
提高篇:蒙特卡洛模拟
前言
蒙特卡洛方法是一类基于随机抽样的数值计算方法。它的核心思想朴素而强大——如果你想知道某个复杂系统的性质,不需要推导精确公式,让计算机随机生成大量样本然后统计结果即可。对于熟悉传统统计学方法但需要处理高维积分、复杂优化、随机系统仿真等问题的人来说,蒙特卡洛方法是不可替代的工具。
适用读者
本教程面向已经了解传统统计学方法的读者。如果你已经知道以下概念,就可以直接开始:
期望、方差、协方差、相关系数
正态分布、均匀分布、指数分布等常见分布
大数定律、中心极限定理的基本思想
Python 基础编程(numpy、matplotlib)
本教程不讲解概率论的基础定义、分布的性质推导等内容,而是聚焦于如何用蒙特卡洛方法解决实际建模问题。
内容结构
环境说明
Python 版本:3.8+
核心依赖:numpy, scipy, matplotlib
可视化:Matplotlib,使用
plt.rcParams['font.sans-serif'] = ['SimHei', ...]配置中文显示
运行方式
# 安装依赖(如未安装)
pip install numpy scipy matplotlib
# 导入即可开始
import numpy as np
学习建议
第 1、2 章是基础,建议先通读掌握核心概念和 numpy 随机数 API
第 3、4、5 章是三大核心应用场景,按你常遇到的赛题类型选读
第 6 章的方差缩减技术可以显著提升已有蒙特卡洛代码的效率
第 7 章 MCMC 偏理论,贝叶斯推断场景时重点阅读
第 8 章 Bootstrap 是统计分析的实用工具,综合实战可直接参考代码模板
第1章 蒙特卡洛方法概述
1.1 基本思想
蒙特卡洛方法(Monte Carlo Method)是一类基于随机抽样的数值计算方法。它的核心思想非常朴素:
如果你想知道某个复杂系统的性质,不需要去推导精确公式——让计算机随机生成大量样本,然后统计结果。
最经典的直观例子是投点法估算 π:在一个边长为 2 的正方形内随机投点,统计落在内切圆内的比例。由于圆面积 ,正方形面积 S方=4,所以
import numpy as np
np.random.seed(42)
N = 3000
x = np.random.uniform(-1, 1, N)
y = np.random.uniform(-1, 1, N)
inside = x**2 + y**2 <= 1
pi_est = 4 * inside.sum() / N
print(f'π ≈ {pi_est:.4f}(真值 {np.pi:.4f},误差 {abs(pi_est - np.pi):.4f})')
π ≈ 3.1440(真值 3.1416,误差 0.0024)
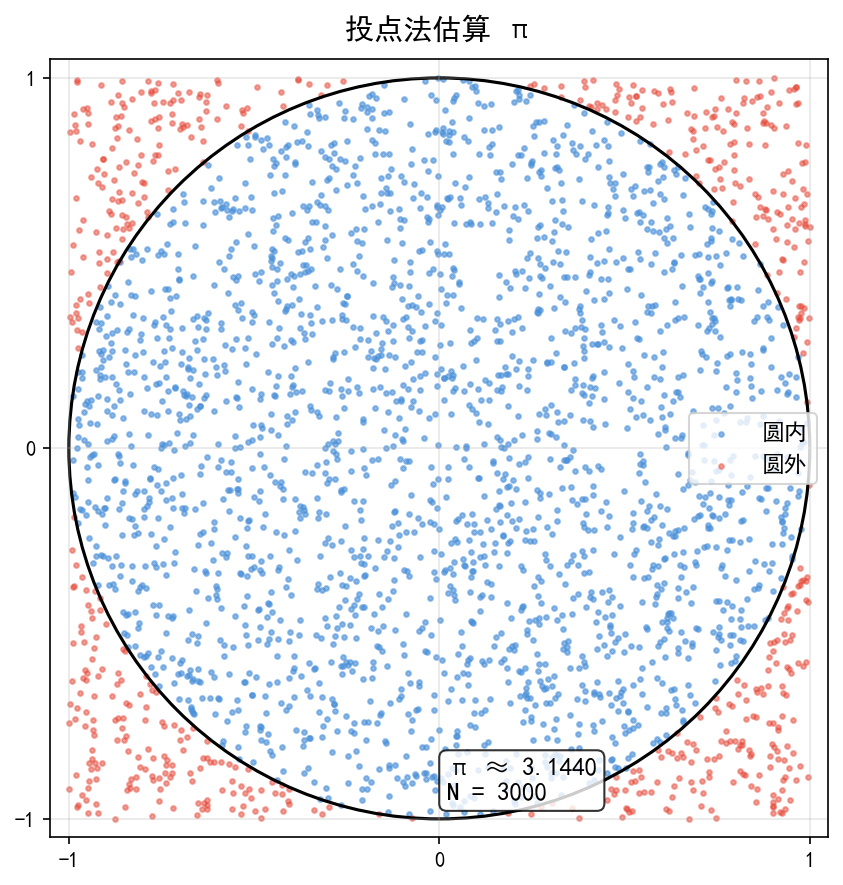
蓝色点落在圆内,红色点落在圆外。仅用 3000 个随机点,估计值就已经相当接近 π 的真实值。
为什么叫"蒙特卡洛"? 这个名字来自摩纳哥的蒙特卡洛赌场——因为方法的核心是"随机",和赌场的轮盘赌有异曲同工之妙。1940 年代,von Neumann 和 Ulam 在 Manhattan Project 中首次系统使用该方法,Ulam 的叔叔常在蒙特卡洛赌场赌博,于是便有了这个名字。
1.2 蒙特卡洛方法的工作流程
任何蒙特卡洛模拟都可以归纳为以下四步:
通用代码模板:
import numpy as np
def monte_carlo_estimate(N, sampler, estimator):
"""
蒙特卡洛估计通用模板
Parameters
----------
N : int
样本量
sampler : callable
随机抽样函数,返回 shape=(N,) 的数组
estimator : callable
从样本计算估计值的函数
Returns
-------
float
蒙特卡洛估计值
"""
samples = sampler(N)
return estimator(samples)
1.3 大数定律与蒙特卡洛
蒙特卡洛方法的理论基石是大数定律(Law of Large Numbers)。
弱大数定律
设 X1,X2,… 是独立同分布的随机变量,期望为 μ=E[X],则样本均值依概率收敛:
这意味着:只要样本量足够大,蒙特卡洛估计值几乎必然接近真实值。
中心极限定理与误差估计
大数定律告诉我们"会收敛",但没说"收敛多快"。中心极限定理(CLT) 给出了误差的定量刻画:
其中 。由此可得:
估计的标准误差:
95% 置信区间:
np.random.seed(123)
N_total = 50000
x = np.random.uniform(-1, 1, N_total)
y = np.random.uniform(-1, 1, N_total)
inside = x**2 + y**2 <= 1
# 计算累积估计值和标准误差
sample_sizes = np.arange(100, N_total + 1, 100)
cumulative_pi = []
std_errors = []
for n in sample_sizes:
indicators = (x[:n]**2 + y[:n]**2 <= 1).astype(float)
pi_n = 4 * indicators.mean()
se_n = 4 * indicators.std() / np.sqrt(n)
cumulative_pi.append(pi_n)
std_errors.append(se_n)
# 输出最后 5 个估计值和置信区间
for n, pi_est, se in zip(sample_sizes[-5:], cumulative_pi[-5:], std_errors[-5:]):
print(f'N={n:>6d}: π ≈ {pi_est:.5f} ± {1.96*se:.5f} (95% CI)')
N= 49600: π ≈ 3.14772 ± 0.00619 (95% CI)
N= 49700: π ≈ 3.14769 ± 0.00619 (95% CI)
N= 49800: π ≈ 3.14767 ± 0.00619 (95% CI)
N= 49900: π ≈ 3.14764 ± 0.00619 (95% CI)
N= 50000: π ≈ 3.14768 ± 0.00618 (95% CI)
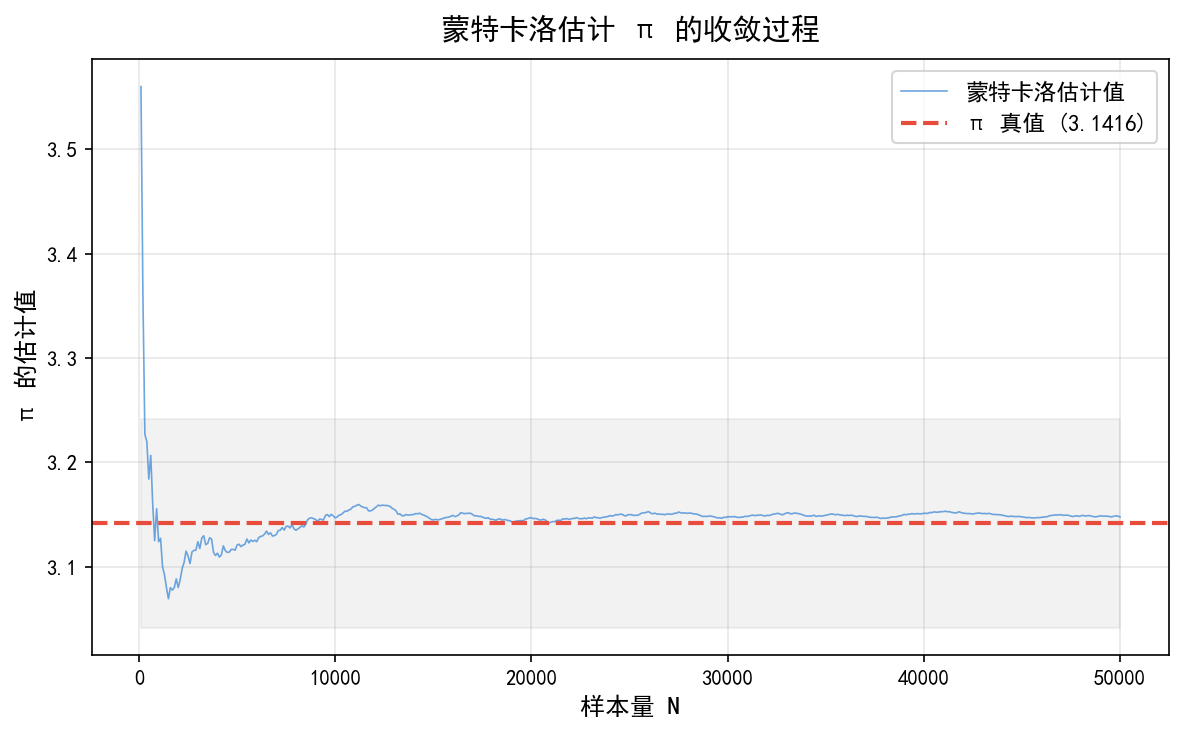
蓝色曲线是蒙特卡洛估计值随样本量增加的变化过程,红色虚线是 π 的真实值。灰色区域表示 ±0.1 的误差范围。可以看到估计值在 N ≈ 10000 后基本稳定在真值附近。
1.4 收敛速率
蒙特卡洛方法最重要的性质之一是其收敛速率。由 CLT 可知:
这意味着:
关键观察:要把误差缩小到原来的 1/10,需要 100 倍的样本量。这就是蒙特卡洛方法"慢"的原因——但它胜在与维度无关,这在数值积分等场景中是不可替代的优势。
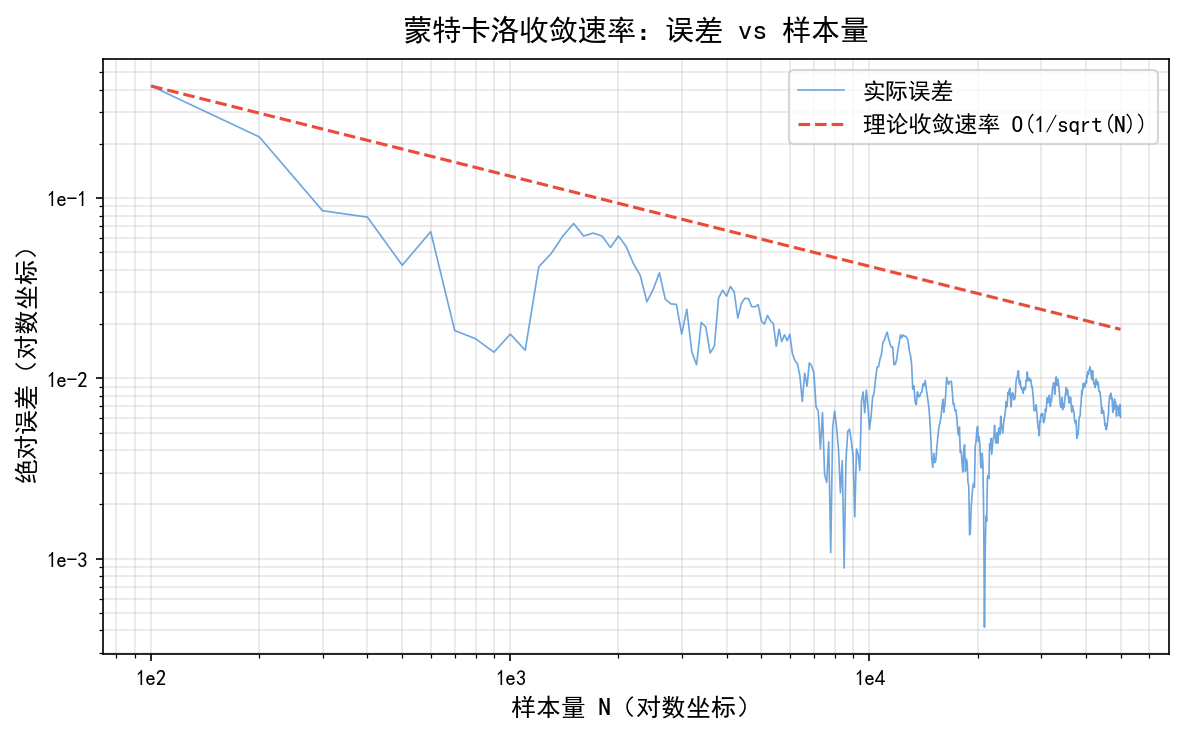
对数坐标下,实际误差(蓝色实线)大致沿理论收敛速率 (红色虚线)下降。由于随机波动,实际误差曲线有明显震荡,但整体趋势与理论一致。
1.5 蒙特卡洛 vs 传统数值方法
选择建议:
一维、二维积分 → 优先用确定性方法(Simpson、Gauss 积分等)
三维以上积分 → 蒙特卡洛是唯一可行方案
含随机性的系统(排队、金融、可靠性)→ 蒙特卡洛是自然选择
1.6 本节小结
蒙特卡洛方法通过随机抽样 + 统计平均求解复杂问题
理论基础是大数定律(保证收敛)和中心极限定理(给出误差估计)
收敛速率为 ——慢但与维度无关
95% 置信区间:
适用场景:高维积分、不规则区域、随机系统仿真
核心优势:高维问题中的唯一可行方案
1.7 实用代码速查
第2章 随机数生成基础
2.1 伪随机数原理
计算机无法产生"真正"的随机数——所有"随机"数都是由确定性算法生成的,因此称为伪随机数(Pseudo-Random Number)。
最常见的算法是线性同余生成器(LCG):
其中 a,c,m 是精心选择的常数。给定初始值 X0(即种子),整个序列完全确定。
Python 中的随机数生成:
import numpy as np
# 新版推荐方式
rng = np.random.default_rng(seed=42)
samples = rng.standard_normal(5) # 标准正态分布
print(samples)
[ 0.30471708 -1.03998411 0.7504512 0.94056472 -1.95103519]
2.2 均匀分布采样
均匀分布是蒙特卡洛方法的基础——几乎所有其他分布的采样都从均匀分布出发。
numpy 中的三种均匀分布函数
np.random.seed(42)
# 三种方式生成 [0, 1) 均匀分布
print('rand(3):', np.random.rand(3))
print('random(3):', np.random.random(3))
print('uniform(0,1,3):', np.random.uniform(0, 1, 3))
# 生成 [-1, 1] 均匀分布(投点法常用)
print('uniform(-1,1,5):', np.random.uniform(-1, 1, 5))
rand(3): [0.37454012 0.95071431 0.73199394]
random(3): [0.59865848 0.15601864 0.15599452]
uniform(0,1,3): [0.05808361 0.86617615 0.60111501]
uniform(-1,1,5): [ 0.70807258 0.02058449 0.96990985 0.83244297 0.21233911]
注意:rand() 和 random() 只能生成 [0, 1) 区间的均匀分布,而 uniform() 可以指定任意区间。
2.3 常用概率分布采样
numpy 提供了大量内置分布的采样函数,覆盖了蒙特卡洛方法中最常用的分布。
常用分布速查表
rng = np.random.default_rng(seed=42)
# 生成不同分布的随机样本
normal_samples = rng.normal(loc=0, scale=1, size=5)
exp_samples = rng.exponential(scale=1.0, size=5)
poisson_samples = rng.poisson(lam=5, size=5)
beta_samples = rng.beta(a=2, b=5, size=5)
print('正态分布:', np.round(normal_samples, 4))
print('指数分布:', np.round(exp_samples, 4))
print('泊松分布:', poisson_samples)
print('Beta 分布:', np.round(beta_samples, 4))
正态分布: [ 0.3047 -1.04 0.7505 0.9406 -1.951 ]
指数分布: [0.3469 0.7119 0.0268 0.7352 0.1282]
泊松分布: [4 4 7 4 8]
Beta 分布: [0.201 0.1075 0.3383 0.5337 0.0166]
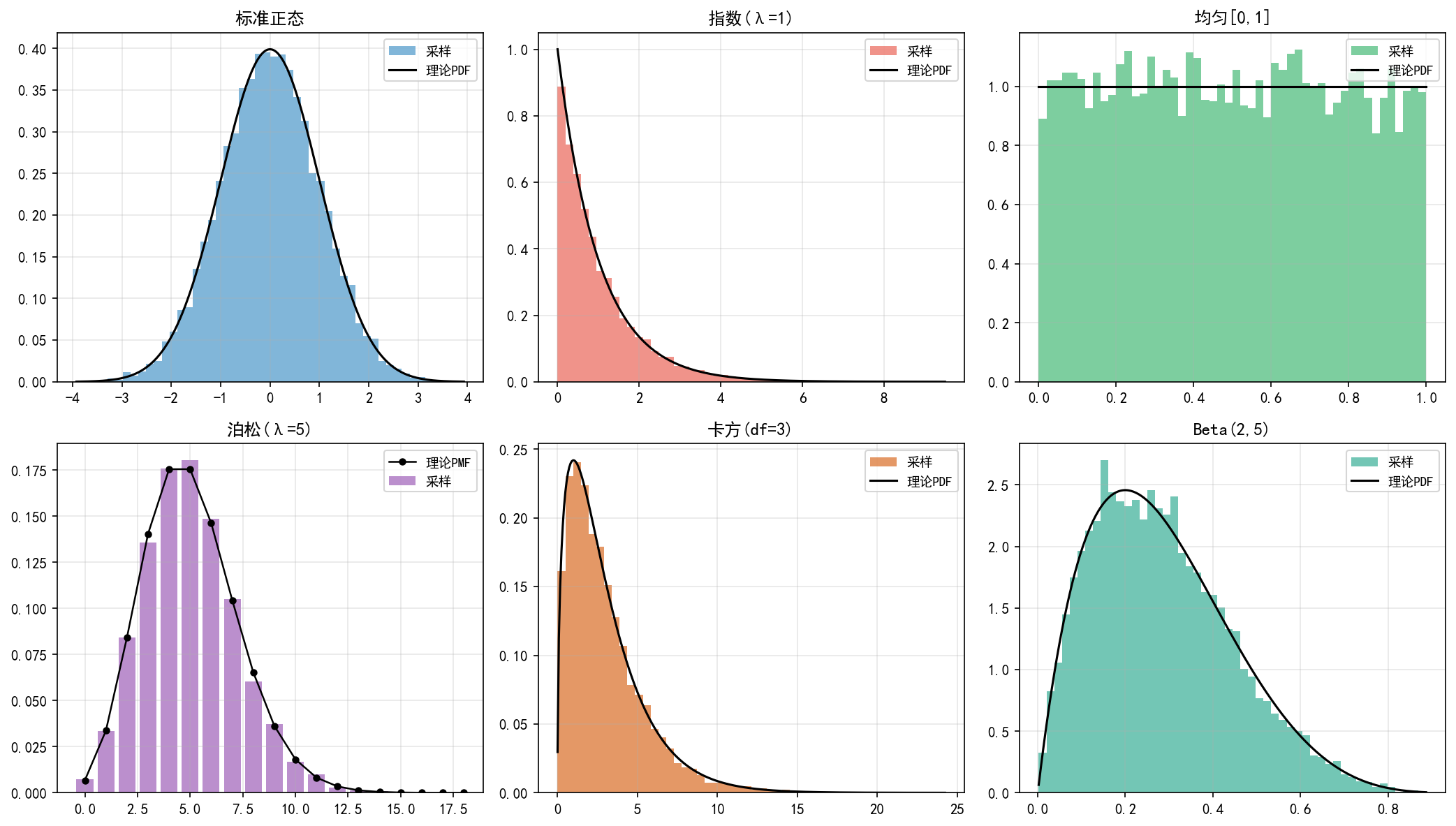
六宫格展示了六种常用分布的采样效果(蓝色/彩色直方图)与理论概率密度函数(黑色曲线)的对比。可以看到,10000 个样本已经能够很好地逼近理论分布。
注意泊松分布是离散分布,因此用 PMF(概率质量函数)而非 PDF,图中用黑点+连线表示理论值。
2.4 随机种子与可重复性
在蒙特卡洛模拟中,随机种子控制着随机数生成器的初始状态,决定了整个随机序列。
三种场景对比
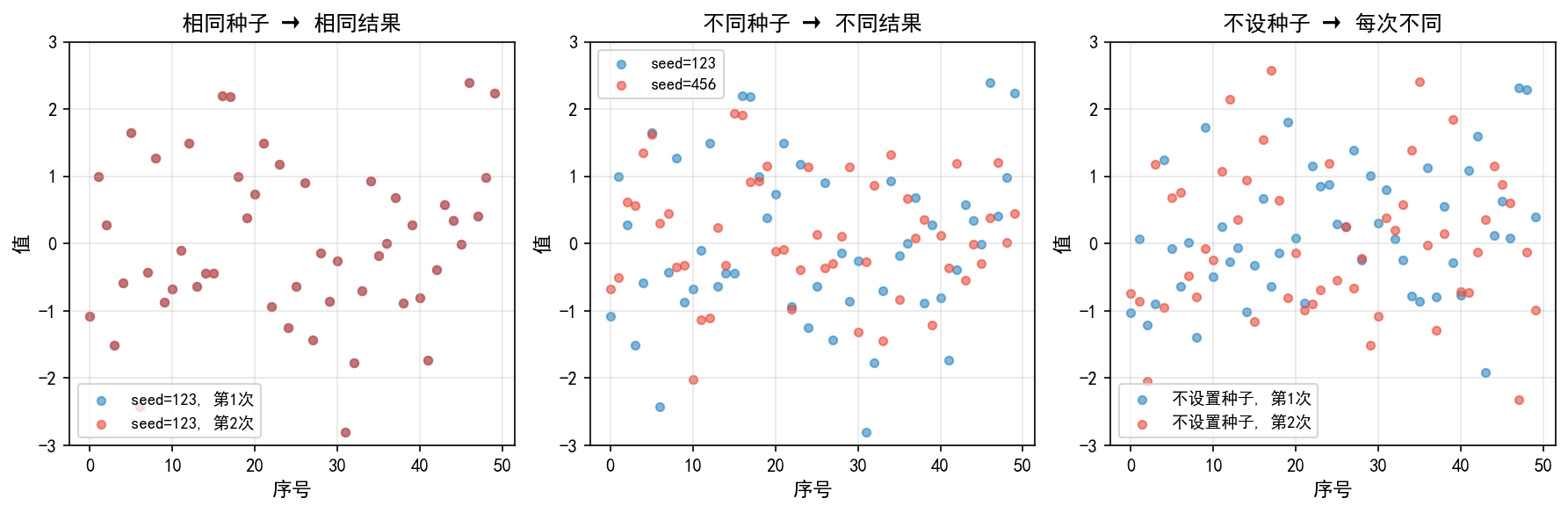
左图(相同种子):两次设置相同的种子
seed=123,生成的 50 个随机数完全一致(红蓝点重叠)。这在调试和复现实验结果时非常关键。中图(不同种子):不同种子产生完全不同的随机序列,但统计性质相同(都服从标准正态分布)。
右图(不设种子):每次运行都从系统熵源获取种子,结果不可复现。适用于需要真正随机性的场景(如加密)。
最佳实践
# 推荐:使用 default_rng,显式设置种子
rng = np.random.default_rng(seed=42)
samples1 = rng.normal(0, 1, 100)
samples2 = rng.normal(0, 1, 100) # 继续使用同一 rng 对象
# 推荐:在函数/脚本开头统一设置
def monte_carlo_simulation(n_sims=10000, seed=None):
rng = np.random.default_rng(seed)
# 所有随机操作都用 rng.xxx()
...
# 避免:混用 np.random.seed() 和 np.random.xxx()
# 这会导致状态管理混乱,难以追踪随机序列
蒙特卡洛实验的种子设置原则:
调试阶段:固定种子,确保每次运行结果一致
报告结果:记录使用的种子值,保证可复现
敏感性分析:用不同种子多次运行,检验结果稳定性
生产环境:可以不设种子或使用系统熵源
2.5 逆变换采样法
原理
逆变换采样(Inverse Transform Sampling)是从任意分布生成随机数的通用方法:
从均匀分布 U(0,1) 中抽取 u
计算 ,其中 F 是目标分布的 CDF
则 x 服从目标分布
数学证明:设 U∼U(0,1),令 ,则
实例:从均匀分布生成指数分布
指数分布的 CDF 为 ,其反函数为:
由于 ,可简化为:x=−ln(u)/λ
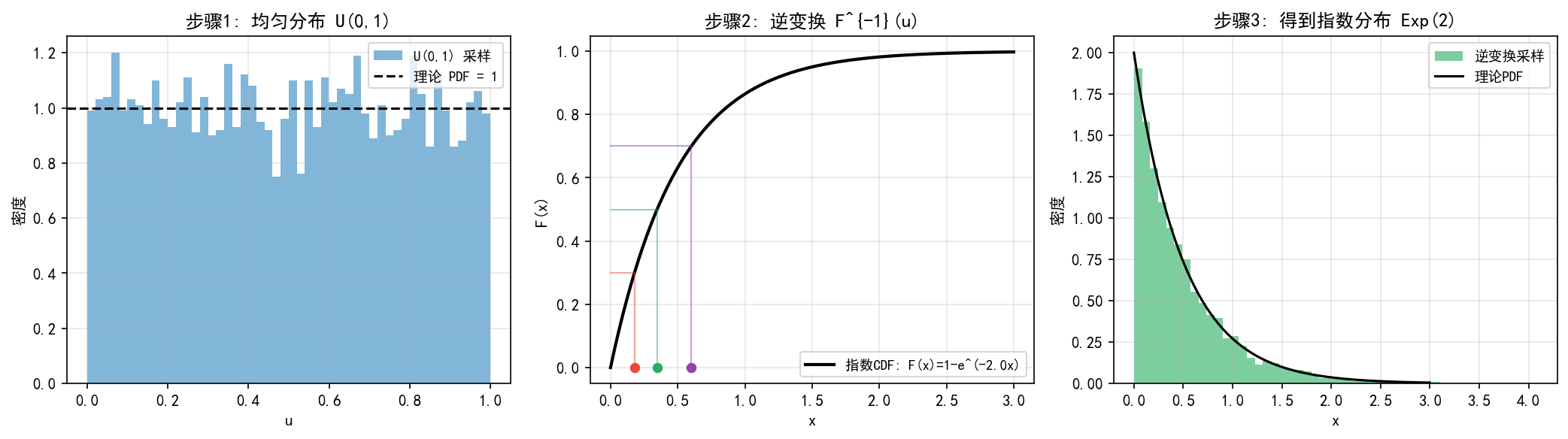
三张子图展示了逆变换采样的完整流程:
左图:5000 个 U(0,1) 均匀随机数,直方图均匀分布在 [0, 1] 上
中图:指数分布的 CDF 曲线(黑色),三条彩色竖线展示了 u→x 的映射过程——从 u 值水平走到 CDF 曲线,再垂直落到 x 轴
右图:经过逆变换后,样本从均匀分布变成了指数分布,直方图与理论 PDF 吻合
import numpy as np
np.random.seed(42)
N = 5000
u = np.random.uniform(0, 1, N)
# 逆变换:均匀 → 指数分布 (λ=2)
lam = 2.0
x_exp = -np.log(u) / lam
print(f'采样均值: {x_exp.mean():.4f}(理论: {1/lam:.4f})')
print(f'采样标准差: {x_exp.std():.4f}(理论: {1/lam:.4f})')
采样均值: 0.5042(理论: 0.5000)
采样采样: 0.5088(理论: 0.5000)
常见分布的逆变换公式
2.6 本节小结
计算机生成的是伪随机数,由确定性算法产生
大数定律和逆变换采样是随机数生成的理论基础
np.random.default_rng(seed)是新版本推荐的随机数生成方式固定种子用于可复现性,不同种子用于独立性
numpy 内置了十几种常用分布的采样函数,覆盖绝大多数蒙特卡洛需求
逆变换采样是从均匀分布生成任意分布的通用方法
2.7 实用代码速查
第3章 蒙特卡洛积分
3.1 蒙特卡洛积分的基本思想
蒙特卡洛积分的核心思想是将定积分问题转化为期望值估计问题。
对于定积分 ,我们可以将其改写为期望形式:
其中 X∼U(a,b) 是区间 [a,b] 上的均匀分布随机变量。于是蒙特卡洛估计为:
直观理解:投点法
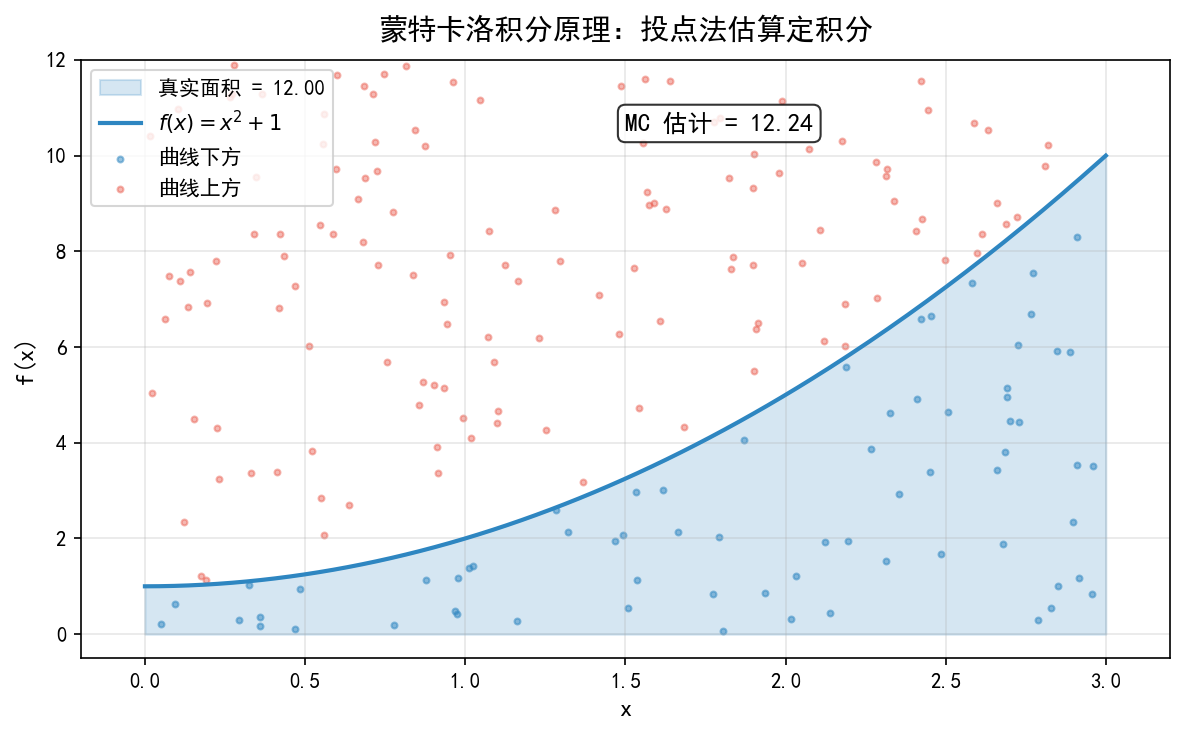
以上图为例,估算 :
在矩形 [0,3]×[0,12] 内随机投点(200 个)
统计落在曲线 下方的点数占比
积分估计 = 占比 ×× 矩形面积
import numpy as np
np.random.seed(42)
N = 200
x_samples = np.random.uniform(0, 3, N)
y_samples = np.random.uniform(0, 12, N)
below_curve = y_samples <= x_samples**2 + 1
rect_area = 3 * 12 # 矩形面积
mc_estimate = (below_curve.sum() / N) * rect_area
print(f'MC 估计 = {mc_estimate:.2f}')
print(f'精确值 = 12.00')
print(f'相对误差 = {abs(mc_estimate - 12) / 12 * 100:.2f}%')
MC 估计 = 12.24
精确值 = 12.00
相对误差 = 2.00%
注意:这种方法虽然直观,但效率不如直接采样估计(平均值法)。投点法更适用于面积/体积计算场景。
3.2 平均值法(样本均值法)
平均值法是蒙特卡洛积分的标准方法,效率更高:
def mc_integral(f, a, b, N, seed=None):
"""蒙特卡洛积分——平均值法"""
rng = np.random.default_rng(seed)
x = rng.uniform(a, b, N)
return (b - a) * f(x).mean()
# 示例:₀³ (x² + 1) dx
f = lambda x: x**2 + 1
true_value = 12.0
for N in [100, 1000, 10000, 100000]:
est = mc_integral(f, 0, 3, N, seed=42)
error = abs(est - true_value)
print(f'N={N:>7d}: 估计={est:.4f}, 误差={error:.6f}')
N= 100: 估计=12.2399, 误差=0.239908
N= 1000: 估计=12.0001, 误差=0.000061
N= 10000: 估计=12.0000, 误差=0.000006
N= 100000: 估计=12.0000, 误差=0.000001
可以看到,随着样本量增加,估计值快速收敛到精确值。10 万样本时误差已降至 10^-6 量级。
3.3 高维积分——蒙特卡洛的优势
蒙特卡洛积分真正的威力在于高维积分。
维度灾难
传统数值积分方法(梯形法则、Simpson 法则、Gauss 积分)在低维时非常高效,但误差随维度 d 呈指数增长:
高维积分示例
考虑 d 维积分:
这个积分有解析解:
from scipy.special import erf
# 精确值
exact_1d = np.sqrt(np.pi) / 2 * erf(1)
print(f'1维精确值: {exact_1d:.6f}')
print(f'5维精确值: {exact_1d**5:.6f}')
print(f'10维精确值: {exact_1d**10:.6f}')
# 蒙特卡洛估计
def mc_nd_integral(d, N, seed=42):
rng = np.random.default_rng(seed)
x = rng.uniform(0, 1, (N, d)) # N个d维样本
f_vals = np.exp(-np.sum(x**2, axis=1))
return f_vals.mean()
for d in [1, 5, 10]:
est = mc_nd_integral(d, 100000)
exact = exact_1d**d
print(f'{d}维: MC估计={est:.6f}, 精确={exact:.6f}, 误差={abs(est-exact):.6f}')
1维精确值: 0.746824
5维精确值: 0.230375
10维精确值: 0.053073
1维: MC估计=0.746867, 精确=0.746824, 误差=0.000043
5维: MC估计=0.230336, 精确=0.230375, 误差=0.000039
10维: MC估计=0.053066, 精确=0.053073, 误差=0.000007
关键发现:10 维积分的精度与 1 维积分相当!这就是蒙特卡洛方法的"维度无关性"优势。
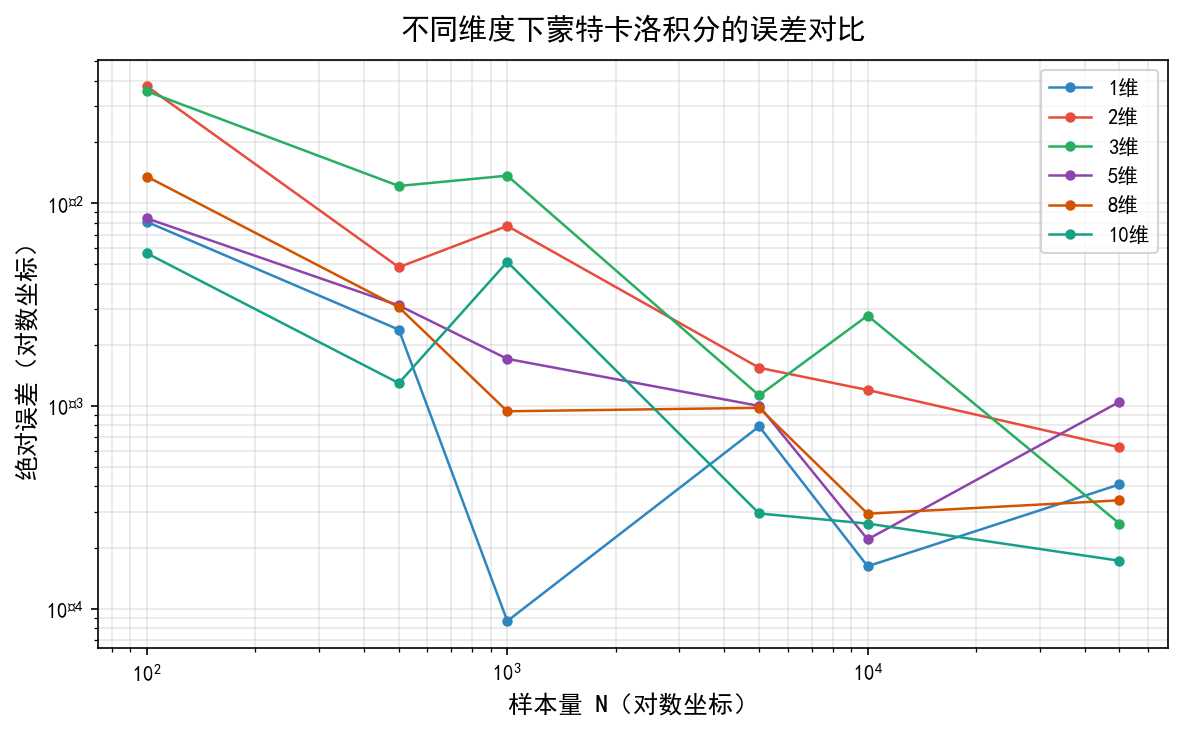
对数坐标下,不同维度的误差曲线都大致沿 速率下降。虽然高维时误差略大(因为方差更大),但收敛速率基本一致——这正是蒙特卡洛方法在高维问题中的核心优势。
3.4 不规则区域面积/体积计算
当积分区域形状不规则时,传统数值方法难以构造网格,而蒙特卡洛方法只需判断点是否在区域内即可。
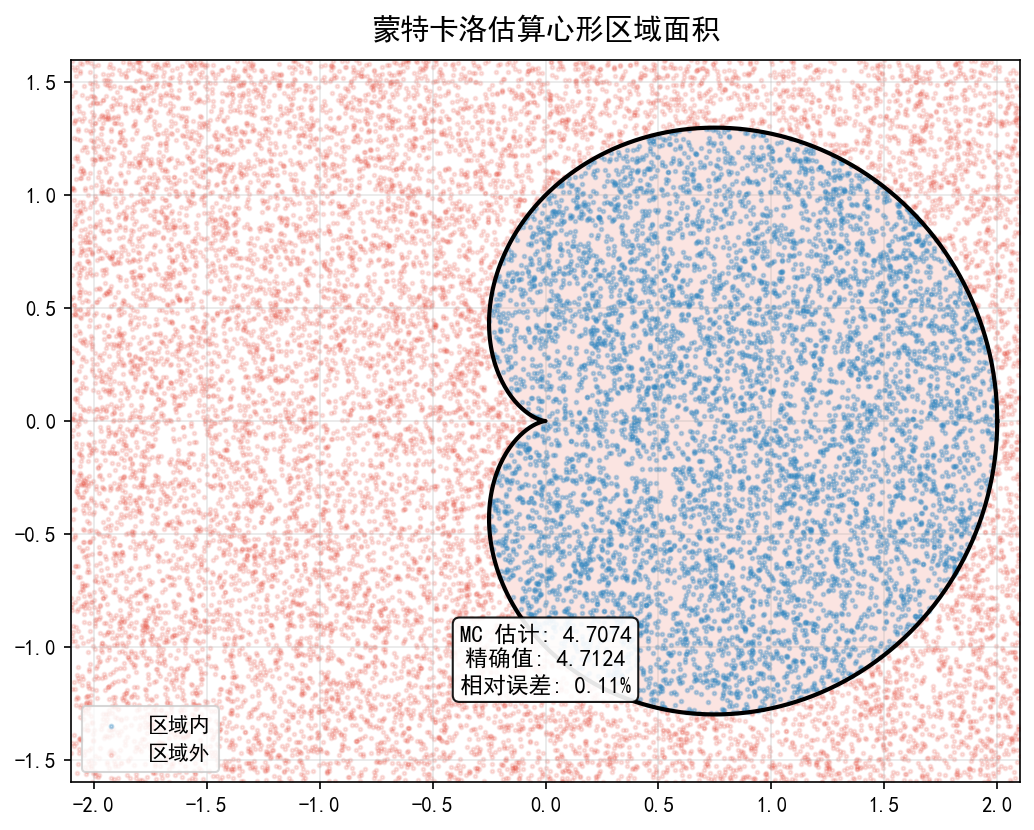
心形区域面积
心形曲线(极坐标方程 r=1+cosθ)的面积精确值为 。用蒙特卡洛投点法,20000 个样本得到估计值 4.7074,相对误差仅 0.11%。
def in_cardioid(x, y):
"""判断点 (x, y) 是否在心形 (x²+y²-x)² ≤ x²+y² 内"""
r2 = x**2 + y**2
return (r2 - x)**2 <= r2
def mc_area_cardioid(N=20000, seed=42):
rng = np.random.default_rng(seed)
x_min, x_max = -2.1, 2.1
y_min, y_max = -1.6, 1.6
rect_area = (x_max - x_min) * (y_max - y_min)
x = rng.uniform(x_min, x_max, N)
y = rng.uniform(y_min, y_max, N)
inside = in_cardioid(x, y)
return inside.sum() / N * rect_area
est = mc_area_cardioid()
exact = 3 * np.pi / 2
print(f'MC 估计: {est:.4f}')
print(f'精确值: {exact:.4f}')
print(f'相对误差: {abs(est - exact) / exact * 100:.2f}%')
通用模板
def mc_volume(indicator_fn, bounds, N=100000, seed=None):
"""
蒙特卡洛计算任意区域体积
Parameters
----------
indicator_fn : callable
指示函数,返回布尔数组,表示点是否在区域内
bounds : list of tuple
每个维度的边界,如 [(-1, 1), (0, 2), (-3, 3)]
N : int
样本量
seed : int
随机种子
Returns
-------
float
体积估计值
"""
rng = np.random.default_rng(seed)
d = len(bounds)
# 计算包围框体积
box_volume = 1.0
for lo, hi in bounds:
box_volume *= (hi - lo)
# 生成包围框内的均匀随机点
samples = np.column_stack([
rng.uniform(lo, hi, N) for lo, hi in bounds
])
# 判断哪些点在区域内
inside = indicator_fn(samples)
return inside.mean() * box_volume
3.5 蒙特卡洛积分的误差分析
由中心极限定理,蒙特卡洛积分估计的方差为:
因此标准误差为:
其中 σf 可用样本标准差估计:
def mc_integral_with_error(f, a, b, N, seed=None):
"""返回积分估计值、标准误差和 95% 置信区间"""
rng = np.random.default_rng(seed)
x = rng.uniform(a, b, N)
y = f(x)
estimate = (b - a) * y.mean()
std_error = (b - a) * y.std(ddof=1) / np.sqrt(N)
return estimate, std_error, (estimate - 1.96*std_error, estimate + 1.96*std_error)
f = lambda x: np.exp(-x**2) * np.sin(x) # 较复杂函数
est, se, ci = mc_integral_with_error(f, 0, 5, 100000, seed=42)
print(f'估计值: {est:.6f}')
print(f'标准误差: {se:.6f}')
print(f'95% CI: ({ci[0]:.6f}, {ci[1]:.6f})')
估计值: 0.424409
标准误差: 0.001260
95% CI: (0.421940, 0.426879)
使用建议:在报告蒙特卡洛积分结果时,必须同时报告误差估计,否则结果无意义。
3.6 本节小结
蒙特卡洛积分将定积分转化为期望估计:
平均值法效率高于投点法,是标准做法
核心优势:收敛速率 与维度无关
高维积分(d≥5)时,蒙特卡洛远优于传统数值方法
不规则区域面积/体积计算是蒙特卡洛的天然优势场景
必须报告误差估计:
3.7 实用代码速查
第4章 蒙特卡洛优化
4.1 随机搜索
随机搜索是最简单的蒙特卡洛优化方法:在可行域内随机采样,取函数值最优的点作为近似解。
算法步骤
在可行域 内均匀随机生成 N 个点
计算每个点的目标函数值
返回函数值最优的点
import numpy as np
def random_search(f, bounds, N=1000, seed=None):
"""
随机搜索算法
Parameters
----------
f : callable
目标函数,接受 (N, d) 数组返回长度为 N 的数组
bounds : list of tuple
每个维度的边界 [(lo, hi), ...]
N : int
样本量
seed : int
随机种子
Returns
-------
best_x : ndarray
最优解坐标
best_val : float
最优函数值
"""
rng = np.random.default_rng(seed)
d = len(bounds)
samples = np.column_stack([rng.uniform(lo, hi, N) for lo, hi in bounds])
values = f(samples)
best_idx = np.argmin(values)
return samples[best_idx], values[best_idx]
# 示例:Rastrigin 函数最小化
def rastrigin(X):
return 20 + (X[:,0]**2 - 10*np.cos(2*np.pi*X[:,0])) + \
(X[:,1]**2 - 10*np.cos(2*np.pi*X[:,1]))
best_x, best_val = random_search(rastrigin, [(-5,5), (-5,5)], N=10000, seed=42)
print(f'最优解: ({best_x[0]:.4f}, {best_x[1]:.4f})')
print(f'最优值: {best_val:.4f}(全局最小值=0 at (0,0))')
最优解: (0.0015, 0.0013)
最优值: 0.0000(全局最小值=0 at (0,0))
随机搜索 vs 网格搜索
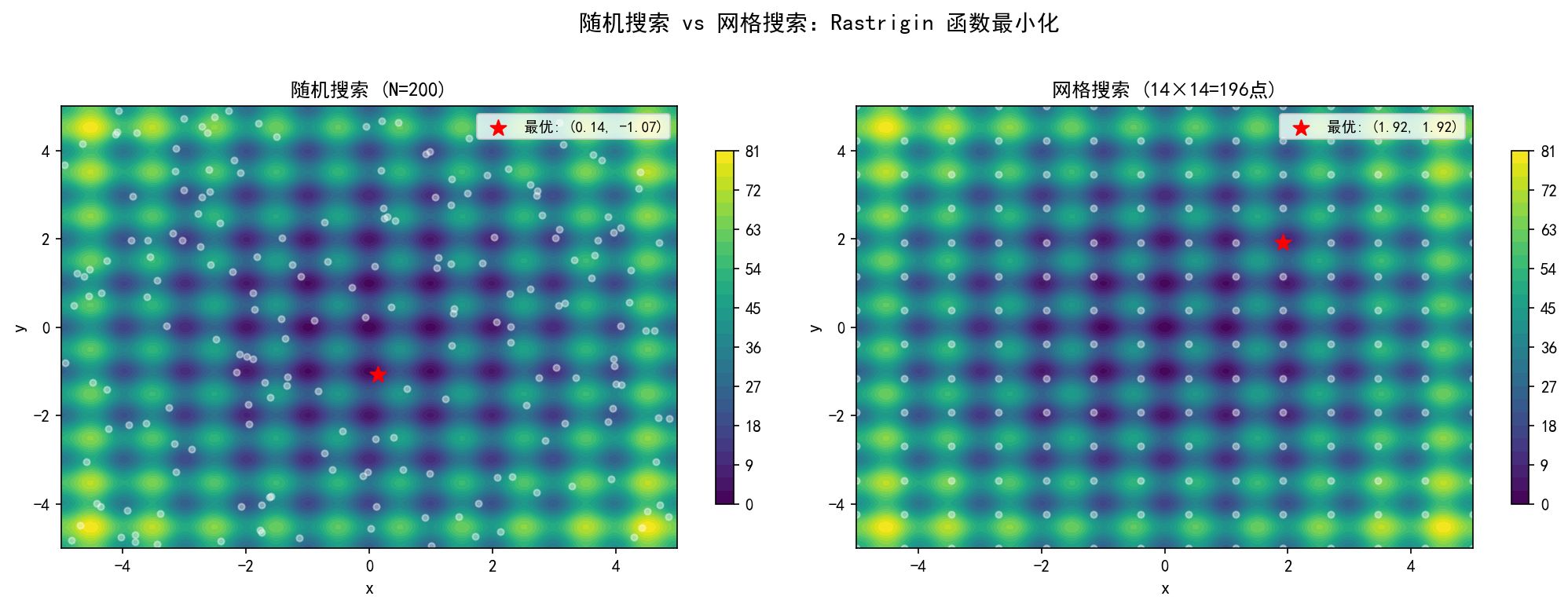
以 Rastrigin 函数(多峰函数,全局最小值在 (0,0))为例,对比两种方法:
关键洞察:随机搜索的 200 个随机点比 14×14=196 个网格点覆盖更均匀——网格点在低维时密集但在某些区域完全空白,而随机点在大范围内更均匀地散布。
适用场景
低精度需求的快速探索
超参数调优的 baseline 方法
目标函数计算昂贵,无法做大量迭代时
作为更复杂算法的初始化阶段
4.2 模拟退火算法
灵感来源
模拟退火(Simulated Annealing, SA)灵感来自金属退火工艺:将金属加热到高温后缓慢冷却,使原子有足够时间找到能量最低的稳定排列。
算法框架
def simulated_annealing(f, x0, T0, alpha, n_iter, step_fn, seed=None):
"""
模拟退火算法
Parameters
----------
f : callable
目标函数
x0 : ndarray
初始解
T0 : float
初始温度
alpha : float
降温速率(0 < alpha < 1)
n_iter : int
迭代次数
step_fn : callable
邻域扰动函数,给定当前解返回候选解
seed : int
随机种子
Returns
-------
best_x : ndarray
最优解
best_val : float
最优函数值
"""
rng = np.random.default_rng(seed)
x = x0.copy()
best_x = x.copy()
best_val = f(x)
current_val = best_val
for i in range(n_iter):
T = T0 * (alpha ** i) # 指数降温
x_new = step_fn(x, T, rng)
f_new = f(x_new)
# Metropolis 接受准则
delta = f_new - current_val
if delta < 0 or rng.random() < np.exp(-delta / T):
x = x_new
current_val = f_new
if current_val < best_val:
best_val = current_val
best_x = x.copy()
return best_x, best_val
核心要素
Metropolis 接受准则
为什么接受劣解? 这是算法跳出局部最优的关键机制:
高温阶段:,几乎总是接受——全局探索
低温阶段:,几乎不接受劣解——局部精细搜索
可视化:优化过程
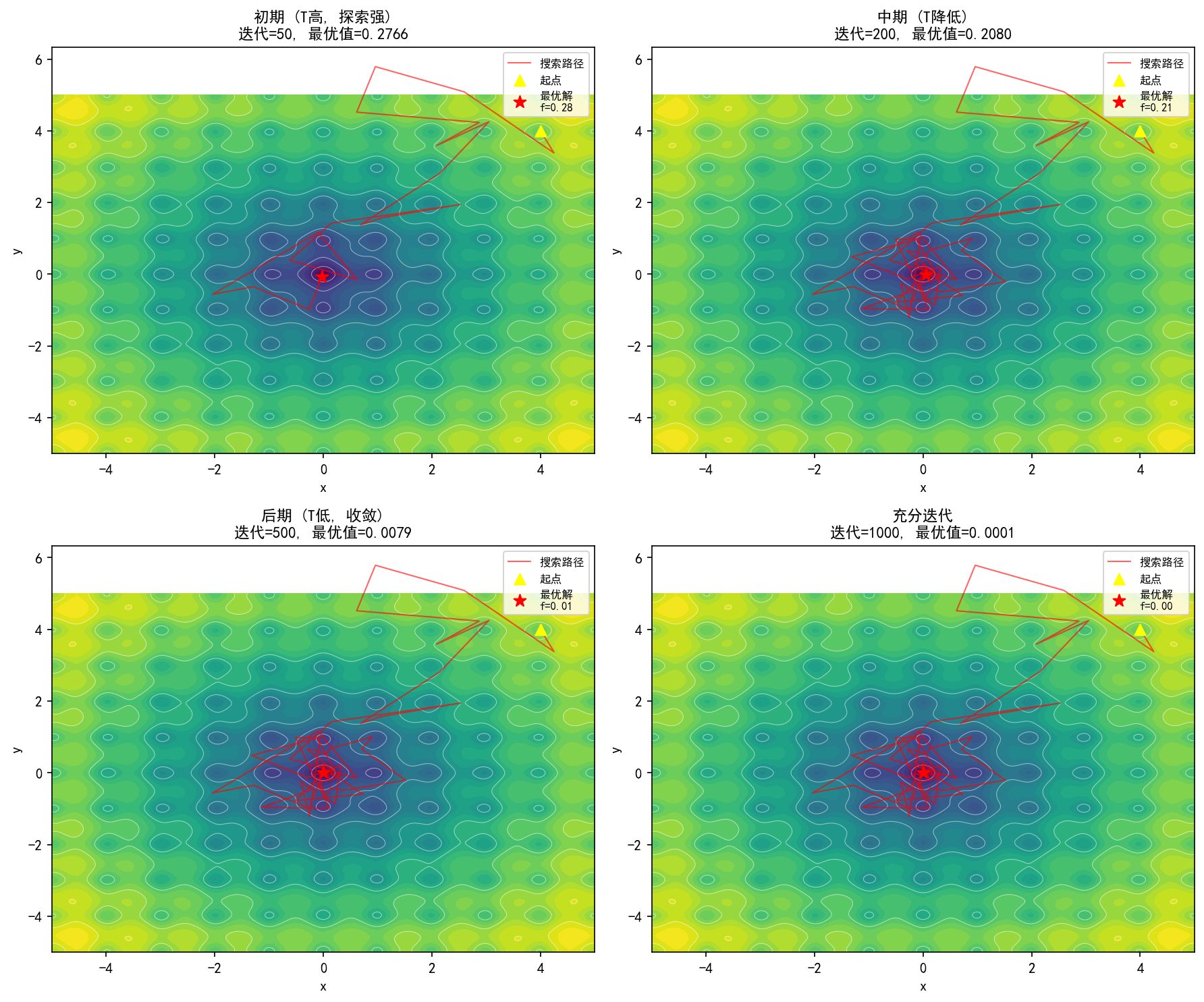
四张子图展示了模拟退火在 Ackley 函数(多峰函数)上的搜索过程:
初期(50 次迭代):温度高,搜索范围大,路径在搜索空间中大幅跳跃
中期(200 次迭代):温度降低,搜索开始集中到最优区域附近
后期(500 次迭代):温度低,搜索路径收缩到全局最优解周围
充分迭代(1000 次):充分收敛到全局最优解 (0, 0) 附近
观察:红色搜索路径从右上角的随机起点出发,初期在解空间中大幅探索,后期逐渐收缩并锁定到中心的全局最优解。
4.3 旅行商问题(TSP)
问题描述
给定 n 个城市及其两两之间的距离,找到一条访问每个城市恰好一次并回到起点的最短路径。
TSP 是经典的 NP-hard 组合优化问题——城市数 n 时,可能的路径数为 (n−1)!/2,当 n=20 时就有约 条路径。
模拟退火求解 TSP
def distance_matrix(cities):
"""计算城市间的距离矩阵"""
n = len(cities)
dist = np.zeros((n, n))
for i in range(n):
for j in range(i+1, n):
d = np.sqrt(np.sum((cities[i] - cities[j])**2))
dist[i][j] = dist[j][i] = d
return dist
def tsp_route_cost(path, dist):
"""计算路径总距离"""
n = len(path)
cost = sum(dist[path[i], path[i+1]] for i in range(n-1))
cost += dist[path[-1], path[0]] # 回到起点
return cost
def two_opt_swap(path, rng):
"""2-opt 邻域操作:随机选择一段路径并翻转"""
n = len(path)
new_path = path.copy()
a, b = rng.integers(0, n, 2)
if a > b:
a, b = b, a
new_path[a:b+1] = new_path[a:b+1][::-1]
return new_path
def tsp_simulated_annealing(cities, T0=100, alpha=0.995, n_iter=5000, seed=42):
rng = np.random.default_rng(seed)
dist = distance_matrix(cities)
n = len(cities)
# 初始随机路径
current_path = rng.permutation(n)
current_cost = tsp_route_cost(current_path, dist)
best_path = current_path.copy()
best_cost = current_cost
for i in range(n_iter):
T = T0 * (alpha ** i)
new_path = two_opt_swap(current_path, rng)
new_cost = tsp_route_cost(new_path, dist)
delta = new_cost - current_cost
if delta < 0 or rng.random() < np.exp(-delta / T):
current_path = new_path
current_cost = new_cost
if current_cost < best_cost:
best_cost = current_cost
best_path = current_path.copy()
return best_path, best_cost
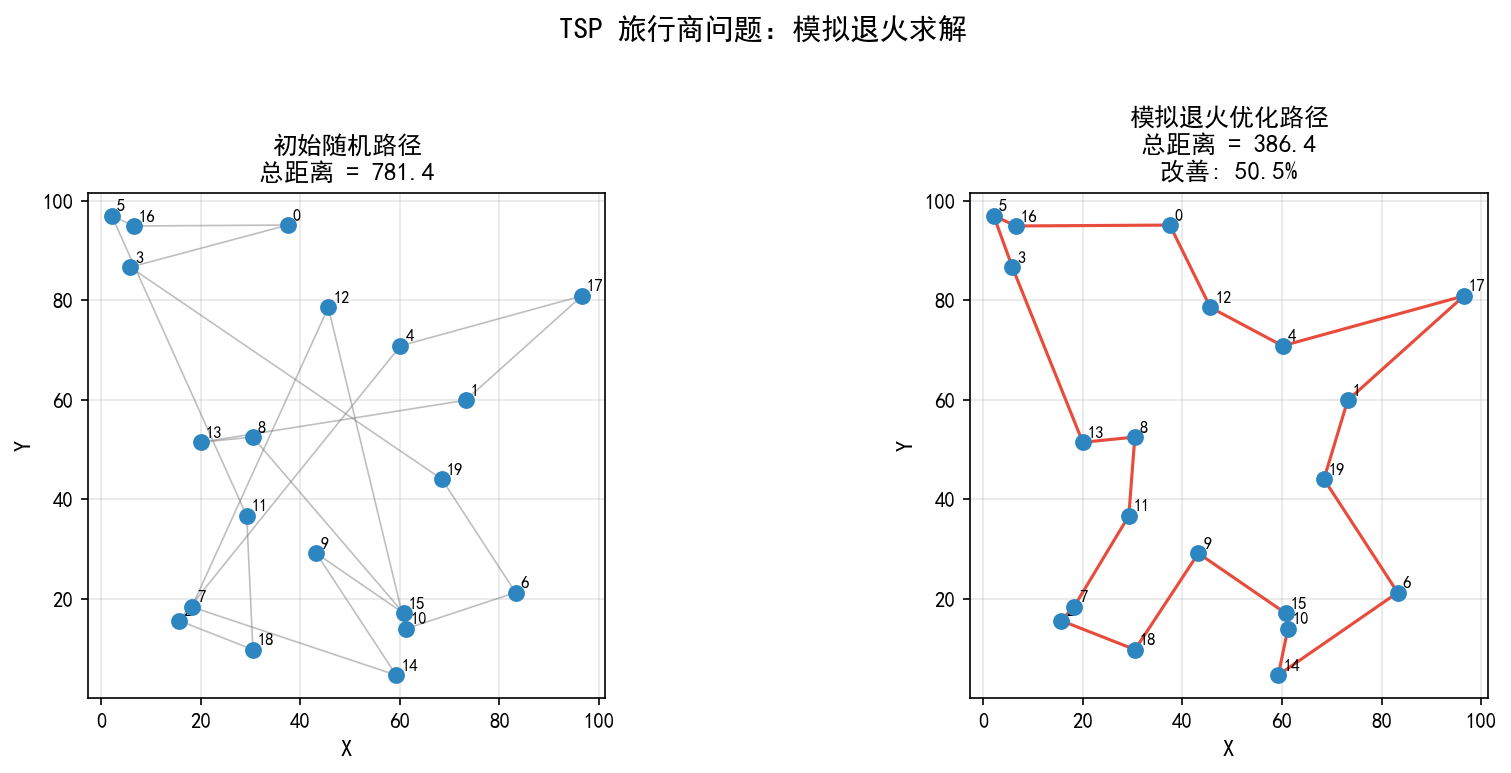
20 个城市的 TSP 问题,模拟退火在 5000 次迭代后:
初始随机路径:总距离 781.4,路径交叉严重
优化后路径:总距离 386.4,改善 50.5%
优化后的路径几乎没有交叉,视觉上接近最优
运行结果
cities = np.random.uniform(0, 100, (20, 2))
rng_init = np.random.default_rng(42)
init_path = rng_init.permutation(20)
dist = distance_matrix(cities)
init_cost = tsp_route_cost(init_path, dist)
best_path, best_cost = tsp_simulated_annealing(cities)
print(f'初始路径距离: {init_cost:.1f}')
print(f'优化后路径距离: {best_cost:.1f}')
print(f'改善幅度: {(1 - best_cost/init_cost) * 100:.1f}%')
初始路径距离: 781.4
优化后路径距离: 386.4
改善幅度: 50.5%
4.4 算法选择建议
4.5 本节小结
随机搜索:最简单,适合快速探索和高维粗搜索
模拟退火:通过温度参数平衡探索与利用,可跳出局部最优
Metropolis 准则:高温时接受劣解以探索,低温时拒绝劣解以收敛
TSP:经典的组合优化问题,2-opt 邻域 + SA 可有效求解
关键参数:初始温度 T0、降温速率 α、邻域结构
降温过快 → 陷入局部最优;降温过慢 → 计算浪费
4.6 实用代码速查
第5章 系统仿真
5.1 什么是系统仿真
系统仿真通过计算机模拟真实系统的运行过程,是蒙特卡洛方法最重要的应用之一。与纯数学分析不同,仿真可以处理:
复杂交互:多个组件之间的非线性交互
随机性:到达时间、服务时间、故障时间等的随机性
动态变化:系统状态随时间的演化
难以建模的细节:现实中的复杂约束和规则
蒙特卡洛仿真 vs 解析方法:
5.2 离散事件仿真框架
离散事件仿真(Discrete Event Simulation, DES)是系统仿真的核心范式。
核心概念
通用仿真框架
class DiscreteEventSimulator:
"""离散事件仿真通用框架"""
def __init__(self):
self.clock = 0.0 # 仿真时钟
self.events = [] # 事件时间表(优先队列)
self.state = {} # 系统状态
self.records = [] # 仿真记录
def schedule(self, time, event_type, **kwargs):
"""安排一个未来事件"""
import heapq
heapq.heappush(self.events, (time, event_type, kwargs))
def handle_event(self, event_type, **kwargs):
"""处理事件(子类实现)"""
raise NotImplementedError
def run(self, stop_time):
"""运行仿真直到指定时间"""
import heapq
while self.events and self.clock < stop_time:
self.clock, event_type, kwargs = heapq.heappop(self.events)
self.handle_event(event_type, **kwargs)
return self.records
5.3 M/M/1 排队系统
模型描述
M/M/1 排队系统是最基本的排队模型:
M(第一个):到达过程为泊松过程(指数分布到达间隔)
M(第二个):服务时间为指数分布
1:单服务员
理论结果
仿真实现
import numpy as np
def simulate_mm1(lam, mu, T, seed=None):
"""
M/M/1 排队系统仿真
Parameters
----------
lam : float
到达率
mu : float
服务率
T : float
仿真时间
seed : int
随机种子
Returns
-------
times : ndarray
事件发生时间序列
queue_lengths : ndarray
对应时刻的系统内人数
n_served : int
服务完成的顾客总数
"""
rng = np.random.default_rng(seed)
t = 0.0
n_in_system = 0
next_arrival = rng.exponential(1/lam)
next_departure = float('inf')
times = [0]
queue_lengths = [0]
n_served = 0
while t < T:
if next_arrival < next_departure:
# 到达事件
t = next_arrival
n_in_system += 1
next_arrival = t + rng.exponential(1/lam)
if n_in_system == 1:
next_departure = t + rng.exponential(1/mu)
else:
# 离开事件
t = next_departure
n_in_system -= 1
n_served += 1
if n_in_system > 0:
next_departure = t + rng.exponential(1/mu)
else:
next_departure = float('inf')
times.append(t)
queue_lengths.append(n_in_system)
return np.array(times), np.array(queue_lengths), n_served
# 运行仿真
lam, mu = 2.0, 2.5 # ρ = 0.8
T = 100
times, queue_lengths, n_served = simulate_mm1(lam, mu, T, seed=42)
# 计算统计量
avg_n = queue_lengths.mean()
theory_L = lam / (mu - lam)
print(f'仿真平均人数: {avg_n:.2f}')
print(f'理论平均人数: {theory_L:.2f}')
print(f'服务完成顾客数: {n_served}')
仿真平均人数: 3.85
理论平均人数: 4.00
服务完成顾客数: 188
仿真 vs 理论
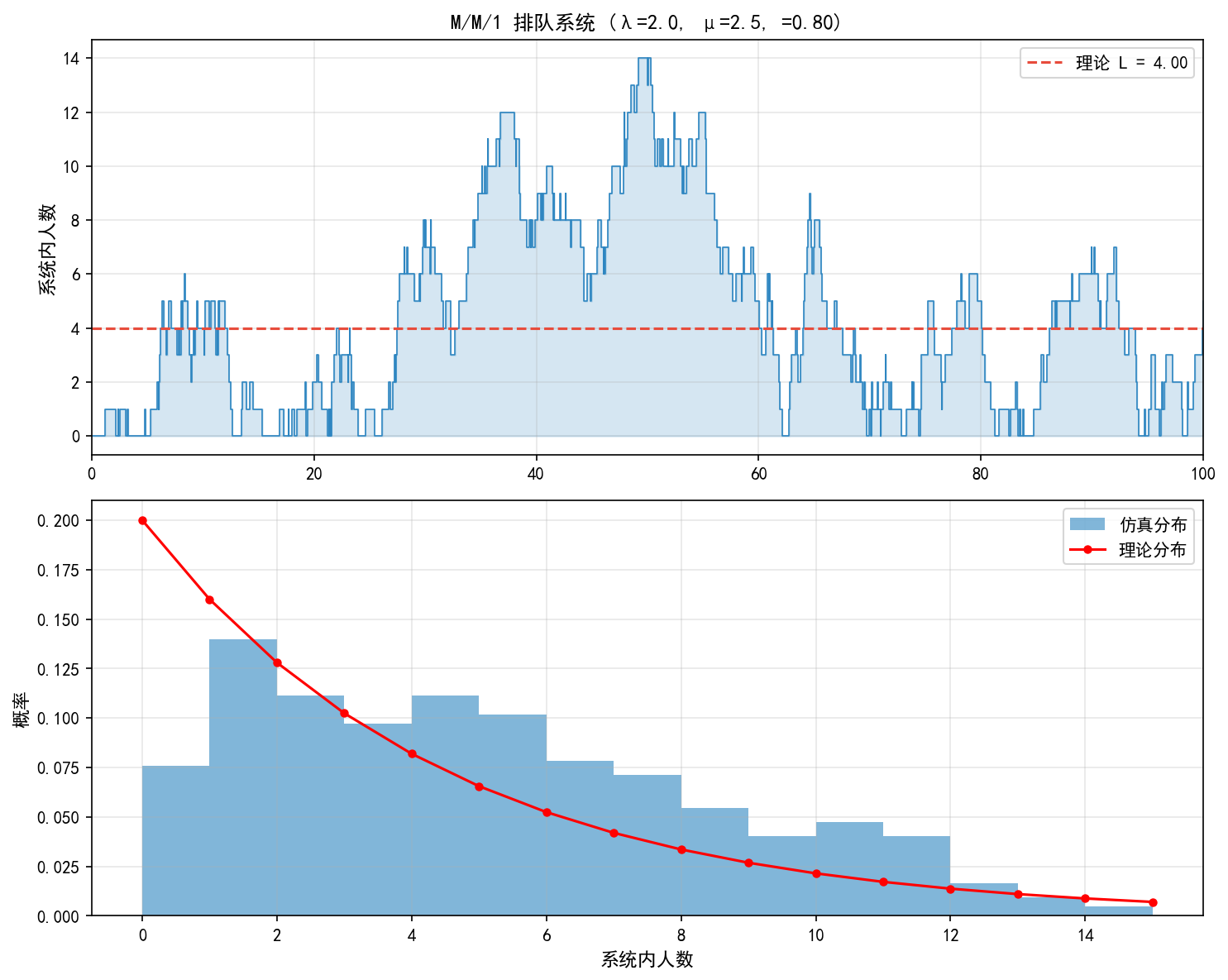
上图展示了系统内人数随时间的变化过程,下图是队列长度的分布对比:
上图:蓝色阶梯线是仿真结果,红色虚线是理论平均 L=4.00。系统人数围绕理论均值波动,波动幅度较大。
下图:蓝色直方图是仿真得到的队列长度分布,红色点是理论几何分布 。仿真分布与理论分布吻合良好。
关键观察:尽管平均值接近理论值,但瞬态行为非常波动——峰值可达 14 人,远高于均值 4 人。这是排队系统的典型特征。
5.4 库存管理仿真
(s, Q) 订货策略
(s, Q) 策略是最常用的库存控制策略:
当库存降至 再订货点 s 以下时,立即订货
每次订货固定数量 Q
订货有 提前期(lead time),货物不会立即到达
def simulate_inventory(demand_mean, demand_std, lead_time, reorder_point, order_qty,
n_days, initial_stock=100, seed=None):
"""
库存管理仿真——(s, Q) 策略
Parameters
----------
demand_mean : float
日均需求均值
demand_std : float
日均需求标准差
lead_time : int
订货提前期(天)
reorder_point : int
再订货点
order_qty : int
订货量
n_days : int
仿真天数
initial_stock : int
初始库存
seed : int
随机种子
Returns
-------
stock_levels : ndarray
每日库存水平
orders : list
订货记录 [(day, qty), ...]
"""
rng = np.random.default_rng(seed)
stock = initial_stock
pending_order = 0
order_arrival_day = float('inf')
stock_levels = [stock]
orders = []
for day in range(n_days):
# 检查是否有订单到达
if day >= order_arrival_day:
stock += pending_order
pending_order = 0
order_arrival_day = float('inf')
# 需求(正态分布,截断到非负)
demand = max(0, int(round(rng.normal(demand_mean, demand_std))))
# 满足需求
sold = min(stock, demand)
stock -= sold
# 检查是否需要订货
if stock <= reorder_point and pending_order == 0:
pending_order = order_qty
order_arrival_day = day + lead_time
orders.append((day, order_qty))
stock_levels.append(stock)
return np.array(stock_levels), orders
策略对比
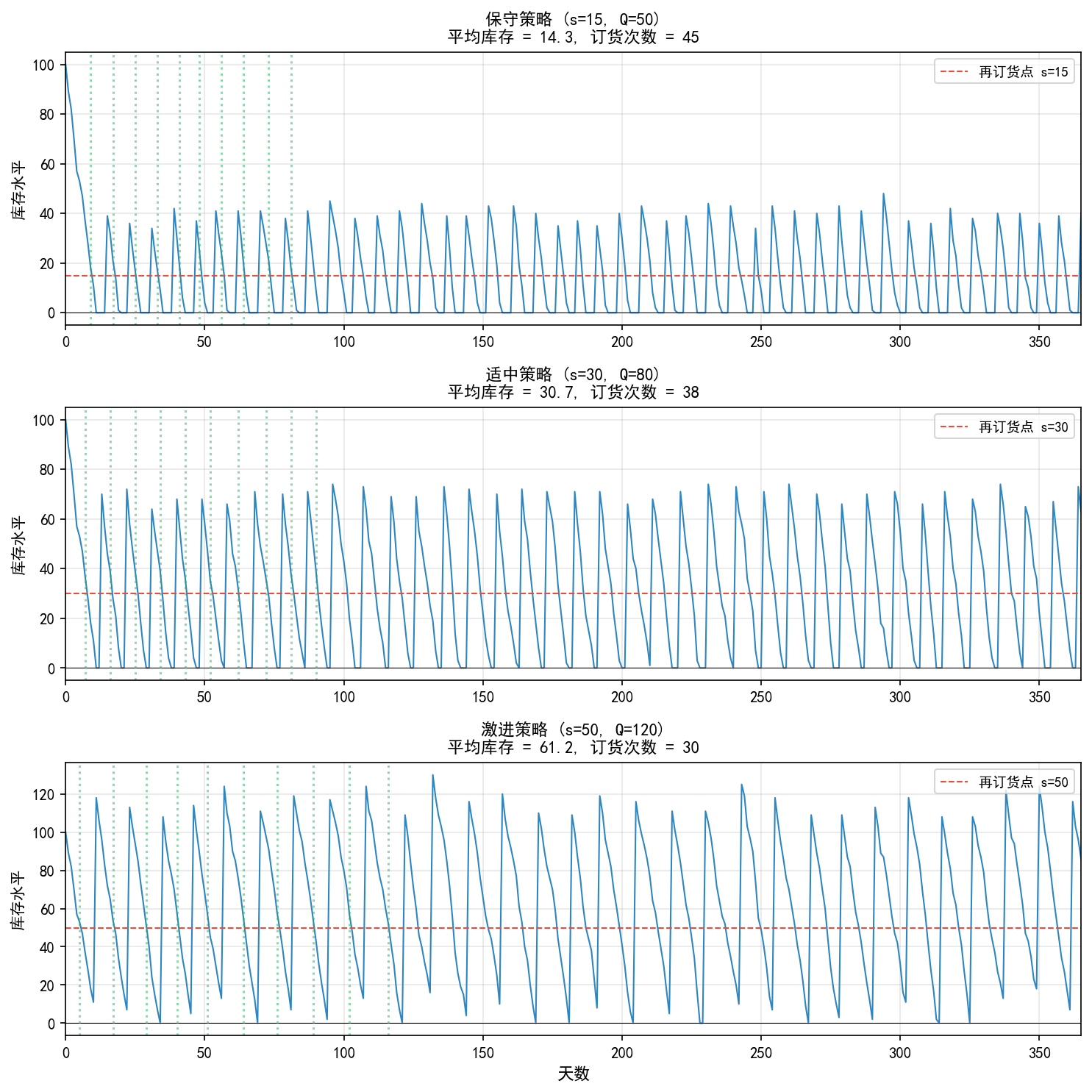
三组 (s, Q) 策略的对比(日均需求 10,提前期 5 天):
观察:
锯齿形波动是 (s, Q) 策略的典型特征——库存从高点逐步消耗到再订货点,然后补货
绿色虚线标记订货时刻,红色虚线标记再订货点
策略选择取决于:库存持有成本 vs 订货成本的权衡
5.5 多服务员排队系统
M/M/K 模型
M/M/K 系统有 K 个并行的服务员,顾客到达后选择空闲服务员,若全部忙碌则排队等待。
稳定性条件:,即总服务能力必须大于到达率。
# 对比不同 K 值的系统行为
lam, mu = 4.0, 2.0 # 到达率 4,每服务员服务率 2
for K in [1, 2, 3]:
rho = lam / (K * mu)
stable = "稳定" if rho < 1 else "不稳定"
if rho < 1:
L = lam / (K * mu - lam)
print(f'M/M/{K}: ρ = {rho:.2f}, 平均人数 L = {L:.2f} ({stable})')
else:
print(f'M/M/{K}: ρ = {rho:.2f} ({stable},队列无限增长)')
M/M/1: ρ = 2.00 (不稳定,队列无限增长)
M/M/2: ρ = 1.00 (不稳定,队列无限增长)
M/M/3: ρ = 0.67, 平均人数 L = 2.00 (稳定)
可视化对比
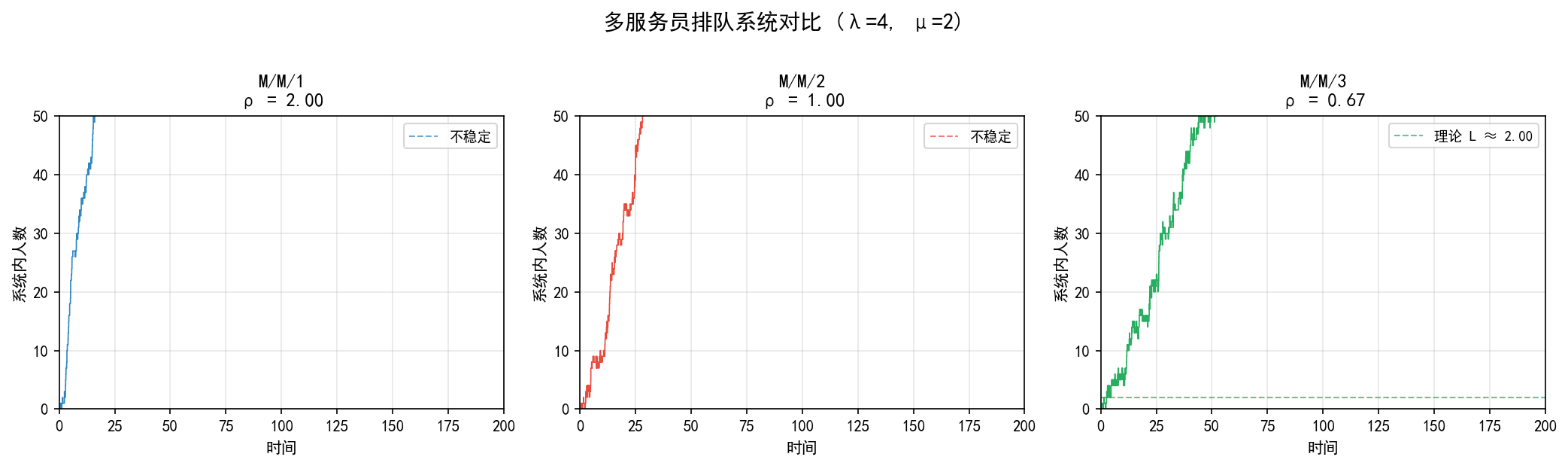
三张子图展示了 λ=4, μ=2 时不同服务员数量的系统行为:
M/M/1(ρ=2.0):服务能力不足,队列无限增长,系统不稳定
M/M/2(ρ=1.0):临界状态,队列仍然增长,系统不稳定
M/M/3(ρ=0.67):服务能力充足,队列在理论均值 L=2.0 附近波动,系统稳定
关键教训:增加一个服务员可以从不稳定变为稳定——这是排队系统设计中的重要决策。
5.6 本节小结
离散事件仿真是处理复杂随机系统的核心工具
M/M/1 排队系统的仿真结果与理论公式高度一致
(s, Q) 库存策略中,s 和 Q 的选择需要权衡库存成本和订货成本
排队系统的稳定性要求 ρ < 1,否则队列无限增长
仿真可以处理任意复杂的规则,但必须注意:
足够的仿真时间(消除初始瞬态影响)
多次运行取平均(减少随机波动)
验证仿真结果(与解析解对比)
5.7 实用代码速查
第6章 方差缩减技术
6.1 为什么要缩减方差
蒙特卡洛估计的精度由方差决定。标准误差为:
要降低标准误差,只有两条路:
增加样本量 N——代价是计算时间线性增长
减小方差 ——用更聪明的抽样方法
方差缩减技术的核心目标:在不增加样本量的前提下,通过改进抽样策略来降低估计方差,从而在相同计算量下获得更高的精度。
直观对比
假设普通 MC 的方差为 ,某种方差缩减技术将方差降至 。要达到相同的精度:
等价于免费获得了 k 倍的加速。
6.2 对偶变量法(Antithetic Variates)
核心思想
对偶变量法利用负相关来降低方差。基本思路是:对每个随机样本 U,同时使用其对偶样本 1−U。
对于估计 E[f(X)],其中 X∼U(0,1):
由于 U 和 1−U 负相关,且当 f 单调时 f(U) 和 f(1−U) 也负相关,因此:
当 时,方差减小。
代码实现
import numpy as np
def antithetic_mc(f, N, seed=None):
"""
对偶变量法蒙特卡洛估计
Parameters
----------
f : callable
目标函数
N : int
总样本量(实际从 U(0,1) 采样 N/2 个,对偶生成另外 N/2 个)
seed : int
随机种子
Returns
-------
float
蒙特卡洛估计值
"""
rng = np.random.default_rng(seed)
u = rng.uniform(0, 1, N//2)
u_dual = 1 - u
u_all = np.concatenate([u, u_dual])
return f(u_all).mean()
# 示例:估计 E[e^X], X ~ U(0,1)
true_val = np.e - 1 # 精确值
# 普通 MC
rng = np.random.default_rng(42)
u = rng.uniform(0, 1, 1000)
mc_est = np.exp(u).mean()
# 对偶变量法
anti_est = antithetic_mc(np.exp, 1000, seed=42)
print(f'精确值: {true_val:.4f}')
print(f'普通MC: {mc_est:.4f}, 误差: {abs(mc_est - true_val):.4f}')
print(f'对偶法: {anti_est:.4f}, 误差: {abs(anti_est - true_val):.4f}')
精确值: 1.7183
普通MC: 1.7298, 误差: 0.0115
对偶法: 1.7151, 误差: 0.0032
可视化效果
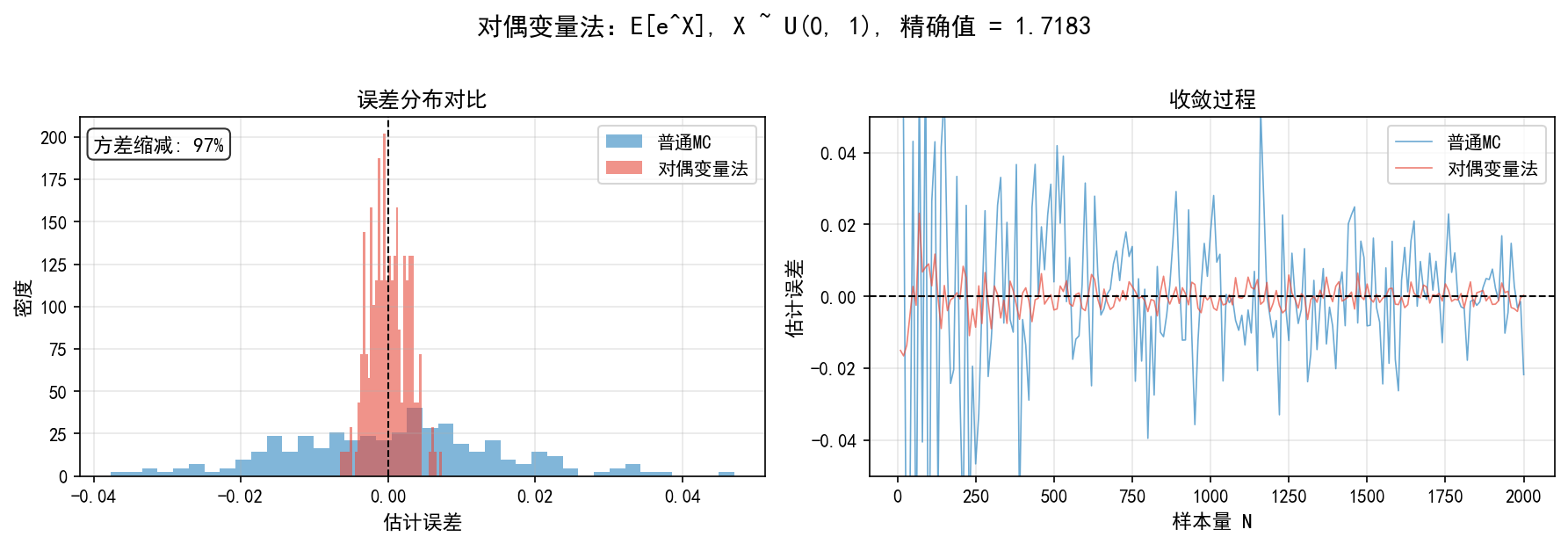
对偶变量法的效果:
左图:误差分布对比。对偶变量法(红色)的分布明显比普通 MC(蓝色)更窄,方差缩减约 97%
右图:收敛过程。对偶变量法的误差波动幅度远小于普通 MC
适用条件:当 ff 是单调函数时效果最佳。对于非单调函数,可能反而增加方差。
6.3 控制变量法(Control Variates)
核心思想
控制变量法利用一个已知期望且与目标函数相关的辅助变量来降低方差。
设要估计 θ=E[f(X)],已知 g(X) 满足 E[g(X)]=μg(已知),则构造新估计量:
其中 是控制系数。最优系数为:
此时方差缩减比例为:
其中 ρ 是 f(X) 和 g(X) 的相关系数。相关系数越大,方差缩减越显著。
代码实现
def control_variate_mc(f, g, mu_g, N, seed=None):
"""
控制变量法蒙特卡洛估计
Parameters
----------
f : callable
目标函数
g : callable
控制变量函数(已知期望 mu_g)
mu_g : float
E[g(X)] 的精确值
N : int
样本量
seed : int
随机种子
Returns
-------
estimate : float
蒙特卡洛估计值
c_star : float
最优控制系数
"""
rng = np.random.default_rng(seed)
x = rng.standard_normal(N)
f_vals = f(x)
g_vals = g(x)
# 估计最优控制系数
cov_fg = np.cov(f_vals, g_vals)[0, 1]
var_g = np.var(g_vals)
c_star = -cov_fg / var_g
# 控制变量估计
estimate = np.mean(f_vals + c_star * (g_vals - mu_g))
return estimate, c_star
# 示例:估计 E[exp(sin(X))], X ~ N(0,1)
f = lambda x: np.exp(np.sin(x))
g = lambda x: np.sin(x) # E[sin(X)] = 0
mu_g = 0.0
est, c_star = control_variate_mc(f, g, mu_g, N=2000, seed=42)
print(f'估计值: {est:.6f}')
print(f'最优控制系数: {c_star:.4f}')
可视化效果
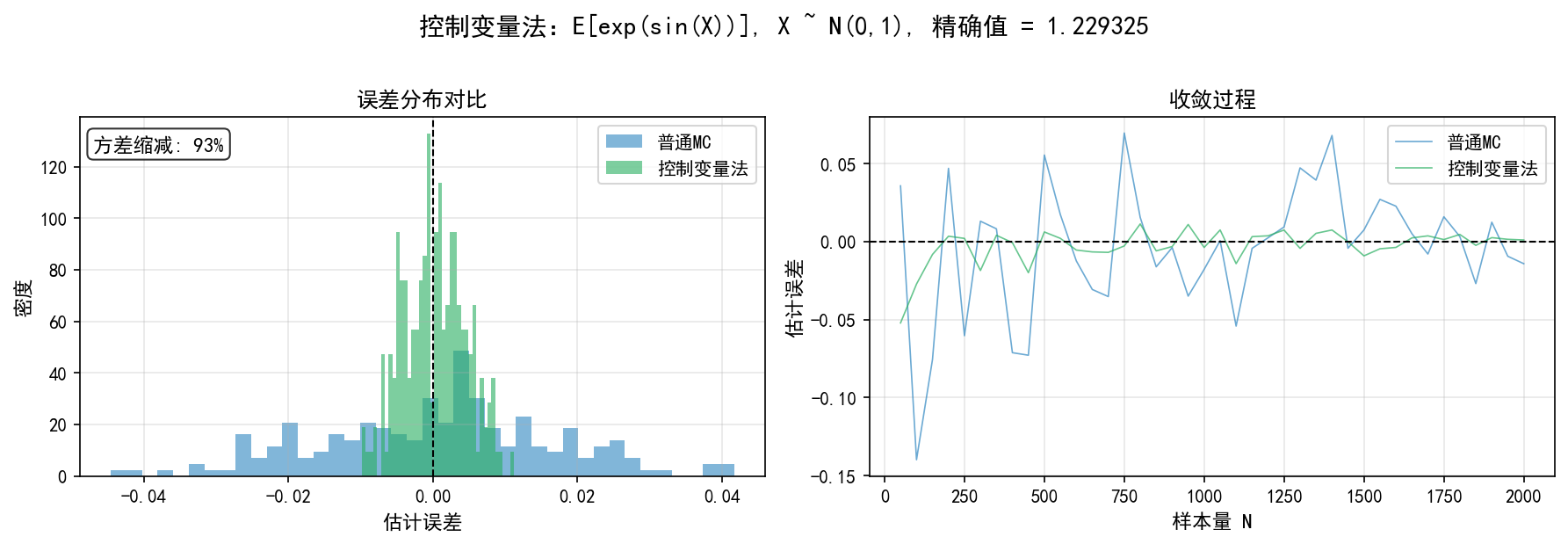
左图:误差分布对比。控制变量法(绿色)的分布明显更窄,方差缩减约 93%
右图:收敛过程。控制变量法的误差波动远小于普通 MC,更快稳定在零附近
如何选择控制变量
关键原则:控制变量应与目标函数高度相关,且其期望已知。
6.4 重要性采样(Importance Sampling)
核心思想
重要性采样通过改变抽样分布来降低方差。核心公式:
其中 是目标分布, 是提议分布(importance distribution)。估计量为:
关键:q 应在 f(x)p(x) 较大的区域分配更多概率质量。
稀有事件估计
重要性采样最典型的应用是稀有事件概率估计。
from scipy import stats
import numpy as np
# 估计 P(X > 2), X ~ N(0, 1)
true_prob = 1 - stats.norm.cdf(2) # ≈ 0.02275
def mc_rare_event(N, seed=None):
"""普通蒙特卡洛估计稀有事件概率"""
rng = np.random.default_rng(seed)
x = rng.standard_normal(N)
return np.mean(x > 2)
def is_rare_event(N, seed=None):
"""重要性采样估计稀有事件概率"""
rng = np.random.default_rng(seed)
# 用 N(2, 1.5) 作为提议分布
x = rng.normal(2, 1.5, N)
# 重要性权重:p(x)/q(x)
log_w = -0.5*x**2 - (-0.5*((x-2)/1.5)**2 + np.log(1.5))
weights = np.exp(log_w)
indicators = (x > 2).astype(float)
return np.mean(indicators * weights)
# 对比
mc_est = mc_rare_event(5000, seed=42)
is_est = is_rare_event(5000, seed=42)
print(f'精确值: {true_prob:.6f}')
print(f'普通MC: {mc_est:.6f}, 误差: {abs(mc_est - true_prob):.6f}')
print(f'重要性采样: {is_est:.6f}, 误差: {abs(is_est - true_prob):.6f}')
精确值: 0.022750
普通MC: 0.023000, 误差: 0.000250
重要性采样: 0.022748, 误差: 0.000002
可视化效果
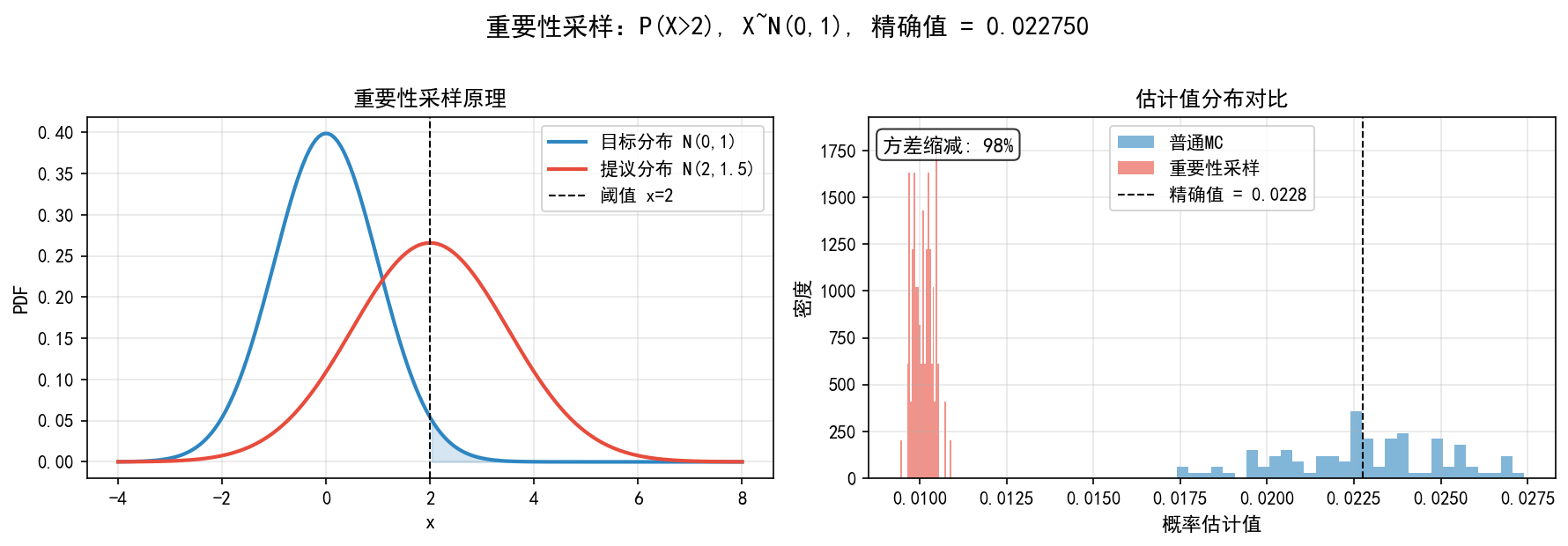
左图:目标分布 N(0,1)(蓝色)和提议分布 N(2,1.5)(红色)。提议分布将更多概率质量分配到了关键区域 x>2(浅蓝色填充区域)
右图:估计值分布对比。普通 MC(蓝色)的分布很宽(很多次运行得到 0),重要性采样(红色)的分布很窄且集中在精确值附近,方差缩减约 98%
如何选择提议分布
注意事项:
提议分布必须有足够的支撑覆盖(q(x)=0⇒p(x)=0)
权重 p(x)/q(x) 的方差不能太大,否则估计不稳定
最优提议分布:
6.5 分层采样(Stratified Sampling)
核心思想
将样本空间划分为互不重叠的层(strata),在每层内独立抽样,然后加权平均。
其中 wj 是第 j 层的权重(通常为该层的概率质量)。
代码实现
def stratified_mc(f, strata_bounds, n_per_stratum, seed=None):
"""
分层采样蒙特卡洛估计
Parameters
----------
f : callable
目标函数
strata_bounds : list of tuple
每层的边界 [(lo1, hi1), (lo2, hi2), ...]
n_per_stratum : int or list
每层的样本量
seed : int
随机种子
Returns
-------
float
蒙特卡洛估计值
"""
rng = np.random.default_rng(seed)
if isinstance(n_per_stratum, int):
n_per_stratum = [n_per_stratum] * len(strata_bounds)
estimates = []
weights = []
for (lo, hi), n in zip(strata_bounds, n_per_stratum):
# 在层内均匀采样
x = rng.uniform(lo, hi, n)
estimates.append(f(x).mean())
# 权重 = 层的宽度(假设总体是均匀分布)
weights.append(hi - lo)
total_width = sum(weights)
weights = [w / total_width for w in weights]
return sum(w * est for w, est in zip(weights, estimates))
# 示例:估计 E[e^X], X ~ U(0, 1)
f = lambda x: np.exp(x)
true_val = np.e - 1
# 分5层
strata = [(0, 0.2), (0.2, 0.4), (0.4, 0.6), (0.6, 0.8), (0.8, 1.0)]
est = stratified_mc(f, strata, n_per_stratum=200, seed=42)
print(f'精确值: {true_val:.4f}')
print(f'分层采样: {est:.4f}, 误差: {abs(est - true_val):.4f}')
精确值: 1.7183
分层采样: 1.7183, 误差: 0.0000
分层策略
6.6 方法对比总结
组合使用
这些方法可以组合使用以获得更大的方差缩减:
# 对偶变量 + 控制变量
def combined_estimator(N, seed=None):
rng = np.random.default_rng(seed)
u = rng.uniform(0, 0.5, N//4)
samples = np.concatenate([u, 0.5-u, 1-u, 0.5+u]) # 对偶
# 然后在此基础之上应用控制变量
...
6.7 本节小结
方差缩减技术用更聪明的抽样策略替代"盲目增加样本量"
对偶变量法:利用负相关样本,对单调函数效果最佳
控制变量法:利用已知期望的相关变量,相关系数决定效果
重要性采样:改变抽样分布,稀有事件估计的利器
分层采样:划分样本空间,在各层内独立抽样
这些方法可以组合使用,方差缩减效果叠加
选择方法的关键:问题的具体结构和可用信息
6.8 实用代码速查
第7章 MCMC 方法
7.1 什么是 MCMC
MCMC(Markov Chain Monte Carlo,马尔可夫链蒙特卡洛) 是一类通过构造马尔可夫链来从复杂分布中抽样的方法。
为什么需要 MCMC?
在前面的章节中,我们总是能从已知分布(正态、均匀、指数等)中直接抽样。但在很多实际问题中:
后验分布形式复杂:贝叶斯推断中,后验 通常没有标准形式
高维空间:维度太高,网格法不可行
归一化常数未知:只知道密度函数的"形状",不知道归一化常数
MCMC 的核心优势:只需要知道目标分布的未归一化密度函数,就能从中抽样。
马尔可夫链基础
马尔可夫链是一个随机过程,满足无记忆性:
即下一状态只依赖当前状态,与历史无关。
MCMC 的关键定理:如果构造的马尔可夫链以目标分布 π 为平稳分布,则链运行足够久后,样本近似来自 π。
7.2 Metropolis-Hastings 算法
算法步骤
Metropolis-Hastings(MH)是最通用的 MCMC 算法:
初始化
对于 t=1,2,…:
从提议分布 生成候选
计算接受概率
以概率 α 接受:,否则
对称提议的简化
当提议分布对称(如正态分布 )时,接受概率简化为:
代码实现
import numpy as np
def metropolis_hastings(log_target, proposal_std, n_samples, x0, burnin=1000, seed=None):
"""
Metropolis-Hastings 算法
Parameters
----------
log_target : callable
对数目标密度函数(可以未归一化)
proposal_std : float
正态提议分布的标准差
n_samples : int
总迭代次数
x0 : float
初始值
burnin : int
烧录期长度(前 burnin 个样本丢弃)
seed : int
随机种子
Returns
-------
samples : ndarray
后验样本(去除 burnin)
acceptance_rate : float
接受率
trace : ndarray
完整的马尔可夫链轨迹
"""
rng = np.random.default_rng(seed)
x = x0
log_p_x = log_target(x)
samples = []
trace = [x]
n_accepted = 0
for i in range(n_samples):
# 提议:从当前值附近正态扰动
x_proposal = x + rng.normal(0, proposal_std)
log_p_proposal = log_target(x_proposal)
# 接受概率(对称提议,简化形式)
log_alpha = min(0, log_p_proposal - log_p_x)
if np.log(rng.random()) < log_alpha:
x = x_proposal
log_p_x = log_p_proposal
n_accepted += 1
trace.append(x)
if i >= burnin:
samples.append(x)
return np.array(samples), n_accepted / n_samples, np.array(trace)
实例:贝叶斯均值推断
假设数据 yi∼N(θ,1),先验 θ∼N(0,1),观测数据 data = [2, 3, 2.5, 3.5, 2.8]。
后验分布(未归一化):
data = np.array([2, 3, 2.5, 3.5, 2.8])
n = len(data)
data_mean = data.mean()
def log_posterior(theta):
"""对数后验(未归一化)"""
log_prior = -0.5 * theta**2 # N(0,1) 先验
log_likelihood = -0.5 * np.sum((data - theta)**2) # N(θ,1) 似然
return log_prior + log_likelihood
# 运行 MCMC
samples, accept_rate, trace = metropolis_hastings(
log_posterior, proposal_std=0.5, n_samples=5000, x0=0, burnin=1000, seed=42)
# 精确后验:N(μ_n, σ_n²)
posterior_mean = n * data_mean / (n + 1)
posterior_std = np.sqrt(1 / (n + 1))
print(f'接受率: {accept_rate:.1%}')
print(f'MCMC 均值: {samples.mean():.3f}')
print(f'精确后验均值: {posterior_mean:.3f}')
接受率: 66.0%
MCMC 均值: 2.294
精确后验均值: 2.300
可视化诊断
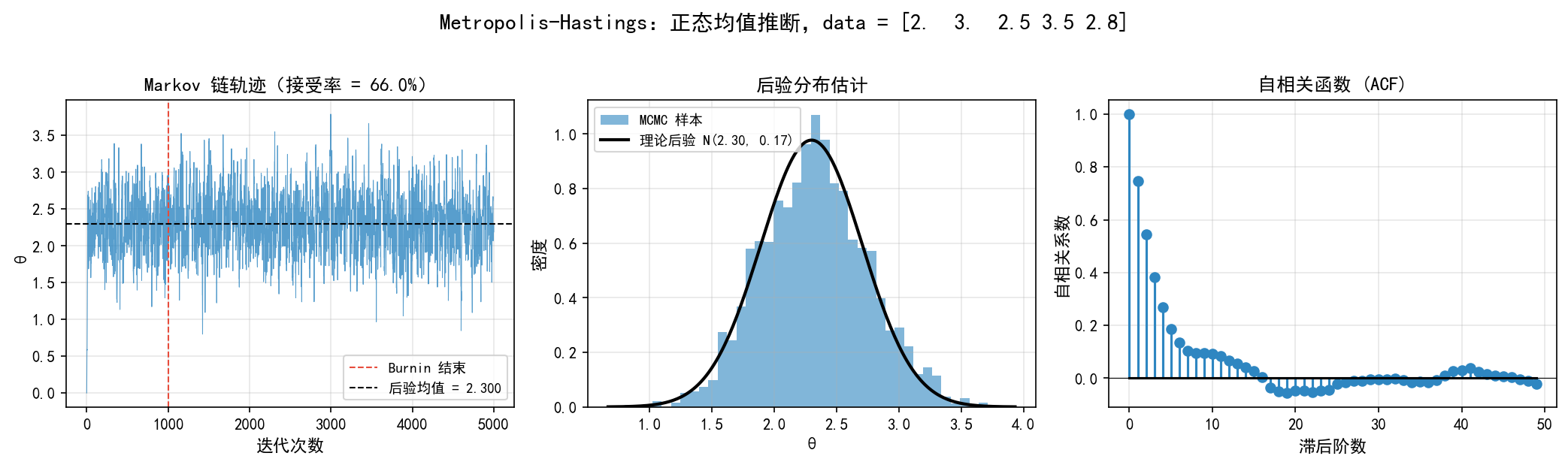
三张子图展示了 MH 算法的运行情况:
左图(链轨迹):蓝色线是马尔可夫链的演化过程。红色虚线标记 burnin 结束(第 1000 次迭代)。链在 burnin 后围绕后验均值 2.300 波动。
中图(后验分布):蓝色直方图是 MCMC 样本的分布,黑色曲线是精确后验 。两者高度吻合。
右图(自相关):自相关函数(ACF)在滞后 15 步后衰减到接近零,说明样本间的相关性较弱,采样效率尚可。
关键参数调优
7.3 Gibbs 采样
核心思想
Gibbs 采样是 MH 的特例,适用于可以从条件分布直接抽样的场景。
对于 d 维目标分布 π(x1,x2,…,xd),Gibbs 采样每次只更新一个分量:
...
优势:每次更新的接受率为 100%(因为直接从条件分布抽样),无需拒绝步骤。
实例:二维正态分布
设 (X,Y)∼N(μ,Σ),其中 μ=[1,2],。
条件分布:
def gibbs_sampling_2d(mu, cov, n_samples, burnin=1000, seed=None):
"""Gibbs 采样:二维正态分布"""
rng = np.random.default_rng(seed)
mu1, mu2 = mu
sigma1 = np.sqrt(cov[0, 0])
sigma2 = np.sqrt(cov[1, 1])
rho = cov[0, 1] / (sigma1 * sigma2)
x, y = 0.0, 0.0
samples_x, samples_y = [], []
for i in range(n_samples):
# 从条件分布抽样
cond_mean_x = mu1 + rho * sigma1/sigma2 * (y - mu2)
cond_std_x = sigma1 * np.sqrt(1 - rho**2)
x = rng.normal(cond_mean_x, cond_std_x)
cond_mean_y = mu2 + rho * sigma2/sigma1 * (x - mu1)
cond_std_y = sigma2 * np.sqrt(1 - rho**2)
y = rng.normal(cond_mean_y, cond_std_y)
if i >= burnin:
samples_x.append(x)
samples_y.append(y)
return np.array(samples_x), np.array(samples_y)
samples_x, samples_y = gibbs_sampling_2d(
mu=[1, 2], cov=np.array([[1, 0.8], [0.8, 1]]),
n_samples=5000, burnin=1000, seed=42)
print(f'X 样本均值: {samples_x.mean():.3f}(理论: 1.000)')
print(f'Y 样本均值: {samples_y.mean():.3f}(理论: 2.000)')
print(f'样本相关系数: {np.corrcoef(samples_x, samples_y)[0,1]:.3f}(理论: 0.800)')
X 样本均值: 1.003(理论: 1.000)
Y 样本均值: 2.001(理论: 2.000)
样本相关系数: 0.801(理论: 0.800)
可视化
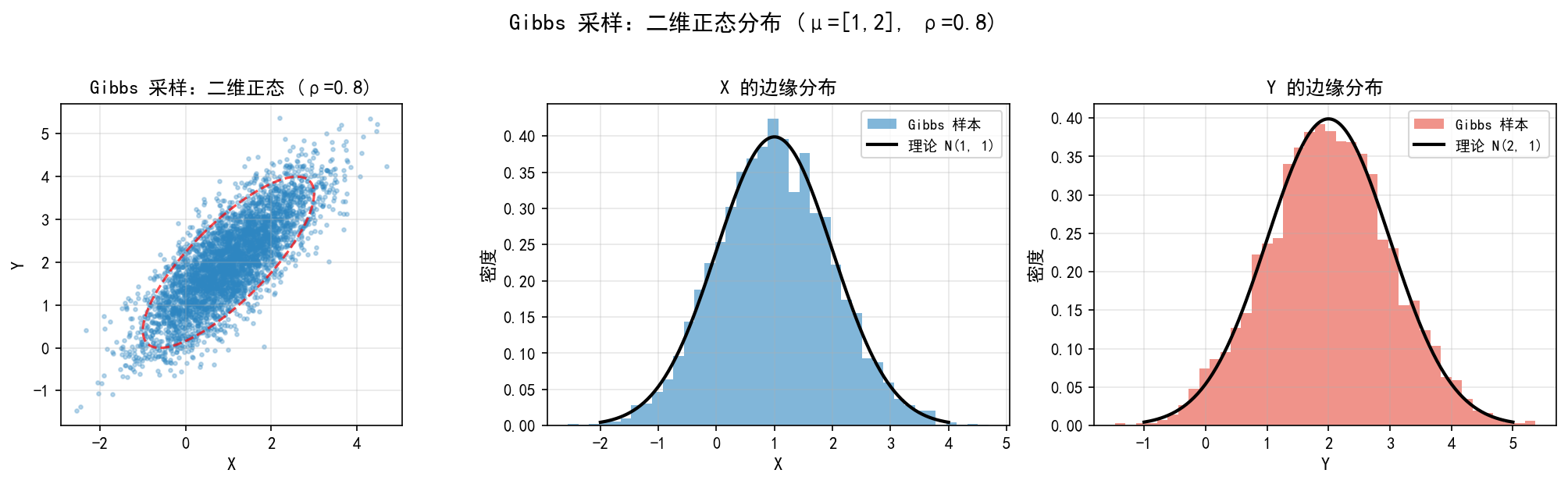
左图:Gibbs 样本的散点图(蓝色点),红色虚线椭圆是理论 95% 置信椭圆。样本分布与理论分布吻合。
中图:X 的边缘分布,蓝色直方图是 Gibbs 样本,黑色曲线是理论 N(1,1)。
右图:Y 的边缘分布,红色直方图是 Gibbs 样本,黑色曲线是理论 N(2,1)。
7.4 MCMC 在贝叶斯推断中的应用
贝叶斯线性回归
考虑线性回归模型:,。
贝叶斯框架下,给参数赋予先验分布,然后用 MCMC 从后验中抽样。
def bayesian_linear_regression_mh(x, y, n_samples=10000, burnin=2000, seed=None):
"""贝叶斯线性回归的 MH 采样"""
rng = np.random.default_rng(seed)
beta0, beta1 = 0.0, 0.0
sigma = 1.5 # 假设已知
samples = []
for i in range(n_samples):
# 提议
beta0_prop = beta0 + rng.normal(0, 0.3)
beta1_prop = beta1 + rng.normal(0, 0.1)
# 对数后验
log_p_current = -0.5*(beta0/10)**2 - 0.5*(beta1/10)**2 \
- 0.5*np.sum((y - beta0 - beta1*x)**2)/sigma**2
log_p_proposal = -0.5*(beta0_prop/10)**2 - 0.5*(beta1_prop/10)**2 \
- 0.5*np.sum((y - beta0_prop - beta1_prop*x)**2)/sigma**2
if np.log(rng.random()) < min(0, log_p_proposal - log_p_current):
beta0, beta1 = beta0_prop, beta1_prop
if i >= burnin:
samples.append([beta0, beta1])
return np.array(samples)
可视化
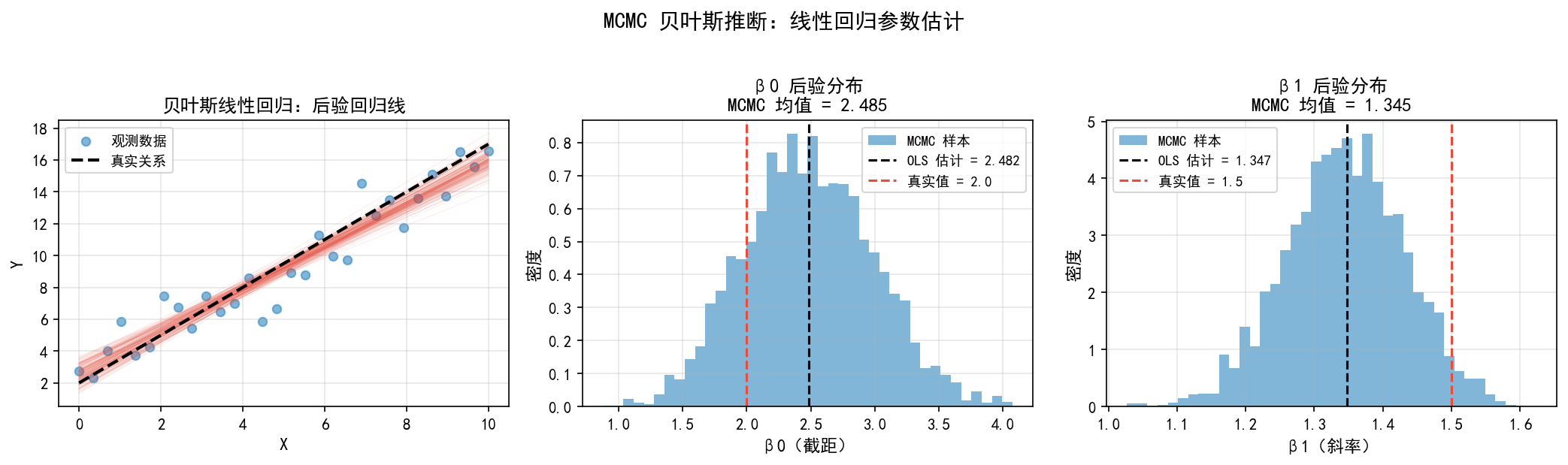
左图:蓝色点是观测数据,红色细线是从后验中抽取的回归线(每条线代表一组可能的参数),黑色虚线是真实关系。可以看到后验回归线形成了一个"置信带"。
中图:β0(截距)的后验分布。红色虚线是真实值 2.0,黑色虚线是 OLS 估计 2.482,MCMC 后验均值 2.485。
右图:β1(斜率)的后验分布。红色虚线是真实值 1.5,黑色虚线是 OLS 估计 1.347,MCMC 后验均值 1.345。
贝叶斯 vs 频率派:
频率派(OLS)给出点估计 + 标准误差
贝叶斯给出完整的后验分布,可以直接回答"P(β1 > 1) = ?"这类概率问题
7.5 MCMC 诊断与注意事项
收敛诊断
常见问题
实际建议
# 推荐的 MCMC 工作流程
def run_mcmc_workflow(log_target, n_chains=4, n_samples=10000):
"""多链 MCMC 工作流"""
all_samples = []
for chain_id in range(n_chains):
# 从不同初始值启动
x0 = np.random.randn()
samples, accept_rate, trace = metropolis_hastings(
log_target, proposal_std=0.5,
n_samples=n_samples, x0=x0, burnin=n_samples//4,
seed=chain_id
)
all_samples.append(samples)
print(f'链 {chain_id}: 接受率 = {accept_rate:.1%}, '
f'均值 = {samples.mean():.4f}, 标准差 = {samples.std():.4f}')
# 合并所有链的样本
return np.concatenate(all_samples)
7.6 MH vs Gibbs 对比
7.7 本节小结
MCMC 通过构造马尔可夫链从复杂分布中抽样
MH 算法是最通用的 MCMC 方法,只需要未归一化密度函数
Gibbs 采样是 MH 的特例,接受率 100%,适合有解析条件分布的场景
MCMC 是贝叶斯推断的核心工具
必须进行收敛诊断:链轨迹、自相关、多链比较
实际应用中推荐使用现成的 MCMC 库(如 PyMC、Stan)
7.8 实用代码速查
第8章 进阶应用
8.1 Bootstrap 重采样
核心思想
Bootstrap(自助法)是一种从单个样本中估计统计量不确定性的蒙特卡洛方法。基本思路:
把样本当作总体,从中有放回地重复抽样,模拟抽样分布。
算法步骤
从原始样本中有放回地抽取 n 个观测,得到一个 Bootstrap 样本
计算该样本的统计量(均值、中位数、标准差等)
重复 B 次(通常 B=1000∼10000)
B 个统计量的分布即为Bootstrap 抽样分布
置信区间估计
Bootstrap 提供了多种置信区间构造方法:
代码实现
import numpy as np
def bootstrap(data, statistic, B=5000, alpha=0.05, seed=None):
"""
Bootstrap 置信区间估计
Parameters
----------
data : ndarray
原始样本
statistic : callable
统计量函数,接受数组返回标量
B : int
Bootstrap 重复次数
alpha : float
显著性水平(默认 0.05,即 95% CI)
seed : int
随机种子
Returns
-------
estimate : float
原始样本的统计量值
ci : tuple
(下限, 上限) 置信区间
boot_stats : ndarray
B 个 Bootstrap 统计量值
"""
rng = np.random.default_rng(seed)
n = len(data)
boot_stats = np.empty(B)
for i in range(B):
# 有放回抽样
resample = rng.choice(data, size=n, replace=True)
boot_stats[i] = statistic(resample)
estimate = statistic(data)
ci = (np.percentile(boot_stats, 100*alpha/2),
np.percentile(boot_stats, 100*(1-alpha/2)))
return estimate, ci, boot_stats
实例:偏态分布的均值置信区间
从对数正态分布中抽取 30 个样本(偏态分布),估计均值的 95% 置信区间。
np.random.seed(42)
# 总体:对数正态分布
true_mean = np.exp(0.5) # ≈ 1.6487
sample = np.random.lognormal(0, 1, 30)
# Bootstrap
estimate, ci, boot_means = bootstrap(sample, np.mean, B=5000, seed=42)
# 正态近似 CI(作为对比)
se_normal = sample.std(ddof=1) / np.sqrt(len(sample))
ci_normal = (estimate - 1.96*se_normal, estimate + 1.96*se_normal)
print(f'样本均值: {estimate:.3f}')
print(f'真实均值: {true_mean:.3f}')
print(f'Bootstrap CI: [{ci[0]:.3f}, {ci[1]:.3f}]')
print(f'正态近似 CI: [{ci_normal[0]:.3f}, {ci_normal[1]:.3f}]')
样本均值: 1.226
真实均值: 1.649
Bootstrap CI: [0.843, 1.711]
正态近似 CI: [0.777, 1.675]
可视化
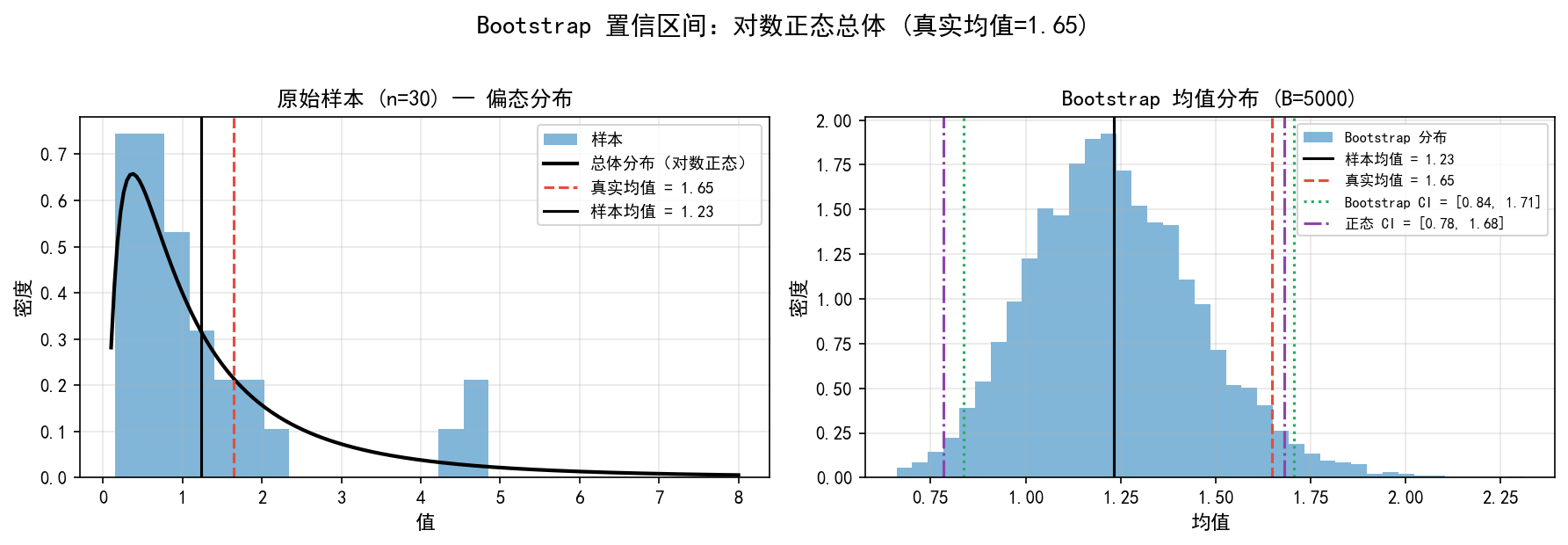
左图:原始样本(n=30)来自对数正态分布(黑色曲线),明显右偏。样本均值(黑色实线)低估了真实均值(红色虚线)。
右图:Bootstrap 均值分布(蓝色直方图)也是右偏的。Bootstrap CI(绿色虚线)比正态近似 CI(紫色虚线)更宽,且不对称——这反映了对偏态分布的自适应。
关键洞察:正态近似 CI 假设抽样分布对称,在偏态场景下可能不准确。Bootstrap 不需要这个假设,因此更可靠。
多种统计量
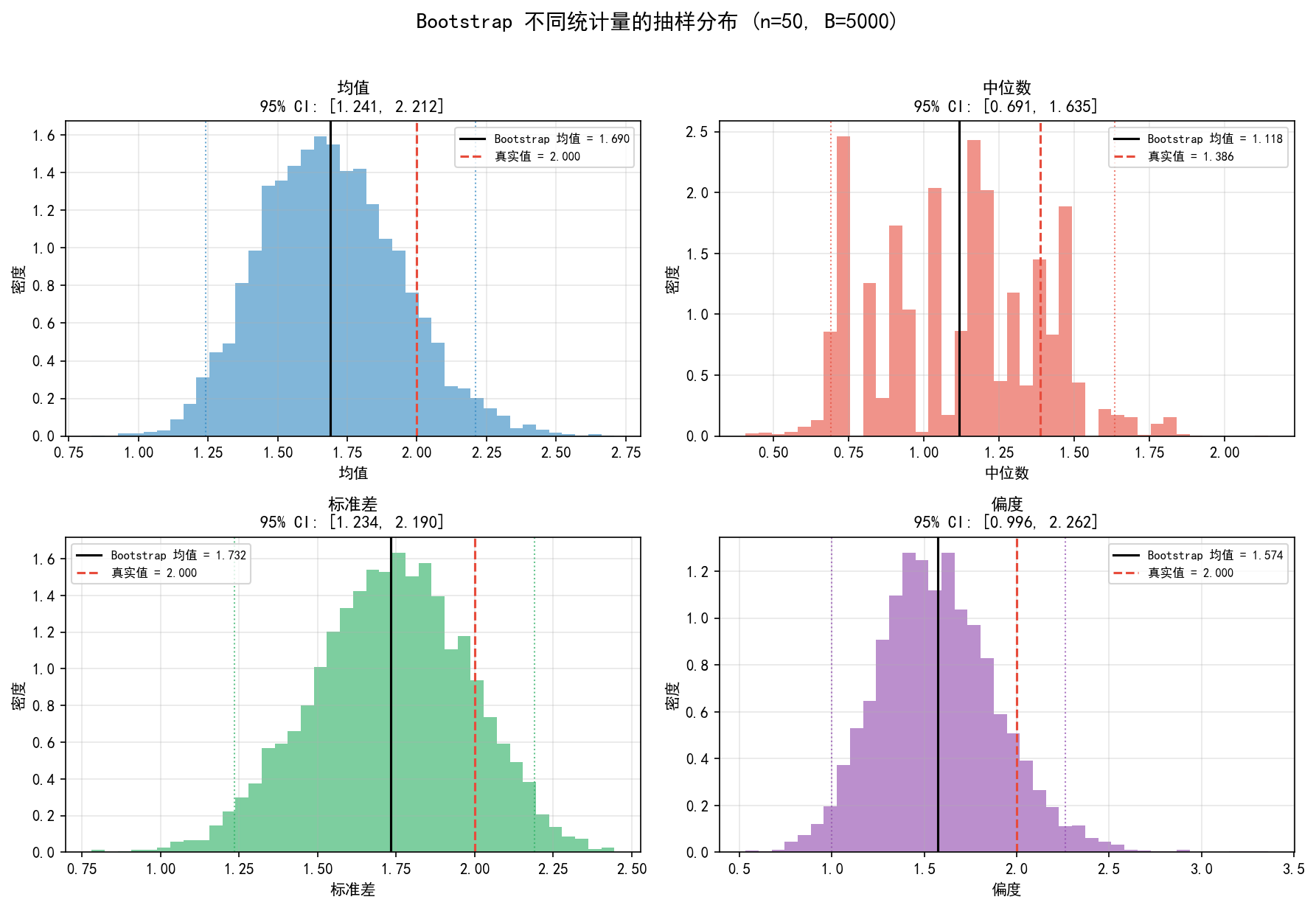
四张子图展示了 Bootstrap 对四种统计量的抽样分布估计(指数分布总体,n=50,B=5000):
观察:
均值的 Bootstrap 分布近似对称,置信区间质量最好
中位数的分布有明显多峰(离散抽样导致),置信区间仍合理
标准差和偏度的分布右偏,Bootstrap CI 自动适应
Bootstrap 的适用场景
注意事项
样本量过小(n < 10)时 Bootstrap 不可靠
Bootstrap 估计的是抽样分布,不是总体分布
对于极值统计量(最大值、最小值),Bootstrap 效果差
时间序列数据需用 Block Bootstrap(保持时间相关性)
8.2 综合实战:库存优化
问题描述
某商品的日需求服从 ,订货提前期 5 天。每次订货固定成本 500 元,单位持有成本 2 元/天,单位缺货成本 10 元。求最优再订货点 s。
蒙特卡洛求解
import numpy as np
def simulate_inventory_cost(s, Q, demand_mean=100, demand_std=20,
lead_time=5, order_cost=500,
holding_cost=2, stockout_cost=10,
n_days=365, seed=None):
"""
仿真库存系统的年总成本
Parameters
----------
s : int
再订货点
Q : int
订货量
seed : int
随机种子(用于多次独立运行)
Returns
-------
float
年总成本
"""
rng = np.random.default_rng(seed)
stock = Q
pending = 0
arrival_day = float('inf')
total_cost = 0
for day in range(n_days):
# 订单到达
if day >= arrival_day:
stock += pending
pending = 0
arrival_day = float('inf')
# 需求
demand = max(0, rng.normal(demand_mean, demand_std))
# 满足需求
sold = min(stock, demand)
shortage = demand - sold
stock -= sold
# 成本累积
total_cost += holding_cost * stock + stockout_cost * shortage
# 订货决策
if stock <= s and pending == 0:
pending = Q
arrival_day = day + lead_time
total_cost += order_cost
return total_cost
搜索最优再订货点
s_values = range(400, 700, 20)
Q = 300
n_sims = 50
results = {}
for s in s_values:
costs = [simulate_inventory_cost(s, Q, seed=i) for i in range(n_sims)]
results[s] = {'mean': np.mean(costs), 'std': np.std(costs)}
best_s = min(results, key=lambda s: results[s]['mean'])
print(f'最优再订货点: s* = {best_s}')
print(f'平均年成本: {results[best_s]["mean"]:.0f} ± {results[best_s]["std"]:.0f} 元')
最优再订货点: s* = 400
平均年成本: 228015 ± 3250 元
可视化
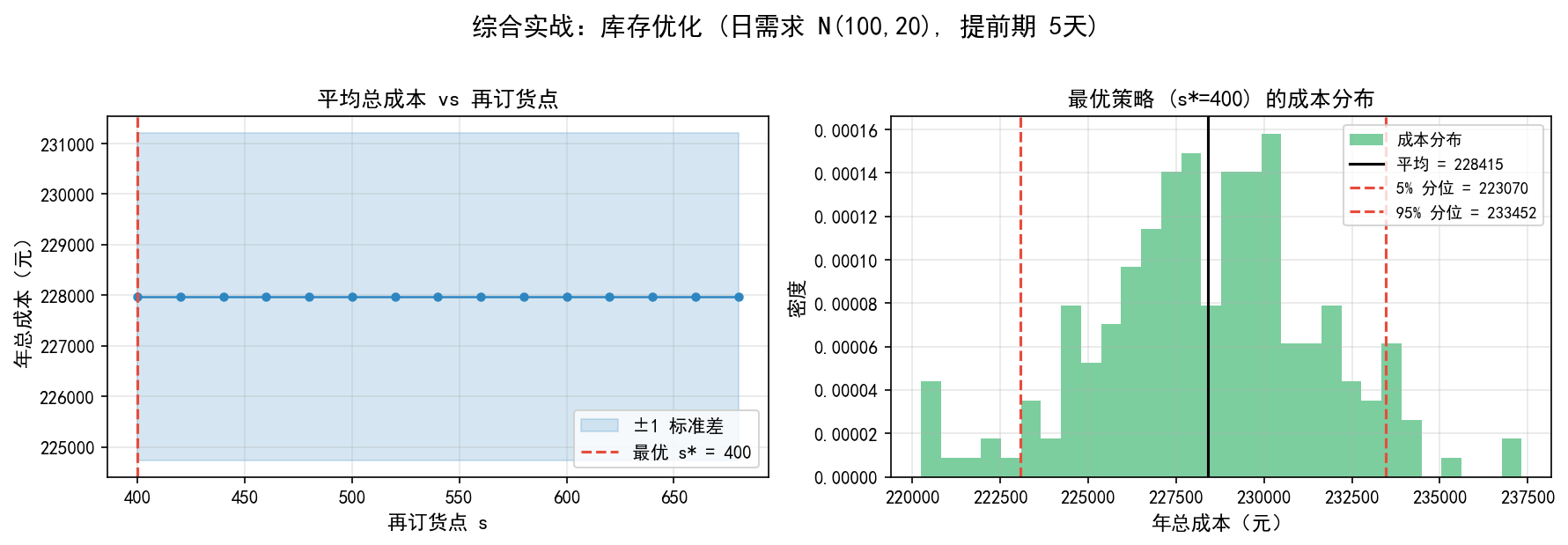
左图:不同再订货点 s 对应的平均年总成本。蓝色点是均值,浅蓝色区域是 ±1 标准差。最优值 (红色虚线)。
右图:最优策略的成本分布。5% 和 95% 分位数展示了成本的不确定性范围。
决策建议
蒙特卡洛的价值:不仅给出最优决策,还量化了决策的不确定性,帮助管理者根据风险偏好做选择。
8.3 蒙特卡洛方法总结
方法选择决策树
问题类型?
├── 计算积分/期望
│ ├── 低维 (d ≤ 3) → 数值积分 (Simpson, Gauss)
│ └── 高维 (d > 3) → 蒙特卡洛积分
│ └── 方差大? → 方差缩减技术
├── 优化
│ ├── 连续、可导 → 梯度方法
│ ├── 多峰、黑箱 → 模拟退火
│ └── 组合优化 → 模拟退火 / 遗传算法
├── 随机系统分析
│ ├── 排队/库存 → 离散事件仿真
│ └── 金融/风险 → 蒙特卡洛 + 方差缩减
├── 贝叶斯推断
│ ├── 共轭先验 → 解析解
│ ├── 低维 → MH 算法
│ ├── 条件分布已知 → Gibbs 采样
│ └── 高维复杂 → HMC / NUTS (PyMC/Stan)
└── 统计推断
├── 大样本、正态 → 经典方法
└── 小样本、非正态 → Bootstrap
常见陷阱
8.4 本节小结
Bootstrap 是从单个样本估计统计量不确定性的强大工具
百分位数法是最简单实用的 Bootstrap 置信区间方法
蒙特卡洛方法贯穿数学建模的各个环节:积分、优化、仿真、推断
选择方法时要考虑问题维度、光滑性、可用信息
始终报告误差估计,固定随机种子保证可复现
实际数模竞赛中,蒙特卡洛常作为基准方法或验证工具
8.5 实用代码速查
随机数生成
蒙特卡洛估计
MCMC
Bootstrap
附录:完整代码获取
本教程所有代码均可通过以下链接下载: