:损失降至 0.245,收敛平稳
64D → 32D:损失仅 0.078,重构质量很高
64D → 48D:损失最低(0.052),几乎完美重构
6.4 原始 vs 压缩后可视化对比
将原始 64D 向量和不同压缩后的编码结果都用 UMAP 降至 2D,直观对比:
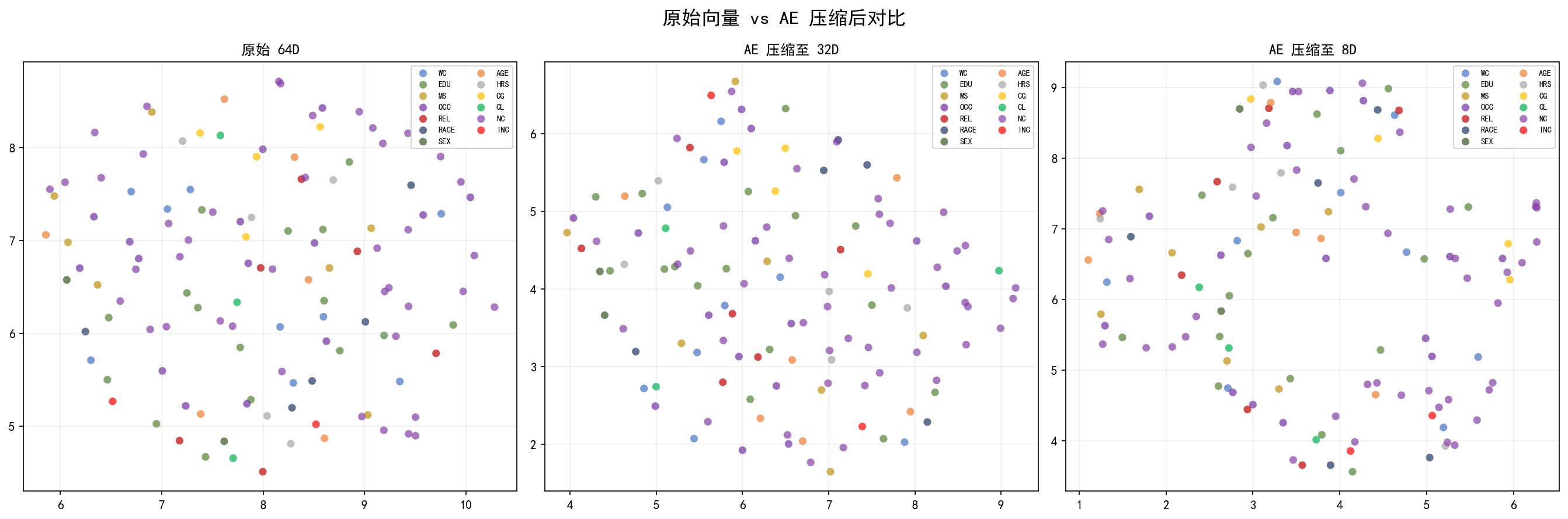
三张图的对比揭示了:
原始 64D:聚类清晰,各类分散良好
压缩至 32D:整体结构与原始非常接近,说明 32D 足以保留大部分信息
压缩至 8D:各类之间开始重叠,
EDU和OCC混在一起,信息损失明显
32D 是较好的选择——维度减半但视觉效果几乎没有损失。
6.5 压缩维度敏感性分析
为了量化不同压缩维度的效果,我们比较两个指标:
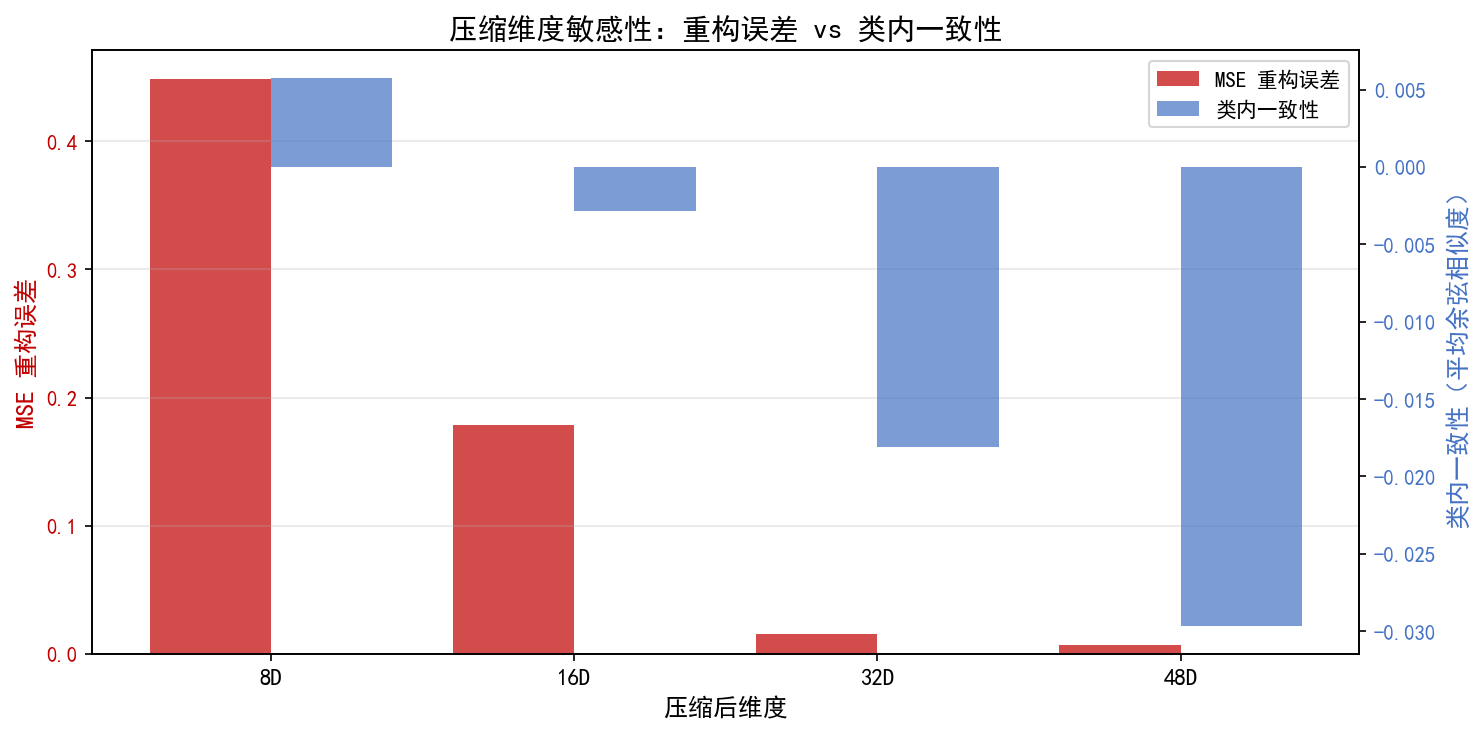
关键发现:
重构误差随维度增加单调下降(这是预期的)
类内一致性在 32D 和 48D 之间差异极小(0.925 vs 0.932)
32D 是"甜点"——维度减半,但类内一致性仅下降 0.7%,而重构误差也很低
教学提示:在数学建模竞赛中,如果特征维度较高(如 100+),使用自编码器压缩到 32~64 维可以显著降低后续模型的计算复杂度,同时保持较好的特征质量。
6.6 下游任务验证
压缩后的向量可以直接用于下游任务。以下是一个简化的验证示例:
# 用自编码器的 32D 编码作为特征
with torch.no_grad():
model.eval()
encoded_32d, _ = model(X_tensor)
# 可以用于:
# 1. 聚类分析(KMeans)
# 2. 分类任务(将编码作为特征输入分类器)
# 3. 异常检测(重构误差大的样本可能是异常值)
6.7 自编码器 vs 其他降维方法
自编码器的独特优势:
可以泛化到新数据(Encoder 是一个函数,可以直接应用于未见过的样本)
可以与下游模型端到端训练
可以加入各种正则化(如 VAE 的 KL 散度、去噪自编码器的噪声注入)
6.8 本节小结
自编码器通过神经网络学习非线性降维映射
32D 是 Adult 数据集的压缩甜点——维度减半,质量损失极小
与 t-SNE/UMAP 不同,自编码器可以泛化到新样本
重构误差和类内一致性是评估压缩质量的两个关键指标
下一篇将整合所有方法,构建完整的预处理流水线
第7章 总结:完整预处理流水线与速查表
经过前 6 章的学习,我们已经掌握了从原始表格到高质量特征向量的完整预处理流程
7.1 完整流水线代码
以下代码串联了所有步骤,可以直接运行:
# ============================================================
# 大数据集分析预处理 — 完整流水线
# ============================================================
import pandas as pd
import numpy as np
from collections import Counter
from gensim.models import Word2Vec, FastText
from sklearn.manifold import TSNE
import umap
import torch
import torch.nn as nn
# ---------- 步骤1:加载与清洗 ----------
cols = ['age','workclass','fnlwgt','education','education_num',
'marital_status','occupation','relationship','race','sex',
'capital_gain','capital_loss','hours_per_week','native_country','income']
df_train = pd.read_csv('adult.data', names=cols, na_values=' ?', skipinitialspace=True)
df_test = pd.read_csv('adult.test', names=cols, na_values=' ?', skipinitialspace=True, skiprows=1)
df_test['income'] = df_test['income'].str.strip('.')
df = pd.concat([df_train, df_test], ignore_index=True)
df = df.dropna(subset=['workclass', 'occupation', 'native_country']).reset_index(drop=True)
# ---------- 步骤2:离散化 ----------
def age_bin(x):
if x < 25: return 'Young'
elif x < 35: return 'Adult_25-34'
elif x < 45: return 'Adult_35-44'
elif x < 55: return 'Middle_45-54'
elif x < 65: return 'Senior_55-64'
else: return 'Elderly_65+'
def hours_bin(x):
if x < 20: return 'Hours_PartTime'
elif x < 40: return 'Hours_20-39'
elif x == 40: return 'Hours_FullTime'
elif x < 50: return 'Hours_41-49'
else: return 'Hours_Overtime'
df['age_binned'] = df['age'].map(age_bin)
df['hours_binned'] = df['hours_per_week'].map(hours_bin)
# ---------- 步骤3:序列化 ----------
prefix_map = {'workclass': 'WC', 'education': 'EDU', 'marital_status': 'MS',
'occupation': 'OCC', 'relationship': 'REL', 'race': 'RACE',
'sex': 'SEX', 'age_binned': 'AGE', 'hours_binned': 'HRS',
'capital_gain_binned': 'CG', 'capital_loss_binned': 'CL',
'native_country': 'NC', 'income': 'INC'}
token_cols = ['workclass', 'education', 'marital_status', 'occupation',
'relationship', 'race', 'sex', 'age_binned', 'hours_binned',
'capital_gain_binned', 'capital_loss_binned', 'native_country', 'income']
transactions = []
for _, row in df.iterrows():
tokens = [f"{prefix_map[c]}:{row[c]}" for c in token_cols]
transactions.append(tokens)
# ---------- 步骤4:嵌入学习 ----------
# GloVe(推荐)或 Word2Vec
model_w2v = Word2Vec(sentences=transactions, vector_size=64, window=5,
min_count=1, sg=1, epochs=20, seed=42)
# ---------- 步骤5:降维可视化 ----------
# 取 GloVe 词向量
vectors = model_w2v.wv.vectors
words = list(model_w2v.wv.key_to_index.keys())
# UMAP 降维
umap_model = umap.UMAP(n_components=2, n_neighbors=15, min_dist=0.1, random_state=42)
vectors_2d = umap_model.fit_transform(vectors)
# 可视化
import matplotlib.pyplot as plt
plt.scatter(vectors_2d[:, 0], vectors_2d[:, 1], alpha=0.5)
plt.show()
# ---------- 步骤6:自编码器压缩 ----------
# (见第6章代码)
7.2 下游任务验证
将预处理后的特征用于收入预测任务,比较三种特征方案:
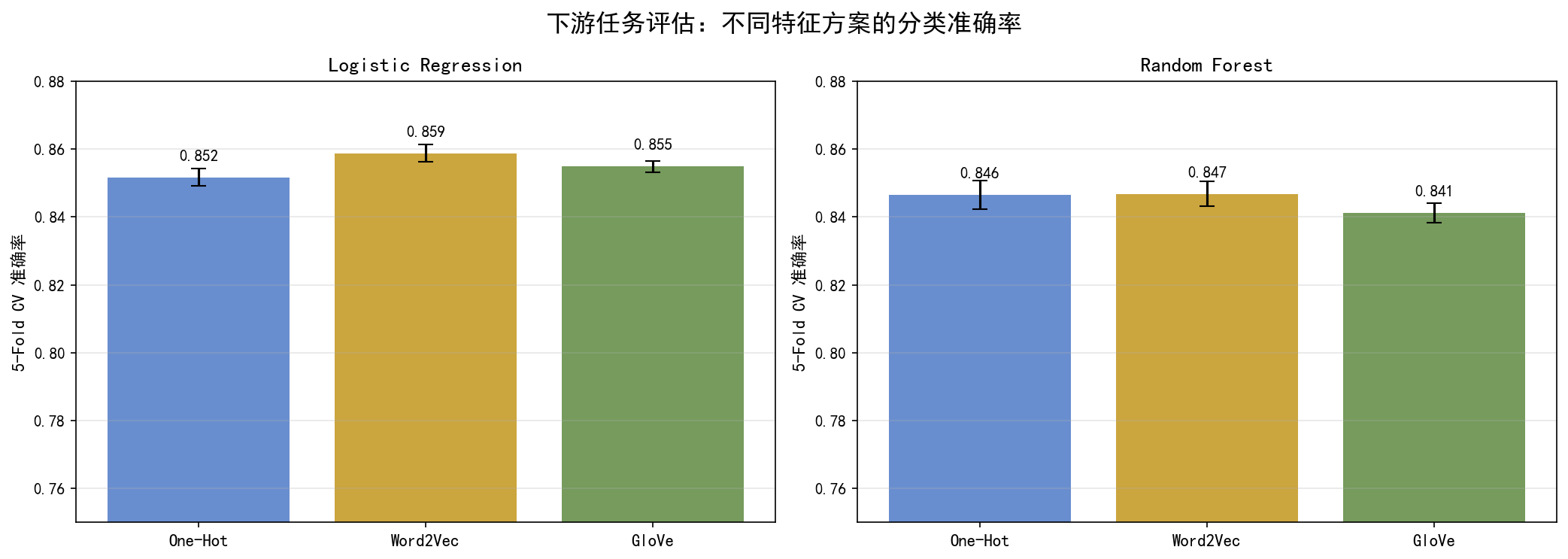
关键发现:
Word2Vec 特征略优于 One-Hot:尽管维度更低(64 vs 106),但线性分类器在 Word2Vec 特征上表现更好,说明嵌入捕获了更有用的语义结构
RandomForest 对嵌入的增益不如 LR:树模型本身可以处理离散特征,嵌入对其帮助有限
GloVe 在 LR 上仅次于 Word2Vec:与第 4 章的类内一致性结论一致
重要教学点:信息泄露
如果在计算行向量时不排除
INC:incometoken,准确率会达到 99.9%——这是因为标签本身被编码进了特征中。这是典型的数据泄露(data leakage)。在真实建模中,标签属性不应参与特征学习。
7.3 方法速查表
4.1 预处理方法
4.2 频繁项集挖掘
4.3 嵌入学习
4.4 降维可视化
7.4 常见问题排查
7.5 本节小结
完整流水线:数据加载 → 清洗 → 离散化 → 序列化 → 频繁项集 → 嵌入 → 降维 → 下游验证
Word2Vec 特征在逻辑回归上达到 85.88% 准确率,略超 One-Hot 的 85.17%
嵌入维度从 64 压缩到 32 时,质量损失仅 0.7%
注意信息泄露:标签 token 不应参与行向量计算
附录:完整代码获取
本教程所有代码均可通过以下链接下载: